Параллельная внешняя память
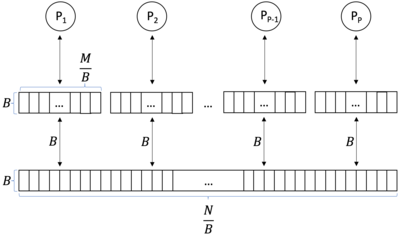
В информатике модель параллельной внешней памяти (PEM) представляет собой с поддержкой кэша и внешней памятью абстрактную машину . [1] Это аналогия параллельных вычислений модели однопроцессорной внешней памяти (EM). Подобным образом, это аналогия с поддержкой кэша параллельной машины с произвольным доступом (PRAM). Модель PEM состоит из нескольких процессоров вместе с соответствующими частными кэшами и общей основной памятью.
Модель
[ редактировать ]Определение
[ редактировать ]Модель PEM [1] представляет собой комбинацию модели EM и модели PRAM. Модель PEM — это вычислительная модель, состоящая из процессоры и двухуровневая иерархия памяти . Эта иерархия памяти состоит из большой внешней памяти (основной памяти) размером и небольшая внутренняя память (кеши) . Процессоры совместно используют основную память. Каждый кэш предназначен только для одного процессора. Процессор не может получить доступ к чужому кэшу. Тайники имеют размер который разделен на блоки размером . Процессоры могут выполнять операции только с данными, которые находятся в их кэше. Данные могут передаваться между основной памятью и кэшем блоками размером .




Сложность ввода-вывода
[ редактировать ]Мерой сложности модели PEM является сложность ввода-вывода, [1] который определяет количество параллельных передач блоков между основной памятью и кэшем. Во время параллельной передачи блоков каждый процессор может передать блок. Итак, если процессоры параллельно загружают блок данных размером формируют основную память в свои кэши, это считается сложностью ввода-вывода нет . Программа в модели PEM должна минимизировать передачу данных между основной памятью и кэшами и как можно больше оперировать данными в кэшах.


Конфликты чтения/записи
[ редактировать ]В модели PEM нет прямой сети связи между процессорами P. Процессоры должны взаимодействовать косвенно через основную память. Если несколько процессоров пытаются одновременно получить доступ к одному и тому же блоку в основной памяти, возникают конфликты чтения/записи. [1] происходить. Как и в модели PRAM, рассматриваются три различных варианта этой проблемы:
- Одновременное чтение и параллельная запись (CRCW): один и тот же блок в основной памяти может одновременно читаться и записываться несколькими процессорами.
- Параллельное чтение и эксклюзивная запись (CREW): один и тот же блок в основной памяти может одновременно читаться несколькими процессорами. Только один процессор может записывать данные в блок одновременно.
- Эксклюзивное чтение Эксклюзивная запись (EREW): один и тот же блок в основной памяти не может быть прочитан или записан несколькими процессорами одновременно. Только один процессор может одновременно обращаться к блоку.
Следующие два алгоритма [1] решить проблему ЭКИПАЖА и ЭРВ, если процессоры записывают в один и тот же блок одновременно. Первый подход заключается в сериализации операций записи. Только один процессор за другим записывает в блок. В результате получается в общей сложности параллельные блочные передачи. Второй подход требует параллельная передача блоков и дополнительный блок для каждого процессора. Основная идея состоит в том, чтобы запланировать операции записи в виде двоичного дерева и постепенно объединить данные в один блок. В первом раунде процессоры объединяют свои блоки в блоки. Затем процессоры объединяют в себе блоки в . Эта процедура продолжается до тех пор, пока все данные не объединятся в один блок.




Сравнение с другими моделями
[ редактировать ]| Модель | Многоядерный | Поддержка кэша |
|---|---|---|
| Машина произвольного доступа (ОЗУ) | Нет | Нет |
| Параллельная машина произвольного доступа (PRAM) | Да | Нет |
| Внешняя память (ЕМ) | Нет | Да |
| Параллельная внешняя память (PEM) | Да | Да |
Примеры
[ редактировать ]Многостороннее разбиение
[ редактировать ]Позволять быть вектором d-1 опорных точек, отсортированным в порядке возрастания. Пусть A — неупорядоченное множество из N элементов. D-образный раздел [1] представляет собой A множество , где и для . называется i-м ведром. Количество элементов в больше, чем и меньше, чем . В следующем алгоритме [1] вход разделен на смежные сегменты размера N/P. в основной памяти. Процессор i преимущественно работает на сегменте . Алгоритм многостороннего разбиения ( PEM_DIST_SORT[1] PEM суммирования префиксов ) использует алгоритм [1] рассчитать сумму префикса с оптимальным Сложность ввода-вывода. Этот алгоритм имитирует оптимальный алгоритм суммы префиксов PRAM.











// Compute parallelly a d-way partition on the data segments for each processor i in parallel do Read the vector of pivots M into the cache. Partition into d buckets and let vector be the number of items in each bucket. end for Run PEM prefix sum on the set of vectors simultaneously. // Use the prefix sum vector to compute the final partition for each processor i in parallel do Write elements into memory locations offset appropriately by and . end for Using the prefix sums stored in the last processor P calculates the vector B of bucket sizes and returns it.





Если вектор опорные точки M и входной набор A расположены в непрерывной памяти, то проблема d-стороннего разделения может быть решена в модели PEM с помощью Сложность ввода-вывода. Содержимое последних сегментов должно располагаться в непрерывной памяти.


Выбор
[ редактировать ]Задача выбора поиске k-го наименьшего элемента в неупорядоченном списке A размера N. заключается в
Следующий код [1] использует PRAMSORT который представляет собой оптимальный алгоритм сортировки PRAM, который работает в , и SELECT, который представляет собой алгоритм выбора оптимального для кэша однопроцессорного процессора.

if then return end if //Find median of each for each processor i in parallel do end for // Sort medians // Partition around median of medians if then return else return end if


![{\displaystyle А[к]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/37bea76700f1268910c4be5ca16ef0f9193b40a1)




![{\displaystyle {\texttt {PEMSELECT}}(A[1:t],P,k)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c39d5a07ede4bdd5385f2ef30b08f53ecab830f9)
![{\displaystyle {\texttt {PEMSELECT}}(A[t+1:N],P,kt)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/21685a86e7d03a3937c6ba2cf95c1724967d4d4e)
Предполагая, что входные данные хранятся в непрерывной памяти, PEMSELECT имеет сложность ввода-вывода:

Сортировка распределения
[ редактировать ]Сортировка по распределению разделяет входной список A размера N на d непересекающиеся сегменты одинакового размера. Затем каждый сегмент рекурсивно сортируется, и результаты объединяются в полностью отсортированный список.
Если задача делегируется оптимальному для кэша однопроцессорному алгоритму сортировки.

В противном случае следующий алгоритм [1] используется:
// Sample elements from A for each processor i in parallel do if then Load in M-sized pages and sort pages individually else Load and sort as single page end if Pick every 'th element from each sorted memory page into contiguous vector of samples end for in parallel do Combine vectors into a single contiguous vector Make copies of : end do // Find pivots for to in parallel do end for Pack pivots in contiguous array // Partition Aaround pivots into buckets // Recursively sort buckets for to in parallel do recursively call on bucket jof size using processors responsible for elements in bucket j end for










![{\displaystyle {\mathcal {M}}[j]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a79e9f6b98434837054f3ce301a6a283c09c904d)

![{\displaystyle {\mathcal {M}}[j]={\texttt {PEMSELECT}}({\mathcal {R}}_{i},{\tfrac {P}{\sqrt {d}}},{ \tfrac {j\cdot 4N}{d}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71b090408c8e1eefe120ea73f20112f89ba45305)


![{\displaystyle {\mathcal {B}}={\texttt {PEMMULTIPARTITION}}(A[1:N],{\mathcal {M}},{\sqrt {d}},P)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ee71380bf87811d22672bf62a50d5d9844891634)


![{\displaystyle {\mathcal {B}}[j]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/15afe12fdc196264ed086fccdd186ba470fcdcae)
![{\displaystyle O\left(\left\lceil {\tfrac {{\mathcal {B}}[j]}{N/P}}\right\rceil \right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/42f0326dc968b44303f83dccb1bd793dda7e41d9)
Сложность ввода/вывода PEMDISTSORT является:

где

Если выбрано такое количество процессоров и тогда сложность ввода-вывода составит:



Другие алгоритмы PEM
[ редактировать ]| PEM-алгоритм | Сложность ввода-вывода | Ограничения |
|---|---|---|
| Сортировка слиянием [1] | ||
| Рейтинг списка [2] | ||
| Эйлерова башня [2] | ||
| дерева выражений Оценка [2] | ||
| Поиск MST [2] |







Где — это время, необходимое для сортировки N элементов с помощью P процессоров в модели PEM.

См. также
[ редактировать ]- Параллельная машина произвольного доступа (PRAM)
- Машина произвольного доступа (ОЗУ)
- Внешняя память (ЕМ)
Ссылки
[ редактировать ]- ^ Jump up to: а б с д и ж г час я дж к л Арге, Ларс; Гудрич, Майкл Т.; Нельсон, Майкл; Ситчинава, Нодари (2008). «Фундаментальные параллельные алгоритмы для мультипроцессоров с частным кэшем». Материалы двадцатого ежегодного симпозиума по параллелизму в алгоритмах и архитектурах . Нью-Йорк, Нью-Йорк, США: ACM Press. стр. 197–206. дои : 10.1145/1378533.1378573 . ISBN 9781595939739 . S2CID 11067041 .
- ^ Jump up to: а б с д Арге, Ларс; Гудрич, Майкл Т.; Ситчинава, Нодари (2010). «Алгоритмы параллельного графа внешней памяти». 2010 Международный симпозиум IEEE по параллельной и распределенной обработке (IPDPS) . IEEE. стр. 1–11. дои : 10.1109/ipdps.2010.5470440 . ISBN 9781424464425 . S2CID 587572 .
| Общий | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Аппаратное обеспечение | |
| API | |
| Проблемы | |