Интеграция данных
Интеграция данных предполагает объединение данных , находящихся в разных источниках, и предоставление пользователям единого представления о них. [ 1 ] Этот процесс становится важным в различных ситуациях, которые включают как коммерческую (например, когда двум схожим компаниям необходимо объединить свои базы данных объединение результатов исследований из разных репозиториев биоинформатики ), так и научную ( например, ) области. Интеграция данных возникает все чаще по мере увеличения объема, сложности (то есть больших данных ) и необходимости совместного использования существующих данных . [ 2 ] Это стало предметом обширной теоретической работы, и многие открытые проблемы остаются нерешенными. Интеграция данных способствует сотрудничеству между внутренними и внешними пользователями. Интегрируемые данные должны быть получены из гетерогенной системы баз данных и преобразованы в единое согласованное хранилище данных, которое обеспечивает синхронные данные по сети файлов для клиентов. [ 3 ] Обычно интеграция данных используется в интеллектуальном анализе данных при анализе и извлечении информации из существующих баз данных, которая может быть полезна для бизнес-информации . [ 4 ]
История
[ редактировать ]
Проблемы с объединением разнородных источников данных, часто называемые информационными хранилищами , в рамках единого интерфейса запросов, существуют уже некоторое время. В начале 1980-х годов ученые-компьютерщики начали разрабатывать системы для взаимодействия разнородных баз данных. [ 5 ] Первая система интеграции данных, основанная на структурированных метаданных, была разработана в Университете Миннесоты в 1991 году для серии интегрированных микроданных общего пользования (IPUMS) . IPUMS использовал подход к хранилищу данных , который извлекает, преобразует и загружает данные из разнородных источников в уникальную схему представления , благодаря чему данные из разных источников становятся совместимыми. [ 6 ] Обеспечив совместимость тысяч баз данных о населении, IPUMS продемонстрировала возможность крупномасштабной интеграции данных. Подход к хранилищу данных предлагает тесно связанную архитектуру, поскольку данные уже физически согласованы в одном репозитории, доступном для запросов, поэтому разрешение запросов обычно занимает мало времени. [ 7 ]
Подход к хранилищу данных менее осуществим для наборов данных, которые часто обновляются, требуя извлечения, преобразования, загрузки постоянного повторного выполнения процесса (ETL) для синхронизации. Трудности возникают также при построении хранилищ данных, когда имеется только интерфейс запросов к сводным источникам данных и нет доступа к полным данным. Эта проблема часто возникает при интеграции нескольких коммерческих сервисов запросов, таких как веб-приложения для путешествий или тематической рекламы.
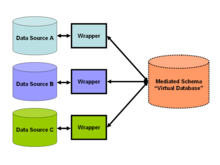
По состоянию на 2009 год [update] тенденция в интеграции данных благоприятствовала слабой связи данных [ 8 ] и предоставление унифицированного интерфейса запросов для доступа к данным в реальном времени по опосредованной схеме (см. рисунок 2), что позволяет извлекать информацию непосредственно из исходных баз данных. Это соответствует подходу SOA, популярному в ту эпоху. Этот подход основан на сопоставлении между опосредованной схемой и схемой исходных источников и преобразовании запроса в декомпозированные запросы для соответствия схеме исходных баз данных. Такие сопоставления можно задать двумя способами: как сопоставление сущностей в опосредованной схеме с сущностями в исходных источниках («Global-as-View»). [ 9 ] (GAV)), или как сопоставление сущностей в исходных источниках с опосредованной схемой («Локальный как представление»). [ 10 ] (LAV) подход). Последний подход требует более сложных выводов для разрешения запроса к опосредованной схеме, но упрощает добавление новых источников данных в (стабильную) опосредованную схему.
По состоянию на 2010 год [update] некоторая работа по исследованию интеграции данных касается проблемы семантической интеграции . Эта проблема касается не структурирования архитектуры интеграции, а разрешения семантических конфликтов между разнородными источниками данных. Например, если две компании объединяют свои базы данных, некоторые понятия и определения в их соответствующих схемах, такие как «прибыль», неизбежно будут иметь разные значения. В одной базе данных это может означать прибыль в долларах (число с плавающей запятой), а в другой — количество продаж (целое число). Общая стратегия решения таких проблем предполагает использование онтологий , которые явно определяют термины схемы и, таким образом, помогают разрешать семантические конфликты. Этот подход представляет собой интеграцию данных на основе онтологий . С другой стороны, проблема объединения результатов исследований из разных репозиториев биоинформатики требует сравнительного анализа сходств, вычисленных на основе разных источников данных, по одному критерию, такому как положительная прогностическая ценность. Это позволяет напрямую сравнивать источники данных и интегрировать их, даже если характер экспериментов различен. [ 11 ]
По состоянию на 2011 год [update] Было установлено, что современные методы моделирования данных обеспечивают изоляцию данных в каждой архитектуре данных в виде островов разрозненных данных и информационных хранилищ. Такая изоляция данных является непреднамеренным артефактом методологии моделирования данных, который приводит к разработке несопоставимых моделей данных. Разные модели данных, созданные в виде баз данных, образуют разные базы данных. Методологии усовершенствованных моделей данных были разработаны для устранения артефакта изоляции данных и содействия разработке интегрированных моделей данных. [ 12 ] Один из усовершенствованных методов моделирования данных изменяет модели данных, дополняя их структурными метаданными в форме стандартизированных объектов данных. В результате преобразования нескольких моделей данных набор преобразованных моделей данных теперь будет иметь одно или несколько отношений общности, которые связывают структурные метаданные, которые теперь являются общими для этих моделей данных. Отношения общности — это одноранговые отношения сущностей, которые связывают стандартизированные сущности данных нескольких моделей данных. Несколько моделей данных, которые содержат один и тот же стандартный объект данных, могут участвовать в одних и тех же отношениях общности. Когда интегрированные модели данных создаются в виде баз данных и правильно заполняются из общего набора основных данных, тогда эти базы данных интегрируются.
С 2011 года подходы к концентратору данных вызывают больший интерес, чем полностью структурированные (обычно реляционные) корпоративные хранилища данных. С 2013 года подходы к озерам данных поднялись до уровня центров данных. (Смотрите популярность всех трех поисковых запросов в Google Trends. [ 13 ] ) Эти подходы объединяют неструктурированные или разнообразные данные в одном месте, но не обязательно требуют (часто сложной) главной реляционной схемы для структурирования и определения всех данных в Hub.
Интеграция данных играет большую роль в бизнесе в плане сбора данных , используемых для изучения рынка. Преобразование необработанных данных, полученных от потребителей, в последовательные данные — это то, что предприятия пытаются сделать, обдумывая, какие шаги им следует предпринять дальше. [ 14 ] Организации все чаще используют интеллектуальный анализ данных для сбора информации и закономерностей из своих баз данных, и этот процесс помогает им разрабатывать новые бизнес-стратегии для повышения эффективности бизнеса и более эффективного проведения экономического анализа. Сбор большого объема данных, которые они собирают для хранения в своей системе, представляет собой форму интеграции данных, адаптированную для бизнес-аналитики и повышающую их шансы на успех. [ 15 ]
Пример
[ редактировать ]Рассмотрим веб-приложение , в котором пользователь может запрашивать различную информацию о городах (например, статистику преступности, погоду, отели, демографию и т. д.). Традиционно информация должна храниться в одной базе данных с единой схемой. Однако сбор информации такого масштаба для любого отдельного предприятия будет трудным и дорогостоящим. Даже если существуют ресурсы для сбора данных, они, скорее всего, будут дублировать данные в существующих базах данных о преступности, веб-сайтах с погодой и данных переписи населения.
Решение по интеграции данных может решить эту проблему, рассматривая эти внешние ресурсы как материализованные представления виртуальной опосредованной схемы , что приводит к «виртуальной интеграции данных». Это означает, что разработчики приложений создают виртуальную схему ( опосредованную схему ) для наилучшего моделирования тех ответов, которые нужны пользователям. Затем они разрабатывают «обертки» или адаптеры для каждого источника данных, например базы данных о преступлениях и веб-сайта погоды. Эти адаптеры просто преобразуют результаты локальных запросов (те, которые возвращаются соответствующими веб-сайтами или базами данных) в легко обрабатываемую форму для решения по интеграции данных (см. рисунок 2). Когда пользователь приложения запрашивает промежуточную схему, решение по интеграции данных преобразует этот запрос в соответствующие запросы к соответствующим источникам данных. Наконец, виртуальная база данных объединяет результаты этих запросов в ответ на запрос пользователя.
Это решение обеспечивает удобство добавления новых источников путем простого создания для них адаптера или прикладного программного обеспечения. Это контрастирует с системами ETL или решением с единой базой данных, которые требуют ручной интеграции всего нового набора данных в систему. Виртуальные решения ETL используют виртуальную опосредованную схему для реализации гармонизации данных; при этом данные копируются из назначенного «главного» источника в определенные цели, поле за полем. Расширенная виртуализация данных также основана на концепции объектно-ориентированного моделирования для создания виртуальной опосредованной схемы или виртуального хранилища метаданных с использованием звездообразной архитектуры.
Каждый источник данных несоизмерим и поэтому не предназначен для поддержки надежных соединений между источниками данных. Таким образом, виртуализация данных, а также объединение данных зависят от случайной общности данных для поддержки объединения данных и информации из разрозненных наборов данных. Из-за отсутствия общности значений данных в разных источниках данных возвращаемый набор может быть неточным, неполным и его невозможно проверить.
Одним из решений является переработка разрозненных баз данных для их интеграции без необходимости использования ETL . Переработанные базы данных поддерживают ограничения общности, при которых между базами данных может быть обеспечена ссылочная целостность. Переработанные базы данных обеспечивают разработанные пути доступа к данным с общностью значений данных во всех базах данных.
Теория
[ редактировать ]Теория интеграции данных [ 1 ] формирует подмножество теории баз данных и формализует основные концепции проблемы в логике первого порядка . Применение теорий дает представление о возможности и сложности интеграции данных. Хотя его определения могут показаться абстрактными, они обладают достаточной общностью, чтобы соответствовать всем видам интеграционных систем. [ 16 ] включая те, которые включают вложенные реляционные/XML базы данных [ 17 ] и те, которые рассматривают базы данных как программы. [ 18 ] Соединения с конкретными системами баз данных, такими как Oracle или DB2, обеспечиваются технологиями уровня реализации, такими как JDBC , и не изучаются на теоретическом уровне.
Определения
[ редактировать ]Системы интеграции данных формально определяются как кортеж где это глобальная (или опосредованная) схема, - это гетерогенный набор исходных схем, и — это сопоставление, которое сопоставляет запросы между источником и глобальными схемами. Оба и выражаются в языках посредством алфавитов, состоящих из символов для каждого из соответствующих отношений . Отображение состоит из утверждений между запросами по и вопросы более . Когда пользователи задают вопросы в системе интеграции данных, они задают вопросы и затем отображение устанавливает связи между элементами глобальной схемы и исходными схемами.




База данных по схеме определяется как набор наборов, по одному для каждого отношения (в реляционной базе данных). База данных, соответствующая исходной схеме. будет включать набор наборов кортежей для каждого из гетерогенных источников данных и называется исходной базой данных . Обратите внимание, что эта база данных с одним источником может на самом деле представлять собой набор несвязанных баз данных. База данных, соответствующая виртуальной опосредованной схеме. называется глобальной базой данных . Глобальная база данных должна удовлетворять отображению относительно исходной базы данных. Законность такого сопоставления зависит от характера переписки между и . Существует два популярных способа моделирования этого соответствия: глобальный как View или GAV и локальный как View или LAV.

Системы GAV моделируют глобальную базу данных как представлений набор . В этом случае ассоциируется с каждым элементом запрос более . Обработка запросов становится простой операцией благодаря четко определенным связям между и . Бремя сложности ложится на реализацию кода-посредника, который точно инструктирует систему интеграции данных, как извлекать элементы из исходных баз данных. Если к системе присоединяются какие-либо новые источники, могут потребоваться значительные усилия для обновления посредника, поэтому подход GAV представляется предпочтительным, когда кажется маловероятным, что источники изменятся.
В подходе GAV к приведенному выше примеру системы интеграции данных разработчик системы сначала разрабатывает посредники для каждого из городских источников информации, а затем разрабатывает глобальную схему вокруг этих посредников. Например, предположим, что один из источников обслуживал веб-сайт погоды. Затем дизайнер, скорее всего, добавит в глобальную схему соответствующий элемент погоды. Затем основная часть усилий концентрируется на написании надлежащего кода-посредника, который преобразует предикаты о погоде в запрос на веб-сайте погоды. Эта работа может усложниться, если какой-либо другой источник также связан с погодой, поскольку разработчику может потребоваться написать код для правильного объединения результатов из двух источников.
С другой стороны, в LAV исходная база данных моделируется как представлений набор . В этом случае ассоциируется с каждым элементом запрос более . Вот точные ассоциации между и уже не имеют четкого определения. Как показано в следующем разделе, бремя определения того, как извлекать элементы из источников, возлагается на процессор запросов. Преимущество моделирования LAV заключается в том, что новые источники могут быть добавлены с гораздо меньшими усилиями, чем в системе GAV, поэтому подходу LAV следует отдавать предпочтение в тех случаях, когда опосредованная схема менее стабильна или может измениться. [ 1 ]
В подходе LAV к приведенному выше примеру системы интеграции данных разработчик системы сначала разрабатывает глобальную схему, а затем просто вводит схемы соответствующих источников информации о городе. Рассмотрим еще раз, если один из источников обслуживает веб-сайт погоды. Дизайнер будет добавлять соответствующие элементы погоды в глобальную схему, только если их еще не существует. Затем программисты пишут адаптер или обертку для сайта и добавляют в исходные схемы описание схемы результатов работы сайта. Сложность добавления нового источника переходит от дизайнера к обработчику запросов.
Обработка запросов
[ редактировать ]Теория обработки запросов в системах интеграции данных обычно выражается с использованием конъюнктивных запросов и Datalog , чисто декларативного логического языка программирования . [ 20 ] Можно условно представить себе конъюнктивный запрос как логическую функцию, применяемую к отношениям в базе данных, например: где ". Если кортеж или набор кортежей подставляются в правило и удовлетворяют ему (делают его истинным), то мы рассматриваем этот кортеж как часть набора ответов в запросе. В то время как формальные языки, такие как Datalog, выражают эти запросы кратко и без двусмысленности, общие запросы SQL также считаются конъюнктивными запросами.


С точки зрения интеграции данных «содержание запроса» представляет собой важное свойство конъюнктивных запросов. Запрос содержит другой запрос (обозначается ) если результаты применения являются подмножеством результатов применения для любой базы данных. Два запроса называются эквивалентными, если результирующие наборы одинаковы для любой базы данных. Это важно, поскольку как в системах GAV, так и в LAV пользователь задает конъюнктивные запросы к виртуальной схеме, представленной набором представлений , или «материализованных» конъюнктивных запросов. Интеграция стремится переписать запросы, представленные представлениями, чтобы сделать их результаты эквивалентными или максимально содержащимися в запросе нашего пользователя. Это соответствует проблеме ответа на запросы с использованием представлений ( AQUV ). [ 21 ]



В системах GAV разработчик системы пишет код-посредник, определяющий переписывание запроса. Каждый элемент в пользовательском запросе соответствует правилу замены точно так же, как каждый элемент в глобальной схеме соответствует запросу к источнику. Обработка запроса просто расширяет подцели пользовательского запроса в соответствии с правилом, указанным в посреднике, и поэтому результирующий запрос, скорее всего, будет эквивалентным. Хотя проектировщик выполняет большую часть работы заранее, некоторые системы GAV, такие как Tsimmis, предполагают упрощение процесса описания посредника.
В системах LAV запросы подвергаются более радикальному процессу переписывания, поскольку не существует посредника, который мог бы согласовать запрос пользователя с простой стратегией расширения. Система интеграции должна выполнить поиск по пространству возможных запросов, чтобы найти лучшую перезапись. Результирующая перезапись может не быть эквивалентным запросом, но максимально содержаться, а результирующие кортежи могут быть неполными. По состоянию на 2011 год [update] алгоритм GQR [ 22 ] является ведущим алгоритмом перезаписи запросов для систем интеграции данных LAV.
В общем, сложность переписывания запроса NP-полная . [ 21 ] Если пространство перезаписи относительно невелико, это не представляет проблемы — даже для систем интеграции с сотнями источников.
Медицина и науки о жизни
[ редактировать ]Крупномасштабные научные вопросы, такие как фактические данные из реального мира , глобальное потепление , распространение инвазивных видов и истощение ресурсов , все чаще требуют сбора разрозненных наборов данных для метаанализа . Этот тип интеграции данных особенно сложен для экологических и экологических данных, поскольку стандарты метаданных не согласованы, и в этих областях создается множество различных типов данных. Инициативы Национального научного фонда, такие как Datanet, призваны облегчить интеграцию данных для ученых путем предоставления киберинфраструктуры и установления стандартов. Пять финансируемых Datanet инициатив : DataONE , [ 23 ] под руководством Уильяма Миченера в Университете Нью-Мексико ; Сохранность данных, [ 24 ] под руководством Саида Чоудхури из Университета Джонса Хопкинса ; SEAD: Устойчивая окружающая среда посредством практических данных, [ 25 ] под руководством Маргарет Хедстром из Мичиганского университета ; Консорциум Федерации DataNet, [ 26 ] во главе с Рейганом Муром из Университета Северной Каролины ; и Терра Популус , [ 27 ] под руководством Стивена Рагглза из Университета Миннесоты . Альянс исследовательских данных , [ 28 ] совсем недавно исследовал создание глобальных структур интеграции данных. Проект OpenPHACTS , финансируемый через Европейского Союза Инициативу по инновационным лекарственным средствам , создал платформу для поиска лекарств, объединив наборы данных от таких поставщиков, как Европейский институт биоинформатики , Королевское химическое общество , UniProt , WikiPathways и DrugBank .
См. также
[ редактировать ]- Управление бизнес-семантикой
- Изменить сбор данных
- Интеграция основных данных
- Интеграция данных клиентов
- Киберинфраструктура
- Смешивание данных
- Курирование данных
- Слияние данных
- Сопоставление данных
- Обсуждение данных
- Модель базы данных
- Пространства данных
- Интеграция периферийных данных
- Интеграция корпоративных приложений
- Структура архитектуры предприятия
- Интеграция корпоративной информации (EII)
- Корпоративная интеграция
- Geodi: интеграция геонаучных данных
- Информационная интеграция
- Информационный бункер
- Центр интеграционных компетенций
- Интеграционный консорциум
- ISO 15926 : Интеграция данных жизненного цикла перерабатывающих предприятий, включая предприятия по добыче нефти и газа.
- JXTA
- Управление основными данными
- Объектно-реляционное отображение
- Открыть текст
- Семантическая интеграция
- Соответствие схемы
- Трехсхемный подход
- UDEF
- Интеграция веб-данных
- Веб-сервис
Ссылки
[ редактировать ]- ^ Jump up to: а б с Маурицио Лензерини (2002). «Интеграция данных: теоретическая перспектива» (PDF) . ПОДС 2002 . стр. 233–246.
- ^ Фредерик Лейн (2006). «IDC: В 2006 году в мире создано 161 миллиард гигабайт данных» . Архивировано из оригинала 15 июля 2015 г.
- ^ микбен. «Связность данных — приложения Win32» . docs.microsoft.com . Архивировано из оригинала 12 июня 2020 г. Проверено 23 ноября 2020 г.
- ^ Чунг, П.; Чунг, Ш. (2013–05). «Об интеграции данных и интеллектуальном анализе данных для разработки бизнес-аналитики». Конференция IEEE по системам, приложениям и технологиям Лонг-Айленда (LISAT) , 2013 г.: 1–6. дои : 10.1109/LISAT.2013.6578235.
- ^ Джон Майлз Смит; и др. (1982). «Мультибаза: интеграция гетерогенных распределенных систем баз данных» . AFIPS '81 Материалы Национальной компьютерной конференции, 4–7 мая 1981 г. стр. 487–499.
- ^ Стивен Рагглс , Дж. Дэвид Хакер и Мэтью Собек (1995). «Порядок из хаоса: серия интегрированных микроданных для публичного использования». Исторические методы . Том. 28. С. 33–39.
{{cite news}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Дженнифер Видом (1995). «Исследование проблем в хранилищах данных» . CIKM '95 Материалы Четвертой Международной конференции по управлению информацией и знаниями . стр. 25–30.
- ^ Паутассо, Чезаре; Уайльд, Эрик (20 апреля 2009 г.). «Почему сеть слабосвязана?» . Материалы 18-й международной конференции по Всемирной паутине . WWW '09. Мадрид, Испания: Ассоциация вычислительной техники. стр. 911–920. дои : 10.1145/1526709.1526832 . ISBN 978-1-60558-487-4 . S2CID 207172208 .
- ^ «Что такое GAV (Global as View)?» . Гики для Гиков . 18 апреля 2020 г. Архивировано из оригинала 30 ноября 2020 г. Проверено 23 ноября 2020 г.
- ^ «Local-as-View» , Arc.Ask3.Ru (на немецком языке), 24 июля 2020 г. , получено 23 ноября 2020 г.
- ^ Шубхра С. Рэй; и др. (2009). «Объединение информации из нескольких источников посредством взвешивания на основе функциональных аннотаций: прогнозирование функций генов в дрожжах» (PDF) . Транзакции IEEE по биомедицинской инженерии . 56 (2): 229–236. CiteSeerX 10.1.1.150.7928 . дои : 10.1109/TBME.2008.2005955 . ПМИД 19272921 . S2CID 10848834 . Архивировано (PDF) из оригинала 8 мая 2010 г. Проверено 17 мая 2012 г.
- ^ Майкл Миреку Квакье (2011). «Практический подход к объединению многомерных моделей данных». HDL : 10393/20457 .
- ^ «Тенденции поиска Hub Lake и складов» . Архивировано из оригинала 17 февраля 2017 г. Проверено 12 января 2016 г.
- ^ «Интеллектуальный анализ данных в бизнес-аналитике» . Западный губернаторский университет . 15 мая 2020 года. Архивировано из оригинала 23 декабря 2020 года . Проверено 22 ноября 2020 г.
- ^ Сурани, Ибрагим (30 марта 2020 г.). «Интеграция данных для бизнес-аналитики: лучшие практики» . ДАННЫЕ . Архивировано из оригинала 30 ноября 2020 г. Проверено 23 ноября 2020 г.
- ^ Алагич, Суад; Бернштейн, Филип А. (2002). Языки программирования баз данных . Конспекты лекций по информатике. Том. 2397. стр. 228–246. дои : 10.1007/3-540-46093-4_14 . ISBN 978-3-540-44080-2 .
- ^ «Вложенные сопоставления: перезагрузка сопоставления схемы» (PDF) . Архивировано (PDF) из оригинала 28 октября 2015 г. Проверено 10 сентября 2015 г.
- ^ «Инициатива Common Framework для алгебраической спецификации и разработки программного обеспечения» (PDF) . Архивировано (PDF) из оригинала 4 марта 2016 г. Проверено 10 сентября 2015 г.
- ^ Кристоф Кох (2001). «Интеграция данных с использованием нескольких развивающихся автономных схем» (PDF) . Архивировано из оригинала (PDF) 26 сентября 2007 г.
- ^ Джеффри Д. Уллман (1997). «Интеграция информации с использованием логических представлений» . ИКДТ 1997 . стр. 19–40.
- ^ Jump up to: а б Алон Ю. Халеви (2001). «Ответы на запросы с использованием представлений: опрос» (PDF) . Журнал ВЛДБ . стр. 270–294.
- ^ Георгий Константинидис; и др. (2011). «Масштабируемое переписывание запросов: подход на основе графов» (PDF) . в материалах Международной конференции ACM SIGMOD по управлению данными, SIGMOD'11, 12–16 июня 2011 г., Афины, Греция .
- ^ Уильям Миченер; и др. «DataONE: Сеть наблюдения за Землей» . www.dataone.org. Архивировано из оригинала 22 января 2013 г. Проверено 19 января 2013 г.
- ^ Саид Чоудхури; и др. «Консервация данных» . dataconservancy.org. Архивировано из оригинала 13 января 2013 г. Проверено 19 января 2013 г.
- ^ Маргарет Хедстром ; и др. «Устойчивая окружающая среда ЮВАО – практические данные» . sead-data.net. Архивировано из оригинала 20 сентября 2012 г. Проверено 19 января 2013 г.
- ^ Рейган Мур ; и др. «Консорциум Федерации DataNet» . datafed.org. Архивировано из оригинала 15 апреля 2013 г. Проверено 19 января 2013 г.
- ^ Стивен Рагглс ; и др. «Terra Populus: Интегрированные данные о населении и окружающей среде» . terrapop.org. Архивировано из оригинала 18 мая 2013 г. Проверено 19 января 2013 г.
- ^ Билл Николс. «Альянс исследовательских данных» . rd-alliance.org. Архивировано из оригинала 18 ноября 2014 г. Проверено 1 октября 2014 г.
Внешние ссылки
[ редактировать ]| Базы данных органов управления : Национальные |
|---|