Программирование экспрессии генов
Судя по всему, основной автор этой статьи тесно связан с ее предметом. ( Ноябрь 2012 г. ) |
В компьютерном программировании программирование экспрессии генов (GEP) — это эволюционный алгоритм , который создает компьютерные программы или модели. Эти компьютерные программы представляют собой сложные древовидные структуры , которые обучаются и адаптируются, изменяя свои размеры, форму и состав, подобно живому организму. И, как и живые организмы, компьютерные программы GEP также закодированы в простых линейных хромосомах фиксированной длины. Таким образом, GEP представляет собой систему генотип-фенотип , использующую простой геном для хранения и передачи генетической информации и сложный фенотип для исследования окружающей среды и адаптации к ней.
Предыстория [ править ]
Эволюционные алгоритмы используют популяции особей, отбирают особей в соответствии с приспособленностью и вводят генетическую изменчивость с помощью одного или нескольких генетических операторов . Их использование в искусственных вычислительных системах началось в 1950-х годах, когда они использовались для решения задач оптимизации (например, Box 1957). [1] и Фридман 1959 г. [2] ). Но это произошло с введением стратегии эволюции . Рехенбергом в 1965 году [3] что эволюционные алгоритмы приобрели популярность. Хорошим обзорным текстом по эволюционным алгоритмам является книга Митчелла «Введение в генетические алгоритмы» (1996). [4]
Программирование экспрессии генов [5] принадлежит к семейству эволюционных алгоритмов и тесно связан с генетическими алгоритмами и генетическим программированием . От генетических алгоритмов он унаследовал линейные хромосомы фиксированной длины; а от генетического программирования он унаследовал выразительные деревья разбора различных размеров и форм.
При программировании экспрессии генов линейные хромосомы работают как генотип, а деревья синтаксического анализа — как фенотип, создавая систему генотип/фенотип . Эта система генотип/фенотип является мультигенной , поэтому в каждой хромосоме кодируется несколько деревьев разбора. Это означает, что компьютерные программы, созданные GEP, состоят из нескольких деревьев синтаксического анализа. Поскольку эти деревья синтаксического анализа являются результатом экспрессии генов, в GEP они называются деревьями экспрессии . Масуд Некойи и др. использовал этот стиль программирования выражений в оптимизации ABC для проведения ABCEP как метода, который превзошел другие эволюционные алгоритмы. АБЦЕП
Кодировка: генотип [ править ]
Геном программирования экспрессии генов состоит из линейной символической строки или хромосомы фиксированной длины, состоящей из одного или нескольких генов одинакового размера. Эти гены, несмотря на их фиксированную длину, кодируют деревья экспрессии разных размеров и форм. Примером хромосомы с двумя генами, каждый размером 9, является строка (нулевая позиция указывает на начало каждого гена):
012345678012345678L+a-baccd**cLabacd
где «L» представляет собой функцию натурального логарифма, а «a», «b», «c» и «d» представляют собой переменные и константы, используемые в задаче.
фенотип экспрессии Деревья :
Как показано выше , гены программирования экспрессии генов имеют одинаковый размер. Однако эти строки фиксированной длины кодируют деревья выражений разных размеров. Это означает, что размер кодирующих областей варьируется от гена к гену, что позволяет плавно осуществлять адаптацию и эволюцию.
Например, математическое выражение:

также может быть представлено в виде дерева выражений :
 |
где «Q» представляет собой функцию квадратного корня.
Такое дерево экспрессии состоит из фенотипической экспрессии генов GEP, тогда как гены представляют собой линейные строки, кодирующие эти сложные структуры. В этом конкретном примере линейная строка соответствует:
01234567Q*-+abcd
это простое чтение дерева выражений сверху вниз и слева направо. Эти линейные строки называются k-выражениями (из обозначения Карвы ).
Переход от k-выражений к деревьям выражений также очень прост. Например, следующее k-выражение:
01234567890Q*b**+baQba
состоит из двух разных терминалов (переменные «a» и «b»), двух разных функций с двумя аргументами («*» и «+») и функции с одним аргументом («Q»). Его выражение дает:
 |
K-выражения и гены [ править ]
K-выражения программирования экспрессии генов соответствуют области генов, которая экспрессируется. Это означает, что в генах могут быть последовательности, которые не экспрессируются, что действительно верно для большинства генов. Целью создания этих некодирующих областей является создание буфера терминалов, чтобы все k-выражения, закодированные в генах GEP, всегда соответствовали действительным программам или выражениям.
Таким образом, гены, отвечающие за программирование экспрессии генов, состоят из двух разных доменов – «головы» и «хвоста», каждый из которых имеет разные свойства и функции. Головка используется в основном для кодирования функций и переменных, выбранных для решения поставленной задачи, тогда как хвост, хотя и используется для кодирования переменных, по сути представляет собой резервуар терминалов, гарантирующий отсутствие ошибок во всех программах.
Для генов GEP длина хвоста определяется формулой:

где h — длина головы, а n max — максимальная арность. Например, для гена, созданного с использованием набора функций F = {Q, +, −, ∗, /} и набора терминалей T = {a, b}, n max = 2. А если мы выберем длину головы равно 15, то t = 15 (2–1) + 1 = 16, что дает длину гена g 15 + 16 = 31. Случайно сгенерированная строка ниже является примером одного такого гена:
0123456789012345678901234567890*b+a-aQab+//+b+babbabbbababbaaa
Он кодирует дерево выражений:
 |
который в данном случае использует только 8 из 31 элемента, составляющего ген.
Нетрудно заметить, что, несмотря на фиксированную длину, каждый ген потенциально может кодировать деревья экспрессии разных размеров и форм, причем простейший из них состоит только из одного узла (когда первый элемент гена является терминалем) и наибольшая состоит из такого количества узлов, сколько элементов в гене (когда все элементы в голове являются функциями с максимальной арностью).
Также нетрудно увидеть, что осуществить все виды генетических модификаций ( мутацию , инверсию, вставку, рекомбинацию и т. д.) тривиально, гарантируя, что все полученные потомки будут кодировать правильные, безошибочные программы.
Мультигенные хромосомы [ править ]
Хромосомы программирования экспрессии генов обычно состоят из более чем одного гена одинаковой длины. Каждый ген кодирует дерево субвыражений (суб-ET) или подпрограмму. Тогда суб-инопланетяне смогут взаимодействовать друг с другом по-разному, образуя более сложную программу. На рисунке показан пример программы, состоящей из трех суб-ET.

В окончательной программе суб-ET могут быть связаны путем добавления или какой-либо другой функции, поскольку нет никаких ограничений на тип функции связывания, которую можно выбрать. Некоторые примеры более сложных линкеров включают в себя взятие среднего значения, медианы, среднего диапазона, определение порога их суммы для биномиальной классификации, применение сигмовидной функции для вычисления вероятности и так далее. Эти связывающие функции обычно выбираются априори для каждой проблемы, но они также могут быть элегантно и эффективно развиты сотовой системой. [6] [7] программирования экспрессии генов.
Ячейки и повторное использование кода [ править ]
При программировании экспрессии генов гомеозисные гены контролируют взаимодействие различных суб-ET или модулей основной программы. Экспрессия таких генов приводит к появлению различных основных программ или клеток, то есть они определяют, какие гены экспрессируются в каждой клетке и как суб-ET каждой клетки взаимодействуют друг с другом. Другими словами, гомеозисные гены определяют, какие суб-ET вызываются и как часто, в какой основной программе или клетке и какие связи они устанавливают друг с другом.
и клеточная Гомеозисные система гены
Гомеозисные гены имеют точно такую же структурную организацию, что и нормальные гены, и строятся с использованием идентичного процесса. Они также содержат головной домен и хвостовой домен с той разницей, что головки теперь содержат связывающие функции и особый вид терминалей – генные терминалы – которые представляют собой нормальные гены. Экспрессия нормальных генов обычно приводит к образованию различных суб-ET, которые в клеточной системе называются ADF (автоматически определяемые функции). Что касается хвостов, то они содержат только генные терминалы, то есть производные признаки, генерируемые алгоритмом на лету.
Например, хромосома на рисунке содержит три нормальных гена и один гомеотический ген и кодирует основную программу, которая вызывает в общей сложности три разные функции четыре раза, связывая их определенным образом.

Из этого примера становится ясно, что сотовая система не только допускает неограниченную эволюцию функций связи, но и повторное использование кода. в этой системе не составит труда И реализовать рекурсию .
основных программ и Несколько системы многоклеточные
Многоклеточные системы состоят из более чем одного гомеозисного гена . Каждый гомеозисный ген в этой системе объединяет различные комбинации деревьев субэкспрессий или ADF, создавая множество клеток или основных программ.
Например, программа, показанная на рисунке, была создана с использованием клеточной системы с двумя клетками и тремя нормальными генами.

Приложения этих многоклеточных систем многочисленны и разнообразны, и, как и мультигенные системы , их можно использовать как в задачах с одним выходом, так и в задачах с несколькими выходами.
Другие уровни сложности [ править ]
Головной/хвостовой домен генов GEP (как нормальных, так и гомеотических) является основным строительным блоком всех алгоритмов GEP. Однако программирование экспрессии генов также исследует другие хромосомные организации, которые более сложны, чем структура головы/хвоста. По сути, эти сложные структуры состоят из функциональных единиц или генов с основным доменом «голова/хвост» плюс одним или несколькими дополнительными доменами. Эти дополнительные домены обычно кодируют случайные числовые константы, которые алгоритм неустанно настраивает, чтобы найти хорошее решение. Например, эти числовые константы могут быть весами или коэффициентами в задаче аппроксимации функции (см. алгоритм GEP-RNC ниже); они могут быть весами и порогами нейронной сети (см. алгоритм GEP-NN ниже); числовые константы, необходимые для построения деревьев решений (см. алгоритм GEP-DT ниже); веса, необходимые для полиномиальной индукции; или случайные числовые константы, используемые для определения значений параметров в задаче оптимизации параметров.
Базовый алгоритм экспрессии генов [ править ]
Основные этапы базового алгоритма экспрессии генов перечислены ниже в псевдокоде:
- Выберите набор функций;
- Выберите набор терминалов;
- Загрузить набор данных для оценки пригодности;
- Создать хромосомы исходной популяции случайным образом;
- Для каждой программы в популяции:
- Экспресс хромосома;
- Выполнить программу;
- Оценить физическую форму;
- Проверьте состояние остановки;
- Выбрать программы;
- Воспроизвести выбранные программы для формирования следующей популяции;
- Модифицировать хромосомы с помощью генетических операторов;
- Перейдите к шагу 5.
Первые четыре шага подготавливают все ингредиенты, необходимые для итерационного цикла алгоритма (шаги с 5 по 10). Из этих подготовительных шагов решающим является создание начальной популяции, которая создается случайным образом с использованием элементов функционального и терминального наборов.
Популяции программ [ править ]
Как и все эволюционные алгоритмы, программирование экспрессии генов работает с популяциями особей, которые в данном случае представляют собой компьютерные программы. Следовательно, чтобы начать работу, необходимо создать какую-то начальную популяцию. Последующие популяции являются потомками посредством отбора и генетической модификации исходной популяции .
В системе генотип/фенотип программирования экспрессии генов необходимо создавать только простые линейные хромосомы индивидуумов, не беспокоясь о структурной устойчивости программ, которые они кодируют, поскольку их выражение всегда приводит к синтаксически правильным программам.
Фитнес-функции и среда выбора [ править ]
Фитнес-функции и среды выбора (называемые наборами обучающих данных в машинном обучении ) — это два аспекта фитнеса, и поэтому они тесно связаны между собой. Действительно, пригодность программы зависит не только от функции стоимости, используемой для измерения ее производительности, но также от данных обучения, выбранных для оценки пригодности.
Среда выбора или данные обучения [ править ]
Среда выбора состоит из набора записей тренировок, которые также называются фитнес-кейсами. Эти случаи пригодности могут представлять собой набор наблюдений или измерений, касающихся какой-либо проблемы, и они образуют так называемый набор обучающих данных.
Качество обучающих данных имеет важное значение для разработки хороших решений. Хороший обучающий набор должен быть репрезентативным для рассматриваемой задачи, а также быть хорошо сбалансированным, иначе алгоритм может застрять на каком-то локальном оптимуме. Кроме того, также важно избегать использования излишне больших наборов данных для обучения, поскольку это неоправданно замедлит работу. Хорошее практическое правило — выбрать достаточно записей для обучения, чтобы обеспечить хорошее обобщение данных проверки, а остальные записи оставить для проверки и тестирования.
Фитнес-функции [ править ]
Вообще говоря, существует три различных типа проблем, основанных на типе прогноза:
- Проблемы, связанные с числовыми (непрерывными) прогнозами;
- Проблемы, связанные с категориальными или номинальными предсказаниями, как биномиальными, так и полиномиальными;
- Проблемы, связанные с двоичными или логическими предсказаниями.
Первый тип проблем носит название регрессии ; второй известен как классификация , где логистическая регрессия является особым случаем, когда, помимо четких классификаций, таких как «Да» или «Нет», к каждому результату также прилагается вероятность; и последнее связано с булевой алгеброй и логическим синтезом .
для регрессии Фитнес - функции
В регрессии ответ или зависимая переменная являются числовыми (обычно непрерывными), и поэтому выходные данные модели регрессии также являются непрерывными. Таким образом, довольно просто оценить пригодность развивающихся моделей, сравнивая выходные данные модели со значением ответа в обучающих данных.
Существует несколько основных функций пригодности для оценки производительности модели, наиболее распространенная из которых основана на ошибке или остатке между выходными данными модели и фактическим значением. К таким функциям относятся среднеквадратическая ошибка , среднеквадратическая ошибка , средняя абсолютная ошибка , относительная квадратичная ошибка, корневая относительная квадратичная ошибка, относительная абсолютная ошибка и другие.
Все эти стандартные меры обеспечивают тонкую детализацию или гладкость пространства решений и поэтому очень хорошо работают для большинства приложений. Но некоторые проблемы могут потребовать более грубой эволюции, например, определения того, находится ли прогноз в определенном интервале, например, менее 10% от фактического значения. Однако даже если вас интересует только подсчет совпадений (то есть прогноз, находящийся в пределах выбранного интервала), развитие совокупности моделей на основе только количества совпадений, которые оценивает каждая программа, обычно не очень эффективно из-за грубого подхода. детализация фитнес-ландшафта . Таким образом, решение обычно включает в себя объединение этих грубых показателей с какой-либо гладкой функцией, такой как меры стандартной ошибки, перечисленные выше.
Функции фитнеса, основанные на коэффициенте корреляции и R-квадрате, также очень гладкие. Для задач регрессии эти функции лучше всего работают в сочетании с другими показателями, поскольку сами по себе они имеют тенденцию измерять только корреляцию , не заботясь о диапазоне значений выходных данных модели. Таким образом, объединяя их с функциями, которые аппроксимируют диапазон целевых значений, они образуют очень эффективные функции пригодности для поиска моделей с хорошей корреляцией и хорошим соответствием между прогнозируемыми и фактическими значениями.
пригодности для классификации и логистической Функции регрессии
При разработке функций приспособленности для классификации и логистической регрессии используются три различных характеристики моделей классификации. Наиболее очевидным является подсчет попаданий, то есть, если запись классифицирована правильно, она считается попаданием. Эта фитнес-функция очень проста и хорошо работает для простых задач, но для более сложных задач или сильно несбалансированных наборов данных она дает плохие результаты.
Один из способов улучшить этот тип фитнес-функции, основанной на попаданиях, состоит в расширении понятия правильных и неправильных классификаций. В задаче двоичной классификации правильными классификациями могут быть 00 или 11. Представление «00» означает, что отрицательный случай (представленный «0») был правильно классифицирован, тогда как «11» означает, что положительный случай (представленный «1» ») было правильно классифицировано. Классификации типа «00» называются истинно отрицательными (TN) и «11» истинно положительными (TP).
Существует также два типа неверных классификаций, которые обозначаются цифрами 01 и 10. Они называются ложными срабатываниями (FP), когда фактическое значение равно 0, а модель прогнозирует 1; и ложноотрицательные результаты (FN), когда целевое значение равно 1, а модель прогнозирует 0. Значения TP, TN, FP и FN обычно хранятся в таблице, известной как матрица путаницы .
| Прогнозируемый класс | |||
|---|---|---|---|
| Да | Нет | ||
Действительный сорт | Да | Город | ФН |
| Нет | ФП | ТН | |
Таким образом, подсчитав TP, TN, FP и FN и дополнительно присвоив этим четырем типам классификации разные веса, можно создать более плавные и, следовательно, более эффективные функции приспособленности. Некоторые популярные функции пригодности, основанные на матрице путаницы, включают чувствительность/специфичность , полноту/точность , F-меру , сходство Жаккара , коэффициент корреляции Мэтьюса и матрицу затрат/прибыли, которая объединяет затраты и выгоды, присвоенные 4 различным типам классификаций.
Эти функции, основанные на матрице путаницы, довольно сложны и достаточны для эффективного решения большинства проблем. Но есть еще одно измерение моделей классификации, которое является ключом к более эффективному исследованию пространства решений и, следовательно, приводит к открытию лучших классификаторов. Это новое измерение предполагает изучение структуры самой модели, которая включает не только область и диапазон, но также распределение выходных данных модели и предел классификатора.
Изучая это другое измерение моделей классификации, а затем объединяя информацию о модели с матрицей путаницы, можно разработать очень сложные функции пригодности, которые позволяют плавно исследовать пространство решений. Например, можно объединить некоторую меру, основанную на матрице путаницы, со среднеквадратичной ошибкой, оцененной между необработанными выходными данными модели и фактическими значениями. Или объедините F-меру с R-квадратом, оцененным для необработанных выходных данных модели и цели; или матрица затрат/прибыли с коэффициентом корреляции и т. д. Более экзотические функции пригодности, которые исследуют степень детализации модели, включают площадь под кривой ROC и меру ранга.
С этим новым измерением моделей классификации также связана идея присвоения вероятностей выходным данным модели, что и делается в логистической регрессии . Затем также можно использовать эти вероятности и оценить среднеквадратическую ошибку (или какую-либо другую подобную меру) между вероятностями и фактическими значениями, а затем объединить это с матрицей путаницы, чтобы создать очень эффективные функции приспособленности для логистической регрессии. Популярные примеры функций приспособленности, основанных на вероятностях, включают оценку максимального правдоподобия и потерю шарнира .
Фитнес-функции для логических задач [ править ]
В логике не существует структуры модели (как определено выше для классификации и логистической регрессии), которую нужно было бы исследовать: область и диапазон логических функций включают только 0 и 1 или ложь и истину. Таким образом, функции пригодности, доступные для булевой алгебры, могут быть основаны только на совпадениях или матрице путаницы, как описано в разделе выше .
Отбор и элитарность [ править ]
Выбор с помощью колеса рулетки — пожалуй, самая популярная схема выбора, используемая в эволюционных вычислениях. Он предполагает сопоставление пригодности каждой программы срезу колеса рулетки, пропорциональному ее приспособленности. Затем рулетку крутят столько раз, сколько программ имеется в популяции, чтобы сохранить численность популяции постоянной. Таким образом, с помощью рулетки программы выбора выбираются как в зависимости от физической подготовки, так и в зависимости от удачи розыгрыша, а это означает, что иногда лучшие качества могут быть потеряны. Однако, сочетая отбор в рулетке с клонированием лучшей программы каждого поколения, можно гарантировать, что, по крайней мере, самые лучшие черты не будут потеряны. Этот метод клонирования программы лучшего поколения известен как простой элитизм и используется в большинстве схем стохастического отбора.
Репродукция с модификацией [ править ]
Воспроизведение программ предполагает сначала отбор, а затем воспроизведение их геномов. Модификация генома не требуется для размножения, но без нее невозможна адаптация и эволюция.
Репликация и отбор [ править ]
Оператор выбора выбирает программы для копирования оператором репликации. В зависимости от схемы выбора количество копий, создаваемых одной программой, может варьироваться: некоторые программы копируются более одного раза, а другие копируются только один раз или не копируются вообще. Кроме того, отбор обычно устроен таким образом, чтобы размер популяции оставался постоянным от поколения к поколению.
Репликация геномов в природе очень сложна, и ученым потребовалось много времени, чтобы открыть двойную спираль ДНК и предложить механизм ее репликации. Но репликация строк тривиальна в искусственных эволюционных системах, где требуется только инструкция по копированию строк для передачи всей информации в геноме из поколения в поколение.
Репликация выбранных программ является фундаментальной частью всех искусственных эволюционных систем, но для того, чтобы эволюция произошла, она должна быть реализована не с обычной точностью инструкции копирования, а скорее с добавлением нескольких ошибок. Действительно, генетическое разнообразие созданные с помощью генетических операторов, таких как мутация , рекомбинация , транспозиция , инверсия и многие другие.
Мутация [ править ]
В программировании экспрессии генов мутация является наиболее важным генетическим оператором. [8] Он изменяет геномы, заменяя один элемент другим. Накопление множества небольших изменений с течением времени может создать большое разнообразие.
При программировании экспрессии генов мутация совершенно ничем не ограничена, а это означает, что в каждом домене гена любой символ домена может быть заменен другим. Например, в головах генов любую функцию можно заменить терминалом или другой функцией, независимо от количества аргументов в этой новой функции; и терминал может быть заменен функцией или другим терминалом.
Рекомбинация [ править ]
Рекомбинация обычно включает две родительские хромосомы для создания двух новых хромосом путем объединения различных частей родительских хромосом. И пока родительские хромосомы выровнены и обменявшиеся фрагменты гомологичны (т. е. занимают одно и то же положение в хромосоме), новые хромосомы, созданные в результате рекомбинации, всегда будут кодировать синтаксически правильные программы.
Различные виды скрещивания легко реализовать либо путем изменения количества задействованных родителей (нет смысла выбирать только двух); количество точек разделения; или способ обмена фрагментами, например, случайным или упорядоченным образом. Например, рекомбинация генов, являющаяся частным случаем рекомбинации, может осуществляться путем обмена гомологичными генами (генами, занимающими одно и то же положение в хромосоме) или путем обмена генами, выбранными случайным образом из любого положения хромосомы.
Транспонирование [ править ]
Транспозиция предполагает введение инсерционной последовательности где-то в хромосоме. При программировании экспрессии генов инсерционные последовательности могут появляться где угодно в хромосоме, но они вставляются только в головки генов. Этот метод гарантирует, что даже последовательности вставок из хвостов приведут к созданию безошибочных программ.
Чтобы транспозиция работала правильно, она должна сохранять длину хромосом и структуру гена. Итак, в программировании экспрессии генов транспозицию можно реализовать двумя разными методами: первый создает сдвиг в месте вставки, за которым следует делеция в конце головки; второй перезаписывает локальную последовательность на целевом сайте, и поэтому его легче реализовать. Оба метода могут быть реализованы для работы между хромосомами, внутри хромосомы или даже внутри одного гена.
Инверсия [ править ]
Инверсия — интересный оператор, особенно мощный для комбинаторной оптимизации . [9] Он заключается в инвертировании небольшой последовательности внутри хромосомы.
При программировании экспрессии генов его можно легко реализовать во всех генных доменах, и во всех случаях полученное потомство всегда синтаксически правильно. Для любого генного домена последовательность (от как минимум двух элементов до размера самого домена) выбирается случайным образом внутри этого домена, а затем инвертируется.
Другие генетические операторы [ править ]
Существует несколько других генетических операторов, и возможности программирования экспрессии генов с его различными генами и генными доменами безграничны. Например, генетические операторы, такие как одноточечная рекомбинация, двухточечная рекомбинация, генная рекомбинация, равномерная рекомбинация, транспозиция генов, корневая транспозиция, домен-специфическая мутация, домен-специфическая инверсия, домен-специфическая транспозиция и т. д., легко внедрены и широко используются.
Алгоритм GEP-RNC [ править ]
Числовые константы являются важными элементами математических и статистических моделей, и поэтому важно обеспечить их интеграцию в модели, разработанные с помощью эволюционных алгоритмов.
Программирование экспрессии генов решает эту проблему очень элегантно за счет использования дополнительного генного домена – Dc – для обработки случайных числовых констант (RNC). Объединив этот домен со специальным заполнителем терминала для RNC, можно создать богато выразительную систему.
Структурно Dc идет после хвоста, имеет длину, равную размеру хвоста t , и состоит из символов, используемых для представления RNC.
Например, ниже показана простая хромосома, состоящая только из одного гена, с размером головы 7 (Dc простирается на позиции 15–22):
01234567890123456789012+?*+?**aaa??aaa68083295
где терминал "?" представляет собой заполнитель для RNC. Этот тип хромосомы выражается точно так, как показано выше , что дает:
 |
Затем символы? в дереве выражений заменяются слева направо и сверху вниз символами (для простоты представленными цифрами) в Dc, что дает:
 |
Значения, соответствующие этим символам, сохраняются в массиве. (Для простоты число, представленное цифрой, указывает порядок в массиве.) Например, для следующего массива из 10 элементов RNC:
- С = {0,611, 1,184, 2,449, 2,98, 0,496, 2,286, 0,93, 2,305, 2,737, 0,755}
дерево выражений выше дает:
 |
Эта элегантная структура для обработки случайных числовых констант лежит в основе различных систем GEP, таких как нейронные сети GEP и деревья решений GEP .
Как и базовый алгоритм экспрессии генов , алгоритм GEP-RNC также является мультигенным, и его хромосомы декодируются, как обычно, путем экспрессии одного гена за другим, а затем связывания их всех вместе с помощью одного и того же процесса связывания.
Генетические операторы, используемые в системе GEP-RNC, являются расширением генетических операторов базового алгоритма GEP (см. выше ), и все они могут быть напрямую реализованы в этих новых хромосомах. С другой стороны, в алгоритме GEP-RNC также используются основные операторы мутации, инверсии, транспозиции и рекомбинации. Кроме того, специальные операторы, специфичные для Dc, такие как мутация, инверсия и транспозиция, также используются для более эффективной циркуляции RNC между отдельными программами. Кроме того, существует также специальный оператор мутации, позволяющий постоянно вводить вариации в набор RNC. Исходный набор RNC создается случайным образом в начале цикла, что означает, что для каждого гена в исходной популяции случайным образом генерируется определенное количество числовых констант, выбранных из определенного диапазона. Затем их циркуляция и мутация активируются генетическими операторами.
Нейронные сети [ править ]
Искусственная нейронная сеть (ИНС или НС) — это вычислительное устройство, состоящее из множества простых связанных блоков или нейронов. Связям между единицами обычно присваиваются действительные веса. Эти веса являются основным средством обучения в нейронных сетях, и для их корректировки обычно используется алгоритм обучения.
Структурно нейронная сеть имеет три разных класса модулей: входные, скрытые и выходные. Шаблон активации представлен на входных модулях, а затем распространяется в прямом направлении от входных блоков через один или несколько слоев скрытых блоков к выходным блокам. Активация, поступающая в один блок от другого блока, умножается на веса на ссылках, по которым она распространяется. Затем все входящие активации суммируются, и устройство активируется только в том случае, если входящий результат превышает пороговое значение устройства.
Таким образом, основными компонентами нейронной сети являются блоки, связи между блоками, веса и пороги. Итак, чтобы полностью смоделировать искусственную нейронную сеть, необходимо каким-то образом закодировать эти компоненты в линейной хромосоме, а затем иметь возможность выражать их осмысленным образом.
В нейронных сетях GEP (сети GEP-NN или GEP) сетевая архитектура кодируется в обычной структуре головного/хвостового домена. [10] Голова содержит специальные функции/нейроны, которые активируют скрытые и выходные единицы (в контексте GEP все эти единицы правильнее называть функциональными единицами) и терминалы, которые представляют собой входные единицы. Хвост, как обычно, содержит только терминалы/блоки ввода.
Помимо головы и хвоста, эти гены нейронной сети содержат два дополнительных домена, Dw и Dt, для кодирования весов и порогов нейронной сети. Структурно Dw идет после хвоста, а его длина d w зависит от размера головы h и максимальной арности n max и оценивается по формуле:

Dt идет после Dw и имеет длину dt , равную t . Оба домена состоят из символов, представляющих веса и пороги нейронной сети.
Для каждого NN-гена веса и пороги создаются в начале каждого прогона, но их циркуляция и адаптация гарантируются обычными генетическими операторами мутации , транспозиции , инверсии и рекомбинации . Кроме того, используются специальные операторы, обеспечивающие постоянный поток генетических вариаций в наборе весов и порогов.
Например, ниже показана нейронная сеть с двумя входными блоками ( i 1 и i 2 ), двумя скрытыми блоками ( h 1 и h 2 ) и одним выходным блоком ( o 1 ). Всего он имеет шесть соединений с шестью соответствующими весами, представленными цифрами 1–6 (для простоты все пороги равны 1 и опущены):
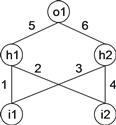 |
Это представление является каноническим представлением нейронной сети, но нейронные сети также могут быть представлены в виде дерева, что в данном случае соответствует:
 |
где «a» и «b» представляют два входа i 1 и i 2 , а «D» представляет функцию со связностью два. Эта функция складывает все свои взвешенные аргументы, а затем устанавливает пороговые значения для этой активации, чтобы определить пересылаемый выходной сигнал. Этот выходной сигнал (ноль или единица в этом простом случае) зависит от порога каждой единицы, то есть, если общая входящая активация равна или превышает порог, то выход равен единице, в противном случае – нулю.
Приведенное выше NN-дерево можно линеаризовать следующим образом:
0123456789012DDDabab654321
где структура в позициях 7–12 (Dw) кодирует веса. Значения каждого веса сохраняются в массиве и извлекаются по мере необходимости для выражения.
В качестве более конкретного примера ниже показан ген нейронной сети для задачи «исключительное-или» . Он имеет размер головы 3 и размер Dw 6:
0123456789012DDDabab393257
Его выражение приводит к следующей нейронной сети:
 |
что для набора весов:
- W = {−1,978, 0,514, −0,465, 1,22, −1,686, −1,797, 0,197, 1,606, 0, 1,753}
это дает:
 |
что является идеальным решением для функции «исключающее или».
Помимо простых логических функций с двоичными входами и двоичными выходами, алгоритм GEP-сетей может обрабатывать все виды функций или нейронов (линейный нейрон, нейрон Танха, нейрон атана, логистический нейрон, предельный нейрон, нейроны радиального базиса и треугольного базиса, все виды шаговые нейроны и так далее). Также интересно то, что алгоритм GEP-сетей может использовать все эти нейроны вместе и позволить эволюции решить, какие из них лучше всего подходят для решения поставленной задачи. Итак, GEP-сети можно использовать не только в булевых задачах, но и в логистической регрессии , классификации и регрессии . Во всех случаях GEP-сети могут быть реализованы не только с мультигенными системами , но и с клеточными системами , как одноклеточными, так и многоклеточными. Более того, проблемы полиномиальной классификации также могут быть решены за один раз с помощью GEP-сетей как с мультигенными системами, так и с многоклеточными системами.
Деревья решений [ править ]
Деревья решений (DT) — это модели классификации, в которых ряд вопросов и ответов отображаются с использованием узлов и направленных ребер.
Деревья решений имеют три типа узлов: корневой узел, внутренние узлы и листовые или конечные узлы. Корневой узел и все внутренние узлы представляют условия тестирования для различных атрибутов или переменных в наборе данных. Листовые узлы определяют метку класса для всех различных путей в дереве.
Большинство алгоритмов индукции дерева решений включают выбор атрибута для корневого узла, а затем принятие одного и того же обоснованного решения обо всех узлах дерева.
Деревья решений также могут быть созданы с помощью программирования экспрессии генов. [11] с тем преимуществом, что все решения, касающиеся роста дерева, принимаются самим алгоритмом без какого-либо вмешательства человека.
По сути, существует два разных типа алгоритмов DT: один для создания деревьев решений только с номинальными атрибутами, а другой для создания деревьев решений как с числовыми, так и с номинальными атрибутами. Этот аспект индукции дерева решений также применим к программированию экспрессии генов, и существует два алгоритма GEP для индукции дерева решений: алгоритм развивающегося дерева решений (EDT) для работы исключительно с номинальными атрибутами и EDT-RNC (EDT со случайными числовыми константами) для обработка как номинальных, так и числовых атрибутов.
В деревьях решений, созданных программированием экспрессии генов, атрибуты ведут себя как функциональные узлы в базовом алгоритме экспрессии генов , тогда как метки классов ведут себя как терминалы. Это означает, что узлы атрибутов также связаны с ними определенной арностью или количеством ветвей, которые будут определять их рост и, в конечном итоге, рост дерева. Метки классов ведут себя как терминалы, что означает, что для задачи классификации k набор терминалов с k -классов используется терминалами, представляющими k различных классов.
Правила кодирования дерева решений в линейном геноме очень похожи на правила, используемые для кодирования математических выражений (см. выше ). Таким образом, для индукции дерева решений у генов также есть голова и хвост: голова содержит атрибуты и терминалы, а хвост содержит только терминалы. Это еще раз гарантирует, что все деревья решений, разработанные GEP, всегда являются действительными программами. Кроме того, размер хвоста t также определяется размером головы h и количеством ветвей атрибута с большим количеством ветвей n max и оценивается по уравнению:

Например, рассмотрите приведенное ниже дерево решений, чтобы решить, играть ли на улице:
 |
Его можно линейно закодировать как:
01234567HOWbaaba
где «H» представляет атрибут «Влажность», «O» — атрибут «Перспектива», «W» — «Ветер», а «a» и «b» — метки класса «Да» и «Нет» соответственно. Обратите внимание, что ребра, соединяющие узлы, являются свойствами данных, определяющими тип и количество ветвей каждого атрибута, и поэтому их не нужно кодировать.
Процесс индукции дерева решений с помощью программирования экспрессии генов начинается, как обычно, с начальной популяции случайно созданных хромосом. Затем хромосомы выражаются в виде деревьев решений, и их пригодность оценивается по набору обучающих данных. В зависимости от приспособленности их затем отбирают для размножения с модификациями. Генетические операторы точно такие же, какие используются в обычной унигенной системе, например, мутация , инверсия , транспозиция и рекомбинация .
структуры Деревья решений как с номинальными, так и с числовыми атрибутами также легко создаются с помощью программирования экспрессии генов с использованием описанной выше для работы со случайными числовыми константами. Хромосомная архитектура включает дополнительный домен для кодирования случайных числовых констант, которые используются в качестве порогов для разделения данных в каждом узле ветвления. Например, ген ниже с размером головы 5 (Dc начинается в позиции 16):
012345678901234567890WOTHabababbbabba46336
кодирует дерево решений, показанное ниже:
 |
В этой системе каждый узел в голове, независимо от его типа (числовой атрибут, номинальный атрибут или терминал), связан с ним случайной числовой константой, которая для простоты в приведенном выше примере представлена цифрой 0–9. Эти случайные числовые константы закодированы в области Dc, и их выражение следует очень простой схеме: сверху вниз и слева направо элементы в Dc присваиваются один за другим элементам дерева решений. Итак, для следующего массива RNC:
- С = {62, 51, 68, 83, 86, 41, 43, 44, 9, 67}
дерево решений выше приводит к:
 |
которое также можно представить более красочно в виде обычного дерева решений:
 |
Критика [ править ]
GEP критиковали за то, что он не является значительным улучшением по сравнению с другими методами генетического программирования . Во многих экспериментах он оказался не лучше существующих методов. [12]
Программное обеспечение [ править ]
Коммерческие приложения [ править ]
- GeneXproИнструменты
- GeneXproTools — это пакет прогнозной аналитики, разработанный Gepsoft . Среды моделирования GeneXproTools включают логистическую регрессию , классификацию , регрессию , прогнозирование временных рядов и логический синтез . GeneXproTools реализует базовый алгоритм экспрессии генов и алгоритм GEP-RNC , которые используются во всех средах моделирования GeneXproTools.
Библиотеки с открытым исходным кодом [ править ]
- GEP4J - GEP для Java-проекта
- GEP4J, созданный Джейсоном Томасом, представляет собой реализацию программирования экспрессии генов с открытым исходным кодом на Java . Он реализует различные алгоритмы GEP, включая развивающиеся деревья решений (с номинальными, числовыми или смешанными атрибутами) и автоматически определяемые функции . GEP4J размещен в Google Code .
- PyGEP — программирование экспрессии генов для Python
- Создана Райаном О'Нилом с целью создать простую библиотеку, подходящую для академического изучения программирования экспрессии генов на Python , с целью простоты использования и быстрой реализации. Он реализует стандартные мультигенные хромосомы и генетические операторы мутации, скрещивания и транспозиции. PyGEP размещен в Google Code .
- jGEP — набор инструментов Java GEP
- Создан Мэтью Соттайлом для быстрого создания кодов прототипов Java , использующих GEP, которые затем можно записать на таком языке, как C или Fortran, с реальной скоростью. jGEP размещен на SourceForge .
Дальнейшее чтение [ править ]
- Феррейра, К. (2006). Программирование экспрессии генов: математическое моделирование с помощью искусственного интеллекта . Спрингер-Верлаг. ISBN 3-540-32796-7 .
- Феррейра, К. (2002). Программирование экспрессии генов: математическое моделирование с помощью искусственного интеллекта . Португалия: Ангра-ду-Эроижму. ISBN 972-95890-5-4 .
См. также [ править ]
- Символическая регрессия
- Искусственный интеллект
- Деревья решений
- Эволюционные алгоритмы
- Генетические алгоритмы
- Генетическое программирование
- Грамматическая эволюция
- Линейное генетическое программирование
- GeneXproИнструменты
- Машинное обучение
- Мультивыраженное программирование
- Нейронные сети
Ссылки [ править ]
- ^ Бокс, GEP, 1957. Эволюционная операция: метод повышения промышленной производительности . Прикладная статистика, 6, 81–101.
- ^ Фридман, Г.Дж., 1959. Цифровое моделирование эволюционного процесса. Ежегодник общих систем, 4, 171–184.
- ^ Речехберг, Инго (1973). Стратегия эволюции . Штутгарт: Хольцманн-Фробуг. ISBN 3-7728-0373-3 .
- ^ Митчелл, Мелани (1996). «Введение в генетические алгоритмы» . Кембридж, Массачусетс: MIT Press. ISBN 978-0-262-13316-6 .
- ^ Феррейра, К. (2001). «Программирование экспрессии генов: новый адаптивный алгоритм решения проблем» (PDF) . Сложные системы, Vol. 13, вып. 2: 87–129.
- ^ Феррейра, К. (2002). Программирование экспрессии генов: математическое моделирование с помощью искусственного интеллекта . Португалия: Ангра-ду-Эроижму. ISBN 972-95890-5-4 .
- ^ Феррейра, К. (2006). «Автоматически определяемые функции в программировании экспрессии генов» (PDF) . В: Н. Неджа, Л. де М. Мурель, А. Абрахам, ред., Программирование генетических систем: теория и опыт, Исследования в области вычислительного интеллекта, Vol. 13, стр. 21–56, Springer-Verlag.
- ^ Феррейра, К. (2002). «Мутация, транспозиция и рекомбинация: анализ эволюционной динамики» (PDF) . В HJ Колфилд, С.-Х. Чен, Х.-Д. Ченг, Р. Дуро, В. Хонавар, Э. Э. Керре, М. Лу, М. Г. Ромай, Т. К. Ши, Д. Вентура, П. П. Ван, Ю. Ян, ред., Материалы 6-й совместной конференции по информационным наукам, 4-го международного семинара «Границы эволюционных алгоритмов», страницы 614–617, Research Triangle Park, Северная Каролина, США.
- ^ Феррейра, К. (2002). «Комбинаторная оптимизация посредством программирования экспрессии генов: новый взгляд на инверсию» (PDF) . Под ред. Дж. М. Сантоса и А. Запико, «Материалы аргентинского симпозиума по искусственному интеллекту», стр. 160–174, Санта-Фе, Аргентина.
- ^ Феррейра, К. (2006). «Проектирование нейронных сетей с использованием программирования экспрессии генов» (PDF) . Под ред. А. Абрахама, Б. де Баетса, М. Кеппена и Б. Николая, «Прикладные технологии мягких вычислений: проблема сложности», страницы 517–536, Springer-Verlag.
- ^ Феррейра, К. (2006). Программирование экспрессии генов: математическое моделирование с помощью искусственного интеллекта . Спрингер-Верлаг. ISBN 3-540-32796-7 .
- ^ Олтеан, М.; Гросан, К. (2003), «Сравнение нескольких методов линейного генетического программирования» , Complex Systems , 14 (4): 285–314.
Внешние ссылки [ править ]
- Домашняя страница GEP , поддерживаемая изобретателем программирования экспрессии генов.
- GeneXproTools — коммерческое программное обеспечение GEP.