B-дерево
| B-дерево | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тип | Дерево (структура данных) | |||||||||||||||||||||||
| Изобретенный | 1970 [1] | |||||||||||||||||||||||
| Изобретён | Рудольф Байер , Эдвард М. МакКрайт | |||||||||||||||||||||||
| ||||||||||||||||||||||||
В информатике B -дерево — это самобалансирующаяся древовидная структура данных , которая поддерживает отсортированные данные и обеспечивает поиск, последовательный доступ, вставку и удаление за логарифмическое время . B-дерево обобщает двоичное дерево поиска , допуская узлы с более чем двумя дочерними узлами. [2] В отличие от других самобалансирующихся двоичных деревьев поиска , B-дерево хорошо подходит для систем хранения, которые читают и записывают относительно большие блоки данных, таких как базы данных и файловые системы .
История [ править ]
B-деревья были изобретены Рудольфом Байером и Эдвардом М. МакКрайтом во время работы в исследовательских лабораториях Boeing с целью эффективного управления индексными страницами для больших файлов с произвольным доступом. Основное предположение заключалось в том, что индексы будут настолько объемными, что только небольшие фрагменты дерева смогут поместиться в основной памяти. Статья Байера и МакКрайта. Организация и обслуживание крупных упорядоченных индексов. [1] был впервые распространен в июле 1970 года и позже опубликован в Acta Informatica . [3]
Байер и МакКрайт так и не объяснили, что буква B означает Боинг , сбалансированный , между , широкий , кустистый и Байер . ; Были предложены [4] [5] [6] МакКрайт сказал, что «чем больше вы думаете о том, что означает буква B в B-деревьях, тем лучше вы понимаете B-деревья». [5]
Определение [ править ]
Согласно определению Кнута , B-дерево порядка m — это дерево, удовлетворяющее следующим свойствам: [7]
- Каждый узел имеет не более m детей.
- Каждый узел, за исключением корня и листьев, имеет не менее ⌈ m /2⌉ детей.
- Корневой узел имеет как минимум двух дочерних узлов, если только он не является листом.
- Все листья появляются на одном уровне.
- Нелистовой узел с k дочерними узлами содержит k -1 ключей.
Ключи каждого внутреннего узла действуют как значения разделения, разделяющие его поддеревья. Например, если внутренний узел имеет 3 дочерних узла (или поддерева), то у него должно быть 2 1 : и 2 ключа . меньше 1 поддереве будут среднем поддереве будут между 1 значения в самом левом и 2 Все , а все значения в крайнем правом поддереве будут больше 2 , все значения в .
- Внутренние узлы
- Внутренние узлы (также известные как внутренние узлы ) — это все узлы, за исключением листовых узлов и корневого узла. Обычно они представляются как упорядоченный набор элементов и указателей на дочерние элементы. Каждый внутренний узел содержит максимум U дочерних узлов и минимум L дочерних узлов. Таким образом, количество элементов всегда на 1 меньше количества дочерних указателей (количество элементов находится между L -1 и U -1). U должно быть либо 2 L , либо 2 L −1; поэтому каждый внутренний узел заполнен как минимум наполовину. Отношения между U и L подразумевают, что два наполовину заполненных узла могут быть объединены, чтобы создать допустимый узел, а один полный узел может быть разделен на два допустимых узла (если есть место для размещения одного элемента в родительском элементе). Эти свойства позволяют удалять и вставлять новые значения в B-дерево, а также настраивать дерево для сохранения свойств B-дерева.
- Корневой узел
- Число дочерних узлов корневого узла имеет тот же верхний предел, что и внутренние узлы, но не имеет нижнего предела. Например, если во всем дереве меньше L -1 элементов, корень будет единственным узлом в дереве, вообще не имеющим дочерних элементов.
- Листовые узлы
- В терминологии Кнута «листовые» узлы — это фактические объекты/фрагменты данных. Внутренние узлы, находящиеся на один уровень выше этих листьев, являются тем, что другие авторы назвали бы «листьями»: эти узлы хранят только ключи (не более m -1 и не менее m /2-1, если они не являются корневыми). и указатели (по одному для каждого ключа) на узлы, несущие объекты/фрагменты данных.
B-дерево глубины n +1 может содержать примерно в U раз больше элементов, чем B-дерево глубины n , но стоимость операций поиска, вставки и удаления растет с глубиной дерева. Как и в любом сбалансированном дереве, стоимость растет гораздо медленнее, чем количество элементов.
Некоторые сбалансированные деревья хранят значения только в конечных узлах и используют разные типы узлов для конечных и внутренних узлов. B-деревья сохраняют значения в каждом узле дерева, кроме конечных узлов.
Различия в терминологии [ править ]
Литература по B-деревьям неоднородна в терминологии. [8]
Байер и МакКрайт (1972), [3] Ешь (1979), [2] и другие определяют порядок B-дерева как минимальное количество ключей в некорневом узле. Фолк и Зеллик [9] указывает на то, что терминология неоднозначна, поскольку неясно максимальное количество ключей. B-дерево порядка 3 может содержать максимум 6 или максимум 7 ключей. Кнут (1998) избегает этой проблемы, определяя порядок как максимальное количество дочерних элементов (которое на один больше, чем максимальное количество ключей). [7]
Термин «лист» также противоречив. Байер и МакКрайт (1972) [3] считал листовой уровень самым низким уровнем клавиш, но Кнут считал листовой уровень на один уровень ниже самых нижних клавиш. [9] Существует множество возможных вариантов реализации. В некоторых конструкциях листья могут содержать всю запись данных; в других конструкциях листья могут содержать только указатели на записи данных. Этот выбор не является фундаментальным для идеи B-дерева. [10]
Для простоты большинство авторов предполагают, что в узле имеется фиксированное количество ключей. Основное предположение заключается в том, что размер ключа фиксирован и размер узла фиксирован. На практике могут использоваться ключи переменной длины. [11]
Неофициальное описание [ править ]
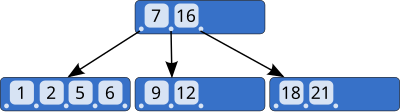
Структура узла [ править ]
Как и другие деревья, B-деревья можно представить как совокупность узлов трех типов: корневых , внутренних (так называемых внутренних) и листовых .
Обратите внимание на следующие определения переменных:
- K : Максимальное количество потенциальных ключей поиска для каждого узла в B-дереве. (это значение постоянно по всему дереву).
- : Указатель на дочерний узел, который начинает поддерево.
- : указатель на запись, в которой хранятся данные.
- : ключ поиска по индексу узла, отсчитываемому от нуля. .




В B-деревьях для этих узлов сохраняются следующие свойства:
- Если существует в любом узле B+-дерева, то существует в том узле, где .
- Все листовые узлы имеют одинаковое количество предков (т. е. все они находятся на одной и той же глубине).



Каждый внутренний узел B-дерева имеет следующий формат:
| точка 0 | до 0 | часть 1 | за 0 | к 1 | часть 2 | бывший 1 | ... | к К-1 | точка К | для К-1 |
|---|
| когда существует | когда и существовать | когда существует, и не существует | когда и не существует | когда существует | когда не существует |
|---|---|---|---|---|---|
| Указывает на поддерево, в котором все ключи поиска меньше . | Указывает на поддерево, в котором все ключи поиска больше, чем и меньше, чем . | Указывает на поддерево, в котором все ключи поиска больше, чем . | Здесь, пусто. | Указывает на запись со значением, равным . | Здесь, пусто. |


Каждый листовой узел B-дерева имеет следующий формат:
| за 0 | до 0 | бывший 1 | к 1 | ... | пр к-1 | к К-1 |
|---|
| когда существует | когда не существует |
|---|---|
| Указывает на запись со значением, равным . | Здесь, пусто. |
Границы узлов приведены в таблице ниже:
| Тип узла | Минимальное количество ключей | Максимальное количество ключей | Минимальное количество дочерних узлов | Максимальное количество дочерних узлов |
|---|---|---|---|---|
| Корневой узел, если он является листовым узлом | 0 | 0 | 0 | |
| Корневой узел, если он является внутренним узлом | 1 | 2 [12] | ||
| Внутренний узел | ||||
| Листовой узел | 0 | 0 |






Вставка и удаление [ править ]
Чтобы поддерживать заранее определенный диапазон дочерних узлов, внутренние узлы можно объединять или разделять.
Обычно количество клавиш выбирается в зависимости от и , где минимальное количество ключей, а — минимальная степень или фактор ветвления дерева. Коэффициент 2 гарантирует, что узлы можно разделить или объединить.



Если внутренний узел имеет ключей, то добавление ключа к этому узлу может быть выполнено путем разделения гипотетического ключевой узел на два ключевые узлы и перемещение ключа, который был бы посередине, к родительскому узлу. Каждый узел разделения имеет необходимое минимальное количество ключей. Аналогично, если внутренний узел и его сосед имеют ключей, то ключ можно удалить из внутреннего узла, объединив его со своим соседом. Удаление ключа приведет к тому, что внутренний узел ключи; присоединение к соседу добавит ключи плюс еще один ключ, полученный от родителя соседа. В результате получается полностью полный узел ключи.


B-дерево сохраняется сбалансированным после вставки путем разделения потенциально переполненного узла. ключи, на две -key siblings и вставка ключа среднего значения в родительский элемент. Глубина увеличивается только тогда, когда корень расщепляется, сохраняя баланс. Аналогичным образом, сбалансированное B-дерево сохраняется после удаления за счет слияния или перераспределения ключей между братьями и сестрами для сохранения целостности. -минимум ключа для некорневых узлов. Слияние уменьшает количество ключей в родительском элементе, потенциально вынуждая его объединять или перераспределять ключи с его родственными элементами и так далее. Единственное изменение глубины происходит, когда у корня есть два потомка: и (переходно) ключи, и в этом случае два родственных элемента и родительский элемент объединяются, уменьшая глубину на единицу.
Эта глубина будет медленно увеличиваться по мере добавления элементов в дерево, но увеличение общей глубины происходит нечасто и приводит к тому, что все конечные узлы оказываются на один узел дальше от корня.
Сравнение с другими деревьями [ править ]
Поскольку разрешен диапазон дочерних узлов, B-деревья не требуют повторной балансировки так часто, как другие самобалансирующиеся деревья поиска, но могут тратить некоторое пространство, поскольку узлы не полностью заполнены.
B-деревья имеют существенные преимущества перед альтернативными реализациями, когда время доступа к данным узла значительно превышает время, затрачиваемое на обработку этих данных, поскольку тогда стоимость доступа к узлу может быть амортизирована за счет нескольких операций внутри узла. Обычно это происходит, когда данные узла находятся во вторичном хранилище, например на дисках . За счет максимального увеличения количества ключей внутри каждого внутреннего узла уменьшается высота дерева и уменьшается количество дорогостоящих обращений к узлу. Кроме того, ребалансировка дерева происходит реже. Максимальное количество дочерних узлов зависит от информации, которую необходимо хранить для каждого дочернего узла, а также размера полного дискового блока или аналогичного размера во вторичном хранилище. Хотя 2–3 B-дерева объяснить проще, практические B-деревья, использующие вторичное хранилище, требуют большого количества дочерних узлов для повышения производительности.
Варианты [ править ]
Термин B-дерево может относиться к конкретному проекту или к общему классу проектов. В узком смысле B-дерево хранит ключи в своих внутренних узлах, но не обязано хранить эти ключи в записях на листьях. Общий класс включает такие варианты, как дерево B+ , дерево B * дерево и буква Б *+ дерево.
- В дереве B+ внутренние узлы не хранят указателей на записи, поэтому все указатели на записи хранятся в конечных узлах. Кроме того, листовой узел может включать в себя указатель на следующий листовой узел для ускорения последовательного доступа. [2] Поскольку внутренние узлы дерева B+ имеют меньше указателей, каждый узел может содержать больше ключей, что делает дерево более мелким и, следовательно, ускоряет поиск.
- Б * дерево балансирует больше соседних внутренних узлов, чтобы внутренние узлы были более плотно упакованы. [2] Этот вариант гарантирует, что некорневые узлы заполнены как минимум на 2/3 вместо 1/2. [13] Поскольку наиболее затратной частью операции вставки узла в B-дерево является его разделение, B * -деревья создаются для того, чтобы отложить операцию разделения настолько долго, насколько это возможно. [14] Чтобы сохранить это, вместо немедленного разделения узла, когда он заполняется, его ключи передаются соседнему узлу. Эта операция освобождения менее затратна, чем разделение, поскольку она требует только перемещения ключей между существующими узлами, а не выделения памяти для нового. [14] При вставке сначала проверяется, есть ли в узле свободное место, и если да, то новый ключ просто вставляется в узел. Однако, если узел заполнен (он имеет m - 1 ключей, где m — порядок дерева как максимальное количество указателей на поддеревья из одного узла), необходимо проверить, существует ли правильный брат и есть ли свободное пространство. . Если правый одноуровневый узел имеет j < m - 1 ключей, то ключи перераспределяются между двумя одноуровневыми узлами как можно более равномерно. Для этого m - 1 ключи из текущего узла, вставленный новый ключ, один ключ из родительского узла и j ключей из родственного узла рассматриваются как упорядоченный массив из m + j + 1 ключей. Массив разделяется пополам, так что ⌊ ( m + j + 1)/2 ⌋ самые низкие ключи остаются в текущем узле, следующий (средний) ключ вставляется в родительский узел, а остальные переходят к правому брату. [14] (Вновь вставленный ключ может оказаться в любом из трех мест.) Аналогична ситуация, когда правый одноуровневый ключ заполнен, а левый нет. [14] Когда оба родственных узла заполнены, два узла (текущий узел и родственный узел) разделяются на три, и еще один ключ перемещается вверх по дереву к родительскому узлу. [14] Если родительский узел заполнен, операция разделения/распределения распространяется на корневой узел. [14] Однако удаление узлов несколько сложнее, чем вставка.
- Б *+ дерево объединяет основное дерево B+ и дерево B * особенности дерева вместе. [15]
- B-деревья можно превратить в деревья статистики порядка, чтобы обеспечить быстрый поиск N-й записи в ключевом порядке или подсчет количества записей между любыми двумя записями, а также различные другие связанные операции. [16]
Использование B-дерева в базах данных [ править ]
этого раздела Тон или стиль могут не отражать энциклопедический тон , используемый в Википедии . ( Май 2022 г. ) |
Время поиска отсортированного файла [ править ]
Алгоритмы сортировки и поиска можно охарактеризовать количеством операций сравнения, которые необходимо выполнить с использованием порядковой записи . примерно за ⌈ log Например, двоичный поиск в отсортированной таблице с N записями можно выполнить 2 N ⌉ сравнений . Если бы в таблице было 1 000 000 записей, то конкретную запись можно было бы найти не более чем с 20 сравнениями: ⌈ log 2 (1 000 000) ⌉ = 20 .
Большие базы данных исторически хранились на дисках. Время чтения записи на диске намного превышает время, необходимое для сравнения ключей, когда запись доступна, из-за времени поиска и задержки вращения. Время поиска может составлять от 0 до 20 или более миллисекунд, а задержка вращения составляет в среднем около половины периода вращения. Для привода со скоростью 7200 об/мин период вращения составляет 8,33 миллисекунды. Для такого накопителя, как Seagate ST3500320NS, время поиска между дорожками составляет 0,8 миллисекунды, а среднее время поиска при чтении — 8,5 миллисекунды. [17] Для простоты предположим, что чтение с диска занимает около 10 миллисекунд.
В приведенном выше примере поиск одной записи из миллиона займет 20 операций чтения с диска, умноженных на 10 миллисекунд на каждое чтение с диска, что составляет 0,2 секунды.
Время поиска сокращается, поскольку отдельные записи группируются в дисковый блок . Блок диска может иметь размер 16 килобайт. Если каждая запись имеет размер 160 байт, то в каждом блоке можно хранить 100 записей. Вышеупомянутое время чтения диска фактически относилось к целому блоку. Как только головка диска окажется на месте, один или несколько блоков диска можно будет прочитать с небольшой задержкой. При 100 записях в блоке последние 6 или около того сравнений не требуют чтения с диска — все сравнения выполняются в пределах последнего прочитанного блока диска.
Чтобы еще больше ускорить поиск, необходимо сократить время выполнения первых 13–14 сравнений (каждое из которых требует доступа к диску).
Индекс ускоряет поиск [ править ]
B-дерева Индекс можно использовать для повышения производительности. Индекс B-дерева создает многоуровневую древовидную структуру, которая разбивает базу данных на блоки или страницы фиксированного размера. Каждый уровень этого дерева можно использовать для связи этих страниц через адрес, позволяя одной странице (известной как узел или внутренняя страница) ссылаться на другую с конечными страницами на самом низком уровне. Одна страница обычно является начальной точкой дерева или «корнем». Именно здесь начнется поиск определенного ключа, проходя путь, заканчивающийся листом. Большинство страниц в этой структуре будут листовыми страницами, которые ссылаются на определенные строки таблицы.
Поскольку каждый узел (или внутренняя страница) может иметь более двух дочерних элементов, индекс B-дерева обычно имеет меньшую высоту (расстояние от корня до самого дальнего листа), чем двоичное дерево поиска. В приведенном выше примере начальное чтение с диска сузило диапазон поиска в два раза. Это можно улучшить, создав вспомогательный индекс, содержащий первую запись в каждом блоке диска (иногда называемый разреженным индексом ). Этот вспомогательный индекс будет составлять 1% от размера исходной базы данных, но его можно быстро найти. Обнаружение записи во вспомогательном индексе подскажет нам, какой блок искать в основной базе данных; после поиска по вспомогательному индексу нам придется искать только этот один блок основной базы данных — ценой еще одного чтения с диска.
В приведенном выше примере индекс будет содержать 10 000 записей, и для возврата результата потребуется не более 14 сравнений. Как и в основной базе данных, последние шесть или около того сравнений во вспомогательном индексе будут находиться в одном и том же дисковом блоке. Поиск по индексу можно было выполнить примерно за восемь операций чтения с диска, а доступ к нужной записи можно было получить за 9 операций чтения с диска.
Создание вспомогательного индекса можно повторить, чтобы создать вспомогательный индекс для вспомогательного индекса. В результате получится индекс aux-aux, который потребует всего 100 записей и поместится в один дисковый блок.
Вместо чтения 14 дисковых блоков для поиска нужной записи нам нужно прочитать всего 3 блока. Эта блокировка является основной идеей создания B-дерева, в котором блоки диска заполняют иерархию уровней, образуя индекс. Чтение и поиск первого (и единственного) блока индекса aux-aux, который является корнем дерева, идентифицирует соответствующий блок в индексе aux на уровне ниже. Чтение и поиск в этом блоке вспомогательного индекса идентифицирует соответствующий блок для чтения до тех пор, пока последний уровень, известный как конечный уровень, не идентифицирует запись в основной базе данных. Вместо 150 миллисекунд нам нужно всего 30 миллисекунд, чтобы получить запись.
Вспомогательные индексы превратили задачу поиска из двоичного поиска, требующего примерно log 2 N операций чтения с диска, в задачу, требующую только log b N операций чтения с диска, где b — коэффициент блокировки (количество записей в блоке: b = 100 записей на блок в нашем пример; log 100 1 000 000 = 3 чтения).
На практике, если в основной базе данных часто выполняется поиск, индекс aux-aux и большая часть индекса aux могут находиться в дисковом кэше , поэтому они не будут требовать чтения с диска. B-дерево остается стандартной реализацией индекса почти во всех реляционных базах данных , и многие нереляционные базы данных также используют их. [18]
Вставки и удаления [ править ]
Если база данных не изменяется, то составить индекс просто, и индекс никогда не нужно менять. Если есть изменения, управление базой данных и ее индексом потребует дополнительных вычислений.
Удалить записи из базы данных относительно легко. Индекс может остаться прежним, а запись можно просто пометить как удаленную. База данных остается в отсортированном порядке. Если происходит большое количество ленивых удалений , то поиск и хранение становятся менее эффективными. [19]
Вставки в отсортированный последовательный файл могут быть очень медленными, поскольку необходимо освободить место для вставленной записи. Вставка записи перед первой записью требует сдвига всех записей на одну вниз. Такая операция слишком дорога, чтобы быть практичной. Одно из решений — оставить немного пробелов. Вместо того, чтобы плотно упаковывать все записи в блок, в блоке может быть некоторое свободное пространство для последующих вставок. Эти пробелы будут помечены как «удаленные» записи.
И вставка, и удаление выполняются быстро, пока в блоке доступно место. Если вставка не помещается в блок, то необходимо найти свободное место в каком-нибудь соседнем блоке и откорректировать вспомогательные индексы. В лучшем случае поблизости будет достаточно места, чтобы можно было свести к минимуму объем реорганизации блоков. В качестве альтернативы можно использовать некоторые дисковые блоки, расположенные вне последовательности. [18]
использования B-дерева для данных Преимущества баз
B-дерево использует все идеи, описанные выше. В частности, B-дерево:
- сохраняет ключи в отсортированном порядке для последовательного перемещения
- использует иерархический индекс для минимизации количества операций чтения с диска
- использует частично полные блоки для ускорения вставки и удаления
- сохраняет индекс сбалансированным с помощью рекурсивного алгоритма
Кроме того, B-дерево минимизирует потери, гарантируя, что внутренние узлы заполнены как минимум наполовину. B-дерево может обрабатывать произвольное количество вставок и удалений. [18]
Высота в лучшем и худшем случае [ править ]
Пусть h ≥ –1 будет высотой классического B-дерева (см. Дерево (структура данных) § Терминология определения высоты дерева). Пусть n ≥ 0 — количество записей в дереве. Пусть m — максимальное количество дочерних элементов, которое может иметь узел. Каждый узел может иметь не более m −1 ключей.
Можно показать (например, по индукции), что B-дерево высоты h со всеми полностью заполненными узлами имеет n = m. час +1 –1 запись. Следовательно, наилучшая высота (т.е. минимальная высота) B-дерева равна:

Позволять — минимальное количество дочерних элементов, которое должно иметь внутренний (некорневой) узел. Для обычного B-дерева

Комер (1979) и Кормен и др. (2001) дают высоту наихудшего случая (максимальную высоту) B-дерева как [20]

Алгоритмы [ править ]
Эта статья может сбивать с толку или быть непонятной читателям . В частности, в приведенном ниже обсуждении термины «элемент», «значение», «ключ», «разделитель» и «значение разделения» означают по существу одно и то же. Термины четко не определены. Есть некоторые тонкие проблемы с корнем и листьями. ( февраль 2012 г. ) |
Поиск [ править ]
Поиск аналогичен поиску в бинарном дереве поиска. Начиная с корня, дерево рекурсивно обходит сверху вниз. На каждом уровне поиск сводит свое поле зрения до дочернего указателя (поддерева), диапазон которого включает искомое значение. Диапазон поддерева определяется значениями или ключами, содержащимися в его родительском узле. Эти предельные значения также известны как значения разделения.
Бинарный поиск обычно (но не обязательно) используется внутри узлов для поиска значений разделения и интересующего дочернего дерева.
Вставка [ править ]
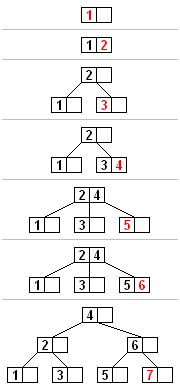
Все вставки начинаются с листового узла. Чтобы вставить новый элемент, выполните поиск в дереве, чтобы найти листовой узел, куда следует добавить новый элемент. Вставьте новый элемент в этот узел, выполнив следующие действия:
- Если узел содержит меньше элементов, чем максимально допустимое, то есть место для нового элемента. Вставьте новый элемент в узел, сохраняя порядок элементов узла.
- В противном случае узел заполнен, разделите его поровну на два узла так:
- Среди элементов листа и нового вставляемого элемента выбирается одна медиана.
- Значения меньше медианы помещаются в новый левый узел, а значения, превышающие медиану, помещаются в новый правый узел, при этом медиана действует как значение разделения.
- Значение разделения вставляется в родительский узел, что может привести к его разделению и т. д. Если у узла нет родителя (т. е. узел был корнем), создайте новый корень над этим узлом (увеличивая высоту дерева).
Если разделение идет до самого корня, создается новый корень с одним значением разделителя и двумя дочерними узлами, поэтому нижняя граница размера внутренних узлов не применяется к корню. Максимальное количество элементов на узел равно U −1. При разделении узла один элемент перемещается к родительскому элементу, но добавляется один элемент. Таким образом, должна быть возможность разделить максимальное количество U элементов −1 на два допустимых узла. Если это число нечетное, то U =2 L и один из новых узлов содержит ( U −2)/2 = L −1 элементов и, следовательно, является допустимым узлом, а другой содержит еще один элемент и, следовательно, законный тоже. Если U −1 четно, то U =2 L 2 L −1, поэтому в узле −2 элемента. Половина этого числа равна L −1, что представляет собой минимальное количество элементов, разрешенное на узел.
Альтернативный алгоритм поддерживает один проход вниз по дереву от корня до узла, в который будет осуществляться вставка, предварительно разбивая любые полные узлы, встречающиеся на пути. Это предотвращает необходимость вызова родительских узлов в память, что может быть дорогостоящим, если узлы находятся во вторичном хранилище. Однако, чтобы использовать этот алгоритм, мы должны иметь возможность отправить один элемент родительскому элементу и разделить оставшиеся элементы U -2 на два допустимых узла без добавления нового элемента. Для этого требуется U = 2 L, а не U = 2 L −1, что объясняет, почему некоторые [ который? ] учебники налагают это требование при определении B-деревьев.
Удаление [ править ]
Существует две популярные стратегии удаления из B-дерева.
- Найдите и удалите элемент, затем реструктурируйте дерево, чтобы сохранить его инварианты, ИЛИ
- Выполните один проход вниз по дереву, но перед входом (посещением) узла реструктурируйте дерево так, чтобы при обнаружении удаляемого ключа его можно было удалить, не вызывая необходимости в дальнейшей реструктуризации.
Алгоритм ниже использует прежнюю стратегию.
При удалении элемента следует учитывать два особых случая:
- Элемент во внутреннем узле является разделителем для своих дочерних узлов.
- Удаление элемента может привести к тому, что его узел окажется ниже минимального количества элементов и дочерних элементов.
Порядок действий в этих случаях приведен ниже.
Удаление из конечного узла [ править ]
- Найдите значение, которое нужно удалить.
- Если значение находится в листовом узле, просто удалите его из узла.
- Если произойдет переполнение, выполните повторную балансировку дерева, как описано в разделе «Перебалансировка после удаления» ниже.
Удаление с внутреннего узла [ править ]
Каждый элемент во внутреннем узле действует как значение разделения для двух поддеревьев, поэтому нам нужно найти замену разделения. Обратите внимание, что самый большой элемент в левом поддереве все еще меньше разделителя. Аналогично, наименьший элемент в правом поддереве по-прежнему больше разделителя. Оба этих элемента находятся в конечных узлах, и любой из них может быть новым разделителем двух поддеревьев. Алгоритмически описано ниже:
- Выберите новый разделитель (либо самый большой элемент в левом поддереве, либо самый маленький элемент в правом поддереве), удалите его из конечного узла, в котором он находится, и замените удаляемый элемент новым разделителем.
- Предыдущий шаг удалил элемент (новый разделитель) из листового узла. Если этот листовой узел теперь недостаточен (имеет меньше узлов, чем необходимо), выполните повторную балансировку дерева, начиная с листового узла.
Ребалансировка после удаления [ править ]
Восстановление баланса начинается с листа и продолжается по направлению к корню, пока дерево не будет сбалансировано. Если удаление элемента из узла привело к тому, что его размер стал меньше минимального, то некоторые элементы необходимо перераспределить, чтобы довести все узлы до минимального. Обычно перераспределение включает в себя перемещение элемента из одноуровневого узла, число узлов которого превышает минимальное. Эта операция перераспределения называется ротацией . Если ни один из одноуровневых узлов не может сохранить элемент, то дефектный узел необходимо объединить с одноуровневым. Слияние приводит к потере родительского элемента-разделителя, поэтому родительский элемент может стать несовершенным и потребовать повторной балансировки. Слияние и ребалансировка могут продолжаться вплоть до корня. Поскольку минимальное количество элементов не применимо к корню, сделать корень единственным недостающим узлом не является проблемой. Алгоритм ребалансировки дерева следующий:
- Если правый брат дефектного узла существует и имеет больше элементов, чем минимальное, то поверните его влево.
- Скопируйте разделитель из родительского узла в конец дефектного узла (разделитель перемещается вниз; дефектный узел теперь имеет минимальное количество элементов)
- Замените разделитель в родительском элементе первым элементом правого родственного элемента (правый одноуровневый элемент теряет один узел, но все равно имеет как минимум минимальное количество элементов)
- Дерево теперь сбалансировано
- В противном случае, если левый брат дефектного узла существует и имеет больше элементов, чем минимальное, то поверните вправо.
- Скопируйте разделитель из родительского узла в начало дефектного узла (разделитель перемещается вниз; дефектный узел теперь имеет минимальное количество элементов)
- Замените разделитель в родительском элементе последним элементом левого родственного элемента (левый одноуровневый элемент теряет один узел, но все еще имеет как минимум минимальное количество элементов)
- Дерево теперь сбалансировано
- В противном случае, если оба непосредственных брата и сестры имеют только минимальное количество элементов, тогда сливаются с братом или сестрой, помещая их разделитель, удаленный из их родительского элемента.
- Скопируйте разделитель в конец левого узла (левый узел может быть дефектным узлом или братом с минимальным количеством элементов)
- Переместите все элементы из правого узла в левый узел (левый узел теперь имеет максимальное количество элементов, а правый узел – пустой)
- Удалите разделитель из родительского элемента вместе с его пустым правым дочерним элементом (родитель теряет элемент)
- Если родительский элемент является корнем и теперь не имеет элементов, освободите его и сделайте объединенный узел новым корнем (дерево станет более мелким).
- В противном случае, если родительский элемент имеет меньше требуемого количества элементов, выполните повторную балансировку родительского элемента. [21]
- Примечание . Операции ребалансировки различаются для деревьев B+ (например, вращение отличается, поскольку родительский элемент имеет копию ключа) и B. * -дерево (например, три брата и сестры объединяются в двух братьев и сестер).
Последовательный доступ [ править ]
Хотя недавно загруженные базы данных, как правило, имеют хорошее последовательное поведение, такое поведение становится все труднее поддерживать по мере роста базы данных, что приводит к более случайному вводу-выводу и проблемам с производительностью. [22]
Первоначальное строительство [ править ]
Распространенным особым случаем является добавление большого количества предварительно отсортированных данных в изначально пустое B-дерево. Хотя вполне возможно просто выполнить серию последовательных вставок, в результате вставки отсортированных данных получится дерево, почти полностью состоящее из наполовину заполненных узлов. Вместо этого можно использовать специальный алгоритм «массовой загрузки» для создания более эффективного дерева с более высоким коэффициентом ветвления.
Когда входные данные отсортированы, все вставки находятся на крайнем правом краю дерева, и, в частности, каждый раз, когда узел разбивается, мы гарантируем, что в левой половине больше не будет вставок. При массовой загрузке мы этим пользуемся и вместо того, чтобы разбивать переполняющиеся узлы поровну, разбиваем их максимально неравномерно : оставляем левый узел полностью заполненным и создаем правый узел с нулевыми ключами и одним дочерним (в нарушение обычного правила B- правила дерева).
В конце массовой загрузки дерево почти полностью состоит из полностью заполненных узлов; только самый правый узел на каждом уровне может быть менее заполнен. Поскольку эти узлы также могут быть заполнены менее чем наполовину , чтобы восстановить обычные правила B-дерева, объедините такие узлы с их (гарантированно заполненными) левыми братьями и сестрами и разделите ключи, чтобы получить два узла, заполненных как минимум наполовину. Единственный узел, у которого отсутствует полный левый брат, — это корень, который может быть заполнен менее чем наполовину.
В файловых системах [ править ]
Помимо использования в базах данных, B-дерево (или § Варианты ) также используется в файловых системах для обеспечения быстрого произвольного доступа к произвольному блоку в конкретном файле. Основная проблема заключается в повороте файлового блока адрес в адрес блока диска.
Некоторые операционные системы требуют, чтобы пользователь выделил максимальный размер файла при его создании. Затем файл можно разместить в виде смежных дисковых блоков. В этом случае для преобразования адреса блока файла в адрес блока диска операционная система просто добавляет адрес блока файла по адресу первого дискового блока, составляющего файл. Схема проста, но файл не может превышать созданный размер.
Другие операционные системы позволяют файлу расти. Получающиеся в результате блоки диска могут не быть смежными, поэтому сопоставление логических блоков с физическими блоками является более сложным.
MS-DOS , например, использовала простую таблицу размещения файлов (FAT). В FAT есть запись для каждого блока диска. [примечание 1] и эта запись определяет, используется ли этот блок файлом, и если да, то какой блок (если есть) является следующим дисковым блоком того же файла. Таким образом, размещение каждого файла представлено в виде связанного списка в таблице. Чтобы найти адрес диска файлового блока , операционная система (или дисковая утилита) должна последовательно следовать связанному списку файла в FAT. Хуже того, чтобы найти свободный блок диска, ему приходится последовательно сканировать FAT. Для MS-DOS это не было большим штрафом, поскольку диски и файлы были небольшими, а в FAT было мало записей и относительно короткие цепочки файлов. В файловой системе FAT12 (использовавшейся на дискетах и ранних жестких дисках) было не более 4080 [примечание 2] записи, а FAT обычно находится в памяти. По мере того, как диски становились больше, архитектура FAT начала сталкиваться со штрафами. На большом диске с использованием FAT может потребоваться выполнить чтение с диска, чтобы узнать расположение на диске блока файла, который нужно прочитать или записать.
В ТОПС-20 (и, возможно, в TENEX ) использовалось дерево уровней от 0 до 2, имеющее сходство с B-деревом. [ нужна ссылка ] . Дисковый блок состоял из 512 36-битных слов. Если файл умещается в 512 (2 9 ) блок слов, то каталог файлов будет указывать на этот блок физического диска. Если файл умещается в 2 18 слова, тогда каталог будет указывать на дополнительный индекс; 512 слов этого индекса будут либо иметь значение NULL (блок не выделен), либо указывать на физический адрес блока. Если файл умещается в 2 27 словами, тогда каталог будет указывать на блок, содержащий индекс aux-aux; каждая запись будет либо иметь значение NULL, либо указывать на дополнительный индекс. Следовательно, блок физического диска для 2 27 Word-файл мог находиться на двух дисках чтения и читаться на третьем.
файловая система Apple HFS+ и APFS , Microsoft NTFS , [23] AIX (jfs2) и некоторые файловые системы Linux , такие как Bcachefs , Btrfs и ext4 , используют B-деревья.
Б * -деревья используются в HFS и Reiser4 файловых системах .
DragonFly BSD использует Файловая система HAMMER модифицированное B+-дерево. [24]
Производительность [ править ]
B-дерево растет медленнее с ростом объема данных, чем линейность связанного списка. По сравнению со списком пропуска обе структуры имеют одинаковую производительность, но B-дерево лучше масштабируется для роста n . T -дерево для систем баз данных в основной памяти аналогично, но более компактно.
Вариации [ править ]
Параллельный доступ [ править ]
Леман и Яо [25] показал, что всех блокировок чтения можно избежать (и, таким образом, значительно улучшить одновременный доступ), связав блоки дерева на каждом уровне вместе указателем «следующий». В результате получается древовидная структура, в которой операции вставки и поиска спускаются от корня к листу. Блокировки записи требуются только при изменении блока дерева. Это максимизирует параллельный доступ нескольких пользователей, что важно для баз данных и/или других методов хранения ISAM на основе B-дерева . Цена, связанная с этим улучшением, заключается в том, что пустые страницы невозможно удалить из btree во время обычных операций. (Однако см. [26] различные стратегии реализации слияния узлов и исходный код. [27] )
Патент США 5283894, выданный в 1994 году, по-видимому, показывает способ использования «метода мета-доступа». [28] чтобы разрешить одновременный доступ и изменение дерева B+ без блокировок. Этот метод осуществляет доступ к дереву «вверх» как для поиска, так и для обновления с помощью дополнительных индексов в памяти, которые указывают на блоки на каждом уровне блочного кэша. Никакой реорганизации для удаления не требуется, и в каждом блоке нет указателей «следующий», как в Lehman и Yao.
Параллельные алгоритмы [ править ]
Поскольку B-деревья по структуре аналогичны красно-черным деревьям , параллельные алгоритмы для красно-черных деревьев можно применять и к B-деревьям.
Клен [ править ]
Дерево Maple — это B-дерево, разработанное для использования в ядре Linux для уменьшения конфликтов блокировок при управлении виртуальной памятью. [29] [30] [31]
См. также [ править ]
Примечания [ править ]
- ^ Для FAT то, что здесь называется «блоком диска», — это то, что в документации FAT называется «кластером», который представляет собой группу фиксированного размера, состоящую из одного или нескольких смежных целых секторов физического диска . Для целей данного обсуждения кластер не имеет существенного отличия от физического сектора.
- ^ Два из них были зарезервированы для специальных целей, поэтому только 4078 могли фактически представлять дисковые блоки (кластеры).
Ссылки [ править ]
- ↑ Перейти обратно: Перейти обратно: а б Байер, Р.; МакКрайт, Э. (июль 1970 г.). «Организация и ведение крупных упорядоченных индексов» (PDF) . Материалы семинара ACM SIGFIDET (ныне SIGMOD) 1970 года по описанию данных, доступу и контролю - SIGFIDET '70 . Научно-исследовательские лаборатории Боинга. п. 107. дои : 10.1145/1734663.1734671 . S2CID 26930249 .
- ↑ Перейти обратно: Перейти обратно: а б с д Ешь 1979 год .
- ↑ Перейти обратно: Перейти обратно: а б с Байер и МакКрайт, 1972 .
- ^ Комер 1979 , с. 123 сноска 1.
- ↑ Перейти обратно: Перейти обратно: а б Вайнер, Питер Г. (30 августа 2013 г.). «4- Эдвард М. МакКрайт» – через Vimeo.
- ^ «Стэнфордский центр профессионального развития» . scpd.stanford.edu . Архивировано из оригинала 4 июня 2014 г. Проверено 16 января 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Кнут 1998 , с. 483.
- ^ Фолк и Зеллик 1992 , с. 362.
- ↑ Перейти обратно: Перейти обратно: а б Фолк и Зеллик 1992 , с. 363.
- ^ Bayer & McCreight (1972) избежали этой проблемы, заявив, что индексный элемент — это (физически смежная) пара ( x , a ), где x — ключ, а a — некоторая связанная информация. Соответствующая информация могла быть указателем на запись или записи в произвольном доступе, но что это было, не имело большого значения. Bayer & McCreight (1972) утверждают: «Для этой статьи соответствующая информация не представляет дальнейшего интереса».
- ^ Фолк и Зеллик 1992 , с. 379.
- ^ Кнут 1998 , с. 488.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Томашевич, Майло (2008). Алгоритмы и структуры данных . Белград, Сербия: Академическая мысль. стр. 274–275. ISBN 978-86-7466-328-8 .
- ^ Ригин А.М., Шершаков С.А. (10.09.2019). «Расширение СУБД SQLite для индексирования данных с использованием модификаций B-дерева» . Труды Института системного программирования РАН . 31 (3). Институт системного программирования РАН (ИСП РАН): 203–216. doi : 10.15514/ispras-2019-31(3)-16 . S2CID 203144646 . Проверено 29 августа 2021 г.
- ^ Подсчитанные B-деревья , получено 25 января 2010 г.
- ^ Руководство по продукту: Barracuda ES.2 Serial ATA, версия F., публикация 100468393 (PDF) . ООО «Сигейт Технолоджи». 2008. с. 6.
- ↑ Перейти обратно: Перейти обратно: а б с Клеппманн, Мартин (2017). Проектирование приложений с интенсивным использованием данных . Севастополь, Калифорния : O'Reilly Media . п. 80. ИСБН 978-1-449-37332-0 .
- ^ Ян Янник.«Реализация удаления в B+-деревьях».Раздел «4 Отложенное удаление» .
- ^ Ешьте 1979 , с. 127; Кормен и др. 2001 , стр. 439–440
- ^ «Удаление в B-дереве» (PDF) . cs.rhodes.edu . Архивировано (PDF) из оригинала 9 октября 2022 г. Проверено 24 мая 2022 г.
- ^ «Кэшировать не обращающие внимания B-деревья» . Государственный университет Нью-Йорка (SUNY) в Стоуни-Брук . Проверено 17 января 2011 г.
- ^ Марк Руссинович (30 июня 2006 г.). «Внутри Win2K NTFS, часть 1» . Сеть разработчиков Microsoft . Архивировано из оригинала 13 апреля 2008 года . Проверено 18 апреля 2008 г.
- ^ Мэтью Диллон (21 июня 2008 г.). «Файловая система HAMMER» (PDF) . Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Леман, Филип Л.; Яо, с. Бинг (1981). «Эффективная блокировка параллельных операций над B-деревьями» . Транзакции ACM в системах баз данных . 6 (4): 650–670. дои : 10.1145/319628.319663 . S2CID 10756181 .
- ^ Ван, Пол (1 февраля 1991 г.). «Углубленный анализ параллельных алгоритмов B-дерева» (PDF) . dtic.mil . Архивировано из оригинала (PDF) 4 июня 2011 года . Проверено 21 октября 2022 г.
- ^ «Загрузки — high-concurrency-btree — код B-дерева с высоким параллелизмом на C — хостинг проектов GitHub» . Гитхаб . Проверено 27 января 2014 г.
- ^ «Метод доступа к мета-доступу к индексу B-дерева без блокировки для кэшированных узлов» .
- ^ Представляем клены (LWN.net)
- ^ Maple Tree (документация ядра Linux)
- ^ Представляем клен (LWN.net/github)
Источники [ править ]
- Байер, Р .; МакКрайт, Э. (1972). «Организация и обслуживание больших упорядоченных индексов» (PDF) . Акта Информатика . 1 (3): 173–189. дои : 10.1007/bf00288683 . S2CID 29859053 . .
- Комер, Дуглас (июнь 1979 г.). «Вездесущее B-дерево» . Вычислительные опросы . 11 (2): 123–137. дои : 10.1145/356770.356776 . ISSN 0360-0300 . S2CID 101673 . .
- Кормен, Томас ; Лейзерсон, Чарльз ; Ривест, Рональд ; Штейн, Клиффорд (2001). Введение в алгоритмы (второе изд.). MIT Press и McGraw-Hill. стр. 434–454. ISBN 0-262-03293-7 . Глава 18: B-деревья.
- Фолк, Майкл Дж.; Зеллик, Билл (1992). Файловые структуры (2-е изд.). Аддисон-Уэсли. ISBN 0-201-55713-4 . .
- Кнут, Дональд (1998). Сортировка и поиск . Искусство компьютерного программирования . Том. 3 (Второе изд.). Аддисон-Уэсли. ISBN 0-201-89685-0 . Раздел 6.2.4: Многопутевые деревья, стр. 481–491. Кроме того, на стр. 476–477 раздела 6.2.3 (Сбалансированные деревья) обсуждаются 2–3 дерева.
Оригинальные статьи [ править ]
- Байер, Рудольф ; МакКрайт, Э. (июль 1970 г.), Организация и обслуживание больших упорядоченных индексов , том. Отчет № 20 по математическим и информационным наукам, Научно-исследовательские лаборатории Boeing .
- Байер, Рудольф (1971). «Двоичные B-деревья для виртуальной памяти». Материалы семинара ACM-SIGFIDET 1971 года по описанию данных, доступу и контролю . Сан-Диего, Калифорния. .
Внешние ссылки [ править ]
- Лекция B-дерева Дэвида Скотта Тейлора, SJSU
- Визуализация B-дерева (нажмите «init»)
- Анимированная визуализация B-дерева
- B-дерево и UB-дерево в Scholarpedia Куратор: д-р Рудольф Байер
- B-деревья: сбалансированные древовидные структуры данных, заархивированные 5 марта 2010 г. на Wayback Machine.
- Словарь алгоритмов и структур данных NIST: B-дерево
- Учебное пособие по B-дереву
- Реализация InfinityDB BTree
- Кэширование забывчивых B(+)-деревьев
- Статья в Словаре алгоритмов и структур данных для B*-дерева
- Структуры открытых данных. Раздел 14.2. B-деревья , Пэт Морин.
- Подсчитанные B-деревья
- B-Tree .Net, современная виртуализированная реализация ОЗУ и диска.
Массовая загрузка
- Шетти, Сумья Б. (2010). Настраиваемая пользователем реализация B-деревьев (Тезис). Университет штата Айова.
- Калдырым, Семих (28 апреля 2015 г.). «Организация файлов, ISAM, дерево B+ и массовая загрузка» (PDF) . Анкара, Турция: Университет Билкент . стр. 4–6. Архивировано (PDF) из оригинала 9 октября 2022 г.
- «ECS 165B: Реализация системы базы данных: лекция 6» (PDF) . Калифорнийский университет в Дэвисе . 9 апреля 2010 г. с. 23. Архивировано (PDF) из оригинала 9 октября 2022 г.
- «МАСОВАЯ ВСТАВКА (Transact-SQL) в SQL Server 2017» . Документы Майкрософт. 6 сентября 2018 г.