Префиксная сумма
В информатике префиксная сумма , накопительная сумма , инклюзивное сканирование или просто сканирование последовательности чисел x 0 , x 1 , x 2 ,... представляет собой вторую последовательность чисел y 0 , y 1 , y 2 , . .. суммы : префиксов ) ( промежуточных итогов входной последовательности
- у 0 = х 0
- у 1 = х 0 + х 1
- у 2 = х 0 + х 1 + х 2
- ...
Например, префиксные суммы натуральных чисел представляют собой треугольные числа :
ввод чисел 1 2 3 4 5 6 ... префиксные суммы 1 3 6 10 15 21 ...
Префиксные суммы легко вычисляются в последовательных моделях вычислений, используя формулу y i = y i - 1 + x i для вычисления каждого выходного значения в порядке последовательности. Однако, несмотря на простоту вычислений, суммы префиксов являются полезным примитивом в некоторых алгоритмах, таких как подсчет сортировки , [1] [2] и они составляют основу сканирования функции высшего порядка в функциональных языках программирования. Префиксные суммы также широко изучались в параллельных алгоритмах , как в качестве тестовой задачи, которую необходимо решить, так и в качестве полезного примитива, который можно использовать в качестве подпрограммы в других параллельных алгоритмах. [3] [4] [5]
Абстрактно, для префиксной суммы требуется только бинарный ассоциативный оператор ⊕ , что делает его полезным для многих приложений, от вычисления хорошо разделенных парных разложений точек до обработки строк. [6] [7]
Математически операцию взятия префиксных сумм можно обобщить от конечных до бесконечных последовательностей; сумма известна как частичная сумма ряда в этом контексте префиксная . Префиксное суммирование или частичное суммирование образуют линейные операторы в векторных пространствах конечных или бесконечных последовательностей; их обратные являются конечно-разностными операторами.
Сканирование функции высшего порядка
[ редактировать ]В терминах функционального программирования префиксная сумма может быть обобщена на любую двоичную операцию (а не только на операцию сложения ); функция более высокого порядка, возникающая в результате этого обобщения, называется сканированием и тесно связана с операцией сгиба . Операции сканирования и свертывания применяют данную бинарную операцию к одной и той же последовательности значений, но отличаются тем, что сканирование возвращает всю последовательность результатов бинарной операции, тогда как свертывание возвращает только окончательный результат. Например, последовательность факториалов чисел может быть сгенерирована путем сканирования натуральных чисел с использованием умножения вместо сложения:
ввод чисел 1 2 3 4 5 6 ... префиксные продукты 1 2 6 24 120 720 ...
Инклюзивные и эксклюзивные сканы
[ редактировать ]Язык программирования и библиотечная реализация сканирования могут быть как инклюзивными , так и эксклюзивными . Инклюзивное сканирование включает входные данные x i при вычислении выходных данных y i (т. е. ), тогда как эксклюзивное сканирование этого не делает (т.е. ). В последнем случае реализации либо оставляют y 0 неопределенным, либо принимают отдельное значение « x −1 » для заполнения сканирования. Любой тип сканирования можно преобразовать в другой: инклюзивное сканирование можно преобразовать в эксклюзивное сканирование, сдвинув массив, созданный в результате сканирования, вправо на один элемент и вставив значение идентификатора слева от массива. И наоборот, исключающее сканирование можно преобразовать в инклюзивное сканирование путем сдвига массива, созданного в результате сканирования, влево и вставки суммы последнего элемента сканирования и последнего элемента входного массива справа от массива. [8]


В следующей таблице приведены примеры инклюзивных и эксклюзивных функций сканирования, предоставляемых несколькими языками программирования и библиотеками:
| Язык/библиотека | Инклюзивное сканирование | Эксклюзивное сканирование |
|---|---|---|
| АПЛ | +\
|
|
| С++ | std::inclusive_scan
|
std::exclusive_scan
|
| Хаскелл | scanl1
|
scanl
|
| HPF | sum_prefix
|
sum_prefix(..., exclusive=.true.)
|
| Котлин | scan
|
|
| ИМБ | MPI_Scan
|
MPI_Exscan
|
| Ржавчина | scan
|
|
| Скала | scan
|
на основе директив Модель параллельного программирования OpenMP поддерживает как инклюзивную, так и исключительную поддержку сканирования, начиная с версии 5.0.
Параллельные алгоритмы
[ редактировать ]Существует два ключевых алгоритма параллельного вычисления суммы префиксов. Первый предлагает более короткий интервал и больший параллелизм , но неэффективен в работе. Второй вариант более эффективен, но требует удвоенного диапазона и обеспечивает меньший параллелизм. Они представлены по очереди ниже.
Алгоритм 1: короче пролет, больше параллельности
[ редактировать ]
Хиллис и Стил представляют следующий алгоритм суммирования параллельных префиксов: [9]
for i <- 0 to floor(log2(n)) do
for j <- 0 to n - 1 do in parallel
if j < 2i then
xi+1
j <- xi
j
else
xi+1
j <- xi
j + xi
j - 2i
Вышеупомянутые обозначения означает значение j- го элемента массива x на временном шаге i .

На одном процессоре этот алгоритм будет выполняться за время O ( n log n ) . Однако если машина имеет как минимум n процессоров для параллельного выполнения внутреннего цикла, алгоритм в целом выполняется за время O (log n ) , количество итераций внешнего цикла.
Алгоритм 2: Эффективный
[ редактировать ]
Эффективную сумму параллельных префиксов можно вычислить с помощью следующих шагов. [3] [10] [11]
- Вычислите суммы последовательных пар элементов, в которых первый элемент пары имеет четный индекс: z 0 = x 0 + x 1 , z 1 = x 2 + x 3 и т. д.
- Рекурсивно вычислить префиксную сумму w 0 , w 1 , w 2 , ... последовательности z 0 , z 1 , z 2 , ...
- Выразите каждый член конечной последовательности y 0 , y 1 , y 2 , ... как сумму до двух членов этих промежуточных последовательностей: y 0 = x 0 , y 1 = z 0 , y 2 = z 0 + x 2 , y 3 = w 1 и т. д. После первого значения каждое последующее число y i либо копируется из позиции, находящейся в половине последовательности w , либо предыдущее значение добавляется к одному значению в последовательности x .
Если входная последовательность имеет n шагов, то рекурсия продолжается до глубины O (log n ) , что также является ограничением времени параллельного выполнения этого алгоритма. Число шагов алгоритма равно O ( n ) , и его можно реализовать на параллельной машине произвольного доступа с O ( n /log n ) процессорами без какого-либо асимптотического замедления путем назначения нескольких индексов каждому процессору в раундах алгоритма для в которых элементов больше, чем процессоров. [3]
Обсуждение
[ редактировать ]Каждый из предыдущих алгоритмов выполняется за время O (log n ) . Однако в первом случае требуется ровно log 2 n шагов, а во втором — 2 log 2 n − 2 шага. Для проиллюстрированных примеров с 16 входами Алгоритм 1 является 12-канальным параллельным (49 единиц работы, разделенным на интервал 4), тогда как Алгоритм 2 является только 4-канальным параллельным (26 единиц работы, разделенными на 6). Однако алгоритм 2 эффективен по работе — он выполняет только постоянный коэффициент (2) от объема работы, требуемой последовательным алгоритмом, — в то время как алгоритм 1 неэффективен по работе — он выполняет асимптотически больше работы (логарифмический коэффициент), чем требуется. последовательно. Следовательно, алгоритм 1, вероятно, будет работать лучше, когда доступен обильный параллелизм, но алгоритм 2, вероятно, будет работать лучше, когда параллелизм более ограничен.
Параллельные алгоритмы для сумм префиксов часто можно обобщить на другие операции сканирования ассоциативных двоичных операций . [3] [4] и их также можно эффективно вычислять на современном параллельном оборудовании, таком как графический процессор . [12] Идею встраивания в аппаратуру функционального блока, предназначенного для вычисления многопараметрической префикс-суммы, запатентовал Узи Вишкин . [13]
Многие параллельные реализации используют двухпроходную процедуру, при которой частичные суммы префиксов вычисляются при первом проходе на каждом процессоре; затем вычисляется префиксная сумма этих частичных сумм и передается обратно в процессоры для второго прохода с использованием теперь известного префикса в качестве начального значения. Асимптотически этот метод требует примерно двух операций чтения и одной операции записи на элемент.
Конкретные реализации алгоритмов суммы префиксов
[ редактировать ]Реализация параллельного алгоритма суммирования префиксов, как и других параллельных алгоритмов, должна учитывать архитектуру распараллеливания платформы. Более конкретно, существует множество алгоритмов, адаптированных для платформ, работающих с общей памятью , а также алгоритмов, которые хорошо подходят для платформ, использующих распределенную память , полагающихся на передачу сообщений как на единственную форму межпроцессного взаимодействия.
Общая память: двухуровневый алгоритм
[ редактировать ]Следующий алгоритм предполагает модель машины с общей памятью ; все обрабатывающие элементы (PE) имеют доступ к одной и той же памяти. Версия этого алгоритма реализована в стандартной библиотеке многоядерных шаблонов (MCSTL). [14] [15] параллельная реализация стандартной библиотеки шаблонов C++ , которая предоставляет адаптированные версии для параллельных вычислений различных алгоритмов.
Чтобы одновременно вычислить сумму префикса по элементы данных с элементы обработки, данные делятся на блоки, каждый из которых содержит элементов (для простоты будем считать, что делит ). Обратите внимание, что хотя алгоритм делит данные на блоки, только элементы обработки работают одновременно.




При первом проходе каждый PE вычисляет сумму локальных префиксов для своего блока. Последний блок вычислять не требуется, поскольку эти суммы префиксов рассчитываются только как смещения к суммам префиксов последующих блоков, а последний блок по определению не является успешным.
The смещения, которые хранятся в последней позиции каждого блока, накапливаются в виде собственной суммы префиксов и сохраняются в последующих позициях. Для поскольку число небольшое, то быстрее делать это последовательно, для большого , этот шаг также можно выполнить параллельно.
Выполняется вторая развертка. На этот раз первый блок обрабатывать не нужно, поскольку не нужно учитывать смещение предыдущего блока. Однако в этот цикл вместо этого включается последний блок, и суммы префиксов для каждого блока вычисляются с учетом смещений блоков суммы префиксов, вычисленных в предыдущем цикле.
function prefix_sum(elements) {
n := size(elements)
p := number of processing elements
prefix_sum := [0...0] of size n
do parallel i = 0 to p-1 {
// i := index of current PE
from j = i * n / (p+1) to (i+1) * n / (p+1) - 1 do {
// This only stores the prefix sum of the local blocks
store_prefix_sum_with_offset_in(elements, 0, prefix_sum)
}
}
x = 0
for i = 1 to p { // Serial accumulation of total sum of blocks
x += prefix_sum[i * n / (p+1) - 1] // Build the prefix sum over the first p blocks
prefix_sum[i * n / (p+1)] = x // Save the results to be used as offsets in second sweep
}
do parallel i = 1 to p {
// i := index of current PE
from j = i * n / (p+1) to (i+1) * n / (p+1) - 1 do {
offset := prefix_sum[i * n / (p+1)]
// Calculate the prefix sum taking the sum of preceding blocks as offset
store_prefix_sum_with_offset_in(elements, offset, prefix_sum)
}
}
return prefix_sum
}
Улучшение: в случае, если количество блоков слишком велико, что делает последовательный шаг трудоемким из-за развертывания одного процессора, алгоритм Хиллиса и Стила для ускорения второго этапа можно использовать .
Распределенная память: алгоритм Hypercube
[ редактировать ]Алгоритм суммирования префиксов гиперкуба [16] хорошо адаптирован для платформ с распределенной памятью и работает с обменом сообщениями между элементами обработки. Предполагается, что он имеет процессорных элементов (ПЭ), участвующих в алгоритме, равно числу углов в -мерный гиперкуб .


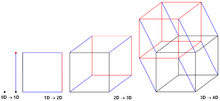
На протяжении всего алгоритма каждый PE рассматривается как угол гипотетического гиперкуба со знанием общей суммы префиксов. а также префиксная сумма всех элементов до себя (в соответствии с упорядоченными индексами среди PE), причем оба в своем гиперкубе.


- Алгоритм начинается с предположения, что каждый PE является единственным углом нульмерного гиперкуба и, следовательно, и равны локальной префиксной сумме своих собственных элементов.
- Алгоритм продолжает объединение гиперкубов, смежных по одному измерению. При каждом объединении обменивается и агрегируется между двумя гиперкубами, что сохраняет инвариант, заключающийся в том, что все PE в углах этого нового гиперкуба хранят общую сумму префиксов этого недавно объединенного гиперкуба в своей переменной . Однако только гиперкуб, содержащий PE с более высоким индексом, также добавляет это в их локальную переменную , сохраняя инвариант, что сохраняет только значение префиксной суммы всех элементов PE с индексами, меньшими или равными их собственному индексу.
В -мерный гиперкуб с ПЭ по углам, алгоритм приходится повторять раз, чтобы иметь нульмерные гиперкубы объединить в один -мерный гиперкуб. Предполагая дуплексную модель связи , в которой двух соседних PE в разных гиперкубах можно обмениваться в обоих направлениях за один шаг связи, это означает коммуникационные стартапы.


i := Index of own processor element (PE)
m := prefix sum of local elements of this PE
d := number of dimensions of the hyper cube
x = m; // Invariant: The prefix sum up to this PE in the current sub cube
σ = m; // Invariant: The prefix sum of all elements in the current sub cube
for (k=0; k <= d-1; k++) {
y = σ @ PE(i xor 2^k) // Get the total prefix sum of the opposing sub cube along dimension k
σ = σ + y // Aggregate the prefix sum of both sub cubes
if (i & 2^k) {
x = x + y // Only aggregate the prefix sum from the other sub cube, if this PE is the higher index one.
}
}
Большие размеры сообщений: конвейерное двоичное дерево
[ редактировать ]Алгоритм конвейерного двоичного дерева [17] — это еще один алгоритм для платформ с распределенной памятью, который особенно хорошо подходит для сообщений большого размера.
Как и алгоритм гиперкуба, он предполагает особую структуру связи. Элементы обработки (PE) гипотетически расположены в виде двоичного дерева (например, дерева Фибоначчи) с инфиксной нумерацией в соответствии с их индексом внутри PE. Связь в таком дереве всегда происходит между родительскими и дочерними узлами.
Инфиксная нумерация гарантирует, что для любого данного PE j индексы всех узлов, достижимых его левым поддеревом меньше, чем и индексы всех узлов в правом поддереве больше, чем . Индекс родительского элемента больше любого из индексов в PE j поддереве , если PE j является левым дочерним элементом, и меньше, если PE j является правым дочерним элементом. Это позволяет сделать следующие рассуждения:
![{\displaystyle \mathbb {[l...j-1]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e42e648cab095972c89f5c3cdfd706a6d6542ab)

![{\displaystyle \mathbb {[j+1...r]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/9bb02bd7fbd1f725326c3fcdeba81a5b64ea2192)

- Сумма локального префикса левого поддерева необходимо агрегировать для вычисления PE j. суммы локального префикса .
- Сумма локального префикса правого поддерева необходимо агрегировать для вычисления суммы локальных префиксов PE h более высокого уровня , которые достигаются на пути, содержащем левое дочернее соединение (что означает ).
- Общая сумма префикса PE j необходим для расчета общих сумм префиксов в правом поддереве (например, для узла с самым высоким индексом в поддереве).
- PE j должен включать общую сумму префиксов первого узла более высокого порядка, который достигается по восходящему пути, включая правое дочернее соединение, для расчета его общей суммы префикса.
![{\displaystyle \mathbb {\oplus [l..j-1]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/111c0326733e32d7fff1d2436c8f91bd93c2f911)
![{\displaystyle \mathbb {\oplus [l..j]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/c8540c987feea78fa6b8c24881a0743b47567bf3)
![{\displaystyle \mathbb {\oplus [j+1..r]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/aaf861ae0ef24c4ce8902502b30eb173ccee27f9)

![{\displaystyle \mathbb {\oplus [0..j]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/ce3a3c99c6216685a2b3ecebd478ab7cddd1a185)
![{\displaystyle \mathbb {\oplus [0..j..r]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4a67fa871d710d36cb7e7db6f6202d1938211f8)
![{\displaystyle \mathbb {\oplus [0..l-1]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/29c0eb618b27e5892fb370b0eb4fdf14a18ed333)
Обратите внимание на различие между локальными и общими префиксными суммами поддерева. Пункты два, три и четыре могут привести к мысли, что они образуют круговую зависимость, но это не так. PE более низкого уровня могут потребовать общую сумму префиксов PE более высокого уровня для расчета общей суммы префиксов, но PE более высокого уровня требуют только суммы локальных префиксов поддерева для расчета общей суммы префиксов. Корневому узлу как узлу самого высокого уровня требуется только сумма локальных префиксов его левого поддерева для вычисления собственной суммы префиксов. Каждому PE на пути от PE 0 до корня PE требуется только сумма локальных префиксов его левого поддерева для вычисления собственной суммы префиксов, тогда как каждому узлу на пути от PE p-1 PE (последний PE) до корня требуется общая сумма префикса своего родителя для расчета собственной общей суммы префикса.
Это приводит к двухфазному алгоритму:
Восходящая фаза
Распространить сумму локального префикса поддерева своему родителю для каждого PE j .
![{\displaystyle \mathbb {\oplus [l..j..r]} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/77936279f8ecfbcde9d649eff659d5fc0acec03c)
Нисходящая фаза
Распространить эксклюзивную (эксклюзивную PE j, а также PE в его левом поддереве) общую сумму префикса. всех PE нижнего индекса, которые не включены в адресуемое поддерево PE j, в PE нижнего уровня в левом дочернем поддереве PE j . Распространить инклюзивную сумму префикса к правому дочернему поддереву PE j .
Обратите внимание, что алгоритм запускается параллельно на каждом PE, и PE будут блокироваться при получении до тех пор, пока их дети/родители не предоставят им пакеты.
k := number of packets in a message m of a PE
m @ {left, right, parent, this} := // Messages at the different PEs
x = m @ this
// Upward phase - Calculate subtree local prefix sums
for j=0 to k-1: // Pipelining: For each packet of a message
if hasLeftChild:
blocking receive m[j] @ left // This replaces the local m[j] with the received m[j]
// Aggregate inclusive local prefix sum from lower index PEs
x[j] = m[j] ⨁ x[j]
if hasRightChild:
blocking receive m[j] @ right
// We do not aggregate m[j] into the local prefix sum, since the right children are higher index PEs
send x[j] ⨁ m[j] to parent
else:
send x[j] to parent
// Downward phase
for j=0 to k-1:
m[j] @ this = 0
if hasParent:
blocking receive m[j] @ parent
// For a left child m[j] is the parents exclusive prefix sum, for a right child the inclusive prefix sum
x[j] = m[j] ⨁ x[j]
send m[j] to left // The total prefix sum of all PE's smaller than this or any PE in the left subtree
send x[j] to right // The total prefix sum of all PE's smaller or equal than this PE
Конвейерная обработка
[ редактировать ]Если сообщение m длины n можно разделить на k пакетов и оператор ⨁ можно использовать для каждого из соответствующих пакетов сообщений отдельно, конвейерная обработка возможна. [17]
Если алгоритм используется без конвейерной обработки, всегда работают только два уровня (отправляющий PE и принимающий PE) двоичного дерева, пока все остальные PE находятся в режиме ожидания. Если имеется p элементов обработки и используется сбалансированное двоичное дерево, то дерево имеет уровней, длина пути от к поэтому который представляет собой максимальное количество непараллельных операций связи во время восходящей фазы; аналогично, связь на нисходящем пути также ограничена стартапы. Предполагая, что время начала связи и время побайтовой передачи , восходящая и нисходящая фазы ограничены в неконвейерном сценарии.







При разделении на k пакетов, каждый размером и отправив их отдельно, первый пакет все равно нужен распространяться на как часть суммы локального префикса, и это произойдет снова для последнего пакета, если . Однако между ними все PE на пути могут работать параллельно, и каждая третья операция связи (получение слева, получение справа, отправка родительскому устройству) отправляет пакет на следующий уровень, так что одна фаза может быть завершена за коммуникационные операции и обе фазы вместе требуют что благоприятно для больших размеров сообщений n .





Алгоритм может быть дополнительно оптимизирован за счет использования полнодуплексной или телефонной модели связи и перекрытия восходящей и нисходящей фаз. [17]
Структуры данных
[ редактировать ]Когда набор данных может обновляться динамически, он может храниться в древовидной структуре данных Фенвика . Эта структура позволяет как искать любое отдельное значение суммы префикса, так и изменять любое значение массива за логарифмическое время за операцию. [18] Однако в более ранней статье 1982 г. [19] представляет структуру данных под названием «Дерево частичных сумм» (см. раздел 5.1), которая, по-видимому, перекрывает деревья Фенвика; в 1982 году термин «префикс-сумма» еще не был так распространен, как сегодня.
Для массивов более высокой размерности таблица суммированных площадей предоставляет структуру данных, основанную на суммах префиксов, для вычисления сумм произвольных прямоугольных подмассивов. Это может быть полезным примитивом в операциях свертки изображений . [20]
Приложения
[ редактировать ]Сортировка подсчетом — это алгоритм сортировки целых чисел , который использует сумму префиксов гистограммы частот ключей для вычисления положения каждого ключа в отсортированном выходном массиве. Он выполняется за линейное время для целочисленных ключей, размер которых меньше числа элементов, и часто используется как часть поразрядной сортировки — быстрого алгоритма сортировки целых чисел, величина которых менее ограничена. [1]
Ранжирование списка , проблема преобразования связанного списка в массив , представляющий одну и ту же последовательность элементов, можно рассматривать как вычисление суммы префикса в последовательности 1, 1, 1,... и последующее сопоставление каждого элемента с позицией массива. задается значением суммы префикса; комбинируя ранжирование списков, суммы префиксов и циклы Эйлера , многие важные проблемы с деревьями могут быть решены с помощью эффективных параллельных алгоритмов. [4]
Раннее применение параллельных алгоритмов суммирования префиксов было при разработке двоичных сумматоров , логических схем, которые могут складывать два n -битных двоичных числа. В этом приложении последовательность битов переноса сложения можно представить как операцию сканирования. на последовательности пар входных битов, используя функцию большинства для объединения предыдущего переноса с этими двумя битами. Затем каждый бит выходного номера можно найти как исключительный или из двух входных битов с соответствующим битом переноса. Используя схему, выполняющую операции параллельного алгоритма суммирования префиксов, можно спроектировать сумматор, использующий O ( n ) логические элементы и O (log n ) временных шагов. [3] [10] [11]
В модели вычислений с параллельными машинами с произвольным доступом суммы префиксов могут использоваться для моделирования параллельных алгоритмов, которые предполагают возможность одновременного доступа нескольких процессоров к одной и той же ячейке памяти на параллельных машинах, которые запрещают одновременный доступ. С помощью сети сортировки набор параллельных запросов доступа к памяти можно упорядочить в последовательность так, чтобы доступы к одной и той же ячейке были непрерывными внутри последовательности; Затем операции сканирования можно использовать для определения того, какие из обращений успешны в записи в запрошенные ячейки, а также для распределения результатов операций чтения памяти по нескольким процессорам, которые запрашивают один и тот же результат. [21]
В Гая Беллоха докторской диссертации . диссертация, [22] параллельные префиксные операции являются частью формализации модели параллелизма данных , предоставляемой такими машинами, как Connection Machine . Соединительная машина CM-1 и CM-2 обеспечивала гиперкубическую сеть, в которой мог быть реализован описанный выше алгоритм 1, тогда как CM-5 предоставляла выделенную сеть для реализации алгоритма 2. [23]
При построении кодов Грея , последовательностей двоичных значений со свойством, что последовательные значения последовательности отличаются друг от друга в одной битовой позиции, число n можно преобразовать в значение кода Грея в позиции n последовательности, просто взяв исключительный или из n и n /2 (число, образованное сдвигом n вправо на одну битовую позицию). закодированного в коде Грея Обратная операция, декодирование значения x, , в двоичное число, более сложна, но может быть выражена как префиксная сумма битов x , где каждая операция суммирования внутри суммы префикса выполняется по модулю два. этого типа может быть эффективно выполнена с использованием поразрядных логических операций, доступных на современных компьютерах, путем вычисления исключающего или x Префиксная сумма с каждым из чисел, образованных сдвигом x влево на количество битов, равное степени двойки. . [24]
Параллельный префикс (с использованием умножения в качестве базовой ассоциативной операции) также можно использовать для построения быстрых алгоритмов параллельной полиномиальной интерполяции . В частности, его можно использовать для вычисления разделенной разности коэффициентов формы Ньютона интерполяционного полинома. [25] Этот подход, основанный на префиксах, также можно использовать для получения обобщенных разделенных разностей для (сливной) интерполяции Эрмита. а также для параллельных алгоритмов для Вандермонда . систем [26]
Сумма префикса используется для балансировки нагрузки в качестве недорогого алгоритма распределения работы между несколькими процессорами, где основной целью является достижение одинакового объема работы на каждом процессоре. Алгоритмы используют массив весов, представляющий объем работы, необходимый для каждого элемента. После расчета суммы префикса рабочий элемент i отправляется на обработку в процессорный блок с номером . [27] Графически это соответствует операции, где объем работы в каждом элементе представлен длиной линейного отрезка, все отрезки последовательно выстраиваются в линию и результат разрезается на количество частей, соответствующее числу процессоров. [28]
![{\displaystyle [{\frac {prefixSumValue_{i}}{{totalWork}/{numberOfProcessors}}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/298df8f2f4a5e87a72e3165b367b166d08b1baa4)
См. также
[ редактировать ]- Вычисления общего назначения на графических процессорах
- Сегментированное сканирование
- Таблица суммированных площадей
Ссылки
[ редактировать ]- ^ Перейти обратно: а б Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л .; Штейн, Клиффорд (2001), «Сортировка подсчетом 8.2», Введение в алгоритмы (2-е изд.), MIT Press и McGraw-Hill , стр. 168–170, ISBN 0-262-03293-7 .
- ^ Коул, Ричард; Вишкин, Узи (1986), «Детерминистическое подбрасывание монеты с применением оптимального ранжирования в параллельных списках», Information and Control , 70 (1): 32–53, doi : 10.1016/S0019-9958(86)80023-7
- ^ Перейти обратно: а б с д и Ладнер, RE; Фишер, MJ (1980), «Параллельное вычисление префиксов», Journal of the ACM , 27 (4): 831–838, CiteSeerX 10.1.1.106.6247 , doi : 10.1145/322217.322232 , MR 0594702 , S2CID 207568668 .
- ^ Перейти обратно: а б с Тарьян, Роберт Э .; Вишкин, Узи (1985), «Эффективный параллельный алгоритм двусвязности», SIAM Journal on Computing , 14 (4): 862–874, CiteSeerX 10.1.1.465.8898 , doi : 10.1137/0214061 .
- ^ Лакшмиварахан, С.; Дхалл, СК (1994), Параллелизм в проблеме префиксов , Oxford University Press , ISBN 0-19508849-2 .
- ^ Блеллок, Гай (2011), Суммы префиксов и их применение (конспекты лекций) (PDF) , Университет Карнеги-Меллона .
- ^ Каллахан, Пол; Косараджу, С. Рао (1995), «Разложение многомерных наборов точек с применением к потенциальным полям k-ближайших соседей и n-тел», Journal of the ACM , 42 (1): 67–90, doi : 10.1145/200836.200853 , S2CID 1818562 .
- ^ «ГПУ Джемс 3» .
- ^ Хиллис, В. Дэниел; Стил-младший, Гай Л. (декабрь 1986 г.). «Алгоритмы параллельного анализа данных» . Коммуникации АКМ . 29 (12): 1170–1183. дои : 10.1145/7902.7903 .
- ^ Перейти обратно: а б Ofman, Yu. (1962), Об алгоритмической сложности дискретных функций , Доклады Академии наук СССР , 145 (1): 48–51, МР 0168423 . Английский перевод, «Об алгоритмической сложности дискретных функций», Доклады физики СССР 7 : 589–591, 1963.
- ^ Перейти обратно: а б Храпченко В.М. (1967), "Асимптотическая оценка времени сложения параллельного сумматора", Проблемы Кибернета. (на русском языке), 19 : 107–122 . Английский перевод в Сист. Теория Рез. 19 ; 105–122, 1970.
- ^ Сенгупта, Шубхабрата; Харрис, Марк; Чжан, Яо; Оуэнс, Джон Д. (2007). Сканирование примитивов для вычислений на графическом процессоре . Учеб. 22-й симпозиум ACM SIGGRAPH/EUROGRAPHICS по графическому оборудованию. стр. 97–106. Архивировано из оригинала 3 сентября 2014 г. Проверено 29 ноября 2007 г.
- ^ Вишкин, Узи (2003). Префиксные суммы и их применение . Патент США 6542918.
- ^ Синглер, Йоханнес. «MCSTL: Библиотека стандартных шаблонов многоядерных процессоров» . Проверено 29 марта 2019 г.
- ^ Синглер, Йоханнес; Сандерс, Питер; Путце, Феликс (2007). «MCSTL: Многоядерная стандартная библиотека шаблонов». Euro-Par 2007 Параллельная обработка . Конспекты лекций по информатике. Том. 4641. стр. 682–694. дои : 10.1007/978-3-540-74466-5_72 . ISBN 978-3-540-74465-8 . ISSN 0302-9743 .
- ^ Анант Грама; Випин Кумар; Аншул Гупта (2003). Введение в параллельные вычисления . Аддисон-Уэсли. стр. 85, 86 . 978-0-201-64865-2 .
- ^ Перейти обратно: а б с Сандерс, Питер; Трефф, Йеспер Ларссон (2006). «Алгоритмы параллельного префикса (сканирования) для MPI». Последние достижения в области параллельных виртуальных машин и интерфейса передачи сообщений . Конспекты лекций по информатике. Том. 4192. стр. 49–57. дои : 10.1007/11846802_15 . ISBN 978-3-540-39110-4 . ISSN 0302-9743 .
- ^ Фенвик, Питер М. (1994), «Новая структура данных для кумулятивных таблиц частот», Software: Practice and Experience , 24 (3): 327–336, doi : 10.1002/spe.4380240306 , S2CID 7519761
- ^ Шилоах, Йоси; Вишкин, Узи (1982б), «Ан О ( н 2 log n ) параллельный алгоритм максимального потока», Journal of Algorithms , 3 (2): 128–146, doi : 10.1016/0196-6774(82)90013-X
- ^ Селиски, Ричард (2010), «Таблица суммированных площадей (целое изображение)», Компьютерное зрение: алгоритмы и приложения , Тексты по информатике, Springer, стр. 106–107, ISBN 9781848829350 .
- ^ Вишкин, Узи (1983), «Реализация одновременного доступа к адресам памяти в моделях, которые это запрещают», Журнал алгоритмов , 4 (1): 45–50, doi : 10.1016/0196-6774(83)90033-0 , MR 0689265 .
- ^ Белллох, Гай Э. (1990). Векторные модели для параллельных вычислений . Кембридж, Массачусетс: MIT Press. ISBN 026202313X . ОСЛК 21761743 .
- ^ Лейзерсон, Чарльз Э .; Абухамде, Захи С.; Дуглас, Дэвид С.; Фейнман, Карл Р.; Ганмухи, Махеш Н.; Хилл, Джеффри В.; Хиллис, В. Дэниел ; Кушмаул, Брэдли С.; Сен-Пьер, Маргарет А. (15 марта 1996 г.). «Сетевая архитектура соединительной машины CM-5». Журнал параллельных и распределенных вычислений . 33 (2): 145–158. дои : 10.1006/jpdc.1996.0033 . ISSN 0743-7315 .
- ^ Уоррен, Генри С. (2003), «Восторг хакера» , Аддисон-Уэсли, с. 236, ISBN 978-0-201-91465-8 .
- ^ Эгечиоглу, О.; Галлопулос, Э.; Коч, К. (1990), «Параллельный метод для быстрой и практичной интерполяции Ньютона высокого порядка», BIT Computer Science and Numerical Mathematics , 30 (2): 268–288, doi : 10.1007/BF02017348 , S2CID 9607531 .
- ^ Эгечиоглу, О.; Галлопулос, Э.; Коч, К. (1989), «Быстрое вычисление разделенных разностей и параллельная интерполяция Эрмита», Journal of Complexity , 5 (4): 417–437, doi : 10.1016/0885-064X(89)90018-6
- ^ Беккер, Аарон; Чжэн, Гэнбинь; Кале, Лакшмикант В. (2011). «Балансировка нагрузки, распределенная память». Энциклопедия параллельных вычислений . Бостон, Массачусетс: Springer US. п. 1046. дои : 10.1007/978-0-387-09766-4_504 . ISBN 978-0-387-09765-7 .
- ^ Сандерс, Питер; Мельхорн, Курт; Дитцфельбингер, Мартин; Дементьев, Роман (2019). «Балансировка нагрузки» (PDF) . Последовательные и параллельные алгоритмы и структуры данных . Чам: Международное издательство Springer. п. 419–434. дои : 10.1007/978-3-030-25209-0_14 . ISBN 978-3-030-25208-3 .