Аварийное восстановление ИТ
Аварийное восстановление ИТ (также просто аварийное восстановление (DR) ) — это процесс поддержания или восстановления жизненно важной инфраструктуры и систем после стихийного бедствия или антропогенного бедствия , такого как шторм или битва. Аварийное восстановление использует политики, инструменты и процедуры с упором на ИТ-системы, поддерживающие критически важные бизнес-функции. [1] Это предполагает поддержание функционирования всех основных аспектов бизнеса, несмотря на значительные разрушительные события; поэтому его можно рассматривать как подмножество обеспечения непрерывности бизнеса (BC). [2] [3] Аварийное восстановление предполагает, что первичный сайт невозможно восстановить немедленно, и восстанавливает данные и службы на вторичном сайте.
Непрерывность ИТ-услуг
[ редактировать ]Непрерывность ИТ-услуг (ITSC) является подмножеством BCP, [4] который опирается на метрики (часто используемые в качестве ключевых индикаторов риска ) целевых точек/времени восстановления. Он включает в себя планирование аварийного восстановления ИТ и более широкое планирование устойчивости ИТ . Он также включает в себя ИТ-инфраструктуру и услуги , связанные с коммуникациями , такие как телефония и передача данных . [5] [6]
Принципы резервного копирования сайтов
[ редактировать ]Планирование включает в себя организацию резервных площадок, независимо от того, являются ли они «горячими» (работающими до катастрофы), «теплыми» (готовыми к началу работы) или «холодными» (для начала работы требуются значительные работы), а также резервными площадками с готовым к работе оборудованием. необходимо для непрерывности.
В 2008 году Британский институт стандартов выпустил специальный стандарт, поддерживающий стандарт непрерывности бизнеса BS 25999 , под названием BS25777, специально для того, чтобы согласовать непрерывность работы компьютеров с непрерывностью бизнеса. Это требование было отозвано после публикации в марте 2011 года стандарта ISO/IEC 27031 «Методы обеспечения безопасности. Рекомендации по обеспечению готовности информационных и коммуникационных технологий к обеспечению непрерывности бизнеса». [7]
ITIL дал определения некоторым из этих терминов. [8]
Целевое время восстановления
[ редактировать ]Целевое время восстановления (RTO) [9] [10] — это целевая продолжительность времени и уровень обслуживания, в пределах которых бизнес-процесс должен быть восстановлен после сбоя, чтобы избежать нарушения непрерывности бизнеса. [11]
Согласно методологии планирования непрерывности бизнеса, RTO устанавливается во время анализа воздействия на бизнес (BIA) владельцем(ами) процесса, включая определение временных рамок для альтернативных или ручных обходных путей.
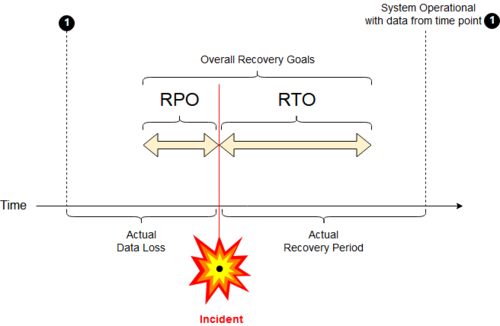
RTO является дополнением RPO. Пределы приемлемой или «приемлемой» производительности ITSC измеряются RTO и RPO с точки зрения времени, потерянного при нормальном функционировании бизнес-процессов, а также данных, потерянных или не скопированных в течение этого периода. [11] [12]
Фактическое время восстановления
[ редактировать ]Фактическое время восстановления (RTA) является важнейшим показателем непрерывности бизнеса и аварийного восстановления. [9]
Группа обеспечения непрерывности бизнеса проводит запланированные репетиции (или фактические данные), в ходе которых RTA определяется и уточняется по мере необходимости. [9]
Цель точки восстановления
[ редактировать ]Целевая точка восстановления (RPO) — это максимально допустимый интервал, в течение которого транзакционные данные теряются из ИТ-службы. [11]
Например, если RPO измеряется в минутах, то на практике зеркальные резервные копии за пределами площадки должны поддерживаться постоянно , поскольку ежедневного резервного копирования за пределы площадки будет недостаточно. [13]
Отношения с РТО
[ редактировать ]Восстановление, которое не является мгновенным, восстанавливает транзакционные данные в течение некоторого интервала времени, не неся при этом значительных рисков или потерь. [11]
RPO измеряет максимальное время, в течение которого последние данные могли быть безвозвратно потеряны, а не является прямым показателем количества потерь. Например, если план BC состоит в восстановлении до последней доступной резервной копии, то RPO — это интервал между такими резервными копиями.
RPO не определяется существующим режимом резервного копирования. Вместо этого BIA определяет RPO для каждой услуги. Если требуются данные за пределами площадки, период, в течение которого данные могут быть потеряны, может начинаться с момента подготовки резервных копий, а не с момента их защиты за пределами площадки. [12]
Среднее время
[ редактировать ]Метрики восстановления можно преобразовать или использовать вместе с метриками сбоев . Общие измерения включают среднее время наработки на отказ (MTBF), среднее время до первого отказа (MTFF), среднее время ремонта (MTTR) и среднее время простоя (MDT).
Точки синхронизации данных
[ редактировать ]Точка синхронизации данных [14] резервное копирование завершено. Он останавливает обработку обновлений, пока копирование с диска на диск завершено. Резервная копия [15] копия отражает более раннюю версию операции копирования; не тогда, когда данные копируются на ленту или передаются куда-либо еще.
Проектирование системы
[ редактировать ]RTO и RPO должны быть сбалансированы с учетом бизнес-рисков, а также других критериев проектирования системы. [16]
RPO привязан к времени резервного копирования за пределами офиса. Отправка синхронных копий на внешнее зеркало позволяет избежать большинства непредвиденных событий. Использование физической транспортировки лент (или других переносимых носителей) является обычным явлением. Восстановление можно активировать на заранее заданном сайте. Общее удаленное пространство и оборудование дополняют пакет. [17]
Для больших объемов ценных транзакционных данных оборудование можно разделить на несколько площадок.
История
[ редактировать ]Планирование аварийного восстановления и информационные технологии (ИТ) развивались в середине-конце 1970-х годов, когда руководители компьютерных центров начали осознавать зависимость своих организаций от своих компьютерных систем.
В то время большинство систем представляли собой мейнфреймы, ориентированные на пакетную обработку . Внешний мэйнфрейм можно загрузить с резервных лент до восстановления основного сайта; время простоя было относительно менее критичным.
Отрасль аварийного восстановления [18] [19] разработан для обеспечения резервных компьютерных центров. Sungard Availability Services был одним из первых таких центров, расположенных в Шри-Ланке (1978 г.). [20] [21]
В 1980-х и 90-х годах вычислительная техника росла в геометрической прогрессии, включая внутреннее корпоративное разделение времени, онлайн-ввод данных и обработку в реальном времени . Доступность ИТ-систем стала более важной.
В дело были вовлечены регулирующие органы; Часто требовались цели доступности 2, 3, 4 или 5 девяток (99,999%), и высокой доступности решения для объектов с горячими площадками . искались [ нужна ссылка ]
Непрерывность ИТ-услуг стала важной частью управления непрерывностью бизнеса (BCM) и управления информационной безопасностью (ICM), как указано в ISO/IEC 27001 и ISO 22301 соответственно.
Рост популярности облачных вычислений с 2010 года создал новые возможности для повышения устойчивости систем. Поставщики услуг взяли на себя ответственность за поддержание высокого уровня обслуживания, включая доступность и надежность. Они предложили высокоустойчивые сетевые конструкции. Восстановление как услуга (RaaS) широко доступно и поддерживается Cloud Security Alliance . [22]
Классификация
[ редактировать ]Бедствия могут быть результатом трех широких категорий угроз и опасностей.
- К стихийным бедствиям относятся такие стихийные бедствия, как наводнения, ураганы, торнадо, землетрясения и эпидемии.
- К технологическим опасностям относятся аварии или отказы систем и сооружений, такие как взрывы трубопроводов, аварии на транспорте, сбои в работе коммунальных сетей, прорывы плотин и случайные выбросы опасных материалов.
- Угрозы антропогенного характера, которые включают преднамеренные действия, такие как активные нападения, химические или биологические атаки, кибератаки на данные или инфраструктуру, саботаж и войны.
Меры по обеспечению готовности ко всем категориям и типам стихийных бедствий подразделяются на пять областей миссии: предотвращение, защита, смягчение последствий, реагирование и восстановление. [23]
Планирование
[ редактировать ]Исследования подтверждают идею о том, что внедрение более целостного подхода к планированию действий до стихийного бедствия является более экономически эффективным. Каждый доллар, потраченный на снижение опасности (например, план аварийного восстановления ), экономит обществу 4 доллара на затратах на реагирование и восстановление. [24]
Статистика аварийного восстановления за 2015 год показывает, что простой в течение одного часа может стоить [25]
- малые компании $8000,
- организации среднего размера — 74 000 долларов США, и
- крупные предприятия — 700 000 долларов и более.
Поскольку ИТ-системы становятся все более важными для бесперебойной работы компании и, возможно, экономики в целом, возрастает важность обеспечения непрерывной работы этих систем и их быстрого восстановления. [26]
Меры борьбы
[ редактировать ]Меры контроля — это шаги или механизмы, которые могут уменьшить или устранить угрозы. Выбор механизмов отражается в плане аварийного восстановления (DRP).
Меры контроля можно классифицировать как меры контроля, направленные на предотвращение возникновения события, меры контроля, направленные на обнаружение или обнаружение нежелательных событий, и меры контроля, направленные на исправление или восстановление системы после катастрофы или события.
Эти меры контроля документируются и регулярно осуществляются с использованием так называемых «тестов DR».
Стратегии
[ редактировать ]Стратегия аварийного восстановления вытекает из плана обеспечения непрерывности бизнеса. [27] Затем показатели бизнес-процессов сопоставляются с системами и инфраструктурой. [28] Анализ затрат и выгод показывает, какие меры аварийного восстановления являются целесообразными. Различные стратегии имеют смысл, исходя из стоимости простоя по сравнению со стоимостью реализации конкретной стратегии.
Общие стратегии включают в себя:
- резервные копии на ленту и отправка за пределы объекта
- резервное копирование на диск на месте (копирование на внешний диск) или за пределы объекта
- репликация за пределами площадки, например, после восстановления или синхронизации систем, возможно, с помощью сети хранения данных. технологии
- решения для частного облака, которые реплицируют метаданные (виртуальные машины, шаблоны и диски) в частное облако. Метаданные настраиваются как XML- представление, называемое открытым форматом виртуализации, и их можно легко восстановить.
- гибридные облачные решения, которые реплицируют как локальные, так и удаленные центры обработки данных. Это обеспечивает мгновенное переключение на локальное оборудование или в облачные центры обработки данных.
- системы высокой доступности, которые хранят как данные, так и систему, реплицированные за пределами площадки, обеспечивая непрерывный доступ к системам и данным даже после катастрофы (часто связанной с облачным хранилищем ). [29]
Стратегии предосторожности могут включать:
- локальные зеркала систем и/или данных и использование технологии защиты дисков, такой как RAID
- сетевые фильтры — для минимизации воздействия скачков напряжения на чувствительное электронное оборудование.
- использование источника бесперебойного питания (ИБП) и/или резервного генератора для поддержания работы систем в случае сбоя питания
- системы предотвращения/смягчения пожара, такие как сигнализация и огнетушители
- антивирусное программное обеспечение и другие меры безопасности.
Аварийное восстановление как услуга
[ редактировать ]
Аварийное восстановление как услуга (DRaaS) — это соглашение со сторонним поставщиком о выполнении некоторых или всех функций аварийного восстановления в таких сценариях, как отключение электроэнергии, отказы оборудования, кибератаки и стихийные бедствия. [30]
См. также
[ редактировать ]- Резервный сайт
- БС 25999
- Планирование непрерывности бизнеса
- Непрерывность бизнеса
- Непрерывная защита данных
- План аварийного восстановления
- Реагирование на стихийные бедствия
- Управление в чрезвычайных ситуациях
- Высокая доступность
- План действий в чрезвычайных ситуациях информационной системы
- Восстановление в реальном времени
- Цель обеспечения согласованности восстановления
- Служба удаленного резервного копирования
- Виртуальная ленточная библиотека
Ссылки
[ редактировать ]- ^ « Непрерывность систем и операций: аварийное восстановление» . Джорджтаунский университет - Информационные службы университета. Архивировано из оригинала 26 февраля 2012 года . Проверено 20 июля 2024 г.
- ^ «Аварийное восстановление и непрерывность бизнеса» . ИБМ . Архивировано из оригинала 11 января 2013 года . Проверено 20 июля 2024 г.
- ^ «Что такое управление непрерывностью бизнеса?» . Международный институт аварийного восстановления . Проверено 20 июля 2024 г.
- ^ «Защита слоев данных» . ForbesMiddleeast.com . 24 декабря 2013 г.
- ^ М. Ниимимаа; Стивен Бьюкенен (март 2017 г.). «Процесс обеспечения непрерывности информационных систем» . ACM .com (Цифровая библиотека ACM) .
- ^ «Справочник по непрерывности ИТ-услуг на 2017 год» (PDF) . Журнал аварийного восстановления . Архивировано из оригинала (PDF) 30 ноября 2018 г. Проверено 30 ноября 2018 г.
- ^ «ISO 22301 будет опубликован в середине мая, BS 25999-2 будет отозван» . Форум по обеспечению непрерывности бизнеса . 03.05.2012 . Проверено 20 ноября 2021 г.
- ^ «Глоссарий и сокращения ITIL» .
- ^ Jump up to: а б с «Как и драфт НФЛ, часы — враг вашего времени на восстановление» . Форбс . 30 апреля 2015 г.
- ^ «Три причины, по которым вы не можете уложиться в сроки аварийного восстановления» . Форбс . 10 октября 2013 г.
- ^ Jump up to: а б с д «Понимание RPO и RTO» . ДРУВА. 2008 год . Проверено 13 февраля 2013 г.
- ^ Jump up to: а б «Как включить RPO и RTO в ваши планы резервного копирования и восстановления» . ПоискХранилища . Проверено 20 мая 2019 г.
- ^ Ричард Мэй. «Нахождение RPO и RTO» . Архивировано из оригинала 3 марта 2016 г.
- ^ «Передача данных и синхронизация между мобильными системами» . 14 мая 2013 г.
- ^ «Поправка №5 к S-1» . SEC.gov .
в режиме реального времени... обеспечивают резервирование и резервное копирование...
- ^ Питер Х. Грегори (3 марта 2011 г.). «Установка максимально допустимого времени простоя — определение целей восстановления» . Планирование аварийного восстановления ИТ для чайников . Уайли. стр. 19–22. ISBN 978-1118050637 .
- ^ Уильям Кэлли; Денис Лонгли (1989). Информационная безопасность для менеджеров . Спрингер. п. 177. ИСБН 1349101370 .
- ^ «Катастрофа? Этого не может произойти здесь» . Нью-Йорк Таймс . 29 января 1995 г.
... записи пациентов
- ^ «Коммерческая недвижимость/Аварийное восстановление» . Нью-Йорк Таймс . 9 октября 1994 года.
...индустрия аварийного восстановления выросла до
- ^ Чарли Тейлор (30 июня 2015 г.). «Американская технологическая фирма Sungard объявляет о создании 50 рабочих мест в Дублине» . Ирландские Таймс .
Сунгард .. основана в 1978 году.
- ^ Кассандра Маскареньяс (12 ноября 2010 г.). «SunGard будет играть важную роль в банковской сфере» . Wijeya Newspapers Ltd.
SunGard ... Будущее Шри-Ланки.
- ^ Категория 9 SecaaS // Руководство по внедрению BCDR CSA, получено 14 июля 2014 г.
- ^ «Идентификация угроз и опасностей, оценка рисков (THIRA) и проверка готовности заинтересованных сторон (SPR): Руководство «Комплексное руководство по обеспечению готовности (CPG) 201, 3-е издание» (PDF) . Министерство внутренней безопасности США. Май 2018.
- ^ «Форум по планированию восстановления после стихийного бедствия: практическое руководство, подготовленное Партнерством по обеспечению устойчивости к стихийным бедствиям» . Центр общественных работ Университета Орегона, (C) 2007, www.OregonShowcase.org . Проверено 29 октября 2018 г. [ постоянная мертвая ссылка ]
- ^ «Важность аварийного восстановления» . Проверено 29 октября 2018 г.
- ^ «План аварийного восстановления ИТ» . ФЕМА. 25 октября 2012 года . Проверено 11 мая 2013 г.
- ^ «Использование структуры профессиональной практики для разработки, внедрения и поддержания программы обеспечения непрерывности бизнеса может снизить вероятность возникновения значительных пробелов» . ДРИ Интернешнл . 16 августа 2021 г. Проверено 02 сентября 2021 г.
- ^ Грегори, Питер. Универсальное руководство к экзамену для сертифицированного аудитора информационных систем CISA, 2009 г. ISBN 978-0-07-148755-9 . Страница 480.
- ^ Брэндон, Джон (23 июня 2011 г.). «Как использовать облако в качестве стратегии аварийного восстановления» . Инк . Проверено 11 мая 2013 г.
- ^ «Аварийное восстановление как услуга (DRaaS)» .
Дальнейшее чтение
[ редактировать ]- Барнс, Джеймс (2001). Руководство по планированию непрерывности бизнеса . Чичестер, Нью-Йорк: Джон Уайли. ISBN 9780470845431 . OCLC 50321216 .
- Белл, Джуди Кей (2000). Планирование выживания при стихийных бедствиях: практическое руководство для бизнеса . Порт-Хьюнем, Калифорния, США: Планирование выживания при стихийных бедствиях. ISBN 9780963058027 . OCLC 45755917 .
- Фулмер, Кеннет (2015). Планирование непрерывности бизнеса: пошаговое руководство с формами планирования . Rothstein Associates, Inc. Брукфилд, Коннектикут: ISBN 9781931332804 . OCLC 712628907 , 905750518 , 1127407034 .
- ДиМаттиа, Сьюзен С. (2001). «Планирование непрерывности». Библиотечный журнал . 126 (19): 32–34. ISSN 0363-0277 . OCLC 425551440 .
- Харни, Джон (июль – август 2004 г.). «Непрерывность бизнеса и аварийное восстановление: резервное копирование или выключение» . Журнал AIIM E-DOC . ISSN 1544-3647 . OCLC 1058059544 . Архивировано из оригинала 4 февраля 2008 г.
- «ISO 22301:2019(ru), Безопасность и отказоустойчивость. Системы управления непрерывностью бизнеса. Требования» . ИСО.
- «ISO/IEC 27001:2013(en) Информационные технологии. Методы обеспечения безопасности. Системы управления информационной безопасностью. Требования» . ИСО.
- «ISO/IEC 27002:2013(en) Информационные технологии. Методы обеспечения безопасности. Свод правил по управлению информационной безопасностью» . ИСО.
Внешние ссылки
[ редактировать ]- «Глоссарий терминов для обеспечения непрерывности бизнеса, аварийного восстановления и связанных с ними решений по зеркалированию данных и технологиям хранения данных z/OS» . www.recoveryspecialties.com . Архивировано из оригинала 14 ноября 2020 г. Проверено 02 сентября 2021 г.
- «План аварийного восстановления ИТ» . Ready.gov . Проверено 02 сентября 2021 г.
- «Объяснение RPO (Цель точки восстановления)» . ИБМ . 08.08.2019 . Проверено 02 сентября 2021 г.