Присоединиться (SQL)

Предложение соединения в языке структурированных запросов ( SQL ) объединяет столбцы из одной или нескольких таблиц в новую таблицу. Эта операция соответствует операции соединения в реляционной алгебре . Неформально, соединение объединяет две таблицы и помещает в одну и ту же строку записи с совпадающими полями: INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER и CROSS.
Примеры таблиц [ править ]
Чтобы объяснить типы соединений, в оставшейся части этой статьи используются следующие таблицы:
| Фамилия | ID отдела |
|---|---|
| Рафферти | 31 |
| Джонс | 33 |
| Гейзенберг | 33 |
| Робинсон | 34 |
| Смит | 34 |
| Уильямс | NULL
|
| ID отдела | Название отдела |
|---|---|
| 31 | Продажи |
| 33 | Инженерное дело |
| 34 | Канцелярский |
| 35 | Маркетинг |
Department.DepartmentID является первичным ключом Department стол, тогда как Employee.DepartmentID является внешним ключом .
Обратите внимание, что в Employee, "Вильямс" пока не приписан к отделу. Также в отдел «Маркетинг» не закреплены сотрудники.
Это операторы SQL для создания приведенных выше таблиц:
CREATE TABLE department(
DepartmentID INT PRIMARY KEY NOT NULL,
DepartmentName VARCHAR(20)
);
CREATE TABLE employee (
LastName VARCHAR(20),
DepartmentID INT REFERENCES department(DepartmentID)
);
INSERT INTO department
VALUES (31, 'Sales'),
(33, 'Engineering'),
(34, 'Clerical'),
(35, 'Marketing');
INSERT INTO employee
VALUES ('Rafferty', 31),
('Jones', 33),
('Heisenberg', 33),
('Robinson', 34),
('Smith', 34),
('Williams', NULL);
Перекрестное соединение [ править ]
CROSS JOIN возвращает декартово произведение строк из таблиц в объединении. Другими словами, он будет создавать строки, объединяющие каждую строку из первой таблицы с каждой строкой из второй таблицы. [1]
| Сотрудник.Фамилия | Сотрудник.DepartmentID | Department.DepartmentName | Департамент.DepartmentID |
|---|---|---|---|
| Рафферти | 31 | Продажи | 31 |
| Джонс | 33 | Продажи | 31 |
| Гейзенберг | 33 | Продажи | 31 |
| Смит | 34 | Продажи | 31 |
| Робинсон | 34 | Продажи | 31 |
| Уильямс | NULL |
Продажи | 31 |
| Рафферти | 31 | Инженерное дело | 33 |
| Джонс | 33 | Инженерное дело | 33 |
| Гейзенберг | 33 | Инженерное дело | 33 |
| Смит | 34 | Инженерное дело | 33 |
| Робинсон | 34 | Инженерное дело | 33 |
| Уильямс | NULL |
Инженерное дело | 33 |
| Рафферти | 31 | Канцелярский | 34 |
| Джонс | 33 | Канцелярский | 34 |
| Гейзенберг | 33 | Канцелярский | 34 |
| Смит | 34 | Канцелярский | 34 |
| Робинсон | 34 | Канцелярский | 34 |
| Уильямс | NULL |
Канцелярский | 34 |
| Рафферти | 31 | Маркетинг | 35 |
| Джонс | 33 | Маркетинг | 35 |
| Гейзенберг | 33 | Маркетинг | 35 |
| Смит | 34 | Маркетинг | 35 |
| Робинсон | 34 | Маркетинг | 35 |
| Уильямс | NULL |
Маркетинг | 35 |
Пример явного перекрестного соединения:
SELECT *
FROM employee CROSS JOIN department;
Пример неявного перекрестного соединения:
SELECT *
FROM employee, department;
Перекрестное соединение можно заменить внутренним соединением с всегда истинным условием:
SELECT *
FROM employee INNER JOIN department ON 1=1;
CROSS JOIN сам по себе не применяет никаких предикатов для фильтрации строк из объединенной таблицы. Результаты CROSS JOIN можно отфильтровать с помощью WHERE предложение, которое затем может создать эквивалент внутреннего соединения.
В стандарте SQL:2011 перекрестные соединения являются частью дополнительного пакета F401 «Расширенная объединенная таблица».
Обычное использование предназначено для проверки производительности сервера. [ почему? ]
Внутреннее соединение [ править ]
( Внутреннее соединение или join ) требует, чтобы каждая строка в двух соединенных таблицах имела совпадающие значения столбцов, и это часто используемая операция соединения в приложениях, но ее не следует считать лучшим выбором во всех ситуациях. Внутреннее соединение создает новую таблицу результатов путем объединения значений столбцов двух таблиц (A и B) на основе предиката соединения. Запрос сравнивает каждую строку A с каждой строкой B, чтобы найти все пары строк, удовлетворяющие предикату соединения. Когда предикат соединения удовлетворяется путем сопоставления значений, отличных от NULL , значения столбца для каждой совпавшей пары строк A и B объединяются в результирующую строку.
Результат соединения можно определить как результат сначала взятия декартова произведения (или перекрестного соединения ) всех строк в таблицах (объединение каждой строки в таблице A с каждой строкой в таблице B), а затем возврата всех строк, удовлетворяющих условию предикат соединения. Реальные реализации SQL обычно используют другие подходы, такие как хеш-соединения или соединения сортировки-слияния , поскольку вычисление декартова произведения происходит медленнее и часто требует непомерно большого объема памяти для хранения.
SQL определяет два разных синтаксических способа выражения соединений: «нотацию явного соединения» и «нотацию неявного соединения». «Неявная нотация соединения» больше не считается лучшей практикой. [ кем? ] , хотя системы баз данных все еще поддерживают его.
«Явная нотация соединения» использует JOIN ключевое слово, которому может предшествовать ключевое слово INNER ключевое слово, чтобы указать таблицу, к которой нужно присоединиться, и ON Ключевое слово для указания предикатов для соединения, как в следующем примере:
SELECT employee.LastName, employee.DepartmentID, department.DepartmentName
FROM employee
INNER JOIN department ON
employee.DepartmentID = department.DepartmentID;
| Сотрудник.Фамилия | Сотрудник.DepartmentID | Department.DepartmentName |
|---|---|---|
| Робинсон | 34 | Канцелярский |
| Джонс | 33 | Инженерное дело |
| Смит | 34 | Канцелярский |
| Гейзенберг | 33 | Инженерное дело |
| Рафферти | 31 | Продажи |
«Нотация неявного соединения» просто перечисляет таблицы для соединения в FROM положение SELECT утверждение, разделяя их запятыми. Таким образом, он определяет перекрестное соединение , а WHERE В предложении могут применяться дополнительные предикаты-фильтры (которые действуют аналогично предикатам соединения в явной записи).
Следующий пример эквивалентен предыдущему, но на этот раз с использованием неявной записи соединения:
SELECT employee.LastName, employee.DepartmentID, department.DepartmentName
FROM employee, department
WHERE employee.DepartmentID = department.DepartmentID;
Запросы, приведенные в примерах выше, объединят таблицы «Сотрудник» и «Отдел», используя столбец «DepartmentID» обеих таблиц. Если DepartmentID этих таблиц совпадают (т. е. предикат объединения удовлетворен), запрос объединит столбцы LastName , DepartmentID и DepartmentName из двух таблиц в результирующую строку. Если DepartmentID не совпадает, строка результатов не создается.
Таким образом, результатом выполнения приведенного выше запроса будет:
| Сотрудник.Фамилия | Сотрудник.DepartmentID | Department.DepartmentName |
|---|---|---|
| Робинсон | 34 | Канцелярский |
| Джонс | 33 | Инженерное дело |
| Смит | 34 | Канцелярский |
| Гейзенберг | 33 | Инженерное дело |
| Рафферти | 31 | Продажи |
Сотрудник «Вильямс» и отдел «Маркетинг» не появляются в результатах выполнения запроса. Ни один из них не имеет совпадающих строк в другой соответствующей таблице: «Уильямс» не имеет связанного отдела, и ни один сотрудник не имеет идентификатора отдела 35 («Маркетинг»). В зависимости от желаемых результатов такое поведение может быть незаметной ошибкой, которой можно избежать, заменив внутреннее соединение внешним соединением .
Внутреннее соединение и значения NULL [ править ]
Программистам следует проявлять особую осторожность при объединении таблиц по столбцам, которые могут содержать значения NULL , поскольку NULL никогда не будет соответствовать никакому другому значению (даже самому NULL), если только условие соединения явно не использует предикат комбинации, который сначала проверяет, являются ли объединяемые столбцы NOT NULL перед применением оставшихся условий-предикатов. Внутреннее соединение можно безопасно использовать только в базе данных, которая обеспечивает ссылочную целостность или где столбцы соединения гарантированно не равны NULL. Многие реляционные базы данных обработки транзакций полагаются на стандарты обновления данных атомарности, согласованности, изоляции и долговечности (ACID) для обеспечения целостности данных, поэтому внутренние соединения являются подходящим выбором. Однако базы данных транзакций обычно также имеют желательные столбцы соединения, которым разрешено иметь значение NULL. Многие реляционные базы данных и хранилища данных, предоставляющие отчеты, используют пакетные обновления извлечения, преобразования и загрузки (ETL) больших объемов, которые затрудняют или делают невозможным обеспечение соблюдения ссылочной целостности, что приводит к появлению потенциально NULL-столбцов соединения, которые автор SQL-запроса не может изменить и которые приводят к пропуску внутренних соединений. данные без указания ошибки. Выбор использования внутреннего соединения зависит от конструкции базы данных и характеристик данных. Левое внешнее соединение обычно можно заменить внутренним соединением, если столбцы соединения в одной таблице могут содержать значения NULL.
Любой столбец данных, который может иметь значение NULL (пустой), никогда не должен использоваться в качестве ссылки во внутреннем соединении, если только предполагаемым результатом не является удаление строк со значением NULL. Если столбцы соединения NULL должны быть намеренно удалены из набора результатов , внутреннее соединение может быть быстрее, чем внешнее соединение, поскольку объединение таблиц и фильтрация выполняются за один шаг. И наоборот, внутреннее соединение может привести к катастрофическому снижению производительности или даже к сбою сервера при использовании в запросе большого объема в сочетании с функциями базы данных в предложении SQL Where. [2] [3] [4] Функция в предложении SQL Where может привести к тому, что база данных будет игнорировать относительно компактные индексы таблиц. База данных может считывать и объединять выбранные столбцы из обеих таблиц, а затем уменьшать количество строк с помощью фильтра, который зависит от вычисленного значения, что приводит к относительно огромному объему неэффективной обработки.
Когда набор результатов создается путем объединения нескольких таблиц, включая основные таблицы, используемые для поиска полнотекстовых описаний кодов числовых идентификаторов ( таблица поиска ), значение NULL в любом из внешних ключей может привести к удалению всей строки. из набора результатов без указания ошибки. Сложный SQL-запрос, включающий одно или несколько внутренних объединений и несколько внешних объединений, имеет одинаковый риск получения значений NULL в столбцах ссылок внутреннего соединения.
Приверженность коду SQL, содержащему внутренние соединения, предполагает, что столбцы соединения NULL не будут введены будущими изменениями, включая обновления поставщиков, изменения дизайна и массовую обработку за пределами правил проверки данных приложения, таких как преобразования данных, миграции, массовый импорт и слияния.
Кроме того, внутренние соединения можно классифицировать как эквивалентные соединения, естественные соединения или перекрестные соединения.
Равноправное соединение [ править ]
Эквисоединение сравнения на — это особый тип соединения на основе компаратора, который использует только равенство в предикате соединения. Используя другие операторы сравнения (например, <) дисквалифицирует соединение как равноправное соединение. Запрос, показанный выше, уже предоставил пример эквивалентного соединения:
SELECT *
FROM employee JOIN department
ON employee.DepartmentID = department.DepartmentID;
Мы можем написать equi-join, как показано ниже:
SELECT *
FROM employee, department
WHERE employee.DepartmentID = department.DepartmentID;
Если столбцы в эквивалентном соединении имеют одно и то же имя, SQL-92 предоставляет дополнительную сокращенную запись для выражения эквивалентного соединения посредством USING конструкция: [5]
SELECT *
FROM employee INNER JOIN department USING (DepartmentID);
The USING Однако конструкция — это нечто большее, чем просто синтаксический сахар , поскольку набор результатов отличается от набора результатов версии с явным предикатом. В частности, любые столбцы, упомянутые в USING list появится только один раз с неполным именем, а не один раз для каждой таблицы в объединении. В приведенном выше случае будет один DepartmentID столбец и нет employee.DepartmentID или department.DepartmentID.
The USING Предложение не поддерживается MS SQL Server и Sybase.
Естественное соединение [ править ]
Естественное соединение является частным случаем равносоединения. Естественное соединение (⋈) — это бинарный оператор , который записывается как ( R ⋈ S ), где R и S — отношения . [6] Результатом естественного соединения является набор всех комбинаций кортежей в R и S , которые имеют одинаковые имена общих атрибутов. В качестве примера рассмотрим таблицы «Сотрудник» и «Отдел» и их естественное соединение:
|
|
|

Это также можно использовать для определения состава отношений . Например, состав сотрудников и отделов — это их объединение, как показано выше, проецируемое на все атрибуты, кроме общего атрибута DeptName . В теории категорий соединение представляет собой в точности произведение расслоений .
Естественное соединение, возможно, является одним из наиболее важных операторов, поскольку оно является реляционным аналогом логического И. Обратите внимание: если одна и та же переменная появляется в каждом из двух предикатов, соединенных оператором AND, то эта переменная обозначает одно и то же, и оба появления всегда должны быть заменены одним и тем же значением. В частности, естественное соединение позволяет комбинировать отношения, связанные внешним ключом . Например, в приведенном выше примере внешний ключ, вероятно, принадлежит сотруднику . DeptName в Dept. DeptName , а затем естественное объединение сотрудников и отделов объединяет всех сотрудников с их отделами. Это работает, поскольку внешний ключ сохраняется между атрибутами с одинаковым именем. Если это не так, как, например, во внешнем ключе Dept. из менеджер к сотруднику . Name , то эти столбцы необходимо переименовать, прежде чем будет выполнено естественное соединение. Такое соединение иногда также называют эквивалентным соединением .
Более формально семантика естественного соединения определяется следующим образом:
- ,

где Fun — предикат , который истинен для отношения r тогда и только тогда, когда r — функция. Обычно требуется, чтобы R и S имели хотя бы один общий атрибут, но если это ограничение опущено и R и S не имеют общих атрибутов, то естественное соединение становится в точности декартовым произведением.
Естественное соединение можно смоделировать с помощью примитивов Кодда следующим образом. Пусть c 1 , ..., cm — имена атрибутов, общие для R и S , r 1 , ..., r n — имена атрибутов, уникальные для R , и пусть s 1 , ..., sk — атрибуты для С. уникальный Кроме того, предположим, что имена атрибутов x 1 , ..., x m не находятся ни в R, ни в S . На первом этапе имена общих атрибутов в S теперь можно переименовать:

Затем мы берем декартово произведение и выбираем кортежи, которые необходимо соединить:

Естественное соединение — это тип равноправного соединения, при котором предикат соединения возникает неявно путем сравнения всех столбцов в обеих таблицах, имеющих одинаковые имена столбцов в объединенных таблицах. Полученная объединенная таблица содержит только один столбец для каждой пары столбцов с одинаковыми именами. В случае, если столбцы с одинаковыми именами не найдены, результатом является перекрестное соединение .
Большинство экспертов сходятся во мнении, что NATURAL JOIN опасны, и поэтому настоятельно не рекомендуют их использовать. [7] Опасность возникает в случае непреднамеренного добавления нового столбца с таким же именем, как у другого столбца в другой таблице. Существующее естественное соединение может затем «естественным образом» использовать новый столбец для сравнений, выполняя сравнения/сопоставления с использованием других критериев (из разных столбцов), чем раньше. Таким образом, существующий запрос может давать разные результаты, даже если данные в таблицах не были изменены, а только дополнены. Использование имен столбцов для автоматического определения связей таблиц недопустимо в больших базах данных с сотнями или тысячами таблиц, где это накладывает нереалистичные ограничения на соглашения об именах. Реальные базы данных обычно разрабатываются с использованием данных внешнего ключа , которые не заполняются последовательно (допускаются значения NULL) из-за бизнес-правил и контекста. Обычной практикой является изменение имен столбцов схожих данных в разных таблицах, и из-за отсутствия жесткой согласованности естественные соединения относят к теоретической концепции для обсуждения.
Приведенный выше пример запроса для внутренних соединений можно выразить как естественное соединение следующим образом:
SELECT *
FROM employee NATURAL JOIN department;
Как и в случае явного USING в объединенной таблице встречается только один столбец DepartmentID без квалификатора:
| ID отдела | Сотрудник.Фамилия | Department.DepartmentName |
|---|---|---|
| 34 | Смит | Канцелярский |
| 33 | Джонс | Инженерное дело |
| 34 | Робинсон | Канцелярский |
| 33 | Гейзенберг | Инженерное дело |
| 31 | Рафферти | Продажи |
PostgreSQL, MySQL и Oracle поддерживают естественные соединения; Microsoft T-SQL и IBM DB2 этого не делают. Столбцы, используемые в объединении, являются неявными, поэтому код объединения не показывает, какие столбцы ожидаются, а изменение имен столбцов может изменить результаты. В стандарте SQL:2011 естественные соединения являются частью дополнительного пакета F401 «Расширенная объединенная таблица».
Во многих средах баз данных имена столбцов контролируются внешним поставщиком, а не разработчиком запросов. Естественное соединение предполагает стабильность и согласованность имен столбцов, которые могут меняться во время обновлений версий, требуемых поставщиком.
Внешнее соединение [ править ]
В объединенной таблице сохраняется каждая строка, даже если другой соответствующей строки не существует. Внешние соединения подразделяются на левые внешние соединения, правые внешние соединения и полные внешние соединения, в зависимости от того, какие строки таблицы сохраняются: левая, правая или обе (в данном случае левая и правая относятся к двум сторонам таблицы). JOIN ключевое слово). Как и внутренние соединения , все типы внешних соединений можно дополнительно разделить на подкатегории: эквивалентные соединения , естественные соединения , ON <predicate> ( θ -объединить ) и т. д. [8]
В стандартном SQL не существует неявной нотации соединения для внешних соединений.

Левое внешнее соединение [ править ]
Результат левого внешнего соединения (или просто левого соединения ) для таблиц A и B всегда содержит все строки «левой» таблицы (A), даже если условие соединения не находит ни одной подходящей строки в «правой» таблице. (Б). Это означает, что если ON соответствует 0 (нулевым) строкам в B (для данной строки в A), соединение все равно вернет строку в результате (для этой строки), но с NULL в каждом столбце из B. Левое внешнее соединение возвращает все значения из внутреннего соединения плюс все значения в левой таблице, которые не соответствуют значениям в правой таблице, включая строки со значениями NULL (пустыми) в столбце ссылки.
Например, это позволяет нам найти отдел сотрудника, но по-прежнему показывает сотрудников, которые не были назначены этому отделу (в отличие от приведенного выше примера внутреннего объединения, где неназначенные сотрудники были исключены из результата).
Пример левого внешнего соединения (теперь OUTER ключевое слово является необязательным), дополнительная строка результата (по сравнению с внутренним соединением) выделена курсивом:
SELECT *
FROM employee
LEFT OUTER JOIN department ON employee.DepartmentID = department.DepartmentID;
| Сотрудник.Фамилия | Сотрудник.DepartmentID | Department.DepartmentName | Департамент.DepartmentID |
|---|---|---|---|
| Джонс | 33 | Инженерное дело | 33 |
| Рафферти | 31 | Продажи | 31 |
| Робинсон | 34 | Канцелярский | 34 |
| Смит | 34 | Канцелярский | 34 |
| Уильямс | NULL |
NULL |
NULL
|
| Гейзенберг | 33 | Инженерное дело | 33 |
Альтернативные синтаксисы [ править ]
Oracle поддерживает устаревший [9] синтаксис:
SELECT *
FROM employee, department
WHERE employee.DepartmentID = department.DepartmentID(+)
Sybase поддерживает следующий синтаксис ( Microsoft SQL Server объявил этот синтаксис устаревшим с версии 2000):
SELECT *
FROM employee, department
WHERE employee.DepartmentID *= department.DepartmentID
IBM Informix поддерживает синтаксис:
SELECT *
FROM employee, OUTER department
WHERE employee.DepartmentID = department.DepartmentID

Правое внешнее соединение [ править ]
Правое внешнее соединение (или правое соединение ) очень похоже на левое внешнее соединение, за исключением того, что таблицы обрабатываются в обратном порядке. Каждая строка из «правой» таблицы (B) появится в объединенной таблице хотя бы один раз. Если соответствующей строки из «левой» таблицы (A) не существует, NULL появится в столбцах из A для тех строк, которые не имеют совпадений в B.
Правое внешнее соединение возвращает все значения из правой таблицы и совпадающие значения из левой таблицы (NULL в случае отсутствия соответствующего предиката соединения). Например, это позволяет нам найти каждого сотрудника и его отдел, но при этом показывать отделы, в которых нет сотрудников.
Ниже приведен пример правого внешнего соединения (теперь OUTER ключевое слово является необязательным), дополнительная строка результата выделена курсивом:
SELECT *
FROM employee RIGHT OUTER JOIN department
ON employee.DepartmentID = department.DepartmentID;
| Сотрудник.Фамилия | Сотрудник.DepartmentID | Department.DepartmentName | Департамент.DepartmentID |
|---|---|---|---|
| Смит | 34 | Канцелярский | 34 |
| Джонс | 33 | Инженерное дело | 33 |
| Робинсон | 34 | Канцелярский | 34 |
| Гейзенберг | 33 | Инженерное дело | 33 |
| Рафферти | 31 | Продажи | 31 |
NULL |
NULL |
Маркетинг | 35 |
Правое и левое внешние соединения функционально эквивалентны. Ни один из них не предоставляет никаких функций, которых нет у другого, поэтому правое и левое внешние соединения могут заменять друг друга, пока порядок таблиц переключается.

Полное внешнее соединение [ править ]
Концептуально полное внешнее соединение сочетает в себе эффект применения как левого, так и правого внешнего соединения. Если строки в полных внешних объединенных таблицах не совпадают, результирующий набор будет иметь значения NULL для каждого столбца таблицы, в котором отсутствует совпадающая строка. Для тех строк, которые совпадают, в наборе результатов будет создана одна строка (содержащая столбцы, заполненные из обеих таблиц).
Например, это позволяет нам видеть каждого сотрудника, входящего в отдел, и каждый отдел, в котором есть сотрудник, а также видеть каждого сотрудника, не входящего в состав отдела, и каждый отдел, в котором нет сотрудника.
Пример полного внешнего соединения (тег OUTER ключевое слово является необязательным):
SELECT *
FROM employee FULL OUTER JOIN department
ON employee.DepartmentID = department.DepartmentID;
| Сотрудник.Фамилия | Сотрудник.DepartmentID | Department.DepartmentName | Департамент.DepartmentID |
|---|---|---|---|
| Смит | 34 | Канцелярский | 34 |
| Джонс | 33 | Инженерное дело | 33 |
| Робинсон | 34 | Канцелярский | 34 |
| Уильямс | NULL |
NULL |
NULL
|
| Гейзенберг | 33 | Инженерное дело | 33 |
| Рафферти | 31 | Продажи | 31 |
NULL |
NULL |
Маркетинг | 35 |
Некоторые системы баз данных не поддерживают полную функциональность внешнего соединения напрямую, но могут имитировать ее с помощью внутреннего соединения и выбора UNION ALL «отдельных строк таблицы» из левой и правой таблиц соответственно. Тот же пример может выглядеть следующим образом:
SELECT employee.LastName, employee.DepartmentID,
department.DepartmentName, department.DepartmentID
FROM employee
INNER JOIN department ON employee.DepartmentID = department.DepartmentID
UNION ALL
SELECT employee.LastName, employee.DepartmentID,
cast(NULL as varchar(20)), cast(NULL as integer)
FROM employee
WHERE NOT EXISTS (
SELECT * FROM department
WHERE employee.DepartmentID = department.DepartmentID)
UNION ALL
SELECT cast(NULL as varchar(20)), cast(NULL as integer),
department.DepartmentName, department.DepartmentID
FROM department
WHERE NOT EXISTS (
SELECT * FROM employee
WHERE employee.DepartmentID = department.DepartmentID)
Другим подходом может быть UNION ALL левого внешнего соединения и правого внешнего соединения МИНУС внутреннего соединения.
Самостоятельное присоединение [ править ]
Самосоединение — это присоединение таблицы к самой себе. [10]
Пример [ править ]
Если бы существовало две отдельные таблицы для сотрудников и запрос, который запрашивал сотрудников в первой таблице, имеющих ту же страну, что и сотрудники во второй таблице, для поиска таблицы ответов можно было бы использовать обычную операцию соединения. Однако вся информация о сотрудниках содержится в одной большой таблице. [11]
Рассмотрим модифицированный Employee таблица, например следующая:
| идентификатор сотрудника | Фамилия | Страна | ID отдела |
|---|---|---|---|
| 123 | Рафферти | Австралия | 31 |
| 124 | Джонс | Австралия | 33 |
| 145 | Гейзенберг | Австралия | 33 |
| 201 | Робинсон | Соединенные Штаты | 34 |
| 305 | Смит | Германия | 34 |
| 306 | Уильямс | Германия | NULL
|
Пример запроса решения может быть следующим:
SELECT F.EmployeeID, F.LastName, S.EmployeeID, S.LastName, F.Country
FROM Employee F INNER JOIN Employee S ON F.Country = S.Country
WHERE F.EmployeeID < S.EmployeeID
ORDER BY F.EmployeeID, S.EmployeeID;
В результате создается следующая таблица.
| идентификатор сотрудника | Фамилия | идентификатор сотрудника | Фамилия | Страна |
|---|---|---|---|---|
| 123 | Рафферти | 124 | Джонс | Австралия |
| 123 | Рафферти | 145 | Гейзенберг | Австралия |
| 124 | Джонс | 145 | Гейзенберг | Австралия |
| 305 | Смит | 306 | Уильямс | Германия |
Для этого примера:
FиSявляются псевдонимами первой и второй копий таблицы сотрудников.- Состояние
F.Country = S.Countryисключает создание пар между сотрудниками в разных странах. В примере вопроса речь шла только о парах сотрудников из одной страны. - Состояние
F.EmployeeID < S.EmployeeIDисключает пары, в которыхEmployeeIDпервого сотрудника больше или равноEmployeeIDвторого сотрудника. Другими словами, эффект этого условия заключается в исключении дублирующих спариваний и самоспариваний. Без него была бы создана следующая менее полезная таблица (в таблице ниже отображается только часть результата «Германия»):
| идентификатор сотрудника | Фамилия | идентификатор сотрудника | Фамилия | Страна |
|---|---|---|---|---|
| 305 | Смит | 305 | Смит | Германия |
| 305 | Смит | 306 | Уильямс | Германия |
| 306 | Уильямс | 305 | Смит | Германия |
| 306 | Уильямс | 306 | Уильямс | Германия |
Для ответа на исходный вопрос необходима только одна из двух средних пар, а самая верхняя и самая нижняя в этом примере вообще не представляют интереса.
Альтернативы [ править ]
Эффект внешнего соединения также можно получить, используя UNION ALL между INNER JOIN и SELECT строк в «основной» таблице, которые не удовлетворяют условию соединения. Например,
SELECT employee.LastName, employee.DepartmentID, department.DepartmentName
FROM employee
LEFT OUTER JOIN department ON employee.DepartmentID = department.DepartmentID;
также можно записать как
SELECT employee.LastName, employee.DepartmentID, department.DepartmentName
FROM employee
INNER JOIN department ON employee.DepartmentID = department.DepartmentID
UNION ALL
SELECT employee.LastName, employee.DepartmentID, cast(NULL as varchar(20))
FROM employee
WHERE NOT EXISTS (
SELECT * FROM department
WHERE employee.DepartmentID = department.DepartmentID)
Реализация [ править ]

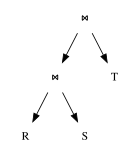
Большая часть работы в системах баз данных была направлена на эффективную реализацию соединений, поскольку реляционные системы обычно требуют соединений, но сталкиваются с трудностями при оптимизации их эффективного выполнения. Проблема возникает потому, что внутренние соединения работают как коммутативно , так и ассоциативно . На практике это означает, что пользователь просто предоставляет список таблиц для объединения и используемые условия соединения, а перед системой базы данных стоит задача определить наиболее эффективный способ выполнения операции. Выбор становится более сложным по мере увеличения количества таблиц, участвующих в запросе, причем каждая таблица имеет разные характеристики по количеству записей, средней длине записи (с учетом полей NULL) и доступных индексов. Фильтры предложений Where также могут существенно повлиять на объем и стоимость запросов.
Оптимизатор запросов определяет, как выполнить запрос, содержащий соединения. Оптимизатор запросов имеет две основные свободы:
- Порядок соединения . Поскольку функции объединяются коммутативно и ассоциативно, порядок, в котором система объединяет таблицы, не меняет окончательный набор результатов запроса. Однако порядок соединения может оказать огромное влияние на стоимость операции соединения, поэтому выбор наилучшего порядка соединения становится очень важным.
- Метод соединения . Учитывая две таблицы и условие соединения, несколько алгоритмов могут создать набор результатов соединения. Какой алгоритм работает наиболее эффективно, зависит от размеров входных таблиц, количества строк в каждой таблице, соответствующих условию соединения, и операций, необходимых для остальной части запроса.
Многие алгоритмы соединения обрабатывают входные данные по-разному. Входные данные соединения можно называть «внешним» и «внутренним» операндами соединения или «левым» и «правым» соответственно. Например, в случае вложенных циклов система базы данных будет сканировать все внутреннее отношение на предмет каждой строки внешнего отношения.
Планы запросов, включающие соединения, можно классифицировать следующим образом: [12]
- слева-глубоко
- использование базовой таблицы (а не другого соединения) в качестве внутреннего операнда каждого соединения в плане
- правая глубина
- использование базовой таблицы в качестве внешнего операнда каждого соединения в плане
- кустистый
- ни влево, ни вправо; оба входа в соединение могут сами по себе быть результатом соединений
Эти имена происходят от внешнего вида плана запроса , если он нарисован в виде дерева , с внешним отношением соединения слева и внутренним отношением справа (как того требует соглашение).
Алгоритмы объединения [ править ]

Существуют три фундаментальных алгоритма выполнения операции двоичного соединения: соединение вложенного цикла , соединение сортировки-слияния и хэш-соединение . Алгоритмы оптимального соединения в худшем случае асимптотически быстрее, чем алгоритмы двоичного соединения для соединений между более чем двумя отношениями в худшем случае .
Объединение индексов [ править ]
Индексы соединения — это индексы базы данных , которые облегчают обработку запросов соединения в хранилищах данных : в настоящее время (2012 г.) они доступны в реализациях Oracle. [14] и Терадата . [15]
В реализации Teradata указанные столбцы, агрегатные функции для столбцов или компоненты столбцов дат из одной или нескольких таблиц указываются с использованием синтаксиса, аналогичного определению представления базы данных : в одном может быть указано до 64 столбцов/выражений столбцов. индекс соединения. При желании также можно указать столбец, определяющий первичный ключ составных данных: на параллельном оборудовании значения столбца используются для разделения содержимого индекса на несколько дисков. Когда исходные таблицы обновляются пользователями в интерактивном режиме, содержимое индекса соединения обновляется автоматически. Любой запрос, в котором предложение WHERE определяет любую комбинацию столбцов или выражений столбцов, которые являются точным подмножеством тех, которые определены в индексе соединения (так называемый «покрывающий запрос»), будет вызывать индекс соединения, а не исходные таблицы и их индексы. к ним следует обращаться во время выполнения запроса.
Реализация Oracle ограничивается использованием растровых индексов . Индекс соединения растровых изображений используется для столбцов с низкой мощностью (т. е. столбцов, содержащих менее 300 различных значений, согласно документации Oracle): он объединяет столбцы с низкой мощностью из нескольких связанных таблиц. Примером, который использует Oracle, является система инвентаризации, в которой разные поставщики поставляют разные детали. Схема . имеет три связанные таблицы: две «главные таблицы» «Деталь» и «Поставщик» и «подробную таблицу» «Инвентаризация» Последняя представляет собой таблицу «многие ко многим», связывающую поставщика с деталью, и содержит наибольшее количество строк. У каждой детали есть тип детали, а каждый поставщик находится в США и имеет столбец «Штат». В США не более 60 штатов и территорий и не более 300 типов деталей. Индекс соединения растровых изображений определяется с использованием стандартного соединения трех таблиц для трех таблиц, указанных выше, и указания столбцов Part_Type и Поставщик_Состояние для индекса. Однако он определен в таблице Inventory, даже несмотря на то, что столбцы Part_Type и Поставщик_Состояние «заимствованы» у Поставщика и Детали соответственно.
Что касается Teradata, индекс соединения растровых изображений Oracle используется только для ответа на запрос, когда в предложении WHERE запроса указаны столбцы, ограниченные теми, которые включены в индекс соединения.
Прямое соединение [ править ]
Некоторые системы баз данных позволяют пользователю заставить систему читать таблицы в объединении в определенном порядке. Это используется, когда оптимизатор соединения решает читать таблицы в неэффективном порядке. Например, в MySQL команда STRAIGHT_JOIN читает таблицы точно в том порядке, который указан в запросе. [16]
См. также [ править ]
Ссылки [ править ]
Цитаты [ править ]
- ^ SQL-КРОСС-СОЕДИНЕНИЕ
- ^ Грег Робиду, «Избегайте функций SQL Server в предложении WHERE для повышения производительности», Советы MSSQL, 3 мая 2007 г.
- ^ Патрик Вольф, «Внутри Oracle APEX «Осторожно при использовании функций PL/SQL в операторе SQL», 30 ноября 2006 г.
- ^ Грегори А. Ларсен, «Лучшие практики T-SQL — не используйте функции скалярных значений в списке столбцов или предложениях WHERE», 29 октября 2009 г.,
- ^ Упрощение объединений с помощью ключевого слова USING
- ^ В Юникоде символ галстука-бабочки — ⋈ (U+22C8).
- ^ Спросите Тома: «Присоединяется Oracle к поддержке ANSI». Назад к основам: внутренние соединения »Блог Эдди Авада. Архивировано 19 ноября 2010 г. в Wayback Machine.
- ^ Зильбершац, Авраам ; Корт, Хэнк ; Сударшан, С. (2002). «Раздел 4.10.2: Типы и условия соединений». Концепции системы баз данных (4-е изд.). МакГроу-Хилл. п. 166. ИСБН 0072283637 .
- ^ Oracle левое внешнее соединение
- ^ Шах 2005 , с. 165
- ^ Адаптировано из Pratt 2005 , стр. 115–6.
- ^ Yu & Meng 1998 , p. 213
- ^ Ван, Ису Реми; Уиллси, Макс; Сучу, Дэн (27 января 2023 г.). «Бесплатное соединение: объединение оптимальных и традиционных соединений для наихудшего случая». arXiv : 2301.10841 [ cs.DB ].
- ^ Индекс соединения растровых изображений Oracle. URL: http://www.dba-oracle.com/art_builder_bitmap_join_idx.htm
- ^ Индексы соединения Teradata. «Присоединиться к индексу» . Архивировано из оригинала 16 декабря 2012 г. Проверено 14 июня 2012 г.
- ^ «13.2.9.2 Синтаксис ПРИСОЕДИНЕНИЯ» . Справочное руководство по MySQL 5.7 . Корпорация Оракл . Проверено 3 декабря 2015 г.
Источники [ править ]
- Пратт, Филлип Дж. (2005), Руководство по SQL, седьмое издание , технология курса Thomson, ISBN 978-0-619-21674-0
- Шах, Нилеш (2005) [2002], Системы баз данных с использованием Oracle - упрощенное руководство по SQL и PL/SQL, второе издание (международное издание), Pearson Education International, ISBN 0-13-191180-5
- Ю, Клемент Т.; Мэн, Вэйи (1998), Принципы обработки запросов к базе данных для продвинутых приложений , Морган Кауфманн, ISBN 978-1-55860-434-6 , получено 3 марта 2009 г.