Дерево интервалов
В информатике дерево интервалов представляет собой древовидную структуру данных, содержащую интервалы . В частности, это позволяет эффективно находить все интервалы, которые перекрываются с любым заданным интервалом или точкой. Он часто используется для оконных запросов, [1] например, чтобы найти все дороги на компьютеризированной карте внутри прямоугольного окна просмотра или найти все видимые элементы внутри трехмерной сцены. Аналогичная структура данных — дерево сегментов .
Тривиальное решение состоит в том, чтобы посетить каждый интервал и проверить, пересекает ли он заданную точку или интервал, что требует время, где — количество интервалов в коллекции. Поскольку запрос может возвращать все интервалы, например, если запрос представляет собой большой интервал, пересекающий все интервалы в коллекции, это асимптотически оптимально ; однако мы можем добиться большего, рассмотрев алгоритмы, чувствительные к выходным данным , где время выполнения выражается в терминах , количество интервалов, созданных запросом. Интервальные деревья имеют время запроса и начальное время создания , ограничивая при этом потребление памяти до . После создания деревья интервалов могут быть динамическими, что позволяет эффективно вставлять и удалять интервалы в время. Если конечные точки интервалов находятся в пределах небольшого целочисленного диапазона ( например , в диапазоне ), существуют более быстрые и фактически оптимальные структуры данных [2] [3] со временем предварительной обработки и время запроса для отчетности интервалы, содержащие данную точку запроса (см. [2] для очень простого).






![{\displaystyle [1,\ldots,O (n)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/292672ded6aef6ae4a14183608844cb053711060)

Наивный подход [ править ]
В простом случае интервалы не перекрываются, и их можно вставить в простое двоичное дерево поиска и запросить в время. Однако при произвольном перекрытии интервалов невозможно сравнить два интервала для вставки в дерево, поскольку порядок сортировки по начальным или конечным точкам может быть разным. Наивный подход мог бы заключаться в построении двух параллельных деревьев: одно упорядочено по начальной точке, а другое — по конечной точке каждого интервала. Это позволяет выбросить половину каждого дерева в время, но результаты должны быть объединены, что требует время. Это дает нам запросы в , что не лучше грубой силы.

Интервальные деревья решают эту проблему. В этой статье описываются две альтернативные конструкции дерева интервалов, получившие название центрированное дерево интервалов и расширенное дерево .
Центрированное дерево интервалов [ править ]
Для запросов требуется время, с общее количество интервалов и количество зарегистрированных результатов. Для строительства требуется время и хранение требует космос.
Строительство [ править ]
Учитывая набор интервалов на числовой прямой, мы хотим построить структуру данных, чтобы мы могли эффективно извлекать все интервалы, перекрывающиеся с другим интервалом или точкой.
Начнем с того, что возьмем весь диапазон всех интервалов и разделим его пополам. (на практике, следует выбирать так, чтобы дерево было относительно сбалансированным). Это дает три набора интервалов, полностью левее который мы назовем , те, что полностью справа от который мы назовем и те, которые перекрываются который мы назовем .




Интервалы в и рекурсивно делятся таким же образом до тех пор, пока не останутся интервалы.
Интервалы в которые перекрывают центральную точку, хранятся в отдельной структуре данных, связанной с узлом в дереве интервалов. Эта структура данных состоит из двух списков: один содержит все интервалы, отсортированные по их начальным точкам, а другой содержит все интервалы, отсортированные по их конечным точкам.
В результате получается двоичное дерево , в котором каждый узел хранит:
- Центральная точка
- Указатель на другой узел, содержащий все интервалы полностью слева от центральной точки.
- Указатель на другой узел, содержащий все интервалы полностью справа от центральной точки.
- Все интервалы, перекрывающие центральную точку, отсортированы по их начальной точке.
- Все интервалы, перекрывающие центральную точку, отсортированы по конечной точке.
Пересекающиеся [ править ]
Учитывая построенную выше структуру данных, мы получаем запросы, состоящие из диапазонов или точек, и возвращаем все диапазоны исходного набора, перекрывающие этот ввод.
С точкой [ править ]
Задача — найти в дереве все интервалы, перекрывающие заданную точку. . Обход дерева осуществляется с помощью рекурсивного алгоритма, аналогичного тому, который используется для обхода традиционного двоичного дерева, но с дополнительной логикой для поддержки поиска интервалов, перекрывающих «центральную» точку в каждом узле.

Для каждого узла дерева сравнивается с , средняя точка, использованная при построении узла выше. Если меньше, чем , самый левый набор интервалов, , считается. Если больше, чем , самый правый набор интервалов, , считается.
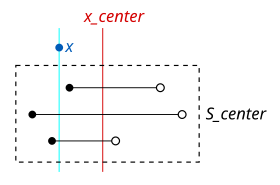
Аналогично, тот же метод применяется и при проверке заданного интервала. Если данный интервал заканчивается в точке y и y меньше , все интервалы в которые начинаются до y, также должны перекрывать заданный интервал.
Поскольку каждый узел обрабатывается по мере прохождения дерева от корня к листу, диапазоны в его обрабатываются. Если меньше, чем , мы знаем, что все интервалы в закончиться после , или они не могли также перекрываться . Поэтому нам нужно найти только эти интервалы в которые начинаются раньше . Мы можем ознакомиться со списками которые уже построены. Поскольку в этом сценарии нас интересуют только начала интервалов, мы можем просмотреть список, отсортированный по началам. Предположим, мы нашли ближайшее число, не превышающее в этом списке. Все диапазоны от начала списка до найденной точки перекрываются потому что они начинаются раньше и закончить после (как мы знаем, потому что они перекрываются который больше, чем ). Таким образом, мы можем просто начать перебирать интервалы в списке до тех пор, пока значение начальной точки не превысит .
Аналогично, если больше, чем , мы знаем, что все интервалы в должно начаться раньше , поэтому находим те интервалы, которые заканчиваются после используя список, отсортированный по окончаниям интервалов.
Если точно соответствует , все интервалы в могут быть добавлены к результатам без дальнейшей обработки, а обход дерева может быть остановлен.
С интервалом [ править ]
Для интервала результата пересечь наш интервал запроса должно выполняться одно из следующих условий:


- начальная и/или конечная точка находится в ; или
- полностью заключает .
Эта статья может сбивать с толку или быть непонятной читателям . ( февраль 2020 г. ) |
Сначала мы находим все интервалы с начальной и/или конечной точкой внутри. с использованием отдельно построенного дерева. В одномерном случае мы можем использовать дерево поиска, содержащее все начальные и конечные точки набора интервалов, каждая из которых имеет указатель на соответствующий интервал. Бинарный поиск в время начала и окончания показывает минимальные и максимальные точки, которые следует учитывать. Каждая точка в этом диапазоне относится к интервалу, который перекрывается и добавляется в список результатов. Необходимо соблюдать осторожность, чтобы избежать дублирования, поскольку интервал может как начинаться, так и заканчиваться в пределах . Это можно сделать, используя двоичный флаг для каждого интервала, чтобы отметить, был ли он добавлен в набор результатов.
Наконец, нам нужно найти интервалы, охватывающие . Чтобы их найти, мы выбираем любую точку внутри и используйте приведенный выше алгоритм, чтобы найти все интервалы, пересекающие эту точку (опять же, стараясь удалить дубликаты).
Высшие измерения [ править ]
Структуру данных дерева интервалов можно обобщить до более высокого измерения. с идентичным временем запроса и построения и космос.

Во-первых, дерево диапазонов в построены измерения, позволяющие эффективно извлекать все интервалы с начальной и конечной точками внутри области запроса. . Как только соответствующие диапазоны найдены, остаются только те диапазоны, которые заключают область в каком-то измерении. Чтобы найти эти совпадения, создаются интервальные деревья, и одна ось пересекается запрашивается для каждого. Например, в двух измерениях нижняя часть квадрата (или любую другую горизонтальную линию, пересекающую ) будет запрошен к дереву интервалов, построенному для горизонтальной оси. Аналогично, левая (или любая другая вертикальная линия, пересекающая ) будет запрашиваться в дереве интервалов, построенном на вертикальной оси.

Каждое дерево интервалов также нуждается в дополнении для более высоких измерений. В каждом узле мы проходим по дереву, сравнивается с чтобы найти совпадения. Вместо двух отсортированных списков точек, как это использовалось в одномерном случае, строится дерево диапазонов. Это позволяет эффективно получить все точки в которые перекрывают регион .
Удаление [ править ]
Если после удаления интервала из дерева узел, содержащий этот интервал, больше не содержит интервалов, этот узел можно удалить из дерева. Это более сложная операция, чем обычная операция удаления двоичного дерева.
Интервал может перекрывать центральную точку нескольких узлов дерева. Поскольку каждый узел хранит перекрывающие его интервалы, причем все интервалы находятся полностью левее его центральной точки в левом поддереве, аналогично правому поддереву, отсюда следует, что каждый интервал хранится в узле, ближайшем к корню из множества узлы, центральную точку которых он перекрывает.
Обычные операции удаления в двоичном дереве (в случае, когда удаляемый узел имеет двух дочерних элементов) включают продвижение узла дальше от листа до позиции удаляемого узла (обычно самого левого дочернего элемента правого поддерева или самого правого дочернего узла). левого поддерева).

В результате такого повышения некоторые узлы, находившиеся выше продвинутого узла, станут его потомками; необходимо найти в этих узлах интервалы, которые также перекрывают продвинутый узел, и переместить эти интервалы в продвинутый узел. Как следствие, это может привести к появлению новых пустых узлов, которые придется удалить снова по тому же алгоритму.
Балансировка [ править ]
Те же проблемы, которые влияют на удаление, также влияют на операции ротации; вращение должно сохранять инвариант, заключающийся в том, что узлы хранятся как можно ближе к корню.
Дополненное дерево [ править ]

Другой способ представления интервалов описан в Cormen et al. (2009 , Раздел 14.3: Интервальные деревья, стр. 348–354).
И вставка, и удаление требуют время, с общее количество интервалов в дереве до операции вставки или удаления.
Расширенное дерево может быть построено из простого упорядоченного дерева, например двоичного дерева поиска или самобалансирующегося двоичного дерева поиска , упорядоченного по «низким» значениям интервалов. Затем к каждому узлу добавляется дополнительная аннотация, записывающая максимальное верхнее значение среди всех интервалов, начиная с этого узла. Поддержание этого атрибута включает обновление всех предков узла снизу вверх при каждом добавлении или удалении узла. Это занимает всего O( h ) шагов на добавление или удаление узла, где h — высота добавленного или удаленного узла в дереве. Если во время вставки и удаления происходят какие-либо повороты дерева , возможно, затронутые узлы также нуждаются в обновлении.
Теперь известно, что два интервала и перекрываться только тогда, когда оба и . При поиске в деревьях узлов, перекрывающихся с заданным интервалом, можно сразу пропустить:




- все узлы справа от узлов, нижнее значение которых находится за концом заданного интервала.
- все узлы, максимальное значение которых находится ниже начала заданного интервала.
Запросы на членство [ править ]
Некоторая производительность может быть увеличена, если дерево избегает ненужных обходов. Это может произойти при добавлении уже существующих интервалов или удалении несуществующих интервалов.
Общий порядок можно определить на интервалах, упорядочив их сначала по нижним границам, а затем по верхним границам. Затем проверку членства можно выполнить в время, по сравнению с время, необходимое для поиска дубликатов, если интервалы перекрывают интервал, который необходимо вставить или удалить. Преимущество этого решения состоит в том, что оно не требует каких-либо дополнительных конструкций. Изменение строго алгоритмическое. Недостаток заключается в том, что запросы на членство занимают время.


Поочередно, по курсу В памяти запросы на членство в ожидаемом постоянном времени могут быть реализованы с помощью хеш-таблицы, обновляемой синхронно с деревом интервалов. Это не обязательно удвоит общую потребность в памяти, если интервалы хранятся по ссылке, а не по значению.
Пример Java: добавление нового интервала в дерево [ править ]
Ключом каждого узла является сам интервал, поэтому узлы упорядочиваются сначала по наименьшему значению, а затем по высокому значению, а значение каждого узла является конечной точкой интервала:
public void add(Interval i) {
put(i, i.getEnd());
}
Пример Java: поиск точки или интервала в дереве [ править ]
Для поиска интервала проходим по дереву, используя ключ ( n.getKey()) и высокое значение ( n.getValue()), чтобы опустить все ветки, которые не могут перекрывать запрос. Самый простой случай — точечный запрос:
// Search for all intervals containing "p", starting with the
// node "n" and adding matching intervals to the list "result"
public void search(IntervalNode n, Point p, List<Interval> result) {
// Don't search nodes that don't exist
if (n == null)
return;
// If p is to the right of the rightmost point of any interval
// in this node and all children, there won't be any matches.
if (p.compareTo(n.getValue()) > 0)
return;
// Search left children
search(n.getLeft(), p, result);
// Check this node
if (n.getKey().contains(p))
result.add(n.getKey());
// If p is to the left of the start of this interval,
// then it can't be in any child to the right.
if (p.compareTo(n.getKey().getStart()) < 0)
return;
// Otherwise, search right children
search(n.getRight(), p, result);
}
где
a.compareTo(b)возвращает отрицательное значение, если a < ba.compareTo(b)возвращает ноль, если a = ba.compareTo(b)возвращает положительное значение, если a > b
Код для поиска интервала аналогичен, за исключением проверки посередине:
// Check this node
if (n.getKey().overlapsWith(i))
result.add (n.getKey());
overlapsWith() определяется как:
public boolean overlapsWith(Interval other) {
return start.compareTo(other.getEnd()) <= 0 &&
end.compareTo(other.getStart()) >= 0;
}
Высшие измерения [ править ]
Дополненные деревья можно расширить до более высоких измерений, циклически просматривая измерения на каждом уровне дерева. Например, для двух измерений нечетные уровни дерева могут содержать диапазоны координаты x , а четные уровни содержат диапазоны координаты y . Этот подход эффективно преобразует структуру данных из расширенного двоичного дерева в расширенное kd-дерево , тем самым существенно усложняя алгоритмы балансировки вставок и удалений.
Более простое решение — использовать вложенные деревья интервалов. Сначала создайте дерево, используя диапазоны координаты y . Теперь для каждого узла в дереве добавьте еще одно дерево интервалов в x- диапазонах для всех элементов, у которых y -диапазон совпадает с y -диапазоном этого узла.
Преимущество этого решения в том, что его можно расширить до произвольного числа измерений, используя ту же базу кода.
На первый взгляд дополнительные затраты на вложенные деревья могут показаться непомерно высокими, но обычно это не так. Как и в случае с невложенным решением ранее, для каждой координаты x необходим один узел , что дает одинаковое количество узлов для обоих решений. Единственные дополнительные издержки — это вложенные древовидные структуры, по одной на вертикальный интервал. Эта структура обычно имеет незначительный размер и состоит только из указателя на корневой узел и, возможно, количество узлов и глубину дерева.
Дерево, ориентированное по медиальной или длине [ править ]
Медиальное или ориентированное по длине дерево похоже на расширенное дерево, но симметрично, с двоичным деревом поиска, упорядоченным по средним точкам интервалов. В каждом узле имеется двоичная куча , ориентированная на максимум, упорядоченная по длине интервала (или половине длины). Также мы храним минимальное и максимально возможное значение поддерева в каждом узле (таким образом, симметрия).
Тест на перекрытие [ править ]
Использование только начальных и конечных значений двух интервалов , для , тест на перекрытие можно выполнить следующим образом:


и


Это можно упростить, используя сумму и разность:


Это уменьшает тест на перекрытие до:

Добавление интервала [ править ]
Добавление новых интервалов в дерево происходит так же, как и для двоичного дерева поиска с использованием срединного значения в качестве ключа. Мы толкаем в двоичную кучу, связанную с узлом, и обновить минимальное и максимальное возможные значения, связанные со всеми узлами более высокого уровня.

Поиск всех перекрывающихся интервалов [ править ]
Давайте использовать для интервала запроса и для ключа узла (по сравнению с интервалов)



Начиная с корневого узла, в каждом узле сначала мы проверяем, возможно ли, что наш интервал запроса перекрывается с поддеревом узла, используя минимальное и максимальное значения узла (если это не так, мы не продолжаем для этого узла).
Затем мы вычисляем чтобы интервалы внутри этого узла (а не его дочерние элементы) перекрывались с интервалом запроса (зная ):



и выполнить запрос к его двоичной куче для больше, чем
Затем мы проходим через левых и правых дочерних элементов узла, делая то же самое.
В худшем случае нам придется сканировать все узлы двоичного дерева поиска, но поскольку запрос к двоичной куче оптимален, это приемлемо (двумерная задача не может быть оптимальной в обоих измерениях).
Ожидается, что этот алгоритм будет быстрее, чем традиционное дерево интервалов (расширенное дерево) для операций поиска. На практике добавление элементов происходит немного медленнее, хотя порядок роста тот же.
Ссылки [ править ]
- ^ https://personal.us.es/almar/cg/08windowing.pdf [ только URL-адрес PDF ]
- ↑ Перейти обратно: Перейти обратно: а б Йенс М. Шмидт . Проблемы интервальной обработки в малых целочисленных диапазонах . ДОИ . ИСААК'09, 2009 г.
- ^ Запросы диапазона#Операторы полугруппы
- Марк де Берг , Марк ван Кревельд , Марк Овермарс и Отфрид Шварцкопф . Вычислительная геометрия , второе исправленное издание. Springer-Verlag 2000. Раздел 10.1: Интервальные деревья, стр. 212–217.
- Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л .; Штейн, Клиффорд (2009), Введение в алгоритмы (3-е изд.), MIT Press и McGraw-Hill, ISBN 978-0-262-03384-8
- Франко П. Препарата и Майкл Ян Шамос . Вычислительная геометрия: Введение . Спрингер-Верлаг, 1985 г.
Внешние ссылки [ править ]
- CGAL: Библиотека алгоритмов вычислительной геометрии на C++ содержит надежную реализацию деревьев диапазонов.
- Boost.Icl предлагает реализации наборов интервалов и карт на C++.
- IntervalTree (Python) — центрированное дерево интервалов с балансировкой AVL, совместимое с интервалами с тегами.
- Дерево интервалов (C#) — расширенное дерево интервалов с балансировкой AVL.
- Дерево интервалов (Ruby) — центрированное дерево интервалов, неизменяемое, совместимое с интервалами с тегами.
- IntervalTree (Java) — расширенное дерево интервалов с балансировкой AVL, поддержкой перекрытия, поиска, интерфейса сбора, интервалов, связанных с идентификатором.
- Tree::Interval::Fast (Perl/C) — эффективное создание интервальных деревьев и манипулирование ими.