Хранилище данных

В вычислительной технике хранилище данных ( DW или DWH ), также известное как хранилище данных предприятия ( EDW ), представляет собой систему, используемую для отчетности и анализа данных , и считается основным компонентом бизнес-аналитики . [1] Хранилища данных — это центральные хранилища интегрированных данных из одного или нескольких разрозненных источников. Они хранят текущие и исторические данные в одном месте, которые используются для создания отчетов. Это выгодно компаниям, поскольку позволяет им запрашивать данные, извлекать информацию из них и принимать решения. [2]
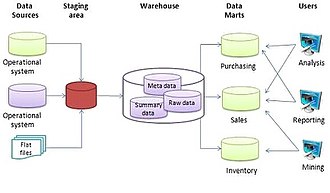
Данные, хранящиеся на складе, загружаются из операционных систем (таких как маркетинг или продажи). Данные могут проходить через хранилище операционных данных и могут потребовать очистки данных для дополнительных операций, чтобы гарантировать качество данных, прежде чем они будут использованы в хранилище данных для отчетности.
Извлечение, преобразование, загрузка (ETL) и извлечение, загрузка, преобразование (ELT) — два основных подхода, используемых для построения системы хранилища данных.
Варианты [ править ]
Хранилище данных на основе ETL [ править ]
Типичное хранилище данных на основе извлечения, преобразования и загрузки (ETL) использует уровни промежуточного хранения , интеграции данных и доступа для размещения своих ключевых функций. Промежуточный уровень или промежуточная база данных хранит необработанные данные, извлеченные из каждой из разрозненных систем исходных данных. Уровень интеграции объединяет разрозненные наборы данных путем преобразования данных из промежуточного уровня, часто сохраняя эти преобразованные данные в базе данных хранилища операционных данных (ODS). Затем интегрированные данные перемещаются в еще одну базу данных, часто называемую базой данных хранилища данных, где данные группируются в иерархические группы, часто называемые измерениями, а также в факты и совокупные факты. Сочетание фактов и измерений иногда называют звездной схемой . Уровень доступа помогает пользователям получать данные. [3]
Основной источник данных очищается , преобразуется, каталогизируется и становится доступным для использования менеджерами и другими бизнес-специалистами для интеллектуального анализа данных , онлайн-аналитической обработки , исследования рынка и поддержки принятия решений . [4] Однако средства извлечения и анализа данных, извлечения, преобразования и загрузки данных, а также управления словарем данных также считаются важными компонентами системы хранения данных. Многие ссылки на хранилища данных используют этот более широкий контекст. Таким образом, расширенное определение хранилища данных включает в себя инструменты бизнес-аналитики , инструменты для извлечения, преобразования и загрузки данных в хранилище, а также инструменты для управления метаданными и их извлечения .
Хранилище данных на основе ELT [ править ]
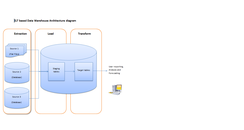
Хранилища данных на основе ELT избавляются от отдельного инструмента ETL для преобразования данных. Вместо этого он поддерживает промежуточную область внутри самого хранилища данных. При таком подходе данные извлекаются из разнородных исходных систем, а затем непосредственно загружаются в хранилище данных до того, как произойдет какое-либо преобразование. Все необходимые преобразования затем выполняются внутри самого хранилища данных. Наконец, обработанные данные загружаются в целевые таблицы в том же хранилище данных.
Преимущества [ править ]
Хранилище данных хранит копию информации из исходных систем транзакций. Такая архитектурная сложность дает возможность:
- Интегрируйте данные из нескольких источников в единую базу данных и модель данных. Большее количество данных в одной базе данных, что позволяет использовать единый механизм запросов для представления данных в ODS .
- Уменьшите проблему конфликтов блокировки уровня изоляции базы данных в системах обработки транзакций , вызванную попытками выполнить большие, длительные аналитические запросы в базах данных обработки транзакций.
- Сохраняйте историю данных , даже если исходные системы транзакций этого не делают.
- Интегрируйте данные из нескольких исходных систем, обеспечивая централизованное представление по всему предприятию. Это преимущество всегда ценно, особенно когда организация выросла за счет слияния.
- Повышайте качество данных , предоставляя согласованные коды и описания, отмечая или даже исправляя неверные данные.
- Представляйте информацию об организации последовательно.
- Обеспечьте единую общую модель данных для всех интересующих данных независимо от источника данных.
- Реструктурируйте данные так, чтобы они были понятны бизнес-пользователям.
- Реструктурируйте данные так, чтобы они обеспечивали превосходную производительность даже для сложных аналитических запросов, не влияя при этом на операционные системы .
- Повысьте ценность операционных бизнес-приложений, особенно систем управления взаимоотношениями с клиентами (CRM).
- Упростите написание запросов для поддержки принятия решений.
- Организуйте и устраните неоднозначность повторяющихся данных.
Общий [ править ]
Среда для хранилищ данных и витрин включает в себя следующее:
- Исходные системы, предоставляющие данные на склад или рынок;
- Технологии и процессы интеграции данных, необходимые для подготовки данных к использованию;
- Различные архитектуры хранения данных в хранилище данных или витринах данных организации;
- Различные инструменты и приложения для разных пользователей;
- Метаданные, качество данных и процессы управления должны быть в наличии, чтобы гарантировать, что склад или рынок соответствуют своим целям.
Что касается перечисленных выше исходных систем, Р. Келли Райнер заявляет: «Общим источником данных в хранилищах данных являются операционные базы данных компании, которые могут быть реляционными базами данных». [5]
Что касается интеграции данных, Райнер заявляет: «Необходимо извлечь данные из исходных систем, преобразовать их и загрузить в витрину или хранилище данных». [5]
Райнер обсуждает хранение данных в хранилище данных или витринах данных организации. [5]
Метаданные — это данные о данных. «ИТ-персоналу нужна информация об источниках данных; именах баз данных, таблиц и столбцов; расписаниях обновления; и мерах использования данных». [5]
Сегодня наиболее успешными компаниями являются те, которые могут быстро и гибко реагировать на изменения и возможности рынка. Ключом к этому ответу является эффективное и действенное использование данных и информации аналитиками и менеджерами. [5] «Хранилище данных» — это хранилище исторических данных, организованное субъектом для поддержки лиц, принимающих решения в организации. [5] Как только данные будут сохранены в витрине или хранилище данных, к ним можно будет получить доступ.
Связанные системы [ править ]
Витрина данных — это простая форма хранилища данных, ориентированная на один предмет (или функциональную область), поэтому они собирают данные из ограниченного числа источников, таких как продажи, финансы или маркетинг. Витрины данных часто создаются и контролируются одним отделом организации. Источниками могут быть внутренние операционные системы, центральное хранилище данных или внешние данные. [6] Денормализация является нормой для методов моделирования данных в этой системе. Учитывая, что витрины данных обычно охватывают только часть данных, содержащихся в хранилище данных, их зачастую проще и быстрее реализовать.
| Атрибут | Хранилище данных | Витрина данных |
|---|---|---|
| Объем данных | в масштабе всего предприятия | общедепартаментский |
| Количество предметных областей | несколько | одинокий |
| Как сложно построить | трудный | легкий |
| Сколько времени нужно на постройку | более | меньше |
| Объем памяти | больше | ограниченный |
Типы витрин данных включают зависимые , независимые и гибридные витрины данных. [ нужны разъяснения ]
Онлайн-аналитическая обработка (OLAP) характеризуется относительно небольшим объемом транзакций. Запросы часто очень сложны и включают в себя агрегаты. Для OLAP-систем время отклика является эффективной мерой. Приложения OLAP широко используются методами интеллектуального анализа данных . Базы данных OLAP хранят агрегированные исторические данные в многомерных схемах (обычно звездообразных ). В системах OLAP задержка данных обычно составляет несколько часов, в отличие от витрин данных, где ожидается, что задержка будет ближе к одному дню. Подход OLAP используется для анализа многомерных данных из нескольких источников и точек зрения. Тремя основными операциями в OLAP являются свертывание (консолидация), детализация и нарезка на кусочки.
Обработка онлайн-транзакций (OLTP) характеризуется большим количеством коротких онлайн-транзакций (INSERT, UPDATE, DELETE). В системах OLTP особое внимание уделяется очень быстрой обработке запросов и поддержанию целостности данных в средах с множественным доступом. Для OLTP-систем эффективность измеряется количеством транзакций в секунду. Базы данных OLTP содержат подробные и актуальные данные. Схема, используемая для хранения транзакционных баз данных, — это модель сущности (обычно 3NF ). [7] Нормализация является нормой для методов моделирования данных в этой системе.
Прогнозная аналитика – это поиск и количественная оценка скрытых закономерностей в данных с использованием сложных математических моделей, которые можно использовать для прогнозирования будущих результатов. Прогнозный анализ отличается от OLAP тем, что OLAP фокусируется на анализе исторических данных и носит реактивный характер, тогда как прогнозный анализ ориентирован на будущее. Эти системы также используются для управления взаимоотношениями с клиентами (CRM).
История [ править ]
Концепция хранилища данных возникла в конце 1980-х годов. [8] когда исследователи IBM Барри Девлин и Пол Мерфи разработали «хранилище бизнес-данных». По сути, концепция хранилища данных была призвана обеспечить архитектурную модель потока данных от операционных систем к средам поддержки принятия решений . В этой концепции была предпринята попытка решить различные проблемы, связанные с этим потоком, в основном связанные с ним высокие затраты. В отсутствие архитектуры хранилища данных требовалась огромная избыточность для поддержки нескольких сред поддержки принятия решений. В крупных корпорациях было типично, что несколько сред поддержки принятия решений работали независимо. Хотя каждая среда обслуживала разных пользователей, им часто требовалась большая часть одних и тех же хранимых данных. Процесс сбора, очистки и интеграции данных из различных источников, обычно из давно существующих операционных систем (обычно называемых устаревшими системами ), обычно частично воспроизводился для каждой среды. Более того, операционные системы часто пересматривались по мере появления новых требований к поддержке принятия решений. Часто новые требования требовали сбора, очистки и интеграции новых данных из « витрины данных », специально предназначенные для быстрого доступа пользователей.
Кроме того, с публикацией книги Джеймса М. Керра «Императив IRM» (Wiley & Sons, 1991) стала популярной идея управлять ресурсами данных организации и определять их денежную стоимость, а затем отражать эту стоимость как актив в балансовом отчете. . В книге Керр описал способ заполнения баз данных предметной области данными, полученными из систем, управляемых транзакциями, для создания области хранения, где сводные данные можно было бы в дальнейшем использовать для информирования руководителей, принимающих решения. Эта концепция способствовала дальнейшему обдумыванию того, как можно было бы разработать хранилище данных и управлять им на практике на любом предприятии.
Ключевые события в первые годы существования хранилищ данных:
- 1960-е годы — General Mills и Дартмутский колледж терминов в рамках совместного исследовательского проекта разрабатывают аспекты и факты . [9]
- 1970-е годы – ACNielsen и IRI предоставляют витрины объемных данных для розничных продаж. [9]
- 1970-е годы – Билл Инмон начинает определять и обсуждать термин «Хранилище данных». [10] [11] [12]
- 1975 – Sperry Univac представляет MAPPER (MAintain, Подготовка и Создание Исполнительных Отчетов), систему управления базами данных и отчетности, которая включает первую в мире систему 4GL . Это первая платформа, предназначенная для создания информационных центров (предшественник современной технологии хранилищ данных).
- 1983 – Teradata представляет компьютер базы данных DBC/1012, специально разработанный для поддержки принятия решений. [13]
- 1984 – Компания Metaphor Computer Systems , основанная Дэвидом Лиддлом и Доном Массаро, выпускает пакет аппаратного/программного обеспечения и графический интерфейс для бизнес-пользователей для создания системы управления базами данных и аналитической системы.
- 1988 - Барри Девлин и Пол Мерфи публикуют статью «Архитектура бизнес-информационной системы», в которой вводят термин «хранилище бизнес-данных». [14]
- 1990 — Red Brick Systems, основанная Ральфом Кимбаллом , представляет Red Brick Warehouse, систему управления базами данных, специально предназначенную для хранения данных.
- 1991 - Джеймс М. Керр пишет книгу «IRM Imperative», которая предполагает, что ресурсы данных могут отражаться как активы в балансовом отчете, что способствует коммерческому интересу к созданию хранилищ данных.
- 1991 — Prism Solutions, основанная Биллом Инмоном , представляет Prism Warehouse Manager, программное обеспечение для разработки хранилища данных.
- 1992 — Билл Инмон публикует книгу Building the Data Warehouse . [15]
- 1995 г. - основан Институт хранилищ данных, коммерческая организация, занимающаяся продвижением хранилищ данных.
- 1996 — Ральф Кимбалл публикует книгу The Data Warehouse Toolkit . [16]
- 1998 г. - Фокальное моделирование реализуется как ансамблевый (гибридный) подход к моделированию хранилища данных, одним из главных инициаторов которого является Патрик Лагер. [17] [18]
- 2000 — Дэн Линстедт публикует в открытом доступе модель хранилища данных , задуманную в 1990 году как альтернативу Inmon и Kimball для обеспечения долгосрочного исторического хранения данных, поступающих из нескольких операционных систем, с упором на отслеживание, аудит и устойчивость к изменениям. модели исходных данных.
- 2008 - Билл Инмон вместе с Дереком Штраусом и Дженией Нойлосс публикует «DW 2.0: Архитектура для следующего поколения хранилищ данных», объясняя свой нисходящий подход к хранению данных и создавая термин «хранилище данных 2.0».
- 2008 - Якорное моделирование было формализовано в статье, представленной на Международной конференции по концептуальному моделированию, и получило награду за лучшую статью. [19]
- 2012 г. - Билл Инмон разрабатывает и обнародует технологию, известную как «устранение текстовой неоднозначности». Устранение текстовой неоднозначности применяет контекст к необработанному тексту и переформатирует необработанный текст и контекст в стандартный формат базы данных. После того как необработанный текст проходит через устранение текстовой неоднозначности, к нему можно легко и эффективно получить доступ и проанализировать его с помощью стандартной технологии бизнес-аналитики. Текстовое устранение неоднозначности достигается посредством выполнения текстового ETL. Устранение текстовой неоднозначности полезно везде, где встречается необработанный текст, например в документах, Hadoop, электронной почте и т. д.
- 2013 г. – выпущено хранилище данных 2.0, [20] [21] внесение небольших изменений в метод моделирования, а также интеграция с лучшими практиками других методологий, архитектур и реализаций, включая принципы Agile и CMMI.
Хранение информации [ править ]
Факты [ править ]
Факт — это значение или измерение, которое представляет факт об управляемом объекте или системе.
Факты, сообщенные отчитывающейся организацией, считаются исходными; например, в системе мобильной телефонной связи, если BTS ( базовая приемопередающая станция ) получает 1000 запросов на выделение каналов трафика, выделяет 820 и отклоняет остальные, она сообщит три факта системе управления или измерения:
tch_req_total = 1000tch_req_success = 820tch_req_fail = 180
Факты на исходном уровне далее агрегируются на более высокие уровни в различных измерениях, чтобы извлечь из них больше информации, важной для услуг или бизнеса. Их называют агрегатами, сводками или агрегированными фактами.
Например, если в городе есть три BTS, то приведенные выше факты можно агрегировать от BTS до уровня города в сетевом измерении. Например:
tch_req_success_city = tch_req_success_bts1 + tch_req_success_bts2 + tch_req_success_bts3avg_tch_req_success_city = (tch_req_success_bts1 + tch_req_success_bts2 + tch_req_success_bts3) / 3
к хранению данных Размерный и нормализованный подход
Существует три или более ведущих подхода к хранению данных в хранилище данных. Наиболее важными подходами являются размерный подход и нормализованный подход.
Размерный подход относится к подходу Ральфа Кимбалла , в котором утверждается, что хранилище данных должно моделироваться с использованием размерной модели/ звездообразной схемы . Нормализованный подход, также называемый моделью 3NF (Третья нормальная форма), относится к подходу Билла Инмона, в котором утверждается, что хранилище данных должно моделироваться с использованием модели ER/нормализованной модели. [22]
Размерный подход [ править ]
При подходе многомерном данные транзакций разделяются на «факты», которые обычно представляют собой числовые данные транзакций, и « измерения », которые представляют собой справочную информацию, которая придает контекст фактам. Например, транзакция продажи может быть разбита на такие факты, как количество заказанных продуктов и общая цена, уплаченная за продукты, а также на такие измерения, как дата заказа, имя клиента, номер продукта, место доставки заказа и получатель счета. местоположения и продавца, ответственного за получение заказа.
Ключевое преимущество размерного подхода заключается в том, что пользователю легче понять и использовать хранилище данных. Кроме того, извлечение данных из хранилища данных обычно происходит очень быстро. [16] Размерные структуры легко понять бизнес-пользователям, поскольку структура разделена на измерения/факты и контекст/измерения. Факты связаны с бизнес-процессами и операционной системой организации, тогда как окружающие их измерения содержат контекст измерения (Кимбалл, Ральф, 2008). Еще одним преимуществом многомерной модели является то, что она не требует постоянного использования реляционной базы данных. Таким образом, этот тип метода моделирования очень полезен для запросов конечных пользователей в хранилище данных.
Модель фактов и измерений также можно понимать как куб данных . [23] Если измерения — это категориальные координаты в многомерном кубе, факт — это значение, соответствующее координатам.
Основными недостатками размерного подхода являются следующие:
- Чтобы сохранить целостность фактов и измерений, загрузка хранилища данных данными из разных операционных систем усложняется.
- Трудно изменить структуру хранилища данных, если организация, применяющая многомерный подход, меняет способ ведения бизнеса.
Нормализованный подход [ править ]
При нормализованном подходе данные в хранилище данных хранятся в соответствии с правилами нормализации базы данных . Таблицы сгруппированы по предметным областям , которые отражают общие категории данных (например, данные о клиентах, продуктах, финансах и т. д.). Нормализованная структура делит данные на сущности, в результате чего в реляционной базе данных создается несколько таблиц. При применении на крупных предприятиях в результате получаются десятки таблиц, связанных между собой сетью объединений. Более того, каждый из созданных объектов при реализации базы данных преобразуется в отдельные физические таблицы (Кимбалл, Ральф, 2008).Основным преимуществом этого подхода является простота добавления информации в базу данных. Некоторые недостатки этого подхода заключаются в том, что из-за большого количества задействованных таблиц пользователям может быть сложно объединить данные из разных источников в значимую информацию и получить доступ к информации без точного понимания источников данных и структуры данных . хранилища данных.
Как нормализованные, так и многомерные модели могут быть представлены в диаграммах сущность-связь, поскольку обе содержат соединенные реляционные таблицы. Разница между двумя моделями заключается в степени нормализации (также известной как нормальные формы ). Эти подходы не являются взаимоисключающими, существуют и другие подходы. Размерные подходы могут в определенной степени включать нормализацию данных (Кимбалл, Ральф, 2008).
В информационно-ориентированном бизнесе [24] Роберт Хиллард предлагает подход к сравнению двух подходов, основанный на информационных потребностях бизнес-задачи. Этот метод показывает, что нормализованные модели содержат гораздо больше информации, чем их размерные эквиваленты (даже если в обеих моделях используются одни и те же поля), но эта дополнительная информация достигается за счет удобства использования. Этот метод измеряет количество информации с точки зрения информационной энтропии и удобства использования с точки зрения меры преобразования данных «Маленькие миры». [25]
Методы проектирования [ править ]
Этот раздел нуждается в дополнительных цитатах для проверки . ( Июль 2015 г. ) |
Дизайн снизу вверх [ править ]
При восходящем подходе витрины данных сначала создаются для предоставления возможностей отчетности и анализа для конкретных бизнес-процессов . Эти витрины данных затем можно интегрировать для создания комплексного хранилища данных. Архитектура шины хранилища данных — это, прежде всего, реализация «шины», набора согласованных измерений и согласованных фактов , которые представляют собой измерения, которые являются общими (определенным образом) между фактами в двух или более витринах данных. [26]
Дизайн сверху вниз [ править ]
Нисходящий подход разработан с использованием нормализованной модели данных предприятия . «Атомарные» данные , то есть данные наибольшего уровня детализации, хранятся в хранилище данных. Из хранилища данных создаются многомерные витрины данных, содержащие данные, необходимые для конкретных бизнес-процессов или конкретных отделов. [27]
дизайн Гибридный
Хранилища данных часто напоминают звездообразную архитектуру . Устаревшие системы, питающие склад, часто включают в себя управление взаимоотношениями с клиентами и планирование ресурсов предприятия , генерируя большие объемы данных. Чтобы объединить эти различные модели данных и облегчить процесс загрузки с извлечением и преобразованием , хранилища данных часто используют хранилище операционных данных , информация из которого анализируется в реальном хранилище данных. Чтобы уменьшить избыточность данных, более крупные системы часто хранят данные в нормализованном виде. Затем на базе хранилища данных можно построить витрины данных для конкретных отчетов.
Гибридная (также называемая ансамблевой) база данных хранилища данных поддерживается в третьей нормальной форме, чтобы исключить избыточность данных . Однако обычная реляционная база данных неэффективна для отчетов бизнес-аналитики, где преобладает многомерное моделирование. Небольшие витрины данных могут приобретать данные из консолидированного хранилища и использовать отфильтрованные конкретные данные для таблиц фактов и необходимых измерений. Хранилище данных предоставляет единый источник информации, из которого могут считываться витрины данных, предоставляя широкий спектр бизнес-информации. Гибридная архитектура позволяет заменить хранилище данных хранилищем управления основными данными , в котором может храниться оперативная (не статическая) информация.
Компоненты моделирования хранилища данных соответствуют архитектуре концентратора и периферийных устройств. Этот стиль моделирования представляет собой гибридную схему, состоящую из лучших практик как третьей нормальной формы, так и звездообразной схемы . Модель хранилища данных не является настоящей третьей нормальной формой и нарушает некоторые из ее правил, но это нисходящая архитектура с восходящим дизайном. Модель хранилища данных предназначена исключительно для хранения данных. Он не предназначен для доступа к конечному пользователю, что при его создании по-прежнему требует использования витрины данных или области выпуска на основе звездообразной схемы для бизнес-целей.
Характеристики [ править ]
Существуют базовые функции, которые определяют данные в хранилище данных, включая предметную ориентацию, интеграцию данных, изменяющиеся во времени, энергонезависимые данные и степень детализации данных.
Предметно-ориентированный [ править ]
В отличие от операционных систем, данные в хранилище данных вращаются вокруг субъектов предприятия. Предметная ориентация – это не нормализация баз данных . Предметная ориентация может быть очень полезна для принятия решений.Сбор необходимых объектов называется предметно-ориентированным.
Интегрированный [ править ]
Данные, найденные в хранилище данных, интегрируются. Поскольку он исходит из нескольких операционных систем, все несоответствия необходимо устранить. Согласованность включает соглашения об именах, измерение переменных, структуры кодирования, физические атрибуты данных и т. д.
Временной вариант [ править ]
В то время как операционные системы отражают текущие значения, поскольку они поддерживают повседневные операции, данные хранилища данных представляют собой длительный временной горизонт (до 10 лет), что означает, что они хранят в основном исторические данные. В основном он предназначен для интеллектуального анализа данных и прогнозирования. (Например, если пользователь ищет структуру покупок конкретного клиента, ему необходимо просмотреть данные о текущих и прошлых покупках.) [28]
Энергонезависимый [ править ]
Данные в хранилище данных доступны только для чтения, что означает, что их нельзя обновлять, создавать или удалять (если это не предусмотрено нормативными или законодательными обязательствами). [29]
Опции [ править ]
Агрегация [ править ]
В процессе хранилища данных данные могут быть агрегированы в витринах данных на разных уровнях абстракции. Пользователь может начать просматривать общее количество продаж продукта во всем регионе. Затем пользователь просматривает штаты в этом регионе. Наконец, они могут проверить отдельные магазины в определенном состоянии. Поэтому, как правило, анализ начинается на более высоком уровне и переходит к более низким уровням детализации. [28]
Виртуализация [ править ]
Благодаря виртуализации данных используемые данные остаются в исходных местах, и устанавливается доступ в режиме реального времени, что позволяет проводить аналитику из нескольких источников, создавая виртуальное хранилище данных. Это может помочь решить некоторые технические трудности, такие как проблемы совместимости при объединении данных с разных платформ, снизить риск ошибок, вызванных ошибочными данными, и гарантировать использование новейших данных. Кроме того, отказ от создания новой базы данных, содержащей личную информацию, может облегчить соблюдение правил конфиденциальности. Однако при виртуализации данных подключение ко всем необходимым источникам данных должно быть работоспособным, поскольку локальная копия данных отсутствует, что является одним из основных недостатков подхода. [30]
Архитектура [ править ]
Существует множество различных методов, используемых для создания/организации хранилища данных, указанного организацией. Используемое аппаратное обеспечение, созданное программное обеспечение и ресурсы данных, специально необходимые для правильной работы хранилища данных, являются основными компонентами архитектуры хранилища данных. Все хранилища данных проходят несколько этапов, на которых требования организации изменяются и уточняются. [31]
Сравнение с операционной системой [ править ]
Операционные системы оптимизированы для сохранения целостности данных и скорости записи бизнес-транзакций за счет использования нормализации базы данных и модели «сущность-связь» . Разработчики операционных систем обычно следуют Кодда, 12 правилам нормализации базы данных чтобы гарантировать целостность данных. Полностью нормализованные конструкции баз данных (то есть удовлетворяющие всем правилам Кодда) часто приводят к тому, что информация о бизнес-транзакциях сохраняется в десятках или сотнях таблиц. Реляционные базы данных эффективно управляют связями между этими таблицами. Базы данных имеют очень высокую производительность вставки/обновления, поскольку при каждой обработке транзакции затрагивается лишь небольшой объем данных в этих таблицах. Для повышения производительности старые данные обычно периодически удаляются из операционных систем.
Хранилища данных оптимизированы для аналитических шаблонов доступа. Шаблоны аналитического доступа обычно включают выбор определенных полей и редко, если вообще когда-либо, select *, который выбирает все поля/столбцы, как это чаще встречается в операционных базах данных. Из-за этих различий в шаблонах доступа операционные базы данных (грубо говоря, OLTP) выигрывают от использования СУБД, ориентированной на строки, тогда как аналитические базы данных (грубо говоря, OLAP) выигрывают от использования СУБД, ориентированной на столбцы . В отличие от операционных систем, которые поддерживают моментальный снимок бизнеса, хранилища данных обычно поддерживают бесконечную историю, которая реализуется посредством процессов ETL, которые периодически переносят данные из операционных систем в хранилище данных.
Эволюция в использовании организации [ править ]
Эти термины относятся к уровню сложности хранилища данных:
- Офлайн-хранилище оперативных данных
- Хранилища данных на этом этапе развития обновляются на регулярной основе (обычно ежедневно, еженедельно или ежемесячно) из операционных систем, и данные хранятся в интегрированной базе данных, ориентированной на отчетность.
- Офлайн-хранилище данных
- Хранилища данных на этом этапе регулярно обновляются на основе данных в операционных системах, а данные хранилища данных хранятся в структуре данных, предназначенной для облегчения отчетности.
- Своевременное хранилище данных
- Интегрированное онлайн-хранилище данных представляет собой хранилище данных в режиме реального времени. Данные на этапе хранилища обновляются для каждой транзакции, выполняемой с исходными данными.
- Интегрированное хранилище данных
- Эти хранилища данных собирают данные из разных областей бизнеса, поэтому пользователи могут искать нужную им информацию в других системах. [32]
См. также [ править ]
- Список программного обеспечения для бизнес-аналитики
- Озеро данных — система или хранилище данных, хранящихся в естественном/необработанном формате.
- Сетка данных – среда распределенной архитектуры для управления данными.
Ссылки [ править ]
- ^ Дедич, Недим; Станье, Клэр (2016). Хаммуди, Слиман; Мацяшек, Лешек; Миссикофф, Мишель М. Миссикофф; Кэмп, Оливье; Кордейро, Хосе (ред.). Оценка проблем многоязычия при разработке хранилищ данных . Международная конференция по корпоративным информационным системам, 25–28 апреля 2016 г., Рим, Италия (PDF) . Материалы 18-й Международной конференции по информационным системам предприятия (ICEIS 2016) . Том. 1. СайТеПресс. стр. 196–206. дои : 10.5220/0005858401960206 . ISBN 978-989-758-187-8 . Архивировано (PDF) из оригинала 22 мая 2018 г.
- ^ «Что такое хранилище данных? | Ключевые понятия | Веб-сервисы Amazon» . Amazon Веб-сервисы, Inc. Проверено 13 февраля 2023 г.
- ^ Патил, Прити С.; Шриканта Рао; Сурьякант Б. Патил (2011). «Оптимизация системы хранения данных: упрощение отчетности и анализа» . Материалы IJCA Международной конференции и семинара по новым тенденциям в технологиях (ICWET) . 9 (6). Фонд компьютерных наук: 33–37.
- ^ Маракас и О'Брайен, 2009 г.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Райнер, Р. Келли; Цегельски, Кейси Г. (1 мая 2012 г.). Введение в информационные системы: обеспечение и преобразование бизнеса, 4-е издание (изд. Kindle). Уайли. стр. 127 , 128, 130, 131, 133. ISBN. 978-1118129401 .
- ^ «Концепции витрины данных» . Оракул. 2007.
- ^ «OLTP против OLAP» . Datawarehouse4u.Info . 2009.
ИТ-системы можно разделить на транзакционные (OLTP) и аналитические (OLAP). В целом можно предположить, что OLTP-системы предоставляют исходные данные в хранилища данных, тогда как OLAP-системы помогают их анализировать.
- ^ «История до сих пор» . 15 апреля 2002 г. Архивировано из оригинала 8 июля 2008 г. Проверено 21 сентября 2008 г.
- ↑ Перейти обратно: Перейти обратно: а б Кимбалл 2013, стр. 15
- ^ «Аудит структуры хранилища данных» (PDF) . Архивировано (PDF) из оригинала 12 мая 2012 г.
- ^ Кемпе, Шеннон (23 августа 2012 г.). «Краткая история хранилищ данных» . ДАННЫЕ . Проверено 10 мая 2024 г.
- ^ «Хранилище данных: что это такое и почему это важно» . www.sas.com . Проверено 10 мая 2024 г.
- ^ Пол Гиллин (20 февраля 1984 г.). «Сможет ли Teradata возродить рынок?» . Компьютерный мир . стр. 43, 48 . Проверено 13 марта 2017 г.
- ^ Девлин, бакалавр; Мерфи, ПТ (1988). «Архитектура бизнеса и информационной системы». Системный журнал IBM . 27 : 60–80. дои : 10.1147/sj.271.0060 .
- ^ Инмон, Билл (1992). Создание хранилища данных . Уайли. ISBN 0-471-56960-7 .
- ↑ Перейти обратно: Перейти обратно: а б Кимбалл, Ральф (2011). Инструментарий хранилища данных . Уайли. п. 237. ИСБН 978-0-470-14977-5 .
- ^ Введение в фокусную структуру
- ^ Встреча по моделированию данных в Мюнхене: введение в Focal с Патриком Лагером - YouTube
- ^ Регардт, Олле; Рённбек, Ларс; Берггольц, Мария; Йоханнессон, Пол; Вохед, Петия (2009). «Якорное моделирование». Материалы 28-й Международной конференции по концептуальному моделированию . скорая помощь '09. Грамаду, Бразилия: Springer-Verlag: 234–250. ISBN 978-3-642-04839-5 .
- ^ Краткое введение в #datavault 2.0.
- ^ Анонс Data Vault 2.0
- ^ Гольфарелли, Маттео; Майо, Дарио; Рицци, Стефано (1 июня 1998 г.). «Многомерная модель фактов: концептуальная модель хранилищ данных» . Международный журнал совместных информационных систем . 07 (2н03): 215–247. дои : 10.1142/S0218843098000118 . ISSN 0218-8430 .
- ^ «Введение в кубы данных» .
- ^ Хиллард, Роберт (2010). Информационный бизнес . Уайли. ISBN 978-0-470-62577-4 .
- ^ «Теория информации и стратегия бизнес-аналитики — Мера преобразования данных в маленьких мирах — MIKE2.0, методология с открытым исходным кодом для разработки информации» . Mike2.openmethodology.org . Проверено 14 июня 2013 г.
- ^ «Неправильное название «снизу вверх» — DecisionWorks Consulting» . Консалтинг DecisionWorks . 17 сентября 2003 года . Проверено 06 марта 2016 г.
- ^ Gartner, О хранилищах данных, хранилищах операционных данных, витринах данных и туалетах данных, декабрь 2005 г.
- ↑ Перейти обратно: Перейти обратно: а б Паульрадж., Понния (2010). Основы хранения данных для ИТ-специалистов . Понния, Паульраж. (2-е изд.). Хобокен, Нью-Джерси: John Wiley & Sons. ISBN 9780470462072 . OCLC 662453070 .
- ^ Инмон, Уильям Х. (2005). Построение хранилища данных (4-е изд.). Индианаполис, Индиана: Паб Wiley. ISBN 9780764599446 . OCLC 61762085 .
- ^ Пайхо, Сказка; Туоминен, Пекка; Рёкман, Юри; Юликераля, Маркус; Паюла, Юха; Сиикавирта, Ханне (2022). «Возможности собранных городских данных для умных городов» . ИЭПП «Умные города» . 4 (4): 275–291. дои : 10.1049/smc2.12044 . S2CID 253467923 .
- ^ Гупта, Сатиндер Бал; Миттал, Адитья (2009). Введение в систему управления базами данных . Публикации Лакшми. ISBN 9788131807248 .
- ^ «Хранилище данных» . 6 апреля 2019 г.
Дальнейшее чтение [ править ]
- Давенпорт, Томас Х. и Харрис, Джин Г. Конкуренция в аналитике: новая наука о победе (2007) Издательство Гарвардской школы бизнеса. ISBN 978-1-4221-0332-6
- Ганчарски, Джо. Реализации хранилищ данных: исследование критических факторов реализации (2009) VDM Verlag ISBN 3-639-18589-7 ISBN 978-3-639-18589-8
- Кимбалл, Ральф и Росс, Марджи. Набор инструментов для хранилищ данных, третье издание (2013 г.), Wiley, ISBN 978-1-118-53080-1
- Линстедт, Грациано, Хультгрен. Бизнес моделирования хранилищ данных, второе издание (2010 г.) Дэн Линстедт, ISBN 978-1-4357-1914-9
- Уильям Инмон. Создание хранилища данных (2005) Джон Уайли и сыновья, ISBN 978-81-265-0645-3
| Базы данных органов управления : Национальные |
|---|