Алгоритм поиска A*
| Сорт | Алгоритм поиска |
|---|---|
| Структура данных | График |
| Худшая производительность | |
| Наихудшая пространственная сложность |


A* (произносится как «А-звезда») — обхода графа и поиска пути алгоритм , который используется во многих областях информатики благодаря своей полноте, оптимальности и оптимальной эффективности. [1] Учитывая взвешенный граф , исходный узел и целевой узел, алгоритм находит кратчайший путь (относительно заданных весов) от источника к цели.
Одним из основных практических недостатков является пространственная сложность , где d — глубина решения (длина кратчайшего пути), а b — коэффициент ветвления (среднее количество преемников на состояние), поскольку все сгенерированные узлы хранятся в памяти. Таким образом, в практических системах маршрутизации поездок его обычно уступают алгоритмам, которые могут предварительно обрабатывать график для достижения лучшей производительности. [2] а также с помощью подходов, ограниченных памятью; однако A* по-прежнему остается лучшим решением во многих случаях. [3]

Питер Харт , Нильс Нильссон и Бертрам Рафаэль из Стэнфордского исследовательского института (ныне SRI International ) впервые опубликовали алгоритм в 1968 году. [4] Его можно рассматривать как расширение алгоритма Дейкстры . A* достигает большей производительности, используя эвристику для управления поиском.
По сравнению с алгоритмом Дейкстры, алгоритм A* находит только кратчайший путь от указанного источника к указанной цели, а не дерево кратчайшего пути от указанного источника ко всем возможным целям. Это необходимый компромисс для использования эвристики, ориентированной на конкретную цель. Для алгоритма Дейкстры, поскольку генерируется все дерево кратчайшего пути, каждый узел является целью, и не может быть никакой эвристики, направленной на конкретную цель.
История [ править ]

A* был создан в рамках проекта Shakey , целью которого было создание мобильного робота, способного самостоятельно планировать свои действия. Нильс Нильссон первоначально предложил использовать алгоритм Graph Traverser. [5] для планирования пути Шейки. [6] Graph Traverser руководствуется эвристической функцией h ( n ) — предполагаемым расстоянием от узла n до целевого узла: он полностью игнорирует g ( n ) — расстояние от начального узла до n . Бертрам Рафаэль предложил использовать сумму g ( n ) + h ( n ) . [7] Питер Харт изобрел концепции, которые мы сейчас называем допустимостью и непротиворечивостью эвристических функций. Первоначально A* был разработан для поиска путей с наименьшей стоимостью, когда стоимость пути равна сумме его стоимостей, но было показано, что A* можно использовать для поиска оптимальных путей для любой задачи, удовлетворяющей условиям алгебры стоимости. [8]
Оригинальная бумага A * 1968 года. [4] содержала теорему о том, что ни один A*-подобный алгоритм [а] может расширить меньше узлов, чем A*, если эвристическая функция непротиворечива и правильно выбрано правило разрешения конфликтов для A*. «Поправка» была опубликована несколько лет спустя. [9] утверждая, что последовательность не требуется, но это оказалось ложным в 1985 году в окончательном исследовании Дехтера и Перла оптимальности A* (теперь называемого оптимальной эффективностью), которое дало пример A* с эвристикой, которая была допустимой, но не последовательное расширение произвольно большего количества узлов, чем альтернативный A*-подобный алгоритм. [10]
Описание [ править ]

A* — это алгоритм информированного поиска , или поиск по принципу «сначала лучший» , что означает, что он сформулирован в терминах взвешенных графов : начиная с определенного начального узла графа, он стремится найти путь к заданному целевому узлу, имеющему наименьшее стоимость (наименьшее пройденное расстояние, кратчайшее время и т. д.). Это достигается путем поддержания дерева путей, берущих начало в начальном узле, и расширения этих путей по одному ребру за раз, пока не будет достигнут целевой узел.
На каждой итерации основного цикла A* необходимо определить, какой из путей следует расширить. Это делается на основе стоимости пути и оценки стоимости, необходимой для продления пути до цели. В частности, A* выбирает путь, который минимизирует

где n — следующий узел на пути, g ( n ) — стоимость пути от начального узла до n , а h ( n ) — эвристическая функция, оценивающая стоимость самого дешевого пути от n до цели. Эвристическая функция зависит от проблемы. Если эвристическая функция допустима (то есть она никогда не переоценивает фактическую стоимость достижения цели), A* гарантированно вернет путь с наименьшими затратами от начала до цели.
Типичные реализации A* используют очередь приоритетов для повторного выбора узлов с минимальной (оценочной) стоимостью для расширения. Эта приоритетная очередь известна как открытое множество , граница или граница . На каждом шаге алгоритма узел с наименьшим значением f ( x ) удаляется из очереди, значения f и g его соседей соответственно обновляются, и эти соседи добавляются в очередь. Алгоритм продолжается до тех пор, пока удаленный узел (то есть узел с наименьшим значением f из всех краевых узлов) не станет целевым узлом. [б] Значение f этой цели тогда также является стоимостью кратчайшего пути, поскольку h в цели равно нулю в допустимой эвристике.
Описанный до сих пор алгоритм дает нам только длину кратчайшего пути. Чтобы найти фактическую последовательность шагов, алгоритм можно легко пересмотреть, чтобы каждый узел на пути отслеживал своего предшественника. После запуска этого алгоритма конечный узел будет указывать на своего предшественника и так далее, пока предшественник какого-либо узла не станет начальным узлом.
Например, при поиске кратчайшего маршрута на карте h ( x ) может представлять собой расстояние по прямой до цели, поскольку это физически наименьшее возможное расстояние между любыми двумя точками. Для карты-сетки из видеоигры использование расстояния Такси или расстояния Чебышева становится лучше в зависимости от набора доступных движений (4-х или 8-х).
Если эвристика h удовлетворяет дополнительному условию h ( x ) ≤ d ( x , y ) + h ( y ) для каждого ребра ( x , y ) графа (где d обозначает длину этого ребра), то h называется монотонный или последовательный . При последовательной эвристике A* гарантированно найдет оптимальный путь без обработки какого-либо узла более одного раза, а A* эквивалентно запуску алгоритма Дейкстры с уменьшенной стоимостью d' ( x , y ) = d ( x , y ) + h ( y ) - час ( Икс ) . [11]
Псевдокод [ править ]
Следующий псевдокод описывает алгоритм:
function reconstruct_path(cameFrom, current)
total_path := {current}
while current in cameFrom.Keys:
current := cameFrom[current]
total_path.prepend(current)
return total_path
// A* finds a path from start to goal.
// h is the heuristic function. h(n) estimates the cost to reach goal from node n.
function A_Star(start, goal, h)
// The set of discovered nodes that may need to be (re-)expanded.
// Initially, only the start node is known.
// This is usually implemented as a min-heap or priority queue rather than a hash-set.
openSet := {start}
// For node n, cameFrom[n] is the node immediately preceding it on the cheapest path from the start
// to n currently known.
cameFrom := an empty map
// For node n, gScore[n] is the cost of the cheapest path from start to n currently known.
gScore := map with default value of Infinity
gScore[start] := 0
// For node n, fScore[n] := gScore[n] + h(n). fScore[n] represents our current best guess as to
// how cheap a path could be from start to finish if it goes through n.
fScore := map with default value of Infinity
fScore[start] := h(start)
while openSet is not empty
// This operation can occur in O(Log(N)) time if openSet is a min-heap or a priority queue
current := the node in openSet having the lowest fScore[] value
if current = goal
return reconstruct_path(cameFrom, current)
openSet.Remove(current)
for each neighbor of current
// d(current,neighbor) is the weight of the edge from current to neighbor
// tentative_gScore is the distance from start to the neighbor through current
tentative_gScore := gScore[current] + d(current, neighbor)
if tentative_gScore < gScore[neighbor]
// This path to neighbor is better than any previous one. Record it!
cameFrom[neighbor] := current
gScore[neighbor] := tentative_gScore
fScore[neighbor] := tentative_gScore + h(neighbor)
if neighbor not in openSet
openSet.add(neighbor)
// Open set is empty but goal was never reached
return failure
Примечание. В этом псевдокоде, если узел достигается одним путем, удаляется из openSet, а затем достигается более дешевым путем, он снова будет добавлен в openSet. Это важно для того, чтобы гарантировать, что возвращаемый путь является оптимальным, если эвристическая функция допустима , но несовместима . Если эвристика непротиворечива, то при удалении узла из openSet путь к нему гарантированно будет оптимальным, поэтому тест ' tentative_gScore < gScore[neighbor]' всегда завершится неудачей, если узел будет достигнут снова.

Пример [ править ]
Пример алгоритма A* в действии, где узлами являются города, соединенные дорогами, а h(x) — расстояние по прямой до целевой точки:
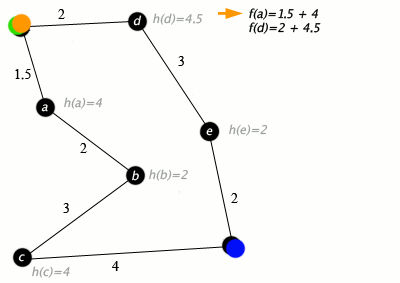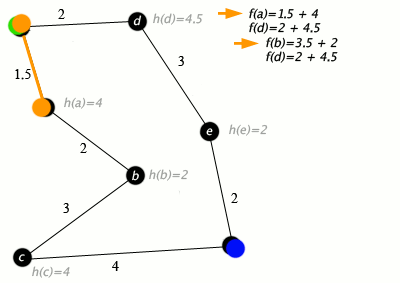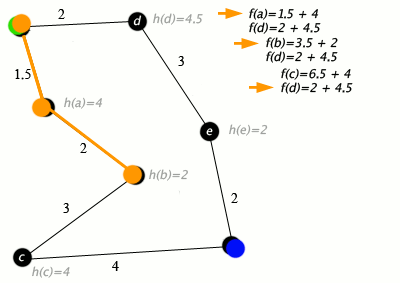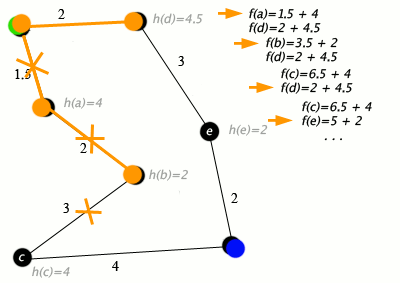
Клавиша: зеленая: старт; синий: цель; оранжевый: посетил
Алгоритм A* имеет реальное применение. В этом примере края — это железные дороги, а h(x) — расстояние по большому кругу (кратчайшее возможное расстояние на сфере) до цели. Алгоритм ищет путь между Вашингтоном (округ Колумбия) и Лос-Анджелесом.

Детали реализации [ править ]
Существует ряд простых оптимизаций или деталей реализации, которые могут существенно повлиять на производительность реализации A*. Первая деталь, на которую следует обратить внимание, заключается в том, что способ обработки связей приоритетной очередью может в некоторых ситуациях существенно влиять на производительность. Если связи нарушены и очередь ведет себя по принципу LIFO , A* будет вести себя как поиск в глубину среди путей с равной стоимостью (избегая исследования более чем одного одинаково оптимального решения).
Когда в конце поиска требуется путь, обычно в каждом узле сохраняется ссылка на родительский узел этого узла. В конце поиска эти ссылки можно использовать для восстановления оптимального пути. Если эти ссылки сохраняются, может быть важно, чтобы один и тот же узел не появлялся в очереди приоритетов более одного раза (каждая запись соответствует разному пути к узлу и каждая имеет разную стоимость). Стандартный подход здесь — проверить, появился ли уже добавляемый узел в приоритетной очереди. Если да, то указатели приоритета и родительского элемента изменяются, чтобы соответствовать пути с меньшей стоимостью. Стандартная приоритетная очередь на основе двоичной кучи не поддерживает напрямую операцию поиска одного из своих элементов, но ее можно дополнить хеш-таблицей , которая сопоставляет элементы с их положением в куче, позволяя выполнять эту операцию понижения приоритета в логарифмическое время. В качестве альтернативы, куча Фибоначчи может выполнять те же операции с понижением приоритета в константах. амортизированное время .
Особые случаи [ править ]
Алгоритм Дейкстры , как еще один пример алгоритма поиска с равномерной стоимостью, можно рассматривать как частный случай A*, где для всех х . [12] [13] Общий поиск в глубину можно реализовать с использованием A*, если учесть, что существует глобальный счетчик C, инициализированный очень большим значением. Каждый раз, когда мы обрабатываем узел, мы присваиваем C всем его вновь обнаруженным соседям. После каждого присваивания мы уменьшаем счетчик C на единицу. Таким образом, чем раньше обнаружен узел, тем выше его ценить. И алгоритм Дейкстры, и поиск в глубину могут быть реализованы более эффективно без включения значение в каждом узле.


Свойства [ править ]
Прекращение действия и полнота [ править ]
На конечных графах с неотрицательными весами ребер A* гарантированно завершается и является полным , т. е. всегда найдет решение (путь от начала до цели), если оно существует. На бесконечных графах с конечным фактором ветвления и ценами ребер, отделенными от нуля ( для некоторых фиксированных ), A* гарантированно завершится, только если существует решение. [1]


Приемлемость [ править ]
Алгоритм поиска называется допустимым , если он гарантированно возвращает оптимальное решение. Если эвристическая функция, используемая A*, допустима , то A* допустима. Интуитивное «доказательство» этого состоит в следующем:
Когда A* завершает свой поиск, он нашел путь от начала до цели, фактическая стоимость которого ниже, чем предполагаемая стоимость любого пути от начала до цели через любой открытый узел ( ценить). Когда эвристика допустима, эти оценки оптимистичны (не совсем — см. следующий абзац), поэтому A* может безопасно игнорировать эти узлы, поскольку они не могут привести к более дешевому решению, чем то, которое у него уже есть. Другими словами, A* никогда не упустит из виду возможность более дешевого пути от начала до цели и поэтому будет продолжать поиск до тех пор, пока такие возможности не исчезнут.

Фактическое доказательство немного сложнее, потому что значения открытых узлов не обязательно будут оптимистичными, даже если эвристика допустима. Это потому, что значения открытых узлов не гарантированно будут оптимальными, поэтому сумма не гарантирует оптимизма.


Оптимальность и последовательность [ править ]
Алгоритм A оптимально эффективен по отношению к множеству альтернативных алгоритмов Alts на множестве задач P, если для каждой задачи P в P и каждого алгоритма A' в Alts набор узлов, расширенный A при решении P, является подмножеством (возможно, равно) множества узлов, расширенных на A ' при решении P. Окончательное исследование оптимальной эффективности A * принадлежит Рине Дехтер и Джуде Перл. [10] Они считали, что различные определения Alts и P в сочетании с эвристикой A* являются просто допустимыми или одновременно непротиворечивыми и допустимыми. Самый интересный положительный результат, который они доказали, заключается в том, что A* с последовательной эвристикой оптимально эффективен по отношению ко всем допустимым A*-подобным алгоритмам поиска для всех «непатологических» задач поиска. Грубо говоря, их представление о непатологической проблеме — это то, что мы сейчас подразумеваем под «вплоть до решения тай-брейка». Этот результат неверен, если эвристика А* допустима, но несовместна. В этом случае Дехтер и Перл показали, что существуют допустимые A*-подобные алгоритмы, которые могут расширять произвольно меньше узлов, чем A*, для некоторых непатологических задач.
Оптимальная эффективность связана с расширенным набором узлов, а не с количеством расширений узлов (количество итераций основного цикла A*). Когда используемая эвристика допустима, но несовместима, узел может быть расширен на A* много раз, в худшем случае – экспоненциальное число раз. [14] В таких обстоятельствах алгоритм Дейкстры может значительно превзойти A*. Однако более поздние исследования показали, что этот патологический случай возникает только в определенных надуманных ситуациях, когда вес ребра графа поиска экспоненциально зависит от размера графа, и что определенные противоречивые (но допустимые) эвристики могут привести к уменьшению количества расширений узлов. в поиске A*. [15] [16]
Ограниченное расслабление [ править ]

Хотя критерий допустимости гарантирует оптимальный путь решения, он также означает, что A* должен проверить все одинаково эффективные пути, чтобы найти оптимальный путь. Для вычисления приближенных кратчайших путей можно ускорить поиск за счет оптимальности, ослабив критерий допустимости. Часто мы хотим ограничить это расслабление, чтобы гарантировать, что путь решения не хуже, чем (1 + ε ) раз оптимальный путь решения. Эта новая гарантия называется ε -допустимой.
Существует ряд ε -допустимых алгоритмов:
- Взвешенное A*/статическое взвешивание. [17] Если h a ( n ) является допустимой эвристической функцией, во взвешенной версии поиска A* используется h w ( n ) = ε h a ( n ) , ε > 1 в качестве эвристической функции и выполняется поиск A * как обычно (что в конечном итоге происходит быстрее, чем при использовании h a, поскольку расширяется меньше узлов). Таким образом, путь, найденный алгоритмом поиска, может иметь стоимость, не более чем в ε раз превышающую стоимость пути с наименьшей стоимостью в графе. [18]
- Динамическое взвешивание [19] использует функцию стоимости , где , и где — глубина поиска, а N — ожидаемая длина пути решения.
- Выборочное динамическое взвешивание [20] использует выборку узлов для лучшей оценки и устранения эвристической ошибки.
- . [21] использует две эвристические функции. Первый — это список FOCAL, который используется для выбора узлов-кандидатов, а второй h F используется для выбора наиболее перспективного узла из списка FOCAL.
- ε [22] выбирает узлы с помощью функции , где A и B — константы. Если ни один узел не может быть выбран, алгоритм вернется с помощью функции , где C и D — константы.
- Альфа* [23] попытки продвигать эксплуатацию в глубину, отдавая предпочтение недавно расширенным узлам. Alpha* использует функцию стоимости , где , где λ и Λ — константы с , π ( n ) является родительским узлом n , а ñ является последним расширенным узлом.









Сложность [ править ]
Временная сложность A* зависит от эвристики. В худшем случае неограниченного пространства поиска количество расширенных узлов экспоненциально зависит от глубины решения (кратчайшего пути) d : O ( b д ) , где b — коэффициент ветвления (среднее количество преемников на одно состояние). [24] Это предполагает, что целевое состояние вообще существует и достижимо из начального состояния; если это не так и пространство состояний бесконечно, алгоритм не завершится.
Эвристическая функция оказывает большое влияние на практическую эффективность поиска A*, поскольку хорошая эвристика позволяет A* отсекать многие из b. д узлы, которые неосведомленный поиск расширил бы. Его качество можно выразить через эффективный коэффициент ветвления b * , который можно определить эмпирически для конкретного экземпляра задачи путем измерения количества узлов, генерируемых расширением, N и глубины решения, а затем решения [25]

Хорошими эвристиками являются эвристики с низким эффективным коэффициентом ветвления (оптимальным является b * = 1 ).
Временная сложность является полиномиальной , когда пространство поиска представляет собой дерево, существует одно целевое состояние и эвристическая функция h удовлетворяет следующему условию:

где ч * — оптимальная эвристика, точная стоимость перехода от x к цели. Другими словами, ошибка h не будет расти быстрее, чем логарифм «совершенной эвристики» h. * который возвращает истинное расстояние от x до цели. [18] [24]
Пространственная сложность A* примерно такая же, как и у всех других алгоритмов поиска по графу, поскольку он сохраняет все сгенерированные узлы в памяти. [1] На практике это оказывается самым большим недостатком поиска A*, приводящим к развитию эвристического поиска, ограниченного памятью, такого как итеративное углубление A* , A*, ограниченное памятью, и SMA* .
Приложения [ править ]
A* часто используется для решения общей задачи поиска пути в таких приложениях, как видеоигры, но изначально был разработан как общий алгоритм обхода графа. [4] Он находит применение в разнообразных задачах, включая задачу синтаксического анализа с использованием стохастических грамматик в НЛП . [26] Другие случаи включают информационный поиск с онлайн-обучением. [27]
Отношения с другими алгоритмами [ править ]
Что отличает A* от жадного алгоритма поиска по принципу «сначала лучшее», так это то, что он учитывает уже пройденное расстояние g ( n ) .
Некоторые распространенные варианты алгоритма Дейкстры можно рассматривать как частный случай A*, когда эвристика для всех узлов; [12] [13] в свою очередь, и Дейкстра, и А* являются частными случаями динамического программирования . [28] A* сам по себе является частным случаем обобщения метода ветвей и границ . [29]

A* аналогичен поиску луча, за исключением того, что при поиске луча сохраняется ограничение на количество путей, которые необходимо исследовать. [30]
Варианты [ править ]
- В любое время А* [31]
- Блок А*
- Д*
- Поле Д*
- Бахрома
- Дополнительная экономия A* (FSA*)
- Обобщенный адаптивный A* (GAA*)
- Инкрементальный эвристический поиск
- Пониженный А* [32]
- Итеративное углубление A* (IDA*)
- Поиск точки прыжка
- Планирование на всю жизнь A* (LPA*)
- Новый двунаправленный A* (НБА*) [33]
- Упрощенная память, ограниченная A* (SMA*)
- Тета*
A* также можно адаптировать к алгоритму двунаправленного поиска . Особое внимание необходимо уделить критерию остановки. [34]
См. также [ править ]
- Поиск в ширину
- Поиск в глубину
- Планирование пути под любым углом , поиск путей, которые не ограничиваются движением по краям графа, а могут принимать любой угол.
Примечания [ править ]
- ^ «A*-like» означает, что алгоритм выполняет поиск, расширяя пути, исходящие из начального узла, по одному ребру за раз, так же, как это делает A*. Это исключает, например, алгоритмы, которые выполняют поиск назад от цели или в обоих направлениях одновременно. Кроме того, алгоритмы, охватываемые этой теоремой, должны быть допустимыми и «не более информированными», чем A*.
- ^ Узлы цели можно пропускать несколько раз, если остаются другие узлы с меньшими значениями f , поскольку они могут привести к более короткому пути к цели.
Ссылки [ править ]
- ↑ Перейти обратно: Перейти обратно: а б с Рассел, Стюарт Дж. (2018). Искусственный интеллект – современный подход . Норвиг, Питер (4-е изд.). Бостон: Пирсон. ISBN 978-0134610993 . OCLC 1021874142 .
- ^ Деллинг, Д.; Сандерс, П .; Шультес, Д.; Вагнер, Д. (2009). «Алгоритмы планирования инженерных маршрутов». Алгоритмы больших и сложных сетей: проектирование, анализ и моделирование . Конспекты лекций по информатике. Том. 5515. Спрингер. стр. 117–139. дои : 10.1007/978-3-642-02094-0_7 . ISBN 978-3-642-02093-3 .
- ^ Цзэн, В.; Черч, РЛ (2009). «Поиск кратчайших путей в реальных дорожных сетях: случай А*» . Международный журнал географической информатики . 23 (4): 531–543. дои : 10.1080/13658810801949850 . S2CID 14833639 .
- ↑ Перейти обратно: Перейти обратно: а б с Харт, ЧП ; Нильссон, Нью-Джерси ; Рафаэль, Б. (1968). «Формальная основа эвристического определения путей с минимальной стоимостью». Транзакции IEEE по системным наукам и кибернетике . 4 (2): 100–7. дои : 10.1109/TSSC.1968.300136 .
- ^ Доран, Дж. Э.; Мичи, Д. (20 сентября 1966 г.). «Эксперименты с программой Graph Traverser». Учеб. Р. Сок. Лонд. А. 294 (1437): 235–259. Бибкод : 1966RSPSA.294..235D . дои : 10.1098/rspa.1966.0205 . S2CID 21698093 .
- ^ Нильссон, Нильс Дж. (30 октября 2009 г.). В поисках искусственного интеллекта (PDF) . Кембридж: Издательство Кембриджского университета. ISBN 9780521122931 .
Одной из первых проблем, которые мы рассмотрели, было то, как спланировать последовательность «путевых точек», которые Шейки мог бы использовать для навигации с места на место. […] Проблема навигации Шейки — это проблема поиска, подобная тем, о которых я упоминал ранее.
- ^ Нильссон, Нильс Дж. (30 октября 2009 г.). В поисках искусственного интеллекта (PDF) . Кембридж: Издательство Кембриджского университета. ISBN 9780521122931 .
Бертрам Рафаэль, который в то время руководил работой над Шейки, заметил, что лучшим значением для оценки будет сумма пройденного на данный момент расстояния от исходного положения плюс моя эвристическая оценка того, как далеко должен пройти робот.
- ^ Эделькамп, Стефан; Джаббар, Шахид; Ллуч-Лафуэнте, Альберто (2005). «Стоимостно-алгебраический эвристический поиск» (PDF) . Материалы Двадцатой национальной конференции по искусственному интеллекту (AAAI) : 1362–7. ISBN 978-1-57735-236-5 .
- ^ Харт, Питер Э.; Нильссон, Нильс Дж.; Рафаэль, Бертрам (1 декабря 1972 г.). «Поправка к «Формальной основе для эвристического определения путей с минимальной стоимостью» » (PDF) . Бюллетень ACM SIGART (37): 28–29. дои : 10.1145/1056777.1056779 . S2CID 6386648 .
- ↑ Перейти обратно: Перейти обратно: а б Дектер, Рина; Иудея Перл (1985). «Обобщенные стратегии поиска по принципу «лучшее сначала» и оптимальность A*» . Журнал АКМ . 32 (3): 505–536. дои : 10.1145/3828.3830 . S2CID 2092415 .
- ^ Нанничини, Джакомо; Деллинг, Дэниел; Шультес, Доминик; Либерти, Лео (2012). «Двунаправленный поиск A* в зависимых от времени дорожных сетях» (PDF) . Сети . 59 (2): 240–251. дои : 10.1002/NET.20438 .
- ↑ Перейти обратно: Перейти обратно: а б Де Смит, Майкл Джон; Гудчайлд, Майкл Ф.; Лонгли, Пол (2007), Геопространственный анализ: комплексное руководство по принципам, методам и программным инструментам , Troubadour Publishing Ltd, стр. 344, ISBN 9781905886609 .
- ↑ Перейти обратно: Перейти обратно: а б Хетланд, Магнус Ли (2010), Алгоритмы Python: освоение базовых алгоритмов языка Python , Apress, стр. 214, ISBN 9781430232377 .
- ^ Мартелли, Альберто (1977). «О сложности допустимых алгоритмов поиска». Искусственный интеллект . 8 (1): 1–13. дои : 10.1016/0004-3702(77)90002-9 .
- ^ Фельнер, Ариэль; Узи Захави (2011). «Непоследовательная эвристика в теории и практике» . Искусственный интеллект . 175 (9–10): 1570–1603. дои : 10.1016/j.artint.2011.02.001 .
- ^ Чжан, Чжифу; Н. Р. Стертевант (2009). Использование противоречивой эвристики при поиске A* . Двадцать первая международная совместная конференция по искусственному интеллекту. стр. 634–639.
- ^ Поль, Ира (1970). «Первые результаты о влиянии ошибки при эвристическом поиске». Машинный интеллект 5 . Издательство Эдинбургского университета: 219–236. ISBN 978-0-85224-176-9 . OCLC 1067280266 .
- ↑ Перейти обратно: Перейти обратно: а б Перл, Иудея (1984). Эвристика: стратегии интеллектуального поиска для решения компьютерных задач . Аддисон-Уэсли. ISBN 978-0-201-05594-8 .
- ^ Поль, Ира (август 1973 г.). «Избежание (относительной) катастрофы, эвристическая компетентность, настоящее динамическое взвешивание и вычислительные проблемы при решении эвристических задач» (PDF) . Материалы Третьей международной совместной конференции по искусственному интеллекту (IJCAI-73) . Том. 3. Калифорния, США. стр. 11–17.
- ^ Кёлль, Андреас; Герман Кайндл (август 1992 г.). «Новый подход к динамическому взвешиванию» . Материалы Десятой Европейской конференции по искусственному интеллекту (ECAI-92) . Вена, Австрия: Вили. стр. 16–17. ISBN 978-0-471-93608-4 .
- ^ Перл, Иудея; Джин Х. Ким (1982). «Исследования по полудопустимой эвристике». Транзакции IEEE по анализу шаблонов и машинному интеллекту . 4 (4): 392–399. дои : 10.1109/TPAMI.1982.4767270 . ПМИД 21869053 . S2CID 3176931 .
- ^ Галлаб, Малик; Деннис Аллард (август 1983 г.). « A ε - эффективный почти допустимый эвристический алгоритм поиска» (PDF) . Материалы Восьмой Международной совместной конференции по искусственному интеллекту (IJCAI-83) . Том. 2. Карлсруэ, Германия. стр. 789–791. Архивировано из оригинала (PDF) 6 августа 2014 г.
- ^ Риз, Бьорн (1999). AlphA*: ε -допустимый эвристический алгоритм поиска (Отчет). Институт производственных технологий Университета Южной Дании. Архивировано из оригинала 31 января 2016 г. Проверено 5 ноября 2014 г.
- ↑ Перейти обратно: Перейти обратно: а б Рассел, Стюарт ; Норвиг, Питер (2003) [1995]. Искусственный интеллект: современный подход (2-е изд.). Прентис Холл. стр. 97–104. ISBN 978-0137903955 .
- ^ Рассел, Стюарт ; Норвиг, Питер (2009) [1995]. Искусственный интеллект: современный подход (3-е изд.). Прентис Холл. п. 103. ИСБН 978-0-13-604259-4 .
- ^ Кляйн, Дэн; Мэннинг, Кристофер Д. (2003). «А*синтаксический анализ: быстрый и точный выбор анализа Витерби» (PDF) . Материалы конференции по технологиям человеческого языка 2003 года Североамериканского отделения Ассоциации компьютерной лингвистики . стр. 119–126. дои : 10.3115/1073445.1073461 .
- ^ Каган Э.; Бен-Гал И. (2014). «Алгоритм группового тестирования с информационным онлайн-обучением» (PDF) . Операции IIE . 46 (2): 164–184. дои : 10.1080/0740817X.2013.803639 . S2CID 18588494 . Архивировано из оригинала (PDF) 5 ноября 2016 г. Проверено 12 февраля 2016 г.
- ^ Фергюсон, Дэйв; Лихачев Максим; Стенц, Энтони (2005). «Руководство по эвристическому планированию пути» (PDF) . Материалы международного семинара по планированию в условиях неопределенности для автономных систем, Международная конференция по автоматизированному планированию и составлению графиков (ICAPS) . стр. 9–18. Архивировано (PDF) из оригинала 29 июня 2016 г.
- ^ Нау, Дана С.; Кумар, Випин; Канал, Лавин (1984). «Общая ветвь и граница и ее связь с A∗ и AO∗» (PDF) . Искусственный интеллект . 23 (1): 29–58. дои : 10.1016/0004-3702(84)90004-3 . Архивировано (PDF) из оригинала 4 октября 2012 г.
- ^ «Варианты А*» . Theory.stanford.edu . Проверено 9 июня 2023 г.
- ^ Хансен, Эрик А.; Чжоу, Ронг (2007). «Эвристический поиск в любое время» . Журнал исследований искусственного интеллекта . 28 : 267–297. arXiv : 1110.2737 . дои : 10.1613/jair.2096 . S2CID 9832874 .
- ^ Фарех, Рауф; Базияд, Мохаммед; Рахман, Мохаммад Х.; Раби, Тамер; Беттаеб, Маамар (14 мая 2019 г.). «Исследование стратегии планирования сокращенного пути для мобильного робота с дифференциальными колесами» . Роботика . 38 (2): 235–255. дои : 10.1017/S0263574719000572 . ISSN 0263-5747 . S2CID 181849209 .
- ^ Пейлс, Вим; Пост, Хенк. Еще один двунаправленный алгоритм поиска кратчайших путей (PDF) (Технический отчет). Эконометрический институт Роттердамского университета Эразма. ЭИ 2009-10. Архивировано (PDF) из оригинала 11 июня 2014 г.
- ^ Гольдберг, Эндрю В.; Харрельсон, Крис; Каплан, Хаим; Вернек, Ренато Ф. «Эффективные алгоритмы кратчайшего пути между точками» (PDF) . Принстонский университет . Архивировано (PDF) из оригинала 18 мая 2022 года.
Дальнейшее чтение [ править ]
- Нильссон, Нью-Джерси (1980). Принципы искусственного интеллекта . Пало-Альто, Калифорния: Издательская компания Tioga. ISBN 978-0-935382-01-3 .
Внешние ссылки [ править ]
- Вариант A*, называемый иерархическим поиском пути A* (HPA*).
- Брайан Гринстед. «Алгоритм поиска A* в JavaScript (обновлено)» . Архивировано из оригинала 15 февраля 2020 года . Проверено 8 февраля 2021 г.