Межполучатель надежность
В этом разделе нужны дополнительные цитаты для проверки . ( Декабрь 2018 г. ) |
В статистике надежность между рейтингом (также называемая различными аналогичными именами, такими как межбасторское соглашение , согласованность между рейтингом , надежность между наблюдателями , надежность межкодеров и т. Д.)-это степень согласия между независимыми наблюдателями скорость, код или оценить то же явление.
Инструменты оценки, которые полагаются на рейтинги, должны проявлять хорошую надежность между оценщиками, в противном случае они не являются действительными тестами .
Существует ряд статистических данных, которые можно использовать для определения надежности между оценкой. Различные статистические данные подходят для различных типов измерения. Некоторые варианты-это совместный соглашение, такие как Каппа Коэна , Скотт Пи и Флисс Каппа ; или межполучательская корреляция, коэффициент корреляции согласия , корреляция внутри классов и альфа Криппендорфа .
Концепция
[ редактировать ]Существует несколько оперативных определений «надежности между оценкой», отражающих различные точки зрения о том, что является надежным согласием между оценщиками. [ 1 ] Есть три операционных определения соглашения:
- Надежные оценщики согласны с «официальным» рейтингом эффективности.
- Надежные оценщики согласны друг с другом по поводу точных рейтингов, которые будут присуждены.
- Надежные оценщики согласны с тем, какая производительность лучше, а какая.
Они в сочетании с двумя оперативными определениями поведения:
- Надежными оценщиками являются автоматы, ведущие как «Рейтинговые машины». Эта категория включает в себя оценки эссе по компьютеру [ 2 ] Такое поведение может быть оценено с помощью теории обобщения .
- Надежные оценщики ведут себя как независимые свидетели. Они демонстрируют свою независимость, немного не согласившись. Такое поведение может быть оценено моделью Rasch .
Статистика
[ редактировать ]Совместная вероятность согласия
[ редактировать ]Совместная экономия соглашения является самой простой и наименее надежной мерой. Он оценивается как процент того времени, когда оценщики соглашаются в номинальной или категориальной системе рейтинга. Это не учитывает тот факт, что соглашение может произойти исключительно на основе случайности. Существует какой -то вопрос, необходимо ли «исправить» для случайного соглашения; Некоторые предполагают, что в любом случае любая такая корректировка должна основываться на явной модели того, как шанс и ошибка влияют на решения оценщиков. [ 3 ]
Когда количество используемых категорий невелико (например, 2 или 3), вероятность 2 оценщиков с учетом чистой случайности резко возрастает. Это связано с тем, что оба оценщика должны ограничиваться ограниченным количеством доступных вариантов, что влияет на общую скорость согласия, и не обязательно их склонность к «внутреннему» соглашению (соглашение считается «внутренним», если это не связано с случайностью).
Следовательно, совместная вероятность согласия останется высокой даже в отсутствие какого -либо «внутреннего» соглашения между оценщиками. Ожидается, что полезный коэффициент надежности между оценкой (а) будет близок к 0, когда нет «внутреннего» соглашения, и (b) увеличиваться по мере улучшения «внутренней» соглашения. Большинство корректных коэффициентов согласия достигают первой цели. Тем не менее, вторая цель не достигается многими известными поправками на случайность. [ 4 ]
Каппа статистика
[ редактировать ]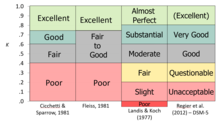
Каппа - это способ измерения согласия или надежности, исправляя то, как часто рейтинги могут согласоваться случайно. Каппа Коэна, [ 5 ] который работает для двух оценщиков, и Fleiss 'Kappa, [ 6 ] Адаптация, которая работает для любого фиксированного числа оценщиков, улучшает совместную вероятность в том, что они учитывают сумму соглашения, которое, как можно ожидать, произойдет через случайность. Первоначальные версии имели ту же проблему, что и совместная допущность , поскольку они рассматривают данные как номинальные и предполагают, что рейтинги не имеют естественного упорядочения; Если данные фактически имеют ранг (порядковый уровень измерения), то эта информация не полностью рассматривается в измерениях.
Более поздние расширения подхода включали версии, которые могли бы обрабатывать «частичный кредит» и порядковые шкалы. [ 7 ] Эти расширения сходятся с семейством внутриклассных корреляций (ICCS), поэтому существует концептуально связанный способ оценки надежности для каждого уровня измерения от номинального (каппа) до порядкового (порядковой каппа или ICC-устричь допущения) до интервала (ICC , или порядковая каппа - обращение с интервальной шкалой как порядковой) и соотношение (ICC). Также есть варианты, которые могут рассмотреть согласие оценщиков по набору элементов (например, два интервьюера согласны с оценками депрессии для всех элементов на одном полуструктурированном интервью для одного случая?), А также о оценке X. (Например, насколько хорошо два или более оценщики согласны с тем, имеют ли 30 случаев диагноз депрессии, да/нет - номинальная переменная).
Каппа похож на коэффициент корреляции в том, что он не может превышать +1,0 или ниже -1,0. Поскольку он используется в качестве меры согласия, в большинстве ситуаций можно ожидать только положительных значений; Отрицательные значения указывают на систематическое несогласие. Каппа может достигать очень высоких значений только тогда, когда оба согласия хороши, а скорость целевого состояния составляет около 50% (поскольку она включает базовую ставку при расчете совместных вероятностей). Несколько органов власти предложили «Правила эмпиатра» для интерпретации уровня соглашения, многие из которых согласны с GIST, даже если слова не являются идентичны. [ 8 ] [ 9 ] [ 10 ] [ 11 ]
Коэффициенты корреляции
[ редактировать ]Либо Пирсонс , Кендалл τ или Спирмен , Может использоваться для измерения парной корреляции среди оценщиков, используя упорядоченную шкалу. Пирсон предполагает, что шкала оценки непрерывна; Статистика Кендалла и Спирмана предполагают, что она порядковая. Если наблюдаются более двух оценщиков, средний уровень согласия для группы может быть рассчитано как среднее значение , τ , или Значения от каждой возможной пары оценщиков.


Внутренний коэффициент корреляции
[ редактировать ]Другим способом выполнения тестирования надежности является использование внутриклассового коэффициента корреляции (ICC). [ 12 ] Существует несколько типов этого, и один определяется как «доля дисперсии наблюдения из-за изменчивости между субъектом в истинных оценках». [ 13 ] Диапазон ICC может составлять от 0,0 до 1,0 (раннее определение ICC может быть между -1 до +1). ICC будет высоким, когда оценщики, приведенные каждым элементом, не будут иметь небольших изменений, например, если все оценщики дают одинаковые или похожие оценки для каждого из элементов. ICC - улучшение по сравнению с Пирсоном и Спирмен , поскольку это учитывает различия в оценках для отдельных сегментов, наряду с корреляцией между оценщиками.
Пределы соглашения
[ редактировать ]
Другой подход к согласию (полезный, когда существует только два оценщика, а шкала непрерывна) заключается в расчете различий между каждой парой наблюдений двух оценщиков. Среднее значение этих различий называется смещением , а эталонный интервал (среднее значение ± 1,96 × стандартное отклонение ) называется пределами согласия . Пределы согласия дают представление о том, сколько случайных изменений может влиять на рейтинги.
Если оценщики склонны соглашаться, различия между наблюдениями оценщиков будут почти нулевыми. Если один оценщик обычно выше или ниже другого на постоянную сумму, смещение будет отличаться от нуля. Если оценщики, как правило, не согласны, но без последовательной схемы одного рейтинга выше другого, среднее значение будет около нуля. Доветные пределы (обычно 95%) могут быть рассчитаны как для смещения, так и для каждого из пределов согласия.
Есть несколько формул, которые можно использовать для расчета пределов согласия. Простая формула, которая была приведена в предыдущем абзаце и хорошо работает для размера выборки более 60, [ 14 ] является

Для меньших размеров выборки еще одно распространенное упрощение [ 15 ] является

Однако наиболее точная формула (которая применима для всех размеров выборки) [ 14 ] является

Блэнд и Альтман [ 15 ] расширили эту идею, график разницы в каждой точке, среднюю разницу и пределы согласия по вертикали в отношении среднего из двух рейтингов на горизонтали. Полученный сюжет Бланда -Альтман демонстрирует не только общую степень согласия, но также и о том, связано ли соглашение с базовой стоимостью элемента. Например, два оценщика могут тесно согласиться в оценке размера мелких предметов, но не согласны с более крупными предметами.
При сравнении двух методов измерения, представляет не только интерес к оценке как предвзятости , так и ограничений согласия между двумя методами (межполучательское согласие), но и оценить эти характеристики для каждого метода внутри себя. Вполне может быть, что согласие между двумя методами плохое просто потому, что один из методов имеет широкие границы согласия, в то время как другой имеет узкие. В этом случае метод с узкими пределами согласия будет превосходить с статистической точки зрения, в то время как практические или другие соображения могут изменить эту оценку. То, что представляет собой узкие или широкие пределы согласия или крупного или небольшого уклона, является вопросом практической оценки в каждом случае.
Альфа Криппендорфа
[ редактировать ]Криппендорфа Альфа [ 16 ] [ 17 ] является универсальной статистикой, которая оценивает соглашение, достигнутое среди наблюдателей, которые классифицируют, оценивают или измеряют заданный набор объектов с точки зрения значений переменной. Он обобщает несколько специализированных коэффициентов соглашения, принимая любое количество наблюдателей, применимо к номинальным, порядковым, интервалу и уровням измерения измерения, имея возможность обрабатывать отсутствующие данные и корректировать для небольших размеров выборки.
Альфа появилась в анализе контента, где текстовые единицы классифицируются подготовленными кодерами и используются в исследованиях консультирования и обследования , где эксперты кодируют открытые данные интервью в анализе, в психометрии , где отдельные атрибуты протестируются несколькими методами, в обсервационных исследованиях , где неструктурированные события записаны для последующего анализа и в вычислительной лингвистике , где тексты аннотируются для различных синтаксических и семантических качеств.
Разногласия
[ редактировать ]Для любой задачи, в которой несколько оценщиков полезны, ожидается, что оценщики не согласятся с наблюдаемой мишенью. Напротив, ситуации, связанные с однозначным измерением, такие как простые задачи подсчета (например, количество потенциальных клиентов, входящих в магазин), часто не требуют более одного человека, выполняющего измерение.
Измерение, включающее двусмысленность в характеристиках, представляющих интерес для оценки, обычно улучшается с несколькими обученными оценщиками. Такие задачи измерения часто связаны с субъективным суждением о качестве. Примеры включают рейтинги врача «прикроватной манеры», оценку доверия свидетелей присяжными и навыки презентации спикера.
Изменение по оценкам в процедурах измерения и изменчивость в интерпретации результатов измерения являются двумя примерами источников дисперсии ошибок в оценках измерений. Четко заявленные руководящие принципы для рейтинга рендеринга необходимы для надежности в неоднозначных или сложных сценариях измерения.
Без рекомендаций по оценке оценки на рейтинги все чаще влияют предвзятость экспериментатора , то есть тенденцию рейтинговых значений к дрейфу к тому, что ожидается оценщиком. Во время процессов, включающих повторные измерения, коррекция дрейфа оценщика может быть рассмотрена посредством периодической переподготовки, чтобы обеспечить, чтобы оценщики понимали руководящие принципы и цели измерения.
Смотрите также
[ редактировать ]Ссылки
[ редактировать ]- ^ Saal, Fe; Дауни, RG; Lahey, MA (1980). «Оценка рейтингов: оценка психометрического качества данных оценки» . Психологический бюллетень . 88 (2): 413. DOI : 10.1037/0033-2909.88.2.413 .
- ^ Page, EB; Петерсен, Н.С. (1995). «Компьютер переходит в оценку эссе: обновление древнего теста» . Пхи Дельта Каппан . 76 (7): 561.
- ^ Uebersax, JS (1987). «Разнообразие моделей принятия решений и измерение соглашения об межзащите» . Психологический бюллетень . 101 (1): 140–146. doi : 10.1037/0033-2909.101.1.140 . S2CID 39240770 .
- ^ "Исправление надежности между рейтингом для случайного соглашения: почему?" Полем www.agreestat.com . Архивировано с оригинала 2018-04-02 . Получено 2018-12-26 .
- ^ Cohen, J. (1960). «Коэффициент согласия для номинальных масштабов» (PDF) . Образовательное и психологическое измерение . 20 (1): 37–46. doi : 10.1177/001316446002000104 . S2CID 15926286 .
- ^ Fleiss, JL (1971). «Измерение номинального соглашения по шкале между многими оценщиками» . Психологический бюллетень . 76 (5): 378–382. doi : 10.1037/h0031619 .
- ^ Лэндис, Дж. Ричард; Кох, Гэри Г. (1977). «Измерение соглашения наблюдателя для категориальных данных» . Биометрия . 33 (1): 159–74. doi : 10.2307/2529310 . JSTOR 2529310 . PMID 843571 . S2CID 11077516 .
- ^ Лэндис, Дж. Ричард; Кох, Гэри Г. (1977). «Применение иерархической статистики типа каппа при оценке соглашения большинства между несколькими наблюдателями». Биометрия . 33 (2): 363–74. doi : 10.2307/2529786 . JSTOR 2529786 . PMID 884196 .
- ^ Cicchetti, DV; Воробей, SA (1981). «Разработка критериев для установления достоверности межотражающих конкретных элементов: приложения для оценки адаптивного поведения». Американский журнал умственного дефицита . 86 (2): 127–137. PMID 7315877 .
- ^ Fleiss, JL (1981-04-21). Статистические методы для ставок и пропорций. 2 -е изд . Уайли. ISBN 0-471-06428-9 Полем OCLC 926949980 .
- ^ Региер, Даррел А.; Узкий, Уильям Э.; Кларк, Диана Э.; Крамер, Хелена С.; Курамото, С. Джанет; Куль, Эмили А.; Купфер, Дэвид Дж. (2013). «Полевые испытания DSM-5 в Соединенных Штатах и Канаде, часть II: надежность тестирования выбранных категориальных диагнозов». Американский журнал психиатрии . 170 (1): 59–70. doi : 10.1176/appi.ajp.2012.12070999 . ISSN 0002-953X . PMID 23111466 .
- ^ Шрут, PE; Fleiss, JL (1979). «Внутриклассные корреляции: использование при оценке надежности оценщика» . Психологический бюллетень . 86 (2): 420–428. doi : 10.1037/0033-2909.86.2.420 . PMID 18839484 . S2CID 13168820 .
- ^ Everitt, BS (1996). Изучение статистики в психологии: курс второго уровня . Издательство Оксфордского университета. ISBN 978-0-19-852365-9 .
- ^ Jump up to: а беременный Ludbrook, J. (2010). Уверенность в участках Альтмана -Бланда: критический обзор метода различий. Клиническая и экспериментальная фармакология и физиология, 37 (2), 143-149.
- ^ Jump up to: а беременный Bland, JM, & Altman, D. (1986). Статистические методы оценки согласия между двумя методами клинического измерения. Lancet, 327 (8476), 307-310.
- ^ Криппендорф, Клаус (2018). Контент -анализ: введение в свою методологию (4 -е изд.). Лос -Анджелес. ISBN 9781506395661 Полем OCLC 1019840156 .
{{cite book}}: CS1 Maint: местоположение отсутствует издатель ( ссылка ) - ^ Хейс, AF; Криппендорф, К. (2007). «Ответь на вызов для стандартной меры надежности для кодирования данных». Методы и меры связи . 1 (1): 77–89. doi : 10.1080/19312450709336664 . S2CID 15408575 .
Дальнейшее чтение
[ редактировать ]- Gwet, Kilem L. (2014). Справочник по достоверности межполучия (4-е изд.). Гейтерсбург: передовая аналитика. ISBN 978-0970806284 Полем OCLC 891732741 .
- Gwet, KL (2008). «Вычисление достоверности между рейтингом и ее дисперсией в присутствии высокого согласия» (PDF) . Британский журнал математической и статистической психологии . 61 (Pt 1): 29–48. doi : 10.1348/000711006x126600 . PMID 18482474 . S2CID 13915043 . Архивировано из оригинала (PDF) 2016-03-03 . Получено 2010-06-16 .
- Джонсон, Р.; Пенни, Дж.; Гордон Б. (2009). Оценка производительности: разработка, оценка и проверка задач производительности . Гилфорд. ISBN 978-1-59385-988-6 .
- Шукри, М.М. (2010). Меры межбыточного соглашения и надежности (2 -е изд.). CRC Press. ISBN 978-1-4398-1080-4 Полем OCLC 815928115 .
Внешние ссылки
[ редактировать ]- Соглашение 360: Облачный анализ надежности между рейтингом, Каппа Коэна, GWET AC1/AC2, Альфа Криппендорфа, Бреннан-Педигер, Флайсс обобщенные каппа, коэффициенты внутриклассовой корреляции, коэффициенты корреляции
- Статистические методы соглашения о оценке Джона Уэберсакса
- Калькулятор надежности между рейтингом по медицинскому образованию онлайн
- Онлайн (мультиратер) Каппа-калькулятор архивировал 2009-02-28 на машине Wayback
- Онлайн-калькулятор для межполучающего соглашения Архивировал 2016-04-10 на машине Wayback