Радикс-дерево

В информатике поразрядное дерево (также поразрядное дерево , или компактное префиксное дерево , или сжатое дерево ) — это структура данных , представляющая оптимизированное по пространству дерево (префиксное дерево), в котором каждый узел, являющийся единственным дочерним элементом, объединяется со своим родителем. В результате количество дочерних элементов каждого внутреннего узла не превышает основание r дерева счисления, где r = 2. х для некоторого целого числа x ≥ 1. В отличие от обычных деревьев, ребра можно помечать как последовательностями элементов, так и отдельными элементами. Это делает базовые деревья более эффективными для небольших наборов (особенно если строки длинные) и для наборов строк с общими длинными префиксами.
В отличие от обычных деревьев (где целые ключи сравниваются массово от их начала до точки неравенства), ключ в каждом узле сравнивается по частям битов, где количество битов в этом куске в этот узел является основанием r дерева счисления. Когда r равно 2, дерево счисления является двоичным (т. е. сравнивается 1-битовая часть ключа этого узла), что минимизирует разреженность за счет максимизации глубины дерева, т. е. максимизации вплоть до объединения нерасходящихся битовых строк в ключе. . Когда r ≥ 4 является степенью 2, тогда дерево счисления является r -арным деревом, что уменьшает глубину дерева счисления за счет потенциальной разреженности.
В качестве оптимизации метки ребер можно сохранять постоянного размера, используя два указателя на строку (для первого и последнего элементов). [1]
Обратите внимание: хотя примеры в этой статье показывают строки как последовательности символов, тип строковых элементов может быть выбран произвольно; например, как бит или байт строкового представления при использовании символов многобайтовых кодировок или Unicode .
Приложения
[ редактировать ]Деревья счисления полезны для построения ассоциативных массивов с ключами, которые можно выразить в виде строк. Они находят особое применение в области IP- маршрутизации . [2] [3] [4] где способность содержать большие диапазоны значений за некоторыми исключениями особенно подходит для иерархической организации IP-адресов . [5] Они также используются для инвертированных индексов текстовых документов при поиске информации .
Операции
[ редактировать ]Основанные деревья поддерживают операции вставки, удаления и поиска. Вставка добавляет новую строку в дерево, пытаясь минимизировать объем хранимых данных. Удаление удаляет строку из дерева. Операции поиска включают (но не обязательно ограничиваются) точный поиск, поиск предшественника, поиск преемника и поиск всех строк с префиксом. Все эти операции имеют вид O( k ), где k — максимальная длина всех строк в наборе, где длина измеряется количеством бит, равным основанию дерева счисления.
Искать
[ редактировать ]
Операция поиска определяет, существует ли строка в дереве. Большинство операций каким-то образом модифицируют этот подход для решения своих конкретных задач. Например, значение может иметь узел, в котором заканчивается строка. Эта операция аналогична попыткам, за исключением того, что некоторые ребра потребляют несколько элементов.
Следующий псевдокод предполагает, что эти методы и члены существуют.
Край
- Узел targetNode
- строковая метка
Узел
- Массив ребер Edges
- функция isLeaf()
function lookup(string x){ // Begin at the root with no elements found Node traverseNode := root; int elementsFound := 0; // Traverse until a leaf is found or it is not possible to continue while (traverseNode != null && !traverseNode.isLeaf() && elementsFound < x.length) { // Get the next edge to explore based on the elements not yet found in x Edge nextEdge := select edge from traverseNode.edges where edge.label is a prefix of x.suffix(elementsFound) // x.suffix(elementsFound) returns the last (x.length - elementsFound) elements of x // Was an edge found? if (nextEdge != null) { // Set the next node to explore traverseNode := nextEdge.targetNode; // Increment elements found based on the label stored at the edge elementsFound += nextEdge.label.length; } else { // Terminate loop traverseNode := null; } } // A match is found if we arrive at a leaf node and have used up exactly x.length elements return (traverseNode != null && traverseNode.isLeaf() && elementsFound == x.length);}Вставка
[ редактировать ]Чтобы вставить строку, мы просматриваем дерево до тех пор, пока не сможем добиться дальнейшего прогресса. На этом этапе мы либо добавляем новое исходящее ребро, помеченное всеми оставшимися элементами во входной строке, либо, если уже существует исходящее ребро, имеющее общий префикс с оставшейся входной строкой, мы разбиваем его на два ребра (первое помечено общим префикс) и продолжайте. Этот шаг разделения гарантирует, что ни один узел не будет иметь больше дочерних элементов, чем количество возможных строковых элементов.
Ниже показано несколько случаев вставки, хотя их может быть и больше. Обратите внимание, что r просто представляет корень. Предполагается, что ребра могут быть помечены пустыми строками для завершения строк там, где это необходимо, и что корень не имеет входящего ребра. (Алгоритм поиска, описанный выше, не будет работать при использовании ребер пустой строки.)
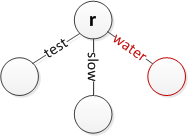 Вставьте слово «вода» в корень
Вставьте слово «вода» в корень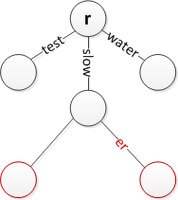 Вставьте слово «медленнее», сохраняя при этом слово «медленно».
Вставьте слово «медленнее», сохраняя при этом слово «медленно». Вставьте слово «test», которое является префиксом слова «тестер».
Вставьте слово «test», которое является префиксом слова «тестер». Вставьте слово «team», разделив «test» и создав новую метку края «st».
Вставьте слово «team», разделив «test» и создав новую метку края «st».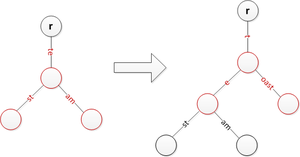 Вставьте «toast», разделив «te» и переместив предыдущие строки на уровень ниже.
Вставьте «toast», разделив «te» и переместив предыдущие строки на уровень ниже.





Удаление
[ редактировать ]Чтобы удалить строку x из дерева, мы сначала находим лист, представляющий x. Затем, предполагая, что x существует, мы удаляем соответствующий листовой узел. Если у родителя нашего листового узла есть только один дочерний узел, то входящая метка этого дочернего узла добавляется к входящей метке родительского узла, а дочерний узел удаляется.
Дополнительные операции
[ редактировать ]- Найти все строки с общим префиксом: возвращает массив строк, начинающихся с одного и того же префикса.
- Найти предшественника: находит самую большую строку, меньшую, чем заданная строка, в лексикографическом порядке.
- Найти преемника: находит наименьшую строку, большую, чем заданная, в лексикографическом порядке.
История
[ редактировать ]Структура данных была изобретена в 1968 году Дональдом Р. Моррисоном. [6] с которым оно в первую очередь связано, и Гернотом Гвеенбергером. [7]
Дональд Кнут , страницы 498-500 тома III « Искусства компьютерного программирования », называет их «деревьями Патриции», предположительно в честь аббревиатуры в названии статьи Моррисона: «PATRICIA — Практический алгоритм для извлечения информации, закодированной в буквенно-цифровом формате». Сегодня деревья Патриции рассматриваются как базисные деревья с основанием, равным 2, что означает, что каждый бит ключа сравнивается индивидуально, и каждый узел представляет собой двустороннюю (т. е. левую и правую) ветвь.
Сравнение с другими структурами данных
[ редактировать ](В следующих сравнениях предполагается, что ключи имеют длину k , а структура данных содержит n элементов.)
В отличие от сбалансированных деревьев , поразрядные деревья допускают поиск, вставку и удаление за время O( k ), а не за O(log n ). Это не кажется преимуществом, поскольку обычно k ≥ log n , но в сбалансированном дереве каждое сравнение представляет собой сравнение строк, требующее O( k в худшем случае времени ), многие из которых на практике медленны из-за длинных общих префиксов (в случай, когда сравнения начинаются с начала строки). В дереве все сравнения требуют постоянного времени, но требуется m для поиска строки длины m сравнений . Основанные деревья могут выполнять эти операции с меньшим количеством сравнений и требуют гораздо меньше узлов.
Однако базисные деревья также имеют общие недостатки с попытками: поскольку их можно применять только к строкам элементов или элементам с эффективно обратимым сопоставлением со строками, им не хватает полной универсальности сбалансированных деревьев поиска, которые применимы к любому типу данных с общим числом заказ . Обратимое сопоставление со строками можно использовать для создания требуемого общего порядка для сбалансированных деревьев поиска, но не наоборот. Это также может быть проблематичным, если тип данных обеспечивает только операцию сравнения, но не операцию (де) сериализации .
Обычно говорят, что хэш-таблицы ожидают времени вставки и удаления O (1), но это верно только в том случае, если рассматривать вычисление хэш-ключа ключа как операцию с постоянным временем. Когда учитывается хеширование ключа, хеш-таблицы ожидают времени вставки и удаления O( k ), но в худшем случае это может занять больше времени в зависимости от того, как обрабатываются коллизии. В радикс-деревьях вставка и удаление в наихудшем случае O( k ). Операции преемника/предшественника поразрядных деревьев также не реализуются хеш-таблицами.
Варианты
[ редактировать ]Обычное расширение поразрядных деревьев использует два цвета узлов: «черный» и «белый». Чтобы проверить, сохранена ли данная строка в дереве, поиск начинается сверху и следует по краям входной строки до тех пор, пока дальнейший прогресс не будет прекращен. Если строка поиска использована, а конечный узел является черным узлом, поиск не удался; если он белый, поиск удался. Это позволяет нам добавлять в дерево большой диапазон строк с общим префиксом, используя белые узлы, а затем удалять небольшой набор «исключений» с экономией места, вставляя их с использованием черных узлов.
HAT -trie — это структура данных с поддержкой кэша, основанная на базовых деревьях, которая обеспечивает эффективное хранение и извлечение строк, а также упорядоченные итерации. Производительность по отношению ко времени и пространству с поддержкой кэша сравнимо с хэш- таблицей . [8] [9]
Дерево PATRICIA — это специальный вариант (двоичного) дерева счисления 2, в котором вместо явного хранения каждого бита каждого ключа узлы хранят только позицию первого бита, который различает два поддерева. Во время обхода алгоритм проверяет индексированный бит ключа поиска и выбирает левое или правое поддерево в зависимости от ситуации. Примечательные особенности дерева PATRICIA включают в себя то, что для каждого сохраненного уникального ключа в дерево требуется вставить только один узел, что делает PATRICIA гораздо более компактным, чем стандартное двоичное дерево. Кроме того, поскольку фактические ключи больше не сохраняются явно, необходимо выполнить одно полное сравнение ключей индексированной записи, чтобы подтвердить совпадение. В этом отношении PATRICIA имеет определенное сходство с индексацией с использованием хеш-таблицы. [6]
Адаптивное базисное дерево — это вариант базисного дерева, который объединяет адаптивные размеры узлов с базисным деревом. Одним из основных недостатков обычных поразрядных деревьев является использование пространства, поскольку на каждом уровне используется постоянный размер узла. Основное различие между базисным деревом и адаптивным базисным деревом заключается в его переменном размере для каждого узла в зависимости от количества дочерних элементов, которое увеличивается при добавлении новых записей. Следовательно, адаптивное базисное дерево приводит к лучшему использованию пространства без снижения его скорости. [10] [11] [12]
Обычной практикой является смягчение критериев, запрещающих родителям иметь только одного ребенка в ситуациях, когда родитель представляет действительный ключ в наборе данных. Этот вариант поразрядного дерева обеспечивает более высокую эффективность использования пространства, чем тот, который допускает только внутренние узлы как минимум с двумя дочерними узлами. [13]
См. также
[ редактировать ]- Дерево префиксов (также известное как Trie)
- Детерминированный ациклический конечный автомат (DAFSA)
- Тернарный поиск пытается
- Хэш-три
- Детерминированные конечные автоматы
- Массив Джуди
- Алгоритм поиска
- Расширяемое хеширование
- Дерево, отображаемое хеш-массивом
- Префиксное хеш-дерево
- Пакетная сортировка
- Алгоритм Лулео
- Кодирование Хаффмана
Ссылки
[ редактировать ]- ^ Морен, Патрик. «Структуры данных для строк» (PDF) . Проверено 15 апреля 2012 г.
- ^ "rtfree(9)" . www.freebsd.org . Проверено 23 октября 2016 г.
- ^ Регенты Калифорнийского университета (1993). "/sys/net/radix.c" . Перекрестная ссылка BSD . НетБСД . Проверено 25 июля 2019 г.
Подпрограммы для построения и поддержки базисных деревьев для поиска маршрутов.
- ^ «Блокированные, атомарные и универсальные деревья Radix/Patricia» . НетБСД . 2011.
- ^ Книжник, Константин. «Патриция Трис: лучший индекс для поиска по префиксам» , журнал доктора Добба , июнь 2008 г.
- ^ Перейти обратно: а б Моррисон, Дональд Р. ПАТРИСИЯ - Практический алгоритм извлечения информации, закодированной в буквенно-цифровом формате.
- ^ Г. Гвеэнбергер, Применение метода двоичной цепочки ссылок при построении списков. Электронные вычислительные системы 10 (1968), стр. 223–226.
- ^ Аскитис, Николас; Синха, Ранджан (2007). HAT-trie: структура данных на основе Trie с учетом кэша для строк . Том. 62. С. 97–105. ISBN 978-1-920682-43-9 .
{{cite book}}:|journal=игнорируется ( помогите ) - ^ Аскитис, Николас; Синха, Ранджан (октябрь 2010 г.). «Разработка масштабируемых, кэш- и компактных попыток для строк». Журнал ВЛДБ . 19 (5): 633–660. дои : 10.1007/s00778-010-0183-9 . S2CID 432572 .
- ^ Кемпер, Альфонс; Эйклер, Андре (2013). Системы баз данных. Введение . Том 9. Ольденбург. стр. 604–605. ISBN 978-3-486-72139-3 .
- ^ «armon/libart: адаптивные счисления, реализованные на C» . Гитхаб . Проверено 17 сентября 2014 г.
- ^ Виктор Лейс; и др. (2013). «Адаптивное поразрядное дерево: ARTful индексирование для баз данных в основной памяти». 2013 29-я Международная конференция IEEE по инженерии данных (ICDE) . стр. 38–49. дои : 10.1109/ICDE.2013.6544812 . ISBN 978-1-4673-4910-9 . S2CID 14030601 .
- ^ Может ли узел дерева Radix, представляющий действительный ключ, иметь одного дочернего элемента?
Внешние ссылки
[ редактировать ]- Исследования и справочные материалы по алгоритмам и структурам данных: PATRICIA , Ллойд Эллисон, Университет Монаша
- Патрисия Три , Словарь алгоритмов и структур данных NIST
- Деревья с критическими битами , Дэниел Дж. Бернштейн.
- API Radix Tree в ядре Linux , Джонатан Корбет
- Карт (основное дерево ключевых изменений) , Пол Жарк
- Адаптивное корневое дерево: ARTful индексирование для баз данных в основной памяти , Виктор Лейс, Альфонс Кемпер , Томас Нейман , Мюнхенский технический университет
Реализации
[ редактировать ]- Реализация FreeBSD , используемая для подкачки, пересылки и прочего.
- Реализация ядра Linux , используемая, среди прочего, для кэша страниц.
- Стандартная библиотека GNU C++ имеет реализацию trie.
- Java-реализация Concurrent Radix Tree , автор: Найл Галлахер
- C# реализация радикс-дерева
- Библиотека шаблонов практических алгоритмов , библиотека C++ для попыток PATRICIA (VC++ >=2003, GCC G++ 3.x), автор Роман С. Клюйков
- Реализация шаблонного класса Патрисии Три C++ , автор: Раду Груян
- Реализация стандартной библиотеки Haskell , «основанная на деревьях патриции с прямым порядком байтов». доступный для просмотра в Интернете Исходный код, .
- Реализация Патрисии Три на Java , авторы Роджер Капси и Сэм Берлин
- Деревья критических битов, созданные из кода C Дэниелом Дж. Бернштейном
- Реализация Патрисии Три на C , в libcprops
- Патрисия Трис: эффективные множества и отображения целых чисел в OCaml , Жан-Кристоф Филлиатр
- Реализация Radix DB (Patricia trie) на C , автор GB Versiani
- Либарт — адаптивные корневые деревья, реализованные на C , автором Армоном Дадгаром и другими участниками (открытый исходный код, лицензия BSD с 3 пунктами)
- Реализация дерева критических битов в Nim
- rax , реализация базового дерева в ANSI C от Сальваторе Санфилиппо (создателя REDIS )