Медоид
Медоиды — это репрезентативные объекты набора данных или кластера внутри набора данных, сумма различий которых со всеми объектами в кластере минимальна. [1] Медоиды по своей концепции аналогичны средним или центроидам , но медоиды всегда могут быть членами набора данных. Медоиды чаще всего используются для данных, когда среднее значение или центроид невозможно определить, например, для графиков. Они также используются в контекстах, где центроид не является репрезентативным для набора данных, например, в изображениях, трехмерных траекториях и экспрессии генов. [2] (где, хотя данных мало, медоид может не присутствовать). Они также представляют интерес при поиске представителя с использованием некоторого расстояния, отличного от квадрата евклидова расстояния (например, в рейтингах фильмов).
Для некоторых наборов данных может быть более одного медоида, как в случае с медианами.Распространенным применением медоида является алгоритм кластеризации k-medoids , который аналогичен алгоритму k-means , но работает, когда среднее значение или центроид невозможно определить. Этот алгоритм в основном работает следующим образом. Сначала случайным образом выбирается набор медоидов. Во-вторых, вычисляются расстояния до других точек. В-третьих, данные кластеризуются в соответствии с медоидом, на который они наиболее похожи. В-четвертых, набор медоидов оптимизируется посредством итерационного процесса.
Обратите внимание, что медоид не эквивалентен медиане , геометрической медиане или центроиду . Медиана нормой определяется только для одномерных данных и минимизирует только отличие от других точек для метрик, вызванных ( например, Манхэттенское расстояние или Евклидово расстояние ). Геометрическая медиана определяется в любом измерении, но в отличие от медоида она не обязательно является точкой исходного набора данных.
Определение
[ редактировать ]Позволять быть набором точки в пространстве с функцией расстояния d. Медоид определяется как



Кластеризация с помощью медоидов
[ редактировать ]Медоиды являются популярной заменой кластерного среднего, когда функция расстояния не является (возведенной в квадрат) евклидовым расстоянием или даже не является метрикой ( поскольку медоид не требует неравенства треугольника). При разбиении набора данных на кластеры медоид каждого кластера можно использовать в качестве представителя каждого кластера.
Алгоритмы кластеризации, основанные на идее медоидов, включают:
- Разделение вокруг медоидов (PAM), стандартный k-medoids. алгоритм
- Иерархическая кластеризация вокруг медоидов (HACAM), которая использует медоиды в иерархической кластеризации.
Алгоритмы вычисления медоида множества
[ редактировать ]Из определения, приведенного выше, ясно, что медоид множества может быть вычислено после вычисления всех попарных расстояний между точками ансамбля. Это потребует дистанционные оценки (с ). В худшем случае невозможно вычислить медоид с меньшим количеством оценок расстояния. [3] [4] Однако существует множество подходов, которые позволяют нам точно или приблизительно рассчитывать медоиды за субквадратичное время в рамках различных статистических моделей.



Если точки лежат на реальной линии, вычисление медоида сводится к вычислению медианы, что можно сделать в по алгоритму быстрого выбора Хоара. [5] Однако в реальных пространствах более высокой размерности алгоритм линейного времени неизвестен. РЭНД [6] — это алгоритм, который оценивает среднее расстояние каждой точки до всех остальных точек путем выборки случайного подмножества других точек. Всего требуется вычисления расстояний для аппроксимации медоида с точностью до коэффициента с высокой вероятностью, где это максимальное расстояние между двумя точкамив ансамбле. Обратите внимание, что RAND — это аппроксимационный алгоритм, причем может быть не известно априори.




RAND использовала ТОПРАНК [7] который использует оценки, полученные с помощью RAND оценивает среднее расстояние этих точек , чтобы сосредоточиться на небольшом подмножестве точек-кандидатов, точно и выбирает минимальное из них. ТОПРАНК нуждается расчеты расстояний найти точный медоид с высокой вероятностью согласно предположению о распределении на средних дистанциях.

обрезанный [3] представляет алгоритм найти медоид с помощью дистанционные оценки в рамках распределительного предположение по пунктам. Алгоритм использует неравенство треугольника для сокращения пространства поиска.

Меддит [4] рычаги воздействия связь вычислений медоида с многорукими бандитами и использует алгоритм с верхней границей достоверности, чтобы получить алгоритм, который принимает дистанционные оценки в рамках статистическихпредположения по пунктам.

Коррелированное последовательное сокращение вдвое [8] также использует методы многорукого бандита, улучшая Meddit . Используя корреляционную структуру задачи, алгоритм способен значительно улучшить (обычно примерно на 1-2 порядка) как количество необходимых вычислений расстояния, так и время настенных часов.
Реализации
[ редактировать ]Реализацию RAND , TOPRANK и Trimed можно найти здесь . Реализация Меддит можно найти здесь и здесь . Реализация коррелированного последовательного халвинга можно найти здесь .
Медоиды в обработке текста и естественного языка (НЛП)
[ редактировать ]Медоиды можно применять к различным текстовым задачам и задачам НЛП для повышения эффективности и точности анализа. [9] Кластеризуя текстовые данные на основе сходства, медоиды могут помочь идентифицировать репрезентативные примеры в наборе данных, что приводит к лучшему пониманию и интерпретации данных.
Кластеризация текста
[ редактировать ]Кластеризация текста — это процесс группировки схожего текста или документов на основе их содержания. Алгоритмы кластеризации на основе Medoid можно использовать для разделения больших объемов текста на кластеры, где каждый кластер представлен документом medoid. Этот метод помогает организовывать, обобщать и извлекать информацию из больших коллекций документов, например, в поисковых системах, аналитике социальных сетей и системах рекомендаций. [10]
Обобщение текста
[ редактировать ]Целью резюмирования текста является создание краткого и связного изложения более крупного текста путем извлечения наиболее важной и актуальной информации. Кластеризация на основе Medoid может использоваться для определения наиболее репрезентативных предложений в документе или группе документов, которые затем можно объединить для создания резюме. Этот подход особенно полезен для задач экстрактивного реферирования, целью которых является создание резюме путем выбора наиболее релевантных предложений из исходного текста. [11]
Анализ настроений
[ редактировать ]Анализ настроений включает в себя определение настроения или эмоции, выраженной в фрагменте текста, например положительного, отрицательного или нейтрального. Кластеризация на основе Medoid может применяться к групповым текстовым данным на основе схожих шаблонов настроений. Анализируя медоид каждого кластера, исследователи могут получить представление о преобладающих настроениях в кластере, помогая в таких задачах, как сбор мнений, анализ отзывов клиентов и мониторинг социальных сетей. [12]
Тематическое моделирование
[ редактировать ]Тематическое моделирование — это метод, используемый для обнаружения абстрактных тем, встречающихся в коллекции документов. Кластеризация на основе Medoid может применяться к групповым документам со схожими темами или темами. Анализируя медоиды этих кластеров, исследователи могут получить представление об основных темах в текстовом корпусе, облегчая такие задачи, как категоризация документов, анализ тенденций и рекомендации по содержанию. [13]
Методы измерения сходства текста при кластеризации на основе медоидов
[ редактировать ]При применении кластеризации на основе медоидов к текстовым данным важно выбрать соответствующую меру сходства для эффективного сравнения документов. Каждый метод имеет свои преимущества и ограничения, и выбор меры сходства должен основываться на конкретных требованиях и характеристиках анализируемых текстовых данных. [14] Ниже приведены распространенные методы измерения сходства текста при кластеризации на основе медоидов:

Косинусное подобие
[ редактировать ]Косинусное сходство — широко используемый показатель для сравнения сходства между двумя частями текста. Он вычисляет косинус угла между двумя векторами документа в многомерном пространстве. [14] Косинусное сходство находится в диапазоне от -1 до 1, где значение ближе к 1 указывает на большее сходство, а значение ближе к -1 указывает на меньшее сходство. Визуализируя две линии, исходящие из начала координат и идущие к соответствующим точкам интереса, а затем измеряя угол между этими линиями, можно определить сходство между связанными точками. На косинусное сходство меньше влияет длина документа, поэтому лучше создавать медоиды, которые представляют содержимое кластера, а не длину.
Сходство Жаккара
[ редактировать ]
Сходство Жаккара, также известное как коэффициент Жаккара, измеряет сходство между двумя множествами путем сравнения отношения их пересечения к их объединению. В контексте текстовых данных каждый документ представлен как набор слов, а сходство Жаккара вычисляется на основе общих слов между двумя наборами. Сходство Жаккара находится в диапазоне от 0 до 1, где более высокое значение указывает на более высокую степень сходства между документами. [ нужна ссылка ]
Евклидово расстояние
[ редактировать ]
Евклидово расстояние — это стандартная метрика расстояния, используемая для измерения несходства между двумя точками в многомерном пространстве. В контексте текстовых данных документы часто представляются в виде многомерных векторов, таких как векторы TF, и евклидово расстояние может использоваться для измерения несходства между ними. Меньшее евклидово расстояние указывает на более высокую степень сходства между документами. [14] Использование евклидова расстояния может привести к тому, что медоиды будут более точно отражать длину документа.
Изменить расстояние
[ редактировать ]Расстояние редактирования, также известное как расстояние Левенштейна, измеряет сходство между двумя строками путем расчета минимального количества операций (вставок, удалений или замен), необходимых для преобразования одной строки в другую. В контексте текстовых данных расстояние редактирования можно использовать для сравнения сходства между короткими текстовыми документами или отдельными словами. Меньшее расстояние редактирования указывает на более высокую степень сходства между строками. [15]
Приложения Medoid в больших языковых моделях
[ редактировать ]Медоиды для анализа вложений больших языковых моделей.
[ редактировать ]
Медоиды можно использовать для анализа и понимания представлений векторного пространства, созданных большими языковыми моделями (LLM), такими как BERT, GPT или RoBERTa. Применяя кластеризацию на основе медоидов к вложениям, созданным этими моделями для слов, фраз или предложений, исследователи могут исследовать семантические отношения, фиксируемые LLM. Этот подход может помочь идентифицировать кластеры семантически схожих объектов, обеспечивая понимание структуры и организации многомерных пространств внедрения, созданных этими моделями. [16]
Медоиды для отбора данных и активного обучения
[ редактировать ]Активное обучение включает в себя выбор точек данных из обучающего пула, которые позволят максимизировать производительность модели. Медоиды могут сыграть решающую роль в выборе данных и активном обучении с помощью LLM. Кластеризация на основе Medoid может использоваться для идентификации репрезентативных и разнообразных выборок из большого набора текстовых данных, которые затем можно использовать для более эффективной настройки LLM или для создания лучших обучающих наборов. Выбирая медоиды в качестве обучающих примеров, исследователи могут получить более сбалансированный и информативный обучающий набор, что потенциально улучшит обобщение и надежность точно настроенных моделей. [17]
Медоиды для интерпретируемости модели и безопасности
[ редактировать ]Применение медоидов в контексте LLM может способствовать улучшению интерпретируемости модели. Кластеризуя вложения, генерируемые LLM, и выбирая медоидов в качестве представителей каждого кластера, исследователи могут предоставить более интерпретируемую сводку поведения модели. [18] Этот подход может помочь понять процесс принятия решений в модели, выявить потенциальные отклонения и раскрыть основную структуру вложений, генерируемых LLM. Поскольку дискуссия вокруг интерпретируемости и безопасности LLM продолжает набирать обороты, использование медоидов может служить ценным инструментом для достижения этой цели.
Реальные приложения
[ редактировать ]Как универсальный метод кластеризации, медоиды можно применять для решения множества реальных проблем во многих областях, от биологии и медицины до рекламы и маркетинга, а также социальных сетей. Его способность обрабатывать сложные наборы данных с высокой степенью сложности делает его мощным устройством в современном анализе данных.
Анализ экспрессии генов
[ редактировать ]При анализе экспрессии генов [19] Исследователи используют передовые технологии, включающие микрочипы и секвенирование РНК, для измерения уровней экспрессии многочисленных генов в биологических образцах, что приводит к получению многомерных данных, которые могут быть сложными и трудными для анализа. Медоиды являются потенциальным решением, позволяющим группировать гены в первую очередь на основе их профилей экспрессии, что позволяет исследователям обнаруживать совместно экспрессируемые группы генов, которые могут дать ценную информацию о молекулярных механизмах биологических процессов и заболеваний.
Анализ социальных сетей
[ редактировать ]Для оценки социальной сети, [20] medoids может быть исключительным инструментом для распознавания центральных или влиятельных узлов в социальной сети. Исследователи могут группировать узлы на основе их стилей подключения и определять узлы, которые с наибольшей вероятностью окажут существенное влияние на функционирование и структуру сети. Один из популярных подходов к использованию медоидов в анализе социальных сетей — вычисление показателя расстояния или сходства между парами узлов на основе их свойств.
Сегментация рынка
[ редактировать ]Медоиды также можно использовать для сегментации рынка. [21] Это аналитическая процедура, включающая группировку клиентов в первую очередь на основе их покупательского поведения, демографических характеристик и различных других признаков. Кластеризация клиентов по сегментам с использованием медоидов позволяет компаниям адаптировать свои методы рекламы и маркетинга таким образом, чтобы они соответствовали потребностям каждой группы клиентов. Медоиды служат репрезентативными факторами внутри каждого кластера, инкапсулируя основные характеристики клиентов в этой группе.
Сумма квадратов ошибок внутри групп (WGSS) — это формула, используемая при сегментации рынка и направленная на количественную оценку концентрации квадратов ошибок внутри кластеров. Он стремится уловить распределение ошибок внутри групп, возводя их в квадрат и агрегируя результаты. Метрика WGSS количественно определяет связность выборок внутри кластеров, указывая на более плотные кластеры с более низкими значениями WGSS и, соответственно, более высокий эффект кластеризации. Формула WGSS:
![{\displaystyle {\text{WGSS}}={\frac {1}{2}}\left[(m_{1}-1){\overline {d_{1}^{2}}}+\cdots + (m_{k}-1){\overline {d_{k}^{2}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ad19657ee425e259ef4da7dd36527452c25a440)
Где — среднее расстояние образцов внутри k -го кластера и — количество выборок в k -м кластере.


Обнаружение аномалий
[ редактировать ]Медоиды также могут сыграть важную роль в выявлении аномалий, и одним из эффективных методов является обнаружение аномалий на основе кластеров. Их можно использовать для обнаружения кластеров точек данных, которые значительно отличаются от остальных данных. Кластеризируя данные в группы с использованием медоидов и сравнивая свойства каждого кластера с данными, исследователи могут четко обнаружить аномальные кластеры. [ нужна ссылка ]
Визуализация процесса кластеризации на основе медоидов
[ редактировать ]Цель
[ редактировать ]Визуализация кластеризации на основе медоидов может быть полезна при попытке понять, как работает кластеризация на основе медоидов. Исследования показали, что люди лучше учатся, используя визуальную информацию. [22] В кластеризации на основе медоидов медоид является центром кластера. Это отличается от кластеризации k-средних , где центр не является реальной точкой данных, а может находиться между точками данных. Мы используем медоид для группировки «кластеров» данных, который получается путем нахождения элемента с минимальным средним отличием от всех остальных объектов в кластере. [23] Хотя в используемом примере визуализации используется кластеризация k-medoids, визуализацию можно применить и к кластеризации k-mean, заменяя среднее различие средним значением используемого набора данных.
Визуализация с использованием одномерных данных
[ редактировать ]Матрица расстояний
[ редактировать ]
Для кластеризации на основе медоидов требуется матрица расстояний, которая генерируется с использованием различия Жаккара (которое равно 1 — индекс Жаккара ). Эта матрица расстояний используется для расчета расстояния между двумя точками на одномерном графике. [ нужна ссылка ] На изображении выше показан пример графика различия Жаккара.
Кластеризация
[ редактировать ]- Шаг 1
Кластеризация на основе Medoid используется для поиска кластеров в наборе данных. Исходный одномерный набор данных, содержащий кластеры, которые необходимо обнаружить, используется для процесса кластеризации на основе медоидов. На изображении ниже в наборе данных имеется двенадцать различных объектов в разных положениях по оси X.

- Шаг 2
В качестве начальных центров выбираются K случайных точек. Значение, выбранное для K, известно как значение K. На изображении ниже в качестве значения K выбрано 3. Процесс поиска оптимального значения K будет обсуждаться на шаге 7.

- Шаг 3
Каждому нецентральному объекту присваивается ближайший к нему центр. Это делается с помощью матрицы расстояний. Чем меньше различие, тем ближе точки. На изображении ниже 5 объектов в кластере 1, 3 в кластере 2 и 4 в кластере 3.

- Шаг 4
Новый центр для каждого кластера находится путем нахождения объекта, среднее отличие которого от всех других объектов в кластере минимально. Центр, выбранный на этом этапе, называется медоидом. На изображении ниже показаны результаты выбора медоида.
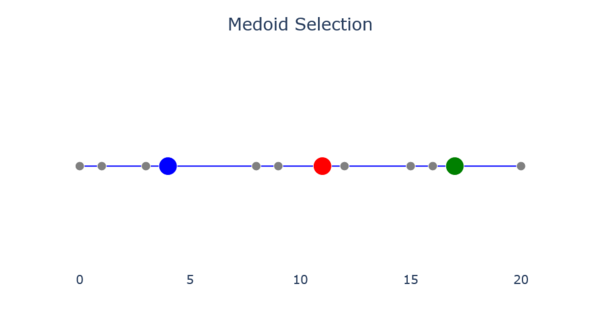
- Шаг 5
Шаги 3–4 повторяются до тех пор, пока центры не перестанут двигаться, как на изображениях ниже.
- Повторение шагов 3–4 (слева направо)
 Второй кластер.
Второй кластер. Медоидный выбор.
Медоидный выбор.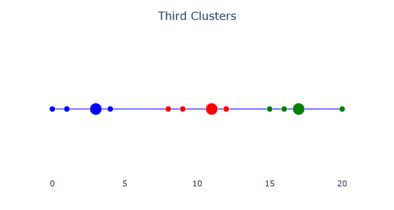 Третий кластер.
Третий кластер.- Окончательный выбор медоида.



- Шаг 6
Окончательные кластеры получаются, когда центры больше не перемещаются между шагами. На изображении ниже показано, как может выглядеть окончательный кластер.

- Шаг 7
Вариация суммируется внутри каждого кластера, чтобы увидеть, насколько точны центры. Запустив этот тест с различными значениями K, можно получить « колено » графика вариаций, где вариации графика выравниваются. «Колоко» графика — это оптимальное значение K для набора данных.
Медоиды в больших измерениях
[ редактировать ]Распространенной проблемой кластеризации k-медоидов и других алгоритмов кластеризации на основе медоидов является « проклятие размерности », при котором точки данных содержат слишком много измерений или признаков. По мере добавления к данным размеров расстояние между ними становится редким. [24] и становится трудно характеризовать кластеризацию только с помощью евклидова расстояния. В результате меры сходства, основанные на расстоянии, сходятся к постоянной величине. [25] и у нас есть характеристика расстояния между точками, которая может не отражать наш набор данных значимым образом.
Одним из способов смягчить последствия проклятия размерности является использование спектральной кластеризации . Спектральная кластеризация обеспечивает более подходящий анализ за счет уменьшения размерности данных с использованием анализа главных компонентов , проецирования точек данных в подпространство меньшей размерности и последующего запуска выбранного алгоритма кластеризации, как и раньше. Однако следует отметить, что, как и при любом уменьшении размерности, мы теряем информацию. [26] поэтому необходимо заранее сопоставить с кластеризацией, насколько необходимо сокращение, прежде чем будет потеряно слишком много данных.
Однако высокая размерность влияет не только на метрики расстояния, поскольку временная сложность также увеличивается с увеличением количества функций. k-medoids чувствителен к первоначальному выбору медоидов, поскольку они обычно выбираются случайным образом. В зависимости от того, как инициализируются такие медоиды, k-медоиды могут сходиться к разным локальным оптимумам, что приводит к различным кластерам и показателям качества. [27] это означает, что k-medoids, возможно, придется запускать несколько раз с разными инициализациями, что приводит к гораздо большему времени выполнения. Один из способов уравновесить это — использовать k-medoids++, [28] альтернатива k-medoids, аналогичная ее аналогу k-means, k-means++, которая выбирает исходные медоиды для начала на основе распределения вероятностей, как своего рода «информированная случайность» или обоснованное предположение, если хотите. Если такие медоиды выбираются по этой причине, результатом будет улучшение времени выполнения и повышение производительности кластеризации. Алгоритм k-medoids++ описывается следующим образом: [29]
- Начальный медоид выбирается случайным образом среди всех пространственных точек.
- Для каждой пространственной точки 𝑝 вычислите расстояние между 𝑝 и ближайшими медоидами, которое называется D(𝑝), и просуммируйте все расстояния до 𝑆.
- Следующий медоид определяется с использованием взвешенного распределения вероятностей. В частности, выбирается случайное число 𝑅 между нулем и суммированным расстоянием 𝑆, и соответствующая пространственная точка является следующим медоидом.
- Шаг (2) и Шаг (3) повторяются до тех пор, пока не будут выбраны 𝑘 медоиды.
Теперь, когда у нас есть соответствующие первые выборки для медоидов, можно запустить нормальную вариацию k-медоидов.
Ссылки
[ редактировать ]- ^ Стройф, Аня; Хьюберт, Миа ; Руссеу, Питер (1997). «Кластеризация в объектно-ориентированной среде» . Журнал статистического программного обеспечения . 1 (4): 1–30.
- ^ ван дер Лаан, Марк Дж .; Поллард, Кэтрин С.; Брайан, Дженнифер (2003). «Новый алгоритм разбиения вокруг медоидов» . Журнал статистических вычислений и моделирования . 73 (8). Группа Тейлора и Фрэнсиса: 575–584. дои : 10.1080/0094965031000136012 . S2CID 17437463 .
- ^ Перейти обратно: а б Ньюлинг, Джеймс; и Флере, Франсуа (2016); «Субквадратичный точный медоидный алгоритм», в материалах 20-й Международной конференции по искусственному интеллекту и статистике , PMLR 54: 185-193, 2017 г. Доступно в Интернете .
- ^ Перейти обратно: а б Багария, Вивек; Камат, Говинда М.; Нтранос, Василис; Чжан, Мартин Дж.; Це, Дэвид (2017). «Медоиды в почти линейном времени через многоруких бандитов». arXiv : 1711.00817 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Хоар, Чарльз Энтони Ричард (1961); «Алгоритм 65: найти», в Сообщениях ACM , 4 (7), 321-322.
- ^ Эппштейн, Дэвид ; И Ван, Джозеф (2006); «Быстрое приближение центральности», в «Алгоритмы графов и приложения» , 5 , стр. 39-45.
- ^ Окамото, Казуя; Чен, Вэй; Ли, Сян-Ян (2008). «Рейтинг централизации близости для крупномасштабных социальных сетей». Границы в алгоритмике . Конспекты лекций по информатике. Том. 5059. стр. 186–195. дои : 10.1007/978-3-540-69311-6_21 . ISBN 978-3-540-69310-9 .
- ^ Бахарав, Тавор З.; И Це, Дэвид Н. (2019); «Сверхбыстрая идентификация медоидов посредством коррелированного последовательного деления пополам», в книге «Достижения в области нейронных систем обработки информации », доступно в Интернете.
- ^ Дай, Цюнцзе; Лю, Цзичэн (июль 2019 г.). «Исследование и применение K-медоидов в кластеризации текста» (PDF) . Проверено 25 апреля 2023 г.
- ^ «Что такое обработка естественного языка?» .
- ^ Ху, По; Он, Тингтинг; Джи, Донхун. «Обобщение китайского текста на основе определения тематических областей» (PDF) .
- ^ Пессутто, Лукас; Варгас, Дэнни; Морейра, Вивиан (24 февраля 2020 г.). «Многоязычная кластеризация аспектов для анализа настроений» . Системы, основанные на знаниях . 192 : 105339. дои : 10.1016/j.knosys.2019.105339 . S2CID 211830280 .
- ^ Преюдом, Грегуар; Дуарте, Кевин (18 февраля 2021 г.). «Личное сравнение методов кластеризации гетерогенных данных: тест, основанный на моделировании» . Научные отчеты . 11 (1): 4202. Бибкод : 2021NatSR..11.4202P . дои : 10.1038/s41598-021-83340-8 . ПМЦ 7892576 . ПМИД 33603019 .
- ^ Перейти обратно: а б с Амер, Али; Абдалла, Хасан (14 сентября 2020 г.). «Мера сходства, основанная на теории множеств, для кластеризации и классификации текста» . Журнал больших данных . 7 . дои : 10.1186/s40537-020-00344-3 . S2CID 256403960 .
- ^ Ву, Банда (17 декабря 2022 г.). «Метрики сходства строк – изменение расстояния» .
- ^ Мохтарани, Шабнам (26 августа 2021 г.). «Внедрение в машинное обучение: все, что вам нужно знать» .
- ^ Ву, Юэсинь; Сюй, Ичун; Сингх, Аарти; Ян, Имин; Дубравский, Артур (2019). «Активное обучение графовых нейронных сетей посредством распространения признаков узла». arXiv : 1910.07567 [ cs.LG ].
- ^ Тивари, Миссури; Мэйклин, Джеймс; Пих, Крис; Чжан, Мартин; Трун, Себастьян; Шомороный, Илан (2020). «BanditPAM: кластеризация k-медоидов почти в линейном времени с помощью многоруких бандитов». arXiv : 2006.06856 [ cs.LG ].
- ^ Чжан, Ян; Ши, Вэйю; Сунь, Ецин (17 февраля 2023 г.). «Алгоритм идентификации функционального генного модуля в данных об экспрессии генов, основанный на генетическом алгоритме и онтологии генов» . БМК Геномика . 24 (1): 76. дои : 10.1186/s12864-023-09157-z . ISSN 1471-2164 . ПМЦ 9936134 . ПМИД 36797662 .
- ^ Саха, Санджит Кумар; Шмитт, Инго (01 января 2020 г.). «Не-TI-кластеризация в контексте социальных сетей» . Procedia Информатика . 11-я Международная конференция по окружающим системам, сетям и технологиям (ANT) / 3-я Международная конференция по новым данным и индустрии 4.0 (EDI40) / Дочерние семинары. 170 : 1186–1191. дои : 10.1016/j.procs.2020.03.031 . ISSN 1877-0509 . S2CID 218812939 .
- ^ У, Цзэнъюань; Джин, Линмин; Чжао, Цзяли; Цзин, Личжэн; Чен, Лян (18 июня 2022 г.). «Исследование сегментации клиентов электронной коммерции с помощью улучшенного алгоритма кластеризации K-Medoids» . Вычислительный интеллект и нейронаука . 2022 : 1–10. дои : 10.1155/2022/9930613 . ПМЦ 9233613 . ПМИД 35761867 .
- ^ Мидуэй, Стивен Р. (декабрь 2020 г.). «Принципы эффективной визуализации данных» . Узоры . 1 (9): 100141. doi : 10.1016/j.patter.2020.100141 . ПМЦ 7733875 . ПМИД 33336199 .
- ^ https://www.researchgate.net/publication/243777819_Clustering_by_Means_of_Medoids
- ^ «Проклятие размерности» . 17 мая 2019 г.
- ^ «Преимущества и недостатки K-средств | Машинное обучение» .
- ^ «K означает кластеризацию многомерных данных» . 10 апреля 2022 г.
- ^ «Каковы основные недостатки использования k-средних для многомерных данных?» . [ самостоятельно опубликованный источник? ]
- ^ Юэ, Ся (2015). «Параллельный алгоритм пространственной кластеризации K-Medoids ++ на основе MapReduce». arXiv : 1608.06861 [ cs.DC ].
- ^ Юэ, Ся (2015). «Параллельный алгоритм пространственной кластеризации K-Medoids ++ на основе MapReduce». arXiv : 1608.06861 [ cs.DC ].
Внешние ссылки
[ редактировать ]- Видео StatQuest k-means, используемое для наглядности в #Visualization_of_the_medoid-based_clustering_process разделе