Обнаружение цикла
Эта статья может быть слишком технической для понимания большинства читателей . ( февраль 2018 г. ) |
В информатике обнаружение цикла или поиск цикла — это алгоритмическая проблема поиска цикла в повторяющихся последовательности значений функции .
Для любой функции f , которая отображает конечное множество S в себя, и любого начального значения x 0 в S , последовательность повторяемых значений функции

в конечном итоге должен использовать одно и то же значение дважды: должна существовать некоторая пара различных индексов i и j, такая что x i = x j . Как только это произойдет, последовательность должна периодически продолжаться , повторяя одну и ту же последовательность значений от x i до x j − 1 . Обнаружение цикла — это проблема поиска i и j по заданным f и x 0 .
Известно несколько алгоритмов для быстрого поиска циклов и с небольшим объемом памяти. Алгоритм Роберта Флойда « черепаха и заяц» перемещает два указателя с разной скоростью через последовательность значений, пока они оба не укажут на равные значения. Альтернативно, алгоритм Брента основан на идее экспоненциального поиска . Алгоритмы Флойда и Брента используют только постоянное количество ячеек памяти и принимают количество оценок функции, пропорциональное расстоянию от начала последовательности до первого повторения. Некоторые другие алгоритмы используют больший объем памяти для меньшего количества вычислений функций.
Приложения обнаружения циклов включают проверку качества генераторов псевдослучайных чисел и криптографических хеш-функций , алгоритмов вычислительной теории чисел , обнаружение бесконечных циклов в компьютерных программах и периодических конфигураций в клеточных автоматах , автоматический анализ формы структур данных связанного списка и обнаружение тупиков. для управления транзакциями в СУБД .
Пример
[ редактировать ]
На рисунке показана функция f , которая отображает множество S = {0,1,2,3,4,5,6,7,8} в себя. Если начать с x 0 = 2 и неоднократно применять f , можно увидеть последовательность значений
- 2, 0, 6, 3, 1, 6, 3, 1, 6, 3, 1, ....
Цикл в этой последовательности значений равен 6, 3, 1 .
Определения
[ редактировать ]Пусть S — любое конечное множество, f — любая функция из S в себя и x0 — элемент S. любой Для любого я > 0 пусть Икс я знак равно ж ( Икс я - 1 ) . Пусть µ будет наименьшим индексом, таким образом, что значение x µ появляется бесконечно часто в последовательности значений x i , и пусть λ (длина цикла) будет наименьшим положительным целым числом таким, что x µ = x λ + µ . Проблема обнаружения цикла — это задача нахождения λ и µ . [1]
Эту же проблему можно рассматривать с точки зрения теории графов , построив функциональный граф (то есть ориентированный граф , в котором каждая вершина имеет одно выходящее ребро), вершины которого являются элементами S , а ребра которого отображают элемент в соответствующее значение функции, как показано на рисунке. Набор вершин, достижимых из начальной вершины x 0, образует подграф, форма которого напоминает греческую букву ро ( ρ ): путь длины μ от x 0 до цикла из λ вершин. [2]
Компьютерное представление
[ редактировать ]Обычно f не указывается в виде таблицы значений, как показано на рисунке выше. Скорее, алгоритму обнаружения цикла может быть предоставлен доступ либо к последовательности значений x i , либо к подпрограмме для вычисления f . Задача состоит в том, чтобы найти λ и μ, исследуя как можно меньше значений последовательности или выполняя как можно меньше вызовов подпрограмм. Обычно также пространственная сложность важна алгоритма для задачи обнаружения цикла: мы хотим решить проблему, используя объем памяти, значительно меньший, чем потребовалось бы для хранения всей последовательности.
В некоторых приложениях, в частности в алгоритме Полларда для факторизации целых чисел , алгоритм имеет гораздо более ограниченный доступ к S и f . Например, в ро-алгоритме Полларда S даже размер S. представляет собой набор целых чисел по модулю неизвестного простого множителя числа, подлежащего факторизации, поэтому алгоритму неизвестен Чтобы алгоритмы обнаружения циклов можно было использовать при таких ограниченных знаниях, они могут быть разработаны на основе следующих возможностей. Первоначально предполагается, что алгоритм имеет в памяти объект, представляющий указатель на начальное значение x 0 . На любом этапе он может выполнить одно из трех действий: он может скопировать любой имеющийся у него указатель на другой объект в памяти, он может применить f и заменить любой из своих указателей указателем на следующий объект в последовательности или он может применить подпрограмма для определения того, представляют ли два ее указателя равные значения в последовательности. Действие проверки на равенство может включать в себя некоторые нетривиальные вычисления: например, в алгоритме Ро Полларда оно реализуется путем проверки того, имеет ли разница между двумя сохраненными значениями нетривиальную величину. наибольший общий делитель с числом, которое нужно факторизовать. [2] В этом контексте, по аналогии с моделью вычислений на указательной машине , алгоритм, который использует только копирование указателей, продвижение внутри последовательности и тесты на равенство, можно назвать алгоритмом указателей.
Алгоритмы
[ редактировать ]Если входные данные заданы в виде подпрограммы для вычисления f , проблема обнаружения цикла может быть решена тривиально, используя только приложения с функциями λ + µ , просто вычислив последовательность значений x i и используя структуру данных , такую как хеш-таблица, для хранения этих значений. значения и проверьте, было ли уже сохранено каждое последующее значение. Однако пространственная сложность этого алгоритма пропорциональна λ + µ , что неоправданно велико. Кроме того, для реализации этого метода в качестве алгоритма указателя потребуется применить тест на равенство к каждой паре значений, что приведет к квадратичному общему времени. Таким образом, исследования в этой области сконцентрировались на двух целях: использовать меньше места, чем этот наивный алгоритм, и найти алгоритмы указателей, которые используют меньше тестов на равенство.
Черепаха и заяц Флойда
[ редактировать ]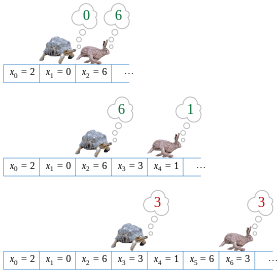
Алгоритм поиска цикла Флойда — это алгоритм указателей, который использует только два указателя, которые перемещаются по последовательности с разной скоростью. Его также называют «алгоритмом черепахи и зайца», отсылая к басне Эзопа « Черепаха и заяц» .
Алгоритм назван в честь Роберта Флойда , которому приписывают его изобретение Дональд Кнут . [3] [4] Однако алгоритм не фигурирует в опубликованной работе Флойда, и это может быть ошибочной атрибуцией: Флойд описывает алгоритмы составления списка всех простых циклов в ориентированном графе в статье 1967 года: [5] но в этой статье не описывается проблема поиска циклов в функциональных графах, которая является предметом этой статьи. Фактически, утверждение Кнута (в 1969 году), приписывающее его Флойду, без цитирования, является первым известным появлением в печати, и, таким образом, это может быть народной теоремой , не приписываемой отдельному человеку. [6]
Суть алгоритма заключается в следующем. Если цикл существует, то для любых целых чисел i ≥ µ и k ≥ 0 , x i = x i + kλ , где λ — длина искомого цикла, µ — номер первого элемента цикла. , а k — целое число, обозначающее количество циклов. На основании этого можно затем показать, что i = kλ ≥ µ для некоторого k тогда и только тогда, когда x i = x 2 i (если x i = x 2 i в цикле, то существует такой k , что 2 i = i + kλ , откуда следует, что i = kλ , и если существуют некоторые i и k такие, что i = kλ , то 2i = i + kλ и x 2 i = x i + kλ ). Таким образом, алгоритму нужно только проверять наличие повторяющихся значений этой специальной формы, одно из которых находится в два раза дальше от начала последовательности, чем другое, чтобы найти период ν повторения, кратный λ . Как только ν найдено, алгоритм прослеживает последовательность от ее начала, чтобы найти первое повторяющееся значение x µ в последовательности, используя тот факт, что λ делит ν и, следовательно, x µ = x µ + v . Наконец, как только значение µ известно, найти длину тривиально. λ кратчайшего повторяющегося цикла, путем поиска первой позиции µ + λ , для которой x µ + λ = x µ .
Таким образом, алгоритм поддерживает два указателя на данную последовательность: один (черепаха) в точке xi , а другой (заяц) в точке x 2 i . На каждом шаге алгоритма он увеличивает i на единицу, перемещая черепаху на один шаг вперед, а зайца на два шага вперед в последовательности, а затем сравнивает значения последовательности по этим двум указателям. Наименьшее значение i > 0 , при котором черепаха и заяц указывают на равные значения, является искомым значением ν .
Следующий код Python показывает, как эту идею можно реализовать в виде алгоритма.
def floyd(f, x0) -> (int, int):
"""Floyd's cycle detection algorithm."""
# Main phase of algorithm: finding a repetition x_i = x_2i.
# The hare moves twice as quickly as the tortoise and
# the distance between them increases by 1 at each step.
# Eventually they will both be inside the cycle and then,
# at some point, the distance between them will be
# divisible by the period λ.
tortoise = f(x0) # f(x0) is the element/node next to x0.
hare = f(f(x0))
while tortoise != hare:
tortoise = f(tortoise)
hare = f(f(hare))
# At this point the tortoise position, ν, which is also equal
# to the distance between hare and tortoise, is divisible by
# the period λ. So hare moving in cycle one step at a time,
# and tortoise (reset to x0) moving towards the cycle, will
# intersect at the beginning of the cycle. Because the
# distance between them is constant at 2ν, a multiple of λ,
# they will agree as soon as the tortoise reaches index μ.
# Find the position μ of first repetition.
mu = 0
tortoise = x0
while tortoise != hare:
tortoise = f(tortoise)
hare = f(hare) # Hare and tortoise move at same speed
mu += 1
# Find the length of the shortest cycle starting from x_μ
# The hare moves one step at a time while tortoise is still.
# lam is incremented until λ is found.
lam = 1
hare = f(tortoise)
while tortoise != hare:
hare = f(hare)
lam += 1
return lam, mu
Этот код получает доступ к последовательности только путем сохранения и копирования указателей, оценок функций и проверок на равенство; следовательно, он квалифицируется как алгоритм указателя. Алгоритм использует O ( λ + µ ) операций этих типов и O (1) дискового пространства. [7]
Алгоритм Брента
[ редактировать ]Ричард П. Брент описал альтернативный алгоритм обнаружения цикла, который, как и алгоритм черепахи и зайца, требует только двух указателей в последовательности. [8] Однако он основан на другом принципе: поиск наименьшей степени двух 2 я это больше, чем λ и µ . Для i = 0, 1, 2,... алгоритм сравнивает x 2 я −1 с каждым последующим значением последовательности до следующей степени двойки, останавливаясь, когда находит совпадение. Он имеет два преимущества по сравнению с алгоритмом черепахи и зайца: он находит правильную длину λ цикла напрямую, вместо необходимости искать ее на следующем этапе, и его шаги включают только одно вычисление функции f, а не три. [9]
Следующий код Python более подробно показывает, как работает этот метод.
def brent(f, x0) -> (int, int):
"""Brent's cycle detection algorithm."""
# main phase: search successive powers of two
power = lam = 1
tortoise = x0
hare = f(x0) # f(x0) is the element/node next to x0.
while tortoise != hare:
if power == lam: # time to start a new power of two?
tortoise = hare
power *= 2
lam = 0
hare = f(hare)
lam += 1
# Find the position of the first repetition of length λ
tortoise = hare = x0
for i in range(lam):
# range(lam) produces a list with the values 0, 1, ... , lam-1
hare = f(hare)
# The distance between the hare and tortoise is now λ.
# Next, the hare and tortoise move at same speed until they agree
mu = 0
while tortoise != hare:
tortoise = f(tortoise)
hare = f(hare)
mu += 1
return lam, mu
Как и алгоритм черепахи и зайца, это алгоритм указателя, который использует O ( λ + μ ) тестов и оценок функций и O (1) пространства для хранения. Нетрудно показать, что число вычислений функции никогда не может быть больше, чем для алгоритма Флойда. Брент утверждает, что в среднем его алгоритм поиска циклов работает примерно на 36% быстрее, чем алгоритм Флойда, и что он ускоряет ро-алгоритм Полларда примерно на 24%. Он также выполняет анализ среднего случая для рандомизированной версии алгоритма, в которой последовательность индексов, отслеживаемая более медленным из двух указателей, представляет собой не сами степени двойки, а скорее рандомизированное кратное степеням двойки. Хотя его основным предполагаемым применением были алгоритмы факторизации целых чисел, Брент также обсуждает приложения для тестирования генераторов псевдослучайных чисел. [8]
Алгоритм Госпера
[ редактировать ]Р.В. Госпера Алгоритм [10] [11] находит период , а также нижняя и верхняя границы начальной точки, и , первого цикла. Разница между нижней и верхней границей того же порядка, что и период, т.е. .




Преимущества
[ редактировать ]Основная особенность алгоритма Госпера заключается в том, что он никогда не делает резервного копирования для повторной оценки функции генератора и экономичен как по пространству, так и по времени. Его можно грубо описать как параллельную версию алгоритма Брента. В то время как алгоритм Брента постепенно увеличивает разрыв между черепахой и зайцем, алгоритм Госпера использует несколько черепах (несколько предыдущих значений сохраняются), которые расположены примерно по экспоненте. Согласно примечанию в пункте 132 HAKMEM, [11] этот алгоритм обнаружит повторение до третьего появления любого значения, т. е. цикл будет повторяться не более двух раз. В этом примечании также указано, что достаточно хранить предыдущие значения; однако предоставленная реализация [10] магазины ценности. Например, предположим, что значения функции представляют собой 32-битные целые числа, а вторая итерация цикла заканчивается не более чем через 2 32 оценки функций с самого начала (т. ). Тогда алгоритм Госпера найдет цикл после не более чем 2 32 оценки функций, занимая при этом пространство из 33 значений (каждое значение представляет собой 32-битное целое число).



Сложность
[ редактировать ]После -й оценки функции генератора, алгоритм сравнивает сгенерированное значение с предыдущие значения; заметить, что поднимается по крайней мере до и самое большее . Следовательно, временная сложность этого алгоритма равна . Поскольку он хранит значения, его пространственная сложность равна . Это происходит при обычном предположении, присутствующем в этой статье, что размер значений функции постоянен. Без этого предположения пространственная сложность равна поскольку нам нужно как минимум отдельные значения, и, следовательно, размер каждого значения равен .







Компромиссы время-пространство
[ редактировать ]Ряд авторов изучали методы обнаружения циклов, которые используют больше памяти, чем методы Флойда и Брента, но обнаруживают циклы быстрее. Обычно эти методы хранят несколько ранее вычисленных значений последовательности и проверяют, соответствует ли каждое новое значение одному из ранее вычисленных значений. Чтобы сделать это быстро, они обычно используют хеш-таблицу или аналогичную структуру данных для хранения ранее вычисленных значений и, следовательно, не являются указательными алгоритмами: в частности, их обычно нельзя применять к ро-алгоритму Полларда. Отличие этих методов заключается в том, как они определяют, какие значения хранить. Вслед за Нивашем [12] мы кратко рассмотрим эти методы.
- Брент [8] уже описывает варианты своего метода, в которых индексы сохраненных значений последовательности являются степенями числа R, отличного от двух. Выбирая R как число, близкое к единице, и сохраняя значения последовательности в индексах, которые находятся рядом с последовательностью последовательных степеней R , алгоритм обнаружения цикла может использовать количество оценок функции, которое находится в пределах сколь угодно малого коэффициента оптимального. λ + мкм . [13] [14]
- Седжвик, Шимански и Яо [15] предоставить метод, который использует M ячеек памяти и требует только в худшем случае оценки функций для некоторой константы c , которая, как они показывают, является оптимальной. Этот метод включает в себя сохранение числового параметра d , сохранение в таблице только тех позиций в последовательности, которые кратны d , а также очистку таблицы и удвоение d всякий раз, когда было сохранено слишком много значений.
- Несколько авторов описали выдающиеся точечные методы, которые сохраняют значения функций в таблице на основе критерия, включающего значения, а не (как в методе Седжвика и др.) На основе их позиций. Например, значения, равные нулю по модулю некоторого значения d . могут храниться [16] [17] Проще говоря, Ниваш [12] благодарит Д. П. Вудраффа за предложение хранить случайную выборку ранее увиденных значений, делая соответствующий случайный выбор на каждом этапе, чтобы выборка оставалась случайной.
- Ниваш [12] описывает алгоритм, который не использует фиксированный объем памяти, но для которого ожидаемый объем используемой памяти (при условии, что входная функция случайна) является логарифмическим по длине последовательности. С помощью этого метода элемент сохраняется в таблице памяти, если ни один из последующих элементов не имеет меньшего значения. Как показывает Ниваш, элементы с помощью этого метода можно поддерживать с использованием структуры данных стека , и каждое последующее значение последовательности необходимо сравнивать только с вершиной стека. Алгоритм завершает работу, когда найден повторяющийся элемент последовательности с наименьшим значением. Запуск одного и того же алгоритма с несколькими стеками, используя случайные перестановки значений для изменения порядка значений в каждом стеке, позволяет найти компромисс между временем и пространством, аналогичный предыдущим алгоритмам. Однако даже версия этого алгоритма с одним стеком не является алгоритмом указателя из-за сравнений, необходимых для определения того, какое из двух значений меньше.

Любой алгоритм обнаружения цикла, который хранит не более M значений из входной последовательности, должен выполнять как минимум функциональные оценки. [18] [19]

Приложения
[ редактировать ]Обнаружение цикла использовалось во многих приложениях.
- Определение длины цикла генератора псевдослучайных чисел является одним из показателей его силы. Это приложение, на которое ссылается Кнут при описании метода Флойда. [3] Брент [8] описывает результаты тестирования линейного конгруэнтного генератора таким образом; его срок оказался значительно меньше заявленного. Для более сложных генераторов последовательность значений, в которой нужно найти цикл, может представлять не выход генератора, а его внутреннее состояние.
- Несколько теоретико-числовых алгоритмов основаны на обнаружении циклов, включая ро-алгоритм Полларда для факторизации целых чисел. [20] и связанный с ним алгоритм «кенгуру» для задачи дискретного логарифма . [21]
- В криптографических приложениях способность находить два различных значения x µ -1 и x λ + µ -1, сопоставленных некоторой криптографической функцией ƒ с одним и тем же значением x µ, может указывать на слабость ƒ . Например, Кискатер и Делескайль. [17] применять алгоритмы обнаружения циклов при поиске сообщения и пару ключей стандарта шифрования данных , которые сопоставляют это сообщение с тем же зашифрованным значением; Калиски , Ривест и Шерман [22] также используйте алгоритмы обнаружения циклов для атаки на DES. Этот метод также можно использовать для обнаружения коллизий в криптографической хэш-функции . [23]
- Обнаружение циклов может быть полезно для обнаружения бесконечных циклов в определенных типах компьютерных программ . [24]
- Периодические конфигурации в моделировании клеточных автоматов можно найти, применяя алгоритмы обнаружения циклов к последовательности состояний автомата. [12]
- Анализ формы структур данных связанного списка — это метод проверки правильности алгоритма, использующего эти структуры. Если узел в списке ошибочно указывает на более ранний узел в том же списке, структура сформирует цикл, который может быть обнаружен этими алгоритмами. [25] В Common Lisp принтер S-выражений , находящийся под управлением
*print-circle*переменная, определяет циклическую структуру списка и компактно печатает ее. - Чайная ложка [14] описывает приложения в вычислительной теории групп : определение структуры абелевой группы по набору ее генераторов. Криптографические алгоритмы Калиски и др. [22] также можно рассматривать как попытку сделать вывод о структуре неизвестной группы.
- Фич (1981) кратко упоминает приложение к компьютерному моделированию небесной механики , которое она приписывает Уильяму Кахану . В этом приложении обнаружение цикла в фазовом пространстве орбитальной системы может использоваться для определения того, является ли система периодической с точностью моделирования. [18]
- В генерации фракталов множества Мандельброта используются некоторые методы повышения производительности для ускорения генерации изображения. Один из них называется «проверка периода» и заключается в нахождении циклов на точечной орбите. В этой статье описывается техника « проверки периода ». Другое объяснение вы можете найти здесь . Для реализации этого метода необходимо реализовать некоторые алгоритмы обнаружения цикла.
Ссылки
[ редактировать ]- ^ Жу, Антуан (2009), Алгоритмический криптоанализ , CRC Press, стр. 223, ISBN 9781420070033 .
- ^ Jump up to: Перейти обратно: а б Жу (2009 , стр. 224).
- ^ Jump up to: Перейти обратно: а б Кнут, Дональд Э. (1969), Искусство компьютерного программирования, том. II: Получисловые алгоритмы , Аддисон-Уэсли, с. 7, упражнения 6 и 7
- ^ Справочник по прикладной криптографии Альфреда Дж. Менезеса, Пола К. ван Оршота, Скотта А. Ванстона, стр. 125 , описывает этот и другие алгоритмы.
- ^ Флойд, Р.В. (1967), «Недетерминированные алгоритмы», J. ACM , 14 (4): 636–644, doi : 10.1145/321420.321422 , S2CID 1990464
- ^ Хэш-функция BLAKE, Жан-Филипп Омассон, Вилли Мейер, Рафаэль К.-В. Фан, Люк Хензен (2015), с. 21 , сноска
- ^ Жу (2009) , Раздел 7.1.1, Алгоритм поиска цикла Флойда, стр. 225–226.
- ^ Jump up to: Перейти обратно: а б с д Брент, Р.П. (1980), «Улучшенный алгоритм факторизации Монте-Карло» (PDF) , BIT Numerical Mathematics , 20 (2): 176–184, doi : 10.1007/BF01933190 , S2CID 17181286 .
- ^ Жу (2009) , Раздел 7.1.2, Алгоритм поиска цикла Брента, стр. 226–227.
- ^ Jump up to: Перейти обратно: а б «Архивная копия» . Архивировано из оригинала 14 апреля 2016 г. Проверено 8 февраля 2017 г.
{{cite web}}: CS1 maint: архивная копия в заголовке ( ссылка ) - ^ Jump up to: Перейти обратно: а б «Хакмем — Потоки и итерированные функции — черновой вариант, еще не проверенный» . Архивировано из оригинала 18 марта 2020 г. Проверено 2 мая 2024 г.
- ^ Jump up to: Перейти обратно: а б с д Ниваш, Габриэль (2004), «Обнаружение цикла с использованием стека», Information Processing Letters , 90 (3): 135–140, doi : 10.1016/j.ipl.2004.01.016 .
- ^ Шнорр, Клаус П .; Ленстра, Хендрик В. (1984), «Алгоритм факторизации Монте-Карло с линейным хранилищем», Mathematics of Computation , 43 (167): 289–311, doi : 10.2307/2007414 , hdl : 1887/3815 , JSTOR 2007414 .
- ^ Jump up to: Перейти обратно: а б Теске, Эдлин (1998), «Экономичный алгоритм вычисления структуры группы», Mathematics of Computation , 67 (224): 1637–1663, Bibcode : 1998MaCom..67.1637T , doi : 10.1090/S0025-5718-98- 00968-5 .
- ^ Седжвик, Роберт ; Шимански, Томас Г.; Яо, Эндрю К.-К. (1982), «Сложность поиска циклов в периодических функциях», SIAM Journal on Computing , 11 (2): 376–390, doi : 10.1137/0211030 .
- ^ ван Оршот, Пол К.; Винер, Майкл Дж. (1999), «Параллельный поиск коллизий с криптоаналитическими приложениями» , Journal of Cryptology , 12 (1): 1–28, doi : 10.1007/PL00003816 , S2CID 5091635 .
- ^ Jump up to: Перейти обратно: а б Кискатер, Ж.-Ж.; Делескайль, Ж.-П., «Насколько прост поиск коллизий? Приложение к DES», Достижения в криптологии – EUROCRYPT '89, Семинар по теории и применению криптографических методов , Конспекты лекций по информатике, том. 434, Springer-Verlag, стр. 429–434, номер документа : 10.1007/3-540-46885-4_43 .
- ^ Jump up to: Перейти обратно: а б Фич, Фейт Эллен (1981), «Нижние оценки проблемы обнаружения цикла», Proc. 13-й симпозиум ACM по теории вычислений , стр. 96–105, doi : 10.1145/800076.802462 , S2CID 119742106 .
- ^ Аллендер, Эрик В .; Клове, Мария М. (1985), «Улучшенные нижние границы проблемы обнаружения циклов», Theoretical Computer Science , 36 (2–3): 231–237, doi : 10.1016/0304-3975(85)90044-1 .
- ^ Поллард, Дж. М. (1975), «Метод Монте-Карло для факторизации», BIT , 15 (3): 331–334, doi : 10.1007/BF01933667 , S2CID 122775546 .
- ^ Поллард, Дж. М. (1978), «Методы Монте-Карло для вычисления индексов (mod p )», Mathematics of Computation , 32 (143), Американское математическое общество: 918–924, doi : 10.2307/2006496 , JSTOR 2006496 , S2CID 235457090 .
- ^ Jump up to: Перейти обратно: а б Калиски, Бертон С. младший; Ривест, Рональд Л .; Шерман, Алан Т. (1988), «Является ли стандарт шифрования данных группой? (Результаты циклических экспериментов над DES)», Journal of Cryptology , 1 (1): 3–36, doi : 10.1007/BF00206323 , S2CID 17224075 .
- ^ Жу (2009) , Раздел 7.5, Коллизии в хэш-функциях, стр. 242–245.
- ^ Ван Гелдер, Аллен (1987), «Эффективное обнаружение циклов в Прологе с использованием техники черепахи и зайца», Journal of Logic Programming , 4 (1): 23–31, doi : 10.1016/0743-1066(87)90020- 3 .
- ^ Огюстон, Михаил; Хон, Миу Хар (1997), «Утверждения для динамического анализа формы структур данных списков», AADEBUG '97, Материалы третьего международного семинара по автоматической отладке , Электронные статьи Linköping в области компьютерных и информационных наук, Университет Линчёпинга , стр. 37– 42 .
Внешние ссылки
[ редактировать ]- Габриэль Ниваш, Проблема обнаружения цикла и стековый алгоритм
- Черепаха и заяц , Портлендский репозиторий шаблонов
- Алгоритм обнаружения цикла Флойда (Черепаха и Заяц)
- Алгоритм обнаружения цикла Брента (Телепортирующаяся черепаха)