Унификация (информатика)
В логике и информатике , в частности в автоматизированном рассуждении , унификация — это алгоритмический процесс решения уравнений между символическими выражениями , каждое из которых имеет вид Левая часть = Правая часть . Например, используя x , y , z в качестве переменных и принимая f в качестве неинтерпретируемой функции , набор одноэлементных уравнений { f (1, y ) = f ( x ,2) } представляет собой синтаксическую задачу унификации первого порядка, которая имеет замена { x ↦ 1, y ↦ 2 } как единственное решение.
Соглашения различаются в отношении того, какие значения могут принимать переменные и какие выражения считаются эквивалентными. При синтаксической унификации первого порядка переменные варьируются в пределах терминов первого порядка , и эквивалентность является синтаксической. Эта версия унификации имеет уникальный «лучший» ответ и используется в логическом программировании и реализации системы типов языка программирования , особенно в Хиндли-Милнера на основе алгоритмах вывода типа . При унификации более высокого порядка, которая, возможно, ограничена унификацией шаблонов более высокого порядка , термины могут включать лямбда-выражения, а эквивалентность сводится к бета-редукции. доказательству и логическом программировании высшего порядка, например Isabelle , Twelf иlambdaProlog Эта версия используется в помощниках по . Наконец, при семантической унификации или электронной унификации равенство зависит от базовых знаний, а переменные варьируются в различных областях. Эта версия используется в решателях SMT , алгоритмах перезаписи терминов и криптографических протоколов анализе .
Формальное определение
[ редактировать ]Проблема объединения — это конечное множество E = { l 1 ≐ r 1 , ..., l n ≐ r n } уравнений, которые необходимо решить, где l i , r i находятся в множестве терминов или выражений . В зависимости от того, какие выражения или термины могут встречаться в наборе уравнений или задаче унификации и какие выражения считаются равными, различают несколько рамок унификации. Если в выражении разрешены переменные более высокого порядка, то есть переменные, представляющие функции , процесс называется унификацией высшего порядка , в противном случае — унификацией первого порядка . Если требуется решение, чтобы сделать обе стороны каждого уравнения буквально равными, этот процесс называется синтаксической или свободной унификацией , иначе — семантической или эквациональной унификацией , или E-унификацией , или теорией унификации по модулю .

Если правая часть каждого уравнения замкнута (нет свободных переменных), проблема называется сопоставлением (образца) . Левая часть (с переменными) каждого уравнения называется шаблоном . [1]
Предварительные условия
[ редактировать ]Формально унификационный подход предполагает
- Бесконечный набор переменных . Для объединения более высокого порядка удобно выбрать не пересекается с набором связанных переменных лямбда-члена .
- Набор терминов что таких, . Для объединения первого порядка обычно представляет собой набор термов первого порядка (терминов, построенных из символов переменных и функций). Для объединения высшего порядка состоит из термов первого порядка и лямбда-терминов (терминов, содержащих некоторые переменные более высокого порядка).
- Отображение , присваивая каждому члену набор свободных переменных, встречающихся в .
- Теория или отношение эквивалентности на , указывая, какие члены считаются равными. Для электронного объединения первого порядка отражает базовые знания об определенных функциональных символах; например, если считается коммутативным, если результат путем замены аргументов в некоторых (возможно, во всех) случаях. [примечание 1] В наиболее типичном случае, когда фоновые знания отсутствуют вообще, тогда равными считаются только буквально или синтаксически идентичные термины. В этом случае ≡ называется свободной теорией (поскольку это свободный объект ), пустой теорией (поскольку множество эквациональных предложений или фоновые знания пусты), теорией неинтерпретируемых функций (поскольку объединение выполняется на неинтерпретируемые термины ) или теорию конструкторов (поскольку все функциональные символы просто создают термины данных, а не работают с ними). Для объединения более высокого порядка обычно если и являются альфа-эквивалентными .











В качестве примера того, как набор терминов и теория влияют на набор решений, синтаксическая задача унификации первого порядка { y = cons (2, y ) } не имеет решения над множеством конечных терминов . Однако оно имеет единственное решение { y ↦ cons (2, cons (2, cons (2,...))) } над множеством членов бесконечного дерева . Аналогично, семантическая задача объединения первого порядка { a ⋅ x = x ⋅ a } имеет каждую замену вида { x ↦ a ⋅...⋅ a } как решение в полугруппе , т. е. если (⋅) считается ассоциативным . Но та же проблема, рассматриваемая в абелевой группе , где (⋅) также считается коммутативной , вообще имеет любую замену в качестве решения.
В качестве примера унификации высшего порядка можно привести одноэлементный набор { a = y ( x ) }, который представляет собой синтаксическую задачу унификации второго порядка, поскольку y является функциональной переменной. Одним из решений является { x ↦ a , y ↦ ( тождественная функция ) }; другой — { y ↦ ( постоянная функция, отображающая каждое значение в a ), x ↦ (любое значение) }.
Замена
[ редактировать ]Замена – это отображение от переменных к термам; обозначение относится к замене, отображающей каждую переменную к сроку , для и каждая другая переменная сама по себе; тот должны быть попарно различны. Применение этой замены к термину записывается в постфиксной записи как ; это означает (одновременную) замену каждого вхождения каждой переменной в срок к . Результат применения замены на срок называется экземпляром этого термина .В качестве примера первого порядка, применив замену { x ↦ h ( a , y ), z ↦ b } к термину








| урожайность | |||||








Обобщение, специализация
[ редактировать ]Если срок имеет экземпляр, эквивалентный термину , то есть, если для какой-то замены , затем называется более общим, чем , и называется более специальным , чем или отнесенным к нему, . Например, является более общим, чем если ⊕ коммутативен , так как тогда .





Если ≡ — буквальное (синтаксическое) тождество терминов, то термин может быть как более общим, так и более специальным, чем другой, только если оба термина различаются только именами переменных, а не синтаксической структурой; такие термины называются вариантами или переименованиями друг друга.Например, это вариант ,с и Однако, это не вариант , поскольку никакая замена не может превратить последний член в первый.Следовательно, последний термин более специальный, чем первый.





Для произвольного , термин может быть как более общим, так и более специальным, чем структурно другой термин.Например, если ⊕ идемпотент , то есть если всегда , то срок является более общим, чем , [примечание 2] и наоборот, [примечание 3] хотя и имеют различную структуру.



Замена более специфичен , чем замена или отнесен к ней если относится к за каждый семестр . Мы также говорим, что является более общим, чем . Более формально, возьмем непустое бесконечное множество вспомогательных переменных таких, что ни одно уравнение в задаче объединения содержит переменные из . Тогда замена включается другой заменой если есть замена такой, что для всех условий , . [2] Например относится к , с использованием , но не относится к , как не является примером . [3]











Набор решений
[ редактировать ]Замена σ является решением задачи объединения E, если l i σ ≡ r i σ для . называют унификатором E. замену еще Такую Например, если ⊕ ассоциативен , проблема объединения { x ⊕ a ≐ a ⊕ x } имеет решения { x ↦ a }, { x ↦ a ⊕ a }, { x ↦ a ⊕ a ⊕ a } и т. д., а задача { x ⊕ a ≐ a } не имеет решения.

Для данной задачи объединения E набор S унификаторов называется полным если каждая замена решения включается некоторой заменой в S. , Полный набор подстановок всегда существует (например, набор всех решений), но в некоторых рамках (например, неограниченная унификация высшего порядка) проблема определения того, существует ли какое-либо решение (т. е. непусто ли полный набор подстановок) неразрешима.
Множество S называется минимальным , если ни один из его членов не включает в себя другой. В зависимости от структуры полный и минимальный набор подстановок может иметь ноль, один, конечное или бесконечное число членов или может вообще не существовать из-за бесконечной цепочки избыточных членов. [4] Таким образом, в целом алгоритмы унификации вычисляют конечную аппроксимацию полного набора, который может быть минимальным, а может и не быть, хотя большинство алгоритмов по возможности избегают избыточных унификаторов. [2] Для синтаксической унификации первого порядка Мартелли и Монтанари [5] дал алгоритм, который сообщает о неразрешимости или вычисляет единственный унификатор, который сам по себе образует полный и минимальный набор подстановок, называемый наиболее общим унификатором .
Синтаксическая унификация терминов первого порядка
[ редактировать ]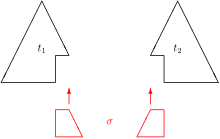
Синтаксическая унификация терминов первого порядка является наиболее широко используемой структурой унификации.Он основан на том, что T является набором термов первого порядка (по некоторому заданному набору V переменных, C констант и F n -арных n функциональных символов), а ≡ является синтаксическим равенством .В этой структуре каждая разрешимая проблема объединения { l 1 ≐ r 1 , ..., l n ≐ r n } имеет полный и, очевидно, минимальный одноэлементный набор решений { σ } .Его член σ называется наиболее общим унификатором ( mgu ) задачи.Члены в левой и правой частях каждого потенциального уравнения становятся синтаксически равными, когда применяется mgu, т. е. l 1 σ = r 1 σ ∧ ... ∧ l n σ = r n σ .Любой объединитель проблемы относится к категории [примечание 4] по mgu σ .Mgu уникален с точностью до вариантов: если S 1 и S 2 являются полным и минимальным множествами решений одной и той же задачи синтаксического объединения, то S 1 = { σ 1 } и S 2 = { σ 2 } для некоторых замен σ 1 и σ 2 , а xσ 1 является вариантом xσ 2 для каждой переменной x, встречающейся в задаче.
Например, проблема объединения { x ≐ z , y ≐ f ( x ) } имеет объединитель { x ↦ z , y ↦ f ( z ) }, потому что
х { Икс ↦ z , y ↦ ж ( z ) } = С = С { Икс ↦ z , y ↦ ж ( z ) } , и и { Икс ↦ z , y ↦ ж ( z ) } = ж ( я ) = е ( х ) { Икс ↦ z , y ↦ ж ( z ) } .
Это также самый общий унификатор.Другими унификаторами для той же проблемы являются, например, { x ↦ f ( x 1 ), y ↦ f ( f ( x 1 )), z ↦ f ( x 1 ) }, { x ↦ f ( f ( x 1 )), y ↦ f ( f ( f ( x 1 ))), z ↦ f ( f ( x 1 )) } и так далее; подобных объединителей бесконечно много.
В качестве другого примера, проблема g ( x , x ) ≐ f ( y ) не имеет решения в отношении того, что ≡ является буквальным тождеством, поскольку любая замена, примененная к левой и правой части, сохранит самые внешние g и f соответственно, и термины с разными внешними функциональными символами синтаксически различны.
Алгоритмы унификации
[ редактировать ]


Жак Эрбран обсудил основные концепции унификации и набросал алгоритм в 1930 году. [9] [10] [11] Но большинство авторов приписывают первый алгоритм объединения Джону Алану Робинсону (см. вставку). [12] [13] [примечание 5] Алгоритм Робинсона имел экспоненциальное поведение в худшем случае как во времени, так и в пространстве. [11] [15] Многие авторы предложили более эффективные алгоритмы унификации. [16] Алгоритмы с наихудшим поведением в линейном времени были независимо открыты Мартелли и Монтанари (1976) и Патерсоном и Вегманом (1976). [примечание 6] Баадер и Снайдер (2001) используют тот же метод, что и Патерсон-Вегман, поэтому он линейный, [17] но, как и большинство алгоритмов унификации с линейным временем, он медленнее, чем версия Робинсона, на входных данных небольшого размера из-за накладных расходов на предварительную обработку входных данных и постобработку выходных данных, например построение представления DAG . де Шампо (2022) также имеет линейную сложность по размеру входных данных, но конкурирует с алгоритмом Робинсона на входных данных небольшого размера. Ускорение достигается за счет использования объектно-ориентированного представления исчисления предикатов, которое позволяет избежать необходимости предварительной и последующей обработки, вместо этого возлагая на переменные объекты ответственность за создание замены и работу с псевдонимами. де Шампо утверждает, что возможность добавлять функциональность к исчислению предикатов, представленному в виде программных объектов, также предоставляет возможности для оптимизации других логических операций. [15]
Следующий алгоритм широко представлен и взят из работы Мартелли и Монтанари (1982) . [примечание 7] Учитывая конечное множество потенциальных уравнений,алгоритм применяет правила для преобразования его в эквивалентный набор уравнений вида{ Икс 1 ≐ ты 1 , ..., Икс м ≐ ты м }где x 1 , ..., x m - различные переменные, а u 1 , ..., um из - термины, не содержащие ни одного x i .Набор такой формы можно считать заменой.Если решения нет, алгоритм завершается нажатием ⊥; другие авторы в этом случае используют «Ом» или « провал ».Операцию замены всех вхождений переменной x в задаче G на терм t обозначается G { x ↦ t }.Для простоты константные символы рассматриваются как функциональные символы, имеющие нулевые аргументы.

удалить разлагать если или конфликт менять если и устранять [примечание 8] если проверять
















Происходит проверка
[ редактировать ]Попытка объединить переменную x с термином, содержащим x как строгий подтерм x ≐ f (..., x , ...) привела бы к бесконечному терму в качестве решения для x , поскольку x возник бы как подтермин самого себя. .В множестве (конечных) членов первого порядка, определенных выше, уравнение x ≐ f (..., x , ...) не имеет решения; следовательно, правило исключения может применяться только в том случае, если x ∉ vars ( t ).Поскольку эта дополнительная проверка, называемая «происходит проверка» , замедляет работу алгоритма, она опускается, например, в большинстве систем Пролога.С теоретической точки зрения пропуск проверки равнозначен решению уравнений над бесконечными деревьями, см. #Унификация бесконечных термов ниже.
Доказательство прекращения
[ редактировать ]Для доказательства завершения алгоритма рассмотрим тройку где n var — количество переменных, которые встречаются в наборе уравнений более одного раза, n lhs — количество функциональных символов и констант.в левых частях потенциальных уравнений, а n eqn — количество уравнений. правило исключения Когда применяется , n var уменьшается, поскольку x исключается из G и сохраняется только в { x ≐ t }.Применение любого другого правила никогда не сможет снова увеличить n var . правило decompose , конфликт или замена Когда применяется , n lhs левой части уменьшается, так как по крайней мере крайний f исчезает.Применение любого из оставшихся правил delete или check не может увеличить n lhs , но уменьшит n eqn .Следовательно, любое применение правил уменьшает тройную относительно лексикографического порядка , что возможно только конечное число раз.

Конор МакБрайд наблюдает [18] что «путем выражения структуры, которую использует унификация» на зависимо типизированном языке, таком как Epigram , алгоритм унификации Робинсона может быть сделан рекурсивным по количеству переменных , и в этом случае отдельное доказательство завершения становится ненужным.
Примеры синтаксической унификации терминов первого порядка
[ редактировать ]В синтаксическом соглашении Пролога символ, начинающийся с заглавной буквы, является именем переменной; символ, начинающийся со строчной буквы, является функциональным символом; запятая используется как логический оператор .Для математической записи x,y,z используются как переменные, f,g как функциональные символы и a,b как константы.
| Обозначение Пролога | Математические обозначения | Объединяющая замена | Объяснение |
|---|---|---|---|
a = a | { а = а } | {} | Успешно. ( тавтология ) |
a = b | { а = б } | ⊥ | а и б не совпадают |
X = X | { х = х } | {} | Успешно. ( тавтология ) |
a = X | { а = х } | { Икс ↦ а } | x унифицирован с константой a |
X = Y | { х = у } | { Икс ↦ у } | x и y имеют псевдонимы |
f(a,X) = f(a,b) | { ж ( а , Икс ) знак равно ж ( а , б ) } | { Икс ↦ б } | символы функции и константы совпадают, x унифицирован с константой b |
f(a) = g(a) | { ж ( а ) знак равно г ( а ) } | ⊥ | f и g не совпадают |
f(X) = f(Y) | { ж ( Икс ) знак равно ж ( у ) } | { Икс ↦ у } | x и y имеют псевдонимы |
f(X) = g(Y) | { ж ( Икс ) знак равно г ( у ) } | ⊥ | f и g не совпадают |
f(X) = f(Y,Z) | { ж ( Икс ) знак равно ж ( у , z ) } | ⊥ | Не удалось. Символы функции f имеют разную арность. |
f(g(X)) = f(Y) | { ж ( г ( Икс )) знак равно ж ( у ) } | { у ↦ г ( Икс ) } | Объединяет y с термином |
f(g(X),X) = f(Y,a) | { ж ( г ( Икс ), Икс ) знак равно ж ( у , а ) } | { Икс ↦ а , y ↦ грамм ( а )} | Объединяет x с константой a и y с термином |
X = f(X) | { Икс знак равно ж ( Икс ) } | должно быть ⊥ | Возвращает ⊥ в логике первого порядка и во многих современных диалектах Пролога (обеспечивается проверкой возникновения ). Успешно работает в традиционном Прологе и в Прологе II, объединяя x с бесконечным термином. |
X = Y, Y = a | { Икс знак равно у , у знак равно а } | { Икс ↦ а , у ↦ а } | И x, и y объединены константой a. |
a = Y, X = Y | { а знак равно у , х знак равно у } | { Икс ↦ а , у ↦ а } | Как указано выше (порядок уравнений в наборе не имеет значения) |
X = a, b = X | { Икс знак равно а , б знак равно х } | ⊥ | Не удалось. a и b не совпадают, поэтому x не может быть объединен с обоими |



Самый общий унификатор синтаксической задачи унификации первого порядка размера n может иметь размер 2. н . Например, проблема имеет самый общий унификатор , см. картина. Чтобы избежать экспоненциальной временной сложности, вызванной таким разрушением, усовершенствованные алгоритмы унификации работают с ориентированными ациклическими графами (дагами), а не с деревьями. [19]


Применение: унификация в логическом программировании.
[ редактировать ]Концепция унификации является одной из основных идей логического программирования . В частности, унификация является основным строительным блоком разрешения , правилом вывода для определения выполнимости формулы. В Прологе символ равенства = подразумевает синтаксическую унификацию первого порядка. Он представляет собой механизм связывания содержимого переменных и может рассматриваться как своего рода одноразовое присвоение.
В Прологе:
- Переменная . может быть объединена с константой, термином или другой переменной, тем самым фактически становясь ее псевдонимом Во многих современных диалектах Пролога и в логике первого порядка переменная не может быть объединена с содержащим ее термином; это так называемая проверка на наличие событий .
- Две константы могут быть объединены только в том случае, если они идентичны.
- Аналогично, термин может быть унифицирован с другим термином, если верхние функциональные символы и арии термов идентичны и если параметры могут быть унифицированы одновременно. Обратите внимание, что это рекурсивное поведение.
- Большинство операций, в том числе
+,-,*,/, не оцениваются=. Так например1+2 = 3невыполнимо, поскольку они синтаксически различны. Использование ограничений целочисленной арифметики#=вводит форму E-унификации, для которой эти операции интерпретируются и оцениваются. [20]
Применение: вывод типа
[ редактировать ]Алгоритмы вывода типа обычно основаны на унификации, в частности на выводе типа Хиндли-Милнера , который используется функциональными языками Haskell и ML . Например, при попытке определить тип выражения Haskell True : ['x'], компилятор будет использовать тип a -> [a] -> [a] функции построения списка (:), тип Bool из первого аргумента Trueи тип [Char] второго аргумента ['x']. Переменная полиморфного типа a будет унифицирован с Bool и второй аргумент [a] будет унифицирован с [Char]. a не может быть и то, и другое Bool и Char в то же время, поэтому это выражение набрано неправильно.
Как и в Прологе, можно задать алгоритм вывода типа:
- Любая переменная типа объединяется с любым выражением типа и создается для этого выражения. Конкретная теория может ограничить это правило проверкой возникновения.
- Константы двух типов объединяются, только если они относятся к одному и тому же типу.
- Две конструкции типов объединяются только в том случае, если они являются приложениями одного и того же конструктора типа и все типы их компонентов рекурсивно унифицируются.
Приложение: Унификация структуры функций
[ редактировать ]Унификация использовалась в различных областях исследований компьютерной лингвистики. [21] [22]
Унификация по порядку
[ редактировать ]Логика сортировки по порядку позволяет присваивать сорт или тип каждому термину и объявлять сорт другого сорта s s 1 подсортом 2 , обычно записываемого как s 1 ⊆ s 2 . Например, рассуждая о биологических существах, полезно объявить породистую собаку разновидностью породистого животного . Везде, где требуется термин какого-либо типа s , вместо него может быть указан термин любого подвида s .Например, предполагая объявление функции mother : Animal → Animal и объявление константы lassie : Dog , термин Mother ( lassie ) совершенно допустим и имеет вид Animal . Для предоставления информации о том, что мать собаки, в свою очередь, является собакой, другое заявление мать : собака → собака может быть выдано ; это называется перегрузкой функций , аналогично перегрузке в языках программирования .
Вальтер предложил алгоритм объединения терминов в логике с упорядоченной сортировкой, требуя, чтобы для любых двух объявленных сортов s 1 , s 2 их пересечение s 1 ∩ s 2 также было объявлено : если x 1 и x 2 являются переменными сорта s 1 и s 2 соответственно, уравнение x 1 ≐ x 2 имеет решение { x 1 = x , x 2 = x }, где x : s 1 ∩ s 2 . [23] Включив этот алгоритм в автоматизированный механизм доказательства теорем на основе предложений, он смог решить эталонную задачу, переведя ее в логику упорядоченной сортировки, тем самым уменьшив ее на порядок, поскольку многие унарные предикаты превратились в сортировки.
Смолка обобщил логику упорядоченной сортировки, допускающую параметрический полиморфизм . [24] В его рамках объявления подсортировки передаются в выражения сложного типа.В качестве примера программирования список параметрической сортировки ( X можно объявить ) (где X является параметром типа, как в шаблоне C++ ), и из объявления подсортировки int ⊆ float отношений список ( int ) ⊆ list ( float автоматически создается ). это означает, что каждый список целых чисел также является списком чисел с плавающей запятой.
Шмидт-Шаус обобщил логику упорядоченной сортировки, позволяющую объявлять термины. [25] В качестве примера, предполагая, что объявления подсортировки четные ⊆ int и нечетные ⊆ int , объявление термина типа ∀ i : int . ( i + i ) : позволяет даже объявить свойство сложения целых чисел, которое невозможно выразить обычной перегрузкой.
Объединение бесконечных членов
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( декабрь 2021 г. ) |
Фон на бесконечных деревьях:
- Б. Курсель (1983). «Фундаментальные свойства бесконечных деревьев» . Теория. Вычислить. Наука . 25 (2): 95–169. дои : 10.1016/0304-3975(83)90059-2 .
- Майкл Дж. Махер (июль 1988 г.). «Полные аксиоматизации алгебр конечных, рациональных и бесконечных деревьев». Учеб. Третий ежегодный симпозиум IEEE. по логике в информатике, Эдинбург . стр. 348–357.
- Джоксан Джаффар; Питер Дж. Стаки (1986). «Семантика программирования на основе бесконечной древовидной логики» . Теоретическая информатика . 46 : 141–158. дои : 10.1016/0304-3975(86)90027-7 .
Алгоритм объединения, Пролог II:
- А. Кольмерауэр (1982). К.Л. Кларк; С.-А. Тарнлунд (ред.). Пролог и бесконечные деревья . Академическая пресса.
- Ален Кольмерауэр (1984). «Уравнения и неравенства на конечных и бесконечных деревьях». В ICOT (ред.). Учеб. Межд. Конф. о компьютерных системах пятого поколения . стр. 85–99.
Приложения:
- Фрэнсис Джаннезини; Жак Коэн (1984). «Генерация парсера и манипулирование грамматикой с использованием бесконечных деревьев Пролога» . Журнал логического программирования . 1 (3): 253–265. дои : 10.1016/0743-1066(84)90013-X .
Электронное объединение
[ редактировать ]E-унификация — это проблема поиска решений заданного набора уравнений ,принимая во внимание некоторые эквациональные фоновые знания E .Последнее дано в виде набора универсальных равенств .Для некоторых конкретных множеств E решения уравнений алгоритмы (также известные как алгоритмы E-унификации были разработаны );для других было доказано, что таких алгоритмов не может существовать.
Например, если a и b — разные константы,уравнение не имеет решениячто касается чисто синтаксической унификации ,где ничего не известно об операторе .Однако, если , как известно, коммутативен ,тогда замена { x ↦ b , y ↦ a } решает приведенное выше уравнение,с


{ Икс ↦ б , у ↦ а } = по заявке на замену = по коммутативности = { Икс ↦ б , у ↦ а } путем (обратного) применения замены




Базовые знания E могли бы утверждать коммутативность по универсальному равенству" для всех u , v ".

Конкретные базовые наборы знаний E
[ редактировать ]| ∀ ты , v , ш : | | = | | А | Ассоциативность |
| ∀ u , v : | | = | | С | Коммутативность |
| ∀ ты , v , ш : | | = | | Д л | Левая дистрибутивность более |
| ∀ ты , v , ш : | | = | | Д р | Правая дистрибутивность более |
| ∀ в : | | = | в | я | Идемпотентность |
| ∀ в : | | = | в | Н л | Левый нейтральный элемент n относительно |
| ∀ в : | | = | в | NНет | Правый нейтральный элемент n относительно |












Говорят, что объединение теории разрешимо , если для нее разработан алгоритм объединения, завершающийся при любой входной задаче.Говорят, что объединение является полуразрешимым для теории, если для нее разработан алгоритм объединения, который завершается при любой разрешимой входной задаче, но может продолжать поиск решения неразрешимой входной проблемы вечно.
Объединение разрешимо для следующих теорий:
- А [26]
- А , С [27]
- А , С , Я [28]
- А , С , Н л [примечание 9] [28]
- А , я [29]
- A , N l , N r (моноид) [30]
- С [31]
- Булевы кольца [32] [33]
- Абелевы группы , даже если сигнатура расширена произвольными дополнительными символами (но не аксиомами) [34]
- K4 Модальные алгебры [35]
Унификация полуразрешима для следующих теорий:
- А , Д л , Д р [36]
- А , С , Д л [примечание 9] [37]
- Коммутативные кольца [34]
Односторонняя парамодуляция
[ редактировать ]Если существует конвергентная система переписывания терминов R, доступная для E ,алгоритм односторонней парамодуляции [38] можно использовать для перечисления всех решений заданных уравнений.
| грамм ∪ { ж ( s 1 ,..., s п ) ≐ ж ( т 1 ,..., т п ) } | ; С | ⇒ | г ∪ { s 1 ≐ т 1 , ..., s n ≐ т n } | ; С | разлагать | |
| г ∪ { Икс ≐ т } | ; С | ⇒ | г { Икс ↦ т } | ; S { Икс ↦ т } ∪ { Икс ↦ т } | если переменная x не встречается в t | устранять |
| г ∪ { ж ( s 1 ,..., s п ) ≐ т } | ; С | ⇒ | г ∪ { s 1 ≐ ты 1 , ..., s п ≐ ты п , р ≐ т } | ; С | если f ( u 1 ,..., ) un → r — правило из R | мутировать |
| г ∪ { ж ( s 1 ,..., s п ) ≐ y } | ; С | ⇒ | г ∪ { s 1 ≐ y 1 , ..., s n ≐ y n , y ≐ ж ( y 1 ,..., y n ) } | ; С | если y 1 ,..., y n — новые переменные | подражать |
Начиная с G — проблемы объединения, которую необходимо решить, а S — замены идентичности, правила применяются недетерминировано до тех пор, пока пустое множество не станет фактическим G , и в этом случае фактическое S является объединяющей заменой. В зависимости от порядка применения правил парамодуляции, выбора фактического уравнения из G и выбора R правил в mutate возможны разные пути вычислений. Лишь некоторые из них приводят к решению, тогда как другие заканчиваются на G ≠ {}, где дальнейшее правило не применимо (например, G = { f (...) ≐ g (...) }).
| 1 | приложение ( ноль , z ) | → я |
| 2 | приложение ( x . y , z ) | → х . приложение ( y , z ) |
Например, термин «система перезаписи R», используется определяющий оператор добавления списков, построенных из cons и nil ; где cons ( x , y ) записывается в инфиксной записи как x . y для краткости; например приложение ( a.b.nil , c.d.nil ) → a . приложение ( б . ноль , c . d . ноль ) → а . б . приложение ( ноль , c . d . ноль ) → а . б . в . д . nil демонстрирует объединение списков a . б . ноль и c . д . nil используя правила перезаписи 2, 2 и 1. Эквациональная теория E, соответствующая R , представляет собой конгруэнтное замыкание R , , оба рассматриваемые как бинарные отношения в терминах.Например app ( a.b.nil , c.d.nil . ) ≡ a , б . в . д . ноль ≡ приложение ( a . b . c . d . ноль , ноль ). Алгоритм парамодуляции перечисляет решения уравнений относительно этого E при использовании примера R .
Успешный пример пути вычислений для задачи объединения { app ( x , app ( y , x )) ≐ a . а . ноль } показано ниже. Чтобы избежать конфликтов имен переменных, правила перезаписи последовательно переименовываются каждый раз перед их использованием с помощью правила mutate ; v 2 , v 3 , ... — это имена переменных, генерируемые компьютером для этой цели. В каждой строке выбранное уравнение из G выделено красным. Каждый раз, когда изменения применяется правило , выбранное правило перезаписи ( 1 или 2 ) указывается в круглых скобках. Из последней строки объединяющая замена S = { y ↦ nil , x ↦ a . ноль } можно получить. Фактически, приложение ( Икс , приложение ( y , Икс )) { y ↦ ноль , Икс ↦ а . ноль } = приложение ( а . ноль , приложение ( ноль , а . ноль )) ≡ приложение ( а . ноль , а . ноль ) ≡ а . приложение ( ноль , а . ноль ) ≡ а . а . nil решает данную проблему.Второй успешный путь вычислений, который можно получить, выбрав «mutate(1), mutate(2), mutate(2), mutate(1)», приводит к замене S = { y ↦ a . а . ноль , х ↦ ноль }; здесь это не показано. Никакой другой путь не приведет к успеху.
| Используемое правило | Г | С | |
|---|---|---|---|
| { приложение ( x , приложение ( y , x )) ≐ а . а . ноль } | {} | ||
| мутировать(2) | ⇒ | { Икс ≐ v 2 . v 3 , приложение ( y , x ) ≐ v 4 , v2 . приложение ( v 3 , v 4 ) ≐ a . а . ноль } | {} |
| разлагать | ⇒ | { Икс ≐ v 2 . v 3 , приложение ( y , x ) ≐ v 4 , v 2 ≐ а , приложение ( v 3 , v 4 ) ≐ а . ноль } | {} |
| устранять | ⇒ | { app ( y , v 2 . v 3 ) ≐ v 4 , v 2 ≐ а , приложение ( v 3 , v 4 ) ≐ а . ноль } | { Икс ↦ v 2 . v 3 } |
| устранять | ⇒ | { приложение ( y , а . v 3 ) ≐ v 4 , приложение ( v 3 , v 4 ) ≐ a . ноль } | { Икс ↦ а . v 3 } |
| мутировать(1) | ⇒ | { у ≐ ноль , а . v 3 ≐ v 5 , v 5 ≐ v 4 , приложение ( v 3 , v 4 ) ≐ a . ноль } | { Икс ↦ а . v 3 } |
| устранять | ⇒ | { у ≐ ноль , а . v 3 ≐ v 4 , приложение ( v 3 , v 4 ) ≐ a . ноль } | { Икс ↦ а . v 3 } |
| устранять | ⇒ | { а . v 3 ≐ v 4 , приложение ( v 3 , v 4 ) ≐ a . ноль } | { у ↦ ноль , Икс ↦ а . v 3 } |
| мутировать(1) | ⇒ | { а . v 3 ≐ v 4 , v 3 ≐ ноль , v 4 ≐ v 6 , v 6 ≐ а . ноль } | { у ↦ ноль , Икс ↦ а . v 3 } |
| устранять | ⇒ | { а . v 3 ≐ v 4 , v 3 ≐ ноль , v 4 ≐ а . ноль } | { у ↦ ноль , Икс ↦ а . v 3 } |
| устранять | ⇒ | { а . ноль ≐ v 4 , v 4 ≐ а . ноль } | { у ↦ ноль , Икс ↦ а . ноль } |
| устранять | ⇒ | { и . ноль ≐ а . ноль } | { у ↦ ноль , Икс ↦ а . ноль } |
| разлагать | ⇒ | { а ≐ а , ноль ≐ ноль } | { у ↦ ноль , Икс ↦ а . ноль } |
| разлагать | ⇒ | { ноль ≐ ноль } | { у ↦ ноль , Икс ↦ а . ноль } |
| разлагать | ⇒ | {} | { у ↦ ноль , Икс ↦ а . ноль } |
Сужение
[ редактировать ]
Если R — сходящаяся система переписывания термов для E ,подход, альтернативный предыдущему разделу, состоит в последовательном применении « шагов сужения »;в конечном итоге это приведет к перечислению всех решений данного уравнения.Шаг сужения (см. рисунок) заключается в
- выбор неизменяемого подтерма текущего термина,
- синтаксически объединяя его с левой частью правила из R и
- замена правой части созданного правила на конкретизированный термин.
Формально, если l → r — это переименованная копия правила перезаписи из R , не имеющая общих переменных с термом s и подтерм s | p не является переменной и его можно объединить с l через mgu σ , тогда s можно сузить до термина t = sσ [ rσ ] p , т.е. до термина sσ подтерма в p , с заменой на rσ . Ситуацию, когда s можно сузить до t, обычно обозначают как s ↝ t .Интуитивно последовательность сужающих шагов t 1 ↝ t 2 ↝ ... ↝ t n можно рассматривать как последовательность шагов перезаписи t 1 → t 2 → ... → t n , но с начальным t 1 членом далее и далее реализуются по мере необходимости, чтобы каждое из используемых правил стало применимым.
Приведенный выше пример расчета парамодуляции соответствует следующей сужающей последовательности («↓» указывает на создание экземпляра здесь):
| приложение ( | х | , приложение ( и , | х | )) | |||||||||||||
| ↓ | ↓ | Икс ↦ v 2 . в 3 | |||||||||||||||
| приложение ( | в 2 . v3 | , приложение ( и , | в 2 . v3 | )) | → | в 2 . приложение ( v 3 , приложение ( | и | , т 2 . в 3 )) | |||||||||
| ↓ | и ↦ ноль | ||||||||||||||||
| в 2 . приложение ( v 3 , приложение ( | ноль | , т 2 . в 3 )) | → | v 2 . app ( | vv3 | , т 2 . | vv3 | ) | |||||||||
| ↓ | ↓ | v 3 ↦ ноль | |||||||||||||||
| v 2 . app ( | ноль | , т 2 . | ноль | ) | → | в 2 . в 2 . ноль |
Последний член, v 2 . в 2 . nil может быть синтаксически унифицирован с исходным термином правой части a . а . ноль .
Лемма о сужении [39] гарантирует, что всякий раз, когда экземпляр термина s может быть переписан в термин t с помощью конвергентной системы переписывания терминов, тогда s и t могут быть сужены и переписаны в термины s ′ и t ′ соответственно, так что t ′ является экземпляром из s ' .
Формально: всякий раз, когда sσ t выполняется для некоторой замены σ, то существуют члены s ′ , t ′ такие, что s s ′ и t t ′ и s ′ τ = t ′ для некоторой замены τ.
Объединение высшего порядка
[ редактировать ]



Многие приложения требуют учитывать унификацию типизированных лямбда-термов вместо термов первого порядка. Такое объединение часто называют объединением высшего порядка . Объединение высшего порядка неразрешимо , [40] [41] [42] и такие проблемы унификации не имеют наиболее общих унификаторов. Например, задача объединения { f ( a , b , a ) ≐ d ( b , a , c ) } , где единственной переменной является f , имеетрешения { ж ↦ λ Икс .λ y .λ z . d ( y , Икс , c ) }, { ж ↦ λ Икс .λ y .λ z . d ( y , z , c ) },{ ж ↦ λ Икс .λ y .λ z . d ( y , а , c ) }, { ж ↦ λ Икс .λ y .λ z . d ( б , х , с ) },{ ж ↦ λ Икс .λ y .λ z . d ( б , z , c ) } и { ж ↦ λ Икс .λ y .λ z . д ( б , а , в ) }. Хорошо изученной ветвью унификации высшего порядка является проблема объединения просто типизированных лямбда-термов по модулю равенства, определяемого преобразованиями αβη. Жерар Юэ предложил полуразрешимый алгоритм (предварительного) объединения. [43] позволяющий осуществлять систематический поиск в пространстве объединителей (обобщающий алгоритм объединения Мартелли-Монтанари [5] с правилами для терминов, содержащих переменные более высокого порядка), который, кажется, работает достаточно хорошо на практике. Хюэт [44] и Жиль Доук [45] написали статьи, посвященные этой теме.
Некоторые подмножества унификации более высокого порядка хорошо себя ведут, поскольку они разрешимы и имеют наиболее общий унификатор для решаемых задач. Одним из таких подмножеств являются ранее описанные члены первого порядка. Объединение шаблонов высшего порядка , благодаря Дейлу Миллеру, [46] это еще одно такое подмножество. Языки логического программирования высшего порядка λProlog и Twelf перешли от полной унификации высшего порядка к реализации только фрагмента шаблона; Удивительно, но унификация шаблона достаточна почти для всех программ, если каждая проблема унификации, не связанная с шаблоном, приостанавливается до тех пор, пока последующая замена не поместит унификацию во фрагмент шаблона. Надмножество унификации шаблонов, называемое унификацией функций как конструкторов, также хорошо себя ведет. [47] Средство доказательства теоремы Ципперпозиции имеет алгоритм, объединяющий эти подмножества с хорошим поведением в полный алгоритм объединения более высокого порядка. [2]
В компьютерной лингвистике одна из наиболее влиятельных теорий эллиптического построения заключается в том, что эллипсы представляются свободными переменными, значения которых затем определяются с использованием унификации высшего порядка. Например, семантическое представление фразы «Джон любит Мэри и Питер тоже» имеет вид ( j , m ) ∧ R( p ) , а значение R (семантическое представление многоточия) определяется уравнением типа ( j , м ) знак равно р( j ) . Процесс решения таких уравнений называется унификацией высшего порядка. [48]
Уэйн Снайдер дал обобщение как унификации высшего порядка, так и E-унификации, то есть алгоритм унификации лямбда-членов по модулю эквациональной теории. [49]
См. также
[ редактировать ]- Переписывание
- Допустимое правило
- Явная замена в лямбда-исчислении
- математических уравнений Решение
- Разъединение : решение неравенств между символическими выражениями
- Антиунификация : вычисление наименее общего обобщения (lgg) двух терминов, двойственное вычислению наиболее общего экземпляра (mgu).
- Решетка включения , решетка, имеющая объединение как встречу и антиобъединение как соединение.
- Выравнивание онтологий (используйте унификацию с семантической эквивалентностью )
Примечания
[ редактировать ]- ^ Например, а ⊕ ( б ⊕ ж ( Икс )) ≡ а ⊕ ( ж ( Икс ) ⊕ б ) ≡ ( б ⊕ ж ( Икс ) ) ⊕ а ≡ ( ж ( Икс ) ⊕ б ) ⊕ а
- ^ с тех пор
- ^ поскольку z { z ↦ x ⊕ y } = x ⊕ y
- ^ формально: каждый объединитель τ удовлетворяет ∀ x : xτ = ( xσ ) ρ для некоторой замены ρ
- ^ Робинсон использовал синтаксическую унификацию первого порядка в качестве основного строительного блока своей процедуры разрешения логики первого порядка, что стало большим шагом вперед в технологии автоматического рассуждения , поскольку оно устранило один источник комбинаторного взрыва : поиск экземпляров терминов. [14]
- ^ Независимое открытие изложено в Martelli & Montanari (1982), раздел 1, стр. 259. Издатель журнала получил награду Paterson & Wegman (1978) в сентябре 1976 года.
- ^ Алг.1, стр.261. Их правило (а) здесь соответствует обмену правилами , (б) — удалению , (в) — как разложению , так и конфликту , и (г) — как устранению , так и проверке .
- ^ Хотя правило сохраняет x ≐ t в G , оно не может зацикливаться вечно, поскольку его предварительное условие x ∈ vars ( G ) становится недействительным при первом применении. В более общем плане алгоритм гарантированно всегда завершается, см. ниже .
- ^ Перейти обратно: а б при наличии равенства C равенства N l и N r эквивалентны, аналогично для D l и D r

Ссылки
[ редактировать ]- ^ Доук, Жиль (1 января 2001 г.). «Объединение и сопоставление высшего порядка». Справочник по автоматизированному рассуждению . Elsevier Science Publishers BV, стр. 1009–1062. ISBN 978-0-444-50812-6 . Архивировано из оригинала 15 мая 2019 года . Проверено 15 мая 2019 г.
- ^ Перейти обратно: а б с Вукмирович, Петар; Бенткамп, Александр; Нуммелин, Visa (14 декабря 2021 г.). «Эффективная полная унификация высшего порядка» . Логические методы в информатике . 17 (4): 6919. arXiv : 2011.09507 . дои : 10.46298/lmcs-17(4:18)2021 .
- ^ Апт, Кшиштоф Р. (1997). От логического программирования к Прологу (1-е изд.). Лондон Мюнхен: Прентис Холл. п. 24. ISBN 013230368X .
- ^ Фаж, Франсуа; Юэ, Жерар (1986). «Полные наборы объединителей и сопоставлений в теориях уравнений» . Теоретическая информатика . 43 : 189–200. дои : 10.1016/0304-3975(86)90175-1 .
- ^ Перейти обратно: а б Мартелли, Альберто; Монтанари, Уго (апрель 1982 г.). «Эффективный алгоритм объединения». АКМ Транс. Программа. Ланг. Сист . 4 (2): 258–282. дои : 10.1145/357162.357169 . S2CID 10921306 .
- ^ Робинсон (1965) № 2.5, 2.14, стр.25
- ^ Робинсон (1965) № 5.6, стр.32
- ^ Робинсон (1965) № 5.8, стр.32
- ^ Ж. Эрбран: Исследования по теории демонстрации. Труды Варшавского общества наук и литературы , класс III, математические и физические науки, 33, 1930.
- ^ Жак Эрбран (1930). Исследования по теории демонстрации (PDF) (кандидатская диссертация). А. Том. 1252. Парижский университет. Здесь: стр.96-97
- ^ Перейти обратно: а б Клаус-Петер Вирт; Йорг Зикманн; Кристоф Бенцмюллер; Серж Отексье (2009). Лекции о Жаке Эрбране как логике (отчет SEKI). ДФКИ. arXiv : 0902.4682 . Здесь: стр.56
- ^ Робинсон, Дж. А. (январь 1965 г.). «Машинно-ориентированная логика, основанная на принципе разрешения» . Журнал АКМ . 12 (1): 23–41. дои : 10.1145/321250.321253 . S2CID 14389185 . ; Здесь: разд.5.8, стр.32
- ^ Дж. А. Робинсон (1971). «Вычислительная логика: унификация вычислений» . Машинный интеллект . 6 : 63–72.
- ^ Дэвид А. Даффи (1991). Принципы автоматического доказательства теорем . Нью-Йорк: Уайли. ISBN 0-471-92784-8 . Здесь: Введение раздела 3.3.3 "Унификация" , стр.72.
- ^ Перейти обратно: а б де Шампо, Деннис (август 2022 г.). «Алгоритм более быстрого линейного объединения» (PDF) . Журнал автоматизированного рассуждения . 66 : 845–860. дои : 10.1007/s10817-022-09635-1 .
- ^ Для Мартелли и Монтанари (1982) :
- Льюис Денвер Бакстер (февраль 1976 г.). Практически линейный алгоритм унификации (PDF) (Рез. отчет). Том. КС-76-13. унив. Ватерлоо, Онтарио.
- Жерар Юэ (сентябрь 1976 г.). Решение уравнений на языках порядка 1,2,...ω (Укажите их). Парижский университет VII.
- Мартелли, Альберто и Монтанари, Уго (июль 1976 г.). Объединение в линейном времени и пространстве: структурированное изложение (Внутренняя заметка). Том ИЭИ-В76-16. Национальный исследовательский совет, Пиза. Архивировано из оригинала 15 января 2015 г.
- Патерсон, Миссисипи; Вегман, Миннесота (май 1976 г.). Чандра, Ашок К.; Вочке, Детлеф; Фридман, Эмили П.; Харрисон, Майкл А. (ред.). Линейное объединение . Материалы восьмого ежегодного симпозиума ACM по теории вычислений (STOC). АКМ. стр. 181–186. дои : 10.1145/800113.803646 .
- Патерсон, Массачусетс ; Вегман, Миннесота (апрель 1978 г.). «Линейное объединение» . Дж. Компьютер. Сист. Наука . 16 (2): 158–167. дои : 10.1016/0022-0000(78)90043-0 .
- Дж. А. Робинсон (январь 1976 г.). «Быстрое объединение» . В Вудро В. Бледсо , Майкл М. Рихтер (ред.). Учеб. Мастерская доказательства теорем в Обервольфахе . Отчет о семинаре в Обервольфахе. Том. 1976/3. [ постоянная мертвая ссылка ]
- М. Вентурини-Зилли (октябрь 1975 г.). «Сложность алгоритма объединения выражений первого порядка». Кальколо . 12 (4): 361–372. дои : 10.1007/BF02575754 . S2CID 189789152 .
- ^ Баадер, Франц; Снайдер, Уэйн (2001). «Теория объединения» (PDF) . Справочник по автоматизированному рассуждению . стр. 445–533. дои : 10.1016/B978-044450813-3/50010-2 .
- ^ Макбрайд, Конор (октябрь 2003 г.). «Объединение первого порядка посредством структурной рекурсии» . Журнал функционального программирования . 13 (6): 1061–1076. CiteSeerX 10.1.1.25.1516 . дои : 10.1017/S0956796803004957 . ISSN 0956-7968 . S2CID 43523380 . Проверено 30 марта 2012 г.
- ^ например , Патерсон и Вегман (1978), раздел 2, стр.159.
- ^ «Декларативная целочисленная арифметика» . SWI-Пролог . Проверено 18 февраля 2024 г.
- ^ Джонатан Колдер, Майк Рип и Хэнк Зиват, Алгоритм генерации категориальной грамматики объединения . В материалах 4-й конференции Европейского отделения Ассоциации компьютерной лингвистики, страницы 233–240, Манчестер, Англия (10–12 апреля), Институт науки и технологий Манчестерского университета, 1989.
- ^ Грэм Херст и Дэвид Сент-Ондж, [1] Лексические цепочки как представление контекста для обнаружения и исправления неправильных слов, 1998.
- ^ Вальтер, Кристоф (1985). «Механическое решение парового катка Шуберта с помощью многосортного разрешения» (PDF) . Артиф. Интелл . 26 (2): 217–224. дои : 10.1016/0004-3702(85)90029-3 . Архивировано из оригинала (PDF) 8 июля 2011 г. Проверено 28 июня 2013 г.
- ^ Смолка, Герт (ноябрь 1988 г.). Логическое программирование с полиморфно отсортированными типами (PDF) . Межд. Практикум по алгебраическому и логическому программированию. ЛНКС. Том. 343. Спрингер. стр. 53–70. дои : 10.1007/3-540-50667-5_58 .
- ^ Шмидт-Шаус, Манфред (апрель 1988 г.). Вычислительные аспекты логики упорядоченной сортировки с объявлениями термов . Конспекты лекций по искусственному интеллекту (LNAI). Том. 395. Спрингер.
- ^ Гордон Д. Плоткин , Теоретико-решеточные свойства включения , Меморандум MIP-R-77, Univ. Эдинбург, июнь 1970 г.
- ^ Марк Э. Стикель , Алгоритм объединения ассоциативно-коммутативных функций , Журнал Ассоциации вычислительной техники, том 28, № 3, стр. 423–434, 1981
- ^ Перейти обратно: а б Ф. Фагес, Ассоциативно-коммутативное объединение , J. Символические вычисления, том 3, № 3, стр. 257–275, 1987.
- ^ Франц Баадер, Объединение в идемпотентных полугруппах имеет нулевой тип , J. Automat. Рассуждения, т.2, №3, 1986 г.
- ^ Я. Маканин, Проблема разрешимости уравнений в свободной полугруппе , Акад. Наук СССР, т.233, №2, 1977 г.
- ^ Ф. Фагес (1987). «Ассоциативно-коммутативное объединение» (PDF) . J. Символические вычисления . 3 (3): 257–275. дои : 10.1016/s0747-7171(87)80004-4 . S2CID 40499266 .
- ^ Мартин У., Нипков Т. (1986). «Объединение в булевых кольцах». В Йорге Х. Зикманне (ред.). Учеб. 8-й КАДЕ . ЛНКС. Том. 230. Спрингер. стр. 506–513.
{{cite book}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ А. Буде; Ж. П. Жуанно; М. Шмидт-Шаус (1989). «Объединение булевых колец и абелевых групп» . Журнал символических вычислений . 8 (5): 449–477. дои : 10.1016/s0747-7171(89)80054-9 .
- ^ Перейти обратно: а б Баадер и Снайдер (2001), стр. 486.
- ^ Ф. Баадер и С. Гиларди, Унификация модальных и дескриптивных логик , Логический журнал IGPL 19 (2011), вып. 6, стр. 705–730.
- ^ П. Сабо, порядка первого Теория объединения , диссертация, Univ. Карлсруэ, Западная Германия, 1982 г.
- ^ Йорг Х. Зикманн, Универсальное объединение , Proc. 7-й Межд. Конф. об автоматическом выводе, Springer LNCS, том 170, стр. 1–42, 1984 г.
- ^ Н. Дершовиц и Г. Сивакумар, Решение задач на эквациональных языках , Proc. 1-й Межд. Семинар по системам переписывания условных терминов, Springer LNCS, том 308, стр. 45–55, 1988 г.
- ^ Фэй (1979). «Объединение первого порядка в эквациональной теории». Учеб. 4-й семинар по автоматизированному дедукции . стр. 161–167.
- ^ Перейти обратно: а б Уоррен Д. Гольдфарб (1981). «Неразрешимость проблемы объединения второго порядка» . ТКС . 13 (2): 225–230. дои : 10.1016/0304-3975(81)90040-2 .
- ^ Жерар П. Юэ (1973). «Неразрешимость объединения в логике третьего порядка» . Информация и контроль . 22 (3): 257–267. дои : 10.1016/S0019-9958(73)90301-X .
- ^ Клаудио Луккези: Неразрешимость проблемы унификации языков третьего порядка (отчет об исследовании CSRR 2059; факультет компьютерных наук, Университет Ватерлоо, 1972)
- ^ Жерар Юэ: Алгоритм объединения типизированного лямбда-исчисления []
- ^ Жерар Юэ: Объединение высшего порядка 30 лет спустя
- ^ Жиль Довек: Объединение и сопоставление высшего порядка. Справочник по автоматическому рассуждению 2001: 1009–1062.
- ^ Миллер, Дейл (1991). «Язык логического программирования с лямбда-абстракцией, функциональными переменными и простой унификацией» (PDF) . Журнал логики и вычислений . 1 (4): 497–536. дои : 10.1093/logcom/1.4.497 .
- ^ Либал, Томер; Миллер, Дейл (май 2022 г.). «Унификация функций-как-конструкторов высшего порядка: расширенная унификация шаблонов» . Анналы математики и искусственного интеллекта . 90 (5): 455–479. дои : 10.1007/s10472-021-09774-y .
- ^ Гардент, Клэр ; Кольхасе, Майкл ; Конрад, Карстен (1997). «Многоуровневый подход к унификации более высокого порядка к многоточию». Представлено в Европейскую ассоциацию компьютерной лингвистики (EACL) . CiteSeerX 10.1.1.55.9018 .
- ^ Уэйн Снайдер (июль 1990 г.). «Электронное объединение высшего порядка». Учеб. 10-я конференция по автоматизированному дедукции . ЛНАИ. Том. 449. Спрингер. стр. 573–587.
Дальнейшее чтение
[ редактировать ]- Франц Баадер и Уэйн Снайдер (2001). «Теория объединения». Архивировано 8 июня 2015 г. в Wayback Machine . Джон Алан Робинсон и Андрей Воронков , редакторы, «Справочник по автоматическому рассуждению» , том I, страницы 447–533. Издательство Elsevier Science. [ мертвая ссылка ]
- Жиль Довек (2001). «Объединение и сопоставление высшего порядка». Архивировано 15 мая 2019 г. на Wayback Machine . В Справочнике по автоматизированному рассуждению .
- Франц Баадер и Тобиас Нипков (1998). Переписывание терминов и все такое . Издательство Кембриджского университета.
- Франц Баадер и Йорг Х. Зикманн (1993). «Теория объединения». В Справочнике по логике в искусственном интеллекте и логическом программировании .
- Жан-Пьер Жуанно и Клод Киршнер (1991). «Решение уравнений в абстрактных алгебрах: обзор унификации на основе правил». В вычислительной логике: Очерки в честь Алана Робинсона .
- Нахум Дершовиц и Жан-Пьер Жуанно , Rewrite Systems , в: Ян ван Леувен (ред.), Справочник по теоретической информатике , том B Формальные модели и семантика , Elsevier, 1990, стр. 243–320.
- Йорг Х. Зикманн (1990). «Теория объединения». В Клоде Киршнере (редактор) Unification . Академическая пресса.
- Кевин Найт (март 1989 г.). «Унификация: междисциплинарный обзор» (PDF) . Обзоры вычислительной техники ACM . 21 (1): 93–124. CiteSeerX 10.1.1.64.8967 . дои : 10.1145/62029.62030 . S2CID 14619034 .
- Жерар Юэ и Дерек К. Оппен (1980). «Уравнения и правила перезаписи: обзор» . Технический отчет. Стэнфордский университет.
- Раулефс, Питер; Зикманн, Йорг; Сабо, П.; Унверихт, Э. (1979). «Краткий обзор современного состояния проблем сопоставления и унификации». Бюллетень ACM SIGSAM . 13 (2): 14–20. дои : 10.1145/1089208.1089210 . S2CID 17033087 .
- Клод Киршнер и Элен Киршнер. Переписывание, решение, доказательство . В стадии подготовки.