Тунсталл кодирование
В информатике и теории информации кодирование Танстолла представляет собой форму энтропийного кодирования, используемую для сжатия данных без потерь .
История [ править ]
Кодирование Танстолла было предметом докторской диссертации Брайана Паркера Танстолла в 1967 году, когда он работал в Технологическом институте Джорджии. Темой дипломной работы был «Синтез бесшумных кодов сжатия». [1]
Его дизайн является предшественником Лемпеля-Зива .
Свойства [ править ]
В отличие от кодов переменной длины , к которым относятся Хаффмана и кодирование Лемпеля-Зива , Кодирование Танстолла — это код , который отображает исходные символы в фиксированное количество битов. [2]
И коды Танстолла, и коды Лемпеля – Зива представляют слова переменной длины с помощью кодов фиксированной длины. [3]
В отличие от типичного наборного кодирования , кодирование Танстолла анализирует стохастический источник с кодовыми словами переменной длины.
Это можно показать [4] что для достаточно большого словаря количество бит на букву источника может быть сколь угодно близко к , энтропия источника.

Алгоритм [ править ]
Алгоритм требует в качестве входных данных входной алфавит. , а также распределение вероятностей для каждого входного слова. Также требуется произвольная константа , который является верхней границей размера словаря, который он будет вычислять. Словарь, о котором идет речь, , строится как дерево вероятностей, в котором каждому ребру соответствует буква входного алфавита. Алгоритм выглядит следующим образом:



D := tree of leaves, one for each letter in . While : Convert most probable leaf to tree with leaves.


Пример [ править ]
Эту статью может потребовать очистки Википедии , чтобы она соответствовала стандартам качества . Конкретная проблема заключается в следующем: неправильные вероятности. ( Август 2014 г. ) |
Давайте представим, что мы хотим закодировать строку «привет, мир». Далее предположим (несколько нереалистично), что входной алфавит содержит только символы из строки «привет, мир» — то есть «h», «e», «l», «,», «», «w», «o», «r», «d». Таким образом, мы можем вычислить вероятность каждого символа на основе его статистического появления во входной строке. Например, буква L встречается трижды в строке из 12 символов: ее вероятность равна .

Мы инициализируем дерево, начиная с дерева листья. Таким образом, каждое слово напрямую связано с буквой алфавита. 9 слов, которые мы таким образом получаем, можно закодировать в выходной файл фиксированного размера: биты.


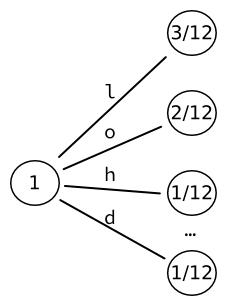
Затем мы берем лист наибольшей вероятности (здесь ) и преобразовать его в еще одно дерево листья, по одному на каждого персонажа. Мы пересчитываем вероятности этих листьев. Например, последовательность двух букв L встречается один раз. Учитывая, что есть три появления букв, за которыми следует буква L, результирующая вероятность равна .


Мы получаем 17 слов, каждое из которых можно закодировать в выходные данные фиксированного размера. биты.

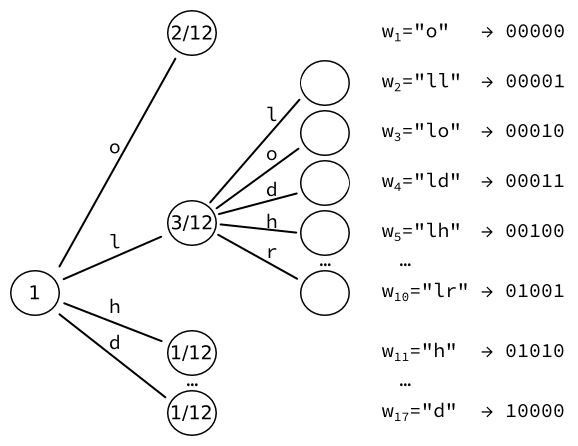
Обратите внимание, что мы могли бы выполнить итерацию дальше, увеличив количество слов на каждый раз.

Ограничения [ править ]
Кодирование Танстолла требует, чтобы алгоритм перед операцией синтаксического анализа знал, каково распределение вероятностей для каждой буквы алфавита. Эта проблема является общей для кодирования Хаффмана .
Требование вывода блока фиксированной длины делает его меньшим, чем Lempel-Ziv , который имеет аналогичную конструкцию на основе словаря, но с выходом блока переменного размера. [ нужны разъяснения ]
Подразумеваемое чтение для базовой модификации [ править ]

Это пример кода Танстолла, используемого для чтения (для передачи) любых данных, которые зашифрованы, например, с помощью полиномиального скремблирования. Этот конкретный пример помогает изменить базу данных с 2 до 3 в потоке, что позволяет избежать дорогостоящих процедур модификации базы. При базовой модификации мы особенно ограничены «эффективностью» чтения, где в идеале биты используются в среднем для чтения кода. Это гарантирует, что при использовании новой базы, которую обязаны использовать в лучшем случае бит на код, наши чтения не приводят к снижению запаса эффективности передачи, для чего мы в первую очередь используем базовую модификацию. Таким образом, мы можем затем использовать механизм чтения для изменения базы для эффективной передачи данных по каналам, которые имеют другую базу. например. передача двоичных данных, скажем, по каналам MLT-3 с повышенной эффективностью по сравнению с кодами отображения (с большим количеством неиспользуемых кодов).

| Символ | Код |
|---|---|
| АА | 010 |
| АБ | 011 |
| переменного тока | 100 |
| Б | 00 |
| ЧТО | 101 |
| КБ | 110 |
| СС | 111 |
По сути, мы читаем идеально зашифрованные двоичные данные или «подразумеваемые данные» с целью их передачи с использованием каналов счисления с основанием 3. См. листовые узлы в троичном дереве туннелей. Как мы видим, чтение приведет к тому, что первая цифра будет равна «B» - в 25% случаев, поскольку подразумеваемая вероятность ее равна 25% и имеет длину 2 при попытке чтения из подразумеваемых данных. Такое чтение «В» дальше не читается, но с вероятностью 75% мы читаем «А» или «С», требуя другой код. Таким образом, эффективность чтения равна 2,75 (средняя длина кода Хаффмана размером 7) / 1,75 (средняя длина 1 или 2-значного кода по основанию - 3 кода Танстолла) = что согласно требованию очень близко к который рассчитывается с эффективностью . Затем мы можем эффективно передавать символы, используя каналы с основанием 3.



Ссылки [ править ]
- ^ Танстолл, Брайан Паркер (сентябрь 1967 г.). Синтез бесшумных кодов сжатия . Технологический институт Джорджии .
- ^ http://www.rle.mit.edu/rgallager/documents/notes1.pdf , Исследование алгоритма Танстолла в Массачусетском технологическом институте.
- ^ «Адаптивное исходное кодирование переменной или фиксированной длины - кодирование Лемпеля-Зива». [1] [2]
- ^ [3] , Исследование алгоритма Танстолла, проведенное . отделом теории информации EPFL
сжатия данных Методы | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| без потерь |
| ||||||||
| с потерями |
| ||||||||
| Аудио |
| ||||||||
| Изображение |
| ||||||||
| Видео |
| ||||||||
| Теория | |||||||||
| Сообщество | |||||||||
| Люди | |||||||||