Иерархическая временная память
Иерархическая темпоральная память ( HTM ) — это биологически ограниченная технология машинного интеллекта, разработанная Numenta . Первоначально описанный в книге «Об интеллекте» Джеффа Хокинса и Сандры Блейксли в 2004 году , HTM сегодня в основном используется для обнаружения аномалий в потоковых данных. Технология основана на нейробиологии , физиологии и взаимодействии пирамидных нейронов в неокортексе мозга млекопитающих (в частности, человека ).
В основе HTM лежат алгоритмы обучения , которые могут хранить, изучать, выводить и вызывать последовательности высокого порядка. В отличие от большинства других машинного обучения методов , HTM постоянно изучает (в процессе без присмотра ) временные закономерности в неразмеченных данных. HTM устойчив к шуму и обладает высокой производительностью (он может изучать несколько шаблонов одновременно). Применительно к компьютерам HTM хорошо подходит для прогнозирования. [ 1 ] обнаружение аномалий, [ 2 ] классификация и, в конечном итоге, сенсомоторные приложения. [ 3 ]
HTM был протестирован и реализован в программном обеспечении с помощью примеров приложений от Numenta и нескольких коммерческих приложений от партнеров Numenta. [ нужны разъяснения ] .
Структура и алгоритмы
[ редактировать ]Типичная сеть HTM представляет собой древовидную иерархию уровней (не путать со « слоями » неокортекса , как описано ниже ). Эти уровни состоят из более мелких элементов, называемых регионами (или узлами). Один уровень иерархии может содержать несколько регионов. Более высокие уровни иерархии часто имеют меньше регионов. Более высокие уровни иерархии могут повторно использовать шаблоны, изученные на более низких уровнях, комбинируя их для запоминания более сложных шаблонов.
Каждый регион HTM имеет одну и ту же основную функцию. В режимах обучения и вывода сенсорные данные (например, данные глаз) поступают в области нижнего уровня. В режиме генерации области нижнего уровня выводят сгенерированный шаблон заданной категории. Верхний уровень обычно имеет единственную область, в которой хранятся наиболее общие и постоянные категории (понятия); они определяют или определяются более мелкими концепциями на более низких уровнях — концепциями, которые более ограничены во времени и пространстве. [ нужны разъяснения ] . При установке в режиме вывода регион (на каждом уровне) интерпретирует информацию, поступающую из его «дочерних» регионов, как вероятности категорий, которые он имеет в памяти.
Каждая область HTM обучается путем идентификации и запоминания пространственных шаблонов — комбинаций входных битов, которые часто возникают одновременно. Затем он определяет временные последовательности пространственных закономерностей, которые могут возникать одна за другой.
Как развивающаяся модель
[ редактировать ]HTM — это алгоритмический компонент Джеффа Хокинса теории интеллекта «Тысяча мозгов». Таким образом, новые данные о неокортексе постепенно включаются в модель HTM, которая со временем меняется в зависимости от реакции. Новые результаты не обязательно отменяют предыдущие части модели, поэтому идеи одного поколения не обязательно исключаются из последующего. Из-за развивающегося характера теории существовало несколько поколений алгоритмов HTM. [ 4 ] которые кратко описаны ниже.
Первое поколение: Зета 1
[ редактировать ]Первое поколение алгоритмов HTM иногда называют zeta 1 .
Обучение
[ редактировать ]Во время обучения узел (или регион) получает на вход временную последовательность пространственных шаблонов. Процесс обучения состоит из двух этапов:
- Пространственное объединение идентифицирует (во входных данных) часто наблюдаемые закономерности и запоминает их как «совпадения». Закономерности, существенно похожие друг на друга, рассматриваются как одно и то же совпадение. Большое количество возможных входных шаблонов сводится к управляемому количеству известных совпадений.
- Временное объединение разделяет совпадения, которые могут следовать друг за другом в обучающей последовательности, на временные группы. Каждая группа шаблонов представляет собой «причину» входного шаблона (или «имя» в On Intelligence ).
Концепции пространственного и временного объединения по-прежнему весьма важны в современных алгоритмах HTM. Временное объединение еще не до конца изучено, и его значение со временем изменилось (по мере развития алгоритмов HTM).
Вывод
[ редактировать ]Во время вывода узел вычисляет набор вероятностей принадлежности шаблона каждому известному совпадению. Затем он вычисляет вероятности того, что входные данные представляют каждую временную группу. Набор вероятностей, назначенных группам, называется «верой» узла в отношении входного шаблона. (В упрощенной реализации убеждение узла состоит только из одной выигрышной группы). Это убеждение является результатом вывода, который передается одному или нескольким «родительским» узлам на следующем более высоком уровне иерархии.
«Неожиданные» шаблоны узла не имеют доминирующей вероятности принадлежности к какой-либо одной временной группе, но имеют почти равные вероятности принадлежности к нескольким группам. Если последовательности шаблонов аналогичны обучающим последовательностям, то присвоенные группам вероятности не будут меняться так часто, как будут получены шаблоны. Выход узла не изменится так сильно, а разрешение во времени [ нужны разъяснения ] потерян.
В более общей схеме убеждение узла может быть отправлено на вход любого узла(ов) на любом уровне(ях), но связи между узлами по-прежнему остаются фиксированными. Узел более высокого уровня объединяет этот вывод с выводом других дочерних узлов, образуя, таким образом, свой собственный входной шаблон.
Поскольку разрешение в пространстве и времени теряется в каждом узле, как описано выше, убеждения, сформированные узлами более высокого уровня, представляют еще больший диапазон пространства и времени. Это призвано отразить организацию физического мира так, как он воспринимается человеческим мозгом. Считается, что более крупные концепции (например, причины, действия и объекты) изменяются медленнее и состоят из более мелких концепций, которые меняются быстрее. Джефф Хокинс постулирует, что мозг развил этот тип иерархии, чтобы соответствовать, предсказывать и влиять на организацию внешнего мира.
Более подробную информацию о работе Zeta 1 HTM можно найти в старой документации Numenta. [ 5 ]
Второе поколение: алгоритмы коркового обучения
[ редактировать ]Второе поколение алгоритмов обучения HTM, часто называемое корковыми алгоритмами обучения ( CLA ), радикально отличалось от дзета-1. Оно опирается на структуру данных , называемую разреженными распределенными представлениями (то есть структуру данных, элементы которой являются двоичными, 1 или 1). 0, и количество битов 1 мало по сравнению с количеством битов 0), чтобы представить активность мозга и более биологически реалистичную модель нейрона (часто также называемую клеткой в контексте ХТМ). [ 6 ] В этом поколении HTM есть два основных компонента: алгоритм пространственного объединения , [ 7 ] который выводит разреженные распределенные представления (SDR) и алгоритм памяти последовательности , [ 8 ] который учится представлять и предсказывать сложные последовательности.
В этом новом поколении слои и миниколонки коры головного мозга рассматриваются и частично моделируются. Каждый уровень HTM (не путать с уровнем HTM иерархии HTM, как описано выше ) состоит из ряда тесно взаимосвязанных министолбцов. Уровень HTM создает разреженное распределенное представление на основе своих входных данных, так что фиксированный процент мини-столбцов активен в любой момент времени. [ нужны разъяснения ] . Под миниколонкой понимают группу клеток, имеющих одинаковое рецептивное поле . Каждый мини-столбец имеет ряд ячеек, способных запоминать несколько предыдущих состояний. Ячейка может находиться в одном из трех состояний: активном , неактивном и прогнозирующем состоянии.
Пространственное объединение
[ редактировать ]Рецептивное поле каждого мини-столбца представляет собой фиксированное количество входов, которые случайным образом выбираются из гораздо большего количества входов узла. В зависимости от (конкретного) шаблона ввода некоторые министолбцы будут более или менее связаны с активными входными значениями. Пространственное объединение выбирает относительно постоянное количество наиболее активных мини-столбцов и инактивирует (ингибирует) другие мини-столбцы вблизи активных. Подобные шаблоны ввода имеют тенденцию активировать стабильный набор мини-столбцов. Объем памяти, используемый каждым слоем, можно увеличить для изучения более сложных пространственных моделей или уменьшить для изучения более простых моделей.
Активные, неактивные и прогнозирующие клетки
[ редактировать ]Как уже говорилось выше, клетка (или нейрон) миниколонки в любой момент времени может находиться в активном, неактивном или прогнозирующем состоянии. Первоначально клетки неактивны.
Как клетки становятся активными?
[ редактировать ]Если одна или несколько ячеек в активном мини-столбце находятся в состоянии прогнозирования (см. ниже), они будут единственными ячейками, которые станут активными на текущем временном шаге. Если ни одна из ячеек в активном мини-столбце не находится в прогнозируемом состоянии (что происходит на начальном временном шаге или когда активация этого мини-столбца не ожидалась), все ячейки становятся активными.
Как клетки становятся предсказательными?
[ редактировать ]Когда ячейка становится активной, она постепенно образует связи с соседними ячейками, которые имеют тенденцию быть активными в течение нескольких предыдущих временных шагов. Таким образом, клетка учится распознавать известную последовательность, проверяя, активны ли подключенные ячейки. Если активно большое количество связанных ячеек, эта ячейка переключается в состояние прогнозирования в ожидании одного из нескольких следующих входных данных последовательности.
Вывод мини-колонки
[ редактировать ]Выходные данные слоя включают министолбцы как в активном, так и в прогнозируемом состояниях. Таким образом, министолбцы активны в течение длительных периодов времени, что приводит к большей временной стабильности, наблюдаемой родительским слоем.
Выводы и онлайн-обучение
[ редактировать ]Алгоритмы коркового обучения способны непрерывно учиться на основе каждого нового входного шаблона, поэтому отдельный режим вывода не требуется. Во время вывода HTM пытается сопоставить поток входных данных с фрагментами ранее изученных последовательностей. Это позволяет каждому уровню HTM постоянно прогнозировать вероятное продолжение распознанных последовательностей. Индекс предсказанной последовательности является результатом слоя. Поскольку прогнозы имеют тенденцию меняться реже, чем входные шаблоны, это приводит к увеличению временной стабильности выходных данных на более высоких уровнях иерархии. Прогнозирование также помогает восполнить недостающие закономерности в последовательности и интерпретировать неоднозначные данные, заставляя систему делать выводы о том, что она предсказала.
Применение CLA
[ редактировать ]Алгоритмы кортикального обучения в настоящее время предлагаются в качестве коммерческого SaaS компанией Numenta (например, Grok [ 9 ] ).
Срок действия CLA
[ редактировать ]В сентябре 2011 года Джеффу Хокинсу был задан следующий вопрос относительно алгоритмов кортикального обучения: «Как узнать, хороши ли изменения, которые вы вносите в модель, или нет?» На что Джефф ответил: «Есть две категории ответов: первая — это изучение нейронауки, а другая — методы машинного интеллекта. В области нейробиологии мы можем сделать множество прогнозов, и их можно проверить. Если наши теории объясняют широкий спектр нейробиологических наблюдений, это говорит нам о том, что мы на правильном пути. В мире машинного обучения их не волнует это, а то, насколько хорошо оно работает при решении практических задач. остается Если вы сможете решить проблему, которую никто не мог решить раньше, люди это заметят». [ 10 ]
Третье поколение: сенсомоторный вывод
[ редактировать ]Третье поколение основывается на втором поколении и добавляет теорию сенсомоторных выводов в неокортексе. [ 11 ] [ 12 ] Эта теория предполагает, что кортикальные столбцы на каждом уровне иерархии могут со временем изучать полные модели объектов и что функции изучаются в определенных местах объектов. Теория была расширена в 2018 году и получила название «Теория тысячи мозгов». [ 13 ]
Сравнение моделей нейронов
[ редактировать ]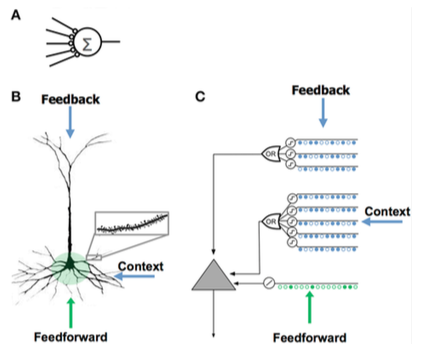
Сравнение моделей нейронов Искусственная нейронная сеть (ИНС) Неокортикальный пирамидальный нейрон (биологический нейрон ) HTM-модель нейрона [ 8 ] - Мало синапсов
- Нет дендритов
- Сумма входных данных × веса
- Обучается, изменяя веса синапсов
- Тысячи синапсов на дендритах
- Активные дендриты: клетка распознает сотни уникальных шаблонов
- Совместная активация набора синапсов на дендритном сегменте вызывает NMDA всплеск и деполяризацию сомы . [ 8 ]
- Источники ввода в ячейку:
- Входные сигналы прямой связи, которые формируют синапсы проксимальнее сомы и непосредственно приводят к потенциалам действия.
- Спайки NMDA генерируются в более дистальных базальных отделах. [ нужны разъяснения ]
- Апикальные дендриты, которые деполяризуют сому (обычно недостаточно для генерации соматического потенциала действия)
- Учится, выращивая новые синапсы
- Вдохновлен пирамидными клетками в слоях неокортекса 2/3 и 5.
- Тысячи синапсов
- Активные дендриты: клетка распознает сотни уникальных шаблонов
- Моделирует дендриты и спайки NMDA с каждым массивом совпадающих детекторов, имеющим набор синапсов.
- Обучается, моделируя рост новых синапсов
Сравнение HTM и неокортекса
[ редактировать ]HTM пытается реализовать функциональность, характерную для иерархически связанной группы корковых областей неокортекса. Область иерархии неокортекса соответствует одному или нескольким уровням НТМ, тогда как гиппокамп отдаленно похож на самый высокий уровень НТМ. Один узел HTM может представлять группу кортикальных столбцов в определенной области.
Хотя это прежде всего функциональная модель, было предпринято несколько попыток связать алгоритмы НТМ со структурой нейронных связей в слоях неокортекса. [ 14 ] [ 15 ] Неокортекс организован в виде вертикальных столбцов из шести горизонтальных слоев. Шесть слоев клеток неокортекса не следует путать с уровнями иерархии НТМ.
Узлы HTM пытаются смоделировать часть кортикальных столбцов (от 80 до 100 нейронов) примерно с 20 «ячейками» HTM на столбец. HTM моделируют только слои 2 и 3 для обнаружения пространственных и временных характеристик входных данных с 1 ячейкой на столбец в слое 2 для пространственного «объединения» и от 1 до 2 дюжин на столбец в слое 3 для временного объединения. Ключом к HTM и коре головного мозга является их способность справляться с шумом и изменениями входных данных, что является результатом использования «разреженного распределительного представления», при котором только около 2% столбцов активны в любой момент времени.
HTM пытается смоделировать часть обучения и пластичности коры, как описано выше. Различия между HTM и нейронами включают: [ 16 ]
- строго бинарные сигналы и синапсы
- нет прямого ингибирования синапсов или дендритов (но моделируется косвенно)
- в настоящее время моделируются только слои 2/3 и 4 (нет 5 или 6)
- нет «моторного» управления (уровень 5)
- нет обратной связи между регионами (от уровня 6 высокого уровня до уровня 1 низкого уровня)
Разреженные распределенные представления
[ редактировать ]Интеграция компонента памяти с нейронными сетями имеет долгую историю, восходящую к ранним исследованиям распределенных представлений. [ 17 ] [ 18 ] и самоорганизующиеся карты . Например, в разреженной распределенной памяти (SDM) шаблоны, закодированные нейронными сетями, используются в качестве адресов памяти для памяти, адресуемой по содержимому , при этом «нейроны», по существу, служат кодировщиками и декодерами адресов. [ 19 ] [ 20 ]
Компьютеры хранят информацию в плотных представлениях, таких как 32-битное слово , где возможны все комбинации единиц и нулей. Напротив, мозг использует разреженные распределенные представления (SDR). [ 21 ] Неокортекс человека содержит примерно 16 миллиардов нейронов, но в любой момент времени активен лишь небольшой процент. Действия нейронов подобны битам в компьютере, поэтому их представление скудно. Похож на SDM, разработанный НАСА в 80-х годах. [ 19 ] и модели векторного пространства , используемые в скрытом семантическом анализе , HTM использует разреженные распределенные представления. [ 22 ]
SDR, используемые в HTM, представляют собой двоичные представления данных, состоящих из множества битов с небольшим процентом активных битов (1 с); типичная реализация может иметь 2048 столбцов и 64 тыс. искусственных нейронов, из которых одновременно может быть активно всего 40. Хотя может показаться менее эффективным, чтобы большинство битов оставались «неиспользованными» в любом заданном представлении, у SDR есть два основных преимущества по сравнению с традиционными плотными представлениями. Во-первых, SDR терпимы к искажениям и двусмысленности из-за того, что значение представления разделяется ( распределяется ) по небольшому проценту ( редкости ) активных битов. В плотном представлении переворот одного бита полностью меняет смысл, тогда как в SDR один бит может не сильно повлиять на общий смысл. Это приводит ко второму преимуществу SDR: поскольку значение представления распределено по всем активным битам, сходство между двумя представлениями можно использовать как меру семантического сходства объектов, которые они представляют. То есть, если два вектора в SDR имеют единицы в одной и той же позиции, то они семантически схожи по этому атрибуту. Биты в SDR имеют семантическое значение, и это значение распределяется по битам. [ 22 ]
Теория складки семантической [ 23 ] опирается на эти свойства SDR, чтобы предложить новую модель семантики языка, в которой слова кодируются в слова-SDR, а сходство между терминами, предложениями и текстами может быть рассчитано с помощью простых мер расстояния.
Сходство с другими моделями
[ редактировать ]Байесовские сети
[ редактировать ]По аналогии с байесовской сетью , HTM состоит из набора узлов, расположенных в виде древовидной иерархии. Каждый узел иерархии обнаруживает массив причин во входных шаблонах и временных последовательностях, которые он получает. Алгоритм пересмотра байесовских убеждений используется для распространения убеждений прямой связи и обратной связи от дочерних узлов к родительским и наоборот. Однако аналогия с байесовскими сетями ограничена, поскольку HTM могут быть самообучаемыми (таким образом, что каждый узел имеет однозначную семейную связь), справляться с чувствительными ко времени данными и предоставлять механизмы для скрытого внимания .
Теория иерархических корковых вычислений, основанная на байесовском распространении убеждений, была предложена ранее Тай Синг Ли и Дэвидом Мамфордом . [ 24 ] Хотя HTM в основном соответствует этим идеям, он добавляет подробности об обработке инвариантных представлений в зрительной коре. [ 25 ]
Нейронные сети
[ редактировать ]Как и любую систему, моделирующую детали неокортекса, HTM можно рассматривать как искусственную нейронную сеть . Древовидная иерархия, обычно используемая в HTM, напоминает обычную топологию традиционных нейронных сетей. HTM пытаются смоделировать кортикальные столбцы (от 80 до 100 нейронов) и их взаимодействие с меньшим количеством «нейронов» HTM. Цель современных HTM — охватить как можно больше функций нейронов и сети (в том виде, в котором они сейчас понимаются) в пределах возможностей типичных компьютеров и в областях, которые можно легко сделать полезными, например, при обработке изображений. Например, обратная связь от более высоких уровней и двигательный контроль не предпринимаются, потому что еще не понятно, как их включить, а вместо переменных синапсов используются двоичные, поскольку они были признаны достаточными в текущих возможностях HTM.
ЛАМИНАРТ и подобные нейронные сети, исследованные Стивеном Гроссбергом, пытаются смоделировать как инфраструктуру коры, так и поведение нейронов во временных рамках, чтобы объяснить нейрофизиологические и психофизические данные. Однако в настоящее время эти сети слишком сложны для реального применения. [ 26 ]
HTM также связан с работой Томасо Поджо , включая подход к моделированию вентрального потока зрительной коры, известный как HMAX. Сходства HTM с различными идеями искусственного интеллекта описаны в декабрьском номере журнала «Искусственный интеллект» за 2005 год. [ 27 ]
Неокогнитрон
[ редактировать ]Неокогнитрон , иерархическая многослойная нейронная сеть, предложенная профессором Кунихико Фукусимой в 1987 году, является одной из первых моделей нейронных сетей глубокого обучения . [ 28 ]
См. также
[ редактировать ]- Искусственное сознание
- Общий искусственный интеллект
- Пересмотр убеждений
- Когнитивная архитектура
- Сверточная нейронная сеть
- Список проектов искусственного интеллекта
- Структура прогнозирования памяти
- Теория множественных следов
- Компрессор нейронной истории
- Нейронная машина Тьюринга
Похожие модели
[ редактировать ]Ссылки
[ редактировать ]- ^ Цуй, Ювэй; Ахмад, Субутай; Хокинс, Джефф (2016). «Непрерывное онлайн-последовательное обучение с использованием модели нейронной сети без учителя». Нейронные вычисления . 28 (11): 2474–2504. arXiv : 1512.05463 . дои : 10.1162/NECO_a_00893 . ПМИД 27626963 . S2CID 3937908 .
- ^ Ахмад, Субутай; Лавин, Александр; Перди, Скотт; Ага, Зуха (2017). «Неконтролируемое обнаружение аномалий в реальном времени для потоковых данных» . Нейрокомпьютинг . 262 : 134–147. дои : 10.1016/j.neucom.2017.04.070 .
- ^ «Предварительные подробности о новой теоретической работе по сенсомоторному выводу» . ХТМ Форум . 03.06.2016.
- ^ Ретроспектива HTM на YouTube
- ^ «Нумента старая документация» . numenta.com . Архивировано из оригинала 27 мая 2009 г.
- ^ Лекция Джеффа Хокинса, описывающая алгоритмы коркового обучения, на YouTube.
- ^ Цуй, Ювэй; Ахмад, Субутай; Хокинс, Джефф (2017). «Пространственный пул HTM — неокортикальный алгоритм для онлайн-разреженного распределенного кодирования» . Границы вычислительной нейронауки . 11 : 111. дои : 10.3389/fncom.2017.00111 . ПМК 5712570 . ПМИД 29238299 .
- ^ Jump up to: а б с Хокинс, Джефф; Ахмад, Субутай (30 марта 2016 г.). «Почему нейроны имеют тысячи синапсов: теория последовательной памяти в неокортексе» . Передний. Нейронные цепи . 10:23 . doi : 10.3389/fncir.2016.00023 . ПМК 4811948 . ПМИД 27065813 .
- ^ «Страница продукта Grok» . grokstream.com . Архивировано из оригинала 26 апреля 2019 г. Проверено 12 августа 2017 г.
- ^ Лазерсон, Джонатан (сентябрь 2011 г.). «От нейронных сетей к глубокому обучению: внимание к человеческому мозгу» (PDF) . Рентгенографический анализ . 18 (1). дои : 10.1145/2000775.2000787 . S2CID 21496694 .
- ^ Хокинс, Джефф; Ахмад, Субутай; Цуй, Ювэй (2017). «Теория того, как столбцы в неокортексе позволяют изучать структуру мира» . Границы в нейронных цепях . 11 : 81. doi : 10.3389/fncir.2017.00081 . ПМК 5661005 . ПМИД 29118696 .
- ^ Мы пропустили половину того, что делает неокортекс? Аллоцентрическое расположение как основа восприятия на YouTube
- ^ «Numenta публикует революционную теорию интеллекта и корковых вычислений» . www.eurekalert.org . 14 января 2019 г.
- ^ Хокинс, Джефф ; Блейксли, Сандра . Об интеллекте .
- ^ Джордж, Дилип; Хокинс, Джефф (2009). «К математической теории корковых микросхем» . PLOS Вычислительная биология . 5 (10): е1000532. Бибкод : 2009PLSCB...5E0532G . дои : 10.1371/journal.pcbi.1000532 . ПМК 2749218 . ПМИД 19816557 .
- ^ «Кортикальные алгоритмы обучения HTM» (PDF) . numenta.org .
- ^ Хинтон, Джеффри Э. (1984). Распределенные представления (PDF) (Технический отчет). Факультет компьютерных наук Университета Карнеги-Меллона. КМУ-КС-84-157.
- ^ Плейт, Тони (1991). «Голографические приведенные представления: алгебра свертки для композиционно распределенных представлений» (PDF) . ИДЖКАИ .
- ^ Jump up to: а б Канерва, Пентти (1988). Разреженная распределенная память . Массачусетский технологический институт Пресс ISBN 9780262111324 .
- ^ Снайдер, Хавьер; Франклин, Стэн (2012). Целочисленная разреженная распределенная память (PDF) . Двадцать пятая международная конференция флейринга. S2CID 17547390 . Архивировано из оригинала (PDF) 29 декабря 2017 г.
- ^ Ольсхаузен, Бруно А.; Филд, Дэвид Дж. (1997). «Разреженное кодирование с чрезмерно полным базисным набором: стратегия, используемая V1?» . Исследование зрения . 37 (23): 3311–3325. дои : 10.1016/S0042-6989(97)00169-7 . ПМИД 9425546 . S2CID 14208692 .
- ^ Jump up to: а б Ахмад, Субутай; Хокинс, Джефф (2016). «Numenta NUPIC – разреженные распределенные представления». arXiv : 1601.00720 [ q-bio.NC ].
- ^ Де Соуза Уэббер, Франциско (2015). «Теория семантической складки и ее применение в семантическом дактилоскопировании». arXiv : 1511.08855 [ cs.AI ].
- ^ Ли, Тай Синг; Мамфорд, Дэвид (2002). «Иерархический байесовский вывод в зрительной коре». Журнал Оптического общества Америки А. 20 (7): 1434–48. CiteSeerX 10.1.1.12.2565 . дои : 10.1364/josaa.20.001434 . ПМИД 12868647 .
- ^ Джордж, Дилип (24 июля 2010 г.). «Иерархический байесовский вывод в зрительной коре» . dileepgeorge.com . Архивировано из оригинала 01 августа 2019 г.
- ^ Гроссберг, Стивен (2007). Чисек, Пол; Дрю, Тревор; Каласка, Джон (ред.). На пути к единой теории неокортекса: ламинарные корковые цепи зрения и познания. Технический отчет CAS/CNS-TR-2006-008. Для вычислительной нейронауки: от нейронов к теории и обратно (PDF) (отчет). Амстердам: Эльзевир. стр. 79–104. Архивировано из оригинала (PDF) 29 августа 2017 г.
- ^ «Специальный выпуск обзора» . Искусственный интеллект . 169 (2): 103–212. Декабрь 2005 г. doi : 10.1016/j.artint.2005.10.001 .
- ^ Фукусима, Кунихико (2007). «Неокогнитрон » Схоларпедия . 2 (1): 1717. Бибкод : 2007SchpJ... 2.1717F. doi : 10.4249/scholarpedia.1717 .
Дальнейшее чтение
[ редактировать ]- Ахмад, Субутай; Хокинс, Джефф (25 марта 2015 г.). «Свойства разреженных распределенных представлений и их применение к иерархической временной памяти». arXiv : 1503.07469 [ q-bio.NC ].
- Хокинс, Джефф (апрель 2007 г.). «Учись как человек» . IEEE-спектр .
- Мальтони, Давиде (13 апреля 2011 г.). «Распознавание образов с помощью иерархической временной памяти» (PDF) . Технический отчет DEIS. Италия: Болонский университет.
- Рэтлифф, Эван (март 2007 г.). «Мыслящая машина» . Проводной .
Внешние ссылки
[ редактировать ]- HTM и Нумента
- Основы HTM с Рахулом (Нумента), разговор об алгоритме коркового обучения (CLA), используемом моделью HTM, на YouTube