Перекрестная энтропия
| Теория информации |
|---|
 |
В теории информации кросс -энтропия между двумя распределениями вероятностей и , по одному и тому же базовому набору событий, измеряет среднее количество битов, необходимых для идентификации события, взятого из набора, когда схема кодирования, используемая для набора, оптимизирована для предполагаемого распределения вероятностей. , а не истинное распределение .


Определение
[ редактировать ]Перекрестная энтропия распределения относительно распределения по заданному множеству определяется следующим образом:
- ,
![{\displaystyle H(p,q)=-\operatorname {E} _{p}[\log q]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/263d05a25e5bb259bc64e4395bd646977bab8326)
где — оператор ожидаемого значения относительно распределения .
![{\displaystyle E_{p}[\cdot ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d16c30a1e4e78c3714c3aed9cd48f7f1990441a9)
Определение можно сформулировать с использованием расхождения Кульбака – Лейблера. , расхождение от (также известная как энтропия относительная относительно ).


где это энтропия .

Для дискретных распределений вероятностей и с той же поддержкой , это означает

| . | ( Уравнение 1 ) |

ситуация и для непрерывных Аналогичная распределений. Мы должны предположить, что и относительно абсолютно непрерывны некоторой эталонной меры (обычно является мерой Лебега на борелевской σ-алгебре ). Позволять и — функции плотности вероятности и относительно . Затем



![{\displaystyle -\int _{\mathcal {X}}P(x)\,\log Q(x)\,\mathrm {d} \ \!x=\operatorname {E} _{p}[-\ журнал Q],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3c7a680f797b5a5c9c542d031e6079378780ab6c)
и поэтому
| . | ( Уравнение 2 ) |

Примечание: Обозначения также используется для другого понятия - совместной энтропии и .

Мотивация
[ редактировать ]В теории информации теорема Крафта-Макмиллана устанавливает, что любая непосредственно декодируемая схема кодирования для кодирования сообщения для идентификации одного значения из множества возможностей можно рассматривать как представление неявного распределения вероятностей над , где длина кода для в битах. Следовательно, перекрестную энтропию можно интерпретировать как ожидаемую длину сообщения на единицу данных при неправильном распределении. предполагается, в то время как данные фактически следуют распределению . Вот почему математическое ожидание принимается за истинное распределение вероятностей. и не Действительно, ожидаемая длина сообщения при истинном распределении является





![{\displaystyle \operatorname {E} _{p}[\ell ]=-\operatorname {E} _{p}\left[{\frac {\ln {q(x)}}{\ln(2)} }\right]=-\operatorname {E} _{p}\left[\log _{2}{q(x)}\right]=-\sum _{x_{i}}p(x_{i} )\,\log _{2}q(x_{i})=-\sum _{x}p(x)\,\log _{2}q(x)=H(p,q).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f5427081785e1c503a5e3c49969c38d8d90c21a)
Оценка
[ редактировать ]Во многих ситуациях необходимо измерить перекрестную энтропию, но распределение неизвестно. Примером является языковое моделирование , где модель создается на основе обучающего набора. , а затем ее перекрестная энтропия измеряется на тестовом наборе, чтобы оценить, насколько точно модель прогнозирует тестовые данные. В этом примере это истинное распределение слов в любом корпусе, и — это распределение слов, предсказанное моделью. Поскольку истинное распределение неизвестно, перекрестную энтропию невозможно вычислить напрямую. В этих случаях оценка перекрестной энтропии рассчитывается по следующей формуле:


где - размер тестового набора, и это вероятность события оценивается по обучающему набору. Другими словами, — это оценка вероятности модели того, что i-е слово текста является . Сумма усредняется по слова теста. Это Монте-Карло , где тестовый набор рассматривается как образцы из оценка истинной перекрестной энтропии методом [ нужна ссылка ] .





Отношение к максимальной вероятности
[ редактировать ]Перекрестная энтропия возникает в задачах классификации при введении логарифма под видом функции логарифма правдоподобия .
Раздел посвящен теме оценки вероятности различных возможных дискретных исходов. Для этого обозначим параметризованное семейство распределений через , с с учетом усилий по оптимизации. Рассмотрим данную конечную последовательность ценности из обучающей выборки, полученной в результате условно независимой выборки. Вероятность, присвоенная любому рассматриваемому параметру модели тогда определяется произведением по всем вероятностям .Возможны повторения, приводящие к равным коэффициентам в продукте. Если количество вхождений значения равно (для некоторого индекса ) обозначается , то частота этого значения равна . Обозначим последнее через , поскольку его можно понимать как эмпирическое приближение к распределению вероятностей, лежащему в основе сценария. Далее обозначим через недоумение , которое можно рассматривать как равное по правилам расчета логарифма и где произведение превышает значения без двойного счета. Так










или

Поскольку логарифм — монотонно возрастающая функция , он не влияет на экстремизацию. Итак, заметьте, что максимизация правдоподобия означает минимизацию перекрестной энтропии.
Минимизация перекрестной энтропии
[ редактировать ]Минимизация перекрестной энтропии часто используется при оптимизации и оценке вероятности редких событий. При сравнении распределения против фиксированного эталонного распределения , кросс-энтропия и KL-дивергенция идентичны с точностью до аддитивной константы (поскольку фиксировано): Согласно неравенству Гиббса , оба принимают свои минимальные значения, когда , что для KL-расхождения, и для перекрестной энтропии. В инженерной литературе принцип минимизации KL-дивергенции (« Принцип минимальной дискриминационной информации » Кульбака) часто называют принципом минимальной перекрестной энтропии (MCE), или Minxent .



Однако, как обсуждается в статье « Расхождение Кульбака – Лейблера» , иногда распределение - фиксированное априорное эталонное распределение, а распределение оптимизирован так, чтобы быть как можно ближе к насколько это возможно, с учетом некоторых ограничений. В этом случае две минимизации не эквивалентны. Это привело к некоторой двусмысленности в литературе: некоторые авторы пытались разрешить это несоответствие, вновь заявив, что кросс-энтропия , скорее, чем . Фактически, перекрестная энтропия — это другое название относительной энтропии ; см. Ковер и Томас [1] и Хорошо. [2] С другой стороны, не согласуется с литературой и может вводить в заблуждение.
Функция перекрестных энтропийных потерь и логистическая регрессия
[ редактировать ]Перекрестная энтропия может использоваться для определения функции потерь в машинном обучении и оптимизации . Мао, Мори и Чжун (2023) дают обширный анализ свойств семейства функций перекрестных энтропийных потерь в машинах.обучение, включая гарантии теоретического обучения и расширениесостязательное обучение. [3] Истинная вероятность - истинная метка, а данное распределение — прогнозируемое значение текущей модели. Это также известно как логарифмические потери (или логарифмические потери). [4] или логистические потери ); [5] термины «логарифмические потери» и «перекрестные энтропийные потери» используются как взаимозаменяемые. [6]


Более конкретно, рассмотрим модель бинарной регрессии , которую можно использовать для классификации наблюдений на два возможных класса (часто обозначаемых просто как и ). Выходные данные модели для данного наблюдения с учетом вектора входных признаков. , можно интерпретировать как вероятность, которая служит основой для классификации наблюдения. В логистической регрессии вероятность моделируется с помощью логистической функции где — некоторая функция входного вектора , обычно просто линейная функция. Вероятность выхода дается





где вектор весов оптимизируется с помощью некоторого подходящего алгоритма, такого как градиентный спуск . Аналогично, дополнительная вероятность найти выход просто дается



Установив наши обозначения, и , мы можем использовать перекрестную энтропию, чтобы получить меру несходства между и :


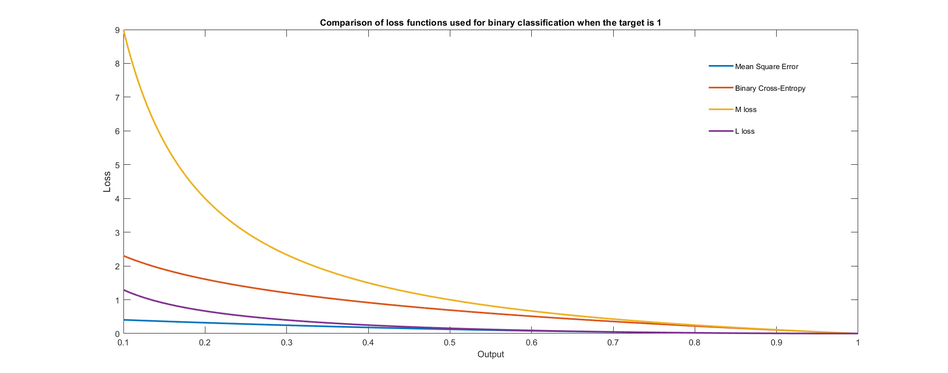
На графике показаны различные функции потерь, которые можно использовать для обучения двоичного классификатора. Показан только случай, когда целевой выход равен 1. Замечено, что потери равны нулю, когда целевое значение равно выходному значению, и увеличиваются по мере того, как выходные данные становятся все более неверными.


Логистическая регрессия обычно оптимизирует потери журнала для всех наблюдений, на которых она обучается, что аналогично оптимизации средней перекрестной энтропии в выборке. Для обучения также можно использовать другие функции потерь, которые по-разному наказывают за ошибки, в результате чего получаются модели с различной точностью окончательного теста. [7] Например, предположим, что у нас есть образцы, каждый из которых индексируется . Среднее значение функции потерь тогда определяется следующим образом:

![{\displaystyle {\begin{aligned}J(\mathbf {w})\ &=\ {\frac {1}{N}}\sum _{n=1}^{N}H(p_{n}, q_{n})\ =\ -{\frac {1}{N}}\sum _{n=1}^{N}\ {\bigg [}y_{n}\log {\hat {y}} _{n}+(1-y_{n})\log(1-{\hat {y}}_{n}){\bigg ]}\,,\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/80f87a71d3a616a0939f5360cec24d702d2593a2)
где , с логистическая функция прежняя.


Логистические потери иногда называют кросс-энтропийными потерями. Это также известно как потеря журнала. [ дублирование? ] (В этом случае двоичная метка часто обозначается {−1,+1}. [8] )
Примечание. Градиент потери перекрестной энтропии для логистической регрессии такой же, как градиент потери квадрата ошибки для линейной регрессии . То есть определить


![{\displaystyle L({\boldsymbol {\beta }})=-\sum _{i=1}^{N}\left[y_{i}\log {\hat {y}}_{i}+( 1-y_{i})\log(1-{\hat {y}}_{i})\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4853978e83348b07e0b3c80d3152d7bbdeb30211)
Тогда у нас есть результат

Доказательство состоит в следующем. Для любого , у нас есть



![{\displaystyle {\begin{aligned}{\frac {\partial }{\partial \beta _{0}}}L({\boldsymbol {\beta }})&=-\sum _{i=1}^ {N}\left[{\frac {y_{i}\cdot e^{-\beta _{0}+k_{0}}}{1+e^{-\beta _{0}+k_{0 }}}}-(1-y_{i}){\frac {1}{1+e^{-\beta _{0}+k_{0}}}}\right]\\&=-\sum _{i=1}^{N}\left[y_{i}-{\hat {y}}_{i}\right]=\sum _{i=1}^{N}({\hat { y}}_{i}-y_{i}),\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/da12a84826141abda49405406ae48a367606398f)

![{\displaystyle {\frac {\partial }{\partial \beta _{1}}}\ln \left[1-{\frac {1}{1+e^{-\beta _{1}x_{i1 }+k_{1}}}}\right]={\frac {-x_{i1}e^{\beta _{1}x_{i1}}}{e^{\beta _{1}x_{i1 }}+e^{k_{1}}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f551d787c499daded9a2cb523f6025d802bf491e)

Подобным образом мы в конечном итоге получаем желаемый результат.
Измененная перекрестная энтропия
[ редактировать ]Может быть полезно обучить ансамбль моделей, которые имеют разнообразие, так что при их объединении точность их прогнозирования увеличивается. [9] [10] Если предположить, что это простой ансамбль классификаторы собираются путем усреднения выходных данных, тогда исправленная кросс-энтропия определяется выражением


где представляет собой функцию стоимости классификатор, - выходная вероятность классификатор, - истинная вероятность, которую необходимо оценить, и — это параметр от 0 до 1, определяющий «разнообразие», которое мы хотели бы установить в ансамбле. Когда мы хотим, чтобы каждый классификатор делал все возможное независимо от ансамбля и времени нам бы хотелось, чтобы классификатор был как можно более разнообразным.






См. также
[ редактировать ]- Метод перекрестной энтропии
- Логистическая регрессия
- Условная энтропия
- Расстояние Кульбака – Лейблера
- Оценка максимального правдоподобия
- Взаимная информация
Ссылки
[ редактировать ]- ^ Томас М. Ковер, Джой А. Томас, Элементы теории информации, 2-е издание, Wiley, с. 80
- ^ И. Дж. Гуд, Максимальная энтропия для формулирования гипотез, особенно для многомерных таблиц непредвиденных обстоятельств, Ann. математики. Статистика, 1963 г.
- ^ Аньци Мао, Мехриар Мори, Ютао Чжун. Функции перекрестных энтропийных потерь: теоретический анализ и приложения. ICML 2023. https://arxiv.org/pdf/2304.07288.pdf.
- ^ Математика кодирования, извлечения и распространения информации , Джордж Цибенко, Дайанна П. О'Лири, Йорма Риссанен, 1999, стр. 82
- ^ Вероятность для машинного обучения: узнайте, как использовать неопределенность с помощью Python , Джейсон Браунли, 2019, стр. 220: «Логистические потери относятся к функции потерь, обычно используемой для оптимизации модели логистической регрессии. Ее также можно называть логарифмическими потерями (что сбивает с толку) или просто логарифмическими потерями».
- ^ sklearn.metrics.log_loss
- ^ Ноэль, Мэтью; Банерджи, Ариндам; Д, Джеральдин Бесси Амали; Мутиа-Накараджан, Венкатараман (17 марта 2023 г.). «Альтернативные функции потерь для классификации и устойчивой регрессии могут повысить точность искусственных нейронных сетей». arXiv : 2303.09935 [ cs.NE ].
- ^ Мерфи, Кевин (2012). Машинное обучение: вероятностный взгляд . Массачусетский технологический институт. ISBN 978-0262018029 .
- ^ Шохам, Рон; Пермутер, Хаим Х. (2019). «Измененная стоимость перекрестной энтропии: подход к поощрению разнообразия в классификационном ансамбле (краткое объявление)». Ин Долев, Шломи; Хендлер, Дэнни; Лодха, Сачин; Юнг, Моти (ред.). Кибербезопасность, криптография и машинное обучение – Третий международный симпозиум, CSCML 2019, Беэр-Шева, Израиль, 27–28 июня 2019 г., Материалы . Конспекты лекций по информатике. Том. 11527. Спрингер. стр. 202–207. дои : 10.1007/978-3-030-20951-3_18 . ISBN 978-3-030-20950-6 .
- ^ Шохам, Рон; Пермутер, Хаим (2020). «Измененная стоимость перекрестной энтропии: основа явного поощрения разнообразия». arXiv : 2007.08140 [ cs.LG ].
Дальнейшее чтение
[ редактировать ]- де Бур, Крозе, Д.П., Маннор, С. и Рубинштейн, Р.Ю. (2005). Учебное пособие по методу перекрестной энтропии . Анналы исследования операций 134 (1), 19–67.