Тег SNP
Метка SNP представляет собой репрезентативный однонуклеотидный полиморфизм (SNP) в участке генома с высоким неравновесием по сцеплению , который представляет собой группу SNP, называемую гаплотипом . Можно идентифицировать генетические вариации и ассоциации с фенотипами без генотипирования каждого SNP в хромосомной области. Это снижает затраты и время на картирование областей генома, связанных с заболеванием, поскольку устраняет необходимость изучения каждого отдельного SNP. Теговые SNP полезны в полногеномных исследованиях ассоциации SNP , в которых генотипируются сотни тысяч SNP по всему геному.
Введение
[ редактировать ]Неравновесие связей
[ редактировать ]
два локуса Говорят, что находятся в равновесии по сцеплению (LE), если их наследование является независимым событием. Если аллели в этих локусах наследуются неслучайно, то мы говорим, что они находятся в состоянии неравновесия по сцеплению (LD) . ЛД чаще всего вызывается физическим сцеплением генов. Когда два гена наследуются на одной хромосоме, в зависимости от их расстояния и вероятности рекомбинации между локусами они могут иметь высокую LD. Однако ЛД также может наблюдаться из-за функциональных взаимодействий, когда даже гены из разных хромосом могут совместно придавать эволюционно выбранный фенотип или влиять на жизнеспособность потенциального потомства.
В семьях LD самая высокая из-за наименьшего количества событий рекомбинации (наименьшее количество событий мейоза). Это особенно верно для инбредных линий. В популяциях LD существует из-за отбора, физической близости генов, вызывающей низкую скорость рекомбинации, или из-за недавнего скрещивания или миграции. На популяционном уровне процессы, влияющие на неравновесие по сцеплению, включают генетическое сцепление , эпистатический естественный отбор , скорость рекомбинации , мутации , генетический дрейф , случайное спаривание , генетический автостоп и поток генов . [2]
Когда группа SNP наследуется вместе из-за высокого LD, существует тенденция к появлению избыточной информации. Выбор тега SNP в качестве представителя этих групп уменьшает количество избыточности при анализе частей генома, связанных с признаками/заболеваниями. [3] Области генома с высоким уровнем LD, которые содержат определенный набор SNP, которые наследуются вместе, также известны как гаплотипы . Следовательно, теговые SNP являются репрезентативными для всех SNP в гаплотипе.
Гаплотипы
[ редактировать ]Выбор теговых SNP зависит от гаплотипов, присутствующих в геноме. Большинство технологий секвенирования предоставляют генотипическую информацию, а не гаплотипы, т.е. они предоставляют информацию о конкретных присутствующих основаниях, но не предоставляют информацию о фазах (на какой конкретной хромосоме появляется каждое из оснований). [4] Определение гаплотипов можно провести молекулярными методами ( аллель-специфическая ПЦР , гибриды соматических клеток ). Эти методы позволяют определить, какой аллель в какой хромосоме присутствует, путем разделения хромосом перед генотипированием. Они могут быть очень трудоемкими и дорогостоящими, поэтому методы статистического вывода были разработаны как менее дорогой и автоматизированный вариант. Эти пакеты программного обеспечения для статистического вывода используют алгоритмы экономии, максимального правдоподобия и байесовские алгоритмы для определения гаплотипов. Недостаток статистического вывода заключается в том, что часть предполагаемых гаплотипов может быть ошибочной. [5]
Популяционные различия
[ редактировать ]Когда гаплотипы используются для полногеномных исследований ассоциаций, важно отметить изучаемую популяцию. Часто разные группы населения имеют разные модели ЛД. Одним из примеров дифференциации моделей являются популяции африканского происхождения и популяции европейского и азиатского происхождения. Поскольку люди возникли в Африке и распространились в Европу, а затем на азиатский и американский континенты, африканские популяции являются наиболее генетически разнообразными и имеют меньшие области LD, в то время как популяции Европы и азиатского происхождения имеют более крупные области LD из-за эффекта основателя . Когда паттерны LD различаются в популяциях, SNP могут диссоциироваться друг с другом из-за изменений в блоках гаплотипов . Это означает, что теговые SNP, как представители блоков гаплотипов, уникальны в популяциях и популяционные различия следует учитывать при проведении ассоциативных исследований. [6]
Приложение
[ редактировать ]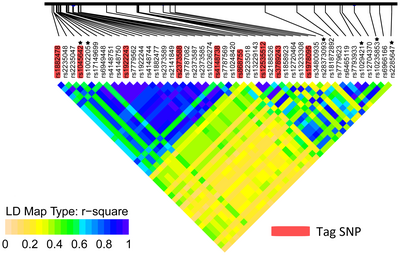
ГВАС
[ редактировать ]Почти каждая черта имеет как генетическое, так и влияние окружающей среды. Наследственность — это доля фенотипической изменчивости, унаследованной от наших предков. Исследования ассоциаций используются для определения генетического влияния на фенотипическое представление . Хотя в основном они используются для картирования заболеваний по областям генома, их также можно использовать для картирования наследственности любого фенотипа, такого как рост, цвет глаз и т. д.
В полногеномных исследованиях ассоциаций (GWAS) используются однонуклеотидные полиморфизмы (SNP) для выявления генетических ассоциаций с клиническими состояниями и фенотипическими признаками. [8] Они свободны от гипотез и используют полногеномный подход для исследования признаков путем сравнения большой группы людей, обладающих фенотипом, с большой группой людей, у которых его нет. Конечная цель GWAS — определить генетические факторы риска, которые можно использовать для прогнозирования того, кто подвержен риску заболевания, каковы биологические основы восприимчивости к заболеваниям, а также для создания новых стратегий профилактики и лечения. [1] Национальный институт исследования генома человека и Европейский институт биоинформатики публикуют Каталог GWAS — каталог опубликованных исследований общегеномных ассоциаций, в котором подчеркиваются статистически значимые ассоциации между сотнями SNP с широким диапазоном фенотипов. [9]

В связи с большим количеством возможных вариантов SNP (более 149 млн по состоянию на июнь 2015 г.) [10] [11] ) секвенировать все SNP по-прежнему очень дорого. Вот почему GWAS использует настраиваемые массивы (чипы SNP) для генотипирования только подмножества вариантов, идентифицированных как snps тегов. Большинство GWAS используют продукты двух основных платформ генотипирования. Платформа Affymetrix печатает ДНК-зонды на стеклянном или силиконовом чипе, которые гибридизуются с определенными аллелями в образце ДНК. Платформа Illumina использует технологию на основе шариков с более длинными последовательностями ДНК и обеспечивает лучшую специфичность. [1] Обе платформы способны генотипировать более миллиона SNP-меток, используя как готовые, так и специальные олигонуклеотиды ДНК .
Полногеномные исследования основаны на гипотезе общего варианта заболевания (CD/CV), которая утверждает, что на общие расстройства влияют общие генетические вариации. Размер эффекта ( пенетрантность ) распространенных вариантов должен быть меньше по сравнению с эффектами, обнаруженными при редких заболеваниях. Это означает, что общий SNP может объяснить лишь небольшую часть дисперсии, обусловленной генетическими факторами, и что на распространенные заболевания влияют многочисленные общие аллели с небольшой величиной эффекта. Другая гипотеза состоит в том, что распространенные заболевания вызываются редкими вариантами, которые синтетически связаны с распространенными вариантами. В этом случае сигнал, вырабатываемый GWAS, представляет собой непрямую (синтетическую) связь между одним или несколькими редкими причинными вариантами неравновесия по сцеплению. Важно осознавать, что это явление возможно при выборе группы для тегов SNP. Когда обнаруживается, что заболевание связано с гаплотипом, некоторые SNP в этом гаплотипе будут иметь синтетическую связь с заболеванием. Чтобы точно определить причинные SNP, нам нужна более высокая точность при выборе блоков гаплотипов. Поскольку технологии полногеномного секвенирования быстро меняются и становятся менее дорогими, вполне вероятно, что они заменят нынешние технологии генотипирования, обеспечивая разрешение, необходимое для точного определения причинных вариантов.
HapКарта
[ редактировать ]Поскольку полногеномное секвенирование отдельных людей по-прежнему является непомерно дорогостоящим, международный проект HapMap был создан с целью сопоставить геном человека с группами гаплотипов (блоками гаплотипов), которые могут описать общие закономерности генетических вариаций человека. Путем сопоставления всего генома с гаплотипами можно идентифицировать теговые SNP, представляющие блоки гаплотипов, изученные в ходе генетических исследований. Важным фактором, который следует учитывать при планировании генетического исследования, является частота и риск, связанный с конкретными аллелями. Эти факторы могут различаться в разных популяциях, поэтому в проекте HapMap использовались различные методы секвенирования для обнаружения и каталогизации SNP из разных групп популяций. Первоначально в рамках проекта секвенировались люди из популяции йоруба африканского происхождения (YRI), жители Юты западноевропейского происхождения (CEU), неродственные люди из Токио, Япония (JPT) и неродственные китайцы хань из Пекина, Китай (CHB). Недавно их наборы данных были расширены и теперь включают другие группы населения (11 групп). [1]
Выбор и оценка
[ редактировать ]Шаги по выбору SNP тега
[ редактировать ]Выбор максимально информативных теговых SNP является NP-полной задачей . Однако можно разработать алгоритмы, обеспечивающие приближенное решение в пределах погрешности. [12] Критерии, необходимые для определения каждого алгоритма выбора SNP тега, следующие:
- Определить область для поиска — алгоритм попытается найти теги SNP в окрестности N(t) целевого SNP t.
- Определите метрику для оценки качества маркировки — метрика должна измерять, насколько хорошо целевой SNP t может быть предсказан с использованием набора его соседей N(t), т. е. насколько хорошо тег SNP является представителем SNP в окрестности N (t) может предсказать целевой SNP t. Его можно определить как вероятность того, что целевой SNP t имеет разные значения для любой пары гаплотипов i и j, где значения SNP s также различны для одних и тех же гаплотипов. Информативность метрики можно представить в терминах теории графов, где каждый SNP представлен в виде графа G, узлы которого являются гаплотипами. Gs имеет ребро между узлами (i,j) тогда и только тогда, когда значения s различны для гаплотипов Hi, Hj. [12]
- Выведите алгоритм для поиска репрезентативных SNP — цель алгоритма — найти минимальное подмножество SNP тегов, выбранное с максимальной информативностью между каждым SNP тега и каждым другим целевым SNP.
- Проверьте алгоритм
Выбор функции
[ редактировать ]Методы выбора объектов делятся на две категории: методы фильтрации и методы-оболочки. Алгоритмы фильтрации — это общие алгоритмы предварительной обработки, которые не предполагают использование конкретного метода классификации. Алгоритмы-оболочки, напротив, «обертывают» выбор признаков вокруг конкретного классификатора и выбирают подмножество признаков на основе точности классификатора с использованием перекрестной проверки. [13]
Метод выбора признаков, подходящий для выбора SNP тегов, должен иметь следующие характеристики:
- хорошо масштабируется для большого количества SNP;
- не требуют явной маркировки классов и не должны предполагать использование конкретного классификатора, поскольку классификация не является целью маркировки выбора SNP;
- разрешить пользователю выбирать разное количество тегов SNP для разных объемов допустимой потери информации;
- имеют сравнимую производительность с другими методами, удовлетворяющими трем первым условиям.
Алгоритмы выбора
[ редактировать ]Было предложено несколько алгоритмов выбора SNP тегов. Первый подход был основан на мере качества наборов SNP и искал подмножества SNP, которые небольшие, но достигают высокого значения определенной меры. Исследование каждого подмножества SNP на предмет поиска хороших с точки зрения вычислений возможно только для небольших наборов данных.
Другой подход использует анализ главных компонентов (PCA) для поиска подмножеств SNP, охватывающих большую часть дисперсии данных. Метод скользящих окон используется для многократного применения PCA к коротким хромосомным участкам. Это сокращает объем получаемых данных, а также не требует экспоненциального времени поиска. Тем не менее, невозможно применить метод PCA к большим наборам хромосомных данных, поскольку он сложен в вычислительном отношении. [13]
Наиболее часто используемый подход, блочный метод, использует принцип неравновесия по сцеплению, наблюдаемый внутри блоков гаплотипов. [12] Было разработано несколько алгоритмов для разделения хромосомных регионов на блоки гаплотипов, которые основаны на разнообразии гаплотипов , LD , тесте четырех гамет и сложности информации , а теговые SNP выбираются из всех SNP, принадлежащих этому блоку. Основное предположение в этом алгоритме состоит в том, что SNP являются двуаллельными . [14] Основным недостатком является то, что определение блоков не всегда простое. Несмотря на то, что существует список критериев формирования блоков гаплотипов, единого мнения по нему нет. Кроме того, выбор тегов SNP на основе локальных корреляций игнорирует межблочные корреляции. [12]
В отличие от блочного подхода, безблочный подход не опирается на блочную структуру. Известно, что частота SNP и скорость рекомбинации варьируются в зависимости от генома, и в некоторых исследованиях сообщалось о расстояниях LD, которые намного превышают зарегистрированные максимальные размеры блоков. Установка строгих границ для соседства нежелательна, и подход без блоков ищет теги SNP по всему миру. Для этого существует несколько алгоритмов. В одном алгоритме SNP без тегов представлены как логические функции SNP тегов, а методы теории множеств используются для уменьшения пространства поиска. Другой алгоритм ищет подмножества маркеров, которые могут происходить из непоследовательных блоков. Из-за близости маркера пространство поиска сокращается. [13]
Оптимизации
[ редактировать ]Поскольку число генотипированных людей и количество SNP в базах данных растет, выбор меток SNP требует слишком много времени для вычислений. Чтобы повысить эффективность метода выбора SNP-метки, алгоритм сначала игнорирует двуаллельность SNP, а затем сжимает длину (номер SNP) матрицы гаплотипов путем группировки сайтов SNP с одинаковой информацией. Сайты SNP, которые объединяют гаплотипы в одну группу, называются избыточными сайтами. Сайты SNP, которые содержат отдельную информацию внутри блока, называются неизбыточными сайтами (NRS). Чтобы дополнительно сжать матрицу гаплотипов, алгоритму необходимо найти SNP тегов, чтобы можно было различить все гаплотипы матрицы. Используя идею совместного разделения, обеспечивается эффективный алгоритм выбора SNP тегов. [14]
Проверка точности алгоритма
[ редактировать ]В зависимости от того, как выбраны SNP тегов, в процессе перекрестной проверки использовались разные методы прогнозирования. Для предсказания пропущенного гаплотипа был использован метод машинного обучения. Другой подход предсказал аллели немаркирующего SNP n из теговых SNP, которые имели самый высокий коэффициент корреляции с n. Если обнаруживается один высококоррелированный тег SNP t, аллели назначаются так, чтобы их частоты совпадали с частотами аллелей t. Когда несколько меченых SNP имеют одинаковый (высокий) коэффициент корреляции с n, общий аллель n имеет преимущество. Легко видеть, что в этом случае метод прогнозирования хорошо согласуется с методом выбора, который использует PCA на матрице коэффициентов корреляции между SNP. [13]
Существуют и другие способы оценки точности метода выбора SNP тега. Точность можно оценить с помощью показателя качества R2, который является мерой связи между истинным количеством копий гаплотипов, определенных по полному набору SNP, и прогнозируемым количеством копий гаплотипов, где прогноз основан на подмножестве меченых SNP. Эта мера предполагает наличие диплоидных данных и явный вывод гаплотипов из генотипов. [13]
Другой метод оценки, предложенный Клейтоном, основан на измерении разнообразия гаплотипов. Разнообразие определяется как общее количество различий при всех попарных сравнениях между гаплотипами. Разница между парой гаплотипов представляет собой сумму различий по всем SNP. Меру разнообразия Клейтона можно использовать для определения того, насколько хорошо набор теговых SNP дифференцирует разные гаплотипы. Эта мера подходит только для блоков гаплотипов с ограниченным разнообразием гаплотипов, и неясно, как ее использовать для больших наборов данных, состоящих из нескольких блоков гаплотипов. [13]
В некоторых недавних работах алгоритмы выбора теговых SNP оцениваются на основе того, насколько хорошо тегирующие SNP могут использоваться для прогнозирования немаркированных SNP. Точность прогноза определяется с помощью перекрестной проверки, такой как исключение одного или удержание. При перекрестной проверке с исключением одного для каждой последовательности в наборе данных алгоритм запускается на остальной части набора данных, чтобы выбрать минимальный набор маркирующих SNP. [13]
Инструменты
[ редактировать ]Теги
[ редактировать ]Tagger — это веб-инструмент, доступный для оценки и выбора SNP тегов из генотипических данных, таких как Международный проект HapMap. Он использует парные методы и подходы с использованием мультимаркерных гаплотипов. Пользователи могут загрузить данные генотипа HapMap или формат родословной, и будут рассчитаны закономерности неравновесия по сцеплению. Параметры тега позволяют пользователю указывать хромосомные ориентиры, которые указывают области интереса в геноме для выбора теговых SNP. Затем программа создает список тегов SNP и их статистических тестовых значений, а также отчет о покрытии. Он разработан Полом де Баккером в лабораториях Дэвида Альтшулера и Марка Дейли в Центре генетических исследований человека Массачусетской больницы общего профиля и Гарвардской медицинской школы при Институте Броуда . [15]
CLUSTAG и WCLUSTAG
[ редактировать ]В бесплатных программах CLUSTAG и WCLUSTAG содержатся алгоритмы кластеризации и покрытия множеств для получения набора теговых SNP, которые могут представлять все известные SNP в хромосомной области. Программы реализованы на языке Java и могут работать как на платформе Windows, так и в среде Unix. Они разработаны СИО-ИОНГ АО и др. в Университете Гонконга. [16] [17]
См. также
[ редактировать ]- Международный проект HapMap
- Полногеномное исследование ассоциаций
- Однонуклеотидный полиморфизм
- Неравновесие связей
Ссылки
[ редактировать ]- ^ Перейти обратно: а б с д Буш, Уильям С.; Мур, Джейсон Х.; Левиттер, Фрэн; Канн, Марисель (27 декабря 2012 г.). «Глава 11: Исследования общегеномных ассоциаций» . PLOS Вычислительная биология . 8 (12): e1002822. Бибкод : 2012PLSCB...8E2822B . дои : 10.1371/journal.pcbi.1002822 . ПМЦ 3531285 . ПМИД 23300413 .
- ^ Ван дер Верф, Юлиус. «Основы сцепления и картирования генов» (PDF) . Проверено 30 апреля 2014 г.
- ^ Левонтин, RC (1988). «О мерах гаметического неравновесия» . Генетика . 120 (3): 849–852. дои : 10.1093/генетика/120.3.849 . ПМЦ 1203562 . ПМИД 3224810 .
- ^ Гальперин Э.; Киммел, Г.; Шамир, Р. (16 июня 2005 г.). «Выбор тегов SNP в данных генотипа для максимизации точности прогнозирования SNP». Биоинформатика . 21 (Приложение 1): i195–i203. doi : 10.1093/биоинформатика/bti1021 . ПМИД 15961458 .
- ^ Кроуфорд, Дана С.; Никерсон, Дебора А. (2005). «Определение и клиническое значение гаплотипов». Ежегодный обзор медицины . 56 (1): 303–320. дои : 10.1146/annurev.med.56.082103.104540 . ПМИД 15660514 .
- ^ Тео, ГГ; Сим, X (апрель 2010 г.). «Модель неравновесия по сцеплению в разных популяциях: значение и возможности для липид-ассоциированных локусов, выявленных в ходе полногеномных исследований ассоциаций». Современное мнение в липидологии . 21 (2): 104–15. дои : 10.1097/MOL.0b013e3283369e5b . ПМИД 20125009 . S2CID 21217250 .
- ^ Шоу, Вэйхуа; Ван, Дажи; Чжан, Кайюэ; Ван, Бэйлан; Ван, Чжиминь; Ши, Цзиньсю; Хуан, Вэй; Хуан, Цинъян (26 сентября 2012 г.). «Общегенная характеристика локусов общих количественных признаков экспрессии мРНК ABCB1 в нормальных тканях печени у китайской популяции» . ПЛОС ОДИН . 7 (9): e46295. Бибкод : 2012PLoSO...746295S . дои : 10.1371/journal.pone.0046295 . ПМЦ 3458811 . ПМИД 23050008 .
- ^ Велтер, Д.; Макартур, Дж.; Моралес, Дж.; Бердетт, Т.; Холл, П.; Джанкинс, Х.; Клемм, А.; Фличек, П.; Манолио, Т.; Хиндорфф, Л.; Паркинсон, Х. (6 декабря 2013 г.). «Каталог NHGRI GWAS, курируемый ресурс ассоциаций SNP-признаков» . Исследования нуклеиновых кислот . 42 (Д1): Д1001–Д1006. дои : 10.1093/нар/gkt1229 . ПМЦ 3965119 . ПМИД 24316577 .
- ^ Витте, Джон С.; Хоффманн, Томас Дж. (2011). «Полигенное моделирование полногеномных ассоциативных исследований: применение к раку простаты и молочной железы» . OMICS: Журнал интегративной биологии . 15 (6): 393–398. дои : 10.1089/omi.2010.0090 . ПМК 3125548 . ПМИД 21348634 .
- ^ Статистика данных dbSNP . Национальный центр биотехнологической информации (США). 2005.
- ^ «Сводка dbSNP» .
- ^ Перейти обратно: а б с д Тарво, Алекс. «Учебное пособие по маркировке гаплотипов» (PDF) . Проверено 1 мая 2014 г.
- ^ Перейти обратно: а б с д и ж г Фуонг, ТМ; Лин, З; Альтман, РБ (апрель 2006 г.). «Выбор SNP с использованием выбора признаков». Журнал биоинформатики и вычислительной биологии . 4 (2): 241–57. CiteSeerX 10.1.1.128.1909 . дои : 10.1109/csb.2005.22 . ПМИД 16819782 . S2CID 821959 .
- ^ Перейти обратно: а б Чен, В.П.; Хунг, CL; Цай, С.Дж.; Лин, Ю.Л. (2014). «Новые и эффективные алгоритмы выбора SNP тегов». Биомедицинские материалы и инженерия . 24 (1): 1383–9. дои : 10.3233/BME-130942 . ПМИД 24212035 .
- ^ «Таггер» . Проверено 1 мая 2014 г.
- ^ «КЛУСТАГ» . Проверено 9 марта 2024 г.
- ^ «ВКЛУСТАГ» . Проверено 9 марта 2024 г.