Исправление ошибок Рида – Соломона
| Коды Рида – Соломона | |
|---|---|
| Назван в честь | Ирвинг С. Рид и Гюстав Соломон |
| Классификация | |
| Иерархия | Линейный блочный код Полиномиальный код Код Рида – Соломона |
| Длина блока | н |
| Длина сообщения | к |
| Расстояние | п - к + 1 |
| Размер алфавита | д = п м ≥ n ( p простое) Часто n = q − 1. |
| Обозначения | [ n , k , n − k + 1] q -код |
| Алгоритмы | |
| Берлекамп-Мэсси евклидов и др. | |
| Характеристики | |
| Разделимый код на максимальное расстояние | |
Коды Рида-Соломона — это группа кодов с исправлением ошибок , которые были представлены Ирвингом С. Ридом и Гюставом Соломоном в 1960 году. [ 1 ] У них есть множество приложений, включая потребительские технологии, такие как MiniDiscs , CD , DVD , Blu-ray диски, QR-коды , Data Matrix , технологии передачи данных , такие как DSL и WiMAX , системы вещания, такие как спутниковая связь, DVB и ATSC , а также системы хранения данных. например RAID 6 .
Коды Рида – Соломона работают с блоком данных, рассматриваемым как набор элементов конечного поля, называемых символами. Коды Рида-Соломона способны обнаруживать и исправлять множественные ошибки символов. Добавляя к данным t = n - k проверочных символов, код Рида-Соломона может обнаруживать (но не исправлять) любую комбинацию до t ошибочных символов или находить и исправлять до ⌊ t /2⌋ ошибочных символов в неизвестных местах. . В качестве кода стирания он может исправлять до стираний в местах, которые известны и предоставлены алгоритму, или может обнаруживать и исправлять комбинации ошибок и стираний. Коды Рида-Соломона также подходят в качестве кодов с множественным пакетным исправлением битовых ошибок, поскольку последовательность из b + 1 последовательных битовых ошибок может повлиять не более чем на два символа размера b . Выбор t остается за разработчиком кода и может выбираться в широких пределах.
Существует два основных типа кодов Рида-Соломона — исходное представление и представление BCH , причем представление BCH является наиболее распространенным, поскольку декодеры представления BCH работают быстрее и требуют меньше рабочей памяти, чем декодеры исходного представления.
История
[ редактировать ]Коды Рида-Соломона были разработаны в 1960 году Ирвингом С. Ридом и Гюставом Соломоном , которые тогда были сотрудниками Лаборатории Линкольна Массачусетского технологического института . Их основополагающая статья называлась «Полиномиальные коды над некоторыми конечными полями». ( Рид и Соломон, 1960 ). В исходной схеме кодирования, описанной в статье Рида и Соломона, использовался переменный полином, основанный на кодируемом сообщении, где кодировщику и декодеру известен только фиксированный набор значений (оценочных точек), подлежащих кодированию. Исходный теоретический декодер генерировал потенциальные полиномы на основе подмножеств k (длина незакодированного сообщения) из n (длина закодированного сообщения) значений полученного сообщения, выбирая наиболее популярный полином в качестве правильного, что было непрактично для всех, кроме самого простого из них. случаи. Первоначально эта проблема была решена путем изменения исходной схемы на схему, подобную коду BCH , основанную на фиксированном полиноме, известном как кодировщику, так и декодеру, но позже были разработаны практические декодеры, основанные на исходной схеме, хотя и более медленные, чем схемы BCH. В результате существует два основных типа кодов Рида-Соломона: те, которые используют исходную схему кодирования, и те, которые используют схему кодирования BCH.
Также в 1960 году практический декодер с фиксированным полиномом для кодов BCH, разработанный Дэниелом Горенштейном и Нилом Цирлером, был описан Цирлером в отчете Лаборатории Линкольна Массачусетского технологического института в январе 1960 года, а затем в статье в июне 1961 года. [ 2 ] Декодер Горенштейна-Цирлера и соответствующая работа над кодами BCH описаны в книге У. Уэсли Петерсона «Коды с исправлением ошибок» (1961). [ 3 ] К 1963 году (или, возможно, раньше) Дж. Дж. Стоун (и другие) осознали, что коды Рида-Соломона могут использовать схему BCH с использованием фиксированного порождающего полинома, что делает такие коды особым классом кодов BCH. [ 4 ] но коды Рида-Соломона, основанные на исходной схеме кодирования, не являются классом кодов БЧХ и в зависимости от набора точек оценки даже не являются циклическими кодами .
В 1969 году улучшенный декодер схемы BCH был разработан Элвином Берлекэмпом и Джеймсом Мэсси и с тех пор известен как алгоритм декодирования Берлекэмпа-Мэсси .
В 1975 году Ясуо Сугияма разработал еще один улучшенный декодер схемы BCH, основанный на расширенном алгоритме Евклида . [ 5 ]
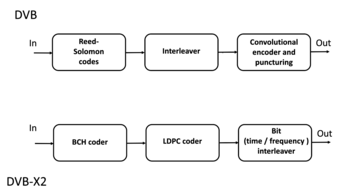
В 1977 году коды Рида–Соломона были реализованы в программе «Вояджер» в виде составных кодов с исправлением ошибок . Первое коммерческое применение в потребительских товарах массового производства появилось в 1982 году с компакт-диском , где два чередующихся используются кода Рида-Соломона. Сегодня коды Рида-Соломона широко применяются в цифровых устройствах хранения данных и стандартах цифровой связи , хотя они постепенно заменяются кодами Бозе-Чаудхури-Хоквенгема (BCH) . Например, коды Рида-Соломона используются в стандарте цифрового видеовещания (DVB) DVB-S в сочетании со сверточным внутренним кодом , но коды BCH используются с LDPC в его преемнике DVB-S2 .
оригинальный декодер схемы, известный как алгоритм Берлекэмпа – Уэлча В 1986 году был разработан .
В 1996 году Мадху Судан и другие разработали варианты декодеров исходной схемы, называемые декодерами списков или мягкими декодерами, и работа над этими типами декодеров продолжается - см. Алгоритм декодирования списков Гурусвами-Судана .
В 2002 году Шухун Гао разработал еще одну оригинальную схему декодера, основанную на расширенном алгоритме Евклида . [ 6 ]
Приложения
[ редактировать ]Хранение данных
[ редактировать ]Кодирование Рида-Соломона очень широко используется в системах хранения данных для исправления ошибок. пакетные ошибки, связанные с дефектами носителя.
Кодирование Рида-Соломона является ключевым компонентом компакт-диска . Это было первое использование кодирования с сильным исправлением ошибок в массовом потребительском продукте, а DAT и DVD используют аналогичные схемы. В CD два уровня кодирования Рида-Соломона, разделенные 28-канальным сверточным перемежителем, дают схему, называемую перекрестно-перемежающимся кодированием Рида-Соломона ( CIRC ). Первый элемент CIRC-декодера представляет собой относительно слабый внутренний (32,28) код Рида – Соломона, сокращенный из кода (255,251) с 8-битными символами. Этот код может исправить до 2 байтовых ошибок на 32-байтовый блок. Что еще более важно, он помечает как стирающие любые неисправимые блоки, т. е. блоки с ошибками более 2 байтов. Декодированные 28-байтовые блоки с индикацией стирания затем распределяются обращенным перемежителем по различным блокам внешнего кода (28,24). Благодаря обращенному перемежению стертый 28-байтовый блок внутреннего кода становится одним стертым байтом в каждом из 28 блоков внешнего кода. Внешний код легко это исправляет, поскольку он может обрабатывать до 4 таких стираний на блок.
Результатом является CIRC, который может полностью корректировать пакеты ошибок размером до 4000 бит, или около 2,5 мм на поверхности диска. Этот код настолько силен, что большинство ошибок воспроизведения компакт-диска почти наверняка вызваны ошибками отслеживания, которые заставляют лазер смещаться с траектории, а не неисправимыми пакетами ошибок. [ 7 ]
В DVD используется аналогичная схема, но с гораздо более крупными блоками, внутренним кодом (208 192) и внешним кодом (182 172).
Исправление ошибок Рида-Соломона также используется в архивных файлах, которые обычно публикуются вместе с мультимедийными файлами в USENET . Служба распределенного онлайн-хранилища Wuala (прекращена в 2015 году) также использовала Рида-Соломона при разбиении файлов.
Штрих-код
[ редактировать ]Почти все двумерные штрих-коды, такие как PDF-417 , MaxiCode , Datamatrix , QR Code и Aztec Code , используют коррекцию ошибок Рида-Соломона, чтобы обеспечить правильное считывание, даже если часть штрих-кода повреждена. Если сканер штрих-кода не может распознать символ штрих-кода, он воспримет это как стирание.
Кодирование Рида-Соломона менее распространено в одномерных штрих-кодах, но используется в символике PostBar .
Передача данных
[ редактировать ]Специализированные формы кодов Рида-Соломона, в частности Коши -RS и Вандермонда -RS, могут использоваться для преодоления ненадежного характера передачи данных по каналам стирания . Процесс кодирования предполагает использование кода RS( N , K ), в результате чего получается N кодовых слов длиной N символов, каждое из которых хранит K символов генерируемых данных, которые затем отправляются по каналу стирания.
Любая комбинация K кодовых слов, полученная на другом конце, достаточна для восстановления всех N кодовых слов. Скорость кода обычно устанавливается равной 1/2, если только вероятность стирания канала не может быть адекватно смоделирована и не считается меньшей. В заключение, N обычно равно 2 K , что означает, что по крайней мере половина всех отправленных кодовых слов должна быть получена, чтобы восстановить все отправленные кодовые слова.
Коды Рида-Соломона также используются в xDSL системах CCSDS и спецификациях протокола космической связи в качестве формы прямого исправления ошибок .
Космическая передача
[ редактировать ]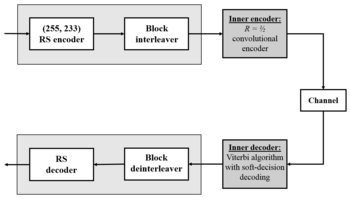
Одним из важных применений кодирования Рида-Соломона было кодирование цифровых изображений, отправленных программой «Вояджер» .
«Вояджер» представил кодирование Рида-Соломона, объединенное со сверточными кодами , практику, которая с тех пор получила очень широкое распространение в дальнем космосе и спутниковой связи (например, прямое цифровое вещание).
Декодеры Витерби имеют тенденцию выдавать ошибки короткими пакетами. Исправление этих пакетов ошибок лучше всего выполнять с помощью коротких или упрощенных кодов Рида – Соломона.
Современные версии конкатенированного сверточного кодирования, декодированного Ридом-Соломоном/Витерби, использовались и используются в миссиях Mars Pathfinder , Galileo , Mars Exploration Rover и Cassini , где они работают в пределах примерно 1–1,5 дБ от предельного предела, пропускной способности Шеннона .
Эти объединенные коды теперь заменяются более мощными турбокодами :
| Годы | Код | Миссия(и) |
|---|---|---|
| 1958 – настоящее время | Некодированный | Исследователь, Моряк и многие другие. |
| 1968–1978 | сверточные коды (СС) (25, 1/2) | Пионер, Венера |
| 1969–1975 | Код Рида-Мюллера (32, 6) | Моряк, Викинг |
| 1977 – настоящее время | Двоичный код Голея | Вояджер |
| 1977 – настоящее время | РС(255, 223) + СС(7, 1/2) | Вояджер, Галилей и многие другие. |
| 1989–2003 | РС(255, 223) + СС(7, 1/3) | Вояджер |
| 1989–2003 | РС(255, 223) + СС(14, 1/4) | Галилео |
| 1996 – настоящее время | РС + СС (15, 1/6) | «Кассини», «Марсианский следопыт» и другие. |
| 2004 – настоящее время | Турбо коды [ номер 1 ] | Messenger, стерео, MRO и другие |
| Восток. 2009 год | Коды LDPC | Созвездие, MSL |
Конструкции (кодирование)
[ редактировать ]Код Рида-Соломона на самом деле представляет собой семейство кодов, где каждый код характеризуется тремя параметрами: алфавита. размером , длина блока и длина сообщения , с . Набор символов алфавита интерпретируется как конечное поле порядка , и, таким образом, должна быть высшая сила . В наиболее полезных параметризациях кода Рида-Соломона длина блока обычно равна некоторому постоянному кратному длине сообщения, то есть скорости — некоторая константа, причем длина блока равна или меньше размера алфавита, то есть или . [ нужна ссылка ]








Оригинальная точка зрения Рида и Соломона: кодовое слово как последовательность значений
[ редактировать ]Существуют разные процедуры кодирования кода Рида-Соломона и, следовательно, существуют разные способы описания набора всех кодовых слов. Согласно первоначальной точке зрения Рида и Соломона (1960) , каждое кодовое слово кода Рида – Соломона представляет собой последовательность функциональных значений полинома степени меньше . Чтобы получить кодовое слово кода Рида – Соломона, символы сообщения (каждый в алфавите размера q) рассматриваются как коэффициенты полинома. степени меньше k над конечным полем с элементы. В свою очередь, полином p оценивается в n ≤ q различных точках. поля F , а последовательность значений представляет собой соответствующее кодовое слово. Обычный выбор набора точек оценки включает {0, 1, 2, ..., n - 1}, {0, 1, α , α. 2 , ..., а п -2 }, или для n < q , {1, α , α 2 , ..., а п -1 }, ... , где α — элемент F примитивный .


Формально набор кодовых слов кода Рида–Соломона определяется следующим образом: Поскольку любые два различных многочлена степени меньше согласен максимум точек, это означает, что любые два кодовых слова кода Рида–Соломона не совпадают по крайней мере по позиции. Более того, есть два полинома, которые согласуются в точки, но не равны, и, таким образом, расстояние кода Рида – Соломона точно равно . Тогда относительное расстояние , где это ставка. Этот компромисс между относительным расстоянием и скоростью является асимптотически оптимальным, поскольку по границе Синглтона каждый код удовлетворяет условию . Будучи кодом, который обеспечивает этот оптимальный компромисс, код Рида – Соломона принадлежит к классу кодов, разделяемых на максимальное расстояние .








В то время как количество различных полиномов степени меньше k и количество различных сообщений равны , и, таким образом, каждое сообщение может быть однозначно сопоставлено такому полиному, существуют разные способы такого кодирования. Исходная конструкция Рида и Соломона (1960) интерпретирует сообщение x как коэффициенты полинома p , тогда как последующие конструкции интерпретируют сообщение как значения полинома в первых k точках. и получить полином p путем интерполяции этих значений полиномом степени меньше k . Последняя процедура кодирования, хотя и немного менее эффективна, имеет то преимущество, что она приводит к систематическому коду , то есть исходное сообщение всегда содержится как подпоследовательность кодового слова.


Простая процедура кодирования: сообщение как последовательность коэффициентов.
[ редактировать ]В оригинальной конструкции Рида и Соломона (1960) сообщение отображается в полином с Кодовое слово получается путем оценки в разные точки поля . Таким образом, классическая функция кодирования для кода Рида–Соломона определяется следующим образом: Эта функция является линейным отображением , т. е. оно удовлетворяет условию для следующих -матрица с элементами из :












Эта матрица является матрицей Вандермонда над . Другими словами, код Рида–Соломона является линейным кодом , и в классической процедуре кодирования его порождающая матрица равна .
Процедура систематического кодирования: сообщение как исходная последовательность значений.
[ редактировать ]Существует альтернативная процедура кодирования, которая создает систематический код Рида – Соломона. Здесь мы используем другой полином . В этом варианте полином определяется как единственный многочлен степени меньше такой, что Чтобы вычислить этот полином от , можно использовать интерполяцию Лагранжа . Как только он найден, он оценивается в других точках. .


Этот вариант является систематическим с момента первого записи, , точно по определению .


Дискретное преобразование Фурье и обратное ему
[ редактировать ]Дискретное преобразование Фурье по существу совпадает с процедурой кодирования; он использует полином генератора чтобы сопоставить набор точек оценки со значениями сообщения, как показано выше:
Обратное преобразование Фурье можно использовать для преобразования безошибочного набора значений сообщения n < q обратно в полином кодирования из k коэффициентов с тем ограничением, что для того, чтобы это работало, набор точек оценки, используемых для кодирования сообщения, должен быть набором возрастающих степеней α :


Однако интерполяция Лагранжа выполняет то же преобразование без ограничения на набор точек оценки или требования безошибочного набора значений сообщения и используется для систематического кодирования, а также на одном из этапов декодера Гао .
Взгляд BCH: кодовое слово как последовательность коэффициентов
[ редактировать ]С этой точки зрения сообщение интерпретируется как коэффициенты полинома . Отправитель вычисляет связанный полином степени где и отправляет полином . Полином строится путем умножения полинома сообщения , имеющий степень , с генераторным полиномом степени это известно как отправителю, так и получателю. Генераторный полином определяется как многочлен, корни которого являются последовательными степенями примитива поля Галуа








Для «узкого кода» .


Процедура систематического кодирования
[ редактировать ]Процедура кодирования для представления BCH кодов Рида-Соломона может быть изменена, чтобы получить процедуру систематического кодирования , в которой каждое кодовое слово содержит сообщение в качестве префикса и просто добавляет символы исправления ошибок в качестве суффикса. Здесь вместо отправки , кодер строит переданный полином такие, что коэффициенты наибольшие мономы равны соответствующим коэффициентам при , а младшие коэффициенты выбираются именно таким образом, чтобы становится делимым на . Тогда коэффициенты являются подпоследовательностью коэффициентов . Чтобы получить в целом систематический код, мы строим полином сообщения интерпретируя сообщение как последовательность его коэффициентов.

Формально построение осуществляется умножением к чтобы освободить место для проверьте символы, разделив это произведение на найти остаток, а затем компенсировать этот остаток путем его вычитания. проверочные символы создаются путем вычисления остатка :





Остаток имеет степень не более , тогда как коэффициенты в полиноме равны нулю. Поэтому следующее определение кодового слова обладает тем свойством, что первый коэффициенты идентичны коэффициентам :




В результате кодовые слова действительно являются элементами , то есть делятся на образующий полином : [ 10 ]

Характеристики
[ редактировать ]Код Рида – Соломона представляет собой код [ n , k , n − k + 1]; другими словами, это линейный блочный код длины n (над F ) с размерностью k и минимальным расстоянием Хэмминга. Код Рида-Соломона оптимален в том смысле, что минимальное расстояние имеет максимально возможное значение для линейного кода размера ( n , k ); это известно как граница Синглтона . Такой код также называется кодом, разделяемым на максимальное расстояние (MDS) .

Способность кода Рида-Соломона исправлять ошибки определяется его минимальным расстоянием или, что то же самое, , мера избыточности в блоке. Если расположение символов ошибок заранее неизвестно, то код Рида–Соломона может исправить до ошибочных символов, т. е. он может исправить вдвое меньше ошибок, чем добавлено в блок избыточных символов. Иногда места ошибок известны заранее (например, «дополнительная информация» в демодулятора отношении сигнал/шум ) — это называется стиранием . Код Рида-Соломона (как и любой MDS-код ) способен исправить в два раза больше стираний, чем ошибок, и любая комбинация ошибок и стираний может быть исправлена, если соотношение 2 E + S ≤ n − k , где выполняется количество ошибок и — количество стираний в блоке.




Теоретическая граница погрешности может быть описана с помощью следующей формулы для канала AWGN для FSK : [ 11 ] и для других схем модуляции: где , , , - частота ошибок символа в случае некодированного AWGN и это порядок модуляции.







Для практического использования кодов Рида – Соломона обычно используют конечное поле. с элементы. В этом случае каждый символ можно представить в виде -битовое значение. Отправитель отправляет точки данных в виде закодированных блоков, а количество символов в закодированном блоке равно . Таким образом, код Рида-Соломона, работающий с 8-битными символами, имеет символов в блоке. (Это очень популярное значение из-за распространенности байт-ориентированных компьютерных систем.) Число , с , символов данных в блоке является параметром конструкции. Часто используемый код кодирует восьмибитные символы данных плюс 32 восьмибитных символа четности в -символьный блок; это обозначается как код и способен исправлять до 16 ошибок символов на блок.







Обсуждаемые выше свойства кода Рида-Соломона делают его особенно подходящим для приложений, в которых ошибки возникают пакетно . Это связано с тем, что для кода не имеет значения, сколько бит в символе содержит ошибку — если несколько битов в символе повреждены, это считается только одной ошибкой. И наоборот, если поток данных характеризуется не пакетами ошибок или пропусками, а случайными однобитовыми ошибками, код Рида-Соломона обычно является плохим выбором по сравнению с двоичным кодом.
Код Рида-Соломона, как и сверточный код , является прозрачным кодом. Это означает, что если где-то в строке символы канала были инвертированы , декодеры все равно будут работать. Результатом будет инверсия исходных данных. Однако код Рида-Соломона теряет прозрачность при его сокращении. «Недостающие» биты в сокращенном коде необходимо заполнить нулями или единицами, в зависимости от того, дополняются данные или нет. (Иными словами, если символы инвертированы, то нулевое заполнение необходимо инвертировать в однозаполнение.) По этой причине обязательно, чтобы смысл данных (т. е. истинный или дополняемый) был определен. до декодирования Рида – Соломона.
Является ли код Рида-Соломона циклическим или нет, зависит от тонких деталей конструкции. В исходной точке зрения Рида и Соломона, где кодовые слова являются значениями многочлена, можно выбрать последовательность точек оценки таким образом, чтобы сделать код циклическим. В частности, если является примитивным корнем поля , то по определению все ненулевые элементы принять форму для , где . Каждый полином над дает начало кодовому слову . Поскольку функция также является многочленом той же степени, эта функция порождает кодовое слово ; с выполняется, то это кодовое слово представляет собой циклический сдвиг влево исходного кодового слова, полученного из . Таким образом, выбор последовательности примитивных корневых степеней в качестве точек оценки делает исходный код Рида-Соломона циклическим . Коды Рида-Соломона в представлении BCH всегда цикличны, поскольку коды BCH являются циклическими .







Примечания
[ редактировать ]От дизайнеров не требуется использовать «естественные» размеры блоков кода Рида – Соломона. Метод, известный как «сокращение», позволяет создать меньший код любого желаемого размера из большего кода. Например, широко используемый код (255,223) можно преобразовать в код (160,128), дополнив неиспользуемую часть исходного блока 95 двоичными нулями и не передавая их. В декодере та же часть блока локально загружается двоичными нулями. Дельсарт-Гетальс-Зейдель [ 12 ] Теорема иллюстрирует пример применения сокращенных кодов Рида – Соломона. Параллельно с сокращением метод, известный как выкалывание, позволяет опустить некоторые закодированные символы четности.
Декодеры представления BCH
[ редактировать ]Декодеры, описанные в этом разделе, используют представление кодового слова BCH как последовательность коэффициентов. Они используют фиксированный полином генератора, известный как кодировщику, так и декодеру.
Декодер Петерсона – Горенштейна – Цирлера
[ редактировать ]Дэниел Горенштейн и Нил Зирлер разработали декодер, который был описан Цирлером в отчете Лаборатории Линкольна Массачусетского технологического института в январе 1960 года, а затем в статье в июне 1961 года. [ 13 ] Декодер Горенштейна-Цирлера и соответствующая работа над кодами BCH описаны в книге Коды с исправлением ошибок» « У. Уэсли Петерсона (1961). [ 14 ]
Формулировка
[ редактировать ]Переданное сообщение, , рассматривается как коэффициенты многочлена s ( x ):


В результате процедуры кодирования Рида-Соломона s ( x ) делится на порождающий полином g ( x ): где α — примитивный элемент.

Поскольку s ( x ) кратно генератору g ( x ), отсюда следует, что он «наследует» все свои корни. Поэтому,


Переданный полином искажается при передаче полиномом ошибки e ( x ) для получения полученного полинома r ( x ).


Коэффициент e i нет ошибки будет нулевым, если в этой степени x , и ненулевым, если ошибка есть. Если имеется ν ошибок в различных степенях i k числа x , то

Цель декодера — найти количество ошибок ( ν , положения ошибок ( ik ) и значения ошибок в этих позициях ( ei ) k ). Из них e ( x можно вычислить ) и вычесть из r ( x ), чтобы получить первоначально отправленное сообщение s ( x ).
Расшифровка синдрома
[ редактировать ]Декодер начинает с оценки полинома, полученного в точках . Мы называем результаты этой оценки «синдромами» Sj . , Они определяются как: Обратите внимание, что потому что имеет корни в , как показано в предыдущем разделе.




Преимущество рассмотрения синдромов состоит в том, что полином сообщения выпадает. Другими словами, синдромы относятся только к ошибке и не зависят от фактического содержания передаваемого сообщения. Если все синдромы равны нулю, алгоритм останавливается на этом этапе и сообщает, что сообщение не было повреждено при передаче.
Локаторы ошибок и значения ошибок
[ редактировать ]Для удобства определите локаторы ошибок X k и значения ошибок Y k как:

Тогда синдромы можно записать в терминах этих локаторов ошибок и значений ошибок как

Данное определение значений синдрома эквивалентно предыдущему, поскольку .

Синдромы дают систему n − k ≥ 2 ν уравнений с 2 ν неизвестными, но эта система уравнений нелинейна относительно X k и не имеет очевидного решения. Однако если бы X k были известны (см. ниже), то уравнения синдрома представляют собой линейную систему уравнений, которую можно легко решить для значений ошибок Y k .

Следовательно, проблема заключается в нахождении X k , поскольку тогда будет известна самая левая матрица, и обе части уравнения можно будет умножить на обратное, что даст Y k
В том варианте этого алгоритма, где места ошибок уже известны (когда он используется в качестве кода стирания ), это конец. Места ошибок ( X k ) уже известны каким-либо другим методом (например, в FM-передаче участки, где битовый поток был нечетким или претерпел помехи, вероятностно определяются из частотного анализа). В этом сценарии до ошибки можно исправить.
Остальная часть алгоритма служит для поиска ошибок и потребует значений синдрома до , а не просто использовал до сих пор. Вот почему необходимо добавить в два раза больше символов исправления ошибок, чем можно исправить, не зная их местоположения.


Полином локатора ошибок
[ редактировать ]Существует линейное рекуррентное соотношение, которое порождает систему линейных уравнений. Решение этих уравнений идентифицирует места ошибок X k .
Определите полином локатора ошибок Λ( x ) как

Нули Λ( x ) являются обратными величинами . Это следует из приведенной выше конструкции обозначения произведения, поскольку если тогда одно из умноженных членов будет равно нулю , в результате чего весь полином будет равен нулю.




Позволять быть любым целым числом таким, что . Умножьте обе части на и оно все равно будет равно нулю.



![{\displaystyle {\begin{aligned}&Y_{k}X_{k}^{j+\nu }\Lambda (X_{k}^{-1})=0.\\[1ex]&Y_{k}X_{ k}^{j+\nu }\left(1+\Lambda _{1}X_{k}^{-1}+\Lambda _{2}X_{k}^{-2}+\cdots +\Lambda _{\nu }X_{k}^{-\nu }\right)=0.\\[1ex]&Y_{k}X_{k}^{j+\nu }+\Lambda _{1}Y_{k }X_{k}^{j+\nu }X_{k}^{-1}+\Lambda _{2}Y_{k}X_{k}^{j+\nu }X_{k}^{-2} +\cdots +\Lambda _{\nu }Y_{k}X_{k}^{j+\nu }X_{k}^{-\nu }=0.\\[1ex]&Y_{k}X_{k }^{j+\nu }+\Lambda _{1}Y_{k}X_{k}^{j+\nu -1}+\Lambda _{2}Y_{k}X_{k}^{j+\nu -2}+\cdots +\Lambda _{\nu }Y_{k}X_{k}^{j}=0.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6573fa0f429ac4349f5da794df9c4fb7831e8cbf)
Суммируйте от k = 1 до ν , и она все равно будет равна нулю.

Соберите каждое слагаемое в свою сумму.

Извлеките постоянные значения на которые не влияет суммирование.


Эти суммы теперь эквивалентны значениям синдромов, которые мы знаем и можем подставить! Таким образом, это сводится к

Вычитание с обеих сторон дает


Напомним, что j было выбрано в качестве любого целого числа от 1 до v включительно, и эта эквивалентность верна для любых и всех таких значений. Следовательно, у нас есть v линейных уравнений, а не одно. Таким образом, эту систему линейных уравнений можно решить для коэффициентов Λ i полинома местоположения ошибки: Вышеупомянутое предполагает, что декодер знает количество ошибок ν , но это число еще не определено. Декодер PGZ не определяет ν напрямую, а скорее ищет его, пробуя последовательные значения. Декодер сначала принимает наибольшее значение пробного ν и настраивает линейную систему для этого значения. Если уравнения можно решить (т. е. определитель матрицы не равен нулю), то пробное значение представляет собой количество ошибок. Если линейную систему решить невозможно, то испытание ν сокращается на единицу и исследуется следующая меньшая система. ( Гилл н.д. , стр. 35)

Найдите корни полинома локатора ошибок
[ редактировать ]Используйте коэффициенты Λ i, найденные на последнем шаге, чтобы построить полином местоположения ошибки. Корни полинома местоположения ошибки можно найти путем перебора. Локаторы ошибок X k являются обратными этим корням. Порядок коэффициентов полинома местоположения ошибки может быть изменен на обратный, и в этом случае корни этого обращенного полинома являются локаторами ошибок. (не их обратные стороны ). Поиск Чиена является эффективной реализацией этого шага.

Рассчитать значения ошибок
[ редактировать ]Как только локаторы ошибок X k известны, можно определить значения ошибок. Это можно сделать путем прямого решения Y k в приведенной выше матрице уравнений ошибок или с помощью алгоритма Форни .
Рассчитать места ошибок
[ редактировать ]Рассчитайте i k, взяв логарифмическую базу X k . Обычно это делается с использованием предварительно вычисленной справочной таблицы.
Исправьте ошибки
[ редактировать ]Наконец, e ( x ) генерируется из i k и e i k , а затем вычитается из r ( x ), чтобы получить первоначально отправленное сообщение s ( x ) с исправленными ошибками.
Пример
[ редактировать ]Рассмотрим код Рида-Соломона, определенный в GF (929) с α = 3 и t = 4 (он используется в штрих-кодах PDF417 ) для кода RS(7,3). Полином генератора Если полином сообщения равен p ( x ) = 3 x 2 + 2 x + 1 , то систематическое кодовое слово кодируется следующим образом. Ошибки при передаче могут привести к тому, что это сообщение будет получено вместо этого. Синдромы рассчитываются путем оценки r в степенях α .







Использование исключения Гаусса :

Коэффициенты можно поменять местами, чтобы получить корни с положительными показателями, но обычно это не используется:
с журналом корней, соответствующих местам ошибок (справа налево, местоположение 0 — последний член кодового слова).
Для расчета значений ошибок применим алгоритм Форни .
Вычитание из полученного полинома r ( x ) воспроизводит исходное кодовое слово s .

Декодер Берлекэмпа – Мэсси
[ редактировать ]Алгоритм Берлекэмпа – Мэсси представляет собой альтернативную итерационную процедуру поиска полинома локатора ошибок. Во время каждой итерации он вычисляет несоответствие на основе текущего экземпляра Λ( x ) с предполагаемым количеством ошибок e : а затем корректирует Λ( x ) и e так, чтобы пересчитанная Δ была равна нулю. В статье «Алгоритм Берлекэмпа – Мэсси» есть подробное описание процедуры. В следующем примере C ( x ) используется для представления Λ ( x ).

Пример
[ редактировать ]Используя те же данные, что и в примере Петерсона Горенштейна Цирлера выше:
| н | С н +1 | д | С | Б | б | м |
|---|---|---|---|---|---|---|
| 0 | 732 | 732 | 197 х + 1 | 1 | 732 | 1 |
| 1 | 637 | 846 | 173 х + 1 | 1 | 732 | 2 |
| 2 | 762 | 412 | 634 х 2 + 173 х + 1 | 173 х + 1 | 412 | 1 |
| 3 | 925 | 576 | 329 х 2 + 821 х + 1 | 173 х + 1 | 412 | 2 |
Окончательное значение C — это полином локатора ошибок Λ( x ).
Евклидов декодер
[ редактировать ]Другой итерационный метод расчета как полинома локатора ошибок, так и полинома значения ошибки основан на адаптации Сугиямой расширенного алгоритма Евклида .
Определите S ( x ), Λ ( x ) и Ω ( x ) для t синдромов и e ошибок:
![{\displaystyle {\begin{aligned}S(x)&=S_{t}x^{t-1}+S_{t-1}x^{t-2}+\cdots +S_{2}x+ S_{1}\\[1ex]\Lambda (x)&=\Lambda _{e}x^{e}+\Lambda _{e-1}x^{e-1}+\cdots +\Lambda _ {1}x+1\\[1ex]\Omega (x)&=\Omega _{e}x^{e}+\Omega _{e-1}x^{e-1}+\cdots +\ Омега _{1}x+\Omega _{0}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a84cd05dee4a72d23c59b3f95c4efdf3c8703600)
Ключевое уравнение:

Для t = 6 и e = 3:

Средние члены равны нулю из-за связи между Λ и синдромами.
Расширенный алгоритм Евклида может найти ряд полиномов вида
где степень R уменьшается с увеличением i . Если степень R i ( x ) < t /2, то
B ( x ) и Q ( x ) сохранять не нужно, поэтому алгоритм выглядит следующим образом:
R−1 := xt R0 := S(x) A−1 := 0 A0 := 1 i := 0 while degree of Ri ≥ t/2 i := i + 1 Q := Ri-2 / Ri-1 Ri := Ri-2 - Q Ri-1 Ai := Ai-2 - Q Ai-1
чтобы установить младший член Λ( x ) равным 1, разделите Λ( x ) и Ω( x ) на A i (0):
A i (0) — постоянный член (низкого порядка) A i .
Пример
[ редактировать ]Используя те же данные, что и в примере Петерсона-Горенштейна-Цирлера выше:
| я | Р я | И я |
|---|---|---|
| −1 | 001 х 4 + 000 х 3 + 000 х 2 + 000 х + 000 | 000 |
| 0 | 925 х 3 + 762 х 2 + 637 х + 732 | 001 |
| 1 | 683 х 2 + 676 х + 024 | 697 х + 396 |
| 2 | 673 х + 596 | 608 х 2 + 704 х + 544 |
Декодер с использованием дискретного преобразования Фурье
[ редактировать ]Для декодирования можно использовать дискретное преобразование Фурье. [ 15 ] Чтобы избежать конфликта с именами синдромов, пусть c ( x ) = s ( x ) закодированное кодовое слово. r ( x ) и e ( x ) такие же, как указано выше. Определите C ( x ), E ( x ) и R ( x ) как дискретные преобразования Фурье c ( x ), e ( x ) и r ( x ). Поскольку r ( x ) = c ( x ) + e ( x ) и поскольку дискретное преобразование Фурье является линейным оператором, R ( x ) = C ( x ) + E ( x ).
Преобразуйте r ( x ) в R ( x ) с помощью дискретного преобразования Фурье. Поскольку вычисление дискретного преобразования Фурье такое же, как и вычисление синдромов, t коэффициенты R ( x ) и E ( x ) такие же, как и синдромы:

Использовать через как синдромы (они одинаковы) и сгенерируйте полином локатора ошибок, используя методы любого из вышеперечисленных декодеров.


Пусть v = количество ошибок. Сгенерируйте E ( x ) с помощью известных коэффициентов к , полином локатора ошибок и эти формулы



Затем вычислите C ( x ) = R ( x ) − E ( x ) и выполните обратное преобразование (полиномиальную интерполяцию) C ( x ), чтобы получить c ( x ).
Декодирование за пределами исправления ошибок
[ редактировать ]Граница Синглтона утверждает, что минимальное расстояние d линейного блочного кода размера ( n , k ) ограничено сверху n − k + 1 . Обычно понималось, что расстояние d ограничивает возможность исправления ошибок до ⌊( d −1) / 2⌋ . Код Рида-Соломона достигает этой границы с равенством и, таким образом, может исправить до ⌊( n − k ) / 2⌋ ошибок. Однако эта граница коррекции ошибок не является точной.
В 1999 году Мадху Судан и Венкатесан Гурусвами из Массачусетского технологического института опубликовали «Улучшенное декодирование кодов Рида – Соломона и алгебро-геометрических кодов», представив алгоритм, который позволял исправлять ошибки, превышающие половину минимального расстояния кода. [ 16 ] Это применимо к кодам Рида – Соломона и, в более общем плане, к алгебро-геометрическим кодам . Этот алгоритм создает список кодовых слов (это алгоритм декодирования списка ) и основан на интерполяции и факторизации полиномов по и его расширения.

В 2023 году, опираясь на три захватывающие работы, [ 17 ] [ 18 ] [ 19 ] Теоретики кодирования показали, что коды Рида-Соломона, определенные по случайным точкам оценки, на самом деле могут с высокой вероятностью достичь способности декодирования списка (до n - k ошибок) в алфавитах линейного размера. Однако этот результат является скорее комбинаторным, чем алгоритмическим.
Мягкое декодирование
[ редактировать ]Описанные выше алгебраические методы декодирования являются методами жесткого решения, что означает, что для каждого символа принимается жесткое решение о его значении. Например, декодер может связать с каждым символом дополнительное значение, соответствующее уверенности демодулятора канала в правильности символа. Появление LDPC и турбокодов , в которых используются итерационные методы декодирования с мягким решением и распространением доверия для достижения производительности исправления ошибок, близкой к теоретическому пределу , стимулировало интерес к применению декодирования с мягким решением к обычным алгебраическим кодам. В 2003 году Ральф Кёттер и Александр Варди представили алгоритм алгебраического списка декодирования с мягким решением с полиномиальным временем для кодов Рида – Соломона, который был основан на работе Судана и Гурусвами. [ 20 ] В 2016 году Стивен Дж. Франке и Джозеф Х. Тейлор опубликовали новый декодер мягкого решения. [ 21 ]
Пример МАТЛАБ
[ редактировать ]Кодер
[ редактировать ]Здесь мы представляем простую MATLAB реализацию кодера .
function encoded = rsEncoder(msg, m, prim_poly, n, k)
% RSENCODER Encode message with the Reed-Solomon algorithm
% m is the number of bits per symbol
% prim_poly: Primitive polynomial p(x). Ie for DM is 301
% k is the size of the message
% n is the total size (k+redundant)
% Example: msg = uint8('Test')
% enc_msg = rsEncoder(msg, 8, 301, 12, numel(msg));
% Get the alpha
alpha = gf(2, m, prim_poly);
% Get the Reed-Solomon generating polynomial g(x)
g_x = genpoly(k, n, alpha);
% Multiply the information by X^(n-k), or just pad with zeros at the end to
% get space to add the redundant information
msg_padded = gf([msg zeros(1, n - k)], m, prim_poly);
% Get the remainder of the division of the extended message by the
% Reed-Solomon generating polynomial g(x)
[~, remainder] = deconv(msg_padded, g_x);
% Now return the message with the redundant information
encoded = msg_padded - remainder;
end
% Find the Reed-Solomon generating polynomial g(x), by the way this is the
% same as the rsgenpoly function on matlab
function g = genpoly(k, n, alpha)
g = 1;
% A multiplication on the galois field is just a convolution
for k = mod(1 : n - k, n)
g = conv(g, [1 alpha .^ (k)]);
end
end
Декодер
[ редактировать ]Теперь часть декодирования:
function [decoded, error_pos, error_mag, g, S] = rsDecoder(encoded, m, prim_poly, n, k)
% RSDECODER Decode a Reed-Solomon encoded message
% Example:
% [dec, ~, ~, ~, ~] = rsDecoder(enc_msg, 8, 301, 12, numel(msg))
max_errors = floor((n - k) / 2);
orig_vals = encoded.x;
% Initialize the error vector
errors = zeros(1, n);
g = [];
S = [];
% Get the alpha
alpha = gf(2, m, prim_poly);
% Find the syndromes (Check if dividing the message by the generator
% polynomial the result is zero)
Synd = polyval(encoded, alpha .^ (1:n - k));
Syndromes = trim(Synd);
% If all syndromes are zeros (perfectly divisible) there are no errors
if isempty(Syndromes.x)
decoded = orig_vals(1:k);
error_pos = [];
error_mag = [];
g = [];
S = Synd;
return;
end
% Prepare for the euclidean algorithm (Used to find the error locating
% polynomials)
r0 = [1, zeros(1, 2 * max_errors)]; r0 = gf(r0, m, prim_poly); r0 = trim(r0);
size_r0 = length(r0);
r1 = Syndromes;
f0 = gf([zeros(1, size_r0 - 1) 1], m, prim_poly);
f1 = gf(zeros(1, size_r0), m, prim_poly);
g0 = f1; g1 = f0;
% Do the euclidean algorithm on the polynomials r0(x) and Syndromes(x) in
% order to find the error locating polynomial
while true
% Do a long division
[quotient, remainder] = deconv(r0, r1);
% Add some zeros
quotient = pad(quotient, length(g1));
% Find quotient*g1 and pad
c = conv(quotient, g1);
c = trim(c);
c = pad(c, length(g0));
% Update g as g0-quotient*g1
g = g0 - c;
% Check if the degree of remainder(x) is less than max_errors
if all(remainder(1:end - max_errors) == 0)
break;
end
% Update r0, r1, g0, g1 and remove leading zeros
r0 = trim(r1); r1 = trim(remainder);
g0 = g1; g1 = g;
end
% Remove leading zeros
g = trim(g);
% Find the zeros of the error polynomial on this galois field
evalPoly = polyval(g, alpha .^ (n - 1 : - 1 : 0));
error_pos = gf(find(evalPoly == 0), m);
% If no error position is found we return the received work, because
% basically is nothing that we could do and we return the received message
if isempty(error_pos)
decoded = orig_vals(1:k);
error_mag = [];
return;
end
% Prepare a linear system to solve the error polynomial and find the error
% magnitudes
size_error = length(error_pos);
Syndrome_Vals = Syndromes.x;
b(:, 1) = Syndrome_Vals(1:size_error);
for idx = 1 : size_error
e = alpha .^ (idx * (n - error_pos.x));
err = e.x;
er(idx, :) = err;
end
% Solve the linear system
error_mag = (gf(er, m, prim_poly) \ gf(b, m, prim_poly))';
% Put the error magnitude on the error vector
errors(error_pos.x) = error_mag.x;
% Bring this vector to the galois field
errors_gf = gf(errors, m, prim_poly);
% Now to fix the errors just add with the encoded code
decoded_gf = encoded(1:k) + errors_gf(1:k);
decoded = decoded_gf.x;
end
% Remove leading zeros from Galois array
function gt = trim(g)
gx = g.x;
gt = gf(gx(find(gx, 1) : end), g.m, g.prim_poly);
end
% Add leading zeros
function xpad = pad(x, k)
len = length(x);
if len < k
xpad = [zeros(1, k - len) x];
end
end
Декодеры оригинального вида Рида Соломона
[ редактировать ]Декодеры, описанные в этом разделе, используют исходное представление Рида-Соломона кодового слова как последовательность полиномиальных значений, где полином основан на кодируемом сообщении. Кодер и декодер используют один и тот же набор фиксированных значений, и декодер восстанавливает полином кодирования (и, возможно, полином обнаружения ошибок) из полученного сообщения.
Теоретический декодер
[ редактировать ]Рид и Соломон (1960) описали теоретический декодер, который исправлял ошибки путем нахождения наиболее популярного полинома сообщения. Декодер знает только набор значений к и какой метод кодирования использовался для генерации последовательности значений кодового слова. Исходное сообщение, полином и любые ошибки неизвестны. Процедура декодирования может использовать такой метод, как интерполяция Лагранжа для различных подмножеств из n значений кодового слова, взятых k за раз, для многократного создания потенциальных полиномов до тех пор, пока не будет создано достаточное количество совпадающих полиномов, чтобы разумно устранить любые ошибки в полученном кодовом слове. После определения полинома любые ошибки в кодовом слове можно исправить путем пересчета соответствующих значений кодового слова. К сожалению, во всех случаях, кроме самых простых, подмножеств слишком много, поэтому алгоритм непрактичен. Число подмножеств – это биномиальный коэффициент , , а количество подмножеств невозможно даже для скромных кодов. Для код, который может исправить три ошибки, наивный теоретический декодер исследует 359 миллиардов подмножеств.




Берлекамп Какой декодер
[ редактировать ]В 1986 году был разработан декодер, известный как алгоритм Берлекэмпа-Уэлча , который способен восстанавливать исходный полином сообщения, а также полином «локатора» ошибок, который выдает нули для входных значений, соответствующих ошибкам, с временной сложностью. , где количество значений в сообщении. Восстановленный полином затем используется для восстановления (при необходимости пересчета) исходного сообщения.

Пример
[ редактировать ]Используя RS(7,3), GF(929) и набор точек оценки a i = i - 1
Если полином сообщения
Кодовое слово
Ошибки при передаче могут привести к тому, что это сообщение будет получено вместо этого.
Ключевые уравнения:

Предположим максимальное количество ошибок: e = 2. Ключевые уравнения принимают вид:


Использование исключения Гаусса :

Пересчитайте P(x) , где E(x) = 0 : {2, 3}, чтобы исправить b, в результате чего будет исправлено кодовое слово:
декодер Гао
[ редактировать ]В 2002 году Шухун Гао разработал улучшенный декодер, основанный на расширенном алгоритме Евклида. [ 6 ]
Пример
[ редактировать ]Используя те же данные, что и в примере Берлекэмпа Уэлча выше:
- Лагранжевая интерполяция для я = от 1 до n





| я | Р я | И я |
|---|---|---|
| −1 | 001 х 7 + 908 х 6 + 175 х 5 + 194 х 4 + 695 х 3 + 094 х 2 + 720 х + 000 | 000 |
| 0 | 055 х 6 + 440 х 5 + 497 х 4 + 904 х 3 + 424 х 2 + 472 х + 001 | 001 |
| 1 | 702 х 5 + 845 х 4 + 691 х 3 + 461 х 2 + 327 х + 237 | 152 х + 237 |
| 2 | 266 х 4 + 086 х 3 + 798 х 2 + 311 х + 532 | 708 х 2 + 176 х + 532 |
разделите Q ( x ) и E ( x ) на наиболее значимый коэффициент E ( x ) = 708. (Необязательно)
Пересчитайте P ( x ) , где E ( x ) = 0 : {2, 3}, чтобы исправить b, в результате чего будет исправлено кодовое слово:
См. также
[ редактировать ]- Код BCH
- Алгоритм Берлекэмпа – Мэсси
- Алгоритм Берлекэмпа – Уэлча
- Чиен поиск
- Циклический код
- Сложенный код Рида – Соломона
- Прямое исправление ошибок
Примечания
[ редактировать ]- ^ Авторы Эндрюс и др. (2007) предоставили результаты моделирования, которые показывают, что для одной и той же скорости кода (1/6) турбокоды превосходят каскадные коды Рида-Соломона до 2 дБ ( коэффициент ошибок по битам ). [ 9 ]
Ссылки
[ редактировать ]- ^ Рид и Соломон (1960)
- ^ Горенштейн, Д.; Цирлер, Н. (июнь 1961 г.). «Класс циклических линейных кодов, исправляющих ошибки в символах p^m». Дж. СИАМ . 9 (2): 207–214. дои : 10.1137/0109020 . JSTOR 2098821 .
- ^ Петерсон, В. Уэсли (1961). Коды исправления ошибок . МТИ Пресс. OCLC 859669631 .
- ^ Петерсон, В. Уэсли; Уэлдон, Э.Дж. (1996) [1972]. Коды исправления ошибок (2-е изд.). МТИ Пресс. ISBN 978-0-585-30709-1 . OCLC 45727875 .
- ^ Сугияма, Ю.; Касахара, М.; Хирасава, С.; Намекава, Т. (1975). «Метод решения ключевого уравнения для декодирования кодов Гоппы» . Информация и контроль . 27 (1): 87–99. дои : 10.1016/S0019-9958(75)90090-X .
- ^ Jump up to: а б Гао, Шухун (январь 2002 г.), Новый алгоритм декодирования кодов Рида-Соломона (PDF) , Клемсон
- ^ Имминк, KAS (1994), «Коды Рида – Соломона и компакт-диск», Уикер, Стивен Б.; Бхаргава, Виджай К. (ред.), Коды Рида-Соломона и их приложения , IEEE Press , ISBN 978-0-7803-1025-4
- ^ Хагенауэр, Дж.; Оффер, Э.; Папке, Л. (1994). «11. Сопоставление декодеров Витерби и декодеров Рида-Соломона в каскадной системе». Коды Рида-Соломона и их приложения . IEEE Пресс. п. 433. ИСБН 9780470546345 . OCLC 557445046 .
- ^ Jump up to: а б Эндрюс, Канзас; Дивсалар, Д.; Долинар, С.; Хэмкинс, Дж.; Джонс, ЧР; Поллара, Ф. (2007). «Разработка турбо-кодов и кодов LDPC для приложений дальнего космоса» (PDF) . Труды IEEE . 95 (11): 2142–56. дои : 10.1109/JPROC.2007.905132 . S2CID 9289140 .
- ^ См ., например, Лин и Костелло (1983 , стр. 171).
- ^ «Аналитические выражения, используемые в беркодировании и BERTool» . Архивировано из оригинала 01 февраля 2019 г. Проверено 1 февраля 2019 г.
- ^ Пфендер, Флориан; Циглер, Гюнтер М. (сентябрь 2004 г.), «Числа целования, упаковки сфер и некоторые неожиданные доказательства» (PDF) , Уведомления Американского математического общества , 51 (8): 873–883, в архиве (PDF) с оригинала на 9 мая 2008 г. , получено 28 сентября 2009 г. Объясняет теорему Дельсарта-Гёталя-Зейделя, используемую в контексте кода исправления ошибок для компакт-диска .
- ^ Д. Горенштейн и Н. Цирлер, «Класс циклических линейных кодов с исправлением ошибок в символах p^m», J. SIAM, vol. 9, стр. 207–214, июнь 1961 г.
- ^ Коды, исправляющие ошибки Уэсли Петерсона, 1961 г.
- ^ Шу Линь и Дэниел Дж. Костелло-младший, «Кодирование контроля ошибок», второе издание, стр. 255–262, 1982, 2004 г.
- ^ Гурусвами, В.; Судан, М. (сентябрь 1999 г.), «Улучшенное декодирование кодов Рида – Соломона и кодов алгебраической геометрии», IEEE Transactions on Information Theory , 45 (6): 1757–1767, CiteSeerX 10.1.1.115.292 , doi : 10.1109/18.782097
- ^ Бракензик, Джошуа; Гопи, Шивакант; Макам, Вису (2 июня 2023 г.). «Общие коды Рида-Соломона обеспечивают способность декодирования по спискам» . Материалы 55-го ежегодного симпозиума ACM по теории вычислений . STOC 2023. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 1488–1501. arXiv : 2206.05256 . дои : 10.1145/3564246.3585128 . ISBN 978-1-4503-9913-5 .
- ^ Го, Зею; Чжан, Зихан (2023). «Случайно проколотые коды Рида-Соломона достигают способности декодирования списка по алфавитам полиномиального размера» . 64-й ежегодный симпозиум IEEE по основам информатики (FOCS) , 2023 г. FOCS 2023, Санта-Круз, Калифорния, США, 2023. стр. 164–176. arXiv : 2304.01403 . дои : 10.1109/FOCS57990.2023.00019 . ISBN 979-8-3503-1894-4 .
- ^ Альрабия, Омар; Гурусвами, Венкатесан; Ли, Рэй (18 августа 2023 г.), Случайно проколотые коды Рида-Соломона обеспечивают способность декодирования списка по полям линейного размера , arXiv : 2304.09445 , получено 8 февраля 2024 г.
- ^ Кеттер, Ральф; Варди, Александр (2003). «Алгебраическое декодирование кодов Рида – Соломона с мягким решением». Транзакции IEEE по теории информации . 49 (11): 2809–2825. CiteSeerX 10.1.1.13.2021 . дои : 10.1109/TIT.2003.819332 .
- ^ Франке, Стивен Дж.; Тейлор, Джозеф Х. (2016). «Декодер мягкого решения с открытым исходным кодом для кода Рида – Соломона JT65 (63,12)» (PDF) . QEX (май/июнь): 8–17. Архивировано (PDF) из оригинала 9 марта 2017 г. Проверено 7 июня 2017 г.
Дальнейшее чтение
[ редактировать ]- Гилл, Джон (nd), Примечания EE387 № 7, Раздаточный материал № 28 (PDF) , Стэнфордский университет, заархивировано из оригинала (PDF) 30 июня 2014 г. , получено 21 апреля 2010 г.
- Хонг, Джонатан; Веттерли, Мартин (август 1995 г.), «Простые алгоритмы декодирования BCH» (PDF) , IEEE Transactions on Communications , 43 (8): 2324–33, doi : 10.1109/26.403765
- Лин, Шу; Костелло-младший, Дэниел Дж. (1983), Кодирование с контролем ошибок: основы и приложения , Прентис-Холл, ISBN 978-0-13-283796-5
- Мэсси, Дж. Л. (1969), «Синтез сдвиговых регистров и декодирование BCH» (PDF) , Транзакции IEEE по теории информации , IT-15 (1): 122–127, doi : 10.1109/tit.1969.1054260 , S2CID 9003708
- Петерсон, Уэсли В. (1960), «Процедуры кодирования и исправления ошибок для кодов Бозе-Чаудхури», IRE Transactions on Information Theory , IT-6 (4): 459–470, doi : 10.1109/TIT.1960.1057586
- Рид, Ирвинг С .; Соломон, Гюстав (1960), «Полиномиальные коды над некоторыми конечными полями», Журнал Общества промышленной и прикладной математики , 8 (2): 300–304, doi : 10.1137/0108018
- Уэлч, Л.Р. (1997), Оригинальный взгляд на коды Рида – Соломона (PDF) , конспекты лекций
- Берлекамп, Элвин Р. (1967), Недвоичное декодирование BCH , Международный симпозиум по теории информации, Сан-Ремо, Италия, OCLC 45195002 , AD0669824
- Берлекамп, Элвин Р. (1984) [1968], Теория алгебраического кодирования (пересмотренная редакция), Лагуна-Хиллз, Калифорния: Aegean Park Press, ISBN 978-0-89412-063-3
- Ципра, Барри Артур (1993), «Вездесущие коды Рида – Соломона» , SIAM News , 26 (1)
- Форни-младший, Г. (октябрь 1965 г.), «О декодировании кодов BCH», IEEE Transactions on Information Theory , 11 (4): 549–557, doi : 10.1109/TIT.1965.1053825
- Кеттер, Ральф (2005), Коды Рида – Соломона , MIT Lecture Notes 6.451 (Видео), заархивировано из оригинала 13 марта 2013 г.
- МакВильямс, Ф.Дж.; Слоан, NJA (1977), Теория кодов, исправляющих ошибки , Северная Голландия, ISBN 978-0-444-85010-2
- Рид, Ирвинг С .; Чен, Сюэмин (2012) [1999], Кодирование с контролем ошибок для сетей передачи данных , Springer, ISBN 9781461550051
Внешние ссылки
[ редактировать ]Информация и учебные пособия
[ редактировать ]- Введение в коды Рида – Соломона: принципы, архитектура и реализация (CMU)
- Учебное пособие по кодированию Рида-Соломона для обеспечения отказоустойчивости в RAID-подобных системах
- Алгебраическое мягкое декодирование кодов Рида – Соломона.
- Викиверситет:Коды Рида – Соломона для программистов
- Технический документ BBC по исследованиям и разработкам WHP031
- Гейзель, Уильям А. (август 1990 г.), Учебное пособие по кодированию с коррекцией ошибок Рида-Соломона , Технический меморандум, НАСА , TM-102162
- Составные коды доктора Дэйва Форни (scholarpedia.org).
- Рид, Джефф А. (апрель 1995 г.), CRC и Рид Соломон ECC (PDF)
Реализации
[ редактировать ]- Библиотека FEC на языке C Фила Карна (также известного как KA9Q) включает кодек Рида – Соломона, как произвольную, так и оптимизированную (223 255) версию.
- Кодек Рида – Соломона Schifra с открытым исходным кодом C++
- Библиотека RSCode Генри Мински, кодер/декодер Рида-Соломона
- Библиотека мягкого декодирования Рида – Соломона с открытым исходным кодом C++
- Реализация Matlab ошибок и стираний, декодирование Рида – Соломона
- Реализация Octave в коммуникационном пакете
- Реализация кодека Рида – Соломона на Pure-Python