Датазавра дюжина
| Часть серии по статистике. |
| Визуализация данных и информации |
|---|
| Основные размеры |
| Важные цифры |
| Информационные графические типы |
|
| Связанные темы |
включает Дюжина Датазавра в себя тринадцать наборов данных , которые имеют почти идентичную простую описательную статистику с точностью до двух знаков после запятой, но имеют очень разные распределения и выглядят очень разными при построении графиков . [1] Он был вдохновлен меньшим квартетом Анскомба , созданным в 1973 году.
Данные
[ редактировать ]В следующей таблице представлена сводная статистика для всех тринадцати наборов данных.
| Свойство | Ценить | Точность |
|---|---|---|
| Количество элементов | 142 | точный |
| Среднее значение х | 54.26 | до 2 десятичных знаков |
| Выборочная дисперсия x : s 2 х |
16.76 | до 2 десятичных знаков |
| Среднее значение у | 47.83 | до 2 десятичных знаков |
| Выборочная дисперсия y : s 2 и |
26.93 | до 2 десятичных знаков |
| Корреляция между x и y | −0.06 | до 3 десятичных знаков |
| линейной регрессии Линия | у = 53 - 0,1 х | до 0 и 1 десятичного знака соответственно |
| Коэффициент детерминации линейной регрессии: | 0.004 | до 3 десятичных знаков |

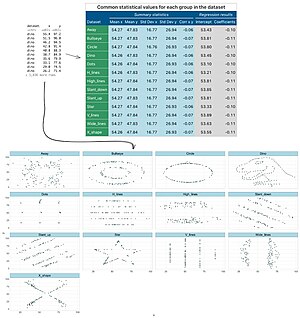
Тринадцать наборов данных были помечены следующим образом:
- прочь
- яблочко
- круг
- динозавр
- точки
- h_lines
- high_lines
- наклон_вниз
- наклон_вверх
- звезда
- v_line
- широкие_линии
- х_форма
Подобно квартету Анскомба , дюжина Datasaurus была разработана для дальнейшей иллюстрации важности графического просмотра набора данных перед началом анализа в соответствии с определенным типом отношений, а также недостаточности основных статистических свойств для описания реалистичных наборов данных. [2] [3] [4] [5] [1] [6]
Создание
[ редактировать ]
Первый набор данных в форме тираннозавра , который вдохновил остальную часть набора данных «датазавра», был создан в 2016 году Альберто Каиро . [7] [8] Маартен Ламбрехтс предложил назвать этот набор данных также «Анскомбозавр». [7]
Затем этот набор данных сопровождался двенадцатью другими наборами данных, созданными Джастином Матейкой и Джорджем Фицморисом из Autodesk . В отличие от квартета Анскомба, где неизвестно, как был сгенерирован набор данных, [9] для создания этих наборов данных авторы использовали моделирование отжига . Они внесли небольшие, случайные и необъективные изменения в каждую точку в направлении желаемой формы. Для создания каждой формы потребовалось 200 000 итераций возмущений. [1]
Псевдокод : этого алгоритма выглядит следующим образом
current_ds ← initial_ds
for x iterations, do:
test_ds ← perturb(current_ds, temp)
if similar_enough(test_ds, initial_ds):
current_ds ← test_ds
function perturb(ds, temp):
loop:
test ← move_random_points(ds)
if fit(test) > fit(ds) or temp > random():
return test
где
initial_dsэто исходный набор данныхcurrent_dsэто последняя версия набора данныхfit()это функция, используемая для проверки того, приближается ли перемещение точек к желаемой формеtemp— температура алгоритма моделирования отжига0similar_enough()это функция, которая проверяет, достаточно ли схожа статистика для двух заданных наборов данныхmove_random_points()это функция, которая случайным образом перемещает точки данных
См. также
[ редактировать ]- Исследовательский анализ данных
- Хорошая посадка
- Проверка регрессии
- Парадокс Симпсона
- Статистическая проверка модели
- квартет Анскомба
Ссылки
[ редактировать ]- ^ Перейти обратно: а б с Матейка, Джастин; Фицморис, Джордж (2 мая 2017 г.). «Одинаковая статистика, разные графики: создание наборов данных с разным внешним видом и идентичной статистикой посредством моделирования отжига» (PDF) . Материалы конференции CHI 2017 года по человеческому фактору в вычислительных системах . ЧИ '17. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники: 1290–1294. дои : 10.1145/3025453.3025912 . ISBN 978-1-4503-4655-9 . Архивировано из оригинала 2 мая 2017 г.
- ^ Элерт, Гленн (2021). «Линейная регрессия» . Гиперучебник по физике .
- ^ Джанерт, Филипп К. (2010). Анализ данных с помощью инструментов с открытым исходным кодом . О'Рейли Медиа . стр. 65–66 . ISBN 978-0-596-80235-6 .
- ^ Чаттерджи, Самприт; Хади, Али С. (2006). Регрессионный анализ на примере . Джон Уайли и сыновья. п. 91. ИСБН 0-471-74696-7 .
- ^ Сэвилл, Дэвид Дж.; Вуд, Грэм Р. (1991). Статистические методы: Геометрический подход . Спрингер . п. 418. ИСБН 0-387-97517-9 .
- ^ Тафти, Эдвард Р. (2001). Визуальное отображение количественной информации (2-е изд.). Чешир, Коннектикут: Graphics Press. ISBN 0-9613921-4-2 .
- ^ Перейти обратно: а б Каир, Альберто. «Загрузите Datasaurus: никогда не доверяйте только сводной статистике; всегда визуализируйте свои данные» . Проверено 1 февраля 2024 г.
- ^ Мурта, Джек (01 февраля 2024 г.). «Чему этот график динозавра может научить нас в области более эффективной науки» . Научный американец . Проверено 8 марта 2024 г.
- ^ Чаттерджи, Сангит; Фират, Айкут (2007). «Генерация данных с идентичной статистикой, но с разной графикой: продолжение набора данных Анскомба». Американский статистик . 61 (3): 248–254. дои : 10.1198/000313007X220057 . JSTOR 27643902 . S2CID 121163371 .
Внешние ссылки
[ редактировать ]- Анимированные примеры от Autodesk для наборов данных Datasaurus Dozen
- datasauRus , наборы данных из Datasaurus Dozen в R
- Дюжина Datasaurus в формате CSV и файлах с разделителями табуляцией https://www.openintro.org/data/index.php?data=datasaurus