Функциональный анализ данных
Функциональный анализ данных (FDA) — это раздел статистики , который анализирует данные, предоставляя информацию о кривых, поверхностях или чем-либо еще, изменяющемся в континууме. В самой общей форме, в рамках FDA, каждый элемент выборки функциональных данных считается случайной функцией. Физическим континуумом, в котором определяются эти функции, часто является время, но также может быть пространственное местоположение, длина волны, вероятность и т. д. По своей сути функциональные данные бесконечномерны. Высокая внутренняя размерность этих данных создает проблемы как для теории, так и для вычислений, причем эти проблемы зависят от того, как были выбраны функциональные данные. Однако многомерная или бесконечномерная структура данных является богатым источником информации, и существует множество интересных задач для исследований и анализа данных.
История
[ редактировать ]Функциональный анализ данных уходит своими корнями в работы Гренандера и Кархунена в 1940-х и 1950-х годах. [1] [2] [3] [4] Они рассмотрели разложение интегрируемого с квадратом стохастического процесса с непрерывным временем на собственные компоненты, теперь известное как разложение Карунена-Лоэва . Строгий анализ анализа главных функциональных компонентов был проведен в 1970-х годах Клеффе, Досуа и Пуссом, включая результаты об асимптотическом распределении собственных значений. [5] [6] Совсем недавно, в 1990-х и 2000-х годах, эта область больше сосредоточилась на приложениях и понимании эффектов плотных и разреженных схем наблюдений. Термин «Функциональный анализ данных» был придуман Джеймсом О. Рамзи . [7]
Математический формализм
[ редактировать ]Случайные функции можно рассматривать как случайные элементы, принимающие значения в гильбертовом пространстве , или как случайный процесс . Первое математически удобно, тогда как второе несколько более пригодно с прикладной точки зрения. Эти два подхода совпадают, если случайные функции непрерывны и условие, называемое среднеквадратичной непрерывностью . выполняется [8]
Гильбертовы случайные величины
[ редактировать ]С точки зрения гильбертова пространства рассматривается -значный случайный элемент , где - сепарабельное гильбертово пространство, такое как пространство интегрируемых с квадратом функций . При условии интегрируемости, что , можно определить среднее значение как уникальный элемент удовлетворяющий


![{\displaystyle L^{2}[0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0cec70e845808e22e359ab32ed7c3c0d946fab70)



Эта формулировка представляет собой интеграл Петтиса , но среднее значение также можно определить как интеграл Бохнера. . При условии интегрируемости, что конечен, оператор ковариационный является линейным оператором однозначно определяемое соотношением



![{\displaystyle {\mathcal {C}}h=\mathbb {E} [\rangle h,X-\mu \rangle (X-\mu)],\quad h\in H,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d78d952144a26c69cacb4b333a3fd5a41ec2d5c)
или, в тензорной форме, . Спектральная теорема позволяет разложить как разложение Карунена-Лоэва
![{\displaystyle {\mathcal {C}}=\mathbb {E} [(X-\mu )\otimes (X-\mu )]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ddfd0d1b91b177d50f38fb344a433984e5c602b)

где являются собственными векторами , соответствующие неотрицательным собственным значениям , в невозрастающем порядке. Усечение этого бесконечного ряда до конечного порядка лежит в основе функционального анализа главных компонент .


Случайные процессы
[ редактировать ]Гильбертова точка зрения математически удобна, но абстрактна; приведенные выше соображения не обязательно даже рассматривают вообще как функция, поскольку общий выбор нравиться и пространства Соболева состоят из классов эквивалентности, а не из функций. Перспективы стохастического процесса как набор случайных величин
![{\displaystyle \{X(t)\}_{t\in [0,1]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/45ca3a75461bffe5a913ccc863136879bd6964af)
индексируется единичным интервалом (или, в более общем смысле, интервалом ). Функции среднего и ковариации определяются поточечно как

![{\displaystyle \mu (t)=\mathbb {E} X(t),\qquad \Sigma (s,t)={\textrm {Cov}}(X(s),X(t)),\qquad с,т\в [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/929a6a917012f2b12e339f93d89c52e098ffd92f)
(если для всех ).
![{\displaystyle \mathbb {E} [X(t)^{2}]<\infty }](https://wikimedia.org/api/rest_v1/media/math/render/svg/0ddc1d5a6fc8a9e9ec013b6f80fefb715b124137)
![{\displaystyle т\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31a5c18739ff04858eecc8fec2f53912c348e0e5)
При среднеквадратичной непрерывности и являются непрерывными функциями, а затем ковариационная функция определяет ковариационный оператор данный


| ( 1 ) |

Спектральная теорема применима к , что дает собственные пары , так что в тензорного произведения записи пишет


Более того, поскольку является непрерывным для всех , все являются непрерывными. Теорема Мерсера утверждает, что



![{\displaystyle \sup _{s,t\in [0,1]}\left|\Sigma (s,t)-\sum _{j=1}^{K}\lambda _{j}\varphi _ {j}(s)\varphi _{j}(t)\right|\to 0,\qquad K\to \infty .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9727fa95c893ad324ae2e588769d644fa65aa59e)
Наконец, при дополнительном предположении, что имеет непрерывные пути выборки, а именно, что с вероятностью единица случайная функция является непрерывным, приведенное выше разложение Карунена-Лёва справедливо для и впоследствии может быть применена космическая машина Гильберта. Непрерывность выборочных путей можно показать с помощью теоремы о непрерывности Колмогорова .
![{\displaystyle X:[0,1]\to \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/f579a095939bfe51f43ca8bdf3904f503f5116e2)
Функциональный дизайн данных
[ редактировать ]Функциональные данные рассматриваются как реализации случайного процесса. это процесс на ограниченном и замкнутом интервале со средней функцией и ковариационная функция . Реализация процесса для i-го субъекта равна , и предполагается, что выборка состоит из самостоятельные субъекты. График отбора проб может варьироваться в зависимости от субъекта, обозначаемого как по i-му предмету. Соответствующее i-е наблюдение обозначается как , где . Кроме того, измерение предполагается, что он имеет случайный шум с и , которые независимы во всех и .
![{\ displaystyle X (t), \ t \ in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/16ccfd4a54f8727a9dcf6ac67a09878e82537a0c)

![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)













1. Полностью наблюдаемые функции без шума на произвольно плотной сетке.
[ редактировать ]Измерения доступен для всех


Часто нереально, но математически удобно.
Пример из реальной жизни: спектральные данные Tecator. [7]
2. Функции с плотной выборкой и измерениями с шумом (плотный дизайн)
[ редактировать ]Измерения , где записываются на регулярной сетке,


, и применяется к типичным функциональным данным.


Пример из реальной жизни: данные исследования роста Беркли и данные о запасах
3. Разреженные функции с зашумленными измерениями (продольные данные)
[ редактировать ]Измерения , где случайные моменты времени и их количество на каждого субъекта случайна и конечна.

Пример из реальной жизни: данные по количеству CD4 у больных СПИДом. [9]
Функциональный анализ главных компонентов
[ редактировать ]Функциональный анализ главных компонентов (FPCA) является наиболее распространенным инструментом в FDA, отчасти потому, что FPCA облегчает уменьшение размерности изначально бесконечномерных функциональных данных до конечномерного случайного вектора оценок. Более конкретно, уменьшение размерности достигается за счет расширения наблюдаемых случайных траекторий. в функциональном базисе, состоящем из собственных функций ковариационного оператора на . Рассмотрим ковариационный оператор как в ( 1 ), который является компактным оператором в гильбертовом пространстве .

![{\displaystyle {\mathcal {C}}:L^{2}[0,1]\rightarrow L^{2}[0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3721486b6ac138647656517335473eb12c30da03)
По теореме Мерсера ядро , т. е. ковариационная функция , имеет спектральное разложение , где сходимость ряда абсолютна и равномерна, и являются действительными неотрицательными собственными значениями в порядке убывания с соответствующими ортонормированными собственными функциями. . По теореме Карунена-Лоэва разложение FPCA базовой случайной траектории равно , где являются функциональными главными компонентами (FPC), иногда называемыми баллами. Разложение Карунена-Лоэва облегчает уменьшение размерности в том смысле, что частичная сумма сходится равномерно, т. е. как и, таким образом, частичная сумма с достаточно большим дает хорошее приближение к бесконечной сумме. Тем самым информация в сводится из бесконечномерного к -мерный вектор с приближенным процессом:






![{\displaystyle \sup _{t\in [0,1]}\mathbb {E} [X_ {i}(t)-\mu (t)-\sum _{k=1}^{K}A_{ ik}\varphi _{k}(t)]^{2}\rightarrow 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98b33e335d769c44209b4a1abf95262ebcc1f1b2)




| ( 2 ) |

Другие популярные базы включают сплайны , ряды Фурье и вейвлеты. Важные применения FPCA включают режимы вариации и регрессию главных функциональных компонентов.
Модели функциональной линейной регрессии
[ редактировать ]Функциональные линейные модели можно рассматривать как расширение традиционных многомерных линейных моделей , которые связывают векторные реакции с векторными ковариатами. Традиционная линейная модель со скалярным откликом и векторная ковариата может быть выражено как


| ( 3 ) |

где обозначает скалярный продукт в евклидовом пространстве , и обозначаем коэффициенты регрессии, а — случайная ошибка (шум) с нулевой средней конечной дисперсией . Функциональные линейные модели можно разделить на два типа в зависимости от ответов.




Модели функциональной регрессии со скалярным откликом
[ редактировать ]Замена векторной ковариаты и вектор коэффициентов в модели ( 3 ) по центрированной функциональной ковариате и коэффициентная функция для и заменив скалярный продукт в евклидовом пространстве на продукт в гильбертовом пространстве. , приходим к функциональной линейной модели



| ( 4 ) |

Простая функциональная линейная модель ( 4 ) может быть расширена до нескольких функциональных ковариат, , включая дополнительные векторные ковариаты , где , к



| ( 5 ) |

где коэффициент регрессии для , область является , - это центрированная функциональная ковариата, определяемая формулой , и — функция коэффициента регрессии для , для . Модели ( 4 ) и ( 5 ) были тщательно изучены. [10] [11] [12]







Модели функциональной регрессии с функциональным ответом
[ редактировать ]Рассмотрим функциональный ответ на и несколько функциональных ковариат , , . В этой установке были рассмотрены две основные модели. [13] [7] Одну из этих двух моделей, обычно называемую функциональной линейной моделью (FLM), можно записать как:


| ( 6 ) |
![{\displaystyle Y(s)=\alpha _{0}(s)+\sum _{j=1}^{p}\int _{0}^{1}\alpha _{j}(s,t )X_{j}^{c}(t)\,dt+\varepsilon (s),\ {\text{for}}\ s\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c808ba95d480095cbbc0b8b7d1635bcf5046293)
где является функциональным перехватом, поскольку , представляет собой центрированную функциональную ковариату , — соответствующие функциональные наклоны с той же областью соответственно, и обычно представляет собой случайный процесс с нулевым средним значением и конечной дисперсией. [13] В этом случае в любой момент времени , значение , то есть, , зависит от всей траектории . Модель ( 6 ) тщательно изучалась. [14] [15] [16] [17] [18]



![{\displaystyle s\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aff1a54fbbee4a2677039524a5139e952fa86eb9)


Регрессия функции на скаляре
[ редактировать ]В частности, взяв как постоянная функция дает частный случай модели ( 6 ) которая представляет собой функциональную линейную модель с функциональными откликами и скалярными ковариатами.

![{\displaystyle Y(s)=\alpha _{0}(s)+\sum _{j=1}^{p}X_{j}\alpha _{j}(s)+\varepsilon (s), \ {\text{for}}\ s\in [0,1],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4b9b9588075901036c260b91f88582557c300e9)
Модели параллельной регрессии
[ редактировать ]Эта модель определяется
| ( 7 ) |
![{\displaystyle Y(s)=\beta _{0}(s)+\sum _{j=1}^{p}\beta _{j}(s)X_{j}(s)+\varepsilon ( s),\ {\text{for}}\ s\in [0,1],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/67f55ca28ff663cc83418173f95c1089b6212e7a)
где являются функциональными ковариатами , являются коэффициентными функциями, определенными на одном и том же интервале, и обычно предполагается, что это случайный процесс с нулевым средним значением и конечной дисперсией. [13] Эта модель предполагает, что значение зависит от текущей стоимости только и не история или будущая стоимость. Следовательно, это «модель параллельной регрессии», которую также называют моделью «с переменным коэффициентом». Кроме того, были предложены различные методы оценки. [19] [20] [21] [22] [23] [24]




Модели функциональной нелинейной регрессии
[ редактировать ]Прямые нелинейные расширения классических моделей функциональной линейной регрессии (FLM) по-прежнему включают линейный предиктор, но объединяют его с нелинейной функцией связи, аналогично идее обобщенной линейной модели из традиционной линейной модели. Разработка моделей полностью непараметрической регрессии для функциональных данных сталкивается с такими проблемами, как проклятие размерности . Чтобы обойти «проклятие» и проблему выбора метрик, мы стремимся рассмотреть модели нелинейной функциональной регрессии, которые подвержены некоторым структурным ограничениям, но не слишком нарушают гибкость. Желательны модели, сохраняющие полиномиальную скорость сходимости, но при этом более гибкие, чем, скажем, функциональные линейные модели. Такие модели особенно полезны, когда диагностика функциональной линейной модели указывает на несоответствие, что часто встречается в реальных жизненных ситуациях. В частности, функциональные полиномиальные модели, функциональные модели с одним и несколькими индексами и функциональные аддитивные модели. представляют собой три особых случая моделей функциональной нелинейной регрессии.
Модели функциональной полиномиальной регрессии
[ редактировать ]Модели функциональной полиномиальной регрессии можно рассматривать как естественное расширение функциональных линейных моделей (FLM) со скалярными откликами, аналогично расширению модели линейной регрессии до полиномиальной регрессии модели . Для скалярного ответа и функциональная ковариата с доменом и соответствующие центрированные процессы прогнозирования Самым простым и наиболее известным членом семейства моделей функциональной полиномиальной регрессии является квадратичная функциональная регрессия. [25] дано следующим образом: где - центрированная функциональная ковариата, скалярный коэффициент, и являются коэффициентными функциями с областями определения и , соответственно. В дополнение к функции параметра β, которую вышеупомянутая модель функциональной квадратичной регрессии разделяет с FLM, она также имеет поверхность параметра γ. По аналогии с FLM со скалярными откликами, оценку функциональных полиномиальных моделей можно получить путем расширения как центрированной ковариаты и коэффициентные функции и в ортонормированном базисе. [25] [26]







![{\displaystyle [0,1]\times [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/92f35a051af39d8299688d7c4a63e39ee5f95c8b)

Функциональные модели с одним и несколькими индексами
[ редактировать ]Ниже представлена функциональная модель с несколькими индексами, где символы имеют свои обычные значения, описанные ранее: Здесь g представляет собой (неизвестную) общую гладкую функцию, определенную в p-мерной области. Дело дает функциональную модель с одним индексом, тогда как модели с несколькими индексами соответствуют случаю . Однако для Эта модель проблематична из-за проклятия размерности . С и относительно небольших размерах выборки, оценка, данная этой моделью, часто имеет большую дисперсию. [27] [28]



Функционально-аддитивные модели (ФАМ)
[ редактировать ]Для данного ортонормированного базиса на , мы можем расширить в домене .


Таким образом, функциональную линейную модель со скалярными откликами (см. ( 3 )) можно записать следующим образом: Одна из форм FAM получается заменой линейной функции в приведенном выше выражении (т.е. ) общей гладкой функцией , аналогично расширению моделей множественной линейной регрессии до аддитивных моделей и выражается как: где удовлетворяет для . [13] [7] Это ограничение на общие гладкие функции обеспечивает идентифицируемость в том смысле, что оценки этих аддитивных компонентных функций не мешают оценке члена . Другой формой FAM является непрерывно-аддитивная модель. [29] выражается как, для двумерной гладкой аддитивной поверхности который необходим для удовлетворения для всех , чтобы обеспечить идентификацию.









![{\displaystyle g:[0,1]\times \mathbb {R} \longrightarrow \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/4a6d29882cd138d3e9fe07e3c53959bdd1179663)
![{\displaystyle \mathbb {E} [g(t,X(t))]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/487837c1630d29d8c48646ecae9f1db15cad3b27)
Обобщенная функциональная линейная модель
[ редактировать ]Очевидным и прямым расширением FLM со скалярными откликами (см. ( 3 )) является добавление функции связи, ведущей к обобщенной функциональной линейной модели (GFLM). [30] по аналогии с обобщенной линейной моделью (ОЛМ). Тремя компонентами GFLM являются:
- Линейный предиктор ; [систематический компонент]
- Функция дисперсии , где – условное среднее ; [случайный компонент]
- Функция связи соединяющее условное среднее и линейный предиктор через . [систематический компонент]






Кластеризация и классификация функциональных данных
[ редактировать ]Для векторных многомерных данных двумя основными подходами являются методы разделения k-средних и иерархическая кластеризация . Эти классические концепции кластеризации векторных многомерных данных были распространены на функциональные данные. Для кластеризации функциональных данных методы кластеризации k-средних более популярны, чем методы иерархической кластеризации. Для кластеризации k-средних по функциональным данным средние функции обычно рассматриваются как центры кластеров. Ковариационные структуры также были приняты во внимание. [31] Помимо кластеризации типа k-средних, функциональная кластеризация [32] основанный на смешанных моделях , также широко используется при кластеризации векторных многомерных данных и был расширен до функциональной кластеризации данных. [33] [34] [35] [36] [37] Кроме того, байесовская иерархическая кластеризация также играет важную роль в разработке функциональной кластеризации на основе моделей. [38] [39] [40] [41]
Функциональная классификация присваивает членство в группе новому объекту данных либо на основе функциональной регрессии, либо функционального дискриминантного анализа. Методы классификации функциональных данных, основанные на моделях функциональной регрессии, используют уровни классов в качестве ответов, а наблюдаемые функциональные данные и другие ковариаты в качестве предикторов. Для моделей функциональной классификации, основанных на регрессии, обычно используются функциональные обобщенные линейные модели или, более конкретно, функциональная бинарная регрессия, такая как функциональная логистическая регрессия для бинарных ответов. обобщенная модель функциональной линейной регрессии, основанная на подходе FPCA . В более общем смысле используется [42] Функциональный линейный дискриминантный анализ (FLDA) также рассматривается как метод классификации функциональных данных. [43] [44] [45] [46] [47] Также была предложена функциональная классификация данных, включающая коэффициенты плотности. [48] Исследование асимптотического поведения предложенных классификаторов в пределе большой выборки показывает, что при определенных условиях уровень ошибочной классификации стремится к нулю - явление, которое получило название «идеальная классификация». [49]
Искажение времени
[ редактировать ]Мотивации
[ редактировать ]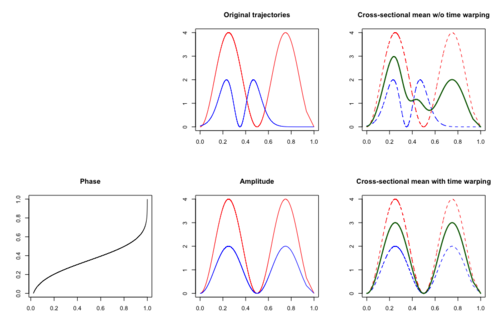
Помимо изменения амплитуды, [50] Можно также предположить, что изменение во времени присутствует в функциональных данных. Изменение времени происходит, когда время определенных интересующих событий, специфичное для субъекта, различается у разных субъектов. Одним из классических примеров являются данные исследования экономического роста Беркли . [51] где изменение амплитуды представляет собой скорость роста, а изменение во времени объясняет разницу в биологическом возрасте детей, в котором произошел пубертатный и препубертатный всплеск роста. При наличии изменений во времени функция поперечного среднего может оказаться неэффективной оценкой, поскольку пики и минимумы расположены случайным образом, и, таким образом, значимые сигналы могут быть искажены или скрыты.
Искажение времени, также известное как регистрация кривой, [52] выравнивание кривой или синхронизация времени направлено на выявление и разделение изменений амплитуды и изменений во времени. Если присутствуют изменения как во времени, так и в амплитуде, то наблюдаемые функциональные данные можно смоделировать как , где является функцией скрытой амплитуды и — это скрытая функция деформации времени, которая соответствует кумулятивной функции распределения. Функции деформации времени предполагаются обратимыми и удовлетворяющими .

![{\displaystyle Y_{i}(t)=X_{i}[h_{i}^{-1}(t)],t\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4936c8e9cb54b7bf9a82083f5118c61b473f8cc4)




Простейшим случаем семейства функций деформации для задания изменения фазы является линейное преобразование, то есть , который искажает время базовой функции шаблона за счет смещения и масштаба, специфичного для субъекта. Более общий класс функций деформации включает диффеоморфизмы области в себя, то есть, грубо говоря, класс обратимых функций, которые отображают компактную область в себя так, что и функция, и ее обратная являются гладкими. Множество линейных преобразований содержится в множестве диффеоморфизмов . [53] Одной из проблем при искажении времени является идентифицируемость изменения амплитуды и фазы. Чтобы преодолеть эту неидентифицируемость, необходимы конкретные предположения.

Методы
[ редактировать ]Более ранние подходы включают динамическое искажение времени (DTW), используемое для таких приложений, как распознавание речи . [54] Еще одним традиционным методом искажения времени является регистрация ориентиров. [55] [56] который выравнивает специальные функции, такие как пиковые местоположения, со средним местоположением. Другие соответствующие методы деформации включают парную деформацию, [57] регистрация с помощью расстояние [53] и упругая деформация. [58]

Динамическое искажение времени
[ редактировать ]Функция шаблона определяется посредством итерационного процесса, начиная со среднего значения поперечного сечения, выполняя регистрацию и пересчитывая среднее значение поперечного сечения для искривленных кривых, ожидая сходимости после нескольких итераций. DTW минимизирует функцию стоимости посредством динамического программирования. Проблемы негладких дифференцируемых искажений или жадных вычислений в DTW можно решить, добавив член регуляризации в функцию стоимости.
Регистрация ориентира
[ редактировать ]Регистрация ориентиров (или выравнивание признаков) предполагает наличие хорошо выраженных признаков во всех выборочных кривых и использует расположение таких признаков в качестве золотого стандарта. Специальные функции, такие как местоположения пиков или впадин в функциях или производных, выравниваются по их средним местоположениям в шаблонной функции. [53] Затем вводится функция деформации посредством плавного преобразования среднего местоположения в местоположения, специфичные для объекта. Проблема регистрации ориентиров заключается в том, что объекты могут отсутствовать или их трудно идентифицировать из-за шума в данных.
Расширения
[ редактировать ]До сих пор мы рассматривали скалярнозначный случайный процесс, , определенный в одномерной временной области.

Многомерная область
[ редактировать ]Домен может быть в , например, данные могут представлять собой выборку случайных поверхностей. [59] [60]

Многомерный случайный процесс
[ редактировать ]Набор диапазонов случайного процесса может быть расширен от к [61] [62] [63] и далее к нелинейным многообразиям, [64] гильбертовые пространства [65] и, в конечном итоге, к метрическим пространствам. [59]

Python Пакеты
[ редактировать ]Существуют пакеты Python для работы с функциональными данными и их представления, выполнения исследовательского анализа или предварительной обработки, а также других задач, таких как вывод, классификация, регрессия или кластеризация функциональных данных.
R- пакеты
[ редактировать ]Некоторые пакеты могут обрабатывать функциональные данные как в плотном, так и в продольном исполнении.
См. также
[ редактировать ]- Функциональный анализ главных компонентов
- Теорема Карунена – Лёва
- Режимы вариаций
- Функциональная регрессия
- Обобщенная функциональная линейная модель
- Случайные процессы
- пространство ЛП
- Функция дисперсии
Дальнейшее чтение
[ редактировать ]- Рамзи, Дж.О. и Сильверман, Б.В. (2005) Функциональный анализ данных , 2-е изд., Нью-Йорк: Springer, ISBN 0-387-40080-X
- Хорват Л. и Кокошка П. (2012) Вывод функциональных данных с помощью приложений , Нью-Йорк: Springer, ISBN 978-1-4614-3654-6
- Хсинг, Т. и Юбанк, Р. (2015) Теоретические основы функционального анализа данных, с введением в линейные операторы , ряды Вили по вероятности и статистике, John Wiley & Sons, Ltd, ISBN 978-0-470-01691-6
- Моррис, Дж. (2015) Функциональная регрессия, Ежегодный обзор статистики и ее применения, Том. 2, 321–359, https://doi.org/10.1146/annurev-statistics-010814-020413.
- Ван и др. (2016) Функциональный анализ данных, Ежегодный обзор статистики и ее применения, Том. 3, 257-295, https://doi.org/10.1146/annurev-statistics-041715-033624
Категория:Регрессионный анализ
Ссылки
[ редактировать ]- ^ Гренандер, У. (1950). «Стохастические процессы и статистический вывод» . Архив по математике 1 (3): 195–277. Бибкод : 1950АрМ.....1..195Г . дои : 10.1007/BF02590638 . S2CID 120451372 .
- ^ Райс, Дж.А.; Сильверман, Б.В. (1991). «Непараметрическая оценка среднего и ковариационной структуры, когда данные представляют собой кривые». Журнал Королевского статистического общества . 53 (1): 233–243. дои : 10.1111/j.2517-6161.1991.tb01821.x .
- ^ Мюллер, ХГ. (2016). «Питер Холл, функциональный анализ данных и случайные объекты» . Анналы статистики . 44 (5): 1867–1887. дои : 10.1214/16-AOS1492 .
- ^ Кархунен, К (1946). К спектральной теории случайных процессов . Annales Academiae scientiarum Fennicae.
- ^ Клефф, Дж. (1973). «Главные компоненты случайных величин со значениями в сепарабельном гильбертовом пространстве». Исследование математических операций и статистика . 4 (5): 391–406. дои : 10.1080/02331887308801137 .
- ^ Даксуа, Дж; Пусс, А; Ромен, Ю. (1982). «Асимптотическая теория анализа главных компонент векторной случайной функции: некоторые приложения к статистическому выводу» . Журнал многомерного анализа . 12 (1): 136–154. дои : 10.1016/0047-259X(82)90088-4 .
- ^ Jump up to: а б с д и Рамзи, Дж; Сильверман, Б.В. (2005). Функциональный анализ данных, 2-е изд . Спрингер.
- ^ Хсинг, Т; Юбанк, Р. (2015). Теоретические основы функционального анализа данных с введением в линейные операторы . Ряд Уайли по вероятности и статистике.
- ^ Ши, М; Вайс, Р.Э.; Тейлор, JMG. (1996). «Анализ количества CD4 у детей при синдроме приобретенного иммунодефицита с использованием гибких случайных кривых». Журнал Королевского статистического общества. Серия C (Прикладная статистика) . 45 (2): 151–163.
- ^ Хильгерт, Н; Мас, А; Верзелен, Н. (2013). «Минимаксные адаптивные тесты функциональной линейной модели». Анналы статистики . 41 (2): 838–869. arXiv : 1206.1194 . дои : 10.1214/13-AOS1093 . S2CID 13119710 .
- ^ Конг, Д; Сюэ, К; Яо, Ф; Чжан, Х.Х. (2016). «Частично функциональная линейная регрессия в больших измерениях». Биометрика . 103 (1): 147–159. дои : 10.1093/biomet/asv062 .
- ^ Хорват, Л; Кокошка, П. (2012). Вывод функциональных данных с помощью приложений . Серия Спрингера по статистике. Спрингер-Верлаг.
- ^ Jump up to: а б с д Ван, Дж.Л.; Чиу, Дж. М.; Мюллер, ХГ. (2016). «Функциональный анализ данных» . Ежегодный обзор статистики и ее применения . 3 (1): 257–295. Бибкод : 2016AnRSA...3..257W . doi : 10.1146/annurev-statistics-041715-033624 . S2CID 13709250 .
- ^ Рамзи, Джо; Далзелл, CJ. (1991). «Некоторые инструменты функционального анализа данных». Журнал Королевского статистического общества, серия B (методологический) . 53 (3): 539–561. дои : 10.1111/j.2517-6161.1991.tb01844.x . S2CID 118960346 .
- ^ Малфейт, Н.; Рамзи, Дж.О. (2003). «Историческая функциональная линейная модель». Канадский статистический журнал . 31 (2): 115–128. дои : 10.2307/3316063 . JSTOR 3316063 . S2CID 55092204 .
- ^ Он, Г; Мюллер, Х.Г.; Ван, Дж.Л. (2003). «Функциональный канонический анализ квадратично интегрируемых случайных процессов». Журнал многомерного анализа . 85 (1): 54–77. дои : 10.1016/S0047-259X(02)00056-8 .
- ^ Jump up to: а б Яо, Ф; Мюллер, Х.Г.; Ван, Дж.Л. (2005). «Функциональный анализ данных для редких продольных данных». Журнал Американской статистической ассоциации . 100 (470): 577–590. дои : 10.1198/016214504000001745 . S2CID 1243975 .
- ^ Он, Г; Мюллер, Х.Г.; Ван, Дж.Л.; Ян, У.Дж. (2010). «Функциональная линейная регрессия посредством канонического анализа». Журнал многомерного анализа . 16 (3): 705–729. arXiv : 1102.5212 . дои : 10.3150/09-BEJ228 . S2CID 17843044 .
- ^ Фан, Дж; Чжан, В. (1999). «Статистическая оценка в моделях с переменными коэффициентами» . Анналы статистики . 27 (5): 1491–1518. дои : 10.1214/aos/1017939139 . S2CID 16758288 .
- ^ Ву, Колорадо; Ю, КФ. (2002). «Непараметрические модели с переменными коэффициентами для анализа продольных данных». Международный статистический обзор . 70 (3): 373–393. дои : 10.1111/j.1751-5823.2002.tb00176.x . S2CID 122007787 .
- ^ Хуанг, JZ; Ву, Колорадо; Чжоу, Л. (2002). «Модели с переменными коэффициентами и аппроксимации базисной функции для анализа повторных измерений». Биометрика . 89 (1): 111–128. дои : 10.1093/biomet/89.1.111 .
- ^ Хуанг, JZ; Ву, Колорадо; Чжоу, Л. (2004). «Оценка полиномиального сплайна и вывод для моделей с различными коэффициентами с продольными данными». Статистика Синица . 14 (3): 763–788.
- ^ Шентюрк, Д; Мюллер, ХГ. (2010). «Модели функциональных переменных коэффициентов для продольных данных». Журнал Американской статистической ассоциации . 105 (491): 1256–1264. дои : 10.1198/jasa.2010.tm09228 . S2CID 14296231 .
- ^ Эггермонт, ППБ; Юбанк, Род-Айленд; ЛаРичча, В.Н. (2010). «Степень сходимости для сглаживающих сплайновых оценок в моделях с различными коэффициентами». Журнал статистического планирования и выводов . 140 (2): 369–381. дои : 10.1016/j.jspi.2009.06.017 .
- ^ Jump up to: а б Яо, Ф; Мюллер, ХГ. (2010). «Функциональная квадратичная регрессия». Биометрика . 97 (1): 49–64.
- ^ Хорват, Л; Ридер, Р. (2013). «Тест значимости функциональной квадратичной регрессии» . Бернулли . 19 (5А): 2120–2151. arXiv : 1105.0014 . дои : 10.3150/12-BEJ446 . S2CID 88512527 .
- ^ Чен, Д; Холл, П; Мюллер ХГ. (2011). «Одно- и множественные индексные модели функциональной регрессии с непараметрической связью». Анналы статистики . 39 (3): 1720–1747.
- ^ Цзян, ЧР; Ван Дж.Л. (2011). «Функциональные модели с одним индексом для продольных данных». Анналы статистики . 39 (1): 362–388.
- ^ Мюллер Х.Г.; У Ю; Яо, Ф. (2013). «Непрерывно аддитивные модели нелинейной функциональной регрессии». Биометрика . 100 (3): 607–622. doi : 10.1093/biomet/ast004 .
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Мюллер Х.Г.; Стадмюллер, У. (2005). «Обобщенные функциональные линейные модели». Анналы статистики . 33 (2): 774–805. arXiv : math/0505638 . дои : 10.1214/009053604000001156 .
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Чиу, Дж. М.; Ли, ПЛ. (2007). «Функциональная кластеризация и выявление подструктур продольных данных» . Журнал Королевского статистического общества, серия B (статистическая методология) . 69 (4): 679–699. дои : 10.1111/j.1467-9868.2007.00605.x . S2CID 120883171 .
- ^ Банфилд, доктор медицинских наук; Рафтери, А.Е. (1993). «Гауссова и негауссова кластеризация на основе модели». Биометрия . 49 (3): 803–821. дои : 10.2307/2532201 . JSTOR 2532201 .
- ^ Джеймс, генеральный менеджер; Шугар, Калифорния. (2003). «Кластеризация функциональных данных с редкой выборкой». Журнал Американской статистической ассоциации . 98 (462): 397–408. дои : 10.1198/016214503000189 . S2CID 9487422 .
- ^ Жак, Дж; Преда, К. (2013). «Funclust: метод кластеризации кривых с использованием аппроксимации плотности функциональных случайных величин» (PDF) . Нейрокомпьютинг . 112 : 164–171. дои : 10.1016/j.neucom.2012.11.042 . S2CID 33591208 .
- ^ Жак, Дж; Преда, К. (2014). «Кластеризация на основе моделей для многомерных функциональных данных». Вычислительная статистика и анализ данных . 71 (С): 92–106. дои : 10.1016/j.csda.2012.12.004 .
- ^ Коффи, Н.; Хинде, Дж; Холиан, Э. (2014). «Кластеризация продольных профилей с использованием P-сплайнов и моделей смешанных эффектов, применяемых к данным об экспрессии генов в зависимости от времени». Вычислительная статистика и анализ данных . 71 (С): 14–29. дои : 10.1016/j.csda.2013.04.001 .
- ^ Хайнцль, Ф; Тутц, Г. (2014). «Кластеризация в линейно-смешанных моделях со штрафом за групповое слитое лассо». Биометрический журнал . 56 (1): 44–68. дои : 10.1002/bimj.201200111 . ПМИД 24249100 . S2CID 10969266 .
- ^ Анджелини, К; Кандитис, Д.Д.; Пенский, М. (2012). «Кластеризация данных микрочипа с временной динамикой с использованием функциональной байесовской модели бесконечной смеси». Журнал прикладной статистики . 39 (1): 129–149. Бибкод : 2012JApSt..39..129A . дои : 10.1080/02664763.2011.578620 . S2CID 8902492 .
- ^ Родригес, А; Дансон, Д.Б.; Гельфанд, А.Е. (2009). «Байесовский непараметрический функциональный анализ данных посредством оценки плотности» . Биометрика . 96 (1): 149–162. doi : 10.1093/biomet/asn054 . ПМК 2650433 . ПМИД 19262739 .
- ^ Петроне, С; Гуиндани, М; Гельфанд, А.Е. (2009). «Гибридные модели смеси Дирихле для функциональных данных». Журнал Королевского статистического общества . 71 (4): 755–782. дои : 10.1111/j.1467-9868.2009.00708.x . S2CID 18638091 .
- ^ Хайнцль, Ф; Тутц, Г. (2013). «Кластеризация в линейных смешанных моделях с приближенными смесями процесса Дирихле с использованием алгоритма EM» (PDF) . Статистическое моделирование . 13 (1): 41–67. дои : 10.1177/1471082X12471372 . S2CID 11448616 .
- ^ Ленг, Х; Мюллер, ХГ. (2006). «Классификация с использованием функционального анализа данных для данных временной экспрессии генов» (PDF) . Биоинформатика . 22 (1): 68–76. doi : 10.1093/биоинформатика/bti742 . ПМИД 16257986 .
- ^ Джеймс, генеральный менеджер; Хасти, Ти Джей. (2001). «Функциональный линейный дискриминантный анализ для кривых с нерегулярной выборкой» . Журнал Королевского статистического общества . 63 (3): 533–550. дои : 10.1111/1467-9868.00297 . S2CID 16050693 .
- ^ Холл, П; Поскитт, Д.С.; Преснелл, Б. (2001). «Функциональные данные — аналитический подход к различению сигналов». Технометрика . 43 (1): 1–9. дои : 10.1198/00401700152404273 . S2CID 21662019 .
- ^ Феррати, Ф; Вье, П. (2003). «Дискриминация кривых: непараметрический функциональный подход». Вычислительная статистика и анализ данных . 44 (1–2): 161–173. дои : 10.1016/S0167-9473(03)00032-X .
- ^ Чанг, К; Чен, Ю; Огден, RT. (2014). «Функциональная классификация данных: вейвлет-подход» . Вычислительная статистика . 29 (6): 1497–1513. дои : 10.1007/s00180-014-0503-4 . ПМЦ 11192549 . S2CID 120454400 .
- ^ Чжу, Х; Браун, ПиДжей; Моррис, Дж.С. (2012). «Надежная классификация функциональных и количественных данных изображений с использованием функциональных смешанных моделей» . Биометрия . 68 (4): 1260–1268. дои : 10.1111/j.1541-0420.2012.01765.x . ПМЦ 3443537 . ПМИД 22670567 .
- ^ Дай, Х; Мюллер, Х.Г.; Яо, Ф. (2017). «Оптимальные классификаторы Байеса для функциональных данных и коэффициентов плотности». Биометрика . 104 (3): 545–560. arXiv : 1605.03707 .
- ^ Делагль, А; Холл, П. (2012). «Достижение почти идеальной классификации функциональных данных» . Журнал Королевского статистического общества. Серия B (Статистическая методология) . 74 (2): 267–286. дои : 10.1111/j.1467-9868.2011.01003.x . ISSN 1369-7412 . S2CID 124261587 .
- ^ Ван, Дж.Л.; Чиу, Дж. М.; Мюллер, ХГ. (2016). «Функциональный анализ данных» . Ежегодный обзор статистики и ее применения . 3 (1): 257–295. Бибкод : 2016AnRSA...3..257W . doi : 10.1146/annurev-statistics-041715-033624 . S2CID 13709250 .
- ^ Гассер, Т; Мюллер, Х.Г.; Колер, В; Молинари, Л; Прадер, А. (1984). «Непараметрический регрессионный анализ кривых роста». Анналы статистики . 12 (1): 210–229.
- ^ Рамзи, Джо; Ли, X. (1998). «Регистрация кривых» . Журнал Королевского статистического общества, серия B. 60 (2): 351–363. дои : 10.1111/1467-9868.00129 . S2CID 17175587 .
- ^ Jump up to: а б с Маррон, Дж. С.; Рамзи, Джо; Сангалли, LM; Шривастава, А (2015). «Функциональный анализ данных изменения амплитуды и фазы». Статистическая наука . 30 (4): 468–484. arXiv : 1512.03216 . дои : 10.1214/15-STS524 . S2CID 55849758 .
- ^ Сакоэ, Х; Чиба, С. (1978). «Оптимизация алгоритма динамического программирования для распознавания устной речи». Транзакции IEEE по акустике, речи и обработке сигналов . 26 : 43–49. дои : 10.1109/ТАССП.1978.1163055 . S2CID 17900407 .
- ^ Кнайп, А; Гассер, Т. (1992). «Статистические инструменты для анализа данных, представляющих выборку кривых» . Анналы статистики . 20 (3): 1266–1305. дои : 10.1214/aos/1176348769 .
- ^ Гассер, Т; Кнайп, А (1995). «Поиск структуры в образце кривой». Журнал Американской статистической ассоциации . 90 (432): 1179–1188.
- ^ Тан, Р; Мюллер, ХГ. (2008). «Попарная синхронизация кривых функциональных данных». Биометрика . 95 (4): 875–889. дои : 10.1093/biomet/asn047 .
- ^ Jump up to: а б Анирудх, Р; Турага, П; Су, Дж; Шривастава, А (2015). «Эластичное функциональное кодирование действий человека: от векторных полей к скрытым переменным». Материалы конференции IEEE по компьютерному зрению и распознаванию образов : 3147–3155.
- ^ Jump up to: а б Дубей, П; Мюллер, Х.Г. (2021). «Моделирование изменяющихся во времени случайных объектов и динамических сетей». Журнал Американской статистической ассоциации . 117 (540): 2252–2267. arXiv : 2104.04628 . дои : 10.1080/01621459.2021.1917416 . S2CID 233210300 .
- ^ Пиголи, Д; Хаджипантелис, ПЗ; Коулман, Дж.С.; Астон, JAD (2017). «Статистический анализ акустических фонетических данных: изучение различий между разговорными романскими языками». Журнал Королевского статистического общества. Серия C (Прикладная статистика) . 67 (5): 1130–1145.
- ^ Хапп, К; Гревен, С (2018). «Многомерный анализ функциональных главных компонентов для данных, наблюдаемых в различных (мерных) областях». Журнал Американской статистической ассоциации . 113 (522): 649–659. arXiv : 1509.02029 . дои : 10.1080/01621459.2016.1273115 . S2CID 88521295 .
- ^ Чиу, Дж. М.; Ян, Ю.Ф.; Чен, Ю.Т. (2014). «Многомерный функциональный анализ главных компонентов: подход нормализации». Статистика Синица . 24 : 1571–1596.
- ^ Кэрролл, К; Мюллер, Х.Г.; Кнайп, А (2021). «Межкомпонентная регистрация многомерных функциональных данных с применением к кривым роста». Биометрия . 77 (3): 839–851. arXiv : 1811.01429 . дои : 10.1111/biom.13340 . S2CID 220687157 .
- ^ Дай, Х; Мюллер, Х.Г. (2018). «Анализ главных компонент функциональных данных на римановых многообразиях и сферах». Анналы статистики . 46 (6Б): 3334–3361. arXiv : 1705.06226 . дои : 10.1214/17-AOS1660 . S2CID 13671221 .
- ^ Чен, К; Деликадо, П; Мюллер, Х.Г. (2017). «Моделирование функционально-стохастических процессов с применением к динамике рождаемости». Журнал Королевского статистического общества. Серия B (Статистическая методология) . 79 (1): 177–196. дои : 10.1111/rssb.12160 . hdl : 2117/126653 . S2CID 13719492 .