Подбор вероятностного распределения
Подбор распределения вероятностей или просто подбор распределения — это подбор распределения вероятностей к ряду данных, касающихся повторных измерений переменного явления.Целью подбора распределения является частоты возникновения величины явления предсказание вероятности или прогнозирования в определенном интервале.
Существует множество распределений вероятностей (см. список распределений вероятностей ), из которых некоторые можно более точно подогнать к наблюдаемой частоте данных, чем другие, в зависимости от характеристик явления и распределения. Предполагается, что распределение, дающее точное соответствие, приведет к хорошим прогнозам.Поэтому при подборе распределения необходимо выбрать распределение, которое хорошо соответствует данным.
Выбор дистрибутива
[ редактировать ]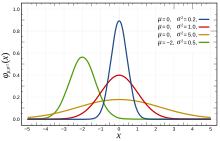
Выбор подходящего распределения зависит от наличия или отсутствия симметрии набора данных относительно центральной тенденции .
Симметричные распределения
Когда данные симметрично распределены вокруг среднего значения, а частота появления данных дальше от среднего значения уменьшается, можно, например, выбрать нормальное распределение , логистическое распределение или t-распределение Стьюдента . Первые два очень похожи, тогда как последний, с одной степенью свободы, имеет «более тяжелые хвосты», что означает, что значения, находящиеся дальше от среднего значения, встречаются относительно чаще (т.е. эксцесс выше ). Распределение Коши также симметрично.
Скос распределения вправо
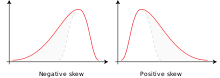
Когда большие значения имеют тенденцию быть дальше от среднего значения, чем меньшие значения, наблюдается асимметрия распределения вправо (т. е. имеется положительная асимметрия ), можно, например, выбрать логарифмически нормальное распределение (т. е. логарифмические значения данные обычно распределяются ), логарифмически-логистическое распределение (т.е. логарифмические значения данных следуют логистическому распределению ), распределение Гамбеля , экспоненциальное распределение , распределение Парето , распределение Вейбулла , распределение Берра или распределение Фреше . Последние четыре распределения ограничены слева.
Скос распределения влево
Когда меньшие значения имеют тенденцию быть дальше от среднего значения, чем большие значения, наблюдается асимметрия распределения влево (т. е. имеется отрицательная асимметрия), можно, например, выбрать квадратично-нормальное распределение (т. е. нормальное распределение, применяемое к квадрат значений данных), [1] инвертированное (зеркальное) распределение Гамбеля, [1] распределение Дагума (зеркальное распределение Берра) или распределение Гомпертца , ограниченное слева.
Техники примерки
[ редактировать ]Существуют следующие методы подбора распределения: [2]
- Параметрические методы , с помощью которых параметры распределения рассчитываются по ряду данных. [3] Параметрические методы:
Например, параметр ( ожидание ) можно оценить по среднему значению данных и параметру ( дисперсия ) может быть оценена по стандартному отклонению данных. Среднее значение находится как , где значение данных и количество данных, а стандартное отклонение рассчитывается как . С помощью этих параметров полностью определяются многие распределения, например нормальное распределение.







- Положение графика плюс регрессионный анализ с использованием преобразования кумулятивной функции распределения таким образом, чтобы линейная связь была найдена между кумулятивной вероятностью и значениями данных, которые также может потребоваться преобразовать в зависимости от выбранного распределения вероятностей. В этом методе кумулятивную вероятность необходимо оценивать по положению графика. [6]
Например, кумулятивное распределение Гамбеля можно линеаризовать до , где это переменная данных и , с кумулятивная вероятность, т. е. вероятность того, что значение данных меньше . Таким образом, используя положение графика для , находятся параметры и из линейной регрессии на , и распределение Гамбеля полностью определено.






Обобщение распределений
[ редактировать ]Обычно данные преобразуются логарифмически, чтобы соответствовать симметричным распределениям (таким как нормальное и логистическое ) к данным, подчиняющимся распределению, которое имеет положительный сдвиг (т. е. сдвиг вправо, со средним > режимом и с правым хвостом, который длиннее, чем левый хвост), см. логнормальное распределение и логлогистическое распределение . Аналогичного эффекта можно добиться, извлекая квадратный корень из данных.
Чтобы подогнать симметричное распределение к данным, подчиняющимся отрицательно перекошенному распределению (т.е. перекошенному влево, со средним < mode и с правым хвостом, который короче левого), можно использовать квадраты значений данных для достижения подходит.
В более общем смысле можно возвести данные в степень p, чтобы подогнать симметричные распределения к данным, подчиняющимся распределению любой асимметрии, при этом p < 1, когда асимметрия положительна, и p > 1, когда асимметрия отрицательна. Оптимальное значение p необходимо найти численным методом . Численный метод может состоять в предположении диапазона значений p , затем многократном применении процедуры подбора распределения для всех предполагаемых значений p и, наконец, выборе значения p, для которого сумма квадратов отклонений рассчитанных вероятностей от измеренных частот ( chi Squared ) минимально, как это сделано в CumFreq .
Обобщение повышает гибкость вероятностных распределений и увеличивает их применимость при подборе распределений. [6]
Универсальность обобщения позволяет, например, подогнать приблизительно нормально распределенные наборы данных к большому количеству различных распределений вероятностей. [7] в то время как отрицательно асимметричные распределения могут быть адаптированы к квадратное нормальное и зеркальное распределения Гамбеля. [8]
Инверсия асимметрии
[ редактировать ]
Перекошенные распределения можно инвертировать (или отзеркалить), заменив в математическом выражении кумулятивную функцию распределения (F) ее дополнением: F'=1-F, получив дополнительную функцию распределения (также называемую функцией выживания ), дающую зеркальное отображение. . Таким образом, распределение, смещенное вправо, преобразуется в распределение, смещенное влево, и наоборот.
Пример . F-выражение положительно асимметричного распределения Гамбеля имеет следующий вид: F=exp[-exp{-( X - u )/0,78 s }], где u — мода (т. е. значение, встречающееся наиболее часто), а s — стандартное отклонение. . Распределение Гамбеля можно преобразовать с помощью F'=1-exp[-exp{-( x - u )/0,78 s }] . Это преобразование дает обратное, зеркальное или дополнительное распределение Гамбеля, которое может соответствовать ряду данных, подчиняющемуся отрицательно искаженному распределению.
Метод инверсии асимметрии увеличивает количество вероятностных распределений, доступных для аппроксимации распределения, и расширяет возможности аппроксимации распределения.
Сдвиг раздач
[ редактировать ]Некоторые распределения вероятностей, такие как экспоненциальное , не поддерживают отрицательные значения данных ( X ). менее, при наличии отрицательных данных такие распределения все равно можно использовать, заменяя X на Y = X - Xm , где Xm — минимальное значение X. Тем не Эта замена представляет собой сдвиг распределения вероятностей в положительном направлении, т.е. вправо, поскольку Xm отрицательно. После завершения подбора распределения Y соответствующие значения X находятся из X = Y + Xm , что представляет собой обратный сдвиг распределения в отрицательном направлении, т.е. влево.
Техника сдвига распределения увеличивает шанс найти правильно подходящее распределение вероятностей.
Составные дистрибутивы
[ редактировать ]
Существует возможность использовать два разных распределения вероятностей: одно для нижнего диапазона данных, а другое для более высокого, например, распределение Лапласа . Диапазоны разделены точкой останова. Использование таких составных (разрывных) распределений вероятностей может оказаться целесообразным, когда данные изучаемого явления получены при двух наборах различных условий. [6]
Неопределенность прогноза
[ редактировать ]
Прогнозы событий, основанные на подобранных распределениях вероятностей, подвержены неопределенности , которая возникает из-за следующих условий:
- Истинное распределение вероятностей событий может отклоняться от подобранного распределения, поскольку наблюдаемый ряд данных может не полностью отражать реальную вероятность возникновения явления из-за случайной ошибки.
- Возникновение событий в другой ситуации или в будущем может отклоняться от подобранного распределения, поскольку это возникновение также может быть подвержено случайной ошибке.
- Изменение условий окружающей среды может вызвать изменение вероятности возникновения явления.

Оценку неопределенности в первом и втором случае можно получить с помощью биномиального распределения вероятностей, используя, например, вероятность превышения Pe (т. е. вероятность того, что событие X превышает эталонное значение Xr для X ) и вероятность невыполнения -превышение Pn (т.е. вероятность того, что событие X меньше или равно эталонному значению Xr , это также называется кумулятивной вероятностью ). В этом случае есть только две возможности: либо превышение, либо непревышение. Эта двойственность является причиной применимости биномиального распределения.
С помощью биномиального распределения можно получить интервал прогнозирования . Такой интервал также оценивает риск неудачи, т.е. вероятность того, что прогнозируемое событие все равно останется за пределами доверительного интервала. Анализ достоверности или риска может включать период повторяемости T=1/Pe , как это делается в гидрологии .
Дисперсия байесовских вероятности функций
[ редактировать ]Для подбора модели можно использовать байесовский подход. наличие предварительного распределения для параметра . Когда у кого-то есть образцы которые извлекаются независимо из основного распределения, то можно получить так называемое апостериорное распределение . Этот апостериор можно использовать для обновления функции массы вероятности для новой выборки. учитывая наблюдения , получается





.

Также можно определить дисперсию вновь полученной функции вероятности. Дисперсия байесовской функции массы вероятности может быть определена как
.
![{\displaystyle \sigma _{P_{\theta }(x|X)}^{2}:=\int d\theta \ \left[P(x|\theta)-P_{\theta }(x|X )\right]^{2}\ P(\theta |X)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de226ff5d1c090c1f59bcffe841e95cbeb02577a)
Это выражение для дисперсии можно существенно упростить (при условии, что выборки составлены независимо). Определение «массовой функции самовероятности» как
,

получаем для дисперсии [12]
.
![{\displaystyle \sigma _{P_{\theta }(x|X)}^{2}=P_{\theta }(x|X)\left[P_{\theta }(x|\left\{X, x\right\})-P_{\theta }(x|X)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d836ebe9321e14e2c6ffc959fa71ebac5f0a2c7)
Выражение для дисперсии включает дополнительную подгонку, включающую выборку. интереса.


Хорошая посадка
[ редактировать ]Ранжируя степень соответствия различных распределений, можно получить представление о том, какое распределение приемлемо, а какое нет.
Гистограмма и функция плотности
[ редактировать ]Из кумулятивной функции распределения (CDF) можно получить гистограмму и функцию плотности вероятности (PDF).
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Jump up to: а б Скошенные влево (отрицательно) частотные гистограммы можно подогнать к квадратным нормальным или зеркальным функциям вероятности Гамбеля. На линии: [1]
- ^ Частотный и регрессионный анализ . Глава 6 в: HPRitzema (изд., 1994), Принципы и применение дренажа , Publ. 16, стр. 175–224, Международный институт мелиорации и улучшения земель (ILRI), Вагенинген, Нидерланды. ISBN 9070754339 . Бесплатная загрузка с веб-страницы [2] под номером. 12 или напрямую в формате PDF: [3]
- ^ Х. Крамер, «Математические методы статистики», Princeton Univ. Пресс (1946)
- ^ Хоскинг, JRM (1990). «L-моменты: анализ и оценка распределений с использованием линейных комбинаций порядковой статистики». Журнал Королевского статистического общества, серия B. 52 (1): 105–124. JSTOR 2345653 .
- ^ Олдрич, Джон (1997). «Р. А. Фишер и создание максимальной вероятности 1912–1922» . Статистическая наука . 12 (3): 162–176. дои : 10.1214/ss/1030037906 . МР 1617519 .
- ^ Jump up to: а б с Программное обеспечение для обобщенных и составных вероятностных распределений. Международный журнал математических и вычислительных методов, 4, 1–9 [4] или [5]
- ^ Пример примерно нормального распределенный набор данных, к которому можно подобрать большое количество различных распределений вероятностей, [6]
- ^ Могут быть перекошены гистограммы частоты влево (отрицательно). соответствуют квадратичным нормальным или зеркальным функциям вероятности Гамбеля. [7]
- ^ Введение в составные распределения вероятностей
- ^ Прогнозы частоты и их биномиальные доверительные пределы. В: Международная комиссия по ирригации и дренажу, Специальная техническая сессия: Экономические аспекты борьбы с наводнениями и неструктурные меры, Дубровник, Югославия, 1988. Онлайн.
- ^ Бенсон, Массачусетс, 1960. Характеристики кривых частоты, основанные на теоретических 1000-летних данных. В: Т.Далримпл (ред.), Анализ частоты наводнений. Документ Геологической службы США по водоснабжению, 1543-A, стр. 51–71.
- ^ Пийльман; Линнарц (2023). «Дисперсия правдоподобия данных» . Материалы SITB 2023 : 34.
- ^ Программное обеспечение для подбора распределения вероятностей.