Алгоритм ОПТИКА
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Упорядочение точек для определения структуры кластеризации ( ОПТИКА ) — это алгоритм поиска на основе плотности [1] кластеры в пространственных данных. Его представили Михаэль Анкерст, Маркус М. Бройниг, Ханс-Петер Кригель и Йорг Зандер. [2] Его основная идея аналогична DBSCAN . [3] но он устраняет один из основных недостатков DBSCAN: проблему обнаружения значимых кластеров в данных различной плотности. Для этого точки базы данных (линейно) упорядочиваются так, что пространственно ближайшие точки становятся соседями в порядке. Кроме того, для каждой точки сохраняется специальное расстояние, представляющее плотность, которую необходимо принять для кластера, чтобы обе точки принадлежали одному кластеру. Это представлено в виде дендрограммы .
Основная идея
[ редактировать ]Как и DBSCAN , OPTICS требует два параметра: ε , который описывает максимальное расстояние (радиус), которое необходимо учитывать, и MinPts , описывающий количество точек, необходимых для формирования кластера. Точка p является базовой точкой как минимум точки MinPts. найдено , если в ее ε -окрестности (включая саму точку p ). В отличие от DBSCAN , OPTICS также учитывает точки, которые являются частью более плотно упакованного кластера, поэтому каждой точке назначается основное расстояние , которое описывает расстояние до MinPts ближайшей точки :


Расстояние достижимости другой точки o от точки p — это либо расстояние между o и p , либо основное расстояние p , в зависимости от того, что больше:

Если p и o — ближайшие соседи, это нам нужно предположить, что p и o принадлежат одному и тому же кластеру.

И расстояние ядра, и расстояние достижимости не определены, если достаточно плотный кластер (по отношению к ε отсутствует ). При достаточно большом ε этого никогда не происходит, но тогда каждый запрос ε -соседства возвращает всю базу данных, что приводит к время выполнения. Следовательно, параметр ε необходим для отсекания плотности кластеров, которые больше не интересны, и для ускорения алгоритма.

Параметр ε , строго говоря, не обязателен. Его можно просто установить на максимально возможное значение. Однако когда пространственный индекс доступен, он играет практическую роль в отношении сложности. OPTICS абстрагируется от DBSCAN, удаляя этот параметр, по крайней мере, до такой степени, что ему приходится указывать только максимальное значение.
Псевдокод
[ редактировать ]Базовый подход OPTICS аналогичен DBSCAN , но вместо сохранения известных, но пока необработанных элементов кластера в наборе, они сохраняются в приоритетной очереди (например, с использованием индексированной кучи ).
function OPTICS(DB, ε, MinPts) is
for each point p of DB do
p.reachability-distance = UNDEFINED
for each unprocessed point p of DB do
N = getNeighbors(p, ε)
mark p as processed
output p to the ordered list
if core-distance(p, ε, MinPts) != UNDEFINED then
Seeds = empty priority queue
update(N, p, Seeds, ε, MinPts)
for each next q in Seeds do
N' = getNeighbors(q, ε)
mark q as processed
output q to the ordered list
if core-distance(q, ε, MinPts) != UNDEFINED do
update(N', q, Seeds, ε, MinPts)
В update() приоритетная очередь Seeds обновляется с помощью - окрестности и , соответственно:



function update(N, p, Seeds, ε, MinPts) is
coredist = core-distance(p, ε, MinPts)
for each o in N
if o is not processed then
new-reach-dist = max(coredist, dist(p,o))
if o.reachability-distance == UNDEFINED then // o is not in Seeds
o.reachability-distance = new-reach-dist
Seeds.insert(o, new-reach-dist)
else // o in Seeds, check for improvement
if new-reach-dist < o.reachability-distance then
o.reachability-distance = new-reach-dist
Seeds.move-up(o, new-reach-dist)
Таким образом, ОПТИКА выводит точки в определенном порядке, аннотируя их наименьшее расстояние достижимости (в исходном алгоритме также экспортируется основное расстояние, но это не требуется для дальнейшей обработки).
Извлечение кластеров
[ редактировать ]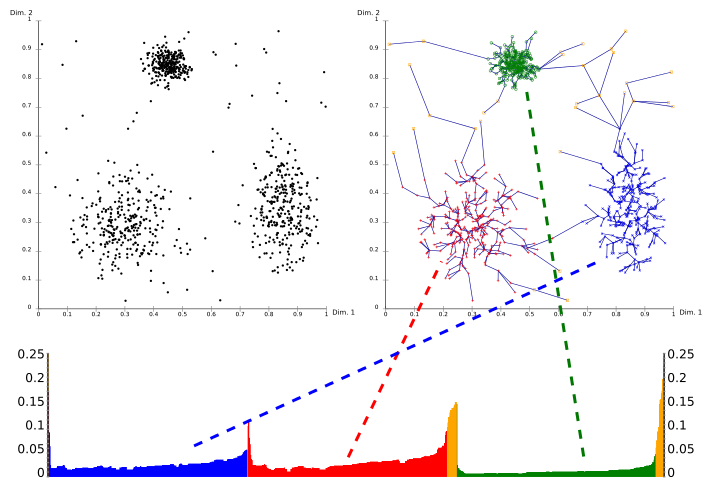
Используя график достижимости (особый вид дендрограммы ), можно легко получить иерархическую структуру кластеров. Это двумерный график с упорядочением точек, обработанных ОПТИКОЙ, по оси X и расстоянием достижимости по оси Y. Поскольку точки, принадлежащие кластеру, имеют малое расстояние достижимости до ближайшего соседа, кластеры отображаются как впадины на графике достижимости. Чем глубже долина, тем плотнее скопление.
Изображение выше иллюстрирует эту концепцию. В верхней левой области показан синтетический пример набора данных. Верхняя правая часть визуализирует связующее дерево, созданное OPTICS, а нижняя часть показывает график достижимости, рассчитанный OPTICS. Цвета на этом графике являются метками и не вычисляются алгоритмом; но хорошо видно, как впадины на графике соответствуют кластерам в приведенном выше наборе данных. Желтые точки на этом изображении считаются шумом, и на их графике достижимости не обнаружено впадин. Обычно они не назначаются кластерам, за исключением вездесущего кластера «все данные» в иерархическом результате.
Извлечение кластеров из этого графика можно выполнить вручную, выбрав диапазоны по оси X после визуального осмотра, выбрав пороговое значение по оси Y (результат будет аналогичен результату кластеризации DBSCAN с тем же и параметры minPts; здесь значение 0,1 может дать хорошие результаты) или с помощью различных алгоритмов, которые пытаются обнаружить впадины по крутизне, обнаружению перегиба или локальным максимумам. Участок участка, начинающийся с крутого спуска и заканчивающийся крутым подъемом, считается долиной и соответствует прилегающей территории с высокой плотностью застройки. Необходимо уделить дополнительное внимание последним точкам впадины, чтобы отнести их к внутреннему или внешнему кластеру. Этого можно добиться, рассматривая предшественника. [4] Кластеризации, полученные таким способом, обычно являются иерархическими и не могут быть достигнуты за один запуск DBSCAN.
Сложность
[ редактировать ]Как и DBSCAN , OPTICS обрабатывает каждую точку один раз и выполняет один -запрос соседства во время этой обработки. Учитывая пространственный индекс , который предоставляет запрос о соседстве в время выполнения, общее время выполнения получается. Однако худший случай , как и в случае с DBSCAN. Авторы оригинальной статьи OPTICS сообщают о фактическом постоянном коэффициенте замедления 1,6 по сравнению с DBSCAN. Обратите внимание, что значение может сильно повлиять на стоимость алгоритма, поскольку слишком большое значение может повысить стоимость запроса окрестности до линейной сложности.


В частности, выбирая (больше максимального расстояния в наборе данных) возможно, но приводит к квадратичной сложности, поскольку каждый запрос окрестности возвращает полный набор данных. Даже если пространственный индекс недоступен, это требует дополнительных затрат на управление кучей. Поэтому, следует выбирать соответствующим образом для набора данных.

Расширения
[ редактировать ]ОПТИКА-О [5] — это алгоритм обнаружения выбросов, основанный на ОПТИКЕ. Основное использование — это извлечение выбросов из существующей серии ОПТИКИ с меньшими затратами по сравнению с использованием другого метода обнаружения выбросов. Более известная версия LOF основана на тех же концепциях.
ДеЛи-Клю, [6] Density-Link-Clustering сочетает в себе идеи односвязной кластеризации и ОПТИКИ, устраняя параметр и предлагает улучшение производительности по сравнению с ОПТИКОЙ.
HiSC [7] - это метод иерархической подпространственной кластеризации (параллельно осям), основанный на ОПТИКЕ.
HICO [8] — это алгоритм иерархической корреляционной кластеризации , основанный на ОПТИКЕ.
Блюдо [9] является улучшением по сравнению с HiSC, позволяющим находить более сложные иерархии.
ФОПТИКА [10] это более быстрая реализация с использованием случайных проекций.
HDBSCAN* [11] основан на усовершенствовании DBSCAN, исключающем граничные точки из кластеров и, таким образом, более строго следуя базовому определению уровней плотности Хартигана. [12]
Доступность
[ редактировать ]Java-реализации OPTICS, OPTICS-OF, DeLi-Clu, HiSC, HiCO и DiSH доступны в среде интеллектуального анализа данных ELKI (с индексным ускорением для нескольких функций расстояния и с автоматическим извлечением кластеров с использованием метода извлечения ξ). Другие реализации Java включают расширение Weka (без поддержки извлечения ξ-кластера).
Пакет R «dbscan» включает реализацию OPTICS на C++ (как с традиционным dbscan, так и с извлечением кластеров ξ), использующую дерево kd для ускорения индекса только для евклидова расстояния.
Реализации OPTICS на Python доступны в библиотеке PyClustering и в scikit-learn . HDBSCAN* доступен в библиотеке hdbscan .
Ссылки
[ редактировать ]- ^ Кригель, Ханс-Петер; Крегер, Пер; Сандер, Йорг; Зимек, Артур (май 2011 г.). «Кластеризация на основе плотности» . Междисциплинарные обзоры Wiley: интеллектуальный анализ данных и обнаружение знаний . 1 (3): 231–240. дои : 10.1002/widm.30 . S2CID 36920706 .
- ^ Михаэль Анкерст; Маркус М. Брюниг; Ханс-Петер Кригель ; Йорг Сандер (1999). ОПТИКА: Упорядочение точек для определения структуры кластеризации . Международная конференция ACM SIGMOD по управлению данными. АКМ Пресс . стр. 49–60. CiteSeerX 10.1.1.129.6542 .
- ^ Мартин Эстер ; Ханс-Петер Кригель ; Йорг Сандер; Сяовэй Сюй (1996). Евангелос Симудис; Цзявэй Хан; Усама М. Файяд (ред.). Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом . Материалы Второй Международной конференции по обнаружению знаний и интеллектуальному анализу данных (KDD-96). АААИ Пресс . стр. 226–231. CiteSeerX 10.1.1.71.1980 . ISBN 1-57735-004-9 .
- ^ Шуберт, Эрих; Герц, Майкл (22 августа 2018 г.). Улучшение структуры кластера, извлеченной из графиков ОПТИКИ (PDF) . Обучение, знания, данные, анализ (LWDA 2018). Vol. CEUR-WS 2191. стр. 318–329 – через CEUR-WS.
- ^ Маркус М. Брюниг; Ханс-Петер Кригель ; Раймонд Т. Нг; Йорг Сандер (1999). «ОПТИКА-ОФ: Выявление локальных выбросов» . Принципы интеллектуального анализа данных и обнаружения знаний . Конспекты лекций по информатике. Том. 1704. Шпрингер-Верлаг . стр. 262–270. дои : 10.1007/b72280 . ISBN 978-3-540-66490-1 . S2CID 27352458 .
- ^ Ахтерт, Эльке; Бём, Кристиан; Крёгер, Пер (2006). «DeLi-Clu: повышение надежности, полноты, удобства использования и эффективности иерархической кластеризации с помощью ранжирования ближайших пар». В Нг, Ви Кеонг; Кицурегава, Масару; Ли, Цзяньчжун; Чанг, Куйю (ред.). Достижения в области обнаружения знаний и интеллектуального анализа данных, 10-я Тихоокеанско-Азиатская конференция, PAKDD 2006, Сингапур, 9–12 апреля 2006 г., Материалы . Конспекты лекций по информатике. Том. 3918. Спрингер. стр. 119–128. дои : 10.1007/11731139_16 .
- ^ Ахтерт, Эльке; Бём, Кристиан; Кригель, Ханс-Петер; Крегер, Пер; Мюллер-Горман, Ина; Зимек, Артур (2006). «Нахождение иерархий подпространственных кластеров». В Фюрнкранце, Йоханнес; Шеффер, Тобиас; Спилиопулу, Майра (ред.). Обнаружение знаний в базах данных: PKDD 2006, 10-я Европейская конференция по принципам и практике обнаружения знаний в базах данных, Берлин, Германия, 18-22 сентября 2006 г., Труды . Конспекты лекций по информатике. Том. 4213. Спрингер. стр. 446–453. дои : 10.1007/11871637_42 .
- ^ Ахтерт, Э.; Бём, К.; Крегер, П.; Зимек, А. (2006). «Горные иерархии корреляционных кластеров». 18-я Международная конференция по управлению научными и статистическими базами данных (SSDBM'06) . стр. 119–128. CiteSeerX 10.1.1.707.7872 . дои : 10.1109/SSDBM.2006.35 . ISBN 978-0-7695-2590-7 . S2CID 2679909 .
- ^ Ахтерт, Эльке; Бём, Кристиан; Кригель, Ханс-Петер; Крегер, Пер; Мюллер-Горман, Ина; Зимек, Артур (2007). «Обнаружение и визуализация иерархий подпространственных кластеров». В Рамамоханарао, Котагири; Кришна, П. Радха; Мохания, Мукеш К.; Нантадживарават, Экавит (ред.). Достижения в области баз данных: концепции, системы и приложения, 12-я Международная конференция по системам баз данных для передовых приложений, DASFAA 2007, Бангкок, Таиланд, 9–12 апреля 2007 г., Материалы . Конспекты лекций по информатике. Том. 4443. Спрингер. стр. 152–163. дои : 10.1007/978-3-540-71703-4_15 .
- ^ Шнайдер, Йоханнес; Влахос, Михаил (2013). «Быстрая кластеризация на основе плотности без параметров с помощью случайных проекций». 22-я Международная конференция ACM по управлению информацией и знаниями (CIKM) .
- ^ Кампелло, Рикардо Дж.Г.Б.; Мулави, Давуд; Зимек, Артур; Сандер, Йорг (22 июля 2015 г.). «Оценки иерархической плотности для кластеризации данных, визуализации и обнаружения выбросов». Транзакции ACM по извлечению знаний из данных . 10 (1): 1–51. дои : 10.1145/2733381 . S2CID 2887636 .
- ^ Дж. А. Хартиган (1975). Алгоритмы кластеризации . Джон Уайли и сыновья.