Бинарный поиск
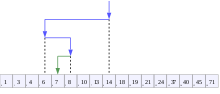 Визуализация алгоритма двоичного поиска, где 7 — целевое значение. | |
| Сорт | Алгоритм поиска |
|---|---|
| Структура данных | Множество |
| Худшая производительность | О ( войти ) |
| Лучшая производительность | О (1) |
| Средняя производительность | О ( войти ) |
| Наихудшая пространственная сложность | О (1) |
| Оптимальный | Да |
В информатике , бинарный поиск также известный как полуинтервальный поиск , [1] логарифмический поиск , [2] или бинарный отбивной , [3] — это алгоритм поиска , который находит положение целевого значения в отсортированном массиве . [4] [5] Двоичный поиск сравнивает целевое значение со средним элементом массива. Если они не равны, половина, в которой цель не может находиться, удаляется, и поиск продолжается на оставшейся половине, снова беря средний элемент для сравнения с целевым значением и повторяя это до тех пор, пока целевое значение не будет найдено. Если поиск заканчивается, а оставшаяся половина пуста, цель отсутствует в массиве.
двоичный поиск выполняется за логарифмическое время В худшем случае , что делает сравнения, где — количество элементов в массиве. [а] [6] Бинарный поиск быстрее линейного поиска, за исключением небольших массивов. Однако сначала массив необходимо отсортировать, чтобы можно было применить двоичный поиск. Существуют специализированные структуры данных, предназначенные для быстрого поиска, такие как хэш-таблицы , поиск по которым можно осуществлять более эффективно, чем двоичный поиск. Однако двоичный поиск можно использовать для решения более широкого круга задач, например, для поиска следующего по наименьшему или по величине элемента массива относительно целевого объекта, даже если он отсутствует в массиве.


Существует множество вариантов двоичного поиска. В частности, дробное каскадирование ускоряет двоичный поиск одного и того же значения в нескольких массивах. Дробный каскад эффективно решает ряд поисковых задач в вычислительной геометрии и во многих других областях. Экспоненциальный поиск расширяет двоичный поиск до неограниченных списков. Дерево двоичного поиска и структуры данных B-дерева основаны на двоичном поиске.
Алгоритм
[ редактировать ]Бинарный поиск работает с отсортированными массивами. Бинарный поиск начинается со сравнения элемента в середине массива с целевым значением. Если целевое значение соответствует элементу, возвращается его позиция в массиве. Если целевое значение меньше элемента, поиск продолжается в нижней половине массива. Если целевое значение больше элемента, поиск продолжается в верхней половине массива. При этом алгоритм на каждой итерации исключает половину, в которой целевое значение не может находиться. [7]
Процедура
[ редактировать ]Учитывая массив из элементы со значениями или записями отсортировано так, что и целевое значение , следующая подпрограмма использует двоичный поиск для поиска индекса в . [7]




- Набор к и к .
- Если , поиск завершается как безуспешный.
- Набор (положение среднего элемента) пола до , которое является наибольшим целым числом, меньшим или равным .
- Если , набор к и перейдите к шагу 2.
- Если , набор к и перейдите к шагу 2.
- Сейчас , поиск завершен; возвращаться .












Эта итеративная процедура отслеживает границы поиска с помощью двух переменных и . Процедура может быть выражена в псевдокоде следующим образом, где имена и типы переменных остаются такими же, как указано выше: floor — функция пола , и unsuccessful относится к конкретному значению, которое сообщает о неудаче поиска. [7]

function binary_search(A, n, T) is
L := 0
R := n − 1
while L ≤ R do
m := floor((L + R) / 2)
if A[m] < T then
L := m + 1
else if A[m] > T then
R := m − 1
else:
return m
return unsuccessful
Альтернативно, алгоритм может потолок принять . Это может изменить результат, если целевое значение появляется в массиве более одного раза.
Альтернативная процедура
[ редактировать ]В приведенной выше процедуре алгоритм проверяет, является ли средний элемент ( ) равно целевому ( ) в каждой итерации. Некоторые реализации исключают эту проверку во время каждой итерации. Алгоритм будет выполнять эту проверку только тогда, когда останется один элемент (когда ). Это приводит к более быстрому циклу сравнения, поскольку на каждой итерации исключается одно сравнение, хотя в среднем требуется только одна дополнительная итерация. [8]

Герман Боттенбрух опубликовал первую реализацию, в которой эта проверка не учитывалась, в 1962 году. [8] [9]
- Набор к и к .
- Пока ,
- Набор (положение среднего элемента) потолка до , что является наименьшим целым числом, большим или равным .
- Если , набор к .
- Еще, ; набор к .
- Сейчас , поиск завершен. Если , возвращаться . В противном случае поиск завершается как безуспешный.



Где ceil — функция потолка, псевдокод для этой версии:
function binary_search_alternative(A, n, T) is
L := 0
R := n − 1
while L != R do
m := ceil((L + R) / 2)
if A[m] > T then
R := m − 1
else:
L := m
if A[L] = T then
return L
return unsuccessful
Дублирующиеся элементы
[ редактировать ]Процедура может вернуть любой индекс, элемент которого равен целевому значению, даже если в массиве есть повторяющиеся элементы. Например, если массив для поиска был и цель была , то для алгоритма было бы правильно возвращать либо 4-й (индекс 3), либо 5-й (индекс 4) элемент. В этом случае обычная процедура вернет четвертый элемент (индекс 3). Он не всегда возвращает первый дубликат (рассмотрим который по-прежнему возвращает 4-й элемент). Однако иногда необходимо найти самый левый или самый правый элемент для целевого значения, которое дублируется в массиве. В приведенном выше примере 4-й элемент — это самый левый элемент значения 4, а 5-й элемент — это самый правый элемент значения 4. Альтернативная процедура, описанная выше, всегда будет возвращать индекс самого правого элемента, если такой элемент существует. [9]
![{\displaystyle [1,2,3,4,4,5,6,7]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8d3a10b0250aafff08cc862bc99b5f3b4f7c33f3)

![{\displaystyle [1,2,4,4,4,5,6,7]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5867073891e85c24ad16f2e0df8a93bd487cdec3)
Процедура поиска крайнего левого элемента
[ редактировать ]Чтобы найти самый левый элемент, можно использовать следующую процедуру: [10]
- Набор к и к .
- Пока ,
- Набор (положение среднего элемента) пола до , которое является наибольшим целым числом, меньшим или равным .
- Если , набор к .
- Еще, ; набор к .
- Возвращаться .


Если и , затем это самый левый элемент, равный . Даже если его нет в массиве, это ранг в массиве или количество элементов в массиве, меньших .


Где floor — функция пола, псевдокод для этой версии:
function binary_search_leftmost(A, n, T):
L := 0
R := n
while L < R:
m := floor((L + R) / 2)
if A[m] < T:
L := m + 1
else:
R := m
return L
Процедура поиска самого правого элемента
[ редактировать ]Чтобы найти самый правый элемент, можно использовать следующую процедуру: [10]
- Набор к и к .
- Пока ,
- Набор (положение среднего элемента) пола до , которое является наибольшим целым числом, меньшим или равным .
- Если , набор к .
- Еще, ; набор к .
- Возвращаться .

Если и , затем это самый правый элемент, равный . Даже если его нет в массиве, количество элементов массива, превышающих .




Где floor — функция пола, псевдокод для этой версии:
function binary_search_rightmost(A, n, T):
L := 0
R := n
while L < R:
m := floor((L + R) / 2)
if A[m] > T:
R := m
else:
L := m + 1
return R - 1
Приблизительные совпадения
[ редактировать ]

Вышеуказанная процедура выполняет только точные совпадения, находя положение целевого значения. Однако расширить двоичный поиск для выполнения приблизительных совпадений тривиально, поскольку двоичный поиск работает с отсортированными массивами. Например, двоичный поиск можно использовать для вычисления для данного значения его ранга (количества меньших элементов), предшественника (следующего наименьшего элемента), преемника (следующего по величине элемента) и ближайшего соседа . Запросы диапазона, определяющие количество элементов между двумя значениями, могут выполняться с помощью двух ранговых запросов. [11]
- Запросы ранга могут выполняться с помощью процедуры поиска крайнего левого элемента . количество элементов меньше целевого значения. Процедура возвращает [11]
- Запросы-предшественники могут выполняться с помощью ранговых запросов. Если ранг целевого значения , его предшественник . [12]
- Для запросов-преемников процедуру поиска самого правого элемента можно использовать . Если результат выполнения процедуры для целевого значения , то преемником целевого значения будет . [12]
- Ближайшим соседом целевого значения является либо его предшественник, либо преемник, в зависимости от того, что ближе.
- Запросы диапазона также просты. [12] Как только ранги двух значений известны, количество элементов, больше или равное первому значению и меньше второго, является разницей двух рангов. Это количество можно увеличить или уменьшить на единицу в зависимости от того, следует ли считать конечные точки диапазона частью диапазона и содержит ли массив записи, соответствующие этим конечным точкам. [13]



Производительность
[ редактировать ]
![{\displaystyle [20,30,40,50,80,90,100]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a2a762c441505aff6153082ad4c7863a26f52962)


Что касается количества сравнений, производительность бинарного поиска можно проанализировать, просматривая выполнение процедуры в бинарном дереве. Корневой узел дерева является средним элементом массива. Средний элемент нижней половины — это левый дочерний узел корня, а средний элемент верхней половины — правый дочерний узел корня. Остальная часть дерева строится аналогичным образом. Начиная с корневого узла, просматриваются левые или правые поддеревья в зависимости от того, меньше или больше целевое значение рассматриваемого узла. [6] [14]
В худшем случае двоичный поиск делает итерации цикла сравнения, где Обозначение обозначает функцию пола , которая дает наибольшее целое число, меньшее или равное аргументу, и это двоичный логарифм . Это связано с тем, что худший случай достигается, когда поиск достигает самого глубокого уровня дерева, и всегда есть уровни в дереве для любого бинарного поиска.



Худший случай также может возникнуть, когда целевой элемент отсутствует в массиве. Если на единицу меньше степени двойки, то это всегда так. В противном случае поиск может выполняться итераций, если поиск достигает самого глубокого уровня дерева. Однако это может сделать итераций, что на одну меньше, чем в худшем случае, если поиск заканчивается на втором по глубине уровне дерева. [15]


В среднем, если предположить, что каждый элемент будет искаться с одинаковой вероятностью, двоичный поиск дает итерации, когда целевой элемент находится в массиве. Это примерно равно итерации. Когда целевой элемент отсутствует в массиве, двоичный поиск выполняет итераций в среднем, предполагая, что диапазон между и внешними элементами будет найден с одинаковой вероятностью. [14]



В лучшем случае, когда целевым значением является средний элемент массива, его позиция возвращается после одной итерации. [16]
С точки зрения итераций, ни один алгоритм поиска, работающий только путем сравнения элементов, не может показать лучшую производительность в среднем и наихудшем случае, чем двоичный поиск. Дерево сравнения, представляющее бинарный поиск, имеет минимально возможное количество уровней, поскольку каждый уровень выше самого нижнего уровня дерева заполняется полностью. [б] В противном случае алгоритм поиска может исключить несколько элементов за итерацию, увеличивая количество требуемых итераций в среднем и худшем случае. Это относится и к другим алгоритмам поиска, основанным на сравнениях, поскольку, хотя они могут работать быстрее с некоторыми целевыми значениями, средняя производительность по всем элементам хуже, чем у двоичного поиска. Разделив массив пополам, двоичный поиск гарантирует, что размеры обоих подмассивов будут максимально похожими. [14]
Пространственная сложность
[ редактировать ]Двоичный поиск требует трех указателей на элементы, которые могут быть индексами массива или указателями на ячейки памяти, независимо от размера массива. Следовательно, пространственная сложность двоичного поиска равна в слове RAM модель вычислений.

Вывод среднего случая
[ редактировать ]Среднее количество итераций, выполняемых при двоичном поиске, зависит от вероятности каждого искомого элемента. В среднем случай успешных и неудачных поисков различается. Предполагается, что каждый элемент с равной вероятностью будет найден для успешного поиска. В случае неудачных поисков предполагается, что интервалы между элементами и за их пределами будут обысканы с одинаковой вероятностью. Средний случай успешного поиска — это количество итераций, необходимых для поиска каждого элемента ровно один раз, разделенное на , количество элементов. Средний случай неудачных поисков — это количество итераций, необходимых для поиска элемента в каждом интервале ровно один раз, деленное на интервалы. [14]

Успешные поиски
[ редактировать ]В представлении двоичного дерева успешный поиск может быть представлен путем от корня до целевого узла, называемым внутренним путем . Длина пути — это количество ребер (соединений между узлами), через которые проходит путь. Количество итераций, выполняемых поиском, при условии, что соответствующий путь имеет длину , является считая начальную итерацию. Длина внутреннего пути — это сумма длин всех уникальных внутренних путей. Поскольку существует только один путь от корня до любого отдельного узла, каждый внутренний путь представляет собой поиск определенного элемента. Если есть элементы, которые являются положительным целым числом, а длина внутреннего пути равна , то среднее количество итераций для успешного поиска , с добавлением одной итерации для подсчета начальной итерации. [14]




Поскольку бинарный поиск является оптимальным алгоритмом поиска со сравнениями, эта задача сводится к вычислению минимальной длины внутреннего пути всех бинарных деревьев с узлов, что равно: [17]

Например, в массиве из 7 элементов корень требует одной итерации, два элемента ниже корня требуют двух итераций, а четыре элемента ниже требуют трех итераций. В этом случае длина внутреннего пути равна: [17]

Среднее количество итераций будет на основе уравнения для среднего случая. Сумма за можно упростить до: [14]


Подставив уравнение для в уравнение для : [14]


Для целого числа , это эквивалентно уравнению для среднего случая успешного поиска, указанному выше.
Неудачные поиски
[ редактировать ]Неудачные поиски можно представить, дополняя дерево внешними узлами , что образует расширенное двоичное дерево . Если внутренний узел или узел, присутствующий в дереве, имеет менее двух дочерних узлов, то добавляются дополнительные дочерние узлы, называемые внешними узлами, так что у каждого внутреннего узла есть два дочерних узла. Таким образом, неудачный поиск можно представить как путь к внешнему узлу, родителем которого является единственный элемент, оставшийся во время последней итерации. Внешний путь — это путь от корня к внешнему узлу. Длина внешнего пути представляет собой сумму длин всех уникальных внешних путей. Если есть элементы, которые являются положительным целым числом, а длина внешнего пути равна , то среднее количество итераций при неудачном поиске , с добавлением одной итерации для подсчета начальной итерации. Длина внешнего пути делится на вместо потому что есть внешние пути, представляющие интервалы между элементами массива и за их пределами. [14]


Эту задачу аналогичным образом можно свести к определению минимальной длины внешнего пути всех бинарных деревьев с узлы. Для всех двоичных деревьев длина внешнего пути равна длине внутреннего пути плюс . [17] Подставив уравнение для : [14]

![{\displaystyle E(n)=I(n)+2n=\left[(n+1)\left\lfloor \log _{2}(n+1)\right\rfloor -2^{\left\lfloor \log _{2}(n+1)\right\rfloor +1}+2\right]+2n=(n+1)(\lfloor \log _{2}(n)\rfloor +2)-2 ^{\lfloor \log _{2}(n)\rfloor +1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/edbb46592a2cfed4a5d626d6080fd530bf7693b5)
Подставив уравнение для в уравнение для , средний случай неудачных поисков можно определить: [14]


Проведение альтернативной процедуры
[ редактировать ]Каждая итерация процедуры двоичного поиска, определенной выше, выполняет одно или два сравнения, проверяя, равен ли средний элемент целевому элементу на каждой итерации. Предполагая, что каждый элемент будет найден с одинаковой вероятностью, каждая итерация выполняет в среднем 1,5 сравнения. Вариант алгоритма проверяет, равен ли средний элемент целевому элементу в конце поиска. В среднем это исключает половину сравнения на каждой итерации. Это немного сокращает время, затрачиваемое на итерацию на большинстве компьютеров. Однако он гарантирует, что поиск займет максимальное количество итераций, добавляя в среднем одну итерацию к поиску. Поскольку цикл сравнения выполняется только раз в худшем случае небольшое увеличение эффективности на итерацию не компенсирует дополнительную итерацию для всех, кроме очень больших . [с] [18] [19]
Время работы и использование кэша
[ редактировать ]При анализе производительности бинарного поиска еще одним фактором является время, необходимое для сравнения двух элементов. Для целых чисел и строк необходимое время увеличивается линейно по мере увеличения длины кодирования (обычно количества битов ) элементов. Например, сравнение пары 64-битных целых чисел без знака потребует сравнения вдвое больше битов, чем сравнение пары 32-битных целых чисел без знака. Худший случай достигается, когда целые числа равны. Это может быть важно, когда длина кодирования элементов велика, например, при больших целочисленных типах или длинных строках, что делает сравнение элементов дорогостоящим. Более того, сравнение значений с плавающей запятой (наиболее распространенное цифровое представление действительных чисел ) часто обходится дороже, чем сравнение целых чисел или коротких строк.
В большинстве компьютерных архитектур процессор имеет аппаратный кэш , отдельный от оперативной памяти . Поскольку они расположены внутри самого процессора, доступ к кэшам осуществляется гораздо быстрее, но обычно они хранят гораздо меньше данных, чем оперативная память. Таким образом, большинство процессоров хранят ячейки памяти, к которым недавно осуществлялся доступ, а также ячейки памяти, близкие к ним. Например, при доступе к элементу массива сам элемент может быть сохранен вместе с элементами, которые хранятся рядом с ним в оперативной памяти, что ускоряет последовательный доступ к элементам массива, которые близки по индексу друг к другу ( локальность ссылки ). . В отсортированном массиве двоичный поиск может переходить к удаленным областям памяти, если массив большой, в отличие от алгоритмов (таких как линейный поиск и линейное зондирование в хеш-таблицах ), которые обращаются к элементам последовательно. Это немного увеличивает время выполнения двоичного поиска больших массивов в большинстве систем. [20]
Бинарный поиск по сравнению с другими схемами
[ редактировать ]Сортированные массивы с двоичным поиском являются очень неэффективным решением, когда операции вставки и удаления чередуются с поиском, занимая время на каждую такую операцию. Кроме того, отсортированные массивы могут усложнить использование памяти, особенно если в массив часто вставляются элементы. [21] Существуют и другие структуры данных, которые поддерживают гораздо более эффективную вставку и удаление. Бинарный поиск можно использовать для выполнения точного сопоставления и установки членства (определения того, находится ли целевое значение в коллекции значений). Существуют структуры данных, которые поддерживают более быстрое точное сопоставление и набор членства. Однако, в отличие от многих других схем поиска, двоичный поиск можно использовать для эффективного приблизительного сопоставления, обычно выполняя такие сопоставления в время независимо от типа или структуры самих значений. [22] Кроме того, есть некоторые операции, такие как поиск наименьшего и самого большого элемента, которые можно эффективно выполнять с отсортированным массивом. [11]


Линейный поиск
[ редактировать ]Линейный поиск — это простой алгоритм поиска, который проверяет каждую запись, пока не найдет целевое значение. Линейный поиск может выполняться в связанном списке, что позволяет выполнять вставку и удаление быстрее, чем в массиве. Бинарный поиск в отсортированных массивах выполняется быстрее, чем линейный поиск, за исключением случаев, когда массив короткий, хотя массив необходимо отсортировать заранее. [д] [24] Все алгоритмы сортировки , основанные на сравнении элементов, такие как быстрая сортировка и сортировка слиянием , требуют как минимум сравнения в худшем случае. [25] В отличие от линейного поиска, двоичный поиск можно использовать для эффективного приблизительного сопоставления. Существуют такие операции, как поиск наименьшего и самого большого элемента, которые можно эффективно выполнить в отсортированном массиве, но не в несортированном. [26]

Деревья
[ редактировать ]
Дерево двоичного поиска — это структура данных двоичного дерева , работающая по принципу двоичного поиска. Записи дерева расположены в отсортированном порядке, и каждая запись в дереве может быть найдена с использованием алгоритма, аналогичного двоичному поиску, занимающего среднее логарифмическое время. Вставка и удаление также требуют в среднем логарифмического времени в двоичных деревьях поиска. Это может быть быстрее, чем вставка и удаление отсортированных массивов с линейным временем, а двоичные деревья сохраняют способность выполнять все возможные операции с отсортированным массивом, включая диапазон и приблизительные запросы. [22] [27]
Однако двоичный поиск обычно более эффективен для поиска, поскольку деревья двоичного поиска, скорее всего, будут несовершенно сбалансированы, что приведет к несколько худшей производительности, чем двоичный поиск. Это относится даже к сбалансированным двоичным деревьям поиска , двоичным деревьям поиска, которые балансируют свои собственные узлы, поскольку они редко создают дерево с наименьшим возможным количеством уровней. За исключением сбалансированных двоичных деревьев поиска, дерево может быть сильно несбалансированным с небольшим количеством внутренних узлов с двумя дочерними узлами, в результате чего среднее и наихудшее время поиска приближается к сравнения. [и] Двоичные деревья поиска занимают больше места, чем отсортированные массивы. [29]
Деревья двоичного поиска пригодны для быстрого поиска во внешней памяти, хранящейся на жестких дисках, поскольку деревья двоичного поиска могут быть эффективно структурированы в файловых системах. B -дерево обобщает этот метод организации дерева. B-деревья часто используются для организации долговременного хранилища, например баз данных и файловых систем . [30] [31]
Хеширование
[ редактировать ]Для реализации ассоциативных массивов хэш -таблицы — структура данных, которая сопоставляет ключи с записями с помощью хэш-функции — обычно быстрее, чем двоичный поиск в отсортированном массиве записей. [32] требуется только амортизированное постоянное время. Для большинства реализаций хеш-таблиц в среднем [ф] [34] Однако хеширование бесполезно для приблизительных совпадений, таких как вычисление следующего наименьшего, следующего по величине и ближайшего ключа, поскольку единственная информация, предоставляемая при неудачном поиске, - это то, что цель отсутствует ни в одной записи. [35] Двоичный поиск идеально подходит для таких совпадений, выполняя их за логарифмическое время. Бинарный поиск также поддерживает приблизительные совпадения. Некоторые операции, например поиск наименьшего и наибольшего элемента, можно эффективно выполнять с отсортированными массивами, но не с хеш-таблицами. [22]
Установите алгоритмы членства
[ редактировать ]Проблема, связанная с поиском, — это членство в наборе . Любой алгоритм, выполняющий поиск, например двоичный поиск, также может использоваться для определения членства во множестве. Существуют и другие алгоритмы, которые более подходят для определения членства во множестве. Битовый массив является самым простым и полезен, когда диапазон ключей ограничен. Он компактно хранит набор битов , каждый бит представляет один ключ в диапазоне ключей. Битовые массивы работают очень быстро, требуя всего лишь время. [36] типа Judy1 Массив Judy эффективно обрабатывает 64-битные ключи. [37]

Для получения приблизительных результатов фильтры Блума , еще одна вероятностная структура данных, основанная на хешировании, хранят набор ключей путем кодирования ключей с использованием битового массива и нескольких хеш-функций. Фильтры Блума в большинстве случаев гораздо более эффективны, чем битовые массивы, и ненамного медленнее: хеш-функции, запросы на членство требуют только время. Однако фильтры Блума страдают от ложных срабатываний . [г] [час] [39]


Другие структуры данных
[ редактировать ]Существуют структуры данных, которые в некоторых случаях могут улучшить двоичный поиск как для поиска, так и для других операций, доступных для отсортированных массивов. Например, поиск, приблизительные совпадения и операции, доступные для отсортированных массивов, могут выполняться более эффективно, чем двоичный поиск, в специализированных структурах данных, таких как деревья Ван Эмде Боаса , деревья слияния , попытки и битовые массивы . Эти специализированные структуры данных обычно работают быстрее только потому, что они используют свойства ключей с определенным атрибутом (обычно ключей, которые являются небольшими целыми числами), и, следовательно, для ключей, у которых нет этого атрибута, потребуется много времени или места. [22] Пока ключи можно упорядочить, эти операции всегда можно выполнить с по крайней мере эффективно над отсортированным массивом независимо от ключей. Некоторые структуры, такие как массивы Джуди, используют комбинацию подходов, чтобы смягчить это, сохраняя при этом эффективность и способность выполнять приблизительное сопоставление. [37]
Вариации
[ редактировать ]Единый двоичный поиск
[ редактировать ]
Равномерный двоичный поиск вместо нижней и верхней границ хранит разницу в индексе среднего элемента от текущей итерации до следующей итерации. Таблица поиска, содержащая различия, вычисляется заранее. Например, если массив для поиска — [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] , средний элемент ( ) будет 6 . В этом случае средний элемент левого подмассива ( [1, 2, 3, 4, 5] ) равен 3 , а средний элемент правого подмассива ( [7, 8, 9, 10, 11] ) равен 9 . Равномерный двоичный поиск будет хранить значение 3, поскольку оба индекса отличаются от 6 на одну и ту же величину. [40] Чтобы уменьшить пространство поиска, алгоритм либо добавляет, либо вычитает это изменение из индекса среднего элемента. Равномерный двоичный поиск может быть быстрее в системах, где вычисление средней точки неэффективно, например, на компьютерах с десятичной дробью . [41]
Экспоненциальный поиск
[ редактировать ]
Экспоненциальный поиск расширяет двоичный поиск до неограниченных списков. Он начинается с поиска первого элемента с индексом, который равен степени двойки и превышает целевое значение. После этого он устанавливает этот индекс в качестве верхней границы и переключается на двоичный поиск. Поиск занимает итераций до начала двоичного поиска и не более итерации бинарного поиска, где — это положение целевого значения. Экспоненциальный поиск работает с ограниченными списками, но становится улучшением по сравнению с бинарным поиском, только если целевое значение находится недалеко от начала массива. [42]



Интерполяционный поиск
[ редактировать ]
Вместо вычисления средней точки интерполяционный поиск оценивает положение целевого значения, принимая во внимание самый низкий и самый высокий элементы в массиве, а также длину массива. Это работает на том основании, что во многих случаях средняя точка не является лучшим предположением. Например, если целевое значение близко к самому высокому элементу массива, оно, скорее всего, будет расположено ближе к концу массива. [43]
Распространенной функцией интерполяции является линейная интерполяция . Если это массив, — нижняя и верхняя границы соответственно, а является целью, то цель оценивается примерно пути между и . При использовании линейной интерполяции и равномерном или близком к равномерному распределении элементов массива интерполяционный поиск делает сравнения. [43] [44] [45]



На практике интерполяционный поиск медленнее, чем двоичный поиск для небольших массивов, поскольку интерполяционный поиск требует дополнительных вычислений. Его временная сложность растет медленнее, чем двоичный поиск, но это компенсирует лишь дополнительные вычисления для больших массивов. [43]
Дробное каскадирование
[ редактировать ]
Дробный каскад — это метод, который ускоряет двоичный поиск одного и того же элемента в нескольких отсортированных массивах. Для поиска каждого массива отдельно требуется время, где количество массивов. Дробный каскад сводит это к сохраняя в каждом массиве конкретную информацию о каждом элементе и его положении в других массивах. [46] [47]


Дробный каскад изначально был разработан для эффективного решения различных задач вычислительной геометрии . Дробный каскад применялся и в других местах, например, в интеллектуальном анализе данных и интернет-протокола . маршрутизации [46]
Обобщение на графики
[ редактировать ]Бинарный поиск был обобщен для работы с определенными типами графов, где целевое значение хранится в вершине, а не в элементе массива. Двоичные деревья поиска являются одним из таких обобщений: когда запрашивается вершина (узел) в дереве, алгоритм либо узнает, что вершина является целью, либо, в противном случае, в каком поддереве будет расположена цель. Однако это можно дополнительно обобщить как следующим образом: учитывая неориентированный, положительно взвешенный граф и целевую вершину, алгоритм при запросе вершины узнает, что она равна целевой, или ему дается инцидентное ребро, которое находится на кратчайшем пути от запрашиваемой вершины к цели. Стандартный алгоритм двоичного поиска — это просто случай, когда граф представляет собой путь. Аналогичным образом, в двоичных деревьях поиска ребра левого или правого поддерева задаются, когда запрашиваемая вершина не равна целевой. Для всех неориентированных графов с положительными весами существует алгоритм, который находит целевую вершину в запросы в худшем случае. [48]
Шумный двоичный поиск
[ редактировать ]
Алгоритмы двоичного поиска с шумом решают случай, когда алгоритм не может надежно сравнить элементы массива. Для каждой пары элементов существует определенная вероятность того, что алгоритм выполнит неправильное сравнение. Шумный двоичный поиск может найти правильное положение цели с заданной вероятностью, которая контролирует надежность полученного положения. Любая процедура двоичного поиска с шумом должна производить как минимум сравнения в среднем, где - двоичная функция энтропии и — это вероятность того, что процедура даст неправильную позицию. [49] [50] [51] Зашумленную задачу бинарного поиска можно рассматривать как случай игры Реньи-Улама : [52] вариант « Двадцати вопросов», ответы на которые могут быть неправильными. [53]



Квантовый бинарный поиск
[ редактировать ]Классические компьютеры ограничены наихудшим случаем ровно итерации при выполнении двоичного поиска. Квантовые алгоритмы бинарного поиска по-прежнему ограничены частью запросы (представляющие итерации классической процедуры), но постоянный коэффициент меньше единицы, что обеспечивает меньшую временную сложность на квантовых компьютерах . Любая точная процедура квантового двоичного поиска, то есть процедура, которая всегда дает правильный результат, требует как минимум запросы в худшем случае, где это натуральный логарифм . [54] Существует точная процедура квантового двоичного поиска, которая работает в запросы в худшем случае. [55] Для сравнения, алгоритм Гровера является оптимальным квантовым алгоритмом для поиска неупорядоченного списка элементов и требует запросы. [56]






История
[ редактировать ]Идея сортировки списка элементов для ускорения поиска возникла еще в древности. Самым ранним известным примером была табличка Инакибит-Ану из Вавилона, датируемая ок . 200 г. до н.э. Табличка содержала около 500 шестидесятеричных чисел и обратных им чисел , отсортированных в лексикографическом порядке , что облегчало поиск конкретной записи. было обнаружено несколько списков имен, отсортированных по первой букве Кроме того, на Эгейских островах . «Католик» , латинский словарь, завершенный в 1286 году нашей эры, был первой работой, описывающей правила сортировки слов в алфавитном порядке, а не только по первым нескольким буквам. [9]
В 1946 году Джон Мочли впервые упомянул бинарный поиск в рамках лекций Школы Мура , основополагающего курса колледжа по информатике. [9] В 1957 году Уильям Уэсли Петерсон опубликовал первый метод интерполяционного поиска. [9] [57] Каждый опубликованный алгоритм двоичного поиска работал только для массивов, длина которых на единицу меньше степени двойки. [я] до 1960 года, когда Деррик Генри Лемер опубликовал алгоритм двоичного поиска, который работал на всех массивах. [59] В 1962 году Герман Боттенбрух представил Алголе 60 реализацию двоичного поиска в , в которой сравнение на равенство помещалось в конец , увеличивая среднее количество итераций на одну, но уменьшая до одного количество сравнений на итерацию. [8] Единый двоичный поиск был разработан А. К. Чандрой из Стэнфордского университета в 1971 году. [9] В 1986 году Бернар Шазель и Леонидас Дж. Гибас представили дробное каскадирование как метод решения многочисленных поисковых задач в вычислительной геометрии . [46] [60] [61]
Проблемы реализации
[ редактировать ]Хотя основная идея двоичного поиска сравнительно проста, детали могут оказаться на удивление сложными.
Когда Джон Бентли назвал бинарный поиск проблемой в курсе для профессиональных программистов, он обнаружил, что девяносто процентов не смогли найти правильное решение после нескольких часов работы над ним, главным образом потому, что неправильные реализации не запускались или в редких случаях возвращали неправильный ответ. крайние случаи . [62] Исследование, опубликованное в 1988 году, показывает, что точный код для него можно найти только в пяти из двадцати учебников. [63] Более того, собственная реализация двоичного поиска Бентли, опубликованная в его книге « Жемчужины программирования» в 1986 году , содержала ошибку переполнения , которая оставалась незамеченной более двадцати лет. Реализация двоичного поиска в библиотеке языка программирования Java имела одну и ту же ошибку переполнения более девяти лет. [64]
В практической реализации переменные, используемые для представления индексов, часто имеют фиксированный размер (целые числа), и это может привести к арифметическому переполнению для очень больших массивов. Если середина пролета рассчитывается как , то значение может превышать диапазон целых чисел типа данных, используемого для хранения средней точки, даже если и находятся в пределах диапазона. Если и неотрицательны, этого можно избежать, вычислив среднюю точку как . [65]


Бесконечный цикл может возникнуть, если условия выхода из цикла определены неправильно. Один раз превышает , поиск не удался и должен сообщать о неудаче поиска. Кроме того, из цикла необходимо выйти, когда целевой элемент найден, или в случае реализации, в которой эта проверка перенесена в конец, в конце должна присутствовать проверка того, был ли поиск успешным или неудачным. Бентли обнаружил, что большинство программистов, неправильно реализовавших двоичный поиск, допустили ошибку при определении условий выхода. [8] [66]
Библиотечная поддержка
[ редактировать ]многих языков Стандартные библиотеки включают процедуры двоичного поиска:
- C предоставляет функцию
bsearch()в своей стандартной библиотеке , которая обычно реализуется посредством двоичного поиска, хотя официальный стандарт этого не требует. [67] - C++ предоставляет Стандартная библиотека функции
binary_search(),lower_bound(),upper_bound()иequal_range(). [68] - D Phobos, в Стандартная библиотека
std.rangeмодуль предоставляет типSortedRange(возвращеноsort()иassumeSorted()функции) с методамиcontains(),equaleRange(),lowerBound()иtrisect(), которые по умолчанию используют методы двоичного поиска для диапазонов, предлагающих произвольный доступ. [69] - КОБОЛ предоставляет
SEARCH ALLглагол для выполнения двоичного поиска в упорядоченных таблицах COBOL. [70] - Иди
sortпакет стандартной библиотеки содержит функцииSearch,SearchInts,SearchFloat64s, иSearchStrings, которые реализуют общий двоичный поиск, а также специальные реализации для поиска фрагментов целых чисел, чисел с плавающей запятой и строк соответственно. [71] - Java предлагает набор перегруженных
binarySearch()статические методы в классахArraysиCollectionsв стандартеjava.utilпакет для выполнения двоичного поиска в массивах Java и наListс соответственно. [72] [73] - Microsoft .NET Framework 2.0 предлагает статические общие версии алгоритма двоичного поиска в своих базовых классах коллекций. Примером может быть
System.ArrayметодBinarySearch<T>(T[] array, T value). [74] - Для Objective-C платформа Cocoa предоставляет
NSArray -indexOfObject:inSortedRange:options:usingComparator:метод в Mac OS X 10.6+. [75] Фреймворк Apple Core Foundation C также содержитCFArrayBSearchValues()функция. [76] - Python предоставляет
bisectмодуль, который сохраняет список в отсортированном порядке без необходимости сортировки списка после каждой вставки. [77] - Ruby Array включает в себя Класс
bsearchметод со встроенным приближенным сопоставлением. [78] - Rust обеспечивает Примитив среза
binary_search(),binary_search_by(),binary_search_by_key(), иpartition_point(). [79]
См. также
[ редактировать ]- Метод бисекции — алгоритм нахождения нуля функции — та же идея, которая используется для решения уравнений в действительных числах.
- Мультипликативный бинарный поиск — вариант бинарного поиска с упрощенным вычислением средней точки.
Примечания и ссылки
[ редактировать ]![]() Эта статья была отправлена в WikiJournal of Science на внешнюю академическую рецензию в 2018 году ( отчеты рецензентов ). Обновленный контент был реинтегрирован на страницу Википедии по лицензии CC-BY-SA-3.0 ( 2019 ). Проверенная версия записи:
Энтони Лин; и др. (2 июля 2019 г.). «Алгоритм двоичного поиска» (PDF) . Викижурнал науки . 2 (1): 5. дои : 10.15347/WJS/2019.005 . ISSN 2470-6345 . Викиданные Q81434400 .
Эта статья была отправлена в WikiJournal of Science на внешнюю академическую рецензию в 2018 году ( отчеты рецензентов ). Обновленный контент был реинтегрирован на страницу Википедии по лицензии CC-BY-SA-3.0 ( 2019 ). Проверенная версия записи:
Энтони Лин; и др. (2 июля 2019 г.). «Алгоритм двоичного поиска» (PDF) . Викижурнал науки . 2 (1): 5. дои : 10.15347/WJS/2019.005 . ISSN 2470-6345 . Викиданные Q81434400 .
Примечания
[ редактировать ]- ^ — обозначение Big O , и это логарифм . В нотации Big O основание логарифма не имеет значения, поскольку каждый логарифм данного основания является постоянным множителем другого логарифма другого основания. То есть, , где является константой.
- ^ Любой алгоритм поиска, основанный исключительно на сравнениях, может быть представлен с помощью двоичного дерева сравнения. Внутренний путь — это любой путь от корня до существующего узла. Позволять быть длиной внутреннего пути , суммой длин всех внутренних путей. Если каждый элемент с одинаковой вероятностью будет найден, средний случай будет или просто один плюс среднее значение всех длин внутренних путей дерева. Это связано с тем, что внутренние пути представляют собой элементы, которые алгоритм поиска сравнивает с целью. Длины этих внутренних путей представляют собой количество итераций после корневого узла. Добавление среднего значения этих длин к одной итерации в корне дает средний случай. Следовательно, чтобы минимизировать среднее количество сравнений, длина внутреннего пути должно быть сведено к минимуму. Оказывается, дерево двоичного поиска минимизирует длину внутреннего пути. Кнут 1998 доказал, что длина внешнего пути (длина пути по всем узлам, где присутствуют оба дочерних узла для каждого уже существующего узла) минимизируется, когда внешние узлы (узлы без дочерних узлов) лежат в пределах двух последовательных уровней дерева. Это также относится к внутренним путям, поскольку длина внутреннего пути линейно зависит от длины внешнего пути . Для любого дерева узлы, . Когда каждое поддерево имеет одинаковое количество узлов или, что то же самое, массив делится на половины на каждой итерации, внешние узлы, а также их внутренние родительские узлы лежат в пределах двух уровней. Отсюда следует, что двоичный поиск минимизирует количество средних сравнений, поскольку его дерево сравнения имеет минимально возможную длину внутреннего пути. [14]
- ^ Кнут в 1998 году показал на своей компьютерной модели MIX , которую Кнут спроектировал как изображение обычного компьютера, что среднее время работы этого варианта для успешного поиска составляет единицы времени по сравнению с единицы для обычного двоичного поиска. Временная сложность для этого варианта растет немного медленнее, но за счет более высокой начальной сложности. [18]
- ^ Кнут 1998 провел формальный анализ производительности обоих алгоритмов поиска по времени. На компьютере Кнута MIX , который Кнут спроектировал как образец обычного компьютера, бинарный поиск занимает в среднем единицы времени для успешного поиска, тогда как линейный поиск со сторожевым узлом в конце списка занимает единицы. Линейный поиск имеет меньшую начальную сложность, поскольку требует минимальных вычислений, но по сложности он быстро превосходит двоичный поиск. На компьютере MIX бинарный поиск превосходит линейный поиск с дозорным только в том случае, если . [14] [23]
- ^ Вставка значений в отсортированном порядке или в чередующемся ключевом шаблоне с наименьшим и наибольшим значениями приведет к созданию двоичного дерева поиска, которое максимизирует среднее и наихудшее время поиска. [28]
- ^ Можно искать некоторые реализации хэш-таблиц за гарантированное постоянное время. [33]
- ^ Это связано с тем, что простая установка всех битов, на которые указывают хэш-функции для определенного ключа, может повлиять на запросы для других ключей, которые имеют общее хэш-местоположение для одной или нескольких функций. [38]
- ^ Существуют улучшения фильтра Блума, которые повышают его сложность или поддерживают удаление; например, фильтр cuckoo использует хеширование cuckoo для получения этих преимуществ. [38]
- ^ То есть массивы длиной 1, 3, 7, 15, 31... [58]













Цитаты
[ редактировать ]- ^ Уильямс-младший, Луи Ф. (22 апреля 1976 г.). Модификация метода полуинтервального поиска (двоичного поиска) . Материалы 14-й Юго-восточной конференции ACM. АКМ. стр. 95–101. дои : 10.1145/503561.503582 . Архивировано из оригинала 12 марта 2017 года . Проверено 29 июня 2018 г.
- ^ Перейти обратно: а б Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Двоичный поиск».
- ^ Баттерфилд и Нгонди 2016 , с. 46.
- ^ Кормен и др. 2009 , с. 39.
- ^ Вайсштейн, Эрик В. «Двоичный поиск» . Математический мир .
- ^ Перейти обратно: а б Флорес, Иван; Мадпис, Джордж (1 сентября 1971 г.). «Средняя длина двоичного поиска для плотных упорядоченных списков» . Коммуникации АКМ . 14 (9): 602–603. дои : 10.1145/362663.362752 . ISSN 0001-0782 . S2CID 43325465 .
- ^ Перейти обратно: а б с Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Алгоритм Б».
- ^ Перейти обратно: а б с д Боттенбрух, Герман (1 апреля 1962 г.). «Строение и использование АЛГОЛА 60» . Журнал АКМ . 9 (2): 161–221. дои : 10.1145/321119.321120 . ISSN 0004-5411 . S2CID 13406983 . Процедура описана на стр. 214 (§43), под названием «Программа двоичного поиска».
- ^ Перейти обратно: а б с д и ж Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «История и библиография».
- ^ Перейти обратно: а б Касахара и Моришита 2006 , стр. 8–9.
- ^ Перейти обратно: а б с Седжвик и Уэйн 2011 , §3.1, подраздел «Ранг и выбор».
- ^ Перейти обратно: а б с Goldman & Goldman 2008 , стр. 461–463.
- ^ Sedgewick & Wayne 2011 , §3.1, подраздел «Запросы диапазона».
- ^ Перейти обратно: а б с д и ж г час я дж к л Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Дальнейший анализ бинарного поиска».
- ^ Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), «Теорема B».
- ^ Чанг 2003 , с. 169.
- ^ Перейти обратно: а б с Кнут 1997 , §2.3.4.5 («Длина пути»).
- ^ Перейти обратно: а б Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Упражнение 23».
- ^ Рольф, Тимоти Дж. (1997). «Аналитический вывод сравнений при двоичном поиске» . Информационный бюллетень ACM SIGNUM . 32 (4): 15–19. дои : 10.1145/289251.289255 . S2CID 23752485 .
- ^ Хуонг, Пол-Вирак; Морен, Пэт (2017). «Макеты массивов для поиска на основе сравнения». Журнал экспериментальной алгоритмики . 22 . Статья 1.3. arXiv : 1509.05053 . дои : 10.1145/3053370 . S2CID 23752485 .
- ^ Кнут 1997 , §2.2.2 («Последовательное распределение»).
- ^ Перейти обратно: а б с д Бим, Пол; Фич, Фейт Э. (2001). «Оптимальные границы проблемы предшественника и связанных с ней проблем» . Журнал компьютерных и системных наук . 65 (1): 38–72. дои : 10.1006/jcss.2002.1822 .
- ^ Кнут 1998 , Ответы на упражнения (§6.2.1) к «Упражнению 5».
- ^ Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»).
- ^ Кнут 1998 , §5.3.1 («Сортировка по минимальному сравнению»).
- ^ Sedgewick & Wayne 2011 , §3.2 («Таблицы упорядоченных символов»).
- ^ Sedgewick & Wayne 2011 , §3.2 («Двоичные деревья поиска»), подраздел «Методы и удаление на основе порядка».
- ^ Кнут 1998 , §6.2.2 («Поиск в двоичном дереве»), подраздел «А как насчет худшего случая?».
- ^ Sedgewick & Wayne 2011 , §3.5 («Приложения»), «Какую реализацию таблицы символов мне следует использовать?».
- ^ Кнут 1998 , §5.4.9 («Диски и барабаны»).
- ^ Кнут 1998 , §6.2.4 («Многосторонние деревья»).
- ^ Кнут 1998 , §6.4 («Хеширование»).
- ^ Кнут 1998 , §6.4 («Хеширование»), подраздел «История».
- ^ Дитцфельбингер, Мартин; Карлин, Анна ; Мельхорн, Курт ; Мейер ауф дер Хайде, Фридхельм; Ронерт, Ганс; Тарьян, Роберт Э. (август 1994 г.). «Динамическое идеальное хеширование: верхняя и нижняя границы». SIAM Journal по вычислительной технике . 23 (4): 738–761. дои : 10.1137/S0097539791194094 .
- ^ Морен, Пэт. «Хеш-таблицы» (PDF) . п. 1. Архивировано (PDF) оригинала 9 октября 2022 г. Проверено 28 марта 2016 г.
- ^ Кнут 2011 , §7.1.3 («Побитовые приемы и методы»).
- ^ Перейти обратно: а б Сильверстайн, Алан, Джуди IV, руководство по эксплуатации (PDF) , Hewlett-Packard , стр. 80–81, заархивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Перейти обратно: а б Фан, Бин; Андерсен, Дэйв Г.; Каминский, Майкл; Митценмахер, Майкл Д. (2014). Фильтр «Кукушка»: практически лучше, чем у Bloom . Материалы 10-й Международной конференции ACM по новым сетевым экспериментам и технологиям. стр. 75–88. дои : 10.1145/2674005.2674994 .
- ^ Блум, Бертон Х. (1970). «Компромисс пространства и времени при хэш-кодировании с допустимыми ошибками». Коммуникации АКМ . 13 (7): 422–426. CiteSeerX 10.1.1.641.9096 . дои : 10.1145/362686.362692 . S2CID 7931252 .
- ^ Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Важный вариант».
- ^ Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Алгоритм U».
- ^ Моффат и Терпин 2002 , с. 33.
- ^ Перейти обратно: а б с Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Интерполяционный поиск».
- ^ Кнут 1998 , §6.2.1 («Поиск в упорядоченной таблице»), подраздел «Упражнение 22».
- ^ Перл, Иегошуа; Итай, Алон; Авни, Хаим (1978). «Интерполяционный поиск — поиск по лог-журналу » . Коммуникации АКМ . 21 (7): 550–553. дои : 10.1145/359545.359557 . S2CID 11089655 .
- ^ Перейти обратно: а б с Шазель, Бернар ; Лю, Дин (6 июля 2001 г.). Нижние границы для поиска пересечений и дробного каскадирования в более высоком измерении . 33-й симпозиум ACM по теории вычислений . АКМ. стр. 322–329. дои : 10.1145/380752.380818 . ISBN 978-1-58113-349-3 . Проверено 30 июня 2018 г.
- ^ Шазель, Бернар ; Лю, Дин (1 марта 2004 г.). «Нижние границы для поиска пересечений и дробного каскадирования в высших измерениях» (PDF) . Журнал компьютерных и системных наук . 68 (2): 269–284. CiteSeerX 10.1.1.298.7772 . дои : 10.1016/j.jcss.2003.07.003 . ISSN 0022-0000 . Архивировано (PDF) из оригинала 9 октября 2022 года . Проверено 30 июня 2018 г.
- ^ Эмамджоме-Заде, Эхсан; Кемпе, Дэвид; Сингхал, Викрант (2016). Детерминированный и вероятностный бинарный поиск по графам . 48-й симпозиум ACM по теории вычислений . стр. 519–532. arXiv : 1503.00805 . дои : 10.1145/2897518.2897656 .
- ^ Бен-Ор, Майкл; Хасидим, Авинатан (2008). «Байесовский обучающий алгоритм оптимален для шумного двоичного поиска (а также очень хорош для квантового поиска)» (PDF) . 49-й симпозиум по основам информатики . стр. 221–230. дои : 10.1109/FOCS.2008.58 . ISBN 978-0-7695-3436-7 . Архивировано (PDF) из оригинала 9 октября 2022 года.
- ^ Пелц, Анджей (1989). «Поиск с известной вероятностью ошибки» . Теоретическая информатика . 63 (2): 185–202. дои : 10.1016/0304-3975(89)90077-7 .
- ^ Ривест, Рональд Л .; Мейер, Альберт Р .; Клейтман, Дэниел Дж .; Винклманн, К. Борьба с ошибками в процедурах двоичного поиска . 10-й симпозиум ACM по теории вычислений . дои : 10.1145/800133.804351 .
- ^ Пелц, Анджей (2002). «Поиск игр с ошибками — пятьдесят лет борьбы с лжецами» . Теоретическая информатика . 270 (1–2): 71–109. дои : 10.1016/S0304-3975(01)00303-6 .
- ^ Реньи, Альфред (1961). «Об одной задаче теории информации». Бюллетени Института математических исследований Венгерской академии наук (на венгерском языке). 6 : 505–516. МР 0143666 .
- ^ Хойер, Питер; Неербек, Ян; Ши, Яоюнь (2002). «Квантовые сложности упорядоченного поиска, сортировки и различения элементов». Алгоритмика . 34 (4): 429–448. arXiv : Quant-ph/0102078 . дои : 10.1007/s00453-002-0976-3 . S2CID 13717616 .
- ^ Чайлдс, Эндрю М.; Ландал, Эндрю Дж.; Паррило, Пабло А. (2007). «Квантовые алгоритмы для задачи упорядоченного поиска посредством полуопределенного программирования». Физический обзор А. 75 (3). 032335. arXiv : quant-ph/0608161 . Бибкод : 2007PhRvA..75c2335C . дои : 10.1103/PhysRevA.75.032335 . S2CID 41539957 .
- ^ Гровер, Лов К. (1996). Быстрый квантовомеханический алгоритм поиска в базе данных . 28-й симпозиум ACM по теории вычислений . Филадельфия, Пенсильвания. стр. 212–219. arXiv : Quant-ph/9605043 . дои : 10.1145/237814.237866 .
- ^ Петерсон, Уильям Уэсли (1957). «Адресация для оперативного хранилища». Журнал исследований и разработок IBM . 1 (2): 130–146. дои : 10.1147/рд.12.0130 .
- ^ "2 н −1". OEIS A000225. Архивировано 8 июня 2016 года в Wayback Machine . Проверено 7 мая 2016 года.
- ^ Лемер, Деррик (1960). «Обучение компьютеру комбинаторным трюкам» . Материалы симпозиумов по прикладной математике . 10 : 180–181. дои : 10.1090/psapm/010 . ISBN 9780821813102 .
- ^ Шазель, Бернар ; Гибас, Леонидас Дж. (1986). «Дробный каскад: I. Техника структурирования данных» (PDF) . Алгоритмика . 1 (1–4): 133–162. CiteSeerX 10.1.1.117.8349 . дои : 10.1007/BF01840440 . S2CID 12745042 .
- ^ Шазель, Бернар ; Гибас, Леонидас Дж. (1986), «Дробный каскад: II. Приложения» (PDF) , Algorithmica , 1 (1–4): 163–191, doi : 10.1007/BF01840441 , S2CID 11232235
- ^ Bentley 2000 , §4.1 («Проблема двоичного поиска»).
- ^ Паттис, Ричард Э. (1988). «Ошибки учебника при двоичном поиске». Бюллетень SIGCSE . 20 : 190–194. дои : 10.1145/52965.53012 .
- ^ Блох, Джошуа (2 июня 2006 г.). «Дополнительно, дополнительно — прочитайте об этом все: почти все двоичные поиски и сортировки слиянием не работают» . Блог исследований Google . Архивировано из оригинала 1 апреля 2016 года . Проверено 21 апреля 2016 г.
- ^ Руджери, Сальваторе (2003). «О вычислении полусуммы двух целых чисел» (PDF) . Письма об обработке информации . 87 (2): 67–71. CiteSeerX 10.1.1.13.5631 . дои : 10.1016/S0020-0190(03)00263-1 . Архивировано (PDF) из оригинала 3 июля 2006 г. Проверено 19 марта 2016 г.
- ^ Bentley 2000 , §4.4 («Принципы»).
- ^ "bsearch – бинарный поиск в отсортированной таблице" . Базовые спецификации открытой группы (7-е изд.). Открытая группа . 2013. Архивировано из оригинала 21 марта 2016 года . Проверено 28 марта 2016 г.
- ^ Страуструп 2013 , с. 945.
- ^ «std.range — язык программирования D» . dlang.org . Проверено 29 апреля 2020 г.
- ^ Unisys (2012), Справочное руководство по программированию COBOL ANSI-85 , том. 1, стр. 598–601.
- ^ «Сортировка пакетов» . Язык программирования Go . Архивировано из оригинала 25 апреля 2016 года . Проверено 28 апреля 2016 г.
- ^ "java.util.Массивы" . Документация платформы Java Standard Edition 8 . Корпорация Оракл . Архивировано из оригинала 29 апреля 2016 года . Проверено 1 мая 2016 г.
- ^ "java.util.Коллекции" . Документация платформы Java Standard Edition 8 . Корпорация Оракл . Архивировано из оригинала 23 апреля 2016 года . Проверено 1 мая 2016 г.
- ^ «Метод List<T>.BinarySearch (T)» . Сеть разработчиков Microsoft . Архивировано из оригинала 7 мая 2016 года . Проверено 10 апреля 2016 г. .
- ^ «НСАррай» . Библиотека разработчиков Mac . Apple Inc. Архивировано из оригинала 17 апреля 2016 года . Проверено 1 мая 2016 г.
- ^ "CFArray" . Библиотека разработчиков Mac . Apple Inc. Архивировано из оригинала 20 апреля 2016 года . Проверено 1 мая 2016 г.
- ^ «8.6. bisect — Алгоритм деления массива пополам» . Стандартная библиотека Python . Фонд программного обеспечения Python. Архивировано из оригинала 25 марта 2018 года . Проверено 26 марта 2018 г.
- ^ Фицджеральд 2015 , с. 152.
- ^ «Примитивный тип
slice" . Стандартная библиотека Rust . The Rust Foundation . 2024. Проверено 25 мая 2024 года .
Источники
[ редактировать ]- Бентли, Джон (2000). Перлы программирования (2-е изд.). Аддисон-Уэсли . ISBN 978-0-201-65788-3 .
- Баттерфилд, Эндрю; Нгонди, Джерард Э. (2016). Словарь информатики (7-е изд.). Оксфорд, Великобритания: Издательство Оксфордского университета . ISBN 978-0-19-968897-5 .
- Чанг, Ши-Куо (2003). Структуры данных и алгоритмы . Программная инженерия и инженерия знаний. Том. 13. Сингапур: World Scientific . ISBN 978-981-238-348-8 .
- Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л .; Стоун, Клиффорд (2009). Введение в алгоритмы (3-е изд.). MIT Press и McGraw-Hill. ISBN 978-0-262-03384-8 .
- Фицджеральд, Майкл (2015). Рубиновый карманный справочник . Севастополь, Калифорния: O'Reilly Media . ISBN 978-1-4919-2601-7 .
- Голдман, Салли А .; Голдман, Кеннет Дж. (2008). Практическое руководство по структурам данных и алгоритмам с использованием Java . Бока-Ратон, Флорида: CRC Press . ISBN 978-1-58488-455-2 .
- Касахара, Масахиро; Моришита, Шиничи (2006). Масштабная обработка последовательности генома . Лондон, Великобритания: Издательство Имперского колледжа. ISBN 978-1-86094-635-6 .
- Кнут, Дональд (1997). Фундаментальные алгоритмы . Искусство компьютерного программирования . Том. 1 (3-е изд.). Ридинг, Массачусетс: Addison-Wesley Professional. ISBN 978-0-201-89683-1 .
- Кнут, Дональд (1998). Сортировка и поиск . Искусство компьютерного программирования . Том. 3 (2-е изд.). Ридинг, Массачусетс: Addison-Wesley Professional. ISBN 978-0-201-89685-5 .
- Кнут, Дональд (2011). Комбинаторные алгоритмы . Искусство компьютерного программирования . Том. 4А (1-е изд.). Ридинг, Массачусетс: Addison-Wesley Professional. ISBN 978-0-201-03804-0 .
- Моффат, Алистер; Терпин, Эндрю (2002). Алгоритмы сжатия и кодирования . Гамбург, Германия: Академическое издательство Kluwer. дои : 10.1007/978-1-4615-0935-6 . ISBN 978-0-7923-7668-2 .
- Седжвик, Роберт ; Уэйн, Кевин (2011). Алгоритмы (4-е изд.). Река Аппер-Сэддл, Нью-Джерси: Addison-Wesley Professional. ISBN 978-0-321-57351-3 . Сокращенная веб-версия
 ; книжная версия
; книжная версия  .
. - Страуструп, Бьярне (2013). Язык программирования C++ (4-е изд.). Река Аппер-Сэддл, Нью-Джерси: Addison-Wesley Professional. ISBN 978-0-321-56384-2 .