Массив (тип данных)
В информатике , массив — это тип данных который представляет собой набор элементов ( значений или переменных ), каждый из которых выбран одним или несколькими индексами (идентифицирующими ключами), которые могут быть вычислены во время выполнения во время выполнения программы. Такую коллекцию обычно называют переменной массива или значением массива . [1] По аналогии с математическими понятиями вектор и матрица , типы массивов с одним и двумя индексами часто называют векторным типом и матричным типом соответственно. В более общем смысле тип многомерного массива можно назвать тензорным типом по аналогии с физическим понятием тензор . [2]
Языковая поддержка типов массивов может включать определенные встроенные типы данных массива, некоторые синтаксические конструкции ( конструкторы типов массивов ), которые программист может использовать для определения таких типов и объявления переменных массива, а также специальные обозначения для индексации элементов массива. [1] Например, в языке программирования Паскаль объявление type MyTable = array [1..4,1..2] of integer, определяет новый тип данных массива, называемый MyTable. Декларация var A: MyTable затем определяет переменную A этого типа, который представляет собой совокупность восьми элементов, каждый из которых представляет собой целочисленную переменную, идентифицируемую двумя индексами. В программе на языке Паскаль эти элементы обозначаются A[1,1], A[1,2], A[2,1], …, A[4,2]. [3] языка Специальные типы массивов часто определяются стандартными библиотеками .
Динамические списки также более распространены и их проще реализовать. [ сомнительно – обсудить ] чем динамические массивы . Типы массивов отличаются от типов записей главным образом потому, что они позволяют вычислять индексы элементов во время выполнения Паскаля. , как в присваивании A[I,J] := A[N-I,2*J]. Помимо прочего, эта функция позволяет одному итеративному оператору обрабатывать произвольное количество элементов переменной массива.
В более теоретическом контексте, особенно в теории типов и при описании абстрактных алгоритмов , термины «массив» и «тип массива» иногда относятся к абстрактному типу данных (ADT), также называемому абстрактным массивом , или могут относиться к ассоциативному массиву , математическая модель с основными операциями и поведением типичного типа массива в большинстве языков — по сути, коллекция элементов, которые выбираются по индексам, вычисляемым во время выполнения.
В зависимости от языка типы массивов могут перекрываться (или отождествляться) с другими типами данных, описывающими совокупность значений, например списками и строками . Типы массивов часто реализуются структурами данных массива , но иногда и другими средствами, такими как хеш-таблицы , связанные списки или деревья поиска .
История
[ редактировать ]Язык программирования Хайнца Рутисхаузера Superplan (1949–1951) включал многомерные массивы. Однако Рутисхаузер, хотя и описал, как должен быть построен компилятор для его языка, не реализовал его.
Языки ассемблера и языки низкого уровня, такие как BCPL. [4] обычно не имеют синтаксической поддержки массивов.
Из-за важности структур массивов для эффективных вычислений самые ранние языки программирования высокого уровня, включая FORTRAN (1957 г.), COBOL (1960 г.) и Algol 60 (1960 г.), обеспечивали поддержку многомерных массивов.
Абстрактные массивы
[ редактировать ]Структуру данных массива можно математически смоделировать как абстрактную структуру данных ( абстрактный массив ) с помощью двух операций.
- get ( A , I ): данные, хранящиеся в элементе массива A , индексы которого представляют собой целочисленный кортеж I .
- set ( A , I , V ): массив, который получается в результате установки значения этого элемента в V .
Эти операции необходимы для удовлетворения аксиом [5]
- получить ( установить ( A , I , V ), I ) = V
- получить ( установить ( A , I , V ), J ) = получить ( A , J ), если я ≠ J
для любого состояния массива A , любого значения V и любых кортежей I , J, для которых определены операции.
Первая аксиома означает, что каждый элемент ведет себя как переменная. Вторая аксиома означает, что элементы с разными индексами ведут себя как непересекающиеся переменные, поэтому сохранение значения в одном элементе не влияет на значение любого другого элемента.
Эти аксиомы не накладывают никаких ограничений на набор допустимых индексных кортежей I , поэтому эту абстрактную модель можно использовать для треугольных матриц и других массивов странной формы.
Реализации
[ редактировать ]Чтобы эффективно реализовать переменные таких типов как структуры массива (с индексированием, выполняемым с помощью арифметики указателей ), многие языки ограничивают индексы целочисленными типами данных. [6] [7] (или другие типы, которые можно интерпретировать как целые числа, например байты и перечислимые типы ), и требуют, чтобы все элементы имели одинаковый тип данных и размер хранилища. Большинство этих языков также ограничивают каждый индекс конечным интервалом целых чисел, который остается фиксированным на протяжении всего времени существования переменной массива. Фактически, в некоторых компилируемых языках диапазоны индексов могут быть известны во время компиляции .
С другой стороны, некоторые языки программирования предоставляют более либеральные типы массивов, которые позволяют индексировать произвольные значения, такие как числа с плавающей запятой , строки , объекты , ссылки и т. д. Такие значения индекса не могут быть ограничены интервалом, а тем более фиксированный интервал. Таким образом, эти языки обычно позволяют создавать произвольные новые элементы в любое время. Этот выбор исключает реализацию типов массивов как структур данных массива. То есть эти языки используют синтаксис, подобный массиву, для реализации более общей семантики ассоциативного массива и, следовательно, должны быть реализованы с помощью хеш-таблицы или какой-либо другой структуры данных поиска .
Языковая поддержка
[ редактировать ]Многомерные массивы
[ редактировать ]Количество индексов, необходимых для указания элемента, называется размерностью , размерностью или рангом типа массива. (Эта номенклатура противоречит понятию размерности в линейной алгебре, которое выражает форму матрицы . Таким образом, массив чисел с 5 строками и 4 столбцами, следовательно, с 20 элементами, считается имеющим размерность 2 в вычислительном контексте, но представляет собой матрица, которая называется 4×5-мерной. Кроме того, значение слова «ранг» в информатике противоречит понятию тензорного ранга , которое является обобщением концепции ранга матрицы в линейной алгебре .)
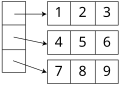
Многие языки поддерживают только одномерные массивы. В этих языках многомерный массив обычно представляется вектором Илиффа — одномерным массивом ссылок на массивы на одно измерение меньше. В частности, двумерный массив будет реализован как вектор указателей на его строки. Таким образом, доступ к элементу в строке i и столбце j массива A будет осуществляться посредством двойной индексации ( A [ i ][ j ] в типичных обозначениях). Этот способ эмуляции многомерных массивов позволяет создавать зубчатые массивы , где каждая строка может иметь разный размер – или, вообще, где допустимый диапазон каждого индекса зависит от значений всех предыдущих индексов.
Такое представление многомерных массивов широко распространено в программном обеспечении C и C++. Однако C и C++ будут использовать формулу линейной индексации для многомерных массивов, которые объявлены с размером постоянной времени компиляции, например int A[10][20] или int A[m][n], вместо традиционного int **A. [8]
Обозначение индексирования
[ редактировать ]Большинство языков программирования, поддерживающих массивы, поддерживают операции сохранения и выбора и имеют специальный синтаксис для индексации. В ранних языках использовались круглые скобки, например A(i,j), как в ФОРТРАНЕ; другие выбирают квадратные скобки, например A[i,j] или A[i][j], как в Алголе 60 и Паскале (чтобы отличить использование круглых скобок для вызовов функций ).
Типы индексов
[ редактировать ]Типы данных массива чаще всего реализуются как структуры массива: с индексами, ограниченными целочисленными (или полностью упорядоченными) значениями, диапазонами индексов, фиксированными во время создания массива, и полилинейной адресацией элементов. Так было в большинстве языков «третьего поколения» и до сих пор так происходит в большинстве языков системного программирования, таких как Ada , C и C++ . Однако в некоторых языках типы данных массива имеют семантику ассоциативных массивов с индексами произвольного типа и созданием динамических элементов. Это относится к некоторым языкам сценариев, таким как Awk и Lua , а также к некоторым типам массивов, предоставляемым стандартными библиотеками C++ .
Проверка границ
[ редактировать ]Некоторые языки (например, Pascal и Modula) выполняют проверку границ при каждом доступе, вызывая исключение или прерывая программу, когда какой-либо индекс выходит за пределы допустимого диапазона. Составители могут разрешить отключение этих проверок, чтобы обменять безопасность на скорость. Другие языки (например, FORTRAN и C) доверяют программисту и не выполняют никаких проверок. Хорошие компиляторы могут также анализировать программу, чтобы определить диапазон возможных значений, которые может иметь индекс, и этот анализ может привести к исключению проверки границ .
Происхождение индекса
[ редактировать ]Некоторые языки, такие как C, предоставляют только типы массивов, отсчитываемые от нуля , для которых минимальное допустимое значение любого индекса равно 0. [9] Этот выбор удобен для реализации массивов и вычислений адресов. С помощью такого языка, как C, можно определить указатель на внутреннюю часть любого массива, который будет символически действовать как псевдомассив, вмещающий отрицательные индексы. Это работает только потому, что C не проверяет индекс на соответствие границам при использовании.
Другие языки предоставляют только основанные на единице типы массивов, , где каждый индекс начинается с 1; это традиционное соглашение в математике для матриц и математических последовательностей . Некоторые языки, такие как Pascal и Lua, поддерживают типы массивов, основанные на n , минимальные допустимые индексы которых выбираются программистом. Относительные достоинства каждого выбора были предметом жарких споров. Индексация с отсчетом от нуля позволяет избежать «отклонение на единицу» или ошибок ошибок «забора» . [10] в частности, отсчет от 0 for (i = 0; i < 5; i += 1) повторяется (5-0) раз, тогда как в эквивалентном полуоткрытом диапазоне, отсчитываемом от 1 for (i = 1; i < 6; i += 1) цифра 6 сама по себе является потенциальной такой ошибкой, обычно требующей length() + 1и включающий диапазон, отсчитываемый от 1. for (i = 1; i <= 5; i+= 1) повторяется (5-1)+1 раз.
Самый высокий индекс
[ редактировать ]Связь между числами, появляющимися в объявлении массива, и индексом последнего элемента этого массива также зависит от языка. Во многих языках (например, C) необходимо указывать количество элементов, содержащихся в массиве; тогда как в других (таких как Pascal и Visual Basic .NET ) следует указать числовое значение индекса последнего элемента. Излишне говорить, что это различие несущественно в языках, где индексы начинаются с 1, таких как Lua .
Алгебра массивов
[ редактировать ]Некоторые языки программирования поддерживают программирование массивов , где операции и функции, определенные для определенных типов данных, неявно расширяются на массивы элементов этих типов. можно написать A + B , чтобы добавить соответствующие элементы двух массивов A и B. Таким образом , Обычно эти языки обеспечивают как поэлементное умножение , так и стандартное матричное произведение , линейной алгебры и то, какое из них представлено оператором * , зависит от языка.
Языки, обеспечивающие возможности программирования массивов, получили широкое распространение после появления инноваций в этой области APL . Это основные возможности предметно-ориентированных языков, таких как ГАУСС , IDL , Matlab и Mathematica . Они являются основным средством в новых языках, таких как Julia и последние версии Fortran . Эти возможности также предоставляются через стандартные библиотеки расширений для других языков программирования общего назначения (например, широко используемая библиотека NumPy для Python ).
Строковые типы и массивы
[ редактировать ]Многие языки предоставляют встроенный строковый тип данных со специальной нотацией (« строковые литералы ») для построения значений этого типа. В некоторых языках (например, C) строка представляет собой просто массив символов или обрабатывается примерно таким же образом. Другие языки, такие как Паскаль , могут предоставлять совершенно другие операции со строками и массивами.
Запросы диапазона индекса массива
[ редактировать ]Некоторые языки программирования предоставляют операции, которые возвращают размер (количество элементов) вектора или, в более общем плане, диапазон каждого индекса массива. В C и C++ массивы не поддерживают функцию размера , поэтому программистам часто приходится объявлять отдельную переменную для хранения размера и передавать ее процедурам как отдельный параметр.
Элементы вновь созданного массива могут иметь неопределенные значения (как в C) или могут иметь определенное значение «по умолчанию», например 0 или нулевой указатель (как в Java).
В C++ объект std::vector поддерживает операции хранения , выбора и добавления с характеристиками производительности, описанными выше. У векторов можно запросить размер и изменить их размер. Также поддерживаются более медленные операции, такие как вставка элемента в середину.
Нарезка
[ редактировать ]Операция разрезания массива берет подмножество элементов объекта типа массива (значения или переменной), а затем собирает их в другой объект типа массива, возможно, с другими индексами. Если типы массивов реализованы как структуры массива, многие полезные операции разрезания (такие как выбор подмассива, замена индексов или изменение направления индексов на противоположное) могут выполняться очень эффективно, манипулируя вектором примеси структуры. Возможные срезы зависят от деталей реализации: например, FORTRAN позволяет отрезать один столбец матричной переменной, но не строку, и обрабатывать ее как вектор; тогда как C позволяет отрезать строку от матрицы, но не столбец.
С другой стороны, другие операции среза возможны, когда типы массивов реализованы другими способами.
Изменение размера
[ редактировать ]Некоторые языки допускают динамические массивы (также называемые изменяемым размером, расширяемыми или расширяемыми): переменные массива, диапазоны индексов которых могут быть расширены в любое время после создания без изменения значений его текущих элементов.
Для одномерных массивов эта возможность может быть предоставлена как операция " append( A , x )", который увеличивает размер массива A на единицу, а затем устанавливает значение последнего элемента равным x . Другие типы массивов (например, строки Паскаля) предоставляют оператор конкатенации, который можно использовать вместе с нарезкой для добиться этого эффекта и даже большего. В некоторых языках присвоение значения элементу массива при необходимости автоматически расширяет массив, включив в него этот элемент. В других типах массивов срез можно заменить массивом другого размера с помощью последующие элементы перенумеровываются соответствующим образом – как в присвоении списка Python « A [5:5] = [10,20,30]», которое вставляет три новых элемента (10,20 и 30) перед элементом « A [5]». Массивы изменяемого размера концептуально похожи на списки , и в некоторых языках эти две концепции являются синонимами.
Расширяемый массив может быть реализован как массив фиксированного размера со счетчиком, который записывает, сколько элементов фактически используется. append операция просто увеличивает счетчик; до тех пор, пока не будет использован весь массив, когда append операция может быть определена как неудачная. Это реализация динамического массива с фиксированной емкостью, как в string тип Паскаля. Альтернативно, append операция может перераспределить базовый массив большего размера и скопировать старые элементы в новую область.
См. также
[ редактировать ]- Анализ доступа к массиву
- Система управления массивом баз данных
- Устранение проверки границ
- Значения, разделенные разделителями
- Проверка индекса
- Параллельный массив
- Разреженный массив
- Массив переменной длины
Ссылки
[ редактировать ]- ^ Jump up to: а б Роберт В. Себеста (2001) Концепции языков программирования . Аддисон-Уэсли. 4-е издание (1998 г.), 5-е издание (2001 г.), ISBN 9780201385960
- ^ «Введение в тензоры | TensorFlow Core» . ТензорФлоу .
- ^ К. Йенсен и Никлаус Вирт, Руководство пользователя и отчет PASCAL . Спрингер. Издание в мягкой обложке (2007 г.), 184 страницы, ISBN 978-3540069508
- ^ Джон Митчелл, Концепции языков программирования . Издательство Кембриджского университета.
- ^ Лукхам, Сузуки (1979), «Проверка операций с массивами, записями и указателями в Паскале». Транзакции ACM на языках и системах программирования 1 (2), 226–244.
- ^ Дейтел, Харви М.; Дейтел, Пол Дж. (2005). C# для программистов . Прентис Холл Профессионал. п. 303. ИСБН 978-0-13-246591-5 . Проверено 22 мая 2024 г.
- ^ Фризен, Джефф (5 марта 2014 г.). Изучите Java для разработки под Android: Java 8 и Android 5 Edition . Апресс. п. 56. ИСБН 978-1-4302-6455-2 . Проверено 22 мая 2024 г.
- ^ Брайан В. Керниган и Деннис М. Ричи (1988), Язык программирования C . Прентис-Холл, с. 81.
- ^ Керниган, Брайан В.; Ричи, Деннис М. (1988). Язык программирования C (2-е изд.). Энглвуд Клиффс, Нью-Джерси: Прентис Холл. п. 24. ISBN 978-0-13-110370-2 .
- ^ Эдсгер В. Дейкстра , « Почему нумерация должна начинаться с нуля »