Список слов
В этой статье нечеткий стиль цитирования . ( Март 2021 г. ) |
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( декабрь 2023 г. ) |
Список слов (или лексикон языка ) — это список лексики (обычно отсортированный по частоте появления либо по уровням, либо в виде ранжированного списка) в некотором заданном текстовом корпусе , служащий цели приобретения словарного запаса . Лексикон, отсортированный по частоте, «обеспечивает рациональную основу для обеспечения того, чтобы учащиеся получали максимальную отдачу от своих усилий по изучению словарного запаса» ( Nation 1997 ), но в основном предназначен для авторов курсов, а не непосредственно для учащихся. Списки частот также составляются для лексикографических целей и служат своего рода контрольным списком, позволяющим убедиться, что общие слова не упущены. Некоторые основные ошибки — это содержание корпуса, регистр корпуса и определение слова . Хотя подсчету слов уже тысяча лет, а в середине 20-го века все еще проводился гигантский анализ вручную, электронная обработка естественного языка больших массивов, таких как субтитры к фильмам (мегаисследование SUBTLEX), ускорила развитие исследовательской области.
В компьютерной лингвистике список частот — это отсортированный список слов (типов слов) вместе с их частотой , где частота здесь обычно означает количество вхождений в данном корпусе , из которого можно получить ранг как позицию в списке.
| Тип | События | Классифицировать |
|---|---|---|
| тот | 3,789,654 | 1-й |
| он | 2,098,762 | 2-й |
| [...] | ||
| король | 57,897 | 1356-е место |
| мальчик | 56,975 | 1357-е место |
| [...] | ||
| стягивать | 5 | 34589-е место |
| [...] | ||
| трансдукционализировать | 1 | 123 567-е место |
Методология
[ редактировать ]Факторы
[ редактировать ]Nation ( Nation 1997 ) отметил невероятную помощь, которую оказывают вычислительные возможности, значительно упрощающие корпусный анализ. Он назвал несколько ключевых вопросов, которые влияют на составление списков частот:
- репрезентативность корпуса
- частота и диапазон слов
- обработка семейств слов
- обработка идиом и устойчивых выражений
- диапазон информации
- различные другие критерии
Корпора
[ редактировать ]Традиционный письменный корпус
[ редактировать ]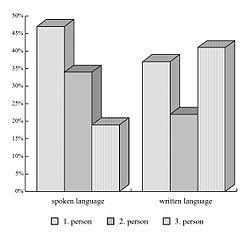
Большинство доступных в настоящее время исследований основаны на корпусе письменных текстов , которые более доступны и просты в обработке.
СУБТЛЕКС движение
[ редактировать ]Однако Нью и др. В 2007 году было предложено использовать большое количество субтитров, доступных в Интернете, для анализа большого количества выступлений. Brysbaert & New 2009 провела длительную критическую оценку этого традиционного подхода к анализу текста и поддержала движение к анализу речи и анализу субтитров к фильмам, доступных в Интернете. Недавно за этим последовало несколько последующих исследований, [ 1 ] обеспечивая ценный анализ частотности для различных языков. Действительно, движение SUBTLEX было завершено за пять полных лет изучения французского ( New et al. 2007 ), американского английского ( Brysbaert & New 2009 ; Brysbaert, New & Keuleers 2012 ), нидерландского ( Keuleers & New 2010 ) и китайского ( Keuleers & New 2010) Cai & Brysbaert 2010 ), испанский ( Cuetos et al. 2011 ), греческий ( Dimitropoulou et al. 2010 ), вьетнамский ( Pham, Bolger & Baayen 2011 ), бразильский португальский ( Tang 2012 ) и португальский португальский ( Soares et al.) . 2015 ), албанский ( Авдыли и Куэтос 2013 ), польский ( Мандера и др. 2014 ) и каталанский (2019). [ 2 ] ). SUBTLEX-IT (2015) предоставляет только необработанные данные. [ 3 ]
Лексическая единица
[ редактировать ]В любом случае следует определить базовую единицу «слово». В латинском алфавите слова обычно состоят из одного или нескольких символов, разделенных пробелами или знаками препинания. Но могут возникнуть исключения, такие как английское «can't», французское «aujourd'hui» или идиомы. Также может быть предпочтительнее группировать слова семейства слов по представлению его основного слова . Таким образом, возможный, невозможный, возможность — это слова одного и того же семейства слов, представленные основным словом *possib* . В статистических целях все эти слова суммируются по базовой словоформе *possib*, что позволяет ранжировать появление понятия и формы. Более того, другие языки могут представлять определенные трудности. Так обстоит дело с китайским языком, который не использует пробелы между словами и где указанную цепочку из нескольких символов можно интерпретировать либо как фразу, состоящую из слов с уникальными символами, либо как слово из нескольких символов.
Статистика
[ редактировать ]Кажется, что закон Ципфа справедлив для списков частот, составленных из более длинных текстов любого естественного языка. Списки частот являются полезным инструментом при создании электронного словаря, который является необходимым условием для широкого спектра приложений в компьютерной лингвистике .
Немецкие лингвисты определяют класс частотности элемента в списке, используя логарифм по основанию 2 отношения его частоты к частоте наиболее частого элемента. Самый распространенный элемент принадлежит к классу частоты 0 (ноль), а любой элемент, который встречается примерно в два раза реже, относится к классу 1. В приведенном выше списке примеров слово возмутительно с ошибкой имеет соотношение 76/3789654 и принадлежит к классу 16.


где это функция пола .

Списки частот вместе с семантическими сетями используются для выявления наименее распространенных специализированных терминов, подлежащих замене их гипернимами в процессе семантического сжатия .
Педагогика
[ редактировать ]Эти списки не предназначены для непосредственного предоставления учащимся, а скорее служат руководством для учителей и авторов учебников ( Nation 1997 ). Краткое содержание преподавания современного языка Пола Нэйшна призывает сначала «перейти от высокочастотной лексики и [тематической] лексики специального назначения к низкочастотной лексике, а затем обучать учащихся стратегиям поддержания автономного расширения словарного запаса» ( Nation 2006 ).
Влияние частоты слов
[ редактировать ]Известно, что частота слов имеет различные эффекты ( Brysbaert et al. 2011 ; Rudell 1993 ). На запоминание положительно влияет более высокая частота слов, вероятно, потому, что учащийся подвергается большему воздействию ( Laufer 1997 ). На лексический доступ положительно влияет высокая частота слов — явление, называемое эффектом частоты слов ( Segui et al. ). Эффект частоты слов связан с эффектом возраста усвоения , возраста, в котором слово было выучено.
Языки
[ редактировать ]Ниже представлен обзор доступных ресурсов.
Английский
[ редактировать ]Счет слов – это древняя область, [ 4 ] с известным обсуждением, относящимся к эллинистическому времени. В 1944 году Эдвард Торндайк , Ирвин Лордж и коллеги [ 5 ] вручную подсчитали 18 000 000 слов и составили первый крупномасштабный список частотности английского языка, прежде чем современные компьютеры сделали такие проекты намного проще ( Nation 1997 ). Все произведения ХХ века страдают от возраста. В частности, слова, относящиеся к технологиям, такие как «блог», который в 2014 году занимал 7665-е место по частоте. [ 6 ] в Корпусе современного американского английского языка, [ 7 ] впервые было подтверждено в 1999 г. [ 8 ] [ 9 ] [ 10 ] и не фигурирует ни в одном из этих трех списков.
- Словарь учителей на 30 000 слов (Торндайк и Лорхе, 1944 г.)
Словарь учителя содержит 30 000 лемм или около 13 000 семейств слов (Goulden, Nation and Read, 1990). Корпус из 18 миллионов письменных слов был проанализирован вручную. Размер исходного корпуса увеличил его полезность, но его возраст и языковые изменения снизили его применимость ( Nation 1997 ).
- Список общих служб (Запад, 1953 г.)
Список общих услуг содержит 2000 заголовков, разделенных на два набора по 1000 слов. В 1940-х годах был проанализирован корпус из 5 миллионов письменных слов. Приводятся проценты встречаемости (%) различных значений и частей речи заглавного слова. К корпусу тщательно применялись различные критерии, помимо частоты и диапазона. Таким образом, несмотря на свой возраст, некоторые ошибки и то, что его корпус представляет собой полностью письменный текст, он по-прежнему представляет собой отличную базу данных о частоте слов, частоте значений и уменьшении шума ( Nation 1997 ). Этот список был обновлен в 2013 году доктором Чарльзом Брауном, доктором Брентом Каллиганом и Джозефом Филлипсом как Новый список услуг общего назначения .
- Частотный справочник слов американского наследия (Кэрролл, Дэвис и Ричман, 1971)
Корпус из 5 миллионов бегущих слов из письменных текстов, используемых в школах США (разные классы, различные предметные области). Его ценность заключается в том, что он сосредоточен на школьных учебных материалах и размечает слова по частоте каждого слова в каждом классе школы и в каждой предметной области ( Nation 1997 ).
- The Brown (Фрэнсис и Кучера, 1982) LOB и связанные с ним корпуса
Сейчас они содержат 1 миллион слов из письменного корпуса, представляющего разные диалекты английского языка. Эти источники используются для составления списков частот ( Nation 1997 ).
Французский
[ редактировать ]- Традиционные наборы данных
Обзор был сделан New & Pallier . Попытка была предпринята в 1950–60-х годах с Français Fondamental . Он включает в себя список FF1 с 1500 высокочастотными словами, дополненный более поздним списком FF2 с 1700 среднечастотными словами, а также наиболее часто используемые правила синтаксиса. [ 11 ] Утверждается, что 70 грамматических слов составляют 50% коммуникативного предложения. [ 12 ] [ 13 ] а 3680 слов составляют около 95–98% охвата. [ 14 ] Доступен список из 3000 часто встречающихся слов. [ 15 ]
Министерство образования Франции также предоставило ранжированный список из 1500 наиболее часто встречающихся семейств слов , составленный лексикологом Этьеном Брюне . [ 16 ] Жан Бодо провел исследование по модели американского исследования Брауна под названием «Частоты использования слов в современном письменном французском языке». [ 17 ]
Совсем недавно проект Lexique3 предоставил 142 000 французских слов с орфографией , фонетикой , слогом , частью речи , полом , количеством вхождений в исходном корпусе, частотным рангом, связанными лексемами и т. д., доступными по открытой лицензии CC-by- са-4.0 . [ 18 ]
- Субтлекс
Этот Lexique3 представляет собой непрерывное исследование, из которого зародилось упомянутое выше движение Subtlex . Нью и др. В 2007 году были произведены совершенно новые подсчеты, основанные на субтитрах онлайн-фильмов.
испанский
[ редактировать ]Было проведено несколько исследований частоты испанских слов ( Cuetos et al. 2011 ). [ 19 ]
китайский
[ редактировать ]Китайские корпуса уже давно изучаются с точки зрения частотных списков. Исторический способ изучения китайской лексики основан на частоте иероглифов ( Allanic 2003 ). Американский китаевед Джон ДеФрэнсис упомянул о его важности для изучения и преподавания китайского языка как иностранного языка в книге « Почему Джонни не может читать по-китайски» ( DeFrancis 1966 ). В качестве инструментария по частоте Da ( Da 1998 ) и Министерство образования Тайваня ( TME 1997 ) предоставили большие базы данных с частотными рангами для символов и слов. Список HSK , содержащий 8848 высоко- и среднечастотных слов в Китайской Народной Республике , и Республики (Тайвань) список Китайской ТОП- , содержащий около 8600 распространенных традиционных китайских слов, — это два других списка, отображающих распространенные китайские слова и иероглифы. Следуя за движением SUBTLEX, Cai & Brysbaert 2010 недавно провели обширное исследование частоты китайских слов и символов.
Другой
[ редактировать ]Викисловарь:Списки частот содержат списки частот на большем количестве языков. [ 20 ]
Наиболее часто используемые слова на разных языках на основе Википедии или объединенных корпусов. [ 21 ]
См. также
[ редактировать ]- Частота букв
- Самые распространенные слова в английском языке
- Длинный хвост
- Google Ngram Viewer – показывает изменения частоты слов/фраз (и относительной частоты) с течением времени.
Примечания
[ редактировать ]- ^ «Crr » Частота слов субтитров» .
- ^ Боада, Роджер; Гуаш, Марк; Аро, Хуан; Деместре, Хосеп; Ферре, Пилар (1 февраля 2020 г.). «SUBTLEX-CAT: Частота слов в субтитрах и контекстное разнообразие каталонского языка» . Методы исследования поведения . 52 (1): 360–375. дои : 10.3758/s13428-019-01233-1 . ISSN 1554-3528 . ПМИД 30895456 . S2CID 84843788 .
- ^ Амента, Симона; Мандера, Павел; Кеулерс, Эммануэль; Брисберт, Марк; Крепальди, Давиде (7 января 2022 г.). «СУБТЛЕКС-ИТ» .
- ^ Бонтрагер, Терри (1 апреля 1991 г.). «Развитие списков частот слов до списка Торндайка-Лорге 1944 года» . Чтение психологии . 12 (2): 91–116. дои : 10.1080/0270271910120201 . ISSN 0270-2711 .
- ^ «АПА ПсихНет» . psycnet.apa.org . Проверено 15 мая 2023 г.
- ^ «Слова и фразы: частота, жанры, словосочетания, соответствия, синонимы и WordNet» .
- ^ «Корпус современного американского английского языка (COCA)» .
- ^ «Это ссылки, дурак» . Экономист. 20 апреля 2006 года . Проверено 5 июня 2008 г.
- ^ Мерхольц, Питер (1999). «Петерме.com» . Интернет-архив . Архивировано из оригинала 13 октября 1999 г. Проверено 5 июня 2008 г.
- ^ Коттке, Джейсон (26 августа 2003 г.). «коттке.орг» . Проверено 5 июня 2008 г.
- ^ «Фундаментальный Франсез» . Архивировано из оригинала 4 июля 2010 г.
- ^ Узулиас, Андре (2004), Понимание и помощь детям с академическими трудностями: фундаментальный словарный запас, 70 основных слов (PDF) , Retz - Цитируя VAC Henmon (неработающая ссылка, нет копии в Интернет-архиве, 10 августа 2023 г.)
- ^ Список «70 основных слов», определенных VAC Henmon.
- ^ «Общие сведения» .
- ^ «PDF 3000 французских слов» .
- ^ «Овладение языком в школе: Словарный запас» . Министерство национального образования.
- ^ Бодо, Ж. (1992), Частоты употребления слов в современном письменном французском языке , Presses de L'Université, ISBN 978-2-7606-1563-2
- ^ «Лексик »
- ^ «Списки частотности испанских слов» . Vocabularywiki.pbworks.com .
- ^ Викисловарь:Списки частот
- ^ Наиболее часто употребляемые слова на разных языках , эзглот
Ссылки
[ редактировать ]Теоретические концепции
[ редактировать ]- Нэйшн, П. (1997), «Размер словарного запаса, охват текста и списки слов» , у Шмитта; Маккарти (ред.), Словарь: описание, приобретение и педагогика , Кембридж: Издательство Кембриджского университета, стр. 6–19, ISBN. 978-0-521-58551-4
- Лауфер, Б. (1997), «Что в слове делает его трудным или легким? Некоторые интралексические факторы, влияющие на изучение слов», Словарь: описание, освоение и педагогика , Кембридж: Cambridge University Press, стр. 140– 155, ISBN 9780521585514
- Нация, П. (2006), «Языковое образование — словарный запас», Энциклопедия языка и лингвистики , Оксфорд: 494–499, doi : 10.1016/B0-08-044854-2/00678-7 , ISBN 9780080448541 .
- Брисберт, Марк; Бухмайер, Матиас; Конрад, Маркус; Джейкобс, Артур М.; Бёльте, Йенс; Бёль, Андреа (2011). «Эффект частоты слова: обзор последних событий и последствий для выбора оценок частоты в немецком языке» . Экспериментальная психология . 58 (5): 412–424. дои : 10.1027/1618-3169/a000123 . ПМИД 21768069 . база данных
- Руделл, AP (1993), «Частота использования слов и воспринимаемая сложность слов: рейтинги слов Кучеры и Фрэнсиса», Most , vol. 25, стр. 455–463.
- Сеги, Дж.; Мелер, Жак; Фрауэнфельдер, Ули; Мортон, Джон (1982), «Эффект частоты слов и лексический доступ» , Neuropsychologia , 20 (6): 615–627, doi : 10.1016/0028-3932(82)90061-6 , PMID 7162585 , S2CID 39694258
- Мейер, Хельмут (1967), Статистика немецкого языка , Хильдесхайм: Олмс (список частотности немецких слов)
- ДеФрэнсис, Джон (1966), Почему Джонни не умеет читать по-китайски
- ) Алланик , Бернар ( 2003
Базы данных на основе письменных текстов
[ редактировать ]- Да, Джун (1998), Джун Да: текстовые вычисления на китайском языке , получено 21 августа 2010 г.
- Министерство образования Тайваня (1997), Отчет об исследовании часто используемых слов за 86 лет , получено 21 августа 2010 г.
- Новый, Борис; Пальер, Кристоф, Lexicon Guide 3 (на французском языке) (изд. 3.01) .
- Гименес, Мануэль; Нью, Борис (2016), «Worldlex: частоты слов в Twitter и блогах для 66 языков», Behavior Research Methods , 48 (3): 963–972, doi : 10.3758/s13428-015-0621-0 , ISSN 1554-3528 , ПМИД 26170053 .
СУБТЛЕКС движение
[ редактировать ]- Нью, Б.; Брисберт, М.; Веронис, Дж.; Пальер, К. (2007). «SUBTLEX-FR: Использование субтитров к фильмам для оценки частоты слов» (PDF) . Прикладная психолингвистика . 28 (4): 661. doi : 10.1017/s014271640707035x . hdl : 1854/LU-599589 . S2CID 145366468 . Архивировано из оригинала (PDF) 24 октября 2016 г.
- Брисберт, Марк; Нью, Борис (2009), «Выйдя за рамки Кучеры и Фрэнсиса: критическая оценка текущих норм частоты слов и введение новой и улучшенной меры частоты слов для американского английского» (PDF) , Behavior Research Methods , 41 (4): 977–990, doi : 10.3758/brm.41.4.977 , PMID 19897807 , S2CID 4792474
- Койлерс, Э, М, Б.; Нью, Б. (2010), «SUBTLEX--NL: новый показатель частоты голландских слов на основе субтитров к фильмам» , Behavior Research Methods , 42 (3): 643–650, doi : 10.3758/brm.42.3.643 , ПМИД 20805586
{{citation}}: CS1 maint: несколько имен: список авторов ( ссылка ) - Цай, К.; Брисберт, М. (2010), «SUBTLEX-CH: Частота китайских слов и символов на основе субтитров к фильмам», PLOS ONE , 5 (6): 8, Bibcode : 2010PLoSO...510729C , doi : 10.1371/journal.pone. 0010729 , ПМК 2880003 , ПМИД 20532192
- Куэтос, Ф.; Глез-ности, Мария; Барбон, Аналия; Брисберт, Марк (2011), «SUBTLEX-ESP: частота испанских слов на основе субтитров к фильмам» (PDF) , Psicológica , 32 : 133–143
- Димитропулу, М.; Дуньябейтиа, Джон Андони; Авилес, Альберто; КОРРАЛ, Хосе; Каррейрас, Мануэль (2010), «SUBTLEX-GR: частоты субтитров как лучшая оценка поведения при чтении: случай греческого языка», Frontiers in Psychology , 1 (декабрь): 12, doi : 10.3389/fpsyg.2010.00218 , PMC 3153823 , ПМИД 21833273
- Фам, Х.; Болджер, П.; Баайен, Р.Х. (2011), «SUBTLEX-VIE: показатель частоты вьетнамских слов и символов в субтитрах к фильмам», ACOL
- Брисберт, М.; Новый, Борис; Койлерс, Э. (2012), «SUBTLEX-US: добавление части речевой информации к частотам слов SUBTLEXus» (PDF) , Методы исследования поведения : 1–22 ( базы данных )
- Мандера, П.; Кеулерс, Э.; Воднецка, З.; Брисберт, М. (2014). «Subtlex-pl: оценки частоты слов на основе субтитров для польского языка» (PDF) . Методы поведения поведения . 47 (2): 471–483. дои : 10.3758/s13428-014-0489-4 . ПМИД 24942246 . S2CID 2334688 .
- Тан, К. (2012), «Корпус субтитров к фильмам на бразильском португальском языке объемом 61 миллион слов как ресурс для лингвистических исследований», UCL Work Pap Linguist (24): 208–214.
- Авдыли, Ррезарта; Куэтос, Фернандо (июнь 2013 г.), «SUBTLEX-AL: частоты албанских слов на основе субтитров к фильмам» , ILIRIA International Review , 3 (1): 285–292, doi : 10.21113/iir.v3i1.112 , ISSN 2365-8592
- СОАРЕС, Ана Паула; МАШАДО, Жуан; КОСТА, Ана; ИРИАрте, Альваро; Симоэнс, Альберто; де Алмейда, Жозе Жуан; Комесанья, Монтсеррат; Переа, Мануэль (апрель 2015 г.), «О преимуществах частоты слов и показателях контекстуального разнообразия, извлеченных из субтитров: случай португальского языка», Ежеквартальный журнал экспериментальной психологии , 68 (4): 680–696, doi : 10.1080/17470218.2014 , 964271 , PMID 25263599 , S2CID 5376519
Если внутренняя ссылка привела вас сюда по ошибке, вы можете изменить ссылку, чтобы она указывала непосредственно на нужную статью.