Идет судьба
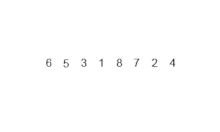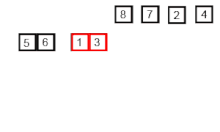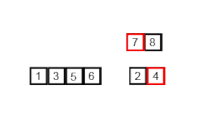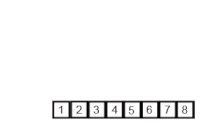 Пример сортировки слиянием. Сначала разделите список на наименьшую единицу (1 элемент), затем сравните каждый элемент с соседним списком, чтобы отсортировать и объединить два соседних списка. Наконец, все элементы сортируются и объединяются. | |
| Сорт | Алгоритм сортировки |
|---|---|
| Структура данных | Множество |
| Худшая производительность | |
| Лучшая производительность | типичный, естественный вариант |
| Средняя производительность | |
| Наихудшая пространственная сложность | всего с вспомогательный, вспомогательный со связанными списками [1] |






В информатике общего назначения , сортировка слиянием (также часто называемая сортировкой слиянием ) — это эффективный основанный на сравнении алгоритм сортировки . Большинство реализаций создают стабильную сортировку , что означает, что относительный порядок одинаковых элементов во входных и выходных данных одинаков. Сортировка слиянием — это алгоритм «разделяй и властвуй» , изобретенный Джоном фон Нейманом в 1945 году. [2] Подробное описание и анализ восходящей сортировки слиянием появилось в отчете Голдстайна и фон Неймана еще в 1948 году. [3]
Алгоритм [ править ]
Концептуально сортировка слиянием работает следующим образом:
- Разделите несортированный список на n подсписков, каждый из которых содержит один элемент (список из одного элемента считается отсортированным).
- Повторно объединяйте подсписки для создания новых отсортированных подсписков, пока не останется только один подсписок. Это будет отсортированный список.
Реализация сверху вниз [ править ]
Пример C-подобного кода, использующего индексы для алгоритма сортировки слиянием сверху вниз, который рекурсивно разбивает список (называемый в этом примере прогонами ) на подсписки до тех пор, пока размер подсписка не станет равным 1, а затем объединяет эти подсписки для создания отсортированного списка. Шаг обратного копирования исключается за счет изменения направления слияния на каждом уровне рекурсии (за исключением первоначального однократного копирования, которого тоже можно избежать).
В качестве простого примера рассмотрим массив из двух элементов. Элементы копируются в B[], а затем объединяются обратно в A[]. Если имеется четыре элемента, то при достижении нижней части уровня рекурсии отдельные прогоны элементов из A[] объединяются с B[], а затем на следующем более высоком уровне рекурсии эти двухэлементные прогоны объединяются с A[ ]. Этот шаблон продолжается на каждом уровне рекурсии.
// Array A[] has the items to sort; array B[] is a work array.
void TopDownMergeSort(A[], B[], n)
{
CopyArray(A, 0, n, B); // one time copy of A[] to B[]
TopDownSplitMerge(A, 0, n, B); // sort data from B[] into A[]
}
// Split A[] into 2 runs, sort both runs into B[], merge both runs from B[] to A[]
// iBegin is inclusive; iEnd is exclusive (A[iEnd] is not in the set).
void TopDownSplitMerge(B[], iBegin, iEnd, A[])
{
if (iEnd - iBegin <= 1) // if run size == 1
return; // consider it sorted
// split the run longer than 1 item into halves
iMiddle = (iEnd + iBegin) / 2; // iMiddle = mid point
// recursively sort both runs from array A[] into B[]
TopDownSplitMerge(A, iBegin, iMiddle, B); // sort the left run
TopDownSplitMerge(A, iMiddle, iEnd, B); // sort the right run
// merge the resulting runs from array B[] into A[]
TopDownMerge(B, iBegin, iMiddle, iEnd, A);
}
// Left source half is A[ iBegin:iMiddle-1].
// Right source half is A[iMiddle:iEnd-1 ].
// Result is B[ iBegin:iEnd-1 ].
void TopDownMerge(B[], iBegin, iMiddle, iEnd, A[])
{
i = iBegin, j = iMiddle;
// While there are elements in the left or right runs...
for (k = iBegin; k < iEnd; k++) {
// If left run head exists and is <= existing right run head.
if (i < iMiddle && (j >= iEnd || A[i] <= A[j])) {
B[k] = A[i];
i = i + 1;
} else {
B[k] = A[j];
j = j + 1;
}
}
}
void CopyArray(A[], iBegin, iEnd, B[])
{
for (k = iBegin; k < iEnd; k++)
B[k] = A[k];
}
Сортировка всего массива осуществляется путем TopDownMergeSort(A, B, длина(A)) .
Реализация снизу вверх [ править ]
Пример C-подобного кода, использующего индексы для алгоритма сортировки слиянием снизу вверх, который рассматривает список как массив из n подсписков (в этом примере называемых прогонами ) размера 1 и итеративно объединяет подсписки вперед и назад между двумя буферами:
// array A[] has the items to sort; array B[] is a work array
void BottomUpMergeSort(A[], B[], n)
{
// Each 1-element run in A is already "sorted".
// Make successively longer sorted runs of length 2, 4, 8, 16... until the whole array is sorted.
for (width = 1; width < n; width = 2 * width)
{
// Array A is full of runs of length width.
for (i = 0; i < n; i = i + 2 * width)
{
// Merge two runs: A[i:i+width-1] and A[i+width:i+2*width-1] to B[]
// or copy A[i:n-1] to B[] ( if (i+width >= n) )
BottomUpMerge(A, i, min(i+width, n), min(i+2*width, n), B);
}
// Now work array B is full of runs of length 2*width.
// Copy array B to array A for the next iteration.
// A more efficient implementation would swap the roles of A and B.
CopyArray(B, A, n);
// Now array A is full of runs of length 2*width.
}
}
// Left run is A[iLeft :iRight-1].
// Right run is A[iRight:iEnd-1 ].
void BottomUpMerge(A[], iLeft, iRight, iEnd, B[])
{
i = iLeft, j = iRight;
// While there are elements in the left or right runs...
for (k = iLeft; k < iEnd; k++) {
// If left run head exists and is <= existing right run head.
if (i < iRight && (j >= iEnd || A[i] <= A[j])) {
B[k] = A[i];
i = i + 1;
} else {
B[k] = A[j];
j = j + 1;
}
}
}
void CopyArray(B[], A[], n)
{
for (i = 0; i < n; i++)
A[i] = B[i];
}
Реализация сверху вниз с использованием списков [ править ]
Псевдокод для алгоритма сортировки слиянием сверху вниз, который рекурсивно делит входной список на более мелкие подсписки до тех пор, пока подсписки не будут тривиально отсортированы, а затем объединяет подсписки, возвращаясь вверх по цепочке вызовов.
function merge_sort(list m) is
// Base case. A list of zero or one elements is sorted, by definition.
if length of m ≤ 1 then
return m
// Recursive case. First, divide the list into equal-sized sublists
// consisting of the first half and second half of the list.
// This assumes lists start at index 0.
var left := empty list
var right := empty list
for each x with index i in m do
if i < (length of m)/2 then
add x to left
else
add x to right
// Recursively sort both sublists.
left := merge_sort(left)
right := merge_sort(right)
// Then merge the now-sorted sublists.
return merge(left, right)
В этом примере Функция слияния объединяет левый и правый подсписки.
function merge(left, right) is
var result := empty list
while left is not empty and right is not empty do
if first(left) ≤ first(right) then
append first(left) to result
left := rest(left)
else
append first(right) to result
right := rest(right)
// Either left or right may have elements left; consume them.
// (Only one of the following loops will actually be entered.)
while left is not empty do
append first(left) to result
left := rest(left)
while right is not empty do
append first(right) to result
right := rest(right)
return result
Реализация снизу вверх с использованием списков [ править ]
Псевдокод для алгоритма сортировки слиянием снизу вверх, который использует небольшой массив ссылок на узлы фиксированного размера, где array[i] — это либо ссылка на список размером 2. я или ноль . node — это ссылка или указатель на узел. Функция merge() аналогична той, что показана в примере слияния списков сверху вниз: она объединяет два уже отсортированных списка и обрабатывает пустые списки. В этом случае merge() будет использовать node в качестве входных параметров и возвращаемого значения.
function merge_sort(node head) is
// return if empty list
if head = nil then
return nil
var node array[32]; initially all nil
var node result
var node next
var int i
result := head
// merge nodes into array
while result ≠ nil do
next := result.next;
result.next := nil
for (i = 0; (i < 32) && (array[i] ≠ nil); i += 1) do
result := merge(array[i], result)
array[i] := nil
// do not go past end of array
if i = 32 then
i -= 1
array[i] := result
result := next
// merge array into single list
result := nil
for (i = 0; i < 32; i += 1) do
result := merge(array[i], result)
return result
Реализация сверху вниз в декларативном стиле [ править ]
Haskell -подобный псевдокод, показывающий, как сортировка слиянием может быть реализована на таком языке с использованием конструкций и идей функционального программирования .
merge_sort :: [a] -> [a]
merge_sort([]) = []
merge_sort([x]) = [x]
merge_sort(xs) = merge(merge_sort(left), merge_sort(right))
where (left, right) = split(xs, length(xs) / 2)
merge :: ([a], [a]) -> [a]
merge([], xs) = xs
merge(xs, []) = xs
merge(x : xs, y : ys)
| if x ≤ y = x : merge(xs, y : ys)
| else = y : merge(x : xs, ys)
Анализ [ править ]

При сортировке n объектов сортировка слиянием имеет среднюю и наихудшую производительность сравнений O ( n log n ). Если время выполнения (количество сравнений) сортировки слиянием для списка длины n равно T ( n ), то рекуррентное соотношение T ( n ) = 2 T ( n /2) + n следует из определения алгоритма ( применить алгоритм к двум спискам размером в два раза меньше исходного списка и добавить n шагов, предпринятых для объединения двух полученных списков). [4] Замкнутая форма следует из основной теоремы для повторений по принципу «разделяй и властвуй» .
Количество сравнений, выполненных при сортировке слиянием, в худшем случае определяется числами сортировки . Эти числа равны или немного меньше ( n ⌈ lg n ⌉ − 2 ⌈lg n ⌉ + 1), которое находится между ( n lg n − n + 1) и ( n lg n + n + O(lg n )). [5] В лучшем случае сортировки слиянием требуется примерно вдвое меньше итераций, чем в худшем случае. [6]
Для большого n и случайно упорядоченного входного списка ожидаемое (среднее) число сравнений сортировки слиянием приближается к α · n меньше, чем в худшем случае, где

В худшем случае сортировка слиянием использует примерно на 39% меньше сравнений, чем быстрая сортировка в среднем случае, а с точки зрения ходов сложность наихудшего случая сортировки слиянием равна O ( n log n ) — такая же сложность, как и лучший вариант быстрой сортировки. [6]
Сортировка слиянием более эффективна, чем быстрая сортировка, для некоторых типов списков, если к сортируемым данным можно эффективно получить только последовательный доступ, и поэтому она популярна в таких языках, как Lisp , где структуры данных с последовательным доступом очень распространены. В отличие от некоторых (эффективных) реализаций быстрой сортировки, сортировка слиянием является стабильной сортировкой.
Наиболее распространенная реализация сортировки слиянием не выполняет сортировку на месте; [7] следовательно, объем входной памяти должен быть выделен для хранения отсортированного вывода (см. ниже варианты, которым требуется только n /2 дополнительных пробелов).
Естественная сортировка слиянием [ править ]
Естественная сортировка слиянием аналогична сортировке слиянием снизу вверх, за исключением того, что любые естественные серии во входных данных используются (отсортированные последовательности). Могут быть использованы как монотонные, так и битонные (попеременные вверх/вниз) прогоны, при этом списки (или, что эквивалентно, ленты или файлы) являются удобными структурами данных (используются в качестве очередей FIFO или стеков LIFO ). [8] При сортировке слиянием снизу вверх исходная точка предполагает, что длина каждого прогона составляет один элемент. На практике случайные входные данные будут иметь множество коротких периодов, которые просто сортируются. В типичном случае естественная сортировка слиянием может не требовать такого количества проходов, поскольку требуется меньшее количество проходов для слияния. В лучшем случае входные данные уже отсортированы (т. е. выполнены за один проход), поэтому для естественной сортировки слиянием достаточно выполнить только один проход по данным. Во многих практических случаях присутствуют длинные естественные прогоны, и по этой причине естественная сортировка слиянием используется как ключевой компонент Timsort . Пример:
Start : 3 4 2 1 7 5 8 9 0 6 Select runs : (3 4)(2)(1 7)(5 8 9)(0 6) Merge : (2 3 4)(1 5 7 8 9)(0 6) Merge : (1 2 3 4 5 7 8 9)(0 6) Merge : (0 1 2 3 4 5 6 7 8 9)
Формально естественная сортировка слиянием называется Runs -optimal, где это количество запусков в , минус один.


Сортировки выбора замены турнира используются для сбора начальных прогонов для внешних алгоритмов сортировки.
Сортировка слиянием в пинг-понге [ править ]
Вместо объединения двух блоков за раз, слияние в пинг-понге объединяет четыре блока за раз. Четыре отсортированных блока одновременно объединяются во вспомогательное пространство в два отсортированных блока, затем два отсортированных блока объединяются обратно в основную память. При этом операция копирования исключается и общее количество ходов уменьшается вдвое. Ранняя общедоступная реализация слияния «четыре одновременно» была реализована WikiSort в 2014 году. Позже в том же году этот метод был описан как оптимизация для терпеливой сортировки и назван слиянием «пинг-понг». [9] [10] Quadsort реализовала этот метод в 2020 году и назвала его четырехкратным слиянием. [11]
Сортировка слиянием на месте [ править ]
Одним из недостатков сортировки слиянием при реализации на массивах является требование O ( n ) рабочей памяти. сортировки слиянием несколько методов уменьшения памяти или полной Было предложено :
- Кронрод (1969) предложил альтернативную версию сортировки слиянием, в которой используется постоянное дополнительное пространство.
- Катаджайнен и др. представить алгоритм, который требует постоянного объема рабочей памяти: достаточно места для хранения одного элемента входного массива и дополнительного места для хранения указателей O (1) во входном массиве. Они достигают времени O ( n log n ) с небольшими константами, но их алгоритм нестабилен. [12]
- Было предпринято несколько попыток создать алгоритм слияния на месте , который можно объединить со стандартной сортировкой слиянием (сверху вниз или снизу вверх) для создания сортировки слиянием на месте. В этом случае понятие «на месте» можно ослабить до значения «занимать логарифмическое пространство стека», поскольку стандартная сортировка слиянием требует такого количества места для собственного использования стека. Это было показано Geffert et al. что стабильное слияние на месте возможно за время O ( n log n ) с использованием постоянного объема рабочего пространства, но их алгоритм сложен и имеет высокие постоянные коэффициенты: объединение массивов длины n и m может занять 5 n + 12 m. + o ( м ) движется. [13] Этот высокий постоянный коэффициент и сложный алгоритм на месте стали проще и понятнее. Бин-Чао Хуан и Майкл А. Лэнгстон [14] представил простой алгоритм линейного времени, практическое слияние на месте для объединения отсортированного списка с использованием фиксированного объема дополнительного пространства. Оба они использовали работы Кронрода и других. Он сливается в линейном времени и постоянном дополнительном пространстве. Этот алгоритм в среднем занимает немного больше времени, чем стандартные алгоритмы сортировки слиянием, позволяя использовать O(n) временных дополнительных ячеек памяти, менее чем в два раза. Хотя на практике алгоритм намного быстрее, но он нестабильен и для некоторых списков. Но используя аналогичные концепции, они смогли решить эту проблему. Другие встроенные алгоритмы включают SymMerge, который занимает в общей сложности O (( n + m ) log ( n + m )) времени и является стабильным. [15] Подключение такого алгоритма к сортировке слиянием увеличивает его сложность до нелинейной , но все же квазилинейной , O ( n (log n ) 2 ) .
- Многие приложения внешней сортировки используют форму сортировки слиянием, при которой входные данные разбиваются на большее количество подсписков, в идеале на такое количество, для которого их объединение по-прежнему позволяет помещать обрабатываемый в данный момент набор страниц в основную память.
- Современный стабильный вариант линейного слияния и слияния на месте — это сортировка слиянием блоков , при которой создается раздел уникальных значений для использования в качестве пространства подкачки.
- Затраты на пространство можно уменьшить до sqrt( n ), используя двоичный поиск и ротацию. [16] Этот метод используется библиотекой C++ STL и квадросортировкой. [11]
- Альтернативой сокращению копирования в несколько списков является связывание нового поля информации с каждым ключом (элементы в m называются ключами). Это поле будет использоваться для связи ключей и любой связанной с ними информации в отсортированном списке (ключ и связанная с ним информация называются записью). Далее происходит объединение отсортированных списков путем изменения значений ссылок; никакие записи перемещать вообще не нужно. Поле, содержащее только ссылку, обычно будет меньше всей записи, поэтому будет использоваться меньше места. Это стандартный метод сортировки, не ограничивающийся сортировкой слиянием.
- Простой способ уменьшить накладные расходы на пространство до n /2 — сохранить лево и право как объединенную структуру, скопировать только левую часть m во временное пространство и указать программе слияния поместить объединенный вывод в m . В этой версии лучше выделить временное пространство вне процедуры слияния , так что потребуется только одно выделение. Упомянутое ранее чрезмерное копирование также смягчается, поскольку последняя пара строк перед оператором возврата результата (функция слияния в приведенном выше псевдокоде) становится лишней.
Использование с ленточными накопителями [ править ]

сортировку Внешнюю слиянием удобно выполнять с использованием дисковых или ленточных накопителей, когда сортируемые данные слишком велики и не помещаются в памяти . Внешняя сортировка объясняет, как сортировка слиянием реализуется на дисках. Типичный тип ленточного накопителя использует четыре ленточных накопителя. Весь ввод-вывод является последовательным (за исключением перемотки в конце каждого прохода). Минимальная реализация может обойтись всего двумя буферами записи и несколькими программными переменными.
Назвав четыре ленточных накопителя как A, B, C, D, с исходными данными в A и используя только два буфера записи, алгоритм аналогичен восходящей реализации , в которой вместо массивов в памяти используются пары ленточных накопителей. Основной алгоритм можно описать следующим образом:
- Объединить пары записей из A; запись подсписков из двух записей поочередно в C и D.
- Объединить подсписки из двух записей из C и D в подсписки из четырех записей; записывая их поочередно в A и B.
- Объединить подсписки из четырех записей из A и B в подсписки из восьми записей; записывая их поочередно на C и D
- Повторяйте, пока не получите один список, содержащий все отсортированные данные — в журнале 2 ( n ). проходит
Вместо того, чтобы начинать с очень коротких прогонов, обычно используется гибридный алгоритм , при котором начальный проход считывает множество записей в память, выполняет внутреннюю сортировку для создания длинного прогона, а затем распределяет эти длинные прогоны на выходной набор. Этот шаг позволяет избежать многих ранних проходов. Например, внутренняя сортировка из 1024 записей позволит сэкономить девять проходов. Внутренняя сортировка часто бывает большой, поскольку она имеет такое преимущество. Фактически, существуют методы, которые могут сделать начальные прогоны дольше, чем доступна внутренняя память. Один из них, «снегоочиститель» Кнута (основанный на двоичной минимальной куче ), генерирует прогоны в два раза длиннее (в среднем), чем размер используемой памяти. [17]
С некоторыми издержками приведенный выше алгоритм можно изменить для использования трех лент. Время работы O ( n log n ) также может быть достигнуто с использованием двух очередей , или стека и очереди, или трех стеков. В другом направлении, используя k > две ленты (и O ( k ) элементов в памяти), мы можем уменьшить количество операций с лентой в O (log k ) раз, используя k/2-путевое слияние .
Более сложная сортировка слиянием, которая оптимизирует использование ленточных (и дисковых) накопителей, — это многофазная сортировка слиянием .
Оптимизация сортировки слиянием [ править ]

На современных компьютерах локальность ссылок может иметь первостепенное значение при оптимизации программного обеспечения , поскольку многоуровневые иерархии памяти используются . Были предложены версии алгоритма сортировки слиянием с поддержкой кэша , операции которых были специально выбраны для минимизации перемещения страниц в кэш-памяти машины и из него. Например, Алгоритм мозаичной сортировки слиянием прекращает разделение подмассивов при достижении подмассивов размера S, где S — количество элементов данных, помещающихся в кеш ЦП. Каждый из этих подмассивов сортируется с помощью алгоритма сортировки на месте, такого как сортировка вставкой , чтобы предотвратить подкачку памяти, а затем обычная сортировка слиянием завершается стандартным рекурсивным способом. Этот алгоритм продемонстрировал лучшую производительность [ нужен пример ] на машинах, которым выгодна оптимизация кэша. ( ЛаМарка и Ладнер, 1997 )
Параллельная сортировка слиянием [ править ]
Сортировка слиянием хорошо распараллеливается благодаря использованию метода «разделяй и властвуй» . За прошедшие годы было разработано несколько различных параллельных вариантов алгоритма. Некоторые алгоритмы параллельной сортировки слиянием тесно связаны с алгоритмом последовательного слияния сверху вниз, в то время как другие имеют другую общую структуру и используют метод слияния K-way .
Сортировка слиянием с параллельной рекурсией [ править ]
Процедуру последовательной сортировки слиянием можно описать в два этапа: этап разделения и этап слияния. Первый состоит из множества рекурсивных вызовов, которые неоднократно выполняют один и тот же процесс деления до тех пор, пока подпоследовательности не будут тривиально отсортированы (содержат один элемент или не содержат его). Интуитивный подход заключается в распараллеливании этих рекурсивных вызовов. [18] Следующий псевдокод описывает сортировку слиянием с параллельной рекурсией с использованием ключевых слов fork и join :
// Sort elements lo through hi (exclusive) of array A.
algorithm mergesort(A, lo, hi) is
if lo+1 < hi then // Two or more elements.
mid := ⌊(lo + hi) / 2⌋
fork mergesort(A, lo, mid)
mergesort(A, mid, hi)
join
merge(A, lo, mid, hi)
Этот алгоритм представляет собой тривиальную модификацию последовательной версии и плохо распараллеливается. Поэтому его ускорение не очень впечатляет. Он диапазон имеет , что является лишь улучшением по сравнению с последовательной версией (см. Введение в алгоритмы ). В основном это связано с методом последовательного слияния, поскольку он является узким местом параллельного выполнения.


Сортировка слиянием с параллельным слиянием [ править ]
Лучшего параллелизма можно добиться, используя алгоритм параллельного слияния . Кормен и др. представить двоичный вариант, который объединяет две отсортированные подпоследовательности в одну отсортированную выходную последовательность. [18]
В одной из последовательностей (более длинной, если длина не одинаковая) выбирается элемент среднего индекса. Его положение в другой последовательности определяется таким образом, чтобы эта последовательность оставалась отсортированной, если бы этот элемент был вставлен в эту позицию. Таким образом, можно узнать, сколько других элементов из обеих последовательностей меньше, и можно вычислить положение выбранного элемента в выходной последовательности. Для частичных последовательностей меньших и больших элементов, созданных таким образом, алгоритм слияния снова выполняется параллельно, пока не будет достигнут базовый случай рекурсии.
Следующий псевдокод демонстрирует модифицированный метод параллельной сортировки слиянием с использованием алгоритма параллельного слияния (заимствованного у Кормена и др.).
/**
* A: Input array
* B: Output array
* lo: lower bound
* hi: upper bound
* off: offset
*/
algorithm parallelMergesort(A, lo, hi, B, off) is
len := hi - lo + 1
if len == 1 then
B[off] := A[lo]
else let T[1..len] be a new array
mid := ⌊(lo + hi) / 2⌋
mid' := mid - lo + 1
fork parallelMergesort(A, lo, mid, T, 1)
parallelMergesort(A, mid + 1, hi, T, mid' + 1)
join
parallelMerge(T, 1, mid', mid' + 1, len, B, off)
Чтобы проанализировать рекуррентное отношение для наихудшего случая, рекурсивные вызовы ParallelMergesort должны быть включены только один раз из-за их параллельного выполнения, получая

Подробную информацию о сложности процедуры параллельного слияния см. в разделе Алгоритм слияния .
Решение этого повторения дается выражением

Этот алгоритм параллельного слияния достигает параллелизма , что значительно выше параллелизма предыдущего алгоритма. Такая сортировка может хорошо работать на практике в сочетании с быстрой стабильной последовательной сортировкой, такой как сортировка вставками , и быстрым последовательным слиянием в качестве базового варианта слияния небольших массивов. [19]

Параллельная многоходовая сортировка слиянием [ править ]
Кажется произвольным ограничивать алгоритмы сортировки слиянием методом двоичного слияния, поскольку обычно доступно p > 2 процессоров. Лучшим подходом может быть использование метода слияния K-way , обобщения бинарного слияния, в котором отсортированные последовательности объединяются. Этот вариант слияния хорошо подходит для описания алгоритма сортировки в PRAM . [20] [21]

Основная идея [ править ]



Дана несортированная последовательность элементов, цель состоит в том, чтобы отсортировать последовательность с помощью доступные процессоры . Эти элементы распределяются поровну между всеми процессорами и сортируются локально с помощью последовательного алгоритма сортировки . Следовательно, последовательность состоит из отсортированных последовательностей длины . Для упрощения пусть быть кратным , так что для .






Эти последовательности будут использоваться для выполнения мультипоследовательного выбора/разделительного выбора. Для , алгоритм определяет элементы разветвителя с мировым рейтингом . Тогда соответствующие позиции в каждой последовательности определяются с помощью двоичного поиска и, таким образом, далее подразделяются на подпоследовательности с .







Кроме того, элементы назначены процессору , означает все элементы между рангом и ранг , которые распределены по всем . Таким образом, каждый процессор получает последовательность отсортированных последовательностей. Тот факт, что звание элементов делителя был выбран глобально, обеспечивает два важных свойства: с одной стороны, был выбран таким образом, чтобы каждый процессор по-прежнему мог работать на элементы после назначения. Алгоритм идеально сбалансирован по нагрузке . С другой стороны, все элементы процессора меньше или равны всем элементам процессора . Следовательно, каждый процессор локально выполняет p -образное слияние и, таким образом, получает отсортированную последовательность из своих подпоследовательностей. Из-за второго свойства дальнейшее p -слияние выполнять не нужно, результаты нужно лишь сложить вместе в порядке номера процессора.







Выбор нескольких последовательностей [ править ]
В своей простейшей форме, учитывая отсортированные последовательности распределены равномерно по процессоры и ранг , задача — найти элемент с мировым рейтингом в объединении последовательностей. Следовательно, это можно использовать для разделения каждого на две части по индексу разделителя , где нижняя часть содержит только элементы размером меньше , а элементы размером больше расположены в верхней части.


Представленный последовательный алгоритм возвращает индексы разбиений в каждой последовательности, например индексы в последовательностях такой, что имеет глобальный ранг меньше, чем и . [22]
![{\displaystyle S_{i}[l_{i}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d02331f6b9e8af20f6fa147074ce4ee4cc86833)
![{\displaystyle \mathrm {rank} \left(S_{i}[l_{i}+1]\right)\geq k}](https://wikimedia.org/api/rest_v1/media/math/render/svg/41413e6e418305ec91ddf5335fd28f14ac8dd84f)
algorithm msSelect(S : Array of sorted Sequences [S_1,..,S_p], k : int) is
for i = 1 to p do
(l_i, r_i) = (0, |S_i|-1)
while there exists i: l_i < r_i do
// pick Pivot Element in S_j[l_j], .., S_j[r_j], chose random j uniformly
v := pickPivot(S, l, r)
for i = 1 to p do
m_i = binarySearch(v, S_i[l_i, r_i]) // sequentially
if m_1 + ... + m_p >= k then // m_1+ ... + m_p is the global rank of v
r := m // vector assignment
else
l := m
return l
Для анализа сложности PRAM выбрана модель . Если данные равномерно распределены по всем , p-кратное выполнение методаbinarySearch имеет время выполнения . Ожидаемая глубина рекурсии равна как в обычном Quickselect . Таким образом, общее ожидаемое время работы равно .



Применительно к параллельной многосторонней сортировке слиянием этот алгоритм должен вызываться параллельно, чтобы все элементы разделителя ранга для встречаются одновременно. Эти элементы разделителя затем можно использовать для разделения каждой последовательности на частей, с одинаковым общим временем работы .


Псевдокод [ править ]
Ниже приведен полный псевдокод параллельного алгоритма многосторонней сортировки слиянием. Мы предполагаем, что существует барьерная синхронизация до и после выбора мультипоследовательностей, так что каждый процессор может правильно определить элементы разделения и разделение последовательности.
/**
* d: Unsorted Array of Elements
* n: Number of Elements
* p: Number of Processors
* return Sorted Array
*/
algorithm parallelMultiwayMergesort(d : Array, n : int, p : int) is
o := new Array[0, n] // the output array
for i = 1 to p do in parallel // each processor in parallel
S_i := d[(i-1) * n/p, i * n/p] // Sequence of length n/p
sort(S_i) // sort locally
synch
v_i := msSelect([S_1,...,S_p], i * n/p) // element with global rank i * n/p
synch
(S_i,1, ..., S_i,p) := sequence_partitioning(si, v_1, ..., v_p) // split s_i into subsequences
o[(i-1) * n/p, i * n/p] := kWayMerge(s_1,i, ..., s_p,i) // merge and assign to output array
return o
Анализ [ править ]
Во-первых, каждый процессор сортирует назначенные элементы локально с использованием алгоритма сортировки со сложностью . После этого элементы делителя необходимо рассчитать по времени. . Наконец, каждая группа разделения должны быть объединены параллельно каждым процессором со временем работы используя последовательный алгоритм слияния p-way . Таким образом, общее время работы определяется выражением



.

и применение адаптация Практическая
Алгоритм многосторонней сортировки слиянием очень масштабируем благодаря своим высоким возможностям распараллеливания, что позволяет использовать множество процессоров. Это делает алгоритм жизнеспособным кандидатом для сортировки больших объемов данных, например тех, которые обрабатываются в компьютерных кластерах . Кроме того, поскольку в таких системах память обычно не является ограничивающим ресурсом, недостаток пространственной сложности сортировки слиянием незначителен. Однако в таких системах становятся важными другие факторы, которые не учитываются при моделировании на PRAM . Здесь необходимо учитывать следующие аспекты: Иерархия памяти , когда данные не помещаются в кэш процессоров, или накладные расходы на обмен данными между процессорами, которые могут стать узким местом, когда к данным больше нельзя получить доступ через общий доступ. память.
Сандерс и др. представили в своей статье объемный синхронный параллельный алгоритм многоуровневой многосторонней сортировки слиянием, который делит процессоры в группы по размеру . Все процессоры сначала сортируют локально. В отличие от одноуровневой многосторонней сортировки слиянием, эти последовательности затем разбиваются на части и назначены соответствующим группам процессоров. Эти шаги рекурсивно повторяются в этих группах. Это сокращает общение и особенно позволяет избежать проблем с множеством небольших сообщений. Иерархическая структура базовой реальной сети может использоваться для определения групп процессоров (например, стоек , кластеров и т. д.). [21]


Дальнейшие варианты [ править ]
Сортировка слиянием была одним из первых алгоритмов сортировки, в которых было достигнуто оптимальное ускорение: Ричард Коул использовал умный алгоритм подвыборки, чтобы обеспечить слияние O (1). [23] Другие сложные алгоритмы параллельной сортировки могут достичь тех же или лучших временных границ с более низкой константой. Например, в 1991 году Дэвид Пауэрс описал параллельную быструю сортировку (и связанную с ней поразрядную сортировку ), которая может работать за время O (log n ) на CRCW параллельной машине произвольного доступа (PRAM) с n процессорами, выполняя неявное разделение. [24] Бэтчера Пауэрс также показывает, что конвейерная версия Bitonic Mergesort в O ((log n ) 2 ) время в сети сортировки «бабочка» на практике на самом деле быстрее, чем его сортировка O (log n ) в PRAM, и он подробно обсуждает скрытые накладные расходы при сравнении, поразрядной и параллельной сортировке. [25]
Сравнение с другими алгоритмами сортировки [ править ]
Хотя пирамидальная сортировка имеет те же временные ограничения, что и сортировка слиянием, для нее требуется только вспомогательное пространство Θ(1) вместо Θ( n ) сортировки слиянием. В типичных современных архитектурах эффективные реализации быстрой сортировки обычно превосходят сортировку слиянием для сортировки массивов в оперативной памяти. [ нужна ссылка ] [26] Быстрая сортировка предпочтительнее, когда размер сортируемых данных меньше, поскольку сложность пространства для быстрой сортировки равна O(log n ), это помогает использовать локальность кэша лучше, чем сортировка слиянием (со сложностью пространства O(n)). [26] С другой стороны, сортировка слиянием является стабильной сортировкой и более эффективна при обработке последовательных носителей с медленным доступом. Сортировка слиянием часто является лучшим выбором для сортировки связанного списка : в этой ситуации относительно легко реализовать сортировку слиянием таким образом, чтобы для нее требовалось всего Θ(1) дополнительного пространства и медленная производительность связанного списка при произвольном доступе. list приводит к тому, что некоторые другие алгоритмы (например, быстрая сортировка) работают плохо, а другие (например, пирамидальная сортировка) становятся совершенно невозможными.
Начиная с Perl 5.8, сортировка слиянием является алгоритмом сортировки по умолчанию (в предыдущих версиях Perl это была быстрая сортировка). [27] В Java методы Arrays.sort () используют сортировку слиянием или настроенную быструю сортировку в зависимости от типов данных, а для эффективности реализации переключаются на сортировку вставками, когда сортируется менее семи элементов массива. [28] Ядро Linux использует сортировку слиянием для своих связанных списков. [29]
Timsort , настроенный гибрид сортировки слиянием и сортировки вставкой, используется на различных программных платформах и языках, включая платформы Java и Android. [30] и ранее использовался Python с версии 2.3 по версию 3.10. [31]
Примечания [ править ]
- ^ Скиена (2008 , стр. 122)
- ^ Кнут (1998 , стр. 158)
- ^ Катахайнен, Юрки; Трефф, Йеспер Ларссон (март 1997 г.). «Алгоритмы и сложность». Материалы 3-й итальянской конференции по алгоритмам и сложности . Итальянская конференция по алгоритмам и сложности. Конспекты лекций по информатике. Том. 1203. Рим. стр. 217–228. CiteSeerX 10.1.1.86.3154 . дои : 10.1007/3-540-62592-5_74 . ISBN 978-3-540-62592-6 .
- ^ Кормен и др. (2009 , стр. 36)
- ^ Наихудшее число, приведенное здесь, не совпадает с числом, данным в « , Кнута Искусстве компьютерного программирования» том 3 . Расхождение связано с тем, что Кнут анализировал вариант реализации сортировки слиянием, который немного неоптимален.
- ↑ Перейти обратно: Перейти обратно: а б Джаялакшми, Н. (2007). Структура данных с использованием C++ . Брандмауэр Медиа. ISBN 978-81-318-0020-1 . ОСЛК 849900742 .
- ^ Кормен и др. (2009 , стр. 151)
- ^ Пауэрс, Дэвид М.В.; МакМахон, Грэм Б. (1983). «Сборник интересных программ на прологе». Технический отчет DCS 8313 (Отчет). Департамент компьютерных наук Университета Нового Южного Уэльса.
- ^ «WikiSort. Быстрый и стабильный алгоритм сортировки, использующий память O (1). Общественное достояние» . Гитхаб . 14 апреля 2014 г.
- ^ Чандрамули, Бадриш; Гольдштейн, Джонатан (2014). Терпение — добродетель: новый взгляд на слияние и сортировку на современных процессорах (PDF) . СИГМОД/ПОДС.
- ↑ Перейти обратно: Перейти обратно: а б «Quadsort — это стабильная адаптивная сортировка слиянием без ветвей» . Гитхаб . 8 июня 2022 г.
- ^ Катаджайнен, Пасанен и Теухола (1996)
- ^ Гефферт, Уильям; Можжевельник, Юрки; Пасанен, Томи (2000). «Асимптотически эффективное слияние на месте» . Теоретическая информатика . 237 (1–2): 159–181. дои : 10.1016/S0304-3975(98)00162-5 .
- ^ Хуан, Бин-Чао; Лэнгстон, Майкл А. (март 1988 г.). «Практическое слияние на месте» . Коммуникации АКМ . 31 (3): 348–352. дои : 10.1145/42392.42403 . S2CID 4841909 .
- ^ Ким, Пок-Сон; Куцнер, Арне (2004). «Слияние стабильного минимального объема памяти путем симметричных сравнений». Алгоритмы – ЕКА 2004 . Европейский симп. Алгоритмы. Конспекты лекций по информатике. Том. 3221. стр. 714–723. CiteSeerX 10.1.1.102.4612 . дои : 10.1007/978-3-540-30140-0_63 . ISBN 978-3-540-23025-0 .
- ^ Ким, Пок-Сон; Куцнер, Арне (1 сентября 2003 г.). «Новый метод эффективного слияния на месте» . Материалы конференции Корейского института интеллектуальных систем : 392–394.
- ^ Феррагина, Паоло (2009–2019), «5. Сортировка атомарных элементов» (PDF) , Магия алгоритмов! , с. 5-4, заархивировано (PDF) из оригинала 12 мая 2021 г.
- ↑ Перейти обратно: Перейти обратно: а б Кормен и др. (2009 , стр. 797–805)
- ^ Виктор Дуваненко «Параллельная сортировка слиянием» Журнал и блог Добба [1] и реализация C++ репозитория GitHub [2]
- ^ Питер Сандерс; Йоханнес Синглер (2008). «Лекция « Параллельные алгоритмы » (PDF) . Проверено 2 мая 2020 г.
- ↑ Перейти обратно: Перейти обратно: а б Астманн, Майкл; Бингманн, Тимо; Сандерс, Питер; Шульц, Кристиан (2015). «Практическая массово-параллельная сортировка» . Материалы 27-го симпозиума ACM по параллелизму в алгоритмах и архитектурах . стр. 13–23. дои : 10.1145/2755573.2755595 . ISBN 9781450335881 . S2CID 18249978 .
- ^ Питер Сандерс (2019). «Лекция « Параллельные алгоритмы » (PDF) . Проверено 2 мая 2020 г.
- ^ Коул, Ричард (август 1988 г.). «Параллельная сортировка слиянием». СИАМ Дж. Компьютер . 17 (4): 770–785. CiteSeerX 10.1.1.464.7118 . дои : 10.1137/0217049 . S2CID 2416667 .
- ^ Пауэрс, Дэвид М.В. (1991). «Параллельная быстрая сортировка и поразрядная сортировка с оптимальным ускорением» . Материалы международной конференции по параллельным вычислительным технологиям, Новосибирск . Архивировано из оригинала 25 мая 2007 г.
- ^ Пауэрс, Дэвид М.В. (январь 1995 г.). Параллельная унификация: практическая сложность (PDF) . Австралазийский семинар по компьютерной архитектуре Университета Флиндерса.
- ↑ Перейти обратно: Перейти обратно: а б Оладипупо, Исав Тайво; Устала от этого, Кристиана (20 января 2024 г.). «Сравнение быстрой сортировки и сортировки слиянием » Наука-прямая . 2020 (2020): 9 – через Elsevier Science Direct.
- ^ «Сортировка – документация Perl 5 версии 8.8» . Проверено 23 августа 2020 г.
- ^ coleenp (22 февраля 2019 г.). "src/java.base/share/classes/java/util/Arrays.java @ 53904:9c3fe09f69bc" . OpenJDK .
- ^ ядро Linux /lib/list_sort.c
- ^ Ливерпульский университет (12 декабря 2022 г.). «Компьютерщики улучшают функцию сортировки Python» . Техэксплор . Проверено 8 мая 2024 г.
- ^ Джеймс, Майк (21 декабря 2022 г.). «Python теперь использует Powersort» . i-programmer.info . Проверено 8 мая 2024 г.
Ссылки [ править ]
- Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л .; Стоун, Клиффорд (2009) [1990]. Введение в алгоритмы (3-е изд.). MIT Press и McGraw-Hill. ISBN 0-262-03384-4 .
- Катахайнен, Юрки; Пасанен, Томи; Теухола, Юкка (1996). «Практическая сортировка слиянием на месте» . Северный журнал вычислительной техники . 3 (1): 27–40. CiteSeerX 10.1.1.22.8523 . ISSN 1236-6064 . Архивировано из оригинала 7 августа 2011 г. Проверено 4 апреля 2009 г. . Также практичная сортировка слиянием на месте . Также [3]
- Кнут, Дональд (1998). «Раздел 5.2.4: Сортировка путем слияния». Сортировка и поиск . Искусство компьютерного программирования . Том. 3 (2-е изд.). Аддисон-Уэсли. стр. 158–168. ISBN 0-201-89685-0 .
- Кронрод, Массачусетс (1969). «Оптимальный алгоритм упорядочения без операционного поля». Советская математика — Доклады . 10 :744.
- ЛаМарка, А.; Ладнер, Р.Э. (1997). «Влияние кешей на производительность сортировки». Учеб. 8-я Энн. Симпозиум ACM-SIAM. О дискретных алгоритмах (SODA97) : 370–379. CiteSeerX 10.1.1.31.1153 .
- Скиена, Стивен С. (2008). «4.5: Сортировка слиянием: сортировка по принципу «разделяй и властвуй». Руководство по разработке алгоритмов (2-е изд.). Спрингер. стр. 120–125. ISBN 978-1-84800-069-8 .
- Сан Микросистемс. «API массивов (Java SE 6)» . Проверено 19 ноября 2007 г.
- Oracle Corp. «Массивы (Java SE 10 и JDK 10)» . Проверено 23 июля 2018 г.
Внешние ссылки [ править ]
- Анимированные алгоритмы сортировки: сортировка слиянием в Wayback Machine (архивировано 6 марта 2015 г.) - графическая демонстрация
- Структуры открытых данных. Раздел 11.1.1. Сортировка слиянием , Пэт Морин.