Межоценочная надежность
Этот раздел нуждается в дополнительных цитатах для проверки . ( декабрь 2018 г. ) |
В статистике надежность между экспертами (также называемая различными похожими названиями, такими как согласие между экспертами , согласованность между экспертами , надежность между наблюдателями , надежность между кодировщиками и т. д.) — это степень согласия между независимыми наблюдателями, которые оценить, закодировать или оценить одно и то же явление.
Инструменты оценки, основанные на рейтингах, должны демонстрировать хорошую межэкспертную надежность, в противном случае они не являются валидными тестами .
Существует ряд статистических данных, которые можно использовать для определения надежности между экспертами. Для разных типов измерений подходят разные статистические данные. Некоторые варианты представляют собой совместную вероятность согласия, например , каппа Коэна , пи Скотта и каппа Флейса ; или корреляция между экспертами, коэффициент корреляции конкордации , внутриклассовая корреляция и альфа Криппендорфа .
Концепция
[ редактировать ]Существует несколько рабочих определений «надежности между оценщиками», отражающих разные точки зрения на то, что такое надежное соглашение между оценщиками. [1] Существует три рабочих определения соглашения:
- Надежные оценщики согласны с «официальной» оценкой выступления.
- Надежные оценщики договариваются друг с другом о том, какие именно рейтинги будут присуждаться.
- Надежные оценщики сходятся во мнении, какая производительность лучше, а какая хуже.
Они сочетаются с двумя оперативными определениями поведения:
- Надежные оценщики — это автоматы, ведущие себя как «рейтинговые машины». В данную категорию входит оценка эссе компьютером. [2] Такое поведение можно оценить с помощью теории обобщаемости .
- Надежные оценщики ведут себя как независимые свидетели. Они демонстрируют свою независимость, слегка не соглашаясь. Такое поведение можно оценить с помощью модели Раша .
Статистика
[ редактировать ]Совместная вероятность соглашения
[ редактировать ]Совместная вероятность соглашения является самым простым и наименее надежным показателем. Он оценивается как процент случаев, когда оценщики соглашаются использовать номинальную или категориальную рейтинговую систему. Он не принимает во внимание тот факт, что соглашение может произойти исключительно случайно. Возникает некоторый вопрос, есть ли необходимость «исправлять» случайное соглашение; некоторые полагают, что в любом случае любая такая корректировка должна основываться на явной модели того, как случайность и ошибка влияют на решения оценщиков. [3]
Когда количество используемых категорий невелико (например, 2 или 3), вероятность того, что два оценщика придут к согласию по чистой случайности, резко возрастает. Это связано с тем, что оба оценщика должны ограничиться ограниченным количеством доступных вариантов, что влияет на общий уровень согласия, а не обязательно на их склонность к «внутреннему» согласию (соглашение считается «внутренним», если оно не является случайным).
Таким образом, общая вероятность согласия останется высокой даже при отсутствии какого-либо «внутреннего» согласия между оценщиками. Ожидается, что полезный коэффициент надежности между экспертами (а) будет близок к 0, когда нет «внутреннего» согласия, и (б) будет увеличиваться по мере улучшения «внутреннего» уровня согласия. Большинство коэффициентов согласия, скорректированных на случайность, достигают первой цели. Однако вторая цель не достигается многими известными мерами, корректируемыми случайностью. [4]
Статистика Каппы
[ редактировать ]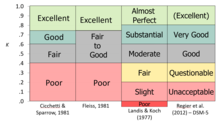
Каппа — это способ измерения согласия или надежности с поправкой на то, как часто рейтинги могут совпадать случайно. Каппа Коэна, [5] который работает для двух оценщиков, и каппа Флейса, [6] адаптация, которая работает для любого фиксированного числа оценщиков, улучшает совместную вероятность, поскольку они принимают во внимание степень согласия, которое, как можно ожидать, произойдет случайно. Первоначальные версии имели ту же проблему, что и совместная вероятность , поскольку они рассматривали данные как номинальные и предполагали, что рейтинги не имеют естественного порядка; если данные действительно имеют ранг (порядковый уровень измерения), то эта информация не полностью учитывается при измерениях.
Более поздние расширения этого подхода включали версии, которые могли обрабатывать «частичный кредит» и порядковые шкалы. [7] Эти расширения сходятся с семейством внутриклассовых корреляций (ICC), поэтому существует концептуально связанный способ оценки надежности для каждого уровня измерения от номинального (каппа) до порядкового (порядковый каппа или ICC — предположения о растяжении) до интервального (ICC). , или порядковая каппа (принимая шкалу интервалов как порядковую) и отношение (ICC). Существуют также варианты, которые могут учитывать согласие оценщиков по набору вопросов (например, согласны ли два интервьюера относительно оценок депрессии по всем пунктам в одном и том же полуструктурированном интервью для одного случая?), а также оценщиков x случаев. (например, насколько хорошо два или более оценщика согласны с тем, есть ли у 30 случаев диагноз депрессии, да/нет — номинальная переменная).
Каппа похожа на коэффициент корреляции тем, что она не может превышать +1,0 или ниже -1,0. Поскольку он используется как мера согласия, в большинстве ситуаций можно ожидать только положительных значений; отрицательные значения будут указывать на систематическое несогласие. Каппа может достичь очень высоких значений только в том случае, если оба соглашения хорошие, а уровень целевого условия составляет около 50% (поскольку он включает базовый уровень в расчет совместных вероятностей). Некоторые авторитетные источники предложили «эмпирические правила» для интерпретации уровня согласия, многие из которых согласны в сути, хотя слова не идентичны. [8] [9] [10] [11]
Коэффициенты корреляции
[ редактировать ]Либо Пирсона , τ Кендалла или Спирмена τ может использоваться для измерения парной корреляции между оценщиками с использованием упорядоченной шкалы. Пирсон предполагает, что шкала оценок является непрерывной; Статистика Кендалла и Спирмена предполагает только то, что он порядковый. Если наблюдают более двух оценщиков, средний уровень согласия для группы можно рассчитать как среднее значение , τ или значения от каждой возможной пары оценщиков.


Коэффициент внутриклассовой корреляции
[ редактировать ]Другой способ проведения тестирования надежности — использование коэффициента внутриклассовой корреляции (ICC). [12] Существует несколько типов этого, и один из них определяется как «доля дисперсии наблюдения из-за вариабельности истинных оценок между субъектами». [13] Диапазон ICC может составлять от 0,0 до 1,0 (раннее определение ICC могло находиться в диапазоне от -1 до +1). ICC будет высоким, если существует небольшая разница между оценками, выставленными оценщиками каждому пункту, например, если все оценщики дают одинаковые или близкие оценки каждому из пунктов. ICC является улучшением по сравнению с Pearson. и Спирмена , так как учитывает различия в рейтингах отдельных сегментов, а также корреляцию между оценщиками.
Пределы соглашения
[ редактировать ]
Другой подход к согласованию (полезный, когда есть только два оценщика и шкала непрерывна) заключается в вычислении разностей между каждой парой наблюдений двух оценщиков. Среднее значение этих различий называется смещением , а референсный интервал (среднее значение ± 1,96 × стандартное отклонение ) называется пределами согласия . Пределы согласия дают представление о том, насколько случайные вариации могут влиять на рейтинги.
Если оценщики склонны соглашаться, различия между наблюдениями оценщиков будут близки к нулю. Если один оценщик обычно выше или ниже другого на постоянную величину, смещение будет отлично от нуля. Если оценщики склонны расходиться во мнениях, но при этом нет устойчивой закономерности, когда одна оценка выше другой, среднее значение будет близко к нулю. Доверительные пределы (обычно 95%) можно рассчитать как для систематической ошибки, так и для каждого из пределов согласия.
Существует несколько формул, которые можно использовать для расчета пределов согласия. Простая формула, приведенная в предыдущем абзаце и хорошо работающая для размера выборки более 60: [14] является

Для меньших размеров выборки есть еще одно распространенное упрощение. [15] является

Однако наиболее точная формула (которая применима для всех размеров выборки) [14] является

Бланд и Альтман [15] расширили эту идею, показав на графике разницу каждой точки, среднюю разницу и пределы согласия по вертикали в сравнении со средним значением двух оценок по горизонтали. Полученный график Бланда-Альтмана демонстрирует не только общую степень согласия, но и то, связано ли согласие с базовой ценностью объекта. Например, два оценщика могут сходиться во мнении в оценке размера мелких предметов, но не соглашаться относительно более крупных предметов.
При сравнении двух методов измерения представляет интерес не только оценить как систематическую ошибку , так и пределы согласия между двумя методами (межэкспертное согласие), но и оценить эти характеристики для каждого метода в отдельности. Вполне возможно, что согласие между двумя методами плохое просто потому, что один из методов имеет широкие пределы согласия , а другой — узкие. В этом случае метод с узкими пределами согласия будет предпочтительнее со статистической точки зрения, в то время как практические или другие соображения могут изменить эту оценку. Что представляет собой узкие или широкие пределы согласия , большую или малую предвзятость, в каждом случае является вопросом практической оценки.
Альфа Криппендорфа
[ редактировать ]Криппендорфа Альфа [16] [17] — это универсальная статистика, которая оценивает согласие, достигнутое между наблюдателями, которые классифицируют, оценивают или измеряют заданный набор объектов с точки зрения значений переменной. Он обобщает несколько специализированных коэффициентов согласия, допуская любое количество наблюдателей, применим к номинальным, порядковым, интервальным и относительным уровням измерения, способен обрабатывать недостающие данные и корректируется для небольших размеров выборки.
Альфа появилась в контент-анализе, где текстовые единицы классифицируются обученными программистами, и используется в консультировании и опросных исследованиях , где эксперты кодируют данные открытых интервью в анализируемые термины, в психометрии , где отдельные атрибуты проверяются несколькими методами, в наблюдательных исследованиях , где неструктурированные события записываются для последующего анализа, а также в компьютерной лингвистике , где тексты аннотируются с учетом различных синтаксических и семантических качеств.
Разногласия
[ редактировать ]Ожидается, что для любой задачи, в которой полезны несколько оценщиков, оценщики не будут расходиться во мнениях относительно наблюдаемой цели. Напротив, ситуации, требующие однозначного измерения, такие как простые задачи подсчета (например, количество потенциальных покупателей, входящих в магазин), часто не требуют выполнения измерения более чем одним человеком.
Измерения, связанные с неоднозначностью характеристик, представляющих интерес для целевого рейтинга, обычно улучшаются с помощью нескольких обученных оценщиков. Такие задачи измерения часто предполагают субъективную оценку качества. Примеры включают оценку «поведения врача у постели больного», оценку присяжными достоверности свидетелей и презентационное мастерство оратора.
Различия в процедурах измерения у разных оценщиков и различия в интерпретации результатов измерений являются двумя примерами источников отклонений ошибок в рейтинговых измерениях. Четко сформулированные рекомендации по вычислению рейтингов необходимы для обеспечения надежности в неоднозначных или сложных сценариях измерения.
Без руководящих принципов выставления оценок на оценки все больше влияет предвзятость экспериментатора , то есть тенденция значений оценок отклоняться в сторону того, что ожидает оценщик. Во время процессов, включающих повторные измерения, коррекция отклонений оценщиков может быть решена посредством периодической переподготовки, чтобы гарантировать, что оценщики понимают руководящие принципы и цели измерений.
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Саал, FE; Дауни, Р.Г.; Лэхи, Массачусетс (1980). «Рейтинг рейтингов: Оценка психометрического качества рейтинговых данных» . Психологический вестник . 88 (2): 413. дои : 10.1037/0033-2909.88.2.413 .
- ^ Пейдж, Э.Б.; Петерсен, Н.С. (1995). «Компьютер переходит к оцениванию эссе: обновление древнего теста» . Пхи Дельта Каппан . 76 (7): 561.
- ^ Уберсакс, Дж. С. (1987). «Разнообразие моделей принятия решений и измерение согласия между экспертами» . Психологический вестник . 101 (1): 140–146. дои : 10.1037/0033-2909.101.1.140 . S2CID 39240770 .
- ^ «Корректировка межоценочной надежности для случайного соглашения: почему?» . www.agreestat.com . Архивировано из оригинала 02 апреля 2018 г. Проверено 26 декабря 2018 г.
- ^ Коэн, Дж. (1960). «Коэффициент согласия для номинальных шкал» (PDF) . Образовательные и психологические измерения . 20 (1): 37–46. дои : 10.1177/001316446002000104 . S2CID 15926286 .
- ^ Фляйсс, Дж. Л. (1971). «Согласование номинальной шкалы между многими оценщиками» . Психологический вестник . 76 (5): 378–382. дои : 10.1037/h0031619 .
- ^ Лэндис, Дж. Ричард; Кох, Гэри Г. (1977). «Измерение соглашения наблюдателя для категориальных данных» . Биометрия . 33 (1): 159–74. дои : 10.2307/2529310 . JSTOR 2529310 . ПМИД 843571 . S2CID 11077516 .
- ^ Лэндис, Дж. Ричард; Кох, Гэри Г. (1977). «Применение иерархической статистики каппа-типа для оценки согласия большинства среди нескольких наблюдателей». Биометрия . 33 (2): 363–74. дои : 10.2307/2529786 . JSTOR 2529786 . ПМИД 884196 .
- ^ Чикетти, Д.В.; Воробей, ЮАР (1981). «Разработка критериев установления межоценочной надежности конкретных объектов: приложения к оценке адаптивного поведения». Американский журнал умственной отсталости . 86 (2): 127–137. ПМИД 7315877 .
- ^ Фляйсс, Дж. Л. (21 апреля 1981 г.). Статистические методы определения ставок и пропорций. 2-е изд . Уайли. ISBN 0-471-06428-9 . OCLC 926949980 .
- ^ Регье, Даррел А.; Узкий, Уильям Э.; Кларк, Диана Э.; Кремер, Хелена К.; Курамото, С. Джанет; Куль, Эмили А.; Купфер, Дэвид Дж. (2013). «Полевые испытания DSM-5 в США и Канаде, Часть II: надежность повторных испытаний выбранных категориальных диагнозов». Американский журнал психиатрии . 170 (1): 59–70. дои : 10.1176/appi.ajp.2012.12070999 . ISSN 0002-953X . ПМИД 23111466 .
- ^ Шраут, ЧП; Фляйсс, Дж.Л. (1979). «Внутриклассовые корреляции: использование при оценке надежности оценщика» . Психологический вестник . 86 (2): 420–428. дои : 10.1037/0033-2909.86.2.420 . ПМИД 18839484 . S2CID 13168820 .
- ^ Эверитт, бакалавр наук (1996). Осмысление статистики в психологии: Курс второго уровня . Издательство Оксфордского университета. ISBN 978-0-19-852365-9 .
- ^ Jump up to: а б Ладбрук, Дж. (2010). Доверие к графикам Альтмана-Бланда: критический обзор метода различий. Клиническая и экспериментальная фармакология и физиология, 37 (2), 143-149.
- ^ Jump up to: а б Бланд Дж. М. и Альтман Д. (1986). Статистические методы оценки согласия между двумя методами клинических измерений. Ланцет, 327 (8476), 307–310.
- ^ Криппендорф, Клаус (2018). Контент-анализ: введение в его методологию (4-е изд.). Лос-Анджелес. ISBN 9781506395661 . OCLC 1019840156 .
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) - ^ Хейс, А.Ф.; Криппендорф, К. (2007). «Отвечая на призыв к стандартным мерам надежности кодирования данных». Методы и меры коммуникации . 1 (1): 77–89. дои : 10.1080/19312450709336664 . S2CID 15408575 .
Дальнейшее чтение
[ редактировать ]- Гвет, Килем Л. (2014). Справочник по надежности между экспертами (4-е изд.). Гейтерсбург: Расширенная аналитика. ISBN 978-0970806284 . OCLC 891732741 .
- Гвет, КЛ (2008). «Вычисление межоценочной надежности и ее дисперсии при высоком согласии» (PDF) . Британский журнал математической и статистической психологии . 61 (Часть 1): 29–48. дои : 10.1348/000711006X126600 . ПМИД 18482474 . S2CID 13915043 . Архивировано из оригинала (PDF) 3 марта 2016 г. Проверено 16 июня 2010 г.
- Джонсон, Р.; Пенни, Дж.; Гордон, Б. (2009). Оценка производительности: разработка, оценка и проверка задач по производительности . Гилфорд. ISBN 978-1-59385-988-6 .
- Шукри, ММ (2010). Меры соглашения между наблюдателями и надежности (2-е изд.). ЦРК Пресс. ISBN 978-1-4398-1080-4 . OCLC 815928115 .
Внешние ссылки
[ редактировать ]- AgreeStat 360: облачный анализ надежности между экспертами, каппа Коэна, AC1/AC2 Гвета, альфа Криппендорфа, Бреннан-Предигер, обобщенная каппа Фляйсса, коэффициенты внутриклассовой корреляции.
- Статистические методы достижения соглашения между оценщиками, Джон Юберсакс
- Калькулятор межоценочной надежности от Medical Education Online
- Онлайн-калькулятор Каппа (мультиратер), заархивировано 28 февраля 2009 г. на Wayback Machine.
- Онлайн-калькулятор соглашения между экспертами. Архивировано 10 апреля 2016 г. на Wayback Machine.