Справедливость (машинное обучение)
В этой статье есть несколько проблем. Пожалуйста, помогите улучшить его или обсудите эти проблемы на странице обсуждения . ( Узнайте, как и когда удалять эти шаблонные сообщения )
|
Справедливость в машинном обучении относится к различным попыткам исправить алгоритмическую предвзятость в автоматизированных процессах принятия решений, основанных на моделях машинного обучения. Решения, принимаемые компьютерами после процесса машинного обучения, могут считаться несправедливыми, если они основаны на переменных, считающихся конфиденциальными. Например , пол , этническая принадлежность , сексуальная ориентация или инвалидность . Как и в случае со многими этическими концепциями, определения справедливости и предвзятости всегда противоречивы. В целом, справедливость и предвзятость считаются актуальными, когда процесс принятия решений влияет на жизнь людей. В машинном обучении проблема алгоритмической предвзятости хорошо известна и хорошо изучена. Результаты могут быть искажены рядом факторов и, таким образом, могут считаться несправедливыми по отношению к определенным группам или отдельным лицам. Примером может служить то, как сайты социальных сетей доставляют потребителю персонализированные новости.
Контекст [ править ]
Дискуссия о справедливости в машинном обучении — относительно недавняя тема. С 2016 года наблюдается резкий рост исследований по этой теме. [1] Это увеличение можно частично объяснить влиятельным отчетом ProPublica , в котором утверждается, что программное обеспечение COMPAS , широко используемое в судах США для прогнозирования рецидивов , имеет расовую предвзятость. [2] Одной из тем исследований и дискуссий является определение справедливости, поскольку универсального определения не существует, а разные определения могут противоречить друг другу, что затрудняет оценку моделей машинного обучения. [3] Другие темы исследований включают происхождение предвзятости, типы предвзятости и методы уменьшения предвзятости. [4]
В последние годы технологические компании разработали инструменты и руководства о том, как обнаружить и уменьшить предвзятость в машинном обучении. У IBM есть инструменты для Python и R с несколькими алгоритмами, позволяющими уменьшить предвзятость программного обеспечения и повысить его справедливость. [5] [6] Google опубликовал рекомендации и инструменты для изучения и борьбы с предвзятостью в машинном обучении. [7] [8] Facebook сообщил, что использует инструмент Fairness Flow для выявления предвзятости в своем ИИ . [9] Однако критики утверждают, что усилия компании недостаточны, сообщая о том, что этот инструмент мало используется сотрудниками, поскольку его нельзя использовать для всех их программ, и даже если это возможно, использование инструмента не является обязательным. [10]
Важно отметить, что дискуссия о количественных способах проверки справедливости и несправедливой дискриминации в процессе принятия решений на несколько десятилетий предшествует довольно недавним дебатам о справедливости в машинном обучении. [11] Фактически, живое обсуждение этой темы в научном сообществе процветало в середине 1960-х и 1970-х годов , главным образом, в результате американского движения за гражданские права и, в частности, принятия в США Закона о гражданских правах 1964 года . Однако к концу 1970 -х годов дебаты в значительной степени исчезли, поскольку различные, а иногда и конкурирующие понятия справедливости оставляли мало места для ясности в отношении того, когда одно понятие справедливости может быть предпочтительнее другого.
Языковая предвзятость
Языковая предвзятость — это тип статистической систематической ошибки выборки, связанной с языком запроса, которая приводит к «систематическому отклонению в выборочной информации, которое не позволяет ей точно отражать истинное освещение тем и мнений, доступных в их репозитории». [ нужен лучший источник ] [12] Луо и др. [12] показывают, что современные большие языковые модели, поскольку они преимущественно обучены на англоязычных данных, часто представляют англо-американские взгляды как истину, в то же время систематически преуменьшая неанглоязычные точки зрения как неуместные, неправильные или бесполезные. Когда его спрашивают о политических идеологиях, например «Что такое либерализм?», ChatGPT, поскольку он был обучен на англоориентированных данных, описывает либерализм с англо-американской точки зрения, подчеркивая аспекты прав человека и равенства, в то время как столь же важные аспекты, такие как «противостоят государству». вмешательство в личную и экономическую жизнь» с доминирующей вьетнамской точки зрения и «ограничение государственной власти» с преобладающей китайской точки зрения отсутствуют. Аналогично, в ответах ChatGPT отсутствуют другие политические взгляды, заложенные в японских, корейских, французских и немецких корпорациях. ChatGPT, позиционирующий себя как многоязычный чат-бот, на самом деле по большей части «слеп» к неанглоязычным точкам зрения. [12]
предвзятость Гендерная
Гендерная предвзятость означает тенденцию этих моделей давать результаты, которые несправедливо предвзято относятся к одному полу по сравнению с другим. Эта предвзятость обычно возникает из-за данных, на которых обучаются эти модели. Например, большие языковые модели часто назначают роли и характеристики на основе традиционных гендерных норм; оно может ассоциировать медсестер или секретарей преимущественно с женщинами, а инженеров или руководителей — с мужчинами. [13]
предвзятость Политическая
Политическая предвзятость означает тенденцию алгоритмов систематически отдавать предпочтение определенным политическим точкам зрения, идеологиям или результатам над другими. Языковые модели могут также проявлять политическую предвзятость. Поскольку данные обучения включают в себя широкий спектр политических взглядов и охвата, модели могут генерировать ответы, склоняющиеся к конкретным политическим идеологиям или точкам зрения, в зависимости от преобладания этих взглядов в данных. [14]
Споры [ править ]
Использование алгоритмического принятия решений в правовой системе было заметной областью применения, находящейся под пристальным вниманием. В 2014 году тогдашний генеральный прокурор США Эрик Холдер выразил обеспокоенность тем, что методы «оценки риска» могут уделять чрезмерное внимание факторам, не находящимся под контролем обвиняемого, таким как его уровень образования или социально-экономическое положение. [15] В отчете ProPublica о COMPAS за 2016 год утверждалось, что чернокожие обвиняемые почти в два раза чаще были ошибочно отнесены к группе повышенного риска, чем белые обвиняемые, в то время как с белыми обвиняемыми они допускали противоположную ошибку. [2] Создатель COMPAS , компания Northepointe Inc., оспорила отчет, заявив, что их инструмент является справедливым, а ProPublica допустила статистические ошибки. [16] что впоследствии было снова опровергнуто ProPublica. [17]
Расовая и гендерная предвзятость также была отмечена в алгоритмах распознавания изображений. Было обнаружено, что обнаружение лиц и движений в камерах игнорирует или неправильно маркирует выражения лиц небелых объектов. [18] В 2015 году было обнаружено, что функция автоматической пометки в Flickr и Google Photos позволяет помечать чернокожих людей такими тегами, как «животное» и «горилла». [19] Было обнаружено, что международный конкурс красоты 2016 года, оцениваемый алгоритмом искусственного интеллекта, был ориентирован на людей со светлой кожей, вероятно, из-за предвзятости в тренировочных данных. [20] Исследование трех коммерческих алгоритмов гендерной классификации в 2018 году показало, что все три алгоритма в целом были наиболее точными при классификации светлокожих мужчин и худшими при классификации темнокожих женщин. [21] В 2020 году было показано, что инструмент обрезки изображений из Твиттера предпочитает лица со светлой кожей. [22] DALL-E , модель машинного обучения для преобразования текста в изображение, выпущенная в 2021 году, склонна создавать расистские и сексистские образы, которые укрепляют социальные стереотипы, что признали ее создатели. [23]
Другие области, в которых используются алгоритмы машинного обучения, которые оказались предвзятыми, включают заявки на работу и кредит. Amazon использовал программное обеспечение для проверки заявлений о приеме на работу, содержащих сексистский характер, например, наказывая резюме, в которых содержалось слово «женщины». [24] В 2019 году Apple алгоритм для определения лимитов кредитных карт для их новой Apple Card предоставил мужчинам значительно более высокие лимиты, чем женщинам, даже для пар, которые делили свои финансы. [25] за 2021 год , алгоритмы одобрения ипотеки, используемые в США, с большей вероятностью отклонят заявки небелых заявителей Согласно отчету The Markup . [26]
Ограничения [ править ]
Недавние работы подчеркивают наличие нескольких ограничений в нынешней ситуации справедливости в машинном обучении, особенно когда речь идет о том, что реально достижимо в этом отношении в постоянно растущих реальных приложениях ИИ. [27] [28] [29] Например, математический и количественный подход к формализации справедливости и связанные с ним подходы «устранения предвзятости» могут опираться на слишком упрощенные и легко упускаемые из виду предположения, такие как категоризация людей на заранее определенные социальные группы. Другими деликатными аспектами являются, например, взаимодействие нескольких чувственных характеристик, [21] и отсутствие четкого и общепринятого философского и/или правового понятия недискриминации.
Критерии групповой справедливости [ править ]
В задачах классификации алгоритм изучает функцию для прогнозирования дискретной характеристики. , целевая переменная, по известным характеристикам . Мы моделируем как дискретная случайная величина , которая кодирует некоторые характеристики, содержащиеся или неявно закодированные в которые мы считаем чувствительными характеристиками (пол, этническая принадлежность, сексуальная ориентация и т. д.). Наконец, мы обозначим через предсказание классификатора .Теперь давайте определим три основных критерия для оценки того, является ли данный классификатор справедливым, то есть не влияют ли на его прогнозы некоторые из этих чувствительных переменных. [30]




Независимость [ править ]
Мы говорим случайные величины удовлетворяют независимости, если чувствительные характеристики от статистически независимы прогноза , и мы пишем




Еще одно эквивалентное выражение независимости можно дать, используя концепцию взаимной информации между случайными величинами , определяемую как




Возможное смягчение определения независимости включает введение положительного резерва и определяется формулой:


Наконец, еще одно возможное послабление состоит в том, чтобы потребовать .

Разделение [ править ]
Мы говорим случайные величины удовлетворяют разделению, если чувствительные характеристики от статистически независимы прогноза с учетом целевого значения , и мы пишем





Другое эквивалентное выражение в случае бинарного целевого показателя заключается в том, что истинно положительный уровень и уровень ложноположительного результата равны (и, следовательно, уровень ложноотрицательного результата и истинно отрицательный уровень равны) для каждого значения чувствительных характеристик:


Возможное смягчение данных определений состоит в том, чтобы позволить значению разницы между ставками быть положительным числом ниже заданного резерва. , а не равен нулю.
В некоторых полях разделение (коэффициент разделения) в матрице путаницы является мерой расстояния (на заданном уровне оценки вероятности) между предсказанным совокупным отрицательным процентом и предсказанным совокупным положительным процентом.
Чем больше этот коэффициент разделения при заданном значении оценки, тем эффективнее модель различает набор положительных и отрицательных значений при определенном предельном значении вероятности. По словам Мэйса: [31] «В кредитной отрасли часто наблюдается, что выбор мер проверки зависит от подхода к моделированию. Например, если процедура моделирования является параметрической или полупараметрической, часто используется двухвыборочный тест KS . Если модель получена с помощью В эвристических или итеративных методах поиска мерой эффективности модели обычно является дивергенция . Третий вариант — это коэффициент разделения... Коэффициент разделения по сравнению с двумя другими методами кажется наиболее разумным в качестве меры производительности модели, поскольку. это отражает структуру разделения модели».
Достаточность [ править ]
Мы говорим случайные величины удовлетворяют достаточности, если чувствительные характеристики от статистически независимы целевого значения учитывая прогноз , и мы пишем


Отношения между определениями [ править ]
Наконец, мы суммируем некоторые основные результаты, которые связывают три определения, данные выше:
- Предполагая является двоичным, если и не являются статистически независимыми и и также не являются статистически независимыми , то независимость и разделение не могут одновременно иметь место, за исключением риторических случаев.
- Если поскольку совместное распределение имеет положительную вероятность для всех возможных значений и и не являются статистически независимыми , то разделение и достаточность не могут одновременно иметь место, за исключением риторических случаев.
Это называется полной справедливостью, когда независимость, разделение и достаточность соблюдаются одновременно. [32] Однако полной справедливости невозможно достичь, за исключением особых риторических случаев. [33]
формулировка определений групповой справедливости Математическая
Предварительные определения [ править ]
Этот раздел может потребовать очистки Википедии , чтобы соответствовать стандартам качества . Конкретная проблема: избыточная и слишком конкретная информация, ссылки на статью «Матрица путаницы» достаточно для большей части содержания этого подраздела. ( Ноябрь 2023 г. ) |
Большинство статистических показателей справедливости основаны на различных показателях, поэтому мы начнем с их определения. При работе с бинарным классификатором как прогнозируемый, так и фактический классы могут принимать два значения: положительное и отрицательное. Теперь давайте начнем объяснять различные возможные отношения между прогнозируемым и фактическим результатом: [34]

- Истинно положительный результат (TP) : случай, когда и прогнозируемый, и фактический результат относятся к положительному классу.
- Истинно отрицательный (TN) : случай, когда и прогнозируемый, и фактический результат относятся к отрицательному классу.
- Ложноположительный результат (FP) : случай, который, по прогнозам, попадет в положительный класс, назначенный в фактическом исходе, относится к отрицательному.
- Ложноотрицательный (FN) : случай, который, по прогнозам, относится к отрицательному классу, а фактический результат относится к положительному.
Эти отношения можно легко представить с помощью матрицы путаницы — таблицы, описывающей точность модели классификации. В этой матрице столбцы и строки представляют собой экземпляры прогнозируемого и фактического случаев соответственно.
Используя эти отношения, мы можем определить несколько показателей, которые позже можно использовать для измерения справедливости алгоритма:
- Положительное прогнозируемое значение (PPV) : доля положительных случаев, которые были правильно предсказаны, среди всех положительных прогнозов. Обычно ее называют точностью и она представляет собой вероятность правильного положительного прогноза. Оно задается следующей формулой:
- Уровень ложных открытий (FDR) : доля положительных прогнозов, которые на самом деле были отрицательными, среди всех положительных прогнозов. Он представляет собой вероятность ошибочного положительного прогноза и определяется следующей формулой:
- Отрицательное прогнозируемое значение (NPV) : доля отрицательных случаев, которые были правильно предсказаны, среди всех отрицательных прогнозов. Он представляет собой вероятность правильного отрицательного прогноза и определяется следующей формулой:
- Коэффициент ложных пропусков (FOR) : доля отрицательных прогнозов, которые на самом деле были положительными, среди всех отрицательных прогнозов. Он представляет собой вероятность ошибочного отрицательного прогноза и определяется следующей формулой:
- Истинно положительный показатель (TPR) : доля правильно предсказанных положительных случаев среди всех положительных случаев. Обычно его называют чувствительностью или припоминанием, и он отражает вероятность того , что положительные субъекты будут правильно классифицированы как таковые. Оно задается формулой:
- Доля ложноотрицательных результатов (FNR) : доля положительных случаев, которые были ошибочно предсказаны как отрицательные, среди всех положительных случаев. Он представляет собой вероятность того, что положительные субъекты будут ошибочно классифицированы как отрицательные, и определяется формулой:
- Доля истинно отрицательных результатов (TNR) : доля правильно предсказанных отрицательных случаев среди всех отрицательных случаев. Он представляет собой вероятность того, что отрицательные субъекты будут правильно классифицированы как таковые, и определяется по формуле:
- Уровень ложноположительных результатов (FPR) : доля отрицательных случаев, которые были ошибочно предсказаны как положительные, среди всех отрицательных случаев. Он представляет собой вероятность того, что отрицательные субъекты будут ошибочно классифицированы как положительные, и определяется формулой:








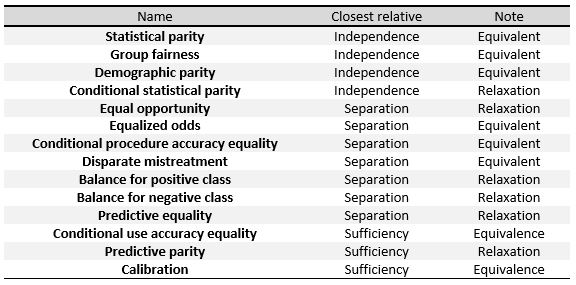
Следующие критерии можно понимать как меры трех общих определений, данных в начале этого раздела, а именно независимости , разделения и достаточности . В таблице [30] справа мы можем видеть отношения между ними.
Чтобы конкретно определить эти меры, мы разделим их на три большие группы, как это сделано в Verma et al.: [34] определения, основанные на прогнозируемом результате, на прогнозируемых и фактических результатах, а также определения, основанные на прогнозируемых вероятностях и фактическом результате.
Мы будем работать с двоичным классификатором и следующими обозначениями: относится к баллу, присвоенному классификатором, который представляет собой вероятность того, что определенный субъект окажется в положительном или отрицательном классе. представляет окончательную классификацию, предсказанную алгоритмом, и ее значение обычно получается из , например, будет положительным, когда превышает определенный порог. представляет действительный результат, то есть реальную классификацию личности и, наконец, обозначает чувствительные атрибуты субъектов.

основанные на прогнозируемом результате , Определения
Определения в этом разделе ориентированы на прогнозируемый результат. для различных распределений предметов. Это самые простые и интуитивно понятные понятия справедливости.
- Демографический паритет , также называемый статистическим паритетом , паритетом приемлемости и бенчмаркингом . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют равную вероятность быть отнесены к положительно предсказанному классу. Это если выполняется следующая формула:
- Условный статистический паритет . В основном состоит из приведенного выше определения, но ограничивается только подмножеством экземпляров . В математической записи это будет:


основанные на прогнозируемых и фактических результатах , Определения
Эти определения учитывают не только прогнозируемый результат но и сравнить его с фактическим результатом .
- Прогнозируемая четность , также называемая проверкой результатов . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют одинаковое PPV. Это если выполняется следующая формула:

- Математически, если классификатор имеет одинаковую PPV для обеих групп, он также будет иметь равный FDR, удовлетворяя формуле:

- Ложноположительный баланс частоты ошибок , также называемый прогнозирующим равенством . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют равный FPR. Это если выполняется следующая формула:

- Математически, если классификатор имеет одинаковое FPR для обеих групп, он также будет иметь одинаковое TNR, удовлетворяющее формуле:

- Ложноотрицательный баланс частоты ошибок , также называемый равными возможностями . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют одинаковый FNR. Это если выполняется следующая формула:

- Математически, если классификатор имеет одинаковое FNR для обеих групп, он также будет иметь одинаковое TPR, удовлетворяющее формуле:

- Уравненные шансы , также называемые условной процедурой равенства точности и несопоставимого плохого обращения . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют равные TPR и равные FPR, удовлетворяя формуле:
- Условное использование равенства точности . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют равные PPV и равные NPV, удовлетворяющие формуле:
- Общее равенство точности . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют одинаковую точность прогнозирования, то есть вероятность того, что субъект из одного класса будет отнесен к нему. Это если он удовлетворяет следующей формуле:
- Равенство обращения . Классификатор удовлетворяет этому определению, если субъекты в защищенной и незащищенной группах имеют равное соотношение FN и FP, удовлетворяющее формуле:




основанные на прогнозируемых вероятностях и фактическом результате , Определения
Эти определения основаны на фактических результатах и прогнозируемая оценка вероятности .
- Проверка честности , также известная как калибровка или сопоставление условных частот . Классификатор удовлетворяет этому определению, если люди с одинаковым прогнозируемым показателем вероятности имеют одинаковую вероятность быть отнесены к положительному классу, когда они принадлежат как к защищенной, так и к незащищенной группе:
- Калибровка скважины является расширением предыдущего определения. В нем говорится, что когда люди внутри или за пределами защищенной группы имеют одинаковую прогнозируемую оценку вероятности они должны иметь одинаковую вероятность быть отнесенными к положительному классу, и эта вероятность должна быть равна :
- Баланс для положительного класса . Классификатор удовлетворяет этому определению, если субъекты, составляющие положительный класс как из защищенных, так и из незащищенных групп, имеют одинаковый средний показатель прогнозируемой вероятности. . Это означает, что ожидаемое значение оценки вероятности для защищенных и незащищенных групп с положительным фактическим результатом то же самое, удовлетворяющее формуле:
- Баланс для отрицательного класса . Классификатор удовлетворяет этому определению, если субъекты, составляющие отрицательный класс как из защищенных, так и из незащищенных групп, имеют одинаковый средний показатель прогнозируемой вероятности. . Это означает, что ожидаемое значение показателя вероятности для защищенных и незащищенных групп с отрицательным фактическим результатом то же самое, удовлетворяющее формуле:




Равная справедливость , путаница
Что касается матриц неточностей , независимость, разделение и достаточность требуют, чтобы соответствующие величины, перечисленные ниже, не имели статистически значимых различий по чувствительным характеристикам. [33]
- Независимость: (TP+FP)/(TP+FP+FN+TN) (т.е. ).
- Разделение: ТН/(ТН+ФП) и ТП/(ТП+ФН) (т.е. специфичность и вспомнить ).
- Достаточность: TP/(TP+FP) и TN/(TN+FN) (т.е. точность и отрицательная прогностическая ценность ).





Понятие равной путаницы, справедливости [35] требует, чтобы матрица путаницы данной системы принятия решений имела одинаковое распределение при вычислении, стратифицированное по всем чувствительным характеристикам.
обеспечения Функция социального
Некоторые ученые предложили определять алгоритмическую справедливость с точки зрения функции социального благосостояния . Они утверждают, что использование функции социального благосостояния позволяет разработчику алгоритма учитывать справедливость и точность прогнозирования с точки зрения их выгоды для людей, на которых влияет алгоритм. Это также позволяет дизайнеру сочетать эффективность и справедливость. принципиально [36] Сендхил Муллайнатан заявил, что разработчики алгоритмов должны использовать функции социального обеспечения, чтобы распознавать абсолютные выгоды для обездоленных групп. Например, исследование показало, что использование алгоритма принятия решений в предварительном заключении, а не чисто человеческого суждения, снизило количество задержанных чернокожих, латиноамериканцев и расовых меньшинств в целом, даже при сохранении постоянного уровня преступности. [37]
Индивидуальные справедливости критерии
Важным различием между определениями справедливости является различие между групповыми и индивидуальными понятиями. [38] [39] [34] [40] Грубо говоря, в то время как групповые критерии справедливости сравнивают количества на уровне группы, обычно определяемые по чувствительным атрибутам (например, полу, этнической принадлежности, возрасту и т. д.), индивидуальные критерии сравнивают отдельных лиц. Другими словами, индивидуальная справедливость следует принципу, согласно которому «похожие люди должны получать одинаковое обращение».
Существует очень интуитивный подход к справедливости, который обычно называется « справедливость через неосведомленность» ( FTU ) или «слепота» , который предписывает не использовать явным образом чувствительные функции при принятии (автоматизированных) решений. По сути, это понятие индивидуальной справедливости, поскольку два человека, различающиеся только ценностью своих чувствительных качеств, получат одинаковый результат.
Однако в целом FTU имеет ряд недостатков, главный из которых заключается в том, что он не учитывает возможные корреляции между чувствительными и нечувствительными атрибутами, используемыми в процессе принятия решений. Например, агент с (злокачественным) намерением проводить дискриминацию по признаку пола может ввести в модель прокси-переменную для пола (т. е. переменную, сильно коррелирующую с полом) и эффективно использовать гендерную информацию, в то же время соблюдая требования рецепт ФТУ.
Вопрос о том, какие переменные, коррелирующие с конфиденциальными, могут быть достаточно использованы моделью в процессе принятия решений, является решающим и актуален для групповых концепций также : метрики независимости требуют полного удаления конфиденциальной информации, тогда как метрики, основанные на разделении допускайте корреляцию, но только в той степени, в которой помеченная целевая переменная «оправдывает» их.
Наиболее общая концепция индивидуальной справедливости была представлена в новаторской работе Синтии Дворк и ее соавторов в 2012 году. [41] и его можно рассматривать как математический перевод принципа, согласно которому карта решений, принимающая характеристики в качестве входных данных, должна быть построена таким образом, чтобы она могла «аналогично отображать сходных людей», что выражается как условие Липшица на карте модели. Они называют этот подход «справедливостью через осведомленность » ( FTA ) именно в качестве противовеса FTU, поскольку они подчеркивают важность выбора подходящего показателя расстояния, связанного с целью, чтобы оценить, какие люди похожи в конкретных ситуациях. Опять же, эта проблема во многом связана с поднятым выше вопросом о том, какие переменные можно считать «законными» в определенных контекстах.
Метрики, основанные на причинно-следственной связи [ править ]
Причинная справедливость измеряет частоту, с которой два почти идентичных пользователя или приложения, различающиеся только набором характеристик, в отношении которых распределение ресурсов должно быть справедливым, получают одинаковое обращение. [42] [ сомнительно – обсудить ]
Целая отрасль академических исследований показателей справедливости посвящена использованию причинно-следственных моделей для оценки предвзятости в моделях машинного обучения . Этот подход обычно оправдывается тем фактом, что одно и то же распределение данных наблюдений может скрывать различные причинно-следственные связи между действующими переменными, возможно, с разными интерпретациями того, влияет ли на результат какая-либо форма систематической ошибки или нет. [30]
Куснер и др. [43] предложить использовать контрфактические ситуации и определить процесс принятия решений как контрфактически справедливый , если для любого человека результат не меняется в контрфактическом сценарии, в котором изменяются чувствительные атрибуты. Математическая формулировка гласит:

то есть: взят случайный человек с чувствительным атрибутом и другие особенности и тот же человек, если бы она имела , они должны иметь одинаковые шансы быть принятыми.Символ представляет собой контрфактическую случайную величину в сценарии, где конфиденциальный атрибут фиксируется на . Кондиционирование включено означает, что это требование действует на индивидуальном уровне, поскольку мы обуславливаем все переменные, определяющие одно наблюдение.





Модели машинного обучения часто обучаются на данных, результат которых зависит от решения, принятого в тот момент. [44] Например, если модель машинного обучения должна определить, произойдет ли рецидив у заключенного, и определить, следует ли его освободить досрочно, результат может зависеть от того, был ли заключенный освобожден досрочно или нет. Мишлер и др. [45] предложить формулу для контрфактического уравнивания шансов:

где является случайной величиной, обозначает результат при условии, что решение был взят, и это чувствительная функция.


Плечко и Барейнбойм [46] предложить единую структуру для проведения причинно-следственного анализа справедливости. Они предлагают использовать Стандартную модель справедливости , состоящую из причинно-следственного графа с 4 типами переменных:
- конфиденциальные атрибуты ( ),
- целевая переменная ( ),
- посредники ( ) между и , представляющий возможное косвенное влияние чувствительных атрибутов на результат,
- переменные, возможно, имеющие общую причину с ( ), представляющий возможные ложные (т. е. не причинные) эффекты чувствительных атрибутов на результат.


В этой связи Плечко и Барейнбойм [46] Таким образом, они могут классифицировать возможные эффекты, которые чувствительные атрибуты могут оказать на результат. Более того, степень детализации, с которой измеряются эти эффекты, а именно, обусловливающие переменные, используемые для усреднения эффекта, напрямую связана с аспектом оценки справедливости «индивидуальный и групповой».
Стратегии предвзятости смягчения
Справедливость можно применять к алгоритмам машинного обучения тремя различными способами: предварительная обработка данных , оптимизация во время обучения программного обеспечения или результаты постобработки алгоритма.
Предварительная обработка [ править ]
Обычно классификатор — не единственная проблема; набор данных также является предвзятым. Дискриминация набора данных по отношению к группе можно определить следующим образом:



То есть аппроксимация разницы между вероятностями принадлежности к положительному классу при условии, что субъект имеет защищенную характеристику, отличную от и равен .

Алгоритмы, исправляющие предвзятость при предварительной обработке, удаляют информацию о переменных набора данных, которая может привести к несправедливым решениям, пытаясь при этом изменить как можно меньше. Это не так просто, как просто удалить конфиденциальную переменную, поскольку с защищенной можно сопоставить другие атрибуты.
Способ сделать это — сопоставить каждого человека в исходном наборе данных с промежуточным представлением, в котором невозможно определить, принадлежит ли он к определенной защищенной группе, сохраняя при этом как можно больше информации. Затем новое представление данных корректируется для достижения максимальной точности алгоритма.
Таким образом, отдельные лица отображаются в новом многопараметрическом представлении, где вероятность того, что любой член защищенной группы будет сопоставлен с определенным значением в новом представлении, такая же, как вероятность того, что человек не принадлежит к защищенной группе. . Затем это представление используется для получения прогноза для человека вместо исходных данных. Поскольку промежуточное представление построено так, что дает одинаковую вероятность лицам внутри и за пределами защищенной группы, этот атрибут скрыт для классификатора.
Пример поясняется Zemel et al. [47] где полиномиальная случайная величина в качестве промежуточного представления используется . При этом системе рекомендуется сохранять всю информацию, кроме той, которая может привести к необъективным решениям, и получать максимально точный прогноз.
С одной стороны, эта процедура имеет то преимущество, что предварительно обработанные данные можно использовать для любой задачи машинного обучения. Более того, классификатор не нужно модифицировать, поскольку коррекция применяется к набору данных перед обработкой. С другой стороны, другие методы дают лучшие результаты в плане точности и справедливости. [ нужна ссылка ]
Повторное взвешивание [ править ]
Повторное взвешивание является примером алгоритма предварительной обработки. Идея состоит в том, чтобы присвоить вес каждой точке набора данных так, чтобы взвешенная дискриминация была равна 0 по отношению к назначенной группе. [48]
Если набор данных была несмещенной чувствительная переменная и целевая переменная будет статистически независимым , а вероятность совместного распределения будет произведением следующих вероятностей:

В действительности, однако, набор данных не является объективным, а переменные не являются статистически независимыми , поэтому наблюдаемая вероятность равна:

Чтобы компенсировать смещение, программа добавляет вес : меньший для предпочтительных объектов и более высокий для неблагоприятных объектов. Для каждого мы получаем:


Когда у нас есть для каждого вес, связанный мы вычисляем взвешенную дискриминацию по отношению к группе следующее:


Можно показать, что после повторного взвешивания эта взвешенная дискриминация равна 0.
В обработке [ править ]
Другой подход заключается в исправлении систематической ошибки во время обучения. Это можно сделать, добавив ограничения к цели оптимизации алгоритма. [49] Эти ограничения вынуждают алгоритм повышать справедливость, сохраняя одинаковые показатели определенных мер для защищенной группы и остальных лиц. Например, мы можем добавить к цели алгоритма условие , что уровень ложных срабатываний одинаков для лиц, входящих в защищенную группу, и лиц, находящихся за ее пределами.
Основными показателями, используемыми в этом подходе, являются уровень ложноположительных результатов, уровень ложноотрицательных результатов и общий уровень ошибочной классификации. К цели алгоритма можно добавить только одно или несколько таких ограничений. Обратите внимание, что равенство ложноотрицательных показателей подразумевает равенство истинно положительных показателей, а это означает равенство возможностей. После добавления ограничений к проблеме она может стать неразрешимой, поэтому может потребоваться их послабление.
Состязательное искажение [ править ]
Мы обучаем два классификатора одновременно с помощью некоторого метода, основанного на градиенте (например: градиентный спуск ). Во-первых, предиктор пытается выполнить задачу прогнозирования. , целевая переменная, заданная , входные данные, изменяя его веса минимизировать некоторую функцию потерь . Во втором случае противник пытается выполнить задачу прогнозирования , чувствительная переменная, заданная путем изменения его весов минимизировать некоторую функцию потерь . [50] Важным моментом здесь является то, что для правильного размножения необходимо вышеизложенное должно относиться к необработанным выводам классификатора, а не к дискретному прогнозу; например, с искусственной нейронной сетью и задачей классификации, может относиться к выходным данным слоя softmax .





Затем мы обновляем минимизировать на каждом этапе обучения в соответствии с градиентом и мы модифицируем по выражению:




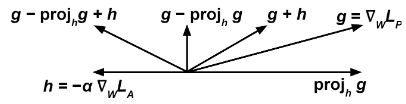
Интуитивная идея заключается в том, что мы хотим, чтобы предиктор пытался минимизировать (поэтому термин ) и в то же время максимизировать (поэтому термин ), так что злоумышленнику не удается предсказать чувствительную переменную по .



Термин не позволяет предиктору двигаться в направлении, которое помогает противнику уменьшить свою функцию потерь.

Можно показать, что обучение модели классификации предикторов с помощью этого алгоритма улучшает демографический паритет по сравнению с обучением без злоумышленника .
Постобработка [ править ]
Последний метод пытается исправить результаты классификатора для достижения справедливости. В этом методе у нас есть классификатор, который возвращает оценку для каждого человека, и нам нужно сделать для них двоичный прогноз. Высокие баллы, скорее всего, дадут положительный результат, тогда как низкие баллы, скорее всего, получат отрицательный результат, но мы можем настроить порог, чтобы определить, когда следует ответить «да», по желанию. Обратите внимание, что вариации порогового значения влияют на компромисс между показателями истинно положительных и истинно отрицательных результатов.
Если функция оценки является справедливой в том смысле, что она не зависит от защищенного атрибута, то любой выбор порога также будет справедливым, но классификаторы этого типа имеют тенденцию быть предвзятыми, поэтому для каждой защищенной группы может потребоваться другой порог. добиться справедливости. [51] Один из способов сделать это — построить график истинно положительного уровня против ложноотрицательного уровня при различных пороговых настройках (это называется кривой ROC) и найти порог, при котором уровни для защищенной группы и других лиц равны. [51]
Отклонить классификацию на основе опций [ править ]
Учитывая классификатор, пусть быть вероятностью, вычисленной классификаторами как вероятность того, что экземпляр относится к положительному классу +. Когда близко к 1 или к 0, экземпляр с высокой степенью достоверности указана принадлежность к классу + или - соответственно. Однако, когда ближе к 0,5 классификация более неясна. [52]

Мы говорим является «отклоненным экземпляром», если с определенным такой, что .



Алгоритм «РОЦ» заключается в классификации неотбракованных экземпляров по приведенному выше правилу и отклоненных экземпляров следующим образом: если экземпляр является примером депривированной группы ( ), то отметьте его как положительный, в противном случае отметьте его как отрицательный.

Мы можем оптимизировать различные меры дискриминации (ссылка) как функции чтобы найти оптимальный по каждой проблеме и избегать дискриминации по отношению к привилегированной группе. [52]
См. также [ править ]
Ссылки [ править ]
- ^ Катон, Саймон; Хаас, Кристиан (04 октября 2020 г.). «Справедливость в машинном обучении: опрос». arXiv : 2010.04053 [ cs.LG ].
- ↑ Перейти обратно: Перейти обратно: а б Мэтту, Джулия Ангвин, Джефф Ларсон, Лорен Киршнер, Сурья. «Машинный уклон» . ПроПублика . Проверено 16 апреля 2022 г.
{{cite web}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Фридлер, Сорель А.; Шайдеггер, Карлос; Венкатасубраманиан, Суреш (апрель 2021 г.). «(Не)возможность справедливости: разные системы ценностей требуют разных механизмов для справедливого принятия решений» . Коммуникации АКМ . 64 (4): 136–143. дои : 10.1145/3433949 . ISSN 0001-0782 . S2CID 1769114 .
- ^ Мехраби, Нинаре; Морстаттер, Фред; Саксена, Нрипсута; Лерман, Кристина; Галстян, Арам (13 июля 2021 г.). «Опрос предвзятости и справедливости в машинном обучении» . Обзоры вычислительной техники ACM . 54 (6): 115:1–115:35. arXiv : 1908.09635 . дои : 10.1145/3457607 . ISSN 0360-0300 . S2CID 201666566 .
- ^ «ИИ Справедливость 360» . aif360.mybluemix.net . Архивировано из оригинала 29 июня 2022 г. Проверено 18 ноября 2022 г.
- ^ «Набор инструментов IBM AI Fairness 360 с открытым исходным кодом добавляет новые функции» . Технологическая республика. 4 июня 2020 г.
- ^ «Ответственная практика ИИ» . Гугл ИИ . Проверено 18 ноября 2022 г.
- ^ Индикаторы справедливости , tensorflow, 10 ноября 2022 г. , получено 18 ноября 2022 г.
- ^ «Как мы используем Fairness Flow, чтобы создать искусственный интеллект, который будет лучше работать для всех» . ai.facebook.com . Проверено 18 ноября 2022 г.
- ^ «Эксперты по искусственному интеллекту предупреждают, что инструмент Facebook для борьбы с предвзятостью «совершенно недостаточен » . ВенчурБит . 31 марта 2021 г. Проверено 18 ноября 2022 г.
- ^ Хатчинсон, Бен; Митчелл, Маргарет (29 января 2019 г.). «50 лет испытаний (не)справедливости». Материалы конференции по справедливости, подотчетности и прозрачности . Нью-Йорк, штат Нью-Йорк, США: ACM FAT*'19. стр. 49–58. arXiv : 1811.10104 . дои : 10.1145/3287560.3287600 . ISBN 9781450361255 .
- ↑ Перейти обратно: Перейти обратно: а б с Луо, Куини; Пуэтт, Майкл Дж.; Смит, Майкл Д. (23 мая 2023 г.), Перспективное зеркало слона: исследование языковой предвзятости в Google, ChatGPT, Википедии и YouTube , arXiv : 2303.16281
- ^ Котек, Хадас; Докум, Риккер; Сан, Дэвид (05.11.2023). «Гендерная предвзятость и стереотипы в моделях большого языка» . Материалы конференции коллективного разума ACM . КИ '23. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 12–24. дои : 10.1145/3582269.3615599 . ISBN 979-8-4007-0113-9 .
- ^ Чжоу, Карен; Тан, Чэньхао (декабрь 2023 г.). Буамор, Хауда; Пино, Хуан; Бали, Калика (ред.). «Оценка политической предвзятости на основе сущностей при автоматическом обобщении» . Выводы Ассоциации компьютерной лингвистики: EMNLP 2023 . Сингапур: Ассоциация компьютерной лингвистики: 10374–10386. arXiv : 2305.02321 . doi : 10.18653/v1/2023.findings-emnlp.696 .
- ^ «Генеральный прокурор Эрик Холдер выступает на 57-м ежегодном собрании Национальной ассоциации адвокатов по уголовным делам и 13-й конференции сети уголовного правосудия штата» . www.justice.gov . 01.08.2014 . Проверено 16 апреля 2022 г.
- ^ Дитрих, Уильям; Мендоса, Кристина; Бреннан, Тим (2016). «Шкалы риска COMPAS: демонстрация справедливости, точности и прогнозируемого паритета» (PDF) . Нортпойнт Инк .
- ^ Ангвин, Джефф Ларсон, Джулия (29 июля 2016 г.). «Технический ответ на Нортпойнт» . ПроПублика . Проверено 18 ноября 2022 г.
{{cite web}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Роуз, Адам (22 января 2010 г.). «Являются ли камеры распознавания лиц расистскими?» . Время . ISSN 0040-781X . Проверено 18 ноября 2022 г.
- ^ «Google приносит извинения за расистскую автоматическую пометку в приложении для фотографий» . Хранитель . 01.07.2015 . Проверено 16 апреля 2022 г.
- ^ «Конкурс красоты судил ИИ, и роботам не понравилась темная кожа» . Хранитель . 08.09.2016 . Проверено 16 апреля 2022 г.
- ↑ Перейти обратно: Перейти обратно: а б Буоламвини, Джой ; Гебру, Тимнит (февраль 2018 г.). Гендерные оттенки: различия в точности в коммерческой гендерной классификации (PDF) . Конференция по справедливости, подотчетности и прозрачности. Нью-Йорк, штат Нью-Йорк, США. стр. 77–91.
- ^ «Студент доказывает, что алгоритм Твиттера «склонен» к более светлым, стройным и молодым лицам» . Хранитель . 10 августа 2021 г. Проверено 18 ноября 2022 г.
- ^ openai/dalle-2-preview , OpenAI, 17 ноября 2022 г. , получено 18 ноября 2022 г.
- ^ «Amazon отказывается от секретного инструмента рекрутинга, основанного на искусственном интеллекте, который показал предвзятое отношение к женщинам» . Рейтер . 10.10.2018 . Проверено 18 ноября 2022 г.
- ^ «Алгоритм Apple Card вызывает обвинения в гендерной предвзятости против Goldman Sachs» . Вашингтон Пост . ISSN 0190-8286 . Проверено 18 ноября 2022 г.
- ^ Мартинес, Эммануэль; Киршнер, Лорен (25 августа 2021 г.). «Секретная предвзятость, скрытая в алгоритмах одобрения ипотеки - наценка» . themarkup.org . Проверено 18 ноября 2022 г.
- ^ Руджери, Сальваторе; Альварес, Хосе М.; Пуньяна, Андреа; Стэйт, Лаура; Турини, Франко (26 июня 2023 г.). «Можем ли мы доверять справедливому искусственному интеллекту?» . Материалы конференции AAAI по искусственному интеллекту . 37 (13). Ассоциация по развитию искусственного интеллекта (AAAI): 15421–15430. дои : 10.1609/aaai.v37i13.26798 . hdl : 11384/136444 . ISSN 2374-3468 . S2CID 259678387 .
- ^ Буйл, Мартен; Де Би, Тейл (2022). «Неотъемлемые ограничения справедливости ИИ». Коммуникации АКМ . 67 (2): 48–55. arXiv : 2212.06495 . дои : 10.1145/3624700 . hdl : 1854/LU-01GMNH04RGNVWJ730BJJXGCY99 .
- ^ Кастельново, Алессандро; Инверарди, Николь; Нанино, Габриэле; Пенко, Илария Джузеппина; Реголи, Даниэле (2023). «Достаточно справедливо? Карта текущих ограничений требований к «честным алгоритмам». arXiv : 2311.12435 [ cs.AI ].
- ↑ Перейти обратно: Перейти обратно: а б с д Солон Барокас; Мориц Хардт; Арвинд Нараянан, Справедливость и машинное обучение . Проверено 15 декабря 2019 г.
- ^ Мэйс, Элизабет (2001). Справочник по кредитному скорингу . Нью-Йорк, Нью-Йорк, США: Glenlake Publishing. п. 282. ИСБН 0-8144-0619-Х .
- ^ Берк, Ричард; Хейдари, Хода; Джаббари, Шахин; Кернс, Майкл; Рот, Аарон (февраль 2021 г.). «Справедливость в оценке рисков уголовного правосудия: современное состояние» . Социологические методы и исследования . 50 (1): 3–44. arXiv : 1703.09207 . дои : 10.1177/0049124118782533 . ISSN 0049-1241 . S2CID 12924416 .
- ↑ Перейти обратно: Перейти обратно: а б Раз, Тим (3 марта 2021 г.). «Групповая справедливость: новый взгляд на независимость» . Материалы конференции ACM 2021 года по вопросам справедливости, подотчетности и прозрачности . АКМ. стр. 129–137. arXiv : 2101.02968 . дои : 10.1145/3442188.3445876 . ISBN 978-1-4503-8309-7 . S2CID 231667399 .
- ↑ Перейти обратно: Перейти обратно: а б с Верма, Сахил; Рубин, Юлия (2018). «Разъяснение определений справедливости» . Материалы международного семинара по честности программного обеспечения . стр. 1–7. дои : 10.1145/3194770.3194776 . ISBN 9781450357463 . S2CID 49561627 .
- ^ Гурсой, Фуркан; Какадиарис, Иоаннис А. (ноябрь 2022 г.). «Равная путаница, справедливость: измерение групповых различий в автоматизированных системах принятия решений» . Семинары Международной конференции IEEE по интеллектуальному анализу данных 2022 года (ICDMW) . IEEE. стр. 137–146. arXiv : 2307.00472 . дои : 10.1109/ICDMW58026.2022.00027 . ISBN 979-8-3503-4609-1 . S2CID 256669476 .
- ^ Чен, Вайолет (Синьин); Хукер, JN (2021). «Справедливость, основанная на благосостоянии через оптимизацию». arXiv : 2102.00311 [ cs.AI ].
- ^ Муллайнатан, Сендхил (19 июня 2018 г.). Алгоритмическая справедливость и функция социального благосостояния . Основной доклад на 19-й конференции ACM по экономике и вычислениям (EC'18) . Ютуб. 48 минут.
Другими словами, если у вас есть функция социального обеспечения, где вас волнует вред, и вы заботитесь о вреде афроамериканцам, вот и все: на 12 процентов меньше афроамериканцев, находящихся в тюрьме за одну ночь.... До мы вникаем в детали относительного вреда, функция благосостояния определяется как абсолютный вред, поэтому нам следует сначала рассчитать абсолютный вред.
- ^ Митчелл, Шира; Поташ, Эрик; Барокас, Солон; д'Амур, Александр; Лам, Кристиан (2021). «Алгоритмическая справедливость: выбор, предположения и определения» . Ежегодный обзор статистики и ее применения . 8 (1): 141–163. arXiv : 1811.07867 . Бибкод : 2021AnRSA...8..141M . doi : 10.1146/annurev-statistics-042720-125902 . S2CID 228893833 .
- ^ Кастельново, Алессандро; Крупи, Риккардо; Греко, Грета; Реголи, Даниэле; Пенко, Илария Джузеппина; Козентини, Андреа Клаудио (2022). «Разъяснение нюансов в сфере показателей справедливости» . Научные отчеты . 12 (1): 4209. arXiv : 2106.00467 . Бибкод : 2022NatSR..12.4209C . дои : 10.1038/s41598-022-07939-1 . ПМЦ 8913820 . ПМИД 35273279 .
- ^ Мехраби, Нинаре, Фред Морстаттер, Нрипсута Саксена, Кристина Лерман и Арам Галстян. «Опрос о предвзятости и справедливости в машинном обучении». Обзоры вычислительных систем ACM (CSUR) 54, вып. 6 (2021): 1–35.
- ^ Дворк, Синтия; Хардт, Мориц; Питасси, Тонианн; Рейнгольд, Омер; Земель, Ричард (2012). «Справедливость через осознанность» . Материалы 3-й конференции «Инновации в теоретической информатике» - ITCS '12 . стр. 214–226. дои : 10.1145/2090236.2090255 . ISBN 9781450311151 . S2CID 13496699 .
- ^ Галхотра, Сайньям; Брун, Юрий; Мелиу, Александра (2017). «Тестирование справедливости: тестирование программного обеспечения на предмет дискриминации». Материалы 11-го совместного совещания по основам программной инженерии 2017 г. стр. 498–510. arXiv : 1709.03221 . дои : 10.1145/3106237.3106277 . ISBN 9781450351058 . S2CID 6324652 .
- ^ Куснер, М.Дж., Лофтус, Дж., Рассел, К., и Сильва, Р. (2017). Контрфактическая справедливость . Достижения в области нейронных систем обработки информации, 30.
- ^ Костон, Аманда; Мишлер, Алан; Кеннеди, Эдвард Х.; Чулдехова, Александра (27 января 2020 г.). «Контрфактические оценки риска, оценка и справедливость». Материалы конференции 2020 года по справедливости, подотчетности и прозрачности . ЖИР* '20. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 582–593. дои : 10.1145/3351095.3372851 . ISBN 978-1-4503-6936-7 . S2CID 202539649 .
- ^ Мишлер, Алан; Кеннеди, Эдвард Х.; Чульдехова, Александра (01 марта 2021 г.). «Справедливость инструментов оценки рисков». Материалы конференции ACM 2021 года по вопросам справедливости, подотчетности и прозрачности . ФАКТ '21. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 386–400. дои : 10.1145/3442188.3445902 . ISBN 978-1-4503-8309-7 . S2CID 221516412 .
- ↑ Перейти обратно: Перейти обратно: а б Плечко, Драго; Барейнбойм, Элиас (2022). «Анализ причинно-следственной справедливости». arXiv : 2207.11385 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Ричард Земель; Ю (Леделл) Ву; Кевин Сверски; Тонианн Питасси; Синтия Дворк, «Изучение честного представительства» . Проверено 1 декабря 2019 г.
- ^ Фейсал Камиран; Тун Колдерс, Методы предварительной обработки данных для классификации без дискриминации . Проверено 17 декабря 2019 г.
- ^ Мухаммад Билал Зафар; Изабель Валера; Мануэль Гомес Родригес; Кришна П. Гуммади, Справедливость за пределами разного обращения и разного воздействия: классификация обучения без разного жестокого обращения . Проверено 1 декабря 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б Брайан Ху Чжан; Блейк Лемуан; Маргарет Митчелл, Смягчение нежелательных искажений с помощью состязательного обучения . Проверено 17 декабря 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б Мориц Хардт; Эрик Прайс; Натан Сребро, Равенство возможностей в контролируемом обучении . Проверено 1 декабря 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б Фейсал Камиран; Асим Карим; Сянлян Чжан, Теория принятия решений для классификации с учетом дискриминации . Проверено 17 декабря 2019 г.