Родословная данных
Эта статья содержит формулировки, которые продвигают эту тему в субъективной манере, не передавая реальной информации . ( Май 2015 г. ) |
Происхождение данных включает в себя происхождение данных , то, что с ними происходит и куда они перемещаются с течением времени. [1] Происхождение данных обеспечивает прозрачность и упрощает отслеживание ошибок до их первопричины в процессе анализа данных . [2]
Это также позволяет воспроизводить определенные части или входные данные потока данных для поэтапной отладки или восстановления потерянных выходных данных. Системы баз данных используют такую информацию, называемую источником данных , для решения аналогичных задач проверки и отладки. [3] Происхождение данных относится к записям входных данных, объектов, систем и процессов, которые влияют на интересующие данные, обеспечивая историческую запись данных и их происхождения. Созданные доказательства поддерживают судебно-медицинскую деятельность, такую как анализ зависимостей данных, обнаружение и восстановление ошибок/компрометаций, аудит и анализ соответствия. « Происхождение — это простой пример происхождения ». [3]
Происхождение данных можно представить визуально, чтобы обнаружить поток/движение данных от источника к месту назначения посредством различных изменений и переходов на своем пути в корпоративной среде, как данные трансформируются на этом пути, как изменяются представление и параметры и как данные разделяются или сходятся после каждого перехода. Простое представление линии передачи данных можно отобразить с помощью точек и линий, где точка представляет собой контейнер данных для точек данных, а линии, соединяющие их, представляют собой преобразования, которым подвергается точка данных между контейнерами данных.
Представление во многом зависит от объема управления метаданными и интересующей точки отсчета. Происхождение данных обеспечивает источники данных и промежуточные переходы потока данных от контрольной точки с обратной линией передачи данных , ведущие к точкам данных конечного пункта назначения и его промежуточным потокам данных с прямой линией передачи данных . Эти представления можно комбинировать со сквозной линией происхождения для создания контрольной точки, которая обеспечивает полный контрольный журнал интересующей точки данных от источников до конечных пунктов назначения. По мере увеличения точек данных или прыжков сложность такого представления становится непостижимой. Таким образом, лучшей особенностью представления происхождения данных была бы возможность упростить представление путем временной маскировки нежелательных периферийных точек данных. Инструменты с функцией маскировки обеспечивают масштабируемость представления и улучшают анализ, обеспечивая удобство работы как для технических, так и для бизнес-пользователей. Происхождение данных также позволяет компаниям отслеживать источники конкретных бизнес-данных в целях отслеживания ошибок, внесения изменений в процессы и внедрения миграция системы позволяет сэкономить значительное количество времени и ресурсов, тем самым значительно повышая BI . эффективность [4]
Объем происхождения данных определяет объем метаданных, необходимых для представления происхождения данных. Обычно управление данными и управление данными определяют объем передачи данных на основе их правил , стратегии управления данными предприятия, влияния данных, атрибутов отчетности и критических элементов данных организации.
Происхождение данных обеспечивает контрольный журнал точек данных на самом высоком уровне детализации, но представление происхождения может осуществляться с различными уровнями масштабирования, чтобы упростить обширную информацию, подобно аналитическим веб-картам. Происхождение данных можно визуализировать на различных уровнях в зависимости от детализации представления. На очень высоком уровне происхождение данных определяет, с какими системами взаимодействуют данные, прежде чем они достигнут места назначения. По мере увеличения детализации она поднимается до уровня точки данных, где может предоставить подробную информацию о точке данных и ее историческом поведении, свойствах атрибутов, а также тенденциях и качестве данных , прошедших через эту конкретную точку данных в линии передачи данных.
Управление данными играет ключевую роль в управлении метаданными для руководящих принципов, стратегий, политики и реализации. Качество данных и управление основными данными помогают обогатить поток данных, придав им большую ценность для бизнеса. Несмотря на то, что окончательное представление происхождения данных предоставляется в одном интерфейсе, способ сбора метаданных и предоставления их графическому пользовательскому интерфейсу происхождения данных может быть совершенно другим. Таким образом, происхождение данных можно в общих чертах разделить на три категории в зависимости от способа сбора метаданных: происхождение данных, включающее пакеты программного обеспечения для структурированных данных, языки программирования и большие данные .
Информация о происхождении данных включает технические метаданные, включающие преобразования данных. Расширенная информация о происхождении данных может включать результаты тестов качества данных, значения справочных данных, модели данных , бизнес-лексику , управляющих данными , информацию управления программами и информационные системы предприятия , связанные с точками данных и преобразованиями. Функция маскировки в визуализации происхождения данных позволяет инструментам включать все дополнения, которые важны для конкретного варианта использования. Чтобы представить разрозненные системы в одном общем представлении, « нормализация может потребоваться метаданных» или стандартизация.
Обоснование [ править ]
Распределенные системы, такие как Google Map уменьшает , [5] Майкрософт Дриада, [6] Апач Хадуп [7] (проект с открытым исходным кодом) и Google Pregel [8] предоставлять такие платформы для бизнеса и пользователей. Однако даже при использовании этих систем анализ больших данных может занять несколько часов, дней или недель просто из-за задействованных объемов данных. Например, выполнение алгоритма прогнозирования рейтингов для конкурса Netflix Prize заняло почти 20 часов на 50 ядрах, а выполнение крупномасштабной задачи обработки изображений для оценки географической информации заняло 3 дня с использованием 400 ядер. [9] «Ожидается, что Большой синоптический обзорный телескоп будет генерировать терабайты данных каждую ночь и в конечном итоге хранить более 50 петабайт, в то время как в секторе биоинформатики крупнейшие в мире центры по секвенированию генома теперь хранят по петабайтам данных каждый». [10] Специалисту по данным очень сложно отследить неизвестный или неожиданный результат.
Отладка больших данных [ править ]
Аналитика больших данных — это процесс изучения больших наборов данных для выявления скрытых закономерностей, неизвестных корреляций, рыночных тенденций, предпочтений клиентов и другой полезной бизнес-информации. Они применяют к данным алгоритмы машинного обучения и т. д., которые преобразуют данные. Из-за огромного размера данных в них могут быть неизвестные особенности, возможно даже выбросы. Специалисту по данным довольно сложно отладить неожиданный результат.
Огромный масштаб и неструктурированный характер данных, сложность этих аналитических конвейеров и длительное время выполнения создают серьезные проблемы с управлением и отладкой. Даже одну ошибку в этой аналитике бывает крайне сложно выявить и устранить. Хотя их можно отладить, повторно пропустив всю аналитику через отладчик для поэтапной отладки, это может оказаться дорогостоящим из-за количества необходимого времени и ресурсов. Аудит и проверка данных являются другими серьезными проблемами из-за растущей легкости доступа к соответствующим источникам данных для использования в экспериментах, обмена данными между научными сообществами и использования сторонних данных на коммерческих предприятиях. [11] [12] [13] [14] Эти проблемы будут только становиться больше и острее по мере того, как эти системы и данные будут продолжать расти. Таким образом, более экономичные способы анализа масштабируемых вычислений с интенсивным использованием данных (DISC) имеют решающее значение для их дальнейшего эффективного использования.
отладки Проблемы данных больших
Масштабный [ править ]
Согласно исследованию EMC/IDC: [15]
- В 2012 году было создано и реплицировано 2,8 ЗБ данных.
- цифровая вселенная будет удваиваться каждые два года в период до 2020 года, и
- в 2020 году на каждого человека будет приходиться примерно 5,2 ТБ данных.
Работать с таким масштабом данных стало очень сложно.
Неструктурированные данные [ править ]
Неструктурированные данные обычно относятся к информации, которая не находится в традиционной базе данных со строками и столбцами. Файлы неструктурированных данных часто содержат текстовый и мультимедийный контент. Примеры включают сообщения электронной почты, текстовые документы, видео, фотографии, аудиофайлы, презентации, веб-страницы и многие другие виды деловых документов. Обратите внимание: хотя файлы такого типа могут иметь внутреннюю структуру, они по-прежнему считаются «неструктурированными», поскольку содержащиеся в них данные не помещаются аккуратно в базу данных. По оценкам экспертов, от 80 до 90 процентов данных в любой организации неструктурированы. Причем объем неструктурированных данных на предприятиях растет значительно, зачастую во много раз быстрее, чем растут структурированные базы данных. « Большие данные могут включать как структурированные, так и неструктурированные данные, но, по оценкам IDC, 90 процентов больших данных — это неструктурированные данные». [16]
Основная проблема неструктурированных источников данных заключается в том, что нетехническим бизнес-пользователям и аналитикам данных их сложно распаковать, понять и подготовить к аналитическому использованию. Помимо вопросов структуры, существует огромный объем данных этого типа. По этой причине современные методы интеллектуального анализа данных часто упускают из виду ценную информацию и делают анализ неструктурированных данных трудоемким и дорогим. [17]
В сегодняшней конкурентной бизнес-среде компаниям приходится быстро находить и анализировать необходимые им данные. Задача состоит в том, чтобы обработать большие объемы данных и получить доступ к необходимому уровню детализации на высокой скорости. Проблема только возрастает по мере увеличения степени детализации. Одним из возможных решений является аппаратное обеспечение. Некоторые поставщики используют увеличенный объем памяти и параллельную обработку для быстрой обработки больших объемов данных. Другой метод — помещение данных в память , но с использованием подхода грид-вычислений , когда для решения проблемы используется множество машин. Оба подхода позволяют организациям исследовать огромные объемы данных. Даже при таком уровне сложности аппаратного и программного обеспечения лишь немногие задачи обработки изображений в больших масштабах занимают от нескольких дней до нескольких недель. [18] Отладка обработки данных чрезвычайно сложна из-за длительного времени выполнения.
Третий подход передовых решений для обнаружения данных сочетает в себе самостоятельную подготовку данных с визуальным обнаружением данных, что позволяет аналитикам одновременно готовить и визуализировать данные в среде интерактивного анализа, предлагаемой новыми компаниями Trifacta , Alteryx и другими. [19]
Другой метод отслеживания происхождения данных — это программы для работы с электронными таблицами, такие как Excel, которые предлагают пользователям происхождение на уровне ячеек или возможность видеть, какие ячейки зависят от других, но структура преобразования теряется. Аналогично, ETL или программное обеспечение для картографирования обеспечивают происхождение на уровне преобразования, однако это представление обычно не отображает данные и является слишком грубым, чтобы различать преобразования, которые являются логически независимыми (например, преобразования, которые работают с отдельными столбцами) и зависимыми. [20] Платформы больших данных имеют очень сложную структуру. Данные распределяются между несколькими машинами. Обычно задания распределяются по нескольким машинам, а результаты позже объединяются с помощью операций сокращения. Отладка конвейера больших данных становится очень сложной задачей из-за самой природы системы. Специалисту по данным будет непросто выяснить, данные какой машины имеют выбросы и неизвестные функции, из-за которых конкретный алгоритм дает неожиданные результаты.
Предлагаемое решение [ править ]
Происхождение данных или происхождение данных можно использовать для упрощения отладки конвейера больших данных . Это требует сбора данных о преобразованиях данных. В разделе ниже будет более подробно объяснено происхождение данных.
Происхождение данных [ править ]
Происхождение научных данных обеспечивает историческую запись данных и их происхождения. Происхождение данных, генерируемых в результате сложных преобразований, таких как рабочие процессы, имеет значительную ценность для ученых. [21] С его помощью можно определить качество данных на основе их исходных данных и выводов, отследить источники ошибок, разрешить автоматическое воспроизведение выводов для обновления данных и обеспечить атрибуцию источников данных. Провенанс также важен для бизнес-сферы, где его можно использовать для детализации источника данных в хранилище данных , отслеживания создания интеллектуальной собственности и обеспечения контрольного журнала для целей регулирования.
Использование источника данных предлагается в распределенных системах для отслеживания записей в потоке данных, воспроизведения потока данных на подмножестве его исходных входных данных и отладки потоков данных. Для этого необходимо отслеживать набор входных данных каждого оператора, которые использовались для получения каждого из его выходных данных. Хотя существует несколько форм происхождения, такие как копирование-провенанс и хау-провенанс. [14] [22] информация, которая нам нужна, представляет собой простую форму «почему-происхождение», или «происхождение» , как это определено Cui et al. [23]
Модель данных PROV
PROV — это рекомендация W3C 2013 года.
- Происхождение — это информация об объектах, действиях и людях, участвующих в создании части данных или предмета, которую можно использовать для формирования оценки ее качества, надежности или достоверности. Семейство документов PROV определяет модель, соответствующие сериализации и другие вспомогательные определения, обеспечивающие функциональный обмен информацией о происхождении в гетерогенных средах, таких как Интернет .
«ПРОВ-Обзор, Обзор семейства документов ПРОВ» [24]

- Происхождение определяется как запись, описывающая людей, учреждения, организации и действия, участвующие в производстве, влиянии или доставке части данных или вещи. В частности, происхождение информации имеет решающее значение для принятия решения о том, следует ли доверять информации, как ее следует интегрировать с другими разнообразными источниками информации и как отдавать должное ее создателям при ее повторном использовании. В открытой и инклюзивной среде, такой как Интернет, где пользователи находят информацию, которая часто противоречива или сомнительна, происхождение может помочь этим пользователям сделать выводы о доверии.
«PROV-DM: Модель данных PROV» [25]
Захват родословной [ править ]
Интуитивно понятно, что для оператора T, производящего выходной сигнал o, происхождение состоит из троек формы {I, T, o}, где I — это набор входных данных для T, используемых для получения o. Регистрация происхождения каждого оператора T в потоке данных позволяет пользователям задавать такие вопросы, как «Какие выходные данные были получены с помощью ввода i оператора T?» и «Какие входные данные дали результат o в операторе T?» [3] Запрос, который находит входные данные, генерирующие выходные данные, называется запросом обратной трассировки, а запрос, который находит выходные данные, полученные с помощью входных данных, называется запросом прямой трассировки . [26] Обратная трассировка полезна для отладки, а прямая трассировка полезна для отслеживания распространения ошибок. [26] Запросы трассировки также составляют основу для воспроизведения исходного потока данных. [12] [23] [26] Однако для эффективного использования происхождения в системе DISC нам необходимо иметь возможность фиксировать происхождение на нескольких уровнях (или детализации) операторов и данных, фиксировать точное происхождение для конструкций обработки DISC и иметь возможность эффективно отслеживать несколько этапов потока данных.
Система DISC состоит из нескольких уровней операторов и данных , и различные варианты использования происхождения могут определять уровень, на котором необходимо фиксировать происхождение. Происхождение можно фиксировать на уровне задания, используя файлы и предоставляя кортежи происхождения в форме {IF i, M RJob, OF i }, происхождение также можно фиксировать на уровне каждой задачи, используя записи и предоставляя, например, кортежи происхождения вида {(k rr, v rr), map, (km, vm )}. Первая форма родословной называется грубозернистой родословной, а вторая форма — мелкозернистой родословной. Интеграция происхождения с различной степенью детализации позволяет пользователям задавать такие вопросы, как «Какой файл, прочитанный заданием MapReduce, создал эту конкретную выходную запись?» и может быть полезен при отладке различных операторов и детализации данных в потоке данных. [3]

Чтобы отразить сквозное происхождение в системе DISC, мы используем модель Ibis, [27] который вводит понятие иерархии включения для операторов и данных. В частности, Ibis предполагает, что один оператор может содержаться внутри другого, и такая связь между двумя операторами называется включением оператора . «Сдерживание оператора подразумевает, что содержащийся (или дочерний) оператор выполняет часть логической операции содержащего (или родительского) оператора». [3] Например, задача MapReduce содержится в задании. Аналогичные отношения содержания существуют и для данных, называемые вложением данных. Включение данных подразумевает, что содержащиеся данные являются подмножеством содержащихся данных (надмножеством).

данных Предписывающая передачи линия
Концепция предписывающего происхождения данных объединяет логическую модель (сущность) того, как эти данные должны передаваться, с фактическим происхождением для этого экземпляра. [28]
Термины «происхождение данных» и «происхождение» обычно описывают последовательность шагов или процессов, через которые прошел набор данных, чтобы достичь своего текущего состояния. Однако анализ корреляций аудита или журналов для определения происхождения с криминалистической точки зрения в некоторых случаях управления данными невозможен. Например, без логической модели невозможно с уверенностью определить, был ли маршрут рабочего процесса с данными правильным и соответствующим требованиям.
Только объединив логическую модель с атомарными криминалистическими событиями, можно проверить правильность действий:
- Авторизованные копии, объединения или CTAS операции
- Сопоставление обработки с системами, в которых эти процессы выполняются.
- Специальная или установленная последовательность обработки
Многие сертифицированные отчеты о соответствии требуют подтверждения происхождения потока данных, а также данных о конечном состоянии для конкретного экземпляра. В подобных ситуациях любое отклонение от предписанного пути необходимо учитывать и потенциально устранять. [29] Это знаменует собой переход от простого «оглядывания назад» к структуре, которая лучше подходит для отслеживания рабочих процессов по соблюдению требований.
и Активная родословная ленивая
Отложенный сбор данных о происхождении обычно собирает только общую информацию о происхождении во время выполнения. Эти системы несут низкие накладные расходы на захват из-за небольшого количества отслеживаемых линий. Однако для ответа на запросы детальной трассировки они должны воспроизводить поток данных на всех (или большей части) входных данных и собирать подробную информацию о происхождении во время воспроизведения. Этот подход подходит для судебно-медицинских систем, где пользователь хочет отладить наблюдаемый неверный результат.
Системы активного сбора фиксируют всю историю потока данных во время выполнения. Тип происхождения, который они фиксируют, может быть крупнозернистым или мелкозернистым, но они не требуют каких-либо дополнительных вычислений в потоке данных после его выполнения. Активные системы детального сбора данных о происхождении требуют более высоких накладных расходов, чем системы ленивого сбора. Однако они позволяют выполнять сложное воспроизведение и отладку. [3]
Актеры [ править ]
Актер — это сущность, которая преобразует данные; это может быть вершина Dryad, отдельные операторы карты и сокращения, задание MapReduce или весь конвейер потока данных. Актеры действуют как черные ящики, а входные и выходные данные актера используются для фиксации происхождения в форме ассоциаций, где ассоциация представляет собой тройку {i, T, o}, которая связывает входные данные i с выходными данными o для актера. Т. Таким образом, инструментарий фиксирует происхождение в потоке данных по одному актеру за раз, разделяя его на набор ассоциаций для каждого актера. Разработчику системы необходимо собирать данные, которые актор читает (от других акторов), и данные, которые актор записывает (другим акторам). Например, разработчик может рассматривать Hadoop Job Tracker как действующее лицо, записывая набор файлов, считываемых и записываемых каждым заданием. [30]
Ассоциации [ править ]
Ассоциация — это комбинация входов, выходов и самой операции. Операция представлена в виде черного ящика, также известного как актер. Ассоциации описывают преобразования, которые применяются к данным. Ассоциации хранятся в таблицах ассоциаций. Каждый уникальный актер представлен своей собственной таблицей ассоциаций. Сама ассоциация выглядит как {i, T, o}, где i — это набор входных данных для актера T, а o — это набор выходных данных, полученных актером. Ассоциации являются основными единицами Data Lineage. Отдельные ассоциации позже объединяются вместе, чтобы построить всю историю преобразований, примененных к данным. [3]
Архитектура [ править ]
Системы больших данных масштабируются горизонтально, т.е. увеличивают емкость за счет добавления новых аппаратных или программных объектов в распределенную систему. Распределенная система действует как единое целое на логическом уровне, даже если она состоит из нескольких аппаратных и программных объектов. Система должна продолжать сохранять это свойство после горизонтального масштабирования. Важным преимуществом горизонтальной масштабируемости является то, что она может обеспечить возможность увеличения емкости «на лету». Самым большим плюсом является то, что горизонтальное масштабирование можно выполнить с помощью стандартного оборудования.
особенность горизонтального масштабирования систем больших данных При создании архитектуры хранилища данных следует учитывать . Это очень важно, поскольку само хранилище данных также должно иметь возможность масштабироваться параллельно с системой больших данных . Количество ассоциаций и объем памяти, необходимые для хранения родословной, будут увеличиваться с увеличением размера и емкости системы. Архитектура систем больших данных делает использование единого хранилища нецелесообразным и невозможным для масштабирования. Непосредственное решение этой проблемы — распространение самого хранилища Lineage. [3]
Наилучший сценарий — использовать локальное хранилище происхождения для каждой машины в сети распределенной системы. Это позволяет хранилищу Lineage также масштабироваться по горизонтали. В этой схеме происхождение преобразований данных, примененных к данным на конкретной машине, хранится в локальном хранилище происхождения этой конкретной машины. В хранилище происхождения обычно хранятся таблицы ассоциаций. Каждый актер представлен своей собственной таблицей ассоциаций. Строки представляют собой сами ассоциации, а столбцы представляют входные и выходные данные. Эта конструкция решает 2 проблемы. Это позволяет горизонтально масштабировать хранилище Lineage. Если бы использовалось единое централизованное хранилище данных, то эту информацию приходилось передавать по сети, что вызывало бы дополнительную задержку в сети. Задержек в сети также можно избежать за счет использования распределенного хранилища происхождения. [30]
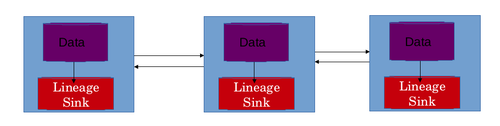
потока Реконструкция данных
Информацию, хранящуюся в виде ассоциаций, необходимо каким-то образом объединить, чтобы получить поток данных для конкретного задания. В распределенной системе работа разбивается на несколько задач. Один или несколько экземпляров запускают определенную задачу. Результаты, полученные на этих отдельных машинах, позже объединяются для завершения работы. Задачи, выполняемые на разных машинах, выполняют несколько преобразований данных на машине. Все преобразования, примененные к данным на машинах, хранятся в локальном хранилище происхождения этих машин. Эту информацию необходимо объединить, чтобы получить происхождение всей работы. Происхождение всего задания должно помочь специалисту по данным понять поток данных задания, и он/она сможет использовать поток данных для отладки конвейера больших данных . Поток данных реконструируется в 3 этапа.
Таблицы ассоциаций [ править ]
Первым этапом реконструкции потока данных является вычисление таблиц ассоциаций. Таблицы ассоциаций существуют для каждого актера в каждом локальном хранилище происхождения. Вся таблица ассоциаций для актера может быть вычислена путем объединения этих отдельных таблиц ассоциаций. Обычно это делается с использованием серии соединений равенства, основанных на самих актерах. В некоторых сценариях таблицы также могут быть объединены с использованием входных данных в качестве ключа. Индексы также можно использовать для повышения эффективности соединения. Объединенные таблицы необходимо хранить на одном экземпляре или на машине для дальнейшего продолжения обработки. Существует несколько схем, которые используются для выбора машины, на которой будет вычисляться соединение. Самый простой вариант — с минимальной загрузкой процессора. При выборе экземпляра, в котором будет происходить объединение, также следует учитывать ограничения по пространству.
Граф ассоциаций [ править ]
Вторым шагом реконструкции потока данных является вычисление графа связей на основе информации о происхождении. На графике представлены этапы потока данных. Актеры действуют как вершины, а ассоциации — как ребра. Каждый актер T связан со своими вышестоящими и нижестоящими актерами в потоке данных. Вышестоящий актор T — это тот, который произвел входные данные T, тогда как нижестоящий актор — это тот, который потребляет выходные данные T. Включающие отношения всегда учитываются при создании связей. Граф состоит из трех типов связей или ребер.
Явно указанные ссылки [ править ]
Самая простая ссылка — это явно указанная связь между двумя актерами. Эти ссылки явно указаны в коде алгоритма машинного обучения. Когда актер знает точного вышестоящего или нижестоящего актера, он может передать эту информацию API-интерфейсу Lineage. Эта информация позже используется для связи этих субъектов во время запроса отслеживания. Например, в архитектуре MapReduce каждый экземпляр карты знает точный экземпляр устройства чтения записей, выходные данные которого он использует. [3]
Логически выведенные ссылки [ править ]
Разработчики могут прикреплять архетипы потока данных к каждому логическому субъекту. Архетип потока данных объясняет, как дочерние типы типа актера располагаются в потоке данных. С помощью этой информации можно сделать вывод о связи между каждым действующим лицом исходного типа и целевого типа. Например, в архитектуре MapReduce тип актера карты является источником сокращения, и наоборот. Система определяет это на основе архетипов потока данных и должным образом связывает экземпляры карты с экземплярами сокращения. может быть несколько заданий MapReduce Однако в потоке данных , и связывание всех экземпляров карты со всеми экземплярами сокращения может привести к созданию ложных связей. Чтобы предотвратить это, такие ссылки ограничиваются экземплярами актеров, содержащимися в общем экземпляре актора содержащего (или родительского) типа актора. Таким образом, экземпляры карты и сокращения связаны друг с другом только в том случае, если они принадлежат к одному и тому же заданию. [3]
Неявные связи посредством совместного использования наборов данных [ править ]
В распределенных системах иногда встречаются неявные ссылки, которые не указываются при выполнении. Например, существует неявная связь между актером, который записывал в файл, и другим актером, который читал из него. Такие ссылки соединяют участников, которые используют для выполнения общий набор данных. Набор данных — это выходные данные первого актера и входные данные следующего за ним актера. [3]
Топологическая сортировка [ править ]
Последним шагом реконструкции потока данных является топологическая сортировка графа связей. Ориентированный граф, созданный на предыдущем шаге, топологически сортируется, чтобы получить порядок, в котором субъекты изменяли данные. Этот порядок наследования актеров определяет поток данных конвейера или задачи больших данных.
Отслеживание и воспроизведение [ править ]
Это наиболее важный шаг в отладке больших данных . Захваченное происхождение объединяется и обрабатывается для получения потока данных конвейера. Поток данных помогает специалисту по данным или разработчику глубже изучить действующих лиц и их преобразования. Этот шаг позволяет специалисту по данным выяснить ту часть алгоритма, которая генерирует неожиданный результат. Конвейер больших данных может пойти не так по двум основным причинам. Во-первых, это присутствие подозрительного субъекта в потоке данных. Во-вторых, наличие выбросов в данных.
Первый случай можно отладить, отслеживая поток данных. Используя вместе информацию о происхождении и потоке данных, специалист по данным может выяснить, как входные данные преобразуются в выходные данные. В ходе процесса могут быть пойманы лица, ведущие себя неожиданно. Либо эти субъекты могут быть удалены из потока данных, либо к ним могут быть добавлены новые субъекты для изменения потока данных. Улучшенный поток данных можно воспроизвести, чтобы проверить его достоверность. Отладка неисправных актеров включает в себя рекурсивное выполнение грубого воспроизведения актеров в потоке данных. [31] что может быть дорогостоящим в ресурсах для длинных потоков данных. Другой подход — вручную проверять журналы происхождения на предмет аномалий. [13] [32] что может быть утомительным и трудоемким на нескольких этапах потока данных. Более того, эти подходы работают только тогда, когда специалист по данным может обнаружить неверные результаты. Чтобы отладить аналитику без известных плохих результатов, специалисту по данным необходимо проанализировать поток данных на предмет подозрительного поведения в целом. Однако часто пользователь может не знать ожидаемого нормального поведения и не может указать предикаты. В этом разделе описывается методология отладки ретроспективного анализа происхождения для выявления ошибочных участников в многоэтапном потоке данных. Мы считаем, что внезапные изменения в поведении субъекта, такие как его средняя избирательность, скорость обработки или размер выходных данных, характерны для аномалии. Происхождение может отражать такие изменения в поведении актеров с течением времени и в разных экземплярах актеров. Таким образом, анализ происхождения для выявления таких изменений может быть полезен при отладке ошибочных участников в потоке данных.
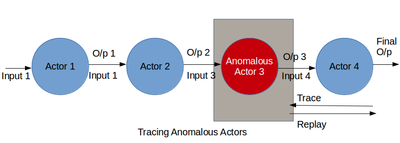
Вторую проблему, т. е. наличие выбросов, также можно выявить путем пошагового выполнения потока данных и просмотра преобразованных выходных данных. Специалист по данным находит подмножество выходных данных, которые не соответствуют остальным выходным данным. Входные данные, которые вызывают эти плохие выходные данные, являются выбросами в данных. Эту проблему можно решить, удалив набор выбросов из данных и воспроизведя весь поток данных. Эту проблему также можно решить, изменив алгоритм машинного обучения путем добавления, удаления или перемещения участников в потоке данных. Изменения в потоке данных считаются успешными, если воспроизводимый поток данных не дает плохих результатов.

Проблемы [ править ]
Несмотря на то, что использование подходов, основанных на происхождении данных, является новым способом отладки конвейеров больших данных , этот процесс непрост. Проблемы включают в себя масштабируемость хранилища родословных, отказоустойчивость хранилища родословных, точный сбор родословных для операторов «черного ящика» и многие другие. Эти проблемы необходимо тщательно рассмотреть и оценить компромиссы между ними, чтобы разработать реалистичную схему сбора данных о происхождении.
Масштабируемость [ править ]
Системы DISC — это, прежде всего, системы пакетной обработки, рассчитанные на высокую производительность. Они выполняют несколько заданий для каждой аналитики, по несколько задач на задание. Общее количество операторов, выполняющихся в кластере в любой момент времени, может варьироваться от сотен до тысяч в зависимости от размера кластера. Захват родословной дляэти системы должны быть способны масштабироваться как для больших объемов данных, так и для большого количества операторов, чтобы не стать узким местом для аналитики DISC.
Отказоустойчивость [ править ]
Системы сбора данных о происхождении также должны быть отказоустойчивыми, чтобы избежать повторного запуска потоков данных для сбора данных о происхождении. В то же время они также должны учитывать сбои в системе DISC. Для этого они должны иметь возможность идентифицировать неудавшуюся задачу DISC и избегать хранения дубликатов родословной между частичной родословной, созданной невыполненной задачей, и дубликатом родословной, созданной перезапущенной задачей. Система происхождения также должна быть в состоянии корректно обрабатывать многочисленные случаи выхода из строя локальных систем происхождения. Этого можно достичь путем хранения копий ассоциаций родословной на нескольких машинах. Реплика может действовать как резервная копия в случае потери реальной копии.
Операторы черного ящика [ править ]
Системы происхождения для потоков данных DISC должны иметь возможность точно фиксировать происхождение операторов черного ящика, чтобы обеспечить детальную отладку. Текущие подходы к этому включают Prober, который пытается найти минимальный набор входных данных, который может дать указанный результат для оператора черного ящика, путем многократного воспроизведения потока данных для получения минимального набора. [33] и динамическая нарезка, используемая Zhang et al. [34] для определения происхождения операторов NoSQL посредством двоичной перезаписи для вычисления динамических срезов. Несмотря на то, что такие методы обеспечивают очень точную линию происхождения, они могут потребовать значительных затрат времени на захват или отслеживание, и вместо этого может быть предпочтительнее пожертвовать некоторой точностью ради лучшей производительности. Таким образом, существует потребность в системе сбора данных о происхождении для потоков данных DISC, которая могла бы фиксировать происхождение от произвольных операторов с разумной точностью и без значительных затрат на сбор или отслеживание.
Эффективное отслеживание [ править ]
Трассировка необходима для отладки, во время которой пользователь может выполнить несколько запросов трассировки. Таким образом, важно, чтобы отслеживание осуществлялось в кратчайшие сроки. Икеда и др. [26] может выполнять эффективные запросы обратной трассировки для потоков данных MapReduce, но не является общим для разных систем DISC и не выполняет эффективные прямые запросы. Помада, [35] система родословной для Свиньи, [36] хотя он способен выполнять как обратную, так и прямую трассировку, он специфичен для операторов Pig и SQL и может выполнять только грубую трассировку для операторов черного ящика. Таким образом, существует потребность в системе происхождения, которая обеспечивает эффективную прямую и обратную трассировку для общих систем DISC и потоков данных с операторами черного ящика.
Сложный повтор [ править ]
Воспроизведение только определенных входных данных или частей потока данных имеет решающее значение для эффективной отладки и моделирования сценариев «что, если». Икеда и др. представить методологию обновления на основе происхождения, которая выборочно воспроизводит обновленные входные данные для повторного расчета затронутых выходных данных. [37] Это полезно во время отладки для повторного вычисления выходных данных, когда были исправлены неправильные входные данные. Однако иногда пользователю может потребоваться удалить неверные входные данные и воспроизвести происхождение выходных данных, ранее затронутых ошибкой, для получения безошибочных выходных данных. Мы называем это эксклюзивным повтором. Другое использование воспроизведения при отладке предполагает воспроизведение неверных входных данных для пошаговой отладки (так называемое выборочное воспроизведение). Современные подходы к использованию происхождения в системах DISC не решают этих проблем. Таким образом, существует потребность в системе происхождения, которая может выполнять как эксклюзивные, так и выборочные повторы для удовлетворения различных потребностей отладки.
Обнаружение аномалий [ править ]
Одной из основных задач отладки систем DISC является выявление ошибочных операторов. В длинных потоках данных с несколькими сотнями операторов или задач проверка вручную может быть утомительной и непомерно трудной. Даже если происхождение используется для сужения подмножества проверяемых операторов, происхождение одного результата все равно может охватывать несколько операторов. Существует потребность в недорогой автоматизированной системе отладки, которая могла бы существенно сузить набор потенциально неисправных операторов с достаточной точностью, чтобы минимизировать объем требуемой ручной проверки.
См. также [ править ]
Ссылки [ править ]
- ^ «Что такое происхождение данных? - Определение из Techopedia» .
- ^ Хоанг, Натали (16 марта 2017 г.). «Происхождение данных помогает повысить ценность бизнеса — Trifacta» . Трифакта . Проверено 20 сентября 2017 г.
- ^ Jump up to: Перейти обратно: а б с д и ж г час я дж к Де, Сумьярупа. (2012). Newt: архитектура для воспроизведения и отладки на основе происхождения в системах DISC. Калифорнийский университет в Сан-Диего: b7355202. Получено с: https://escholarship.org/uc/item/3170p7zn.
- ^ Дрори, Аманон (18 мая 2020 г.). «Что такое линия передачи данных? - Октопай» . Октопай . Проверено 25 августа 2020 г.
- ^ Джеффри Дин и Санджай Гемават. Mapreduce: упрощенная обработка данных на больших кластерах. Коммун. ACM, 51(1):107–113, январь 2008 г.
- ^ Майкл Айсард, Михай Будиу, Юань Ю, Эндрю Биррелл и Деннис Феттерли. Дриада: распределенные программы с параллельными данными из последовательных строительных блоков. В материалах 2-й Европейской конференции ACM SIGOPS/EuroSys по компьютерным системам, 2007 г., EuroSys '07, стр. 59–72, Нью-Йорк, Нью-Йорк, США, 2007 г. ACM.
- ^ Apache Hadoop. http://hadoop.apache.org .
- ^ Гжегож Малевич, Мэтью Х. Остерн, Аарт Дж. К. Бик, Джеймс К. Денерт, Илан Хорн, Нати Лейзер и Гжегож Чайковски. Pregel: система для крупномасштабной обработки графов. В материалах международной конференции по управлению данными 2010 г., SIGMOD '10, страницы 135–146, Нью-Йорк, штат Нью-Йорк, США, 2010. ACM.
- ^ Шимин Чен и Стивен В. Шлоссер. Map-reduce подходит для более широкого спектра приложений. Технический отчет, Intel Research, 2008 г.
- ^ Поток данных в области геномики. https://www-304.ibm.com/connections/blogs/ibmhealthcare/entry/перегрузка данных в genomics3?lang=de, 2010.
- ^ Йогеш Л. Симхан, Бет Плейл и Деннис Гэннон. Обзор данных, подтверждающихфинансы в электронной науке. SIGMOD Rec., 34(3):31–36, сентябрь 2005 г.
- ^ Jump up to: Перейти обратно: а б Ян Фостер, Йенс Воклер, Майкл Уайльд и Юн Чжао. Химера: виртуальная система данных для представления, запроса и автоматизации получения данных. На 14-й Международной конференции по управлению научными и статистическими базами данных, июль 2002 г.
- ^ Jump up to: Перейти обратно: а б Бенджамин Х. Сигельман, Луис Андре Баррозу, Майк Берроуз, Пэт Стивенсон, Манодж Плакал, Дональд Бивер, Сол Джаспан и Чандан Шанбхаг. Dapper — крупномасштабная инфраструктура отслеживания распределенных систем. Технический отчет Google Inc, 2010 г.
- ^ Jump up to: Перейти обратно: а б Питер Бунеман , Санджив Кханна и Ван-Чью Тан . Происхождение данных: некоторые основные вопросы. В материалах 20-й конференции по основам программных технологий и теоретической информатики, FST TCS 2000, страницы 87–93, Лондон, Великобритания, Великобритания, 2000. Springer-Verlag.
- ^ «Новое исследование цифровой вселенной выявило большой пробел в данных. Менее 1 из мировых данных анализируется, менее 20 защищены» .
- ^ Вебопедия
- ^ Шефер, Пейдж (24 августа 2016 г.). «Различия между структурированными и неструктурированными данными» . Трифакта . Проверено 20 сентября 2017 г.
- ^ САС. http://www.sas.com/resources/asset/five-big-data-challenges-article.pdf. Архивировано 20 декабря 2014 г. в Wayback Machine.
- ^ «5 требований к эффективной подготовке данных самообслуживания» . www.itbusinessedge.com . 18 февраля 2016 года . Проверено 20 сентября 2017 г.
- ^ Кандел, Шон (4 ноября 2016 г.). «Отслеживание происхождения данных в финансовых услугах — Trifacta» . Трифакта . Проверено 20 сентября 2017 г.
- ^ Паскье, Томас; Лау, Мэтью К.; Трисович, Ана; Буз, Эмери Р.; Кутюрье, Бен; Кросас, Мерсе; Эллисон, Аарон М.; Гибсон, Валери; Джонс, Крис Р.; Зельцер, Марго (5 сентября 2017 г.). «Если бы эти данные могли говорить» . Научные данные . 4 : 170114. Бибкод : 2017NatSD...470114P . дои : 10.1038/sdata.2017.114 . ПМЦ 5584398 . ПМИД 28872630 .
- ^ Роберт Икеда и Дженнифер Видом. Происхождение данных: опрос. Технический отчет, Стэнфордский университет, 2009 г.
- ^ Jump up to: Перейти обратно: а б Ю. Цюй и Ж. Видом. Отслеживание происхождения для общих преобразований хранилища данных. Журнал ВЛДБ, 12 (1), 2003.
- ^ «ПРОВ-Обзор» .
- ^ «PROV-DM: Модель данных PROV» .
- ^ Jump up to: Перейти обратно: а б с д Роберт Икеда, Хёнджон Пак и Дженнифер Уидом. Провенанс для обобщенной карты и сокращения рабочих процессов. В Proc. CIDR, январь 2011 г.
- ^ К. Олстон и А. Дас Сарма. Ibis: Менеджер по происхождению для многоуровневых систем. В Proc. CIDR, январь 2011 г.
- ^ «Архивная копия» (PDF) . Архивировано из оригинала (PDF) 5 сентября 2015 г. Проверено 2 сентября 2015 г.
{{cite web}}: CS1 maint: архивная копия в заголовке ( ссылка ) - ^ Руководство по соблюдению требований SEC для малых предприятий
- ^ Jump up to: Перейти обратно: а б Дионисий Логотетис, Сумьярупа Де и Кеннет Йокум. 2013. Масштабируемый сбор данных для отладки аналитики DISC. В материалах 4-го ежегодного симпозиума по облачным вычислениям (SOCC '13). ACM, Нью-Йорк, Нью-Йорк, США, Статья 17, 15 страниц.
- ^ Чжоу, Вэньчао; Фей, Цюн; Нараян, Арджун; Хеберлен, Андреас; Тау Лу, Бун ; Шерр, Мика (декабрь 2011 г.). Безопасное сетевое происхождение . Материалы 23-го симпозиума ACM по принципам операционной системы (SOSP).
- ^ Фонсека, Родриго; Портер, Джордж; Кац, Рэнди Х.; Шенкер, Скотт; Стойка, Ион (2007). X-trace: всеобъемлющая система отслеживания сети . Материалы НСДИ'07.
- ^ Аниш Дас Сарма, Альпа Джайн и Филип Боханнон. PROBER: Специальная отладка конвейеров извлечения и интеграции. Технический отчет, Yahoo, апрель 2010 г.
- ^ Минву Чжан, Сянью Чжан, Сян Чжан и Сунил Прабхакар. Отслеживание происхождения за пределами реляционных операторов. В Proc. Конференция по очень большим базам данных (VLDB), сентябрь 2007 г.
- ^ Яэль Амстердамер, Сьюзен Б. Дэвидсон, Дэниел Дойч, Това Майло и Джулия Стоянович. Накрасить свинью помадой: обеспечение происхождения рабочего процесса в стиле базы данных. В Proc. ВЛДБ, август 2011 г.
- ^ Кристофер Олстон, Бенджамин Рид, Уткарш Шривастава, Рави Кумар и Эндрю Томкинс. Свиная латынь: не такой уж иностранный язык для обработки данных. В Proc. ACM SIGMOD, Ванкувер, Канада, июнь 2008 г.
- ^ Роберт Икеда, Семих Салихоглу и Дженнифер Видом. Обновление на основе происхождения в рабочих процессах, ориентированных на данные. В материалах 20-й международной конференции ACM по управлению информацией и знаниями, CIKM '11, страницы 1659–1668, Нью-Йорк, штат Нью-Йорк, США, 2011. ACM.