Итеративный поиск в глубину с углублением
Эта статья нуждается в дополнительных цитатах для проверки . ( январь 2017 г. ) |
| Сорт | Алгоритм поиска |
|---|---|
| Структура данных | Дерево , График |
| Худшая производительность | , где является фактором ветвления и это глубина самого мелкого раствора |
| Наихудшая пространственная сложность | [1] |
| Оптимальный | да (для невзвешенных графиков) |




В информатике — итеративный поиск с углублением или, точнее, итеративный поиск в глубину с углублением. [1] (IDS или IDDFS) — это стратегия поиска в пространстве состояний /графе, в которой ограниченная по глубине версия поиска в глубину запускается повторно с увеличением пределов глубины, пока цель не будет найдена. IDDFS оптимален, что означает, что он находит самую поверхностную цель. [2] Поскольку он посещает все узлы дерева поиска вплоть до глубины перед посещением каких-либо узлов на глубине , совокупный порядок первого посещения узлов фактически такой же, как и при поиске в ширину . Однако IDDFS использует гораздо меньше памяти. [1]

Алгоритм для ориентированных графов
[ редактировать ]Следующий псевдокод показывает IDDFS, реализованную в виде рекурсивной DFS с ограниченной глубиной (называемой DLS) для ориентированных графов . Эта реализация IDDFS не учитывает уже посещенные узлы.
function IDDFS(root) is
for depth from 0 to ∞ do
found, remaining ← DLS(root, depth)
if found ≠ null then
return found
else if not remaining then
return null
function DLS(node, depth) is
if depth = 0 then
if node is a goal then
return (node, true)
else
return (null, true) (Not found, but may have children)
else if depth > 0 then
any_remaining ← false
foreach child of node do
found, remaining ← DLS(child, depth−1)
if found ≠ null then
return (found, true)
if remaining then
any_remaining ← true (At least one node found at depth, let IDDFS deepen)
return (null, any_remaining)
Если целевой узел найден DLS , IDDFS вернет его, не заглядывая глубже. В противном случае, если хотя бы один узел существует на этом уровне глубины, оставшийся флаг позволит IDDFS продолжить работу.
Двухкортежи полезны в качестве возвращаемого значения, чтобы сигнализировать IDDFS неизвестны о продолжении углубления или остановке, в случае, если глубина дерева и целевое членство априори . Другое решение может использовать вместо этого контрольные значения для представления не найденных или оставшихся уровней результатов .
Характеристики
[ редактировать ]IDDFS достигает полноты поиска в ширину (когда коэффициент ветвления конечен) с использованием пространственной эффективности поиска в глубину. Если решение существует, оно найдет путь решения с наименьшим количеством дуг. [2]
Итеративные углубленные посещения штатов проводятся несколько раз, и это может показаться расточительным. Однако если IDDFS исследует дерево поиска на глубину , большая часть общих усилий направлена на глубокое изучение состояний . Относительно количества состояний на глубине , стоимость повторного посещения состояний выше этой глубины всегда невелика. [3]
Основное преимущество IDDFS при поиске в дереве игры состоит в том, что более ранние поиски имеют тенденцию улучшать часто используемые эвристики, такие как эвристика-убийца и альфа-бета-отсечение , так что более точная оценка оценки различных узлов при окончательном поиске на глубину может произойти, и поиск завершается быстрее, поскольку он выполняется в лучшем порядке. Например, альфа-бета-отсечение наиболее эффективно, если сначала ищется лучший ход. [3]
Второе преимущество — оперативность алгоритма. Поскольку ранние итерации используют небольшие значения для , они выполняются чрезвычайно быстро. Это позволяет алгоритму практически сразу же предоставлять ранние сведения о результате с последующими уточнениями по мере необходимости. увеличивается. При использовании в интерактивной обстановке, например, в программе для игры в шахматы , эта возможность позволяет программе играть в любое время с текущим лучшим ходом, найденным в результате поиска, который она завершила на данный момент. Это можно сформулировать так: каждая глубина поиска корекурсивно . обеспечивает лучшее приближение решения, хотя работа, выполняемая на каждом этапе, является рекурсивной Это невозможно при традиционном поиске в глубину, который не дает промежуточных результатов.
Асимптотический анализ
[ редактировать ]Временная сложность
[ редактировать ]Временная сложность IDDFS в (хорошо сбалансированном) дереве оказывается такой же, как и при поиске в ширину, т.е. , [1] : 5 где является фактором ветвления и это глубина цели.
Доказательство
[ редактировать ]При итеративном поиске с углублением узлы на глубине расширяются один раз, те, что на глубине расширяются дважды и так далее до корня дерева поиска, который расширенный раз. [1] : 5 Таким образом, общее количество расширений в итеративном поиске с углублением равно


где количество расширений на глубине , количество расширений на глубине , и так далее. Факторинг дает



Теперь позвольте . Тогда у нас есть


Это меньше, чем бесконечная серия

который сходится к
- , для


То есть у нас есть
, для

С или является константой, не зависящей от (глубина), если (т. е. если коэффициент ветвления больше 1), время выполнения итеративного поиска с углублением в глубину равно .



Пример
[ редактировать ]Для и номер



В общем, итеративный углубляющийся поиск из глубины. вплоть до глубины расширяется только примерно больше узлов, чем один поиск в ширину или с ограничением по глубине , когда . [4]


Чем выше коэффициент ветвления, тем меньше накладные расходы на многократно расширяемые состояния. [1] : 6 но даже когда коэффициент ветвления равен 2, итеративный поиск с углублением занимает примерно вдвое больше времени, чем полный поиск в ширину. Это означает, что временная сложность итеративного углубления по-прежнему велика. .
Пространственная сложность
[ редактировать ]Пространственная сложность IDDFS составляет , [1] : 5 где это глубина цели.
Доказательство
[ редактировать ]Поскольку IDDFS в любой момент выполняет поиск в глубину, ему нужно хранить только стек узлов, который представляет ветвь дерева, которое он расширяет. Поскольку он находит решение оптимальной длины, максимальная глубина этого стека равна , и, следовательно, максимальный объем пространства равен .
В общем, итеративное углубление является предпочтительным методом поиска, когда пространство поиска большое и глубина решения неизвестна. [3]
Пример
[ редактировать ]Для следующего графика:
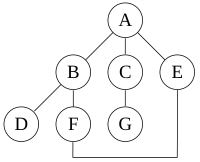
поиск в глубину, начиная с A, предполагая, что левые ребра в показанном графе выбраны раньше правых ребер, и предполагая, что поиск запоминает ранее посещенные узлы и не будет повторять их (поскольку это небольшой граф), посетит узлы в следующем порядке: A, B, D, F, E, C, G. Ребра, пройденные в этом поиске, образуют дерево Тремо — структуру, имеющую важные применения в теории графов .
Выполнение того же поиска без запоминания ранее посещенных узлов приводит к посещению узлов в порядке A, B, D, F, E, A, B, D, F, E и т. д. навсегда, попадая в A, B, D, F. , цикл E и никогда не достигает C или G.
Итеративное углубление предотвращает этот цикл и достигает следующих узлов на следующих глубинах, при условии, что оно происходит слева направо, как указано выше:
- 0: А
- 1: А, Б, В, Е
(Теперь при итеративном углублении появился C, а при обычном поиске в глубину — нет.)
- 2: А, Б, Г, Ж, В, Г, Е, Ж
(Он по-прежнему видит C, но появился позже. Кроме того, он видит E по другому пути и дважды возвращается к F.)
- 3: А, Б, Г, Ж, Е, С, Г, Е, Ж, Б
Для этого графика по мере увеличения глубины два цикла «ABFE» и «AEFB» просто станут длиннее, прежде чем алгоритм сдастся и попробует другую ветвь.
Связанные алгоритмы
[ редактировать ]Подобно итеративному углублению, существует стратегия поиска, называемая поиском с итеративным удлинением , которая работает с увеличением пределов стоимости пути вместо ограничений глубины. Он расширяет узлы в порядке увеличения стоимости пути; поэтому первой целью, с которой он сталкивается, является цель с наименьшей стоимостью пути. Однако итеративное удлинение требует значительных накладных расходов, что делает его менее полезным, чем итеративное углубление. [3]
Итеративное углубление A* — это поиск по принципу «наилучшее первое», который выполняет итеративное углубление на основе значений « f », аналогичных тем, которые вычислены в алгоритме A* .
Двунаправленный IDDFS
[ редактировать ]IDDFS имеет двунаправленный аналог, [1] : 6 который чередует два поиска: один начинается с исходного узла и движется по направленным дугам, а другой начинается с целевого узла и продолжается по направленным дугам в противоположном направлении (от головного узла дуги к хвостовому узлу дуги). Процесс поиска сначала проверяет, что исходный узел и целевой узел совпадают, и если это так, возвращает тривиальный путь, состоящий из одного исходного/целевого узла. В противном случае процесс прямого поиска расширяет дочерние узлы исходного узла (установите ), процесс обратного поиска расширяет родительские узлы целевого узла (установите ), и проверяется, и пересекаться. Если да, то кратчайший путь найден. В противном случае глубина поиска увеличивается и выполняются те же вычисления.


Одним из ограничений алгоритма является то, что кратчайший путь, состоящий из нечетного числа дуг, не будет обнаружен. Предположим, у нас есть кратчайший путь Когда глубина достигнет двух прыжков по дугам, прямой поиск будет продолжаться от к , и обратный поиск будет продолжаться от к . Графически границы поиска будут проходить друг через друга, а вместо этого будет возвращен неоптимальный путь, состоящий из четного числа дуг. Это показано на диаграммах ниже:




Что касается пространственной сложности, алгоритм окрашивает самые глубокие узлы в процессе прямого поиска, чтобы обнаружить существование среднего узла, где встречаются два процесса поиска.
Дополнительная сложность применения двунаправленной IDDFS заключается в том, что если исходный и целевой узлы находятся в разных сильно связанных компонентах, скажем, , если нет ухода дуги и входя , поиск никогда не завершится.



Временные и пространственные сложности
[ редактировать ]Время работы двунаправленной IDDFS определяется выражением

а пространственная сложность определяется выражением

где количество узлов в кратчайшем -путь. Поскольку сложность времени выполнения итеративного поиска в глубину с углублением равна , ускорение примерно




Псевдокод
[ редактировать ]function Build-Path(s, μ, B) is
π ← Find-Shortest-Path(s, μ) (Recursively compute the path to the relay node)
remove the last node from π
return π B (Append the backward search stack)

function Depth-Limited-Search-Forward(u, Δ, F) is
if Δ = 0 then
F ← F {u} (Mark the node)
return
foreach child of u do
Depth-Limited-Search-Forward(child, Δ − 1, F)

function Depth-Limited-Search-Backward(u, Δ, B, F) is
prepend u to B
if Δ = 0 then
if u in F then
return u (Reached the marked node, use it as a relay node)
remove the head node of B
return null
foreach parent of u do
μ ← Depth-Limited-Search-Backward(parent, Δ − 1, B, F)
if μ null then
return μ
remove the head node of B
return null

function Find-Shortest-Path(s, t) is
if s = t then
return <s>
F, B, Δ ← ∅, ∅, 0
forever do
Depth-Limited-Search-Forward(s, Δ, F)
foreach δ = Δ, Δ + 1 do
μ ← Depth-Limited-Search-Backward(t, δ, B, F)
if μ null then
return Build-Path(s, μ, B) (Found a relay node)
F, Δ ← ∅, Δ + 1
Ссылки
[ редактировать ]- ^ Jump up to: а б с д и ж г час Корф, Ричард (1985). «Итеративное углубление в глубину: поиск оптимального допустимого дерева». Искусственный интеллект . 27 : 97–109. дои : 10.1016/0004-3702(85)90084-0 . S2CID 10956233 .
- ^ Jump up to: а б Дэвид Пул; Алан Макворт. «3.5.3 Итеративное углубление ‣ Глава 3 Поиск решений ‣ Искусственный интеллект: основы вычислительных агентов, 2-е издание» . artint.info . Проверено 29 ноября 2018 г.
- ^ Jump up to: а б с д Рассел, Стюарт Дж .; Норвиг, Питер (2003), Искусственный интеллект: современный подход (2-е изд.), Аппер-Сэддл-Ривер, Нью-Джерси: Прентис-Холл, ISBN 0-13-790395-2
- ^ Рассел; Норвиг (1994). Искусственный интеллект: современный подход .