Совместная фильтрация

| Рекомендательные системы |
|---|
| Концепции |
| Методы и проблемы |
| Реализации |
| Исследовать |
Совместная фильтрация ( CF ) – это метод, используемый рекомендательными системами . [ 1 ] Совместная фильтрация имеет два смысла: узкий и более общий. [ 2 ]
В более новом, более узком смысле совместная фильтрация — это метод автоматического прогнозирования (фильтрации) интересов пользователя путем сбора информации о предпочтениях или вкусах от многих пользователей (сотрудничающих). Основное предположение подхода совместной фильтрации заключается в том, что если человек А имеет то же мнение, что и человек Б, по какому-либо вопросу, то у А с большей вероятностью будет мнение Б по другому вопросу, чем мнение случайно выбранного человека. Например, система рекомендаций по совместной фильтрации предпочтений в телевизионных программах может делать прогнозы о том, какое телешоу должно понравиться пользователю, учитывая неполный список вкусов этого пользователя (нравится или не нравится). [ 3 ] Эти прогнозы специфичны для пользователя, но используют информацию, полученную от многих пользователей. Это отличается от более простого подхода, при котором выставляется средний (неконкретный) балл по каждому интересующему вопросу, например, на основе количества голосов .
В более общем смысле совместная фильтрация — это процесс фильтрации информации или шаблонов с использованием методов, включающих сотрудничество между несколькими агентами, точками зрения, источниками данных и т. д. [ 2 ] Приложения совместной фильтрации обычно включают очень большие наборы данных. Методы совместной фильтрации применялись ко многим различным видам данных, включая: данные зондирования и мониторинга, например, при разведке полезных ископаемых, зондировании окружающей среды на больших территориях или при использовании нескольких датчиков; финансовые данные, такие как учреждения финансовых услуг, которые объединяют множество финансовых источников; или в электронной коммерции и веб-приложениях, где основное внимание уделяется пользовательским данным и т. д. Оставшаяся часть этого обсуждения посвящена совместной фильтрации пользовательских данных, хотя некоторые методы и подходы могут применяться и к другим основным приложениям.
Обзор
[ редактировать ]Рост Интернета - онлайн значительно усложнил эффективное извлечение полезной информации из всей доступной информации . [ по мнению кого? ] Огромный объем данных требует механизмов эффективной фильтрации информации . [ по мнению кого? ] Совместная фильтрация — один из методов, используемых для решения этой проблемы.
Мотивация совместной фильтрации исходит из идеи, что люди часто получают лучшие рекомендации от кого-то, чьи вкусы схожи с ними. [ нужна ссылка ] Совместная фильтрация включает в себя методы подбора людей со схожими интересами и выработки рекомендаций на этой основе.
Алгоритмы совместной фильтрации часто требуют (1) активного участия пользователей, (2) простого способа представления интересов пользователей и (3) алгоритмов, которые способны находить людей со схожими интересами.
Обычно рабочий процесс системы совместной фильтрации выглядит следующим образом:
- Пользователь выражает свои предпочтения, оценивая элементы системы (например, книги, фильмы или музыкальные записи). Эти рейтинги можно рассматривать как приблизительное представление об интересе пользователя к соответствующему домену.
- Система сопоставляет рейтинги этого пользователя с рейтингами других пользователей и находит людей с наиболее «похожими» вкусами.
- Подобным пользователям система рекомендует предметы, которые аналогичные пользователи оценили высоко, но еще не получили оценки от этого пользователя (предположительно отсутствие оценки часто расценивается как незнакомство предмета)
Ключевая проблема совместной фильтрации заключается в том, как объединить и взвесить предпочтения соседей пользователей. Иногда пользователи могут сразу оценить рекомендованные товары. В результате система со временем получает все более точное представление о предпочтениях пользователя.
Методология
[ редактировать ]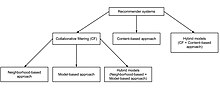
Системы совместной фильтрации имеют множество форм, но многие распространенные системы можно свести к двум этапам:
- Ищите пользователей, которые имеют те же шаблоны оценок, что и активный пользователь (пользователь, для которого предназначен прогноз).
- Используйте оценки пользователей-единомышленников, найденных на шаге 1, чтобы рассчитать прогноз для активного пользователя.
Это подпадает под категорию совместной фильтрации на основе пользователей. Конкретным применением этого является пользовательский алгоритм ближайшего соседа .
Альтернативно, совместная фильтрация на основе элементов (пользователи, которые купили x, также купили y), осуществляется по принципу, ориентированному на элементы:
- Постройте матрицу элементов, определяющую отношения между парами элементов.
- Сделайте вывод о вкусах текущего пользователя, изучив матрицу и сопоставив данные этого пользователя.
См., например, Slope One семейство совместной фильтрации на основе элементов .
Другая форма совместной фильтрации может быть основана на неявных наблюдениях за нормальным поведением пользователей (в отличие от искусственного поведения, налагаемого рейтинговой задачей). Эти системы наблюдают за тем, что сделал пользователь, а также за тем, что сделали все пользователи (какую музыку они слушали, какие товары покупали) и используют эти данные для прогнозирования поведения пользователя в будущем или для прогнозирования того, что пользователю может понравиться. вести себя, если есть возможность. Эти прогнозы затем необходимо отфильтровать с помощью бизнес-логики, чтобы определить, как они могут повлиять на действия бизнес-системы. Например, бесполезно предлагать кому-либо продать определенный музыкальный альбом, если он уже продемонстрировал, что владеет этой музыкой.
Использование системы оценок или рейтингов, которая усредняется по всем пользователям, игнорирует конкретные требования пользователя и особенно неэффективна в задачах, где существует большая разница в интересах (например, в рекомендациях музыки). Однако существуют и другие методы борьбы с информационным взрывом, такие как веб- поиск и кластеризация данных .
Типы
[ редактировать ]На основе памяти
[ редактировать ]Подход на основе памяти использует данные рейтинга пользователей для вычисления сходства между пользователями или элементами. Типичными примерами этого подхода являются CF на основе района и рекомендации Top-N на основе элементов/пользователей. Например, в подходах, основанных на пользователях, ценность оценок, которые пользователь u дает элементу i, рассчитывается как совокупность оценок некоторых аналогичных пользователей этого элемента:

где U обозначает набор из N лучших пользователей, наиболее похожих на пользователя u, поставившего оценку элементу i . Некоторые примеры функции агрегирования включают в себя:


где k — нормирующий коэффициент, определяемый как , и


где — это средний рейтинг пользователя u для всех элементов, которым вы оценили .

Алгоритм на основе соседства вычисляет сходство между двумя пользователями или элементами и выдает прогноз для пользователя, взяв средневзвешенное значение всех оценок. Вычисление сходства между элементами или пользователями является важной частью этого подхода. многочисленные меры, такие как корреляция Пирсона и сходство на основе векторного косинуса Для этого используются .
Сходство корреляции Пирсона двух пользователей x , y определяется как

где I xy — набор элементов, оцененных пользователем x и пользователем y .
Косинусный подход определяет косинусное сходство между двумя пользователями x и y как: [ 4 ]

Алгоритм рекомендаций Top-N на основе пользователей использует векторную модель на основе сходства для идентификации k пользователей, наиболее похожих на активного пользователя. После того, как найдено k наиболее похожих пользователей, соответствующие им матрицы элементов пользователей агрегируются для определения набора элементов, которые следует рекомендовать. Популярным методом поиска похожих пользователей является хеширование с учетом местоположения , которое реализует механизм поиска ближайшего соседа за линейное время.
Преимущества этого подхода включают: объяснимость результатов, что является важным аспектом рекомендательных систем; простота создания и использования; простота получения новых данных; независимость от содержания рекомендуемых товаров; хорошее масштабирование с элементами с одинаковым рейтингом.
У этого подхода также есть несколько недостатков. Его производительность снижается, когда данные становятся разреженными , что часто происходит с элементами, связанными с Интернетом. Это препятствует масштабируемости этого подхода и создает проблемы с большими наборами данных. Хотя он может эффективно обрабатывать новых пользователей, поскольку опирается на структуру данных , добавление новых элементов становится более сложным, поскольку это представление обычно опирается на определенное векторное пространство . Добавление новых элементов требует включения нового элемента и повторной вставки всех элементов в структуру.
На основе модели
[ редактировать ]В этом подходе модели разрабатываются с использованием различных алгоритмов интеллектуального анализа данных и машинного обучения для прогнозирования рейтинга пользователей элементов без рейтинга. Существует множество алгоритмов CF, основанных на моделях. Байесовские сети , модели кластеризации , скрытые семантические модели, такие как разложение по сингулярным значениям , вероятностный скрытый семантический анализ , множественный мультипликативный коэффициент, скрытое распределение Дирихле и марковском процессе принятия решений . модели, основанные на [ 5 ]
Благодаря этому подходу методы уменьшения размерности в основном используются в качестве дополнительного метода для повышения надежности и точности подхода, основанного на памяти. В этом смысле такие методы, как разложение по сингулярным значениям и анализ главных компонентов , известные как модели скрытых факторов, сжимают матрицу пользовательских элементов в низкоразмерное представление с точки зрения скрытых факторов. Одним из преимуществ использования этого подхода является то, что вместо матрицы большой размерности, содержащей большое количество пропущенных значений, мы будем иметь дело с матрицей гораздо меньшего размера в пространстве меньшей размерности. Сокращенное представление можно использовать для алгоритмов соседства, основанных на пользователях или элементах, которые представлены в предыдущем разделе. У этой парадигмы есть несколько преимуществ. Он справляется с разреженностью исходной матрицы лучше, чем матрицы, основанные на памяти. Кроме того, сравнение сходства полученной матрицы гораздо более масштабируемо, особенно при работе с большими разреженными наборами данных. [ 6 ]
Гибридный
[ редактировать ]Ряд приложений сочетают в себе алгоритмы CF на основе памяти и модели. Они преодолевают ограничения собственных подходов CF и улучшают качество прогнозирования. Важно отметить, что они преодолевают проблемы CF, такие как разреженность и потеря информации. Однако они имеют повышенную сложность и дороги в реализации. [ 7 ] Обычно большинство коммерческих рекомендательных систем являются гибридными, например, рекомендательная система новостей Google. [ 8 ]
Глубокое обучение
[ редактировать ]В последние годы был предложен ряд методов нейронного и глубокого обучения. Некоторые обобщают традиционные алгоритмы матричной факторизации с помощью нелинейной нейронной архитектуры. [ 9 ] или использовать новые типы моделей, такие как вариационные автоэнкодеры . [ 10 ] Хотя глубокое обучение применялось во многих различных сценариях: с учетом контекста, с учетом последовательности, социальными тегами и т. д., его реальная эффективность при использовании в простом сценарии совместных рекомендаций была поставлена под сомнение. Систематический анализ публикаций, применяющих методы глубокого обучения или нейронных методов для решения проблемы рекомендаций top-k, опубликованных на ведущих конференциях (SIGIR, KDD, WWW, RecSys), показал, что в среднем менее 40% статей воспроизводимы с минимальными затратами. как 14% на некоторых конференциях. Всего в исследовании выявлено 18 статей, только 7 из них можно воспроизвести, а 6 из них могут превзойти гораздо более старые и простые, правильно настроенные базовые показатели. В статье также подчеркивается ряд потенциальных проблем в сегодняшних научных исследованиях и содержится призыв к совершенствованию научной практики в этой области. [ 11 ] Подобные проблемы были замечены другими [ 12 ] а также в рекомендательных системах с учетом последовательности. [ 13 ]
Контекстно-зависимая совместная фильтрация
[ редактировать ]Многие рекомендательные системы просто игнорируют другую контекстную информацию, существующую наряду с рейтингом пользователя, при предоставлении рекомендаций по товару. [ 14 ] Однако из-за повсеместной доступности контекстной информации, такой как время, местоположение, социальная информация и тип устройства, которое использует пользователь, становится более важным, чем когда-либо, для успешной рекомендательной системы предоставлять контекстно-зависимые рекомендации. По словам Чару Аггравала, «контекстно-зависимые рекомендательные системы адаптируют свои рекомендации к дополнительной информации, которая определяет конкретную ситуацию, в которой даются рекомендации. Эта дополнительная информация называется контекстом». [ 6 ]
Принимая во внимание контекстную информацию, у нас появится дополнительное измерение к существующей матрице рейтингов элементов пользователя. В качестве примера предположим, что система музыкальных рекомендаций дает разные рекомендации в зависимости от времени суток. В этом случае возможно, что в разное время суток у пользователя разные предпочтения в отношении музыки. Таким образом, вместо использования матрицы элементов пользователя мы можем использовать тензор порядка 3 (или выше для рассмотрения других контекстов) для представления контекстно-зависимых предпочтений пользователей. [ 15 ] [ 16 ] [ 17 ]
Чтобы воспользоваться преимуществами совместной фильтрации и, в частности, методов, основанных на соседстве, подходы можно расширить от двумерной рейтинговой матрицы до тензора более высокого порядка. [ нужна ссылка ] . Для этой цели подход состоит в том, чтобы найти пользователей, наиболее похожих/единомышленников на целевого пользователя; можно извлечь и вычислить сходство срезов (например, матрицы элемента-времени), соответствующих каждому пользователю. В отличие от контекстно-независимого случая, для которого вычисляется сходство двух рейтинговых векторов, в контекстно-зависимых подходах сходство рейтинговых матриц, соответствующих каждому пользователю, рассчитывается с использованием коэффициентов Пирсона . [ 6 ] После того, как наиболее единомышленники найдены, соответствующие им рейтинги объединяются, чтобы определить набор товаров, которые будут рекомендованы целевому пользователю.
Наиболее важным недостатком использования контекста в модели рекомендаций является необходимость иметь дело с более крупным набором данных, который содержит гораздо больше пропущенных значений по сравнению с матрицей рейтингов пользовательских элементов. [ нужна ссылка ] . Таким образом, подобно методам матричной факторизации , методы тензорной факторизации можно использовать для уменьшения размерности исходных данных перед использованием любых методов, основанных на соседстве. [ нужна ссылка ] .
Приложение в социальной сети
[ редактировать ]В отличие от традиционной модели основных СМИ, в которой мало редакторов, задающих правила, в социальных сетях с совместной фильтрацией может быть очень большое количество редакторов, а контент улучшается по мере увеличения числа участников. Такие сервисы, как Reddit , YouTube и Last.fm , являются типичными примерами мультимедиа на основе совместной фильтрации. [ 18 ]
Одним из сценариев применения совместной фильтрации является рекомендация интересной или популярной информации по мнению сообщества. Типичный пример: истории появляются на первой странице Reddit , поскольку за них «голосует» (положительно) сообщество. По мере того, как сообщество становится больше и разнообразнее, продвигаемые истории могут лучше отражать средний интерес членов сообщества.
Arc.Ask3.Ru — еще одно приложение совместной фильтрации. Добровольцы вносят свой вклад в энциклопедию, отделяя факты от лжи. [ 19 ]
Еще одним аспектом систем совместной фильтрации является способность генерировать более персонализированные рекомендации путем анализа информации о прошлой активности конкретного пользователя или истории других пользователей, которые, как считается, имеют схожие вкусы с данным пользователем. Эти ресурсы используются для профилирования пользователей и помогают сайту рекомендовать контент для каждого пользователя. Чем больше данный пользователь использует систему, тем лучше становятся рекомендации, поскольку система получает данные для улучшения своей модели этого пользователя.
Проблемы
[ редактировать ]Совместная система фильтрации не обязательно автоматически сопоставляет контент с предпочтениями. Если платформа не достигнет необычайно большого разнообразия и независимости мнений, одна точка зрения всегда будет доминировать над другой в конкретном сообществе. Как и в сценарии персонализированных рекомендаций, введение новых пользователей или новых элементов может вызвать проблему холодного запуска , поскольку в этих новых записях будет недостаточно данных для точной совместной фильтрации. Чтобы дать соответствующие рекомендации новому пользователю, система должна сначала изучить предпочтения пользователя, проанализировав прошлые действия по голосованию или рейтингу. Система совместной фильтрации требует, чтобы значительное количество пользователей оценило новый элемент, прежде чем его можно будет рекомендовать.
Проблемы
[ редактировать ]Разреженность данных
[ редактировать ]На практике многие коммерческие рекомендательные системы основаны на больших наборах данных. В результате матрица элементов пользователя, используемая для совместной фильтрации, может быть чрезвычайно большой и разреженной, что приводит к проблемам с выполнением рекомендаций.
Одной из типичных проблем, вызванных разреженностью данных, является проблема холодного запуска . Поскольку методы совместной фильтрации рекомендуют элементы на основе прошлых предпочтений пользователей, новым пользователям необходимо будет оценить достаточное количество элементов, чтобы система могла точно уловить их предпочтения и, таким образом, предоставить надежные рекомендации.
Аналогично, новинки также имеют ту же проблему. Когда в систему добавляются новые товары, они должны быть оценены значительным количеством пользователей, прежде чем их можно будет рекомендовать пользователям, вкусы которых совпадают с вкусами тех, кто их оценил. Проблема с новым элементом не влияет на рекомендации, основанные на содержании , поскольку рекомендация элемента основана на его дискретном наборе описательных качеств, а не на его рейтингах.
Масштабируемость
[ редактировать ]По мере роста числа пользователей и объектов традиционные алгоритмы CF будут испытывать серьезные проблемы с масштабируемостью. [ нужна ссылка ] . Например, с десятками миллионов клиентов и миллионы предметов , алгоритм CF со сложностью уже слишком велик. Кроме того, многим системам необходимо немедленно реагировать на онлайн-требования и давать рекомендации всем пользователям, независимо от миллионов пользователей, при этом большинство вычислений происходит на машинах с очень большой памятью. [ 20 ]



Синонимы
[ редактировать ]Синонимы относятся к тенденции ряда одинаковых или очень похожих объектов иметь разные названия или записи. Большинство рекомендательных систем не способны обнаружить эту скрытую связь и поэтому относятся к этим продуктам по-разному.
Например, казалось бы разные элементы «детский фильм» и «детский фильм» на самом деле относятся к одному и тому же элементу. Действительно, степень изменчивости в использовании описательных терминов больше, чем обычно предполагалось. [ нужна ссылка ] Преобладание синонимов снижает эффективность рекомендаций систем CF. Тематическое моделирование (например, метод скрытого распределения Дирихле ) может решить эту проблему путем группировки разных слов, принадлежащих к одной и той же теме. [ нужна ссылка ]
Серая овца
[ редактировать ]«Серая овца» относится к пользователям, чьи мнения не всегда совпадают или не совпадают с мнением какой-либо группы людей и, следовательно, не получают выгоды от совместной фильтрации. Паршивые овцы — это группа, чьи идиосинкразические вкусы делают рекомендации практически невозможными. Хотя это и является недостатком рекомендательной системы, неэлектронные рекомендатели также имеют большие проблемы в этих случаях, поэтому наличие паршивой овцы является приемлемым провалом. [ оспаривается – обсуждаем ]
Шиллинговые атаки
[ редактировать ]В системе рекомендаций, где каждый может давать оценки, люди могут давать много положительных оценок своим товарам и отрицательных оценок своим конкурентам. Часто системам совместной фильтрации необходимо принимать меры предосторожности, чтобы препятствовать таким манипуляциям.
Разнообразие и длинный хвост
[ редактировать ]Ожидается, что совместные фильтры увеличат разнообразие, поскольку помогают нам открывать новые продукты. Однако некоторые алгоритмы могут непреднамеренно поступать наоборот. Поскольку совместные фильтры рекомендуют продукты на основе прошлых продаж или рейтингов, они обычно не могут рекомендовать продукты с ограниченными историческими данными. Это может создать для популярных продуктов эффект «богатейте еще богаче», аналогичный положительным отзывам . Эта предвзятость к популярности может помешать тому, что в противном случае было бы лучшим соответствием потребительских товаров. Исследование Wharton подробно описывает это явление, а также несколько идей, которые могут способствовать разнообразию и « длинному хвосту ». [ 21 ] Было разработано несколько алгоритмов совместной фильтрации для обеспечения разнообразия и « длинного хвоста ». [ 22 ] рекомендуя роман, [ 23 ] непредвиденный, [ 24 ] и случайные предметы. [ 25 ]
Инновации
[ редактировать ]- Новые алгоритмы были разработаны для CF в результате премии Netflix .
- Межсистемная совместная фильтрация, при которой профили пользователей из нескольких рекомендательных систем объединяются в многозадачном режиме; таким образом достигается совместное использование шаблонов предпочтений между моделями. [ 26 ]
- Надежная совместная фильтрация , при которой рекомендации устойчивы к попыткам манипулирования. Эта область исследований все еще активна и до конца не решена. [ 27 ]
Вспомогательная информация
[ редактировать ]Матрица элементов пользователя является базовой основой традиционных методов совместной фильтрации и страдает от проблемы разреженности данных (т.е. холодного запуска ). Как следствие, за исключением матрицы «пользователь-элемент», исследователи пытаются собрать больше вспомогательной информации, чтобы повысить эффективность рекомендаций и разработать персонализированные рекомендательные системы. [ 28 ] Обычно существует две популярные вспомогательные информации: информация об атрибутах и информация о взаимодействии. Информация об атрибутах описывает свойства пользователя или элемента. Например, атрибут пользователя может включать общий профиль (например, пол и возраст) и социальные контакты (например, подписчиков или друзей в социальных сетях ); Атрибут товара означает такие свойства, как категория, бренд или контент. Кроме того, информация о взаимодействии относится к неявным данным, показывающим, как пользователи взаимодействуют с элементом. Широко используемая информация о взаимодействии содержит теги, комментарии или обзоры, историю просмотров и т. д. Вспомогательная информация играет важную роль в различных аспектах. Явные социальные ссылки, как надежный представитель доверия или дружбы, всегда используются при расчете сходства, чтобы найти похожих людей, которые разделяют интересы с целевым пользователем. [ 29 ] [ 30 ] Информация, связанная с взаимодействием — теги — рассматривается как третье измерение (в дополнение к пользователю и элементу) в расширенной совместной фильтрации для построения трехмерной тензорной структуры для изучения рекомендаций. [ 31 ]
См. также
[ редактировать ]- Язык разметки профилирования внимания (APML)
- Холодный старт
- Совместная модель
- Совместная поисковая система
- Коллективный разум
- Взаимодействие с клиентами
- Делегативная демократия : тот же принцип применяется к голосованию, а не к фильтрации.
- Корпоративные закладки
- Firefly (веб-сайт) — несуществующий веб-сайт, основанный на совместной фильтрации.
- Фильтр-пузырь
- Рейтинг страницы
- Выявление предпочтений
- Психографическая фильтрация
- Система рекомендаций
- Релевантность (поиск информации)
- Система репутации
- Надежная совместная фильтрация
- Поиск по сходству
- Склон Один
- Социальная прозрачность
Ссылки
[ редактировать ]- ^ Франческо Риччи, Лиор Рокач и Брача Шапира, Справочник «Введение в рекомендательные системы». Архивировано 2 июня 2016 г. в Wayback Machine , Справочник по рекомендательным системам, Springer, 2011, стр. 1–35.
- ^ Перейти обратно: а б Тервин, Лорен ; Хилл, Уилл (2001). «Не только рекомендательные системы: помогаем людям помогать друг другу» (PDF) . Аддисон-Уэсли. п. 6 . Проверено 16 января 2012 г.
- ^ Комплексный подход к рекомендациям по телевидению и видео по запросу. Архивировано 6 июня 2012 г. на Wayback Machine.
- ^ Джон С. Бриз, Дэвид Хекерман и Карл Кэди, Эмпирический анализ алгоритмов прогнозирования для совместной фильтрации , 1998. Архивировано 19 октября 2013 года в Wayback Machine.
- ^ Сяоюань Су, Таги М. Хошгофтаар, Обзор методов совместной фильтрации , Архив достижений в области искусственного интеллекта, 2009.
- ^ Перейти обратно: а б с Рекомендательные системы – Учебник | Чару К. Аггарвал | Спрингер . Спрингер. 2016. ISBN 9783319296579 .
- ^ Газанфар, Мустансар Али; Порка Беннетта, Адам; Седмак, Шандор (2012). «Алгоритмы системы рекомендаций по отображению ядра». Информационные науки . 208 : 81–104. CiteSeerX 10.1.1.701.7729 . дои : 10.1016/j.ins.2012.04.012 . S2CID 20328670 .
- ^ Дас, Абхинандан С.; Датар, Маюр; Гарг, Ашутош; Раджарам, Шьям (2007). «Персонализация новостей Google». Материалы 16-й международной конференции по Всемирной паутине – WWW '07 . п. 271. дои : 10.1145/1242572.1242610 . ISBN 9781595936547 . S2CID 207163129 .
- ^ Он, Сяннань; Ляо, Лизи; Чжан, Ханьван; Не, Лицян; Ху, Ся; Чуа, Тат-Сенг (2017). «Нейронная совместная фильтрация» . Материалы 26-й Международной конференции по Всемирной паутине . Руководящий комитет международных конференций по Всемирной паутине. стр. 173–182. arXiv : 1708.05031 . дои : 10.1145/3038912.3052569 . ISBN 9781450349130 . S2CID 13907106 . Проверено 16 октября 2019 г.
- ^ Лян, Давен; Кришнан, Рахул Г.; Хоффман, Мэтью Д.; Джебара, Тони (2018). «Вариационные автоэнкодеры для совместной фильтрации». Материалы конференции World Wide Web 2018 года по Всемирной паутине – WWW '18 . Руководящий комитет международных конференций по Всемирной паутине. стр. 689–698. arXiv : 1802.05814 . дои : 10.1145/3178876.3186150 . ISBN 9781450356398 .
- ^ Феррари Дакрема, Маурицио; Кремонези, Паоло; Яннах, Дитмар (2019). «Действительно ли мы добились большого прогресса? Тревожный анализ последних подходов к нейронным рекомендациям» . Материалы 13-й конференции ACM по рекомендательным системам . АКМ. стр. 101–109. arXiv : 1907.06902 . дои : 10.1145/3298689.3347058 . hdl : 11311/1108996 . ISBN 9781450362436 . S2CID 196831663 . Проверено 16 октября 2019 г.
- ^ Анелли, Вито Вальтер; Беллогин, Алехандро; Ди Ноя, Томмазо; Яннах, Дитмар; Помо, Клаудио (2022). «Лучшие алгоритмы рекомендаций: поиск новейших достижений» . Материалы 30-й конференции ACM по моделированию, адаптации и персонализации пользователей . АКМ: 121–131. arXiv : 2203.01155 . дои : 10.1145/3503252.3531292 . ISBN 9781450392075 . S2CID 247218662 . Проверено 1 марта 2022 г.
- ^ Людвиг, Мальте; Мауро, Ноэми; Латифи, Сара; Яннах, Дитмар (2019). «Сравнение производительности нейронных и ненейронных подходов к рекомендациям на основе сеансов». Материалы 13-й конференции ACM по рекомендательным системам . АКМ. стр. 462–466. дои : 10.1145/3298689.3347041 . ISBN 9781450362436 .
- ^ Адомавичюс, Гедиминас; Тужилин Александр (1 января 2015 г.). Риччи, Франческо; Рокач, Лиор; Шапира, Брача (ред.). Справочник по рекомендательным системам . Спрингер США. стр. 191–226. дои : 10.1007/978-1-4899-7637-6_6 . ISBN 9781489976369 .
- ^ Би, Сюань; Цюй, Энни; Шен, Сяотун (2018). «Многослойная тензорная факторизация с применением к рекомендательным системам» . Анналы статистики . 46 (6Б): 3303–3333. arXiv : 1711.01598 . дои : 10.1214/17-AOS1659 . S2CID 13677707 .
- ^ Чжан, Яньцин; Тан, Няньшэн; Цюй , ( 2020 Энни . )
- ^ Би, Сюань; Тан, Сивэй; Юань, Юбай; Чжан, Яньцин; Цюй, Энни (2021). «Тензоры в статистике» . Ежегодный обзор статистики и ее применения . 8 (1): аннурев. Бибкод : 2021AnRSA...842720B . doi : 10.1146/annurev-statistics-042720-020816 . S2CID 224956567 .
- ^ Совместная фильтрация: жизненная сила социальной сети. Архивировано 22 апреля 2012 г. в Wayback Machine.
- ^ Глейк, Джеймс (2012). Информация: история, теория, наводнение (1-е изд. Винтажных книг, изд. 2012 г.). Нью-Йорк: Винтажные книги. п. 410. ИСБН 978-1-4000-9623-7 . OCLC 745979816 .
- ^ Панкадж Гупта, Ашиш Гоэл, Джимми Лин, Аниш Шарма, Донг Ван и Реза Босаг Заде WTF: Система «за кем следить» в Твиттере , Материалы 22-й международной конференции по Всемирной паутине
- ^ Фледер, Дэниел; Хосанагар, Картик (май 2009 г.). «Следующий взлет или падение культуры блокбастеров: влияние рекомендательных систем на разнообразие продаж» . Наука управления . 55 (5): 697–712. дои : 10.1287/mnsc.1080.0974 . ССНР 955984 .
- ^ Кастельс, Пабло; Херли, Нил Дж.; Варгас, Саул (2015). «Новинка и разнообразие рекомендательных систем» . В Риччи, Франческо; Рокач, Лиор; Шапира, Брача (ред.). Справочник по рекомендательным системам (2-е изд.). Спрингер США. стр. 881–918. дои : 10.1007/978-1-4899-7637-6_26 . ISBN 978-1-4899-7637-6 .
- ^ Чхве, Чонван; Хон, Соён; Парк, Носон; Чо, Сон Бэ (2022). «Модели процессов размытия и повышения резкости для совместной фильтрации». arXiv : 2211.09324 [ cs.IR ].
- ^ Адамопулос, Панайотис; Тужилин Александр (январь 2015 г.). «О неожиданности в рекомендательных системах: или как лучше ожидать неожиданного». Транзакции ACM в интеллектуальных системах и технологиях . 5 (4): 1–32. дои : 10.1145/2559952 . S2CID 15282396 .
- ^ Адамопулос, Панайотис (октябрь 2013 г.). «За пределами точности прогнозирования рейтинга». Материалы 7-й конференции ACM по рекомендательным системам . стр. 459–462. дои : 10.1145/2507157.2508073 . ISBN 9781450324090 . S2CID 1526264 .
- ^ Хацис, Сотириос (октябрь 2013 г.). «Непараметрическая байесовская многозадачная совместная фильтрация». CIKM '13: Материалы 22-й международной конференции ACM по управлению информацией и знаниями . Портал.acm.org. стр. 2149–2158. дои : 10.1145/2505515.2505517 . ISBN 9781450322638 . S2CID 10515301 .
- ^ Мехта, Бхаскар; Хофманн, Томас; Нейдль, Вольфганг (19 октября 2007 г.). Материалы конференции ACM 2007 г. по рекомендательным системам — Rec Sys '07 . Портал.acm.org. п. 49. CiteSeerX 10.1.1.695.1712 . дои : 10.1145/1297231.1297240 . ISBN 9781595937308 . S2CID 5640125 .
- ^ Ши, Юэ; Ларсон, Марта; Ханьялич, Алан (2014). «Совместная фильтрация за пределами матрицы пользователь-элемент: обзор современного состояния и будущих проблем». Обзоры вычислительной техники ACM . 47 : 1–45. дои : 10.1145/2556270 . S2CID 5493334 .
- ^ Масса, Паоло; Авесани, Паоло (2009). Вычисление с социальным доверием . Лондон: Спрингер. стр. 259–285.
- ^ Гро Георг; Эмиг Кристиан. Рекомендации в областях, связанных со вкусом: совместная фильтрация против социальной фильтрации . Материалы международной конференции ACM 2007 г. по поддержке групповой работы. стр. 127–136. CiteSeerX 10.1.1.165.3679 .
- ^ Симеонидис, Панайотис; Нанопулос, Александрос; Манолопулос, Яннис (2008). «Рекомендации по тегам, основанные на уменьшении размерности тензора». Материалы конференции ACM 2008 года по рекомендательным системам . стр. 43–50. CiteSeerX 10.1.1.217.1437 . дои : 10.1145/1454008.1454017 . ISBN 9781605580937 . S2CID 17911131 .
Внешние ссылки
[ редактировать ]- За пределами рекомендательных систем: помогаем людям помогать друг другу , стр. 12, 2001 г.
- Рекомендательные системы. Прем Мелвилл и Викас Синдхвани. В Энциклопедии машинного обучения, Клод Саммут и Джеффри Уэбб (редакторы), Springer, 2010.
- Рекомендательные системы в промышленном контексте - докторская диссертация (2012 г.), включая всесторонний обзор многих совместных рекомендательных систем.
- На пути к следующему поколению рекомендательных систем: обзор современного состояния и возможных расширений . Адомавичус Г. и Тужилин А. Транзакции IEEE в области знаний и инженерии данных 06.2005
- Оценка рекомендательных систем совместной фильтрации ( DOI : 10.1145/963770.963772 )
- Исследования GroupLens .
- Совместная фильтрация с усилением контента для улучшения рекомендаций. Прем Мелвилл, Рэймонд Дж. Муни и Рамадасс Нагараджан. Материалы Восемнадцатой национальной конференции по искусственному интеллекту (AAAI-2002), стр. 187–192, Эдмонтон, Канада, июль 2002 г.
- Коллекция прошлых и настоящих проектов «фильтрации информации» (включая совместную фильтрацию) в MIT Media Lab.
- Eigentaste: алгоритм совместной фильтрации в постоянном времени. Кен Голдберг, Тереза Рёдер, Друв Гупта и Крис Перкинс. Информационный поиск, 4 (2), 133–151. Июль 2001 года.
- Обзор методов совместной фильтрации Су, Сяоюань и Хошгортаар, Таги. М
- Персонализация новостей Google: масштабируемая совместная онлайн-фильтрация Абхинандан Дас, Маюр Датар, Ашутош Гарг и Шьям Раджарам. Международная конференция по Всемирной паутине, Материалы 16-й международной конференции по Всемирной паутине.
- Фактор соседей: масштабируемая и точная совместная фильтрация Иегуда Корен, Транзакции по обнаружению знаний из данных (TKDD) (2009)
- Прогнозирование рейтинга с использованием совместной фильтрации
- Рекомендательные системы. Архивировано 11 февраля 2013 г. в Wayback Machine.
- Совместная фильтрация Беркли
| Базы данных органов управления : Национальные |
|---|