Приблизительное байесовское вычисление
| Часть серии о |
| Байесовская статистика |
|---|
| Апостериорный = Вероятность × Априорный ÷ Доказательства |
| Фон |
| Модельное здание |
| Апостериорное приближение |
| Оценщики |
| Приближение доказательств |
| Оценка модели |
Приближенные байесовские вычисления ( ABC ) представляют собой класс вычислительных методов, основанных на байесовской статистике , которые можно использовать для оценки апостериорных распределений параметров модели.
на основе моделей Во всех статистических выводах функция правдоподобия имеет центральное значение, поскольку она выражает вероятность наблюдаемых данных в рамках конкретной статистической модели и, таким образом, количественно определяет данные, подтверждающие определенные значения параметров и выбор между различными моделями. Для простых моделей обычно можно вывести аналитическую формулу для функции правдоподобия. Однако для более сложных моделей аналитическая формула может оказаться неуловимой, а оценка функции правдоподобия может оказаться очень дорогостоящей в вычислительном отношении.
Методы ABC обходят оценку функции правдоподобия. Таким образом, методы ABC расширяют область моделей, для которых можно рассматривать статистический вывод. Методы ABC математически хорошо обоснованы, но они неизбежно делают предположения и приближения, влияние которых необходимо тщательно оценить. Более того, более широкая область применения ABC усугубляет проблемы оценки параметров и выбора модели .
ABC быстро завоевал популярность в последние годы, в частности, для анализа сложных проблем, возникающих в биологических науках , например, в популяционной генетике , экологии , эпидемиологии , системной биологии и распространении радиоволн . [1]
История
[ редактировать ]Первые идеи, связанные с ABC, относятся к 1980-м годам. Дональд Рубин , обсуждая интерпретацию байесовских утверждений в 1984 году, [2] описал гипотетический механизм выборки, который дает выборку из апостериорного распределения . Эта схема была скорее концептуальным мысленным экспериментом, призванным продемонстрировать, какие манипуляции выполняются при выводе апостериорных распределений параметров. Описание механизма выборки в точности совпадает с описанием схемы ABC-отбраковки , и эту статью можно считать первой, описывающей приближенные байесовские вычисления. двухэтапный квинконкс был построен Однако в конце 1800-х годов Фрэнсисом Гальтоном , который можно рассматривать как физическую реализацию схемы отклонения ABC для одного неизвестного (параметра) и одного наблюдения. [3] Еще один пророческий момент был высказан Рубином, когда он утверждал, что при байесовском выводе специалисты по прикладной статистике не должны ограничиваться только аналитическими моделями, но вместо этого рассматривают вычислительные методы, которые позволяют им оценить апостериорное распределение интересов. Таким образом, можно рассмотреть более широкий спектр моделей. Эти аргументы особенно актуальны в контексте ABC.
В 1984 году Питер Диггл и Ричард Граттон предложили использовать схему систематического моделирования для аппроксимации функции правдоподобия в ситуациях, когда ее аналитическая форма трудноразрешима . [4] Их метод был основан на определении сетки в пространстве параметров и использовании ее для аппроксимации вероятности путем запуска нескольких симуляций для каждой точки сетки. Затем аппроксимация была улучшена путем применения методов сглаживания к результатам моделирования. Хотя идея использования моделирования для проверки гипотез не была новой, [5] [6] Диггл и Граттон, по-видимому, представили первую процедуру, использующую моделирование для получения статистических выводов в обстоятельствах, когда вероятность невозможна.
Хотя подход Диггла и Грэттона открыл новые горизонты, их метод еще не был полностью идентичен тому, что сейчас известно как ABC, поскольку он был направлен на аппроксимацию вероятности, а не апостериорного распределения. В статье Симона Таваре и соавторов впервые был предложен алгоритм ABC для апостериорного вывода. [7] В их плодотворной работе были рассмотрены выводы о генеалогии данных о последовательностях ДНК и, в частности, проблема определения апостериорного распределения времени до самого последнего общего предка отобранных особей. Такой вывод аналитически неразрешим для многих демографических моделей, но авторы представили способы моделирования сливающихся деревьев в рамках предполагаемых моделей. Выборка апостериорных параметров модели была получена путем принятия/отклонения предложений на основе сравнения количества участков сегрегации в синтетических и реальных данных. За этой работой последовало прикладное исследование Джонатана К. Притчарда и соавторов по моделированию вариаций Y-хромосомы человека с использованием метода ABC. [8] Наконец, термин «приблизительные байесовские вычисления» был введен Марком Бомонтом и соавторами. [9] дальнейшее расширение методологии ABC и обсуждение пригодности ABC-подхода более конкретно для решения проблем популяционной генетики. С тех пор ABC распространилась на приложения, выходящие за рамки популяционной генетики, такие как системная биология, эпидемиология и филогеография .
Приближенные байесовские вычисления можно понимать как своего рода байесовскую версию косвенного вывода . [10] [11]
Было разработано несколько эффективных подходов, основанных на методе Монте-Карло, для выполнения выборки из апостериорного распределения ABC для целей оценки и прогнозирования. Популярным выбором является алгоритм SMC Samplers. [12] [13] [14] адаптирован к контексту ABC в методе (SMC-ABC). [15] [16] [17] [18]
Метод
[ редактировать ]Мотивация
[ редактировать ]Распространенное воплощение теоремы Байеса связывает условную вероятность (или плотность) определенного значения параметра. данные данные к вероятности данный по правилу


- ,

где обозначает заднюю часть, вероятность, предшествующий, и доказательства (также называемые предельной вероятностью или априорной прогнозируемой вероятностью данных). Обратите внимание, что знаменатель нормализует общую вероятность апостериорной плотности единице и может быть рассчитано таким образом.




Априор представляет собой убеждения или знания (например, о физических ограничениях) о до доступен. Поскольку априорные оценки сужают неопределенность, апостериорные оценки имеют меньшую дисперсию, но могут быть смещенными. Для удобства априор часто задается путем выбора конкретного распределения среди набора хорошо известных и понятных семейств распределений, так что как оценка априорных вероятностей, так и случайное генерирование значений относительно просты. Для некоторых типов моделей более прагматично указать априорные используя факторизацию совместного распределения всех элементов в виде последовательности их условных распределений. Если нас интересуют только относительные апостериорные правдоподобия различных значений , доказательства можно игнорировать, поскольку она представляет собой нормирующую константу , которая сокращается при любом отношении апостериорных вероятностей. Однако остается необходимым оценить вероятность и предыдущий . Для многих приложений требует больших вычислительных затрат или даже совершенно невозможна. оценка вероятности [19] что мотивирует использование ABC для обхода этой проблемы.
Алгоритм отклонения ABC
[ редактировать ]Все методы, основанные на ABC, аппроксимируют функцию правдоподобия с помощью моделирования, результаты которого сравниваются с наблюдаемыми данными. [20] [21] [22] [23] [24] Точнее, с помощью алгоритма отклонения ABC — самой базовой формы ABC — набор точек параметров сначала выбирается из предварительного распределения. Учитывая выборочную точку параметра , набор данных затем моделируется в рамках статистической модели указанный . Если сгенерированный слишком отличается от наблюдаемых данных , выбранное значение параметра отбрасывается. Говоря точными словами, принимается с терпимостью если:




- ,

где мера расстояния определяет уровень расхождения между и на основе заданной метрики (например, евклидова расстояния ). Обычно необходим строго положительный допуск, поскольку вероятность того, что результат моделирования точно совпадает с данными (событие ) пренебрежимо мал для всех применений ABC, кроме тривиальных, что на практике привело бы к отклонению почти всех точек выборки параметров. Результатом работы алгоритма отклонения ABC является выборка значений параметров, приблизительно распределенных в соответствии с желаемым апостериорным распределением и, что особенно важно, полученная без необходимости явно оценивать функцию правдоподобия.


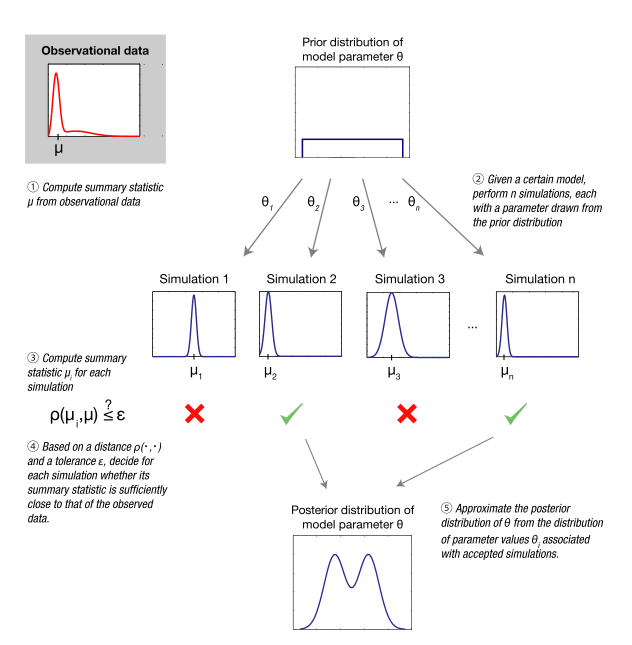
Сводная статистика
[ редактировать ]Вероятность создания набора данных с небольшим расстоянием до обычно уменьшается по мере увеличения размерности данных. Это приводит к существенному снижению вычислительной эффективности описанного выше базового алгоритма отклонения ABC. Распространенный подход к уменьшению этой проблемы заключается в замене с набором сводной статистики меньшей размерности , которые выбраны для сбора соответствующей информации в . Критерием приемлемости в алгоритме отклонения ABC становится:

- .

Если сводная статистика достаточна по параметрам модели , полученное таким образом повышение эффективности не вносит никакой ошибки. [25] Действительно, по определению достаточность подразумевает, что вся информация в о захвачен .
Как подробно описано ниже обычно невозможно , за пределами экспоненциального семейства распределений идентифицировать конечномерный набор достаточной статистики. Тем не менее, информативная, но, возможно, недостаточная сводная статистика часто используется в приложениях, где вывод выполняется с помощью методов ABC.
Пример
[ редактировать ]
Наглядным примером является бистабильная система, которую можно охарактеризовать скрытой марковской моделью (СММ), подверженной шуму измерений. Такие модели используются для многих биологических систем: они, например, использовались в развитии, клеточной передаче сигналов , активации /деактивации, логической обработке и неравновесной термодинамике . Например, поведение транскрипционного фактора Sonic hedgehog (Shh) у Drosophila melanogaster можно смоделировать с помощью HMM. [26] (Биологическая) динамическая модель состоит из двух состояний: А и В. Если вероятность перехода из одного состояния в другое определяется как в обоих направлениях, то вероятность остаться в том же состоянии на каждом временном шаге равна . Вероятность правильно измерить состояние равна (и наоборот, вероятность неправильного измерения равна ).



Из-за условных зависимостей между состояниями в разные моменты времени расчет вероятности данных временных рядов является несколько утомительным, что иллюстрирует мотивацию использования ABC. Вычислительной проблемой для базового ABC является большая размерность данных в таком приложении. Размерность можно уменьшить с помощью сводной статистики , что является частотой переключения между двумя состояниями. Абсолютная разница используется как мера расстояния. с терпимостью . Апостериорный вывод о параметре можно выполнить, выполнив пять шагов, представленных в.



Шаг 1: Предположим, что наблюдаемые данные образуют последовательность состояний AAAABAABBAAAAAABAAAA, которая генерируется с помощью и . Соответствующая сводная статистика — количество переключений между состояниями в экспериментальных данных — равна .



Шаг 2. Предположим, что о нем ничего не известно. , равномерный априор в интервале трудоустроен. Параметр предполагается, что оно известно и зафиксировано на значении, генерирующем данные , но в целом его можно оценить и по наблюдениям. Всего Точки параметров извлекаются из предшествующих, и модель моделируется для каждой из точек параметров. , что приводит к последовательности смоделированных данных. В этом примере , где каждый нарисованный параметр и смоделированный набор данных записаны в таблице 1, столбцы 2–3 . На практике, должно быть намного больше, чтобы получить подходящее приближение.
![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)



| я | Моделируемые наборы данных (шаг 2) | Сводная статистика (шаг 3) | Расстояние (шаг 4) | Исход (шаг 4) | |
|---|---|---|---|---|---|
| 1 | 0.08 | ААААААААААААААААААААААААААААААААААААААА | 8 | 2 | принял |
| 2 | 0.68 | ОТЕЦ ОТЕЦ ОТЕЦ | 13 | 7 | отклоненный |
| 3 | 0.87 | ББББББББББББББ | 9 | 3 | отклоненный |
| 4 | 0.43 | ААААААБББББББББА | 6 | 0 | принял |
| 5 | 0.53 | АББББББАББАБАБААБББ | 9 | 3 | отклоненный |



Шаг 3: Суммарная статистика вычисляется для каждой последовательности смоделированных данных. .

Шаг 4: Расстояние между наблюдаемыми и смоделированными частотами перехода вычисляется для всех точек параметра. Параметр точек, для которых расстояние меньше или равно принимаются как приблизительные образцы сзади.





Шаг 5: Апостериорное распределение аппроксимируется принятыми параметрическими точками. Апостериорное распределение должно иметь непренебрежимо малую вероятность для значений параметров в области вокруг истинного значения в системе, если данные достаточно информативны. В этом примере апостериорная масса вероятности равномерно разделена между значениями 0,08 и 0,43.
Апостериорные вероятности получены с помощью ABC с большими используя сводную статистику (с и ) и полную последовательность данных (с ). Они сравниваются с истинными апостериорными значениями, которые можно точно и эффективно вычислить с помощью алгоритма Витерби . Сводной статистики, использованной в этом примере, недостаточно, поскольку отклонение от теоретического апостериорного значения является значительным даже при строгих требованиях . Для получения апостериорного изображения, сконцентрированного вокруг , истинная стоимость .
В этом примере применения ABC используются упрощения в иллюстративных целях. Более реалистичные применения ABC доступны во все большем количестве рецензируемых статей. [22] [23] [24] [27] [28]
Сравнение модели с ABC
[ редактировать ]Помимо оценки параметров, структуру ABC можно использовать для вычисления апостериорных вероятностей различных моделей-кандидатов. [29] [30] [31] В таких приложениях одной из возможностей является использование отбраковочной выборки иерархическим образом. Сначала модель выбирается из предварительного распределения моделей. Затем параметры выбираются из предыдущего распределения, назначенного этой модели. Наконец, моделирование выполняется, как в одномодельной ABC. Относительные частоты принятия для различных моделей теперь аппроксимируют апостериорное распределение для этих моделей. Опять же, были предложены вычислительные улучшения для ABC в пространстве моделей, такие как построение фильтра частиц в совместном пространстве моделей и параметров. [31]
После оценки апостериорных вероятностей моделей можно в полной мере использовать методы сравнения байесовских моделей . Например, чтобы сравнить относительную правдоподобность двух моделей и , можно вычислить их апостериорное соотношение, которое связано с фактором Байеса :



- .

Если априорные модели модели равны, то есть — фактор Байеса равен апостериорному отношению.

На практике, как обсуждается ниже , эти меры могут быть очень чувствительны к выбору априорных распределений параметров и сводной статистики, поэтому выводы по сравнению моделей следует делать с осторожностью.
Подводные камни и способы их устранения
[ редактировать ]| Источник ошибки | Потенциальная проблема | Решение | Подраздел |
|---|---|---|---|
| Ненулевой допуск | Неточность вносит систематическую ошибку в вычисленное апостериорное распределение. | Теоретические/практические исследования чувствительности заднего распределения к толерантности. Шумная АВС. | #Аппроксимация задней части |
| Недостаточная сводная статистика | Потеря информации приводит к завышению доверительных интервалов. | Автоматический отбор/полуавтоматическое определение достаточной статистики. Проверки валидации модели (например, Templeton 2009). [32] ). | #Выбор и достаточность сводной статистики |
| Малое количество моделей/неправильно указаны модели | Исследуемые модели не являются репрезентативными/не имеют предсказательной силы. | Тщательный подбор моделей. Оценка предсказательной силы. | #Малое количество моделей |
| Приоритеты и диапазоны параметров | Выводы могут быть чувствительны к выбору априорных предпосылок. Выбор модели может оказаться бессмысленным. | Проверьте чувствительность факторов Байеса к выбору априорных значений. Доступны некоторые теоретические результаты, касающиеся выбора априорных подходов. Используйте альтернативные методы проверки модели. | #Априорное распределение и диапазоны параметров |
| Проклятие размерности | Низкая скорость принятия параметров. Ошибки модели нельзя отличить от недостаточного исследования пространства параметров. Риск переобучения. | Методы сокращения модели, если применимо. Методы ускорения исследования параметров. Контроль качества для выявления переобучения. | #Проклятие размерности |
| Рейтинг моделей со сводной статистикой | Вычисление факторов Байеса в сводной статистике может не быть связано с факторами Байеса в исходных данных, что, следовательно, может сделать результаты бессмысленными. | Используйте только сводную статистику, которая удовлетворяет необходимым и достаточным условиям для выбора последовательной байесовской модели. Используйте альтернативные методы проверки модели. | #Байесовский фактор с ABC и сводной статистикой |
| Выполнение | Низкая защита общих предположений в процессе моделирования и вывода. | Проверка работоспособности результатов. Стандартизация программного обеспечения. | #Незаменимый контроль качества |
Что касается всех статистических методов, для применения методов, основанных на ABC, к реальным задачам моделирования по своей сути требуется ряд допущений и приближений. Например, установка параметра допуска до нуля гарантирует точный результат, но обычно делает вычисления непомерно дорогими. Таким образом, значения На практике используются значения, превышающие ноль, что вносит смещение. Аналогичным образом, достаточные статистические данные обычно недоступны, и вместо них используются другие сводные статистические данные, что вносит дополнительную погрешность из-за потери информации. Дополнительные источники систематической ошибки, например, в контексте выбора модели, могут быть более тонкими. [25] [33]
В то же время некоторые критические замечания, направленные в адрес методов ABC, особенно в области филогеографии , [32] [34] [35] не являются специфичными для ABC и применимы ко всем байесовским методам или даже ко всем статистическим методам (например, выбор предварительного распределения и диапазонов параметров). [22] [36] Однако из-за способности ABC-методов обрабатывать гораздо более сложные модели некоторые из этих общих ошибок имеют особое значение в контексте ABC-анализа.
В этом разделе обсуждаются эти потенциальные риски и рассматриваются возможные способы их устранения.
Аппроксимация задней части
[ редактировать ]Немаловажный поставляется с ценой, которую можно получить из образца вместо истинного заднего . При достаточно малом допуске и разумной мере расстояния полученное распределение часто должно приближаться к фактическому целевому распределению достаточно хорошо. С другой стороны, допуск, который достаточно велик, чтобы каждая точка в пространстве параметров стала приемлемой, даст копию предыдущего распределения. Существуют эмпирические исследования разницы между и как функция , [37] [38] и теоретические результаты для верхнего -зависимая граница погрешности оценок параметров. [39] Точность апостериорной функции (определяемой как ожидаемая квадратичная потеря), обеспечиваемая ABC, как функция также было расследовано. [40] Однако сходимость распределений при приближается к нулю, и то, как это зависит от используемой меры расстояния, является важной темой, которая еще предстоит исследовать более подробно. В частности, по-прежнему трудно отличить ошибки, вносимые этим приближением, от ошибок, вызванных неправильной спецификацией модели. [22]

В качестве попытки исправить часть ошибки из-за ненулевого значения было предложено использовать локальную линейно-взвешенную регрессию с ABC для уменьшения дисперсии апостериорных оценок. [9] Метод присваивает веса параметрам в зависимости от того, насколько хорошо смоделированные сводки соответствуют наблюдаемым, и выполняет линейную регрессию между сводками и взвешенными параметрами вблизи наблюдаемых сводок. Полученные коэффициенты регрессии используются для корректировки параметров выборки в направлении наблюдаемых сводок. Было предложено улучшение в форме нелинейной регрессии с использованием модели нейронной сети с прямой связью. [41] Однако было показано, что апостериорные распределения, полученные с помощью этих подходов, не всегда согласуются с априорным распределением, что привело к переформулировке корректировки регрессии, которая учитывает априорное распределение. [42]
Наконец, статистический вывод с использованием ABC с ненулевым допуском. не является дефектным по своей сути: при допущении ошибок измерения оптимальное на самом деле можно показать, что оно не равно нулю. [40] [43] Действительно, систематическая ошибка, вызванная ненулевым допуском, может быть охарактеризована и компенсирована путем введения определенной формы шума в сводную статистику. Установлена асимптотическая состоятельность для такого «зашумленного ABC» и формулы асимптотической дисперсии оценок параметров при фиксированном допуске. [40]
Выбор и достаточность сводной статистики
[ редактировать ]Сводная статистика может использоваться для увеличения скорости принятия ABC для многомерных данных. Для этой цели оптимальны достаточные статистические данные низкой размерности, поскольку они фиксируют всю значимую информацию, присутствующую в данных, в максимально простой форме. [24] [44] [45] Однако достаточная статистика низкой размерности обычно недостижима для статистических моделей, где вывод на основе ABC наиболее уместен, и, следовательно, обычно необходима некоторая эвристика для определения полезной сводной статистики низкой размерности. Использование набора плохо выбранных сводных статистических данных часто приводит к завышению доверительных интервалов из-за подразумеваемой потери информации. [24] что также может повлиять на дискриминацию между моделями. Доступен обзор методов выбора сводной статистики, [46] которые могут дать ценные рекомендации на практике.
Одним из подходов к сбору большей части информации, содержащейся в данных, было бы использование множества статистических данных, но точность и стабильность ABC, по-видимому, быстро снижаются с увеличением количества сводных статистических данных. [22] [24] Вместо этого лучшая стратегия — сосредоточиться только на соответствующих статистических данных, релевантность которых зависит от всей задачи вывода, используемой модели и имеющихся данных. [47]
Был предложен алгоритм для идентификации репрезентативного подмножества сводных статистических данных путем итеративной оценки того, вносит ли дополнительная статистика значимую модификацию апостериорного показателя. [48] Одна из проблем здесь заключается в том, что большая ошибка аппроксимации ABC может сильно повлиять на выводы о полезности статистики на любом этапе процедуры. Другой метод [47] распадается на два основных этапа. Во-первых, эталонная аппроксимация апостериора строится путем минимизации энтропии . Затем наборы резюме кандидатов оцениваются путем сравнения апостериорных изображений, аппроксимированных ABC, с эталонными апостериорными данными.
При использовании обеих этих стратегий подмножество статистики выбирается из большого набора статистических данных-кандидатов. Вместо этого подход частичной регрессии наименьших квадратов использует информацию из всех статистических данных-кандидатов, каждая из которых имеет соответствующий вес. [49] В последнее время значительный интерес приобрел метод построения сводок в полуавтоматическом режиме. [40] Этот метод основан на наблюдении, что оптимальный выбор сводной статистики при минимизации квадратичных потерь точечных оценок параметров может быть получен через апостериорное среднее значений параметров, которое аппроксимируется путем выполнения линейной регрессии на основе смоделированных данных. .
Существенную ценность могли бы иметь методы идентификации сводных статистических данных, которые могли бы также одновременно оценить влияние на аппроксимацию апостериорных данных. [50] Это связано с тем, что выбор сводной статистики и выбор толерантности представляют собой два источника ошибок в итоговом апостериорном распределении. Эти ошибки могут исказить ранжирование моделей, а также привести к неверным прогнозам модели. Действительно, ни один из вышеперечисленных методов не оценивает выбор резюме с целью выбора модели.
Фактор Байеса с ABC и сводной статистикой
[ редактировать ]Было показано, что сочетание недостаточной сводной статистики и ABC для выбора модели может быть проблематичным. [25] [33] Действительно, если учесть байесовский фактор на основе сводной статистики обозначаться , отношение между и принимает форму: [25]

- .

Таким образом, сводная статистика достаточно для сравнения двух моделей и тогда и только тогда, когда:
- ,

что приводит к тому, что . Из приведенного выше уравнения также ясно, что может быть огромная разница между и если условие не выполняется, что можно продемонстрировать на игрушечных примерах. [25] [30] [33] Важно отметить, что было показано, что достаточности для или отдельно или для обеих моделей не гарантирует достаточности для ранжирования моделей. [25] Однако было также показано, что любая достаточная сводная статистика для модели в котором оба и являются вложенными , действительны для ранжирования вложенных моделей . [25]

Вычисление факторов Байеса на поэтому может вводить в заблуждение при выборе модели, если только соотношение между байесовскими факторами и будут доступны или, по крайней мере, могут быть достаточно хорошо аппроксимированы. В качестве альтернативы недавно были получены необходимые и достаточные условия для сводной статистики для последовательного выбора байесовской модели: [51] которые могут дать полезные рекомендации.
Однако эта проблема актуальна только для выбора модели, когда размерность данных уменьшена. Вывод на основе ABC, при котором фактические наборы данных сравниваются напрямую, как это имеет место в некоторых приложениях системной биологии (например, см. [52] ) — обходит эту проблему.
Незаменимый контроль качества
[ редактировать ]Как ясно видно из приведенного выше обсуждения, любой анализ ABC требует выбора и компромиссов, которые могут оказать существенное влияние на его результаты. В частности, выбор конкурирующих моделей/гипотез, количества симуляций, выбора сводной статистики или порога приемлемости в настоящее время не может основываться на общих правилах, но эффект этого выбора должен оцениваться и тестироваться в каждом исследовании. [23]
Был предложен ряд эвристических подходов к контролю качества ABC, таких как количественная оценка доли дисперсии параметров, объясняемой сводной статистикой. [23] Общий класс методов направлен на оценку того, дает ли вывод достоверные результаты, независимо от фактически наблюдаемых данных. Например, учитывая набор значений параметров, которые обычно извлекаются из априорных или апостериорных распределений модели, можно создать большое количество искусственных наборов данных. Таким образом, качество и надежность вывода ABC можно оценить в контролируемых условиях, оценивая, насколько хорошо выбранный метод вывода ABC восстанавливает истинные значения параметров, а также моделирует, если одновременно рассматриваются несколько структурно различных моделей.
Другой класс методов оценивает, был ли вывод успешным в свете данных наблюдений, например, путем сравнения апостериорного прогнозного распределения сводной статистики с наблюдаемой сводной статистикой. [23] Помимо этого, перекрестной проверки методы [53] и прогнозные проверки [54] [55] представляют собой многообещающие будущие стратегии для оценки стабильности и прогностической достоверности выводов ABC за пределами выборки. Это особенно важно при моделировании больших наборов данных, поскольку тогда апостериорная поддержка конкретной модели может оказаться чрезвычайно убедительной, даже если все предлагаемые модели на самом деле являются плохим представлением стохастической системы, лежащей в основе данных наблюдений. Прогностические проверки за пределами выборки могут выявить потенциальные систематические отклонения в модели и дать подсказки о том, как улучшить ее структуру или параметризацию.
Недавно были предложены принципиально новые подходы к выбору модели, которые включают контроль качества как неотъемлемый этап процесса. ABC позволяет, по своей конструкции, оценить расхождения между наблюдаемыми данными и предсказаниями модели в отношении полного набора статистических данных. Эти статистические данные не обязательно совпадают с теми, которые используются в критерии приемки. Полученные распределения несоответствий использовались для выбора моделей, которые одновременно согласуются со многими аспектами данных. [56] а несогласованность модели выявляется на основе противоречивых и взаимозависимых сводок. Другой метод выбора модели, основанный на контроле качества, использует ABC для аппроксимации эффективного количества параметров модели и отклонения апостериорных прогнозных распределений сводок и параметров. [57] Информационный критерий отклонения затем используется в качестве меры соответствия модели. Также было показано, что модели, предпочитаемые на основе этого критерия, могут противоречить моделям, поддерживаемым факторами Байеса . По этой причине полезно комбинировать различные методы выбора модели для получения правильных выводов.
Контроль качества достижим и действительно осуществляется во многих работах, основанных на ABC, но для некоторых проблем оценка влияния параметров, связанных с методом, может быть сложной задачей. Однако можно ожидать, что быстро растущее использование ABC обеспечит более глубокое понимание ограничений и применимости метода.
Общие риски статистических выводов усугубляются в ABC
[ редактировать ]В этом разделе рассматриваются риски, которые, строго говоря, не являются специфическими для ABC, но также актуальны и для других статистических методов. Однако гибкость, предлагаемая ABC для анализа очень сложных моделей, делает их весьма актуальными для обсуждения здесь.
Априорное распределение и диапазоны параметров
[ редактировать ]Спецификация диапазона и априорное распределение параметров сильно выигрывают от предыдущих знаний о свойствах системы. Одна из критических замечаний заключалась в том, что в некоторых исследованиях «диапазоны и распределения параметров только предполагаются на основе субъективного мнения исследователей». [58] что связано с классическими возражениями против байесовских подходов. [59]
При использовании любого вычислительного метода обычно необходимо ограничить диапазоны исследуемых параметров. Диапазоны параметров должны, по возможности, определяться на основе известных свойств изучаемой системы, но для практических приложений могут потребоваться обоснованные предположения. Однако теоретические результаты, касающиеся объективных априорных значений доступны , которые могут быть основаны, например, на принципе безразличия или принципе максимальной энтропии . [60] [61] С другой стороны, автоматические или полуавтоматические методы выбора априорного распределения часто приводят к неправильным значениям плотности . Поскольку большинство процедур ABC требуют создания образцов на основе априорных данных, неправильные априорные данные не применимы напрямую к ABC.
При выборе априорного распределения также следует учитывать цель анализа. В принципе, неинформативные и плоские априорные значения, которые преувеличивают наше субъективное незнание параметров, все же могут дать разумные оценки параметров. Однако факторы Байеса очень чувствительны к априорному распределению параметров. Выводы о выборе модели, основанной на факторе Байеса, могут ввести в заблуждение, если не будет тщательно рассмотрена чувствительность выводов к выбору априорных значений.
Небольшое количество моделей
[ редактировать ]Методы, основанные на моделях, подвергались критике за то, что они не исчерпывающе охватывают пространство гипотез. [35] Действительно, исследования на основе моделей часто вращаются вокруг небольшого количества моделей, и из-за высоких вычислительных затрат для оценки одной модели в некоторых случаях может быть сложно охватить большую часть пространства гипотез.
Верхний предел числа рассматриваемых моделей-кандидатов обычно определяется значительными усилиями, необходимыми для определения моделей и выбора между многими альтернативными вариантами. [23] Не существует общепринятой процедуры построения модели, специфичной для ABC, поэтому вместо этого используются опыт и предварительные знания. [24] Хотя более надежные процедуры априорного выбора и формулирования модели были бы полезны, не существует единой стратегии разработки моделей в статистике: разумная характеристика сложных систем всегда будет требовать большой исследовательской работы и использования экспертных знаний. знания из проблемной области.
Некоторые противники ABC утверждают, что, поскольку лишь немногие модели (субъективно выбранные и, вероятно, все ошибочные) могут быть реально рассмотрены, анализ ABC дает лишь ограниченное понимание. [35] Однако существует важное различие между выявлением правдоподобной нулевой гипотезы и оценкой относительного соответствия альтернативных гипотез. [22] Поскольку полезные нулевые гипотезы, которые потенциально верны, крайне редко могут быть выдвинуты в контексте сложных моделей, предсказательная способность статистических моделей для объяснения сложных явлений в этом контексте гораздо важнее, чем проверка статистической нулевой гипотезы. Также распространено усреднение по исследованным моделям, взвешенное на основе их относительной правдоподобности, чтобы сделать вывод о характеристиках модели (например, значениях параметров) и сделать прогнозы.
Большие наборы данных
[ редактировать ]Большие наборы данных могут стать узким местом вычислений для методов, основанных на моделях. Например, было отмечено, что в некоторых анализах, основанных на ABC, часть данных приходится опускать. [35] Ряд авторов утверждают, что большие наборы данных не являются практическим ограничением. [23] [59] хотя острота этой проблемы сильно зависит от характеристик моделей. Некоторые аспекты задачи моделирования могут способствовать усложнению вычислений, например размер выборки, количество наблюдаемых переменных или признаков, временное или пространственное разрешение и т. д. Однако с увеличением вычислительной мощности этот вопрос потенциально станет менее важным.
Вместо параметров выборки для каждого моделирования из предыдущего было предложено в качестве альтернативы объединить алгоритм Метрополиса-Гастингса с ABC, что, как сообщается, привело к более высокому уровню приемлемости, чем для простого ABC. [50] Естественно, такой подход унаследовал общие трудности методов MCMC, такие как сложность оценки сходимости, корреляции между выборками из апостериорного [37] и относительно плохая распараллеливаемость. [23]
Аналогичным образом, идеи последовательного метода Монте-Карло (SMC) и популяционного метода Монте-Карло (PMC) были адаптированы к условиям ABC. [37] [62] Общая идея состоит в том, чтобы итеративно приближаться к апостериорному от априорного через последовательность целевых распределений. Преимущество таких методов по сравнению с ABC-MCMC заключается в том, что образцы из полученной задней части независимы. Кроме того, при использовании последовательных методов уровни допуска не должны указываться до анализа, а корректируются адаптивно. [63]
Сравнительно просто распараллелить ряд шагов в алгоритмах ABC, основанных на отбраковочной выборке и последовательных методах Монте-Карло. Также было продемонстрировано, что параллельные алгоритмы могут значительно ускорить вывод на основе MCMC в филогенетике. [64] который может быть подходящим подходом и для методов, основанных на ABC. Тем не менее, адекватная модель сложной системы, скорее всего, потребует интенсивных вычислений независимо от выбранного метода вывода, и пользователь должен выбрать метод, который подходит для конкретного рассматриваемого приложения.
Проклятие размерности
[ редактировать ]Многомерные наборы данных и многомерные пространства параметров могут потребовать моделирования чрезвычайно большого количества точек параметров в исследованиях на основе ABC, чтобы получить разумный уровень точности для апостериорных выводов. В таких ситуациях вычислительные затраты значительно возрастают и в худшем случае могут сделать вычислительный анализ невыполнимым. Это примеры хорошо известных явлений, которые обычно называют общим термином « проклятие размерности» . [65]
Чтобы оценить, насколько сильно размерность набора данных влияет на анализ в контексте ABC, были выведены аналитические формулы для ошибки оценщиков ABC как функции размерности сводной статистики. [66] [67] Кроме того, Блюм и Франсуа исследовали, как размерность сводной статистики связана со среднеквадратичной ошибкой для различных поправок на ошибку оценок ABC. Также утверждалось, что методы уменьшения размерностей полезны, чтобы избежать «проклятия размерности» из-за потенциально низкоразмерной базовой структуры сводной статистики. [66] Стремясь минимизировать квадратичные потери оценок ABC, Фернхед и Прангл предложили схему для проецирования (возможно, многомерных) данных в оценки апостериорных средних параметров; эти средние значения, теперь имеющие ту же размерность, что и параметры, затем используются в качестве сводной статистики для ABC. [67]
ABC можно использовать для вывода проблем в многомерных пространствах параметров, хотя следует учитывать возможность переобучения (например, см. методы выбора модели в [56] и [57] ). Однако вероятность принятия смоделированных значений параметров с заданным допуском с помощью алгоритма отклонения ABC обычно уменьшается экспоненциально с увеличением размерности пространства параметров (из-за глобального критерия приемлемости). [24] Хотя ни один вычислительный метод (основанный на ABC или нет), по-видимому, не способен преодолеть проклятие размерности, недавно были разработаны методы для обработки многомерных пространств параметров при определенных предположениях (например, на основе полиномиальной аппроксимации на разреженных сетках, [68] что потенциально может значительно сократить время моделирования для ABC). Однако применимость таких методов зависит от проблемы, и в целом не следует недооценивать сложность исследования пространств параметров. Например, введение детерминированной оценки глобальных параметров привело к сообщениям о том, что глобальные оптимумы, полученные в нескольких предыдущих исследованиях задач малой размерности, были неверными. [69] Поэтому для некоторых проблем может быть сложно определить, является ли модель неправильной или, как обсуждалось выше , не подходит ли исследуемая область пространства параметров. [35] Более прагматичные подходы заключаются в сокращении масштабов проблемы за счет сокращения модели. [24] дискретизация переменных и использование канонических моделей, таких как модели с шумом. Шумные модели используют информацию об условной независимости между переменными. [70]
Программное обеспечение
[ редактировать ]В настоящее время доступен ряд пакетов программного обеспечения для применения ABC к определенным классам статистических моделей.
| Программное обеспечение | Ключевые слова и особенности | Ссылка |
|---|---|---|
| pyABC | Платформа Python для эффективного распределенного ABC-SMC (Sequential Monte Carlo). | [71] |
| ПиМК | Пакет Python для байесовского статистического моделирования и вероятностного машинного обучения. | [72] |
| DIY-Азбука | Программное обеспечение для подгонки генетических данных к сложным ситуациям. Сравнение конкурирующих моделей. Оценка параметров. Вычисление показателей систематической ошибки и точности для данной модели и известных значений параметров. | [73] |
| абв пакет R | Несколько алгоритмов ABC для оценки параметров и выбора модели. Методы нелинейной гетероскедастической регрессии для ABC. Инструмент перекрестной проверки. | [74] [75] |
| EasyABC пакет R | Несколько алгоритмов для выполнения эффективных схем выборки ABC, включая 4 схемы последовательной выборки и 3 схемы MCMC. | [76] [77] |
| ABC-SysBio | Пакет Python. Вывод параметров и выбор модели для динамических систем. Сочетает в себе пробоотборник ABC, ABC SMC для вывода параметров и ABC SMC для выбора модели. Совместимость с моделями, написанными на языке разметки системной биологии (SBML). Детерминистические и стохастические модели. | [78] |
| ABCtoolbox | Программы с открытым исходным кодом для различных алгоритмов ABC, включая браковочную выборку, MCMC без правдоподобия, пробоотборник на основе частиц и ABC-GLM. Совместимость с большинством программ моделирования и расчета сводной статистики. | [79] |
| мсБайес | Пакет программного обеспечения с открытым исходным кодом, состоящий из нескольких программ C и R, которые запускаются с помощью «интерфейса» Perl. Иерархические коалесцентные модели. Популяционно-генетические данные нескольких совместно распространенных видов. | [80] |
| ПопABC | Программный пакет для определения закономерностей демографической дивергенции. Коалесцентное моделирование. Выбор байесовской модели. | [81] |
| ОНЕСАМП | Интернет-программа для оценки эффективной численности популяции на основе выборки микросателлитных генотипов. Оценки эффективной численности популяции вместе с 95%-ным достоверным пределом. | [82] |
| ABC4F | Программное обеспечение для оценки F-статистики доминирующих данных. | [83] |
| 2БАД | Двухсобытийная байесовская смесь AD. Программное обеспечение, позволяющее проводить до двух независимых событий примеси с участием до трех родительских популяций. Оценка нескольких параметров (примесь, эффективные размеры и т.д.). Сравнение пар моделей примесей. | [84] |
| ЭЛЬФЫ | Механизм вывода без правдоподобия. ELFI — это пакет статистического программного обеспечения, написанный на Python для приближенных байесовских вычислений (ABC), также известный, например, как вывод без правдоподобия, вывод на основе симулятора, аппроксимативный байесовский вывод и т. д. | [85] |
| ABCpy | Пакет Python для ABC и других схем вывода без правдоподобия. Доступно несколько современных алгоритмов. Обеспечивает быстрый способ интеграции существующих генеративных методов (из C++, R и т. д.), удобное для пользователя распараллеливание с использованием MPI или Spark и обучение сводной статистике (с помощью нейронной сети или линейной регрессии). | [86] |
Пригодность отдельных пакетов программного обеспечения зависит от конкретного приложения, среды компьютерной системы и требуемых алгоритмов.
См. также
[ редактировать ]Ссылки
[ редактировать ]![]() Эта статья была адаптирована из следующего источника под лицензией CC BY 4.0 ( 2013 г. ) ( отчеты рецензента ): Микаэль Суннокер; Альберто Джованни Бусетто; Элина Нумминен; Юкка Корандер; Матье Фолль; Кристоф Дессимо (2013). «Приблизительное байесовское вычисление» . PLOS Вычислительная биология . 9 (1): e1002803. doi : 10.1371/JOURNAL.PCBI.1002803 . ISSN 1553-734X . ПМЦ 3547661 . ПМИД 23341757 . Викиданные Q4781761 .
Эта статья была адаптирована из следующего источника под лицензией CC BY 4.0 ( 2013 г. ) ( отчеты рецензента ): Микаэль Суннокер; Альберто Джованни Бусетто; Элина Нумминен; Юкка Корандер; Матье Фолль; Кристоф Дессимо (2013). «Приблизительное байесовское вычисление» . PLOS Вычислительная биология . 9 (1): e1002803. doi : 10.1371/JOURNAL.PCBI.1002803 . ISSN 1553-734X . ПМЦ 3547661 . ПМИД 23341757 . Викиданные Q4781761 .
- ^ Бхарти, А; Бриоль, Ф.-Х.; Педерсен, Т (2021). «Общий метод калибровки стохастических моделей радиоканалов с помощью ядер». Транзакции IEEE по антеннам и распространению . 70 (6): 3986–4001. arXiv : 2012.09612 . дои : 10.1109/TAP.2021.3083761 . S2CID 233880538 .
- ^ Рубин, Д.Б. (1984). «Байесово оправданные и релевантные вычисления частоты для прикладного статистика» . Анналы статистики . 12 (4): 1151–1172. дои : 10.1214/aos/1176346785 .
- ^ см. рисунок 5 в Стиглер, Стивен М. (2010). «Дарвин, Гальтон и статистическое просвещение». Журнал Королевского статистического общества. Серия А (Статистика в обществе) . 173 (3): 469–482. дои : 10.1111/j.1467-985X.2010.00643.x . ISSN 0964-1998 . S2CID 53333238 .
- ^ Диггл, Пи Джей (1984). «Методы вывода Монте-Карло для неявных статистических моделей». Журнал Королевского статистического общества, серия B. 46 (2): 193–227. дои : 10.1111/j.2517-6161.1984.tb01290.x .
- ^ Бартлетт, MS (1963). «Спектральный анализ точечных процессов». Журнал Королевского статистического общества, серия B. 25 (2): 264–296. дои : 10.1111/j.2517-6161.1963.tb00508.x .
- ^ Хоэл, генеральный директор; Митчелл, Ти Джей (1971). «Моделирование, подбор и тестирование стохастической модели клеточной пролиферации». Биометрия . 27 (1): 191–199. дои : 10.2307/2528937 . JSTOR 2528937 . ПМИД 4926451 .
- ^ Таваре, С; Балдинг, диджей; Гриффитс, Р.С.; Доннелли, П. (1997). «Определение времени слияния на основе данных последовательности ДНК» . Генетика . 145 (2): 505–518. дои : 10.1093/генетика/145.2.505 . ПМК 1207814 . ПМИД 9071603 .
- ^ Причард, Дж. К.; Зейлстад, Монтана; Перес-Лезон, А; и др. (1999). «Рост популяции Y-хромосом человека: исследование микросателлитов Y-хромосомы» . Молекулярная биология и эволюция . 16 (12): 1791–1798. doi : 10.1093/oxfordjournals.molbev.a026091 . ПМИД 10605120 .
- ^ Перейти обратно: а б Бомонт, Массачусетс; Чжан, В; Болдинг, диджей (2002). «Приблизительные байесовские вычисления в популяционной генетике» . Генетика . 162 (4): 2025–2035. дои : 10.1093/генетика/162.4.2025 . ПМЦ 1462356 . ПМИД 12524368 .
- ^ Кристофер С. Дрованди (2018). «Азбука и косвенный вывод». arXiv : 1803.01999 [ stat.CO ].
- ^ Питерс, Гарет (2009). «Достижения в области приближенных байесовских вычислений и методологии трансмерной выборки» . Электронный журнал ССРН . дои : 10.2139/ssrn.3785580 . hdl : 1959.4/50086 . ISSN 1556-5068 .
- ^ Дель Мораль, Пьер; Дусе, Арно; Ясра, Аджай (2006). «Последовательные пробоотборники Монте-Карло» . Журнал Королевского статистического общества. Серия B (Статистическая методология) . 68 (3): 411–436. arXiv : cond-mat/0212648 . дои : 10.1111/j.1467-9868.2006.00553.x . ISSN 1369-7412 . JSTOR 3879283 .
- ^ Дель Мораль, Пьер; Дусе, Арно; Питерс, Гарет (2004). «Технический отчет CUED о последовательных пробоотборниках Монте-Карло» . Электронный журнал ССРН . дои : 10.2139/ssrn.3841065 . ISSN 1556-5068 .
- ^ Питерс, Гарет (2005). «Темы последовательных сэмплеров Монте-Карло» . Электронный журнал ССРН . дои : 10.2139/ssrn.3785582 . ISSN 1556-5068 .
- ^ Сиссон, ЮАР; Фан, Ю.; Танака, Марк М. (6 февраля 2007 г.). «Последовательный Монте-Карло без вероятностей» . Труды Национальной академии наук . 104 (6): 1760–1765. Бибкод : 2007PNAS..104.1760S . дои : 10.1073/pnas.0607208104 . ISSN 0027-8424 . ПМЦ 1794282 . ПМИД 17264216 .
- ^ Питерс, Гарет (2009). «Достижения в области приближенных байесовских вычислений и методологии трансмерной выборки» . Электронный журнал ССРН . дои : 10.2139/ssrn.3785580 . hdl : 1959.4/50086 . ISSN 1556-5068 .
- ^ Питерс, Г.В.; Сиссон, ЮАР; Фан, Ю. (1 ноября 2012 г.). «Байесовский вывод без правдоподобия для α-стабильных моделей» . Вычислительная статистика и анализ данных . 1-й выпуск «Анналов вычислительной и финансовой эконометрики». 56 (11): 3743–3756. дои : 10.1016/j.csda.2010.10.004 . ISSN 0167-9473 .
- ^ Питерс, Гарет В.; Вютрих, Марио В.; Шевченко, Павел В. (01 августа 2010 г.). «Метод цепной лестницы: байесовский бутстрап против классического бутстрапа» . Страхование: Математика и Экономика . 47 (1): 36–51. arXiv : 1004.2548 . doi : 10.1016/j.insmatheco.2010.03.007 . ISSN 0167-6687 .
- ^ Бусетто А.Г., Буман Дж. Стабильная байесовская оценка параметров биологических динамических систем.; 2009. Издательство IEEE Computer Society Press, стр. 148–157.
- ^ Хантер, Дон (8 декабря 2006 г.). «Байесовский вывод, выборка Монте-Карло и операционный риск» . Журнал операционного риска . 1 (3): 27–50. дои : 10.21314/jop.2006.014 .
- ^ Питерс, Гарет (2009). «Достижения в области приближенных байесовских вычислений и методологии трансмерной выборки» . Электронный журнал ССРН . дои : 10.2139/ssrn.3785580 . hdl : 1959.4/50086 . ISSN 1556-5068 .
- ^ Перейти обратно: а б с д и ж Бомонт, Массачусетс (2010). «Приблизительные байесовские вычисления в эволюции и экологии». Ежегодный обзор экологии, эволюции и систематики . 41 : 379–406. doi : 10.1146/annurev-ecolsys-102209-144621 .
- ^ Перейти обратно: а б с д и ж г час Берторель, Дж; Бенаццо, А; Мона, С (2010). «ABC как гибкая основа для оценки демографии в пространстве и времени: некоторые минусы, много плюсов» . Молекулярная экология . 19 (13): 2609–2625. Бибкод : 2010MolEc..19.2609B . дои : 10.1111/j.1365-294x.2010.04690.x . ПМИД 20561199 . S2CID 12129604 .
- ^ Перейти обратно: а б с д и ж г час Силлери, К; Блюм, МГБ; Гаджотти, штат Огайо; Франсуа, О (2010). «Приближенные байесовские вычисления (ABC) на практике». Тенденции в экологии и эволюции . 25 (7): 410–418. дои : 10.1016/j.tree.2010.04.001 . ПМИД 20488578 . S2CID 13957079 .
- ^ Перейти обратно: а б с д и ж г Дидло, X; Эверитт, Р.Г.; Йохансен, AM; Лоусон, диджей (2011). «Безправдоподобная оценка модельных доказательств» . Байесовский анализ . 6 : 49–76. дои : 10.1214/11-ba602 .
- ^ Лай, К; Робертсон, MJ; Шаффер, Д.В. (2004). «Сигнальная система звукового ежа как бистабильный генетический переключатель» . Биофиз. Дж . 86 (5): 2748–2757. Бибкод : 2004BpJ....86.2748L . дои : 10.1016/s0006-3495(04)74328-3 . ПМК 1304145 . ПМИД 15111393 .
- ^ Марин, Дж. М.; Пудло, П; Роберт, CP; Райдер, Р.Дж. (2012). «Приближенные байесовские вычислительные методы». Статистика и вычисления . 22 (6): 1167–1180. arXiv : 1101.0955 . дои : 10.1007/s11222-011-9288-2 . S2CID 40304979 .
- ^ Роберт, Кристиан П. (2016). «Приблизительные байесовские вычисления: обзор последних результатов». Ин Кулс, Р.; Найенс, Д. (ред.). Методы Монте-Карло и квази-Монте-Карло . Спрингерские труды по математике и статистике. Том. 163. стр. 185–205. дои : 10.1007/978-3-319-33507-0_7 . ISBN 978-3-319-33505-6 .
- ^ Уилкинсон, Р.Г. (2007). Байесовская оценка времени расхождения приматов, доктор философии. диссертация, Кембриджский университет.
- ^ Перейти обратно: а б Грело, А; Марин, Дж. М.; Роберт, К; Родольф, Ф; Талли, Ф (2009). «Безправдоподобные методы выбора модели в случайных полях Гиббса». Байесовский анализ . 3 : 427–442.
- ^ Перейти обратно: а б Тони, Тина; Штумпф, Майкл П.Х. (2010). «Выбор модели динамических систем на основе моделирования в системной и популяционной биологии». Биоинформатика . 26 : 104–110. arXiv : 0911.1705 . doi : 10.1093/биоинформатика/btp619 .
- ^ Перейти обратно: а б Темплтон, Арканзас (2009). «Почему метод, который терпит неудачу, продолжает использоваться? Ответ» . Эволюция . 63 (4): 807–812. дои : 10.1111/j.1558-5646.2008.00600.x . ПМЦ 2693665 . ПМИД 19335340 .
- ^ Перейти обратно: а б с Роберт, CP; Корнюэ, Ж.М.; Марин, Дж. М.; Пиллаи, Н.С. (2011). «Недостаток уверенности в выборе приближенной байесовской модели вычислений» . Proc Natl Acad Sci США . 108 (37): 15112–15117. Бибкод : 2011PNAS..10815112R . дои : 10.1073/pnas.1102900108 . ПМК 3174657 . ПМИД 21876135 .
- ^ Темплтон, Арканзас (2008). «Анализ вложенных клад: широко проверенный метод для серьезных филогеографических выводов» . Молекулярная экология . 17 (8): 1877–1880. Бибкод : 2008MolEc..17.1877T . дои : 10.1111/j.1365-294x.2008.03731.x . ПМЦ 2746708 . ПМИД 18346121 .
- ^ Перейти обратно: а б с д и Темплтон, Арканзас (2009). «Статистическая проверка гипотез во внутривидовой филогеографии: филогеографический анализ вложенных клад против приближенных байесовских вычислений» . Молекулярная экология . 18 (2): 319–331. Бибкод : 2009MolEc..18..319T . дои : 10.1111/j.1365-294x.2008.04026.x . ПМК 2696056 . ПМИД 19192182 .
- ^ Бергер, Дж. О.; Финберг, SE; Рафтери, А.Е.; Роберт, CP (2010). «Бессвязный филогеографический вывод» . Труды Национальной академии наук Соединенных Штатов Америки . 107 (41): Е157. Бибкод : 2010PNAS..107E.157B . дои : 10.1073/pnas.1008762107 . ПМК 2955098 . ПМИД 20870964 .
- ^ Перейти обратно: а б с Сиссон, ЮАР; Фан, Ю; Танака, ММ (2007). «Последовательный Монте-Карло без вероятностей» . Proc Natl Acad Sci США . 104 (6): 1760–1765. Бибкод : 2007PNAS..104.1760S . дои : 10.1073/pnas.0607208104 . ПМЦ 1794282 . ПМИД 17264216 .
- ^ Питерс, Гарет (2009). «Достижения в области приближенных байесовских вычислений и методологии трансмерной выборки» . Электронный журнал ССРН . дои : 10.2139/ssrn.3785580 . hdl : 1959.4/50086 . ISSN 1556-5068 .
- ^ Дин, Томас А.; Сингх, Сумитпал С.; Ясра, Аджай; Питерс, Гарет В. (2011). «Оценка параметров скрытых марковских моделей с трудноразрешимыми вероятностями». arXiv : 1103.5399 [ math.ST ].
- ^ Перейти обратно: а б с д Фернхед, Пол; Прангл, Деннис (2010). «Построение сводной статистики для приближенных байесовских вычислений: полуавтоматический ABC». arXiv : 1004.1112 [ stat.ME ].
- ^ Блюм, М; Франсуа, О (2010). «Модели нелинейной регрессии для приближенных байесовских вычислений». Статкомп . 20 : 63–73. arXiv : 0809.4178 . дои : 10.1007/s11222-009-9116-0 . S2CID 2403203 .
- ^ Лойенбергер, К; Вегманн, Д. (2009). «Байесовские вычисления и выбор модели без учета правдоподобия» . Генетика . 184 (1): 243–252. дои : 10.1534/genetics.109.109058 . ПМК 2815920 . ПМИД 19786619 .
- ^ Уилкинсон, Ричард Дэвид (2013). «Приблизительное байесовское вычисление (ABC) дает точные результаты при допущении ошибки модели». Статистические приложения в генетике и молекулярной биологии . 12 (2). arXiv : 0811.3355 . дои : 10.1515/sagmb-2013-0010 .
- ^ Питерс, Гарет Уильям; Вутрих, Марио В.; Шевченко, Павел Владимирович (2009). «Метод цепной лестницы: байесовский бутстрап против классического бутстрапа» . Электронный журнал ССРН . arXiv : 1004.2548 . дои : 10.2139/ssrn.2980411 . ISSN 1556-5068 .
- ^ Питерс, Г.В.; Сиссон, ЮАР; Фан, Ю. (23 декабря 2009 г.). «Байесовский вывод без правдоподобия для альфа-стабильных моделей». arXiv : 0912.4729 [ stat.CO ].
- ^ Блюм, МГБ; Нуньес, Массачусетс; Прангл, Д.; Сиссон, SA (2013). «Сравнительный обзор методов уменьшения размерности в приближенных байесовских вычислениях». Статистическая наука . 28 (2). arXiv : 1202.3819 . дои : 10.1214/12-STS406 .
- ^ Перейти обратно: а б Нуньес, Массачусетс; Болдинг, диджей (2010). «Об оптимальном выборе сводной статистики для приближенных байесовских вычислений». Stat Appl Genet Mol Biol . 9 : Статья 34. doi : 10.2202/1544-6115.1576 . ПМИД 20887273 . S2CID 207319754 .
- ^ Джойс, П; Майоран, П. (2008). «Приблизительно достаточная статистика и байесовские вычисления». Stat Appl Genet Mol Biol . 7 (1): Статья 26. doi : 10.2202/1544-6115.1389 . ПМИД 18764775 . S2CID 38232110 .
- ^ Вегманн, Д; Лойенбергер, К; Экскофье, Л. (2009). «Эффективное приближенное байесовское вычисление в сочетании с цепью Маркова Монте-Карло без правдоподобия» . Генетика . 182 (4): 1207–1218. дои : 10.1534/генетика.109.102509 . ПМЦ 2728860 . ПМИД 19506307 .
- ^ Перейти обратно: а б Майоран, П; Молитор, Дж; Планноль, В; Таваре, С (2003). «Марковская цепь Монте-Карло без вероятностей» . Proc Natl Acad Sci США . 100 (26): 15324–15328. Бибкод : 2003PNAS..10015324M . дои : 10.1073/pnas.0306899100 . ПМК 307566 . ПМИД 14663152 .
- ^ Марин, Ж.-М.; Пиллаи, Н.; Роберт, CP; Руссо, Дж. (2011). «Соответствующая статистика для выбора байесовской модели». arXiv : 1110.4700 [ math.ST ].
- ^ Тони, Т; Уэлч, Д; Стрелкова, Н; Ипсен, А; Штумпф, М (2007). «Приближенная байесовская схема вычислений для вывода параметров и выбора модели в динамических системах» . Интерфейс JR Soc . 6 (31): 187–202. дои : 10.1098/rsif.2008.0172 . ПМЦ 2658655 . ПМИД 19205079 .
- ^ Арлот, С; Селисса, А (2010). «Обзор процедур перекрестной проверки для выбора модели». Статистические опросы . 4 : 40–79. arXiv : 0907.4728 . дои : 10.1214/09-ss054 . S2CID 14332192 .
- ^ Давид А. «Современное положение и потенциальное развитие: Некоторые личные взгляды: Статистическая теория: предиктиальный подход». Журнал Королевского статистического общества, серия А. 1984 : 278–292.
- ^ Вехтари, А; Лампинен, Дж (2002). «Оценка и сравнение байесовской модели с использованием прогнозных плотностей перекрестной проверки». Нейронные вычисления . 14 (10): 2439–2468. CiteSeerX 10.1.1.16.3206 . дои : 10.1162/08997660260293292 . ПМИД 12396570 . S2CID 366285 .
- ^ Перейти обратно: а б Ратманн, О; Андрие, К; Виуф, К; Ричардсон, С. (2009). «Критика модели, основанная на бесправдоподобном выводе, с применением к эволюции белковых сетей» . Труды Национальной академии наук Соединенных Штатов Америки . 106 (26): 10576–10581. Бибкод : 2009PNAS..10610576R . дои : 10.1073/pnas.0807882106 . ПМЦ 2695753 . ПМИД 19525398 .
- ^ Перейти обратно: а б Франсуа, О; Лаваль, Г. (2011). «Критерии информации об отклонениях для выбора модели в приближенных байесовских вычислениях». Stat Appl Genet Mol Biol . 10 : Статья 33. arXiv : 1105.0269 . Бибкод : 2011arXiv1105.0269F . дои : 10.2202/1544-6115.1678 . S2CID 11143942 .
- ^ Темплтон, Арканзас (2010). «Связные и бессвязные выводы в филогеографии и эволюции человека» . Труды Национальной академии наук Соединенных Штатов Америки . 107 (14): 6376–6381. Бибкод : 2010PNAS..107.6376T . дои : 10.1073/pnas.0910647107 . ПМК 2851988 . ПМИД 20308555 .
- ^ Перейти обратно: а б Бомонт, Массачусетс; Нильсен, Р; Роберт, К; Привет, Джей; Гаджотти, О; и др. (2010). «В защиту модельного вывода в филогеографии» . Молекулярная экология . 19 (3): 436–446. Бибкод : 2010MolEc..19..436B . дои : 10.1111/j.1365-294x.2009.04515.x . ПМЦ 5743441 . ПМИД 29284924 .
- ^ Джейнс ET (1968) Априорные вероятности. Транзакции IEEE по системным наукам и кибернетике 4.
- ^ Бергер, Дж.О. (2006). «Аргументы в пользу объективного байесовского анализа» . Байесовский анализ . 1 (страницы 385–402 и 457–464): 385–402. дои : 10.1214/06-BA115 .
- ^ Бомонт, Массачусетс; Корнюэ, Ж.М.; Марин, Дж. М.; Роберт, CP (2009). «Адаптивные приближенные байесовские вычисления». Биометрика . 96 (4): 983–990. arXiv : 0805.2256 . дои : 10.1093/biomet/asp052 . S2CID 16579245 .
- ^ Дель Мораль П., Дусе А., Ясра А. (2011) Адаптивный последовательный метод Монте-Карло для приближенных байесовских вычислений. Статистика и вычисления.
- ^ Фэн, X; Бьюэлл, Д.А.; Роуз, младший; Уодделлб, П.Дж. (2003). «Параллельные алгоритмы для байесовского филогенетического вывода». Журнал параллельных и распределенных вычислений . 63 (7–8): 707–718. CiteSeerX 10.1.1.109.7764 . дои : 10.1016/s0743-7315(03)00079-0 .
- ^ Беллман Р. (1961) Процессы адаптивного управления: экскурсия: Princeton University Press.
- ^ Перейти обратно: а б Блюм МГБ (2010) Приблизительные байесовские вычисления: непараметрическая перспектива, Журнал Американской статистической ассоциации (105): 1178-1187.
- ^ Перейти обратно: а б Фернхед, П; Прангл, Д. (2012). «Построение сводной статистики для приближенных байесовских вычислений: полуавтоматическое приближенное байесовское вычисление». Журнал Королевского статистического общества, серия B. 74 (3): 419–474. CiteSeerX 10.1.1.760.7753 . дои : 10.1111/j.1467-9868.2011.01010.x . S2CID 53861241 .
- ^ Герстнер, Т; Грибель, М. (2003). «Квадратура тензора-произведения, адаптивная к размерам». Вычисление . 71 : 65–87. CiteSeerX 10.1.1.16.2434 . дои : 10.1007/s00607-003-0015-5 . S2CID 16184111 .
- ^ Сингер, АБ; Тейлор, Дж.В.; Бартон, ИП; Грин, Вашингтон (2006). «Глобальная динамическая оптимизация для оценки параметров химической кинетики». J Phys Chem А. 110 (3): 971–976. Бибкод : 2006JPCA..110..971S . дои : 10.1021/jp0548873 . ПМИД 16419997 .
- ^ Карденас, IC (2019). «Об использовании байесовских сетей в качестве подхода к метамоделированию для анализа неопределенностей при анализе устойчивости склонов». Геориск: оценка и управление рисками для инженерных систем и опасных геологических процессов . 13 (1): 53–65. Бибкод : 2019GAMRE..13...53C . дои : 10.1080/17499518.2018.1498524 . S2CID 216590427 .
- ^ Клингер, Э.; Рикерт, Д.; Хазенауэр, Дж. (2017). pyABC: распределенный вывод без правдоподобия.
- ^ Сальватье, Джон; Вецкий, Томас В.; Фоннесбек, Кристофер (2016). «Вероятностное программирование на Python с использованием PyMC3» . PeerJ Информатика . 2 : е55. arXiv : 1507.08050 . дои : 10.7717/peerj-cs.55 .
- ^ Корнюэ, Ж.М.; Сантос, Ф; Бомонт, М; и др. (2008). «Изучение истории населения с помощью DIY ABC: удобный подход к аппроксимации байесовских вычислений» . Биоинформатика . 24 (23): 2713–2719. doi : 10.1093/биоинформатика/btn514 . ПМЦ 2639274 . ПМИД 18842597 .
- ^ Силлери, К; Франсуа, О; Блюм, МГБ (2012). «abc: пакет R для приближенных байесовских вычислений (ABC)». Методы экологии и эволюции . 3 (3): 475–479. arXiv : 1106.2793 . Бибкод : 2012MEcEv...3..475C . дои : 10.1111/j.2041-210x.2011.00179.x . S2CID 16679366 .
- ^ Силлери, К; Франсуа, О; Блюм, МГБ (21 февраля 2012 г.). «Приблизительное байесовское вычисление (ABC) в R: эпизод» (PDF) . Проверено 10 мая 2013 г.
- ^ Жабо, Ф; Фор, Т; Дюмулен, Н. (2013). «EasyABC: выполнение эффективных схем выборки приближенных байесовских вычислений с использованием R». Методы экологии и эволюции . 4 (7): 684–687. Бибкод : 2013MEcEv...4..684J . дои : 10.1111/2041-210X.12050 .
- ^ Жабо, Ф; Фор, Т; Дюмулен, Н. (3 июня 2013 г.). «EasyABC: виньетка» (PDF) . Архивировано из оригинала (PDF) 18 августа 2016 г. Проверено 19 июля 2016 г.
- ^ Липе, Дж; Барнс, К; Кул, Э; Эргулер, К; Кирк, П; Тони, Т; Штумпф, депутат (2010). «ABC-SysBio — приближенные байесовские вычисления на Python с поддержкой графического процессора» . Биоинформатика . 26 (14): 1797–1799. doi : 10.1093/биоинформатика/btq278 . ПМЦ 2894518 . ПМИД 20591907 .
- ^ Вегманн, Д; Лойенбергер, К; Нойеншвандер, С; Экскофье, Л. (2010). «ABCtoolbox: универсальный набор инструментов для приближенных байесовских вычислений» . БМК Биоинформатика . 11 : 116. дои : 10.1186/1471-2105-11-116 . ПМЦ 2848233 . ПМИД 20202215 .
- ^ Хикерсон, MJ; Шталь, Э; Такебаяси, Н. (2007). «msBayes: Конвейер для тестирования сравнительных филогеографических историй с использованием иерархических приближенных байесовских вычислений» . БМК Биоинформатика . 8 (268): 1471–2105. дои : 10.1186/1471-2105-8-268 . ЧВК 1949838 . ПМИД 17655753 .
- ^ Лопес, Дж.С.; Болдинг, Д; Бомонт, Массачусетс (2009). «PopABC: программа для определения исторических демографических параметров». Биоинформатика . 25 (20): 2747–2749. doi : 10.1093/биоинформатика/btp487 . ПМИД 19679678 .
- ^ Таллмон, Д.А.; Коюк, А; Луикарт, Г; Бомонт, Массачусетс (2008). «КОМПЬЮТЕРНЫЕ ПРОГРАММЫ: onesamp: программа для оценки эффективной численности населения с использованием приближенных байесовских вычислений». Ресурсы молекулярной экологии . 8 (2): 299–301. дои : 10.1111/j.1471-8286.2007.01997.x . ПМИД 21585773 . S2CID 9848290 .
- ^ Фолль, М; Баумонт, Массачусетс; Гаджотти, О.Э. (2008). «Приблизительный подход байесовских вычислений для преодоления систематических ошибок, возникающих при использовании маркеров AFLP для изучения структуры популяции» . Генетика . 179 (2): 927–939. doi : 10.1534/genetics.107.084541 . ПМЦ 2429886 . ПМИД 18505879 .
- ^ Брей, TC; Соуза, ВК; Паррейра, Б; Бруфорд, Миссури; Чихи, Л (2010). «2BAD: приложение для оценки родительского вклада во время двух независимых мероприятий по приему». Ресурсы молекулярной экологии . 10 (3): 538–541. дои : 10.1111/j.1755-0998.2009.02766.x . hdl : 10400.7/205 . ПМИД 21565053 . S2CID 6528668 .
- ^ Кангасрасио, Антти; Линтусаари, Ярно; Скитен, Кусти; Ярвенпяя, Марко; Вуоллекоски, Анри; Гутманн, Майкл; Вехтари, Аки; Корандер, Юкка; Каски, Сэмюэл (2016). «ELFI: Механизм вывода без правдоподобия» (PDF) . Семинар NIPS 2016 по достижениям в области приближенного байесовского вывода . arXiv : 1708.00707 . Бибкод : 2017arXiv170800707L .
- ^ Дутта, Р; Шенгенс, М; Паккьярди, Л; Уммадингу, А; Видмер, Н.; Оннела, Япония; Мира, А (2021). «ABCpy: перспектива высокопроизводительных вычислений для аппроксимации байесовских вычислений». Журнал статистического программного обеспечения . 100 (7). arXiv : 1711.04694 . дои : 10.18637/jss.v100.i07 . S2CID 88516340 .
Внешние ссылки
[ редактировать ]- Даррен Уилкинсон (31 марта 2013 г.). «Введение в приближенные байесовские вычисления» . Проверено 31 марта 2013 г.
- Расмус Боат (20 октября 2014 г.). «Маленькие данные, приближенные байесовские вычисления и носки Карла Бромана» . Проверено 22 января 2015 г.