Модель базы данных
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( июнь 2017 г. ) |


Модель базы данных — это тип модели данных , определяющий логическую структуру базы данных . Он фундаментально определяет, каким образом данные могут храниться, организовываться и манипулироваться ими. Самым популярным примером модели базы данных является реляционная модель , в которой используется табличный формат.
Типы
[ редактировать ]Общие логические модели данных для баз данных включают:
- Это самая старая форма модели базы данных. Он был разработан IBM для IMS (системы управления информацией) и представляет собой набор организованных данных в древовидной структуре. Запись БД представляет собой дерево, состоящее из множества групп, называемых сегментами. Он использует отношения «один ко многим» , а доступ к данным также предсказуем.
- Сетевая модель
- Реляционная модель
- Модель сущность-связь
- Объектная модель
- Модель документа
- Модель сущность-атрибут-значение
- Звездный график
Объектно -реляционная база данных объединяет две связанные структуры.
Модели физических данных включают в себя:
Другие модели включают в себя:
- Многомерная модель
- Многозначная модель
- Семантическая модель
- XML-база данных
- Именованный граф
- Тройной магазин
Отношения и функции
[ редактировать ]Данная система управления базами данных может предоставлять одну или несколько моделей. Оптимальная структура зависит от естественной организации данных приложения и требований приложения, которые включают скорость транзакций, надежность, ремонтопригодность, масштабируемость и стоимость. Большинство систем управления базами данных построены на основе одной конкретной модели данных, хотя продукты могут обеспечивать поддержку более чем одной модели.
Различные физические модели данных могут реализовать любую логическую модель. Большинство программ баз данных предлагают пользователю некоторый уровень контроля над настройкой физической реализации, поскольку сделанный выбор оказывает существенное влияние на производительность.
Модель — это не просто способ структурирования данных: она также определяет набор операций, которые можно выполнять с данными. [1] Например, реляционная модель определяет такие операции, как select ( project ) и join . Хотя эти операции могут быть неявными на конкретном языке запросов , они обеспечивают основу, на которой строится язык запросов.
Плоская модель
[ редактировать ]
Плоская (или табличная) модель состоит из одного двумерного массива элементов данных , где все элементы данного столбца считаются одинаковыми значениями, а все элементы строки считаются связанными друг с другом. Например, столбцы для имени и пароля, которые могут использоваться как часть базы данных безопасности системы. Каждая строка будет иметь определенный пароль, связанный с отдельным пользователем. Столбцы таблицы часто имеют связанный с ними тип, определяющий их как символьные данные, информацию о дате или времени, целые числа или числа с плавающей запятой. Этот табличный формат является предшественником реляционной модели.
Ранние модели данных
[ редактировать ]Эти модели были популярны в 1960-х, 1970-х годах, но в настоящее время их можно встретить преимущественно в старых устаревших системах . Они характеризуются прежде всего тем, что они навигационные , с сильными связями между их логическими и физическими представлениями и недостатками независимости данных .
Иерархическая модель
[ редактировать ]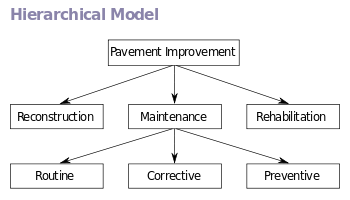
В иерархической модели данные организованы в древовидную структуру , подразумевающую наличие одного родительского элемента для каждой записи. Поле сортировки хранит одноуровневые записи в определенном порядке. Иерархические структуры широко использовались в ранних системах управления базами данных для мэйнфреймов, таких как система управления информацией (IMS) от IBM , и теперь описывают структуру XML- документов. Эта структура обеспечивает связь «один ко многим» между двумя типами данных. Эта структура очень эффективна для описания многих отношений в реальном мире; рецепты, оглавление, порядок абзацев/стихов, любая вложенная и отсортированная информация.
Эта иерархия используется как физический порядок записей в хранилище. Доступ к записи осуществляется путем перемещения вниз по структуре данных с использованием указателей в сочетании с последовательным доступом. По этой причине иерархическая структура неэффективна для определенных операций с базой данных, когда для каждой записи не включен полный путь (в отличие от восходящей ссылки и поля сортировки). Такие ограничения были компенсированы в более поздних версиях IMS дополнительными логическими иерархиями, наложенными на базовую физическую иерархию.
Сетевая модель
[ редактировать ]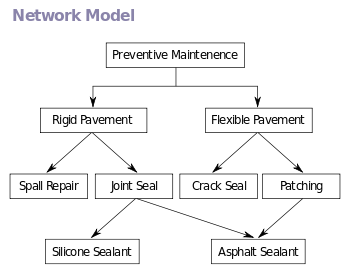
Сетевая модель расширяет иерархическую структуру, допуская отношения «многие ко многим» в древовидной структуре, допускающей наличие нескольких родительских элементов. Она была наиболее популярна до того, как ее заменила реляционная модель, и определяется спецификацией CODASYL .
Сетевая модель организует данные с использованием двух фундаментальных концепций, называемых записями и наборами . Записи содержат поля (которые могут быть организованы иерархически, как в языке программирования COBOL ). Наборы (не путать с математическими наборами) определяют отношения между записями «один ко многим» : один владелец, множество членов. Запись может быть владельцем любого количества наборов и членом любого количества наборов.
Набор состоит из циклических связанных списков, где один тип записи (владелец набора или родительский элемент) появляется один раз в каждом круге, а второй тип записи (подчиненный или дочерний) может появляться в каждом круге несколько раз. Таким образом, между любыми двумя типами записей может быть установлена иерархия, например, тип A является владельцем B. В то же время может быть определено другое множество, где B является владельцем A. Таким образом, все множества составляют общий ориентированный граф. (владение определяет направление) или сетевая конструкция. Доступ к записям осуществляется либо последовательно (обычно в каждом типе записей), либо путем навигации по циклическим связанным спискам.
Сетевая модель способна более эффективно отображать избыточность данных, чем иерархическая модель, и может существовать более одного пути от узла-предка к узлу-потомку. Операции сетевой модели имеют навигационный стиль: программа сохраняет текущую позицию и переходит от одной записи к другой, следуя связям, в которых участвует эта запись. Записи также можно найти, указав значения ключей.
Хотя это не является существенной особенностью модели, сетевые базы данных обычно реализуют заданные отношения посредством указателей , которые напрямую указывают местоположение записи на диске. Это обеспечивает превосходную производительность поиска за счет таких операций, как загрузка и реорганизация базы данных.
Популярными СУБД, в которых он использовался, были Total от Cincom Systems и Cullinet от IDMS . IDMS приобрела значительную клиентскую базу; в 1980-х годах в дополнение к исходным инструментам и языкам была принята реляционная модель и SQL.
Большинство объектных баз данных (изобретенных в 1990-х годах) используют концепцию навигации для обеспечения быстрой навигации по сетям объектов, обычно используя идентификаторы объектов в качестве «умных» указателей на связанные объекты. Objectivity/DB Например, реализует именованные отношения «один к одному», «один ко многим», «многие к одному» и «многие ко многим», которые могут пересекать базы данных. Многие объектные базы данных также поддерживают SQL , сочетая в себе сильные стороны обеих моделей.
Инвертированная файловая модель
[ редактировать ]В инвертированном файле или инвертированном индексе содержимое данных используется в качестве ключей в таблице поиска, а значения в таблице являются указателями на местоположение каждого экземпляра данного элемента контента. Это также логическая структура современных индексов баз данных , которые могут использовать только содержимое определенных столбцов таблицы поиска. Модель данных инвертированного файла может помещать индексы в набор файлов рядом с существующими плоскими файлами базы данных, чтобы эффективно напрямую обращаться к необходимым записям в этих файлах.
Примечательной особенностью использования этой модели данных является СУБД ADABAS компании Software AG , представленная в 1970 году. ADABAS приобрел значительную клиентскую базу и существует и поддерживается до сегодняшнего дня. В 1980-х годах в дополнение к исходным инструментам и языкам была принята реляционная модель и SQL.
База данных, ориентированная на документы, Clusterpoint использует инвертированную модель индексации, чтобы обеспечить быстрый полнотекстовый поиск по объектам данных XML или JSON , например, .
Реляционная модель
[ редактировать ]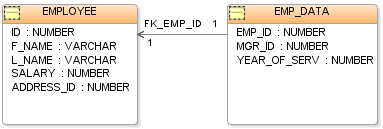
была Реляционная модель представлена Э. Ф. Коддом в 1970 году. [2] как способ сделать системы управления базами данных более независимыми от какого-либо конкретного приложения. Это математическая модель, определенная с точки зрения логики предикатов и теории множеств , и ее реализации использовались мэйнфреймами, системами среднего уровня и микрокомпьютерами.
Продукты, которые обычно называют реляционными базами данных, на самом деле реализуют модель, которая является лишь приближением к математической модели, определенной Коддом. В моделях реляционных баз данных широко используются три ключевых термина: отношения , атрибуты и домены . Отношение — это таблица со столбцами и строками. Именованные столбцы отношения называются атрибутами, а домен — это набор значений, которые атрибуты могут принимать.
Базовой структурой данных реляционной модели является таблица, где информация о конкретной сущности (скажем, о сотруднике) представлена в строках (также называемых кортежами ) и столбцах. Таким образом, « отношение » в «реляционной базе данных» относится к различным таблицам в базе данных; отношение представляет собой набор кортежей. Столбцы перечисляют различные атрибуты сущности (например, имя сотрудника, адрес или номер телефона), а строка представляет собой фактический экземпляр сущности (конкретного сотрудника), представленный отношением. В результате каждый кортеж таблицы сотрудников представляет различные атрибуты одного сотрудника.
Все отношения (и, следовательно, таблицы) в реляционной базе данных должны соответствовать некоторым основным правилам, чтобы квалифицироваться как отношения. Во-первых, порядок столбцов в таблице не имеет значения. Во-вторых, в таблице не может быть одинаковых кортежей или строк. И в-третьих, каждый кортеж будет содержать одно значение для каждого из своих атрибутов.
Реляционная база данных содержит несколько таблиц, каждая из которых аналогична таблице в «плоской» модели базы данных. Одной из сильных сторон реляционной модели является то, что, в принципе, любое значение, встречающееся в двух разных записях (принадлежащих одной и той же таблице или разным таблицам), подразумевает связь между этими двумя записями. Тем не менее, чтобы обеспечить явные ограничения целостности , отношения между записями в таблицах также могут быть определены явно, путем идентификации или неидентификации отношений родитель-потомок, характеризующихся присвоением мощности (1:1, (0)1:M, M:M ). Таблицы также могут иметь назначенный отдельный атрибут или набор атрибутов, которые могут действовать как «ключ», который можно использовать для уникальной идентификации каждого кортежа в таблице.
Ключ, который можно использовать для уникальной идентификации строки в таблице, называется первичным ключом. Ключи обычно используются для объединения или объединения данных из двух или более таблиц. Например, таблица «Сотрудники» может содержать столбец с именем «Местоположение» , который содержит значение, соответствующее ключу таблицы «Местоположение» . Ключи также имеют решающее значение при создании индексов, которые облегчают быстрый поиск данных из больших таблиц. Любой столбец может быть ключом, или несколько столбцов могут быть сгруппированы в составной ключ. Нет необходимости заранее определять все ключи; столбец можно использовать в качестве ключа, даже если он изначально не предназначался для этого.
Ключ, имеющий внешнее, реальное значение (например, имя человека, ISBN книги или серийный номер автомобиля), иногда называют «естественным» ключом. Если естественный ключ не подходит (вспомните многих людей по имени Браун ), можно назначить произвольный или суррогатный ключ (например, предоставив сотрудникам идентификационные номера). На практике большинство баз данных имеют как сгенерированные, так и естественные ключи, поскольку сгенерированные ключи могут использоваться внутри страны для создания связей между строками, которые не могут разорваться, тогда как естественные ключи могут использоваться (менее надежно) для поиска и интеграции с другими базами данных. (Например, записи в двух независимо разработанных базах данных могут сопоставляться по номеру социального страхования , за исключением случаев, когда номера социального страхования неверны, отсутствуют или изменились.)
Наиболее распространенным языком запросов, используемым в реляционной модели, является язык структурированных запросов ( SQL ).
Габаритная модель
[ редактировать ]Многомерная модель — это специализированная адаптация реляционной модели, используемой для представления данных в хранилищах данных таким образом, чтобы данные можно было легко суммировать с помощью онлайн-аналитической обработки или запросов OLAP . В многомерной модели схема базы данных состоит из одной большой таблицы фактов, описываемой с помощью измерений и мер. Измерение предоставляет контекст факта (например, кто участвовал, когда и где это произошло, а также его тип) и используется в запросах для группировки связанных фактов. Измерения имеют тенденцию быть дискретными и часто имеют иерархическую структуру; например, местоположение может включать здание, штат и страну. Мера — это величина, описывающая факт, например доход. Важно, чтобы показатели могли быть осмысленно агрегированы — например, доходы из разных мест можно сложить вместе.
В запросе OLAP выбираются измерения, а факты группируются и агрегируются для создания сводки.
Многомерная модель часто реализуется поверх реляционной модели с использованием звездообразной схемы , состоящей из одной высоконормализованной таблицы, содержащей факты, и окружающих ее денормализованных таблиц, содержащих каждое измерение. Альтернативная физическая реализация, называемая схемой «снежинка» , нормализует многоуровневые иерархии внутри измерения в несколько таблиц.
Хранилище данных может содержать несколько многомерных схем, которые используют общие таблицы измерений, что позволяет использовать их вместе. Создание стандартного набора размеров является важной частью пространственного моделирования .
Высокая производительность сделала многомерную модель самой популярной структурой базы данных для OLAP.
Постреляционные модели баз данных
[ редактировать ]Продукты, предлагающие более общую модель данных, чем реляционная модель, иногда классифицируются как постреляционные . [3] Альтернативные термины включают «гибридную базу данных», «СУБД с объектно-расширенными возможностями» и другие. Модель данных в таких продуктах включает отношения , но не ограничена принципом информации Э. Ф. Кодда , который требует, чтобы
вся информация в базе данных должна быть явно выражена в виде значений в отношениях и никак иначе.
— [4]
Некоторые из этих расширений реляционной модели объединяют концепции технологий, которые предшествовали реляционной модели. Например, они позволяют представить ориентированный граф с деревьями в узлах. Немецкая компания Sones реализует эту концепцию в своей GraphDB .
Некоторые постреляционные продукты расширяют реляционные системы нереляционными функциями. Другие пришли почти к тому же, добавив реляционные функции к дореляционным системам. Парадоксально, но это позволяет продуктам, которые исторически были дореляционными, таким как PICK и MUMPS , сделать правдоподобное заявление о том, что они являются постреляционными.
Модель пространства ресурсов (RSM) — это нереляционная модель данных, основанная на многомерной классификации. [5]
Графовая модель
[ редактировать ]Базы данных графов допускают даже более общую структуру, чем сетевая база данных; любой узел может быть соединен с любым другим узлом.
Многозначная модель
[ редактировать ]Многозначные базы данных представляют собой «кусковые» данные, поскольку они могут храниться точно так же, как и реляционные базы данных, но они также допускают уровень глубины, который реляционная модель может лишь аппроксимировать с помощью подтаблиц. Это почти идентично тому, как XML выражает данные, где данное поле/атрибут может иметь несколько правильных ответов одновременно. Многозначность можно рассматривать как сжатую форму XML.
Примером является счет-фактура, который в многозначных или реляционных данных можно рассматривать как (A) Таблица заголовка счета-фактуры — одна запись для каждого счета-фактуры и (B) Таблица сведений о счете-фактуре — одна запись для каждой отдельной позиции. В многозначной модели у нас есть возможность хранить данные в виде таблицы со встроенной таблицей для представления подробностей: (A) Таблица счетов — одна запись для каждого счета, другие таблицы не нужны.
Преимущество состоит в том, что атомарность Счета-фактуры (концептуального) и Счета-фактуры (представления данных) взаимно однозначно. Это также приводит к меньшему количеству операций чтения, уменьшению проблем ссылочной целостности и резкому уменьшению количества аппаратного обеспечения, необходимого для поддержки заданного объема транзакций.
Объектно-ориентированные модели баз данных
[ редактировать ]
В 1990-х годах парадигма объектно-ориентированного программирования была применена к технологии баз данных, создав новую модель базы данных, известную как объектные базы данных . Это направлено на то, чтобы избежать несоответствия объектно-реляционного импеданса - накладных расходов на преобразование информации между ее представлением в базе данных (например, в виде строк в таблицах) и ее представлением в прикладной программе (обычно в виде объектов). Более того, система типов, используемая в конкретном приложении, может быть определена непосредственно в базе данных, что позволяет базе данных применять одни и те же инварианты целостности данных. ключевые идеи объектного программирования, такие как инкапсуляция и полиморфизм Объектные базы данных также привносят в мир баз данных .
Были опробованы различные способы хранения объектов в базе данных. Некоторый [ который? ] продукты подошли к проблеме со стороны прикладного программирования, сделав объекты, которыми манипулирует программа, постоянными . Обычно для этого требуется добавление какого-либо языка запросов, поскольку традиционные языки программирования не имеют возможности находить объекты на основе их информационного содержания. Другие [ который? ] решили проблему со стороны базы данных, определив объектно-ориентированную модель данных для базы данных и определив язык программирования базы данных, который обеспечивает полные возможности программирования, а также традиционные средства запросов.
Объектные базы данных пострадали из-за отсутствия стандартизации: хотя стандарты были определены ODMG , они никогда не были реализованы достаточно хорошо, чтобы обеспечить совместимость между продуктами. Тем не менее, объектные базы данных успешно используются во многих приложениях: обычно в специализированных приложениях, таких как инженерные базы данных или базы данных молекулярной биологии, а не в основной коммерческой обработке данных. Однако идеи объектных баз данных были подхвачены поставщиками реляционных систем и повлияли на расширения, сделанные для этих продуктов, а также для языка SQL .
Альтернативой преобразованию между объектами и реляционными базами данных является использование библиотеки объектно-реляционного сопоставления (ORM).
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Эльмасри, Рамез; Навате, Шамкант (2016). Основы систем баз данных (Седьмое изд.). п. 33. ISBN 9780133970777 .
- ^ Э. Ф. Кодд (1970). «Реляционная модель данных для крупных общих банков данных». В: Сообщения архива ACM . Том 13. Выпуск 6 (июнь 1970 г.). стр.377-387.
- ^ Представляем базы данных Стивена Чу, Конрик, М. (2006) Информатика здравоохранения: преобразование здравоохранения с помощью технологий , Томсон, ISBN 0-17-012731-1 , с. 69.
- ^ Дата, CJ (1 июня 1999 г.). «Когда расширение не является расширением?» . Интеллектуальное предприятие . 2 (8).
- ^ Чжугэ, Х. (2008). Модель пространства веб-ресурсов . Серия книг по проектированию веб-информационных систем и интернет-технологиям. Том. 4. Спрингер. ISBN 978-0-387-72771-4 .