Двоичная куча
| Двоичная (мин) куча | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тип | двоичное дерево/куча | ||||||||||||||||||||||||||
| Изобретенный | 1964 | ||||||||||||||||||||||||||
| Изобретён | Дж. У. Дж. Уильямс | ||||||||||||||||||||||||||
| |||||||||||||||||||||||||||


Бинарная куча — это кучи структура данных , которая принимает форму двоичного дерева . Двоичные кучи — распространенный способ реализации очередей с приоритетами . [1] : 162–163 Бинарная куча была представлена Дж. Вильямсом в 1964 году как структура данных для пирамидальной сортировки . [2]
Бинарная куча определяется как двоичное дерево с двумя дополнительными ограничениями: [3]
- Свойство формы: двоичная куча представляет собой полное двоичное дерево ; то есть все уровни дерева, за исключением, возможно, последнего (самого глубокого), полностью заполнены, и, если последний уровень дерева не завершен, узлы этого уровня заполняются слева направо.
- Свойство кучи: ключ, хранящийся в каждом узле, либо больше, либо равен (≥), либо меньше или равен (≤) ключей в дочерних узлах в соответствии с некоторым общим порядком .
Кучи, в которых родительский ключ больше или равен (≥) дочерним ключам, называются максимальными кучами ; те, где оно меньше или равно (≤), называются min-кучами . Известны эффективные ( логарифмическое время ) алгоритмы для двух операций, необходимых для реализации приоритетной очереди в двоичной куче: вставка элемента и удаление наименьшего или самого большого элемента из минимальной или максимальной кучи соответственно. Двоичные кучи также часто используются в алгоритме пирамидальной сортировки , который представляет собой алгоритм на месте, поскольку двоичные кучи могут быть реализованы как неявная структура данных , сохраняющая ключи в массиве и использующая их относительные позиции в этом массиве для представления дочерних и родительских отношений. .
Операции с кучей [ править ]
Операции вставки и удаления сначала изменяют кучу, чтобы она соответствовала свойству формы, добавляя или удаляя из конца кучи. Затем свойство кучи восстанавливается путем перемещения вверх или вниз по куче. Обе операции занимают время O(log n ) .
Вставить [ править ]
Чтобы вставить элемент в кучу, мы выполняем следующие шаги:
- Добавьте элемент на нижний уровень кучи в крайнее левое свободное пространство.
- Сравните добавленный элемент с его родителем; если они в правильном порядке, остановитесь.
- Если нет, замените элемент его родителем и вернитесь к предыдущему шагу.
Шаги 2 и 3, которые восстанавливают свойство кучи путем сравнения и, возможно, замены узла с его родительским узлом, называются операцией поднятия кучи (также известной как всплеск , просачивание , просеивание , просачивание , плавание) . up , heapify-up , cascade-up или fix-up ).
Количество требуемых операций зависит только от количества уровней, на которые должен подняться новый элемент, чтобы удовлетворить свойству кучи. Таким образом, временная сложность операции вставки в наихудшем случае равна O(log n ) . Для случайной кучи и повторяющихся вставок операция вставки имеет сложность в среднем O(1). [4] [5]
В качестве примера вставки двоичной кучи предположим, что у нас есть максимальная куча.
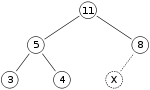
и мы хотим добавить в кучу число 15. Сначала мы помещаем 15 в позицию, отмеченную знаком X. Однако свойство кучи нарушается, поскольку 15 > 8 , поэтому нам нужно поменять местами 15 и 8. Итак, после первой замены мы имеем кучу, которая выглядит следующим образом:
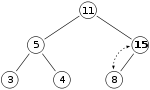
Однако свойство кучи по-прежнему нарушается, поскольку 15 > 11 , поэтому нам нужно снова поменять местами:
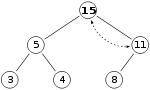
что является допустимой максимальной кучей. После этого последнего шага нет необходимости проверять левый дочерний элемент: в начале максимальная куча была допустимой, то есть корень уже был больше, чем его левый дочерний элемент, поэтому замена корня на еще большее значение сохранит свойство, которое каждый узел больше, чем его дочерние элементы ( 11 > 5 ; если 15 > 11 и 11 > 5 , то 15 > 5 из-за транзитивного отношения ).
Извлечь [ править ]
Процедура удаления корня из кучи (эффективное извлечение максимального элемента в максимальной куче или минимального элемента в минимальной куче) с сохранением свойства кучи следующая:
- Замените корень кучи последним элементом на последнем уровне.
- Сравните новый корень с его дочерними элементами; если они в правильном порядке, остановитесь.
- Если нет, поменяйте местами элемент с одним из его дочерних элементов и вернитесь к предыдущему шагу. (Поменяйте местами его меньший дочерний элемент в минимальной куче и его больший дочерний элемент в максимальной куче.)
Шаги 2 и 3, которые восстанавливают свойство кучи путем сравнения и, возможно, замены узла одним из его дочерних элементов, называются нижней кучей (также известной как пузырчатая куча , просачивание вниз , просеивание вниз , опускание вниз , струйка) . down , heapify-down , cascade-down , fix-down , extract-min или extract-max , или просто heapify ).
Итак, если у нас та же максимальная куча, что и раньше

Убираем цифру 11 и заменяем ее цифрой 4.
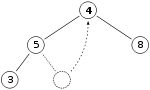
Теперь свойство кучи нарушено, поскольку 8 больше 4. В этом случае замены двух элементов, 4 и 8, достаточно, чтобы восстановить свойство кучи, и нам не нужно дальше менять местами элементы:

Перемещающийся вниз узел меняется местами с большим из своих дочерних узлов в максимальной куче (в минимальной куче он будет заменен на меньший дочерний узел), пока он не будет удовлетворять свойству кучи в своем новом положении. Эта функциональность достигается с помощью функции Max-Heapify , как определено ниже в псевдокоде для массива с поддержкой кучи A длиной length ( A ) . А Индекс начинается с 1.
// Perform a down-heap or heapify-down operation for a max-heap
// A: an array representing the heap, indexed starting at 1
// i: the index to start at when heapifying down
Max-Heapify(A, i):
left ← 2×i
right ← 2×i + 1
largest ← i
if left ≤ length(A) and A[left] > A[largest] then:
largest ← left
if right ≤ length(A) and A[right] > A[largest] then:
largest ← right
if largest ≠ i then:
swap A[i] and A[largest]
Max-Heapify(A, largest)
Чтобы приведенный выше алгоритм правильно перегруппировал массив, никакие узлы, кроме узла с индексом i и двух его прямых дочерних элементов, не могут нарушать свойство кучи. Операцию нижней кучи (без предшествующей замены) также можно использовать для изменения значения корня, даже если элемент не удаляется.
В худшем случае новый корень придется поменять местами со своим дочерним элементом на каждом уровне, пока он не достигнет нижнего уровня кучи, а это означает, что операция удаления имеет временную сложность относительно высоты дерева, или O(log n ).
Вставьте, затем извлеките [ править ]
Вставка элемента с последующим его извлечением из кучи может быть выполнена более эффективно, чем простой вызов функций вставки и извлечения, определенных выше, что потребует как upheap и downheap операция. Вместо этого мы можем сделать просто downheap операцию следующим образом:
- Сравните, больше ли элемент, который мы помещаем, или просматриваемая вершина кучи (при условии, что куча максимальная)
- Если корень кучи больше:
- Заменить корень новым элементом
- Down-heapify, начиная с корня
- В противном случае верните элемент, который мы отправляем.
Python предоставляет такую функцию для вставки и последующего извлечения, которая называется «heappushpop», которая перефразируется ниже. [6] [7] Предполагается, что первый элемент массива кучи имеет индекс 1.
// Push a new item to a (max) heap and then extract the root of the resulting heap.
// heap: an array representing the heap, indexed at 1
// item: an element to insert
// Returns the greater of the two between item and the root of heap.
Push-Pop(heap: List<T>, item: T) -> T:
if heap is not empty and heap[1] > item then: // < if min heap
swap heap[1] and item
_downheap(heap starting from index 1)
return item
Аналогичная функция может быть определена для извлечения и последующей вставки, что в Python называется «куча»:
// Extract the root of the heap, and push a new item
// heap: an array representing the heap, indexed at 1
// item: an element to insert
// Returns the current root of heap
Replace(heap: List<T>, item: T) -> T:
swap heap[1] and item
_downheap(heap starting from index 1)
return item
Поиск [ править ]
Поиск произвольного элемента занимает время O(n).
Удалить [ править ]
Удаление произвольного элемента можно выполнить следующим образом:
- Найдите индекс элемента, который мы хотим удалить
- Поменяйте местами этот элемент с последним элементом
- Уменьшите или увеличьте кучу, чтобы восстановить свойство кучи. В максимальной куче (минимальной куче) повышение кучи требуется только тогда, когда новый ключ элемента больше (меньше), чем предыдущий, поскольку может быть нарушено только свойство кучи родительского элемента. Предполагая, что свойство кучи было действительным между элементом и его дочерние элементы до замены элемента, это не может быть нарушено теперь большим (меньшим) значением ключа. Когда новый ключ меньше (больше), чем предыдущий, тогда требуется только нисходящая куча, поскольку свойство кучи может быть нарушено только в дочерних элементах.

Клавиша уменьшения или увеличения [ править ]
Операция ключа уменьшения заменяет значение узла с заданным значением на более низкое значение, а операция ключа увеличения делает то же самое, но с более высоким значением. Это включает в себя поиск узла с заданным значением, изменение значения, а затем уменьшение или увеличение кучи для восстановления свойства кучи.
Уменьшить ключ можно следующим образом:
- Найдите индекс элемента, который мы хотим изменить.
- Уменьшить значение узла
- Down-heapify (при условии максимальной кучи), чтобы восстановить свойство кучи
Увеличение ключа можно сделать следующим образом:
- Найдите индекс элемента, который мы хотим изменить.
- Увеличение значения узла
- Up-heapify (при условии максимальной кучи), чтобы восстановить свойство кучи
Создание кучи [ править ]
Построение кучи из массива из n входных элементов можно выполнить, начав с пустой кучи, а затем последовательно вставляя каждый элемент. Этот подход, названный методом Уильямса в честь изобретателя двоичных куч, легко увидеть, что он работает за время O ( n log n ) : он выполняет n вставок по цене O (log n ) каждая. [а]
Однако метод Уильямса неоптимален. Более быстрый метод (благодаря Флойду [8] ) начинается с произвольного размещения элементов в двоичном дереве с соблюдением свойства формы (дерево может быть представлено массивом, см. ниже). Затем, начиная с самого низкого уровня и продвигаясь вверх, просеивайте корень каждого поддерева вниз, как в алгоритме удаления, пока свойство кучи не будет восстановлено. Точнее, если все поддеревья начинаются с некоторой высоты уже были «кучированы» (самый нижний уровень соответствует ), деревья на высоте могут быть объединены в кучу, отправив свой корень вниз по пути дочерних элементов с максимальным значением при построении максимальной кучи или дочерних элементов с минимальным значением при построении минимальной кучи. Этот процесс занимает операций (свопов) на узел. В этом методе большая часть кучи происходит на нижних уровнях. Поскольку высота кучи равна , количество узлов на высоте является . Следовательно, стоимость объединения всех поддеревьев в кучу равна:







При этом используется тот факт, что данная бесконечная серия сходится .

Известно, что точное значение вышеуказанного (наихудшее количество сравнений при построении кучи) равно:

где s 2 ( n ) — сумма всех цифр двоичного представления числа n , а e 2 ( n ) — показатель степени 2 в простой факторизации числа n .
Средний случай более сложен для анализа, но можно показать, что он асимптотически приближается к 1,8814 n - 2 log 2 n + O (1) сравнений. [10] [11]
A , Следующая функция Build-Max-Heap преобразует массив в котором хранится полная двоичное дерево с n узлами до максимальной кучи путем многократного использования Max-Heapify (нисходящая куча для максимальной кучи) восходящим способом. Элементы массива, индексированные этаж ( n /2) + 1 , этаж ( n /2) + 2 , ..., n все они являются листьями дерева (при условии, что индексы начинаются с 1) — таким образом, каждый из них представляет собой одноэлементную кучу, и ее не нужно объединять в кучу. Build-Max-Heap Запуск Max-Heapify на каждом из оставшихся узлов дерева.
Build-Max-Heap (A):
for each index i from floor(length(A)/2) downto 1 do:
Max-Heapify(A, i)
Реализация кучи [ править ]
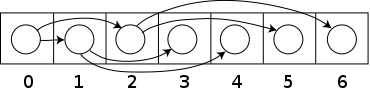

Кучи обычно реализуются с помощью массива . Любое двоичное дерево можно хранить в массиве, но поскольку двоичная куча всегда является полным двоичным деревом, ее можно хранить компактно. не требуется места Для указателей ; вместо этого родительский и дочерний узлы каждого узла можно найти путем арифметических вычислений по индексам массива. Эти свойства делают эту реализацию кучи простым примером неявной структуры данных или Анентафеля списка . Детали зависят от корневой позиции, которая, в свою очередь, может зависеть от ограничений языка программирования, используемого для реализации, или предпочтений программиста. В частности, иногда корень помещается с индексом 1, чтобы упростить арифметику.
Пусть n — количество элементов в куче, а i — произвольный допустимый индекс массива, хранящего кучу. Если корень дерева имеет индекс 0 с допустимыми индексами от 0 до n - 1, то каждый элемент a с индексом i имеет
- дети с индексами 2 i + 1 и 2 i + 2
- его родительский элемент на этаже индекса (( i − 1)/2).
В качестве альтернативы, если корень дерева имеет индекс 1 с допустимыми индексами от 1 до n , то каждый элемент a с индексом i имеет
- дети с индексами 2 i и 2 i +1
- его родительский элемент на индексном этаже ( i /2).
Эта реализация используется в алгоритме пирамидальной сортировки , который повторно использует пространство, выделенное для входного массива, для хранения кучи (т. е. алгоритм выполняется на месте ). Эта реализация также полезна в качестве приоритетной очереди . При использовании динамического массива возможна вставка неограниченного количества элементов.
The upheap или downheap тогда операции можно сформулировать в терминах массива следующим образом: предположим, что свойство кучи справедливо для индексов b , b +1, ..., e . Функция просеивания расширяет свойство кучи до b −1, b , b +1,..., e .
Только индекс i = b −1 может нарушить свойство кучи.
Пусть j будет индексом самого большого дочернего элемента a [ i ] (для максимальной кучи или наименьшего дочернего элемента для минимальной кучи) в диапазоне b , ..., e .
(Если такого индекса не существует, поскольку 2 i > e , то свойство кучи сохраняется для вновь расширенного диапазона, и ничего делать не нужно.)
Путем замены значений a [ i ] и a [ j свойство кучи для позиции i ] устанавливается .
На этом этапе единственная проблема заключается в том, что свойство кучи может не выполняться для индекса j .
Функция просеивания применяется хвостовой рекурсивно к индексу j до тех пор, пока свойство кучи не будет установлено для всех элементов.
Функция просеивания работает быстро. На каждом этапе требуется только два сравнения и одна замена. Значение индекса, в котором он работает, удваивается на каждой итерации, так что не более log 2 шагов требуется .
Для больших куч и использования виртуальной памяти хранить элементы в массиве по приведенной выше схеме неэффективно: (почти) каждый уровень находится на отдельной странице . B-кучи — это двоичные кучи, которые хранят поддеревья на одной странице, сокращая количество страниц, к которым осуществляется доступ, почти в десять раз. [12]
Операция слияния двух двоичных куч требует Θ( n ) для куч одинакового размера. Лучшее, что вы можете сделать, это (в случае реализации массива) просто объединить два массива кучи и построить кучу результата. [13] Куча из n элементов может быть объединена с кучей из k элементов с помощью сравнения ключей O(log n log k ) или, в случае реализации на основе указателей, за O(log n log k ). время [14] Алгоритм разделения кучи из n элементов на две кучи из k и nk элементов соответственно на основе нового представления куч в виде упорядоченных коллекций подкуч. [15] Алгоритм требует сравнений O(log n * log n ). Представление также представляет новый и концептуально простой алгоритм объединения куч. Если слияние является распространенной задачей, рекомендуется другая реализация кучи, например биномиальная куча , которую можно объединить за O(log n ).
Кроме того, двоичную кучу можно реализовать с помощью традиционной структуры данных двоичного дерева, но при добавлении элемента возникает проблема с поиском соседнего элемента на последнем уровне двоичной кучи. Этот элемент можно определить алгоритмически или путем добавления дополнительных данных к узлам, что называется «потоком» дерева — вместо простого хранения ссылок на дочерние элементы мы также сохраняем неупорядоченного преемника узла.
Можно изменить структуру кучи, чтобы сделать возможным извлечение как наименьшего, так и наибольшего элемента. время. [16] Для этого строки чередуются между минимальной кучей и максимальной кучей. Алгоритмы примерно одинаковы, но на каждом этапе необходимо учитывать чередующиеся строки с чередующимися сравнениями. Производительность примерно такая же, как у обычной однонаправленной кучи. Эту идею можно обобщить до кучи min-max-median.


Вывод индексных уравнений
В куче на основе массива дочерние и родительские узлы можно найти с помощью простой арифметики по индексу узла. В этом разделе выводятся соответствующие уравнения для куч с их корнем с индексом 0, с дополнительными примечаниями о кучах с их корнем с индексом 1.
Чтобы избежать путаницы, мы определяем уровень узла как его расстояние от корня, при котором сам корень занимает уровень 0.
Дочерние узлы [ править ]
Для общего узла, расположенного с индексом i (начиная с 0), мы сначала получим индекс его правого дочернего элемента, .

Пусть узел i расположен на уровне L и обратите внимание, что любой уровень l содержит ровно узлы. Кроме того, существуют именно узлы, содержащиеся в слоях до уровня l включительно (представьте себе двоичную арифметику; 0111...111 = 1000...000 - 1). Поскольку корень хранится по адресу 0, k -й узел будет храниться по индексу . Объединение этих наблюдений дает следующее выражение для индекса последнего узла в слое l .




Пусть есть j в слое L после узла i узлов , такие что

У каждого из этих j узлов должно быть ровно 2 дочерних узла, поэтому должно быть узлы, отделяющие правого дочернего элемента i от конца его слоя ( ).



Учитывая, что левый дочерний элемент любого узла всегда находится на 1 место раньше своего правого дочернего элемента, мы получаем .

Если корень расположен с индексом 1 вместо 0, последний узел на каждом уровне вместо этого находится с индексом. . Использование этого повсюду дает и для куч с корнем в 1.


Родительский узел [ править ]
Каждый некорневой узел является левым или правым дочерним элементом своего родителя, поэтому должно выполняться одно из следующих условий:


Следовательно,

Теперь рассмотрим выражение .

Если узел является левым дочерним элементом, это дает результат немедленно, однако также дает правильный результат, если узел правильный ребенок. В этом случае, должно быть четным, и, следовательно, должно быть странным.



Следовательно, независимо от того, является ли узел левым или правым дочерним элементом, его родителя можно найти по выражению:

Связанные структуры [ править ]
Поскольку порядок братьев и сестер в куче не определяется свойством heap, два дочерних элемента одного узла можно свободно менять местами, если это не нарушает свойство shape (сравните с treap ). Однако обратите внимание, что в общей куче на основе массива простая замена дочерних элементов может также потребовать перемещения узлов дочернего поддерева, чтобы сохранить свойство кучи.
Бинарная куча — это частный случай d-арной кучи, в которой d = 2.
Сводка времени работы [ править ]
Вот временные сложности [17] различных структур данных кучи. Имена функций предполагают минимальную кучу. Значение « O ( f )» и « Θ ( f )» см в обозначении Big O. .
| Операция | найти-мин | удаление-мин | вставлять | клавиша уменьшения | сливаться |
|---|---|---|---|---|---|
| Двоичный [17] | я (1) | Θ (логарифм n ) | О ( войти ) | О ( войти ) | Θ ( н ) |
| Левый | я (1) | Θ (логарифм n ) | Θ (логарифм n ) | О ( войти ) | Θ (логарифм n ) |
| Биномиальный [17] [18] | я (1) | Θ (логарифм n ) | я (1) [с] | Θ (логарифм n ) | О ( войти ) |
| Наклонный бином [19] | я (1) | Θ (логарифм n ) | я (1) | Θ (логарифм n ) | О ( войти ) [д] |
| Сопряжение [20] | я (1) | О ( войти ) [с] | я (1) | о ( войти ) [с] [и] | я (1) |
| Сопряжение по рангам [23] | я (1) | О ( войти ) [с] | я (1) | я (1) [с] | я (1) |
| Фибоначчи [17] [24] | я (1) | О ( войти ) [с] | я (1) | я (1) [с] | я (1) |
| Строгий Фибоначчи [25] | я (1) | О ( войти ) | я (1) | я (1) | я (1) |
| Мостовая долина [26] [ф] | я (1) | О ( войти ) | я (1) | я (1) | я (1) |
| 2–3 кучи [28] | я (1) | О ( войти ) [с] | я (1) [с] | я (1) | О ( войти ) |
- ^ Фактически, можно показать, что эта процедура занимает Θ( n log n ) времени в худшем случае , а это означает, что n log n также является асимптотической нижней границей сложности. [1] : 167 Однако в среднем случае (усреднение по всем перестановкам входных данных n ) метод занимает линейное время. [8]
- ^ Это не означает, что сортировку можно выполнять за линейное время, поскольку построение кучи — это только первый шаг алгоритма пирамидальной сортировки .
- ^ Jump up to: Перейти обратно: а б с д и ж г час я Амортизированное время.
- ^ в наихудшем случае Бродал и Окасаки описывают метод уменьшения сложности объединения до Θ (1); этот метод применим к любой структуре данных кучи, которая имеет вставку в Θ (1) и find-min , delete-min , объединение в O (log n ).
- ^ Нижняя граница [21] верхняя граница [22]
- ^ Бродал и Окасаки позже описывают постоянный вариант с теми же границами, за исключением клавиши уменьшения, которая не поддерживается. Кучи с n элементами могут быть построены снизу вверх за O ( n ). [27]


Ссылки [ править ]
- ^ Jump up to: Перейти обратно: а б Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л .; Стоун, Клиффорд (2009) [1990]. Введение в алгоритмы (3-е изд.). MIT Press и McGraw-Hill. ISBN 0-262-03384-4 .
- ^ Уильямс, JWJ (1964), «Алгоритм 232 — пирамидальная сортировка», Communications of the ACM , 7 (6): 347–348, doi : 10.1145/512274.512284
- ^ Ю. Нарахари, «Двоичные кучи» , структуры данных и алгоритмы
- ^ Портер, Томас; Саймон, Иштван (сентябрь 1975 г.). «Случайная вставка в структуру приоритетной очереди». Транзакции IEEE по разработке программного обеспечения . СЭ-1 (3): 292–298. дои : 10.1109/TSE.1975.6312854 . ISSN 1939-3520 . S2CID 18907513 .
- ^ Мельхорн, Курт; Цакалидис, А. (февраль 1989 г.). «Структуры данных» . Universität des Saarlandes : 27. doi : 10.22028/D291-26123 .
Портер и Саймон [171] проанализировали среднюю стоимость вставки случайного элемента в случайную кучу с точки зрения обмена. Они доказали, что это среднее ограничено константой 1,61. Их доказательства не распространяются на последовательности вставок, поскольку случайные вставки в случайные кучи не создают случайные кучи. Проблема повторной вставки была решена Боллобасом и Саймоном [27]; они показывают, что ожидаемое количество обменов ограничено цифрой 1,7645. Стоимость вставок и делеминов в худшем случае изучалась Гонне и Манро [84]; они дают log log n + O(1) и log n + log n* + O(1) границы количества сравнений соответственно.
- ^ "python/cpython/heapq.py" . Гитхаб . Проверено 7 августа 2020 г.
- ^ «heapq — Алгоритм очереди кучи — документация Python 3.8.5» . docs.python.org . Проверено 7 августа 2020 г.
heapq.heappushpop(heap, item): Поместите элемент в кучу, затем извлеките и верните самый маленький элемент из кучи. Комбинированное действие выполняется более эффективно, чем heappush(), за которым следует отдельный вызов heappop().
- ^ Jump up to: Перейти обратно: а б Хейворд, Райан; МакДиармид, Колин (1991). «Анализ среднего случая построения кучи путем повторной вставки» (PDF) . Дж. Алгоритмы . 12 : 126–153. CiteSeerX 10.1.1.353.7888 . дои : 10.1016/0196-6774(91)90027-в . Архивировано из оригинала (PDF) 5 февраля 2016 г. Проверено 28 января 2016 г.
- ^ Сученек, Марек А. (2012), «Элементарный, но точный анализ наихудшего случая программы Флойда по построению кучи» , Fundamenta Informaticae , 120 (1): 75–92, doi : 10.3233/FI-2012-751 .
- ^ Доберкат, Эрнст Э. (май 1984 г.). «Анализ среднего случая алгоритма Флойда для построения кучи» (PDF) . Информация и контроль . 6 (2): 114–131. дои : 10.1016/S0019-9958(84)80053-4 .
- ^ Пасанен, Томи (ноябрь 1996 г.). Элементарный средний анализ алгоритма Флойда для построения куч (технический отчет). Центр компьютерных наук Турку. CiteSeerX 10.1.1.15.9526 . ISBN 951-650-888-Х . Технический отчет TUCS № 64. Обратите внимание, что в этой статье используется оригинальная терминология Флойда «siftup» для того, что сейчас называется отсеиванием вниз .
- ^ Камп, Пол-Хеннинг (11 июня 2010 г.). «Ты делаешь это неправильно» . Очередь АКМ . Том. 8, нет. 6.
- ^ Крис Л. Кушмаул. «Двоичная куча». Архивировано 8 августа 2008 г. в Wayback Machine . Словарь алгоритмов и структур данных, Пол Э. Блэк, изд., Национальный институт стандартов и технологий США. 16 ноября 2009 г.
- ^ Ж.-Р. Сак и Т. Стротхотт «Алгоритм объединения куч» , Акта Информатика 22, 171–186 (1985).
- ^ Зак, Йорг-Рюдигер; Стротхотт, Томас (1990). «Характеристика куч и ее применение» . Информация и вычисления . 86 : 69–86. дои : 10.1016/0890-5401(90)90026-E .
- ^ Аткинсон, доктор медицины; Ж.-Р. Мешок ; Н. Санторо и Т. Стротхотт (1 октября 1986 г.). «Мин-макс кучи и очереди с обобщенными приоритетами» (PDF) . Методы программирования и структуры данных. Комм. ACM, 29 (10): 996–1000. Архивировано из оригинала (PDF) 27 января 2007 года . Проверено 29 апреля 2008 г.
- ^ Jump up to: Перейти обратно: а б с д Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л. (1990). Введение в алгоритмы (1-е изд.). MIT Press и McGraw-Hill. ISBN 0-262-03141-8 .
- ^ «Биномиальная куча | Блестящая вики по математике и естественным наукам» . блестящий.орг . Проверено 30 сентября 2019 г.
- ^ Бродал, Герт Столтинг; Окасаки, Крис (ноябрь 1996 г.), «Оптимальные чисто функциональные очереди приоритетов», Journal of Functional Programming , 6 (6): 839–857, doi : 10.1017/s095679680000201x
- ^ Яконо, Джон (2000), «Улучшенные верхние границы для спаривания куч», Proc. 7-й скандинавский семинар по теории алгоритмов (PDF) , Конспекты лекций по информатике, том. 1851, Springer-Verlag, стр. 63–77, arXiv : 1110.4428 , CiteSeerX 10.1.1.748.7812 , doi : 10.1007/3-540-44985-X_5 , ISBN 3-540-67690-2
- ^ Фредман, Майкл Лоуренс (июль 1999 г.). «Об эффективности объединения куч и связанных структур данных» (PDF) . Журнал Ассоциации вычислительной техники . 46 (4): 473–501. дои : 10.1145/320211.320214 .
- ^ Петти, Сет (2005). К окончательному анализу парных куч (PDF) . FOCS '05 Материалы 46-го ежегодного симпозиума IEEE по основам информатики. стр. 174–183. CiteSeerX 10.1.1.549.471 . дои : 10.1109/SFCS.2005.75 . ISBN 0-7695-2468-0 .
- ^ Хёплер, Бернхард; Сен, Сиддхартха; Тарьян, Роберт Э. (ноябрь 2011 г.). «Кучи ранговых пар» (PDF) . СИАМ Дж. Компьютерные технологии . 40 (6): 1463–1485. дои : 10.1137/100785351 .
- ^ Фредман, Майкл Лоуренс ; Тарьян, Роберт Э. (июль 1987 г.). «Кучи Фибоначчи и их использование в улучшенных алгоритмах оптимизации сети» (PDF) . Журнал Ассоциации вычислительной техники . 34 (3): 596–615. CiteSeerX 10.1.1.309.8927 . дои : 10.1145/28869.28874 .
- ^ Бродал, Герт Столтинг ; Лагояннис, Джордж; Тарьян, Роберт Э. (2012). Строгие кучи Фибоначчи (PDF) . Материалы 44-го симпозиума по теории вычислений - STOC '12. стр. 1177–1184. CiteSeerX 10.1.1.233.1740 . дои : 10.1145/2213977.2214082 . ISBN 978-1-4503-1245-5 .
- ^ Бродал, Герт С. (1996), «Эффективные приоритетные очереди для наихудшего случая» (PDF) , Proc. 7-й ежегодный симпозиум ACM-SIAM по дискретным алгоритмам , стр. 52–58.
- ^ Гудрич, Майкл Т .; Тамассия, Роберто (2004). «7.3.6. Построение кучи снизу вверх». Структуры данных и алгоритмы в Java (3-е изд.). стр. 338–341. ISBN 0-471-46983-1 .
- ^ Такаока, Тадао (1999), Теория 2–3 куч (PDF) , стр. 12