Сетевой мотив
| Часть серии о | ||||
| Сетевая наука | ||||
|---|---|---|---|---|
| Типы сетей | ||||
| Графики | ||||
| ||||
| Модели | ||||
| ||||
| ||||

Сетевые мотивы — это повторяющиеся и статистически значимые подграфы или шаблоны более крупного графа . Все сети, включая биологические сети , социальные сети, технологические сети (например, компьютерные сети и электрические схемы) и многое другое, могут быть представлены в виде графов, включающих большое количество разнообразных подграфов.
Сетевые мотивы — это подграфы, которые повторяются в конкретной сети или даже среди различных сетей. Каждый из этих подграфов, определяемый определенным шаблоном взаимодействия между вершинами, может отражать структуру, в которой конкретные функции достигаются эффективно. Действительно, мотивы имеют особое значение во многом потому, что они могут отражать функциональные свойства. У них недавно [ когда? ] привлекло много внимания как полезная концепция для раскрытия принципов структурного проектирования сложных сетей. [1] Хотя сетевые мотивы могут обеспечить глубокое понимание функциональных возможностей сети, их обнаружение является сложной вычислительной задачей.
Определения [ править ]
Пусть G = (V, E) и G′ = (V′, E′) — два графа. Граф G′ является подграфом графа G (записывается как G′ ⊆ G ), если V′ ⊆ V и E′ ⊆ E ∩ (V′ × V′) . Если G′ ⊆ G и G′ содержит все ребра ∈ E такие, что u, v ∈ V′ , то G′ является индуцированным подграфом G ⟨u, v⟩ . Мы называем G' и G изоморфными (записываемыми как G' ↔ G ), если существует биекция (взаимно однозначное соответствие) f:V' → V с ⟨u, v⟩ ∈ E' ⇔ ⟨f(u) , f(v)⟩ ∈ E для всех u, v ∈ V′ . Отображение f называется изоморфизмом между G и G′ . [2]
Когда G″ ⊂ G и существует изоморфизм между подграфом G″ и графом G′ это отображение представляет собой появление G ′ в G. , Количество появлений графа G' в G называется частотой F G графа G' в G . Граф называется повторяющимся (или частым ) в G, когда его частота F G (G') превышает заранее определенный порог или пороговое значение. В этом обзоре мы используем термины «шаблон» и «частый подграф» как взаимозаменяемые. Существует ансамбль Ω(G) случайных графов, соответствующий нулевой модели, связанной с G . Мы должны равномерно выбрать N случайных графов из Ω(G) и вычислить частоту для конкретного частого подграфа G' в G . Если частота G' в G выше, чем его среднеарифметическая частота в N случайных графах R i , где 1 ≤ i ≤ N , мы называем этот повторяющийся шаблон значимым и, следовательно, рассматриваем G' как сетевой мотив для G . Для небольшого графа G' , сети G и набора рандомизированных сетей R(G) ⊆ Ω(R) , где R(G) = N , Z-оценка частоты G' определяется выражением

где µ R (G') и σ R (G') обозначают среднее и стандартное отклонение частоты в наборе R(G) соответственно. [3] [4] [5] [6] [7] [8] Чем больше Z(G') , тем более значимым является подграф G' как мотив. Альтернативно, другим измерением при проверке статистических гипотез, которое можно учитывать при обнаружении мотива, является p значение , заданное как вероятность F R (G') ≥ F G (G') (как его нулевая гипотеза), где F R (G') указывает частоту G' в рандомизированной сети. [6] Подграфик со значением p меньше порогового значения (обычно 0,01 или 0,05) будет рассматриваться как значимый шаблон. Значение p для частоты G' определяется как


где N указывает количество рандомизированных сетей, i определяется по ансамблю рандомизированных сетей, а дельта-функция Кронекера δ(c(i)) равна единице, если выполнено условие c(i) . Концентрация [9] [10] конкретного подграфа G ' размера n в сети G относится к отношению появления подграфа в сети к общему числу n частот неизоморфных подграфов размера , которое формулируется как

где индекс i определен по множеству всех неизоморфных графов размера n. Другое статистическое измерение предназначено для оценки сетевых мотивов, но оно редко используется в известных алгоритмах. Это измерение введено Пикардом и др. в 2008 году и использовало распределение Пуассона, а не нормальное распределение Гаусса, которое неявно использовалось выше. [11]
Кроме того, были предложены три конкретные концепции частоты подграфов. [12] Как показано на рисунке, первая концепция частоты F 1 учитывает все совпадения графа в исходной сети. Это определение аналогично тому, которое мы ввели выше. Второе понятие F 2 определяется как максимальное количество непересекающихся по ребрам экземпляров данного графа в исходной сети. И, наконец, понятие частоты F 3 предполагает совпадения с непересекающимися ребрами и узлами. Следовательно, две концепции F 2 и F 3 ограничивают использование элементов графа, и, как можно сделать вывод, частота подграфа снижается за счет наложения ограничений на использование сетевых элементов. В результате алгоритм обнаружения сетевых мотивов пропустит больше подграфов-кандидатов, если мы будем настаивать на частотных концепциях F 2 и F 3 .
История [ править ]
Пионерами изучения сетевых мотивов стали Холланд и Лейнхардт. [13] [14] [15] [16] который ввел концепцию триадной переписи сетей. Они представили методы для перечисления различных типов конфигураций подграфов и проверки того, статистически ли числа подграфов отличаются от ожидаемых в случайных сетях.
Эта идея была дополнительно обобщена в 2002 году Ури Алоном и его группой. [17] когда сетевые мотивы были обнаружены в сети регуляции генов ( транскрипции ) бактерий E. coli , а затем и в большом наборе природных сетей. С тех пор на эту тему было проведено значительное количество исследований. Некоторые из этих исследований сосредоточены на биологических приложениях, в то время как другие сосредоточены на вычислительной теории сетевых мотивов.
Биологические исследования пытаются интерпретировать мотивы, обнаруженные в биологических сетях. Например, в следующей работе: [17] сетевые мотивы, обнаруженные в E. coli, были обнаружены в транскрипционных сетях других бактерий. [18] а также дрожжи [19] [20] и высших организмов. [21] [22] [23] Особый набор сетевых мотивов был идентифицирован в других типах биологических сетей, таких как нейронные сети и сети взаимодействия белков. [5] [24] [25]
Вычислительные исследования были сосредоточены на совершенствовании существующих инструментов обнаружения мотивов, чтобы помочь биологическим исследованиям и позволить анализировать более крупные сети. На данный момент предложено несколько различных алгоритмов, которые подробно описаны в следующем разделе в хронологическом порядке.
Совсем недавно был выпущен инструмент acc-MOTIF для обнаружения сетевых мотивов. [26]
обнаружения Алгоритмы мотивов
Были предложены различные решения сложной проблемы обнаружения сетевых мотивов (NM). Эти алгоритмы можно классифицировать по различным парадигмам, таким как методы точного подсчета, методы выборки, методы роста шаблонов и так далее. Однако проблема обнаружения мотивов состоит из двух основных этапов: сначала вычисление количества появлений подграфа, а затем оценка значимости подграфа. Рецидив считается значительным, если он заметно превышает ожидаемый. Грубо говоря, ожидаемое количество появлений подграфа может быть определено с помощью нулевой модели, которая определяется ансамблем случайных сетей с некоторыми из тех же свойств, что и исходная сеть.
До 2004 года единственным точным методом подсчета обнаружения НМ был метод грубой силы, предложенный Майло и др. . [3] Этот алгоритм оказался успешным для обнаружения небольших мотивов, но использование этого метода для обнаружения мотивов даже размером 5 или 6 было невозможно с вычислительной точки зрения. Следовательно, требовался новый подход к этой проблеме.
Здесь дан обзор вычислительных аспектов основных алгоритмов и обсуждаются их преимущества и недостатки с алгоритмической точки зрения.
Классификация алгоритмов [ править ]
В таблице ниже перечислены алгоритмы обнаружения мотивов, которые будут описаны в этом разделе. Их можно разделить на две общие категории: те, которые основаны на точном подсчете, и те, которые вместо этого используют статистическую выборку и оценки. Поскольку вторая группа не учитывает все появления подграфа в основной сети, алгоритмы, принадлежащие к этой группе, работают быстрее, но могут давать необъективные и нереалистичные результаты.
На следующем уровне алгоритмы точного подсчета можно разделить на сетецентрические и подграфоцентрические методы. Алгоритмы первого класса ищут в заданной сети все подграфы заданного размера, тогда как алгоритмы, попадающие во второй класс, сначала генерируют различные возможные неизоморфные графы заданного размера, а затем исследуют сеть для каждого сгенерированного подграфа отдельно. Каждый подход имеет свои преимущества и недостатки, которые обсуждаются ниже.
В таблице также указано, можно ли использовать алгоритм для направленных или ненаправленных сетей, а также для индуцированных или неиндуцированных подграфов. Для получения дополнительной информации обратитесь к предоставленным веб-ссылкам или адресам лабораторий.
| Метод подсчета | Основа | Имя | Режиссер/Нережиссер | Индуцированный/Неиндуцированный |
|---|---|---|---|---|
| Точный | Сетецентричный | м искатель | Оба | Индуцированный |
| ЕСУ (ФАНМОД) | Оба | Индуцированный | ||
| Кавош (используется в CytoKavosh ) | Оба | Индуцированный | ||
| G-Попытки | Оба | Индуцированный | ||
| ПГД | Ненаправленный | Индуцированный | ||
| Подграфоцентрический | ФПФ (Мависто) | Оба | Индуцированный | |
| НеМоФиндер | Ненаправленный | Индуцированный | ||
| Грочоу – Келлис | Оба | Оба | ||
| МОДА | Оба | Оба | ||
| Оценка/Выборка | Цветовое кодирование | Н. Алон и др.' Алгоритм | Ненаправленный | Неиндуцированный |
| Другие подходы | м искатель | Оба | Индуцированный | |
| ЕСУ (ФАНМОД) | Оба | Индуцированный |
| Алгоритм | Название лаборатории/отдела | Кафедра / Школа | институт | Адрес | Электронная почта |
|---|---|---|---|---|---|
| м искатель | Группа Ури Алона | Кафедра молекулярно-клеточной биологии | Научный институт Вейцмана | Реховот, Израиль, Вольфсон, Rm. 607 | уриалон на сайте weizmann.ac.il |
| ФПФ (Мависто) | ---- | ---- | Институт генетики растений и исследований сельскохозяйственных растений Лейбница (IPK) | Corrensstraße 3, D-06466 Город Зееланд, ОТ Гатерслебен, Германия | напишите на ipk-gatersleben.de |
| ЕСУ (ФАНМОД) | Кафедра теоретической информатики I | Институт компьютерных наук | Университет Фридриха Шиллера в Йене | Ernst-Abbe-Platz 2, D-07743 Йена, Германия | Себастьян Вернике на gmail.com |
| НеМоФиндер | ---- | Школа вычислительной техники | Национальный университет Сингапура | Сингапур 119077 | Ченджин на comp.nus.edu.sg |
| Грочоу – Келлис | Группа теории CS и группа сложных систем | Информатика | Университет Колорадо, Боулдер | 1111 Engineering Dr. ECOT 717, 430 UCB Boulder, CO 80309-0430 США | jgrochow на colorado.edu |
| Н. Алон и др.' Алгоритм | Кафедра чистой математики | Школа математических наук | Тель-Авивский университет | Тель-Авив 69978, Израиль | nogaa на post.tau.ac.il |
| МОДА | Лаборатория системной биологии и биоинформатики (ЛББ) | Институт биохимии и биофизики (ИББ) | Тегеранский университет | Площадь Энгелаб, проспект Энгелаб, Тегеран, Иран | Амасудин в ibb.ut.ac.ir |
| Кавош (используется в CytoKavosh ) | Лаборатория системной биологии и биоинформатики (ЛББ) | Институт биохимии и биофизики (ИББ) | Тегеранский университет | Площадь Энгелаб, проспект Энгелаб, Тегеран, Иран | Амасудин в ibb.ut.ac.ir |
| G-Попытки | Центр исследований в области передовых вычислительных систем | Информатика | Университет Порту | Rua Campo Alegre 1021/1055, Порту, Португалия | Прибейро на dcc.fc.up.pt |
| ПГД | Лаборатория сетевого обучения и открытий | Департамент компьютерных наук | Университет Пердью | Университет Пердью, 305 N University St, Вест-Лафайет, Индиана 47907 | [электронная почта защищена] |
mfinder [ править ]
Каштан и др. опубликовал mfinder , первый инструмент для поиска мотивов, в 2004 году. [9] Он реализует два типа алгоритмов поиска мотивов: полный перебор и метод первой выборки.
Их алгоритм обнаружения выборки был основан на выборке границ по всей сети. Этот алгоритм оценивает концентрацию индуцированных подграфов и может использоваться для обнаружения мотивов в направленных или ненаправленных сетях. Процедура выборки алгоритма начинается с произвольного ребра сети, которое ведет к подграфу размера два, а затем расширяет подграф, выбирая случайное ребро, инцидентное текущему подграфу. После этого он продолжает выбирать случайные соседние ребра, пока не будет получен подграф размера n. Наконец, выбранный подграф расширяется и включает в себя все ребра, существующие в сети между этими n узлами. Когда алгоритм использует подход выборки, получение несмещенных выборок является наиболее важной проблемой, которую может решить алгоритм. Однако процедура отбора проб не обеспечивает единообразия, и поэтому Kashtan et al. предложил схему взвешивания, которая присваивает разные веса различным подграфам внутри сети. [9] Основной принцип распределения весов заключается в использовании информации о вероятности выборки для каждого подграфа, т. е. вероятные подграфы получат сравнительно меньшие веса по сравнению с невероятными подграфами; следовательно, алгоритм должен рассчитать вероятность выборки каждого подграфа, который был выбран. Этот метод взвешивания помогает искателю беспристрастно определять концентрации подграфиков.
В расширении, включающем резкий контраст с исчерпывающим поиском, время вычислений алгоритма удивительно асимптотически не зависит от размера сети. Анализ вычислительного времени алгоритма показал, что оно занимает O(n н ) для каждой выборки подграфа размера n из сети. С другой стороны, нет никакого анализа. [9] на время классификации выборочных подграфов, что требует решения проблемы изоморфизма графов для каждой выборки подграфа. Кроме того, при вычислении веса подграфа на алгоритм требуются дополнительные вычислительные усилия. Но нельзя не сказать, что алгоритм может производить выборку одного и того же подграфа несколько раз, тратя время, не собирая никакой информации. [10] В заключение, используя преимущества выборки, алгоритм работает более эффективно, чем алгоритм исчерпывающего поиска; однако он лишь приблизительно определяет концентрации подграфиков. Этот алгоритм может находить мотивы размером до 6 благодаря своей основной реализации, и в результате он выдает наиболее значимый мотив, а не все остальные. Также необходимо отметить, что этот инструмент не имеет возможности визуального представления. Алгоритм выборки показан кратко:
| м искатель |
|---|
| Определения: E s — множество выбранных ребер. V s — это набор всех узлов, которых касаются ребра в E . |
| Инициализируйте V и . E как пустые множества 1. Выберите случайное ребро e 1 = (vi , v j ) . Обновление E s = {e 1 }, V s = {v i , v j } 2. Составьте список L всех соседних ребер E s . Исключите из L все ребра между членами V s . 3. Выберите случайное ребро e = {v k ,v l } из L . Обновить E s = E s ⋃ {e }, V s = V s ⋃ {v k , v l }. 4. Повторяйте шаги 2–3 до завершения подграфа из n узлов (пока |V s | = n ). 5. Вычислите вероятность выборки выбранного подграфа из n узлов. |
FPF (Мависто) [ править ]
Шрайбер и Швеббермейер [12] предложил алгоритм под названием «Flexible Pattern Finder» (FPF) для извлечения частых подграфов входной сети и реализовал его в системе под названием Mavisto . [27] Их алгоритм использует свойство замыкания вниз , которое применимо для частотных концепций F 2 и F 3 . Свойство замыкания вниз утверждает, что частота подграфов монотонно уменьшается с увеличением размера подграфов; однако это свойство не обязательно выполняется для концепции частоты F 1 . FPF основан на дереве шаблонов (см. рисунок), состоящем из узлов, представляющих различные графы (или шаблоны), где родительским элементом каждого узла является подграф его дочерних узлов; другими словами, соответствующий граф каждого узла дерева шаблонов расширяется за счет добавления нового ребра к графу его родительского узла.

Сначала алгоритм FPF перечисляет и сохраняет информацию обо всех совпадениях подграфа, расположенного в корне дерева шаблонов. Затем один за другим он строит дочерние узлы предыдущего узла в дереве шаблонов, добавляя одно ребро, поддерживаемое совпадающим ребром в целевом графе, и пытается расширить всю предыдущую информацию о совпадениях в новом подграфе. (дочерний узел). На следующем этапе он решает, является ли частота текущего шаблона ниже заранее определенного порога или нет. Если он ниже и если замыкание вниз сохраняется, FPF может отказаться от этого пути и не проходить дальше в этой части дерева; в результате избегаются ненужные вычисления. Эта процедура продолжается до тех пор, пока не останется пути для прохождения.
Преимущество алгоритма в том, что он не учитывает редкие подграфы и старается завершить процесс перебора как можно скорее; следовательно, он тратит время только на перспективные узлы в дереве шаблонов и отбрасывает все остальные узлы. В качестве дополнительного бонуса понятие дерева шаблонов позволяет реализовывать и выполнять FPF параллельно, поскольку можно независимо проходить каждый путь дерева шаблонов. Однако FPF наиболее полезен для частотных концепций F 2 и F 3 , поскольку замыкание вниз не применимо к F 1 . Тем не менее, дерево шаблонов по-прежнему практично для F 1 , если алгоритм работает параллельно. Еще одним преимуществом алгоритма является то, что реализация этого алгоритма не имеет ограничений на размер мотива, что делает его более поддающимся улучшениям. Псевдокод FPF (Mavisto) показан ниже:
| Мавист |
|---|
| Данные: график G , размер целевого шаблона t , концепция частоты F. Результат: набор R шаблонов размера t с максимальной частотой. |
| R ← φ , f max ← 0 P ← начать шаблон p1 размера 1 M p 1 ← все совпадения p 1 в G Пока P ≠ φ, делайте P max ← выбрать все шаблоны из P максимального размера. P ← выбрать шаблон с максимальной частотой из P max Ε = ExtensionLoop (G, p, M p ) foreach Шаблон p ∈ E Если F = F 1 , то f ← размер (M p ) Иначе f ← Максимальное независимое множество (F, M p ) Конец Если размер (p) = t , то Если f = f max , то R ← R ⋃ {p } В противном случае, если f > f max, то R ← {p }; f макс ← f Конец Еще Если F = F 1 или f ≥ f max, то P ← P ⋃ {p } Конец Конец Конец Конец |
ЕСУ (ФАНМОД) [ править ]
Смещение выборки Kashtan et al. [9] дало большой стимул для разработки более совершенных алгоритмов решения проблемы открытия НМ. Хотя Каштан и др. попытались устранить этот недостаток с помощью схемы взвешивания, этот метод привел к нежелательным накладным расходам на время выполнения, а также к более сложной реализации. Этот инструмент является одним из самых полезных, поскольку он поддерживает визуальные параметры, а также представляет собой эффективный алгоритм по времени. Но он имеет ограничение на размер мотива, поскольку не позволяет искать мотивы размером 9 или выше из-за особенностей реализации инструмента.
Вернике [10] представил алгоритм под названием RAND-ESU , который обеспечивает значительное улучшение по сравнению с mfinder . [9] Этот алгоритм, основанный на алгоритме точного перечисления ESU , был реализован в виде приложения под названием FANMOD . [10] RAND-ESU — это алгоритм обнаружения NM, применимый как для направленных, так и для ненаправленных сетей, который эффективно использует несмещенную выборку узлов по всей сети и предотвращает повторное подсчет подграфов. Кроме того, RAND-ESU использует новый аналитический подход под названием DIRECT для определения значимости подграфа вместо использования ансамбля случайных сетей в качестве нулевой модели. Метод DIRECT оценивает концентрацию подграфов без явной генерации случайных сетей. [10] Эмпирически метод DIRECT более эффективен по сравнению со случайным ансамблем сетей в случае подграфов с очень низкой концентрацией; однако классическая Null-модель работает быстрее, чем метод DIRECT для подграфов с высокой концентрацией. [3] [10] Далее мы подробно описываем алгоритм ESU , а затем покажем, как этот точный алгоритм можно эффективно модифицировать до RAND-ESU , который оценивает концентрации подграфов.
Алгоритмы ESU и RAND-ESU довольно просты и, следовательно, легко реализуются. ESU сначала находит набор всех индуцированных подграфов размера k , пусть S k будет этим набором. ESU можно реализовать как рекурсивную функцию; выполнение этой функции можно отобразить в виде древовидной структуры глубины k , называемой ESU-деревом (см. рисунок). Каждый из узлов ESU-дерева указывает состояние рекурсивной функции, которая влечет за собой два последовательных набора SUB и EXT. SUB относится к узлам целевой сети, которые являются соседними и образуют частичный подграф размера |SUB| ≤ к . Если |СУБ| = k алгоритм нашел индуцированный полный подграф, поэтому S k = SUB ∪ S k . Однако если |SUB| < k , алгоритм должен расширить SUB для достижения мощности k . Это делается с помощью набора EXT, который содержит все узлы, удовлетворяющие двум условиям: во-первых, каждый из узлов в EXT должен быть смежным хотя бы с одним из узлов в SUB; во-вторых, их числовые метки должны быть больше метки первого элемента в SUB. Первое условие гарантирует, что расширение SUB-узлов приведет к созданию связного графа, а второе условие приведет к тому, что листья ESU-Tree (см. рисунок) будут различимы; в результате это предотвращает пересчет. Обратите внимание, что набор EXT не является статическим набором, поэтому на каждом этапе он может расширяться за счет новых узлов, которые не нарушают эти два условия. Следующий шаг ESU включает классификацию подграфов, помещенных в листья ESU-дерева, по неизоморфным размерам. k классов графов; следовательно, ESU определяет частоты и концентрации подграфиков. Этот этап был реализован с помощью простого алгоритма Маккея . [28] [29] который классифицирует каждый подграф, выполняя тест на изоморфизм графа. Таким образом, ESU находит набор всех индуцированных k подграфов размера в целевом графе с помощью рекурсивного алгоритма, а затем определяет их частоту с помощью эффективного инструмента.
Процедура внедрения RAND-ESU довольно проста и является одним из главных преимуществ FANMOD . Можно изменить алгоритм ESU , чтобы исследовать только часть листьев ESU-дерева, применив значение вероятности 0 ≤ p d ≤ 1 для каждого уровня ESU-дерева и обязав ESU проходить каждый дочерний узел узла на уровне d. -1 с вероятностью p d . Этот новый алгоритм называется RAND-ESU . Очевидно, что когда p d = 1 для всех уровней, RAND-ESU действует как ESU . При p d = 0 алгоритм ничего не находит. Обратите внимание, что эта процедура гарантирует, что шансы посещения каждого листа ESU-дерева одинаковы, что приводит к несмещенной выборке подграфов через сеть. Вероятность посещения каждого листа равна Π d p d и одинакова для всех листьев ESU-дерева; следовательно, этот метод гарантирует несмещенную выборку подграфов из сети. Тем не менее, определение значения p d для 1 ≤ d ≤ k – это еще одна проблема, которую эксперт должен определить вручную, чтобы получить точные результаты концентраций подграфиков. [8] Хотя четкого предписания по этому вопросу не существует, Вернике приводит некоторые общие наблюдения, которые могут помочь в определении значений p_d. Таким образом, RAND-ESU — это очень быстрый алгоритм обнаружения НМ в случае индуцированных подграфов, поддерживающий метод несмещенной выборки. Хотя основной алгоритм ESU и, следовательно, инструмент FANMOD известны тем, что обнаруживают индуцированные подграфы, существует тривиальная модификация ESU , которая позволяет также находить неиндуцированные подграфы. Псевдокод ESU (FANMOD) показан ниже:
| Перечень ЕСУ (FANMOD) |
|---|
| EnumerateSubgraphs(G,k) Входные данные: граф G = (V, E) и целое число 1 ≤ k ≤ |V| . Вывод: все размера k подграфы в G . для каждой вершины v ∈ V делаем VExtension ← {u ∈ N({v}) | u > v } вызвать ExtendSubgraph ({v}, VExtension, v) скорее |
| ExtendSubgraph(VSubgraph, VExtension, v) если |VSubgraph| = k , затем выведите G[VSubgraph] и верните в то время как VExtension ≠ ∅ do Удалить произвольно выбранную вершину w из VExtension VExtension′ ← VExtension ∪ {u ∈ N excl (w, VSubgraph) | ты > v } вызвать ExtendSubgraph (VSubgraph ∪ {w}, VExtension', v) возвращаться |
НеМоФиндер [ править ]
Чен и др. [30] представил новый алгоритм обнаружения НМ под названием NeMoFinder , который адаптирует идею SPIN [31] для извлечения часто встречающихся деревьев и после этого разворачивает их в неизоморфные графы. [8] NeMoFinder использует часто встречающиеся деревья размера n для разделения входной сети на набор графов размера n , после чего находит частые подграфы размера n путем расширения часто встречающихся деревьев ребро за ребром до получения полного размера n графа K n . Алгоритм находит НМ в неориентированных сетях и не ограничивается извлечением только индуцированных подграфов. Более того, NeMoFinder представляет собой алгоритм точного перебора и не основан на методе выборки. Как Чен и др. утверждают, что NeMoFinder применим для обнаружения относительно крупных НМ, например, для обнаружения НМ размером до 12 во всей сети PPI S. cerevisiae (дрожжи), как утверждают авторы. [32]
NeMoFinder состоит из трех основных этапов. Сначала находят часто встречающиеся деревья размера n , затем используют повторяющиеся деревья размера n для разделения всей сети на набор графов размера n и, наконец, выполняют операции соединения подграфов для поиска часто встречающихся подграфов размера n. [30] На первом этапе алгоритм обнаруживает все неизоморфные деревья размера n и отображения дерева в сеть. На втором этапе диапазоны этих отображений используются для разделения сети на графы размера n. До этого шага нет различия между NeMoFinder и методом точного подсчета. Однако большая часть неизоморфных графов размера n все еще остается. NeMoFinder использует эвристику для перечисления недеревьевых графов размера n на основе информации, полученной на предыдущих шагах. Основное преимущество алгоритма заключается в третьем шаге, который генерирует подграфы-кандидаты из ранее пронумерованных подграфов. Это создание новых подграфов размера n осуществляется путем соединения каждого предыдущего подграфа с производными от него подграфами, называемыми двоюродными подграфами . Эти новые подграфы содержат одно дополнительное ребро по сравнению с предыдущими подграфами. Однако существуют некоторые проблемы при создании новых подграфов: не существует четкого метода получения двоюродных братьев из графа, соединение подграфа с его кузенами приводит к избыточности при генерации определенного подграфа более одного раза, а определение двоюродного брата является затруднительным. делается с помощью канонического представления матрицы смежности, которая не закрывается при операции соединения. NeMoFinder — это эффективный алгоритм поиска сетевых мотивов для мотивов размером до 12 только для сетей белок-белкового взаимодействия, которые представлены в виде неориентированных графов. И он не способен работать с направленными сетями, которые так важны в области сложных и биологических сетей. Псевдокод NeMoFinder показан ниже:
| НеМоФиндер |
|---|
| Вход: Г – сеть ППИ; N – количество рандомизированных сетей; K - Максимальный размер сетевого мотива; F - Частотный порог; S – порог уникальности; Выход: U — повторяющийся и уникальный набор сетевых мотивов; D ← ∅ ; для размера мотива k от 3 до K выполните T ← FindRepeatedTrees (k) ; GD k ← GraphPartition (G, T) Д ← Д ∪ Т ; Д' ← Т ; я ← к ; в то время как D′ ≠ ∅ и i ≤ k × (k - 1)/2 делают D′ ← FindRepeatedGraphs (k, i, D′) ; Д ← Д ∪ Д' ; я ← я + 1 ; закончиться, пока конец для для счетчика i от 1 до N сделайте Гранд ; ← RandomizedNetworkGeneration ( ) для каждого g ∈ D делаем GetRandFrequency (g, Grand ) ; конец для конец для В ← ∅ ; для каждого g ∈ D делаем s ← GetUniqunessValue (g) ; если s ≥ S , то U ← U ∪ {g }; конец, если конец для вернуть У ; |
Грочоу-Келлис [ править ]
Грочоу и Келлис [33] предложил точный алгоритм перебора появлений подграфа. Алгоритм основан на мотивно-ориентированном подходе, что означает, что частота данного подграфа, называемого графом запроса , полностью определяется путем поиска всех возможных отображений из графа запроса в более крупную сеть. Это утверждается [33] что мотивно-ориентированный метод по сравнению с сетецентрическими методами имеет некоторые преимущества. Прежде всего, это позволяет избежать повышенной сложности перечисления подграфов. Кроме того, использование отображения вместо перечисления позволяет улучшить проверку изоморфизма. Чтобы улучшить производительность алгоритма, поскольку это неэффективный алгоритм точного перебора, авторы ввели быстрый метод, который называется условиями нарушения симметрии . Во время простых тестов на изоморфизм подграфов подграф может быть сопоставлен с одним и тем же подграфом графа запроса несколько раз. В алгоритме Грохоу-Келлиса (ГК) нарушение симметрии используется, чтобы избежать таких множественных отображений. Здесь мы представляем алгоритм ГК и условие нарушения симметрии, которое устраняет избыточные тесты на изоморфизм.

Алгоритм GK обнаруживает весь набор отображений данного графа запроса в сеть за два основных шага. Все начинается с вычисления условий нарушения симметрии графа запроса. Затем с помощью метода ветвей и границ алгоритм пытается найти все возможные отображения графа запроса в сеть, которые удовлетворяют соответствующим условиям нарушения симметрии. Пример использования условий нарушения симметрии в алгоритме ГК показан на рисунке.
Как упоминалось выше, техника нарушения симметрии представляет собой простой механизм, который исключает необходимость тратить время на поиск подграфа более одного раза из-за его симметрии. [33] [34] Обратите внимание, что вычисление условий нарушения симметрии требует нахождения всех автоморфизмов данного графа запроса. Несмотря на то, что не существует эффективного (или полиномиального) алгоритма для решения проблемы автоморфизма графов, на практике эту проблему можно эффективно решить с помощью инструментов Маккея. [28] [29] Как утверждается, использование условий нарушения симметрии при обнаружении НМ позволяет значительно сэкономить время работы. Более того, об этом можно судить по результатам [33] [34] что использование условий нарушения симметрии приводит к более высокой эффективности, особенно для направленных сетей, по сравнению с неориентированными сетями. Условия нарушения симметрии, используемые в алгоритме GK, аналогичны ограничению, которое алгоритм ESU применяет к меткам в наборах EXT и SUB. В заключение, алгоритм GK вычисляет точное количество появлений данного графа запроса в большой сложной сети, а использование условий нарушения симметрии повышает производительность алгоритма. Кроме того, алгоритм GK является одним из известных алгоритмов, не имеющих ограничений по размеру мотивов при реализации и потенциально способных находить мотивы любого размера.
Цветовое кодирование [ править ]
Большинство алгоритмов в области обнаружения НМ используются для поиска индуцированных подграфов сети. В 2008 году Нога Алон и др. [35] также представил подход для поиска неиндуцированных подграфов. Их техника работает в ненаправленных сетях, таких как PPI. Кроме того, он подсчитывает неиндуцированные деревья и подграфы деревьев с ограниченной шириной. Этот метод применяется для подграфов размером до 10.
Этот алгоритм подсчитывает количество неиндуцированных вхождений дерева T с k = O(logn) вершин в сеть G с n вершинами следующим образом:
- Цветовое кодирование. Раскрасьте каждую вершину входной сети G независимо и равномерно случайным образом одним из k цветов.
- Подсчет. Примените процедуру динамического программирования, чтобы подсчитать количество неиндуцированных вхождений T , в которых каждая вершина имеет уникальный цвет. Подробнее об этом шаге см. [35]
- Повторите два вышеуказанных шага O(e к ) раз и сложите количество вхождений T, чтобы получить оценку количества его вхождений в G .
Поскольку доступные сети PPI далеко не полны и не содержат ошибок, этот подход подходит для обнаружения NM в таких сетях. Поскольку алгоритм Грохоу-Келлиса и этот алгоритм являются популярными для неиндуцированных подграфов, стоит отметить, что алгоритм, предложенный Алоном и др. требует меньше времени, чем алгоритм Грохоу-Келлиса. [35]
МОДА [ править ]
Омиди и др. [36] представил новый алгоритм обнаружения мотивов под названием MODA , который применим для индуцированного и неиндуцированного обнаружения NM в ненаправленных сетях. Он основан на мотивно-ориентированном подходе, обсуждаемом в разделе «Алгоритм Грочоу – Келлиса». Очень важно различать мотивно-ориентированные алгоритмы, такие как алгоритм MODA и GK, из-за их способности работать как алгоритмы поиска запросов. Эта функция позволяет таким алгоритмам находить один запрос на мотив или небольшое количество запросов на мотив (не все возможные подграфы заданного размера) с большими размерами. Поскольку количество возможных неизоморфных подграфов экспоненциально увеличивается с размером подграфа, для мотивов большого размера (даже более 10) сетецентрические алгоритмы, которые ищут все возможные подграфы, сталкиваются с проблемой. Хотя мотивно-ориентированные алгоритмы также имеют проблемы с обнаружением всех возможных подграфов большого размера, их способность находить небольшое их количество иногда является важным свойством.
Используя иерархическую структуру, называемую деревом расширения , алгоритм MODA способен систематически извлекать NM заданного размера и аналогично FPF , который позволяет избежать перечисления бесперспективных подграфов; MODA учитывает потенциальные запросы (или подграфы-кандидаты), которые могут привести к частому появлению подграфов. Несмотря на то, что MODA напоминает FPF в использовании древовидной структуры, дерево расширения применимо только для вычисления концепции частоты F 1 . Как мы обсудим далее, преимущество этого алгоритма состоит в том, что он не выполняет проверку изоморфизма подграфов для графов запросов , не являющихся деревьями . Кроме того, он использует метод выборки, чтобы ускорить время работы алгоритма.
Вот основная идея: по простому критерию можно обобщить отображение графа размера k в сеть на его суперграфы того же размера. Например, предположим, что существует отображение f(G) графа G с k узлами в сеть, и у нас есть граф G' того же размера с еще одним ребром &langu, v⟩ ; f G отобразит G′ есть ребро ⟨f G (u), f G (v)⟩ в сеть, если в сети . В результате мы можем использовать набор отображений графа для определения частот его суперграфов одного и того же порядка просто за время O (1) без проведения проверки изоморфизма подграфа. Алгоритм изобретательно начинается с минимально связных графов запросов размера k и находит их отображения в сети с помощью изоморфизма подграфов. После этого, с сохранением размера графа, он расширяет ранее рассмотренные графы запросов по ребру и вычисляет частоту появления этих расширенных графов, как указано выше. Процесс расширения продолжается до тех пор, пока не будет достигнут полный граф K k (полностью связанный с k(k-1) ⁄ 2 ребра).
Как обсуждалось выше, алгоритм начинается с вычисления частот поддеревьев в сети, а затем расширяет поддеревья по ребру. Один из способов реализации этой идеи называется деревом расширения T k для каждого k . На рисунке показано дерево расширения для подграфов размера 4. T k организует текущий процесс и предоставляет графы запросов в иерархическом порядке. Строго говоря, дерево расширения T k представляет собой просто ориентированный ациклический граф которого или DAG, корневой номер k указывает размер графа, существующего в дереве расширения, а каждый из его остальных узлов содержит матрицу смежности отдельного графа запросов размера k . Все узлы на первом уровне T k представляют собой отдельные k деревья размера обходе T k , и при углубленном графы запросов расширяются с одним ребром на каждом уровне. Граф запросов в узле — это подграф графа запросов в дочернем узле с разницей в одно ребро. Самый длинный путь в T k состоит из (k 2 -3k+4)/2 ребра и представляет собой путь от корня до листового узла, содержащего полный граф. Генерацию деревьев расширения можно выполнить с помощью простой процедуры, которая описана в разделе . [36]
MODA проходит через T k и, извлекая деревья запросов из первого уровня T k, вычисляет их наборы отображений и сохраняет эти сопоставления для следующего шага. Для недеревьевых запросов из T k алгоритм извлекает сопоставления, связанные с родительским узлом в T k, и определяет, какое из этих сопоставлений может поддерживать текущие графы запросов. Процесс будет продолжаться до тех пор, пока алгоритм не получит полный граф запроса. Сопоставления дерева запросов извлекаются с использованием алгоритма Грочоу-Келлиса. Для вычисления частоты графов запросов, не являющихся деревьями, алгоритм использует простую процедуру, которая занимает O(1) шагов. Кроме того, MODA использует метод выборки, при котором выборка каждого узла в сети линейно пропорциональна степени узла, распределение вероятностей точно аналогично известной модели предпочтительного прикрепления Барабаши-Альберта в области сложных сетей. [37] Этот подход генерирует приближения; однако результаты почти стабильны при различных исполнениях, поскольку подграфы агрегируются вокруг узлов с высокой степенью связи. [38] Псевдокод MODA показан ниже:

| МОДА |
|---|
| Входные данные: G : входной график, k : размер подграфа, Δ : пороговое значение. Выходные данные: Список часто встречающихся подграфов: список всех часто встречающихся k. подграфов размера Примечание: F G : набор отображений из G во входном графе G. принести Т К делать G’ = Get-Next-BFS (T k ) // G’ — граф запроса если |E(G′)| = (к – 1) вызвать Mapping-Module (G', G) еще вызов перечисляющего модуля (G′, G, T k ) конец, если сохранить F 2 если |F G | > Δ, тогда добавить G ' в список частых подграфов конец, если До тех пор, пока |E(G')| = (к – 1)/2 вернуть список часто встречающихся подграфов |
Кавош [ править ]
Недавно представленный алгоритм под названием Кавош. [39] направлен на улучшение использования основной памяти. Кавош можно использовать для обнаружения NM как в направленных, так и в ненаправленных сетях. Основная идея перечисления аналогична алгоритмам GK и MODA , которые сначала находят все k , в которых участвовал конкретный узел, затем удаляют узел и впоследствии повторяют этот процесс для остальных узлов. подграфы размера [39]
Для подсчета подграфов размера k , включающих конкретный узел, неявно строятся деревья с максимальной глубиной k, основанные на этом узле и основанные на отношениях соседства. Дочерние узлы каждого узла включают как входящие, так и исходящие соседние узлы. Для спуска по дереву на каждом уровне выбирается дочерний элемент с ограничением: конкретный дочерний элемент может быть включен только в том случае, если он не был включен ни на одном верхнем уровне. После спуска на самый низкий возможный уровень дерево снова поднимается, и процесс повторяется с оговоркой, что узлы, посещенные на более ранних путях потомка, теперь считаются непосещенными узлами. Последнее ограничение при построении деревьев состоит в том, что все дочерние элементы в конкретном дереве должны иметь числовые метки, превышающие метку корня дерева. Ограничения на метки дочерних элементов аналогичны условиям, которые используют алгоритмы GK и ESU , чтобы избежать пересчета подграфов.
Протокол извлечения подграфов использует композиции целых чисел. Для извлечения подграфов размера k все возможные композиции целого числа k-1 необходимо рассмотреть . Композиции k-1 состоят из всех возможных способов выражения k-1 в виде суммы натуральных чисел. Суммы, в которых порядок слагаемых различается, считаются отдельными. Композиция может быть выражена как k 2 ,k 3 ,..., km, где k 2 + k 3 + ... + k m = k-1 . Для подсчета подграфов на основе композиции k i выбираются узлов i -го уровня дерева как узлы подграфов ( i = 2,3,...,m ). Выбранные k -1 узлов вместе с узлом в корне определяют подграф внутри сети. После обнаружения подграфа, соответствующего совпадению в целевой сети, чтобы иметь возможность оценить размер каждого класса в соответствии с целевой сетью, Кавош использует Nauty. алгоритм [28] [29] точно так же, как ФАНМОД . Перечислительная часть алгоритма Кавоша показана ниже:
| Перечисление Кавоша |
|---|
| Enumerate_Vertex(G, u, S, Remainder, i) Ввод: G : График ввода если Остаток = 0, то |
| Проверить(G, Родители, и) Входные данные: G : входной граф, Родители : выбранные вершины последнего слоя, u : Корневая вершина. ValList ← NILL |
Недавно появился плагин Cytoscape под названием CytoKavosh. [40] разработан для этого программного обеспечения. Он доступен на Cytoscape веб-странице [1] .
G-Попытки [ править ]
В 2010 году Педро Рибейро и Фернандо Силва предложили новую структуру данных для хранения набора подграфов, названную g-trie . [41] Эта структура данных, которая концептуально похожа на дерево префиксов, хранит подграфы в соответствии с их структурами и находит вхождения каждого из этих подграфов в более крупный граф. Одним из заметных аспектов этой структуры данных является то, что при обнаружении сетевого мотива необходимо оценить подграфы в основной сети. Таким образом, нет необходимости искать в случайной сети те, которых нет в основной сети. Это может быть одной из трудоемких частей алгоритмов, в которых получаются все подграфы в случайных сетях.
G -три — это многопутевое дерево, в котором может храниться набор графов. Каждый узел дерева содержит информацию об одной вершине графа и ее ребрах, соответствующих узлам-предкам. Путь от корня до листа соответствует одному графу. Потомки узла G-Trie имеют общий подграф. Построение g-три хорошо описано в . [41] После построения g-trie происходит счетная часть. Основная идея процесса подсчета состоит в том, чтобы вернуться по всем возможным подграфам, но в то же время выполнить тесты на изоморфизм. Этот метод обратного отслеживания по сути тот же метод, который используется в других подходах, ориентированных на мотивы, таких как алгоритмы MODA и GK . Использование преимуществ общих подструктур в том смысле, что в данный момент существует частичное изоморфное совпадение для нескольких различных подграфов-кандидатов.
Среди упомянутых алгоритмов G-Tries является самым быстрым. Но чрезмерное использование памяти является недостатком этого алгоритма, который может ограничить размер обнаруживаемых мотивов на персональном компьютере со средней памятью.
ParaMODA и NemoMap [ править ]
ПараМОД [42] и НемоМап [43] — быстрые алгоритмы, опубликованные в 2017 и 2018 годах соответственно. Они не так масштабируемы, как многие другие. [44]
Сравнение [ править ]
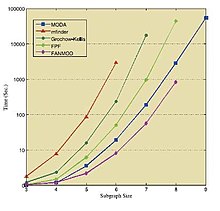
В таблицах и на рисунке ниже показаны результаты запуска упомянутых алгоритмов в различных стандартных сетях. Эти результаты взяты из соответствующих источников, [36] [39] [41] поэтому их следует рассматривать индивидуально.
| Сеть | Размер | Исходная сеть переписи населения | Средняя перепись в случайных сетях | ||||
|---|---|---|---|---|---|---|---|
| ФАН МОД | ГК | Джи-Три | ФАН МОД | ГК | Джи-Три | ||
| Дельфины | 5 | 0.07 | 0.03 | 0.01 | 0.13 | 0.04 | 0.01 |
| 6 | 0.48 | 0.28 | 0.04 | 1.14 | 0.35 | 0.07 | |
| 7 | 3.02 | 3.44 | 0.23 | 8.34 | 3.55 | 0.46 | |
| 8 | 19.44 | 73.16 | 1.69 | 67.94 | 37.31 | 4.03 | |
| 9 | 100.86 | 2984.22 | 6.98 | 493.98 | 366.79 | 24.84 | |
| Схема | 6 | 0.49 | 0.41 | 0.03 | 0.55 | 0.24 | 0.03 |
| 7 | 3.28 | 3.73 | 0.22 | 3.53 | 1.34 | 0.17 | |
| 8 | 17.78 | 48.00 | 1.52 | 21.42 | 7.91 | 1.06 | |
| Социальные | 3 | 0.31 | 0.11 | 0.02 | 0.35 | 0.11 | 0.02 |
| 4 | 7.78 | 1.37 | 0.56 | 13.27 | 1.86 | 0.57 | |
| 5 | 208.30 | 31.85 | 14.88 | 531.65 | 62.66 | 22.11 | |
| Дрожжи | 3 | 0.47 | 0.33 | 0.02 | 0.57 | 0.35 | 0.02 |
| 4 | 10.07 | 2.04 | 0.36 | 12.90 | 2.25 | 0.41 | |
| 5 | 268.51 | 34.10 | 12.73 | 400.13 | 47.16 | 14.98 | |
| Власть | 3 | 0.51 | 1.46 | 0.00 | 0.91 | 1.37 | 0.01 |
| 4 | 1.38 | 4.34 | 0.02 | 3.01 | 4.40 | 0.03 | |
| 5 | 4.68 | 16.95 | 0.10 | 12.38 | 17.54 | 0.14 | |
| 6 | 20.36 | 95.58 | 0.55 | 67.65 | 92.74 | 0.88 | |
| 7 | 101.04 | 765.91 | 3.36 | 408.15 | 630.65 | 5.17 | |
| Размер → | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|
| Сети ↓ | Алгоритмы ↓ | ||||||||
| кишечная палочка | Кавош | 0.30 | 1.84 | 14.91 | 141.98 | 1374.0 | 13173.7 | 121110.3 | 1120560.1 |
| ФАН МОД | 0.81 | 2.53 | 15.71 | 132.24 | 1205.9 | 9256.6 | - | - | |
| Мавист | 13532 | - | - | - | - | - | - | - | |
| Искатель | 31.0 | 297 | 23671 | - | - | - | - | - | |
| Электронный | Кавош | 0.08 | 0.36 | 8.02 | 11.39 | 77.22 | 422.6 | 2823.7 | 18037.5 |
| ФАН МОД | 0.53 | 1.06 | 4.34 | 24.24 | 160 | 967.99 | - | - | |
| Мавист | 210.0 | 1727 | - | - | - | - | - | - | |
| Искатель | 7 | 14 | 109.8 | 2020.2 | - | - | - | - | |
| Социальные | Кавош | 0.04 | 0.23 | 1.63 | 10.48 | 69.43 | 415.66 | 2594.19 | 14611.23 |
| ФАН МОД | 0.46 | 0.84 | 3.07 | 17.63 | 117.43 | 845.93 | - | - | |
| Мавист | 393 | 1492 | - | - | - | - | - | - | |
| Искатель | 12 | 49 | 798 | 181077 | - | - | - | - |
Устоявшиеся мотивы и их функции [ править ]
Большая экспериментальная работа была посвящена пониманию сетевых мотивов в сетях регуляции генов . Эти сети контролируют, какие гены экспрессируются в клетке в ответ на биологические сигналы. Сеть определяется таким образом, что гены представляют собой узлы, а направленные ребра представляют собой контроль одного гена с помощью транскрипционного фактора (регуляторного белка, который связывает ДНК), кодируемого другим геном. Таким образом, сетевые мотивы представляют собой паттерны генов, регулирующих скорость транскрипции друг друга. При анализе транскрипционных сетей видно, что одни и те же сетевые мотивы появляются снова и снова у самых разных организмов, от бактерий до человека. транскрипционная сеть E. coli Например, и дрожжей состоит из трех основных семейств мотивов, которые составляют почти всю сеть. Основная гипотеза состоит в том, что сетевой мотив был независимо выбран в ходе эволюционных процессов сходящимся образом. [45] [46] поскольку создание или устранение регуляторных взаимодействий происходит быстро в эволюционном масштабе времени по сравнению со скоростью изменения генов, [45] [46] [47] Более того, эксперименты по динамике, генерируемой сетевыми мотивами в живых клетках, показывают, что они обладают характерными динамическими функциями. Это предполагает, что сетевой мотив служит строительным блоком в сетях регуляции генов, которые полезны для организма.
Функции, связанные с общими сетевыми мотивами в транскрипционных сетях, были изучены и продемонстрированы в нескольких исследовательских проектах как теоретически, так и экспериментально. Ниже приведены некоторые из наиболее распространенных сетевых мотивов и связанные с ними функции.
Негативная авторегуляция (НАР) [ править ]

Одним из простейших и наиболее распространенных сетевых мотивов в E. coli является негативная ауторегуляция, при которой фактор транскрипции (TF) подавляет собственную транскрипцию. Было показано, что этот мотив выполняет две важные функции. Первая функция — ускорение реакции. Было показано, что NAR ускоряет реакцию на сигналы как теоретически, [48] и экспериментально. Впервые это было показано в синтетической транскрипционной сети. [49] а затем в естественном контексте в системе SOS репарации ДНК E. coli. [50] Вторая функция — повышение стабильности саморегулируемой концентрации продуктов гена против стохастического шума, тем самым уменьшая различия в уровнях белка между различными клетками. [51] [52] [53]
Позитивная авторегуляция (PAR) [ править ]
Положительная ауторегуляция (PAR) происходит, когда фактор транскрипции увеличивает собственную скорость производства. В отличие от мотива NAR, этот мотив замедляет время реакции по сравнению с простой регуляцией. [54] В случае сильного PAR мотив может приводить к бимодальному распределению уровней белка в клеточных популяциях. [55]
Петли прямой связи (FFL) [ править ]

Этот мотив обычно встречается во многих генных системах и организмах. Мотив состоит из трех генов и трех регуляторных взаимодействий. Целевой ген C регулируется двумя TF A и B, а также TF B также регулируется TF A. Поскольку каждое из регуляторных взаимодействий может быть либо положительным, либо отрицательным, возможно, существует восемь типов мотивов FFL. [56] Два из этих восьми типов: когерентный FFL типа 1 (C1-FFL) (где все взаимодействия положительны) и некогерентный FFL типа 1 (I1-FFL) (A активирует C, а также активирует B, который подавляет C) встречаются гораздо чаще. чаще встречается в транскрипционной сети E. coli и дрожжей, чем остальные шесть типов. [56] [57] В дополнение к структуре схемы следует также учитывать способ, которым сигналы от A и B интегрируются промотором C. В большинстве случаев FFL представляет собой либо вентиль И (для активации C требуются A и B), либо вентиль ИЛИ (для активации C достаточно либо A, либо B), но возможны и другие входные функции.
Когерентный тип 1 FFL (C1-FFL) [ править ]
Было показано, что C1-FFL с вентилем И теоретически выполняет функцию элемента «знакочувствительной задержки» и детектора постоянства. [56] и экспериментально [58] с арабинозной системой E. coli . Это означает, что этот мотив может обеспечить фильтрацию импульсов, при которой короткие импульсы сигнала не будут генерировать ответ, а постоянные сигналы будут генерировать ответ после небольшой задержки. Отключение выхода при окончании постоянного импульса будет быстрым. Противоположное поведение наблюдается в случае суммирующего шлюза с быстрым откликом и задержкой закрытия, как это было продемонстрировано на системе жгутиков E. coli . [59] Эволюция de novo C1-FFL в генных регуляторных сетях была продемонстрирована вычислительно в ответ на отбор для фильтрации идеализированного короткого сигнального импульса, но для неидеализированного шума вместо этого использовалась основанная на динамике система прямого регулирования с другой топологией. одобренный. [60]
Некогерентный тип 1 ФФЛ (И1-ФФЛ) [ править ]
I1-FFL — это генератор импульсов и ускоритель реакции. Два сигнальных пути I1-FFL действуют в противоположных направлениях: один путь активирует Z, а другой подавляет его. Когда подавление завершено, это приводит к пульсирующей динамике. Экспериментально было также продемонстрировано, что I1-FFL может служить ускорителем ответа, аналогично мотиву NAR. Разница в том, что I1-FFL может ускорить реакцию любого гена, а не обязательно гена транскрипционного фактора. [61] На сетевой мотив I1-FFL была возложена дополнительная функция: как теоретически, так и экспериментально было показано, что I1-FFL может генерировать немонотонную входную функцию как в синтетическом, так и в синтетическом режиме. [62] и родные системы. [63] Наконец, единицы экспрессии, которые включают некогерентный упреждающий контроль над генным продуктом, обеспечивают адаптацию к количеству ДНК-матрицы и могут превосходить простые комбинации конститутивных промоторов. [64] Регулирование с прямой связью продемонстрировало лучшую адаптацию, чем отрицательная обратная связь , а схемы, основанные на интерференции РНК, были наиболее устойчивыми к изменению количества матрицы ДНК. [64] Эволюция de novo I1-FFL в генных регуляторных сетях была продемонстрирована вычислительно в ответ на отбор на генерацию импульса, причем I1-FFL являются более эволюционно доступными, но не превосходящими по сравнению с альтернативным мотивом, в котором они являются скорее результатом чем вход, который активирует репрессор. [65]
FFL с несколькими выходами [ править ]
В некоторых случаях одни и те же регуляторы X и Y регулируют несколько генов Z одной и той же системы. Было показано, что регулируя силу взаимодействий, этот мотив определяет временной порядок активации генов. Это было продемонстрировано экспериментально на системе жгутиков E. coli . [66]
Модули с одним входом (SIM) [ править ]
Этот мотив возникает, когда один регулятор регулирует набор генов без дополнительной регуляции. Это полезно, когда гены совместно выполняют определенную функцию и поэтому их всегда необходимо активировать синхронно. Регулируя силу взаимодействий, он может создать временную программу экспрессии генов, которые он регулирует. [67]
В литературе модули с несколькими входами (MIM) возникли как обобщение SIM. Однако точные определения SIM и MIM были источником противоречий. Предпринимаются попытки предоставить ортогональные определения канонических мотивов в биологических сетях и алгоритмы для их перечисления, особенно SIM, MIM и Bi-Fan (2x2 MIM). [68]
Плотно перекрывающиеся регулоны (ДОР) [ править ]
Этот мотив возникает в том случае, если несколько регуляторов комбинаторно контролируют набор генов с различными регуляторными комбинациями. Этот мотив был обнаружен у E. coli в различных системах, таких как утилизация углерода, анаэробный рост, реакция на стресс и другие. [17] [22] Чтобы лучше понять функцию этого мотива, необходимо получить больше информации о том, как гены интегрируют множество входных данных. Каплан и др. [69] составил карту входных функций генов утилизации сахара в E. coli , демонстрируя различные формы.
Мотивы деятельности [ править ]
представляют собой интересное обобщение сетевых мотивов. Мотивы активности Мотивы деятельности представляют собой повторяющиеся закономерности, которые можно обнаружить, когда узлы и ребра сети помечены количественными характеристиками. Например, когда края метаболических путей аннотируются величиной или временем экспрессии соответствующего гена, некоторые закономерности встречаются слишком часто, учитывая лежащую в основе структуру сети. [70]
Критика [ править ]
Предположение (иногда более, иногда менее неявное), лежащее в основе сохранения топологической подструктуры, заключается в том, что она имеет особое функциональное значение. Недавно это предположение было подвергнуто сомнению. Некоторые авторы утверждают, что мотивы, такие как мотивы двух вееров , могут проявлять разнообразие в зависимости от сетевого контекста и, следовательно, [71] структура мотива не обязательно определяет функцию. Сетевая структура, конечно, не всегда указывает на функцию; эта идея существует уже некоторое время, например, см. оперон Sin. [72]
Большинство анализов функции мотива проводится при рассмотрении мотива, действующего изолированно. Недавние исследования [73] предоставляет убедительные доказательства того, что сетевой контекст, то есть связи мотива с остальной частью сети, слишком важен, чтобы делать выводы о функции только на основе локальной структуры — в цитируемой статье также рассматриваются критические замечания и альтернативные объяснения наблюдаемых данных. Исследован анализ влияния отдельного мотивного модуля на глобальную динамику сети. [74] Еще одна недавняя работа предполагает, что определенные топологические особенности биологических сетей естественным образом приводят к общему появлению канонических мотивов, тем самым ставя под сомнение, являются ли частоты появления разумным доказательством того, что структуры мотивов выбраны из-за их функционального вклада в работу сетей. [75] [76]
См. также [ править ]
Ссылки [ править ]
- ^ Масуди-Нежад А., Шрайбер Ф., Разаги МК З. (2012). «Строительные блоки биологических сетей: обзор алгоритмов обнаружения основных сетевых мотивов». ИЭПП Системная биология . 6 (5): 164–74. дои : 10.1049/iet-syb.2011.0011 . ПМИД 23101871 .
- ^ Дистель, Рейнхард (2005). Теория графов (3-е изд.). Берлин: Шпрингер. ISBN 9783540261827 .
- ↑ Перейти обратно: Перейти обратно: а б с Майло Р., Шен-Орр СС, Ицковиц С., Каштан Н., Чкловский Д., Алон У. (2002). «Сетевые мотивы: простые строительные блоки сложных сетей». Наука . 298 (5594): 824–827. Бибкод : 2002Sci...298..824M . CiteSeerX 10.1.1.225.8750 . дои : 10.1126/science.298.5594.824 . ПМИД 12399590 . S2CID 9884096 .
- ^ Альберт Р., Барабаси А.Л. (2002). «Статистическая механика сложных сетей». Обзоры современной физики . 74 (1): 47–49. arXiv : cond-mat/0106096 . Бибкод : 2002РвМП...74...47А . CiteSeerX 10.1.1.242.4753 . дои : 10.1103/RevModPhys.74.47 . S2CID 60545 .
- ↑ Перейти обратно: Перейти обратно: а б Майло Р., Ицковиц С., Каштан Н., Левитт Р., Шен-Орр С., Айзенштат И., Шеффер М., Алон У. (2004). «Суперсемейства спроектированных и развитых сетей». Наука . 303 (5663): 1538–1542. Бибкод : 2004Sci...303.1538M . дои : 10.1126/science.1089167 . ПМИД 15001784 . S2CID 14760882 .
- ↑ Перейти обратно: Перейти обратно: а б Швеббермейер, Х (2008). «Сетевые мотивы». В Юнкере Б.Х., Шрайбере Ф. (ред.). Анализ биологических сетей . Хобокен, Нью-Джерси: John Wiley & Sons. стр. 85–108.
- ^ Борнхольдт, С; Шустер, Х.Г. (2003). Справочник по графам и сетям: от генома до Интернета . п. 417. Бибкод : 2003hgnf.book.....B .
{{cite encyclopedia}}:|journal=игнорируется ( помогите ) - ↑ Перейти обратно: Перейти обратно: а б с Сириелло Дж., Герра С. (2008). «Обзор моделей и алгоритмов обнаружения мотивов в сетях белок-белкового взаимодействия» . Брифинги по функциональной геномике и протеомике . 7 (2): 147–156. дои : 10.1093/bfgp/eln015 . ПМИД 18443014 .
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Каштан Н, Ицковиц С, Майло Р, Алон У (2004). «Эффективный алгоритм выборки для оценки концентрации подграфов и обнаружения сетевых мотивов» . Биоинформатика . 20 (11): 1746–1758. doi : 10.1093/биоинформатика/bth163 . ПМИД 15001476 .
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Вернике С. (2006). «Эффективное обнаружение сетевых мотивов». Транзакции IEEE/ACM по вычислительной биологии и биоинформатике . 3 (4): 347–359. CiteSeerX 10.1.1.304.2576 . дои : 10.1109/tcbb.2006.51 . PMID 17085844 . S2CID 6188339 .
- ^ Пикард Ф., Даудин Дж. Дж., Шбат С. , Робин С. (2005). «Оценка исключительности сетевых мотивов». Дж. Комп. Био . 15 (1): 1–20. CiteSeerX 10.1.1.475.4300 . дои : 10.1089/cmb.2007.0137 . ПМИД 18257674 .
- ↑ Перейти обратно: Перейти обратно: а б с Шрайбер Ф., Швеббермейер Х (2005). «Концепции частоты и обнаружение закономерностей для анализа мотивов в сетях». Труды по вычислительной системной биологии III . Конспекты лекций по информатике. Том. 3737. стр. 89–104. CiteSeerX 10.1.1.73.1130 . дои : 10.1007/11599128_7 . ISBN 978-3-540-30883-6 .
- ^ Холланд, П.В., и Лейнхардт, С. (1974). Статистический анализ локальной структуры в социальных сетях. Рабочий документ № 44, Национальное бюро экономических исследований.
- ^ Холланд П. и Лейнхардт С. (1975). Статистический анализ локальных. Структура в социальных сетях. Социологическая методология, Дэвид Хейз, изд. Сан-Франциско: Джози-Басс.
- ^ Холланд, П.В., и Лейнхардт, С. (1976). Локальная структура в социальных сетях. Социологическая методология, 7, 1-45.
- ^ Холланд, П.В., и Лейнхардт, С. (1977). Метод обнаружения структуры социометрических данных. В социальных сетях (стр. 411-432). Академическая пресса.
- ↑ Перейти обратно: Перейти обратно: а б с Шен-Орр СС, Майло Р., Манган С., Алон У (май 2002 г.). «Сетевые мотивы в сети регуляции транскрипции Escherichia coli » . Нат. Жене . 31 (1): 64–8. дои : 10.1038/ng881 . ПМИД 11967538 . S2CID 2180121 .
- ^ Эйхенбергер П., Фудзита М., Дженсен С.Т. и др. (октябрь 2004 г.). «Программа транскрипции генов для одного дифференцирующегося типа клеток во время споруляции у Bacillus subtilis » . ПЛОС Биология . 2 (10): е328. дои : 10.1371/journal.pbio.0020328 . ПМК 517825 . ПМИД 15383836 .

- ^ Майло Р., Шен-Орр С., Ицковиц С., Каштан Н., Чкловский Д., Алон У. (октябрь 2002 г.). «Сетевые мотивы: простые строительные блоки сложных сетей». Наука . 298 (5594): 824–7. Бибкод : 2002Sci...298..824M . CiteSeerX 10.1.1.225.8750 . дои : 10.1126/science.298.5594.824 . ПМИД 12399590 . S2CID 9884096 .
- ^ Ли Т.И., Ринальди, Нью-Джерси, Роберт Ф. и др. (октябрь 2002 г.). «Сети регуляции транскрипции у Saccharomyces cerevisiae». Наука . 298 (5594): 799–804. Бибкод : 2002Sci...298..799L . дои : 10.1126/science.1075090 . ПМИД 12399584 . S2CID 4841222 .
- ^ Одом Д.Т., Зизлспергер Н., Гордон Д.Б. и др. (февраль 2004 г.). «Контроль экспрессии генов поджелудочной железы и печени с помощью факторов транскрипции HNF» . Наука . 303 (5662): 1378–81. Бибкод : 2004Sci...303.1378O . дои : 10.1126/science.1089769 . ПМК 3012624 . ПМИД 14988562 .
- ↑ Перейти обратно: Перейти обратно: а б Бойер Л.А., Ли Т.И., Коул М.Ф. и др. (сентябрь 2005 г.). «Основная схема регуляции транскрипции в эмбриональных стволовых клетках человека» . Клетка . 122 (6): 947–56. дои : 10.1016/j.cell.2005.08.020 . ПМК 3006442 . ПМИД 16153702 .
- ^ Иранфар Н., Фуллер Д., Лумис В.Ф. (февраль 2006 г.). «Транскрипционная регуляция генов постагрегации в Dictyostelium с помощью петли прямой связи с участием GBF и LagC» . Дев. Биол . 290 (2): 460–9. дои : 10.1016/j.ydbio.2005.11.035 . ПМИД 16386729 .
- ^ Мааян А., Дженкинс С.Л., Невес С. и др. (август 2005 г.). «Формирование регуляторных закономерностей при распространении сигнала в сотовой сети млекопитающих» . Наука . 309 (5737): 1078–83. Бибкод : 2005Sci...309.1078M . дои : 10.1126/science.1108876 . ПМК 3032439 . ПМИД 16099987 .
- ^ Птачек Дж., Девган Г., Мишо Дж. и др. (декабрь 2005 г.). «Глобальный анализ фосфорилирования белков у дрожжей» (PDF) . Природа (Представлена рукопись). 438 (7068): 679–84. Бибкод : 2005Natur.438..679P . дои : 10.1038/nature04187 . ПМИД 16319894 . S2CID 4332381 .
- ^ «Accc-Motif: ускоренное обнаружение мотивов» .
- ^ Шрайбер Ф., Швоббермейер Х (2005). «МАВисто: инструмент для исследования сетевых мотивов» . Биоинформатика . 21 (17): 3572–3574. doi : 10.1093/биоинформатика/bti556 . ПМИД 16020473 .
- ↑ Перейти обратно: Перейти обратно: а б с Маккей Б.Д. (1981). «Практический изоморфизм графов». Конгресс графов . 30 : 45–87. arXiv : 1301.1493 . Бибкод : 2013arXiv1301.1493M .
- ↑ Перейти обратно: Перейти обратно: а б с Маккей Б.Д. (1998). «Исчерпывающее поколение без изоморфов». Журнал алгоритмов . 26 (2): 306–324. дои : 10.1006/jagm.1997.0898 .
- ↑ Перейти обратно: Перейти обратно: а б Чен Дж., Сюй В., Ли Ли М. и др. (2006). NeMoFinder: анализ полногеномных белок-белковых взаимодействий с помощью сетевых мотивов мезомасштаба . 12-я международная конференция ACM SIGKDD по открытию знаний и интеллектуальному анализу данных. Филадельфия, Пенсильвания, США. стр. 106–115.
- ^ Хуан Дж., Ван В., Принс Дж. и др. (2004). SPIN: извлечение максимально частых подграфов из графовых баз данных . 10-я международная конференция ACM SIGKDD по открытию знаний и интеллектуальному анализу данных. стр. 581–586.
- ^ Уетц П., Гиот Л., Кэгни Г. и др. (2000). «Комплексный анализ белок-белковых взаимодействий у Saccharomyces cerevisiae». Природа . 403 (6770): 623–627. Бибкод : 2000Natur.403..623U . дои : 10.1038/35001009 . ПМИД 10688190 . S2CID 4352495 .
- ↑ Перейти обратно: Перейти обратно: а б с д Грохов Дж. А., Келлис М. (2007). Обнаружение сетевых мотивов с использованием перечисления подграфов и нарушения симметрии (PDF) . РЕКОМБ. стр. 92–106. дои : 10.1007/978-3-540-71681-5_7 .
- ↑ Перейти обратно: Перейти обратно: а б Грохов Ю.А. (2006). О структуре и эволюции сетей взаимодействия белков (PDF) . Диссертация магистра инженерных наук, Массачусетский технологический институт, факультет электротехники и информатики.
- ↑ Перейти обратно: Перейти обратно: а б с Алон Н; Дао П; Хаджирасулиха I; Хормоздиари Ф; Сахинальп СК (2008 г.). «Подсчет и обнаружение мотивов биомолекулярной сети с помощью цветового кодирования» . Биоинформатика . 24 (13): i241–i249. doi : 10.1093/биоинформатика/btn163 . ПМЦ 2718641 . ПМИД 18586721 .
- ↑ Перейти обратно: Перейти обратно: а б с д и Омиди С., Шрайбер Ф., Масуди-Нежад А. (2009). «MODA: эффективный алгоритм обнаружения сетевых мотивов в биологических сетях» . Гены Генет Сист . 84 (5): 385–395. дои : 10.1266/ggs.84.385 . ПМИД 20154426 .
- ^ Барабаси А.Л., Альберт Р. (1999). «Появление масштабирования в случайных сетях». Наука . 286 (5439): 509–512. arXiv : cond-mat/9910332 . Бибкод : 1999Sci...286..509B . дои : 10.1126/science.286.5439.509 . ПМИД 10521342 . S2CID 524106 .
- ^ Васкес А., Добрин Р., Серхи Д. и др. (2004). «Топологическая связь между крупномасштабными атрибутами и моделями локального взаимодействия сложных сетей» . ПНАС . 101 (52): 17940–17945. arXiv : cond-mat/0408431 . Бибкод : 2004PNAS..10117940V . дои : 10.1073/pnas.0406024101 . ПМК 539752 . ПМИД 15598746 .
- ↑ Перейти обратно: Перейти обратно: а б с д Кашани З.Р., Ахрабиан Х., Элахи Э., Новзари-Далини А., Ансари Э.С., Асади С., Мохаммади С., Шрайбер Ф., Масуди-Неджад А. (2009). «Кавош: новый алгоритм поиска сетевых мотивов» . БМК Биоинформатика . 10 (318): 318. дои : 10.1186/1471-2105-10-318 . ПМК 2765973 . ПМИД 19799800 .
- ^ Али Масуди-Нежад; Митра Анасариола; Али Салехзаде-Язди; Саханд Хакабимамагани (2012). «CytoKavosh: плагин Cytoscape для поиска сетевых мотивов в больших биологических сетях» . ПЛОС ОДИН . 7 (8): е43287. Бибкод : 2012PLoSO...743287M . дои : 10.1371/journal.pone.0043287 . ПМЦ 3430699 . ПМИД 22952659 .
- ↑ Перейти обратно: Перейти обратно: а б с д Рибейро П., Сильва Ф (2010). G-Tries: эффективная структура данных для обнаружения сетевых мотивов . 25-й симпозиум ACM по прикладным вычислениям - трек биоинформатики. Сьерре, Швейцария. стр. 1559–1566.
- ^ Мбадиве, Сомадина; Ким, Уён (ноябрь 2017 г.). «ParaMODA: Улучшение поиска шаблонов подграфов, ориентированных на мотивы, в сетях PPI» . Международная конференция IEEE по биоинформатике и биомедицине (BIBM) , 2017 г. стр. 1723–1730. дои : 10.1109/BIBM.2017.8217920 . ISBN 978-1-5090-3050-7 . S2CID 5806529 . Архивировано из оригинала 4 февраля 2023 г. Проверено 11 сентября 2020 г.
- ^ «NemoMap: Улучшенный алгоритм обнаружения сетевых мотивов, ориентированный на мотивы» . Журнал «Достижения науки, технологий и инженерных систем» . 2018. Архивировано из оригинала 4 февраля 2023 г. Проверено 11 сентября 2020 г.
- ^ Патра, Сабьясачи; Мохапатра, Анджали (2020). «Обзор инструментов и алгоритмов обнаружения сетевых мотивов в биологических сетях» . ИЭПП Системная биология . 14 (4): 171–189. дои : 10.1049/iet-syb.2020.0004 . ISSN 1751-8849 . ПМЦ 8687426 . ПМИД 32737276 .
- ↑ Перейти обратно: Перейти обратно: а б Бабу М.М., Ласкомб Н.М., Аравинд Л., Герштейн М., Тейхманн С.А. (июнь 2004 г.). «Структура и эволюция сетей регуляции транскрипции». Современное мнение в области структурной биологии . 14 (3): 283–91. CiteSeerX 10.1.1.471.9692 . дои : 10.1016/j.sbi.2004.05.004 . ПМИД 15193307 .
- ↑ Перейти обратно: Перейти обратно: а б Конант Г.К., Вагнер А. (июль 2003 г.). «Конвергентная эволюция генных цепей». Нат. Жене . 34 (3): 264–6. дои : 10.1038/ng1181 . ПМИД 12819781 . S2CID 959172 .
- ^ Декель Э., Алон У (июль 2005 г.). «Оптимальность и эволюционная настройка уровня экспрессии белка». Природа . 436 (7050): 588–92. Бибкод : 2005Natur.436..588D . дои : 10.1038/nature03842 . ПМИД 16049495 . S2CID 2528841 .
- ^ Забет Н.Р. (сентябрь 2011 г.). «Отрицательная обратная связь и физические ограничения генов». Журнал теоретической биологии . 284 (1): 82–91. arXiv : 1408.1869 . Бибкод : 2011JThBi.284...82Z . CiteSeerX 10.1.1.759.5418 . дои : 10.1016/j.jtbi.2011.06.021 . ПМИД 21723295 . S2CID 14274912 .
- ^ Розенфельд Н., Еловиц М.Б., Алон У. (ноябрь 2002 г.). «Негативная ауторегуляция ускоряет время отклика сетей транскрипции». Дж. Мол. Биол . 323 (5): 785–93. CiteSeerX 10.1.1.126.2604 . дои : 10.1016/S0022-2836(02)00994-4 . ПМИД 12417193 .
- ^ Камас Ф.М., Бласкес Х., Поятос Х.Ф. (август 2006 г.). «Аутогенный и неаутогенный контроль ответа в генетической сети» . Учеб. Натл. акад. наук. США . 103 (34): 12718–23. Бибкод : 2006PNAS..10312718C . дои : 10.1073/pnas.0602119103 . ПМЦ 1568915 . ПМИД 16908855 .
- ^ Беккей А., Серрано Л. (июнь 2000 г.). «Инженерная стабильность генных сетей путем авторегуляции». Природа . 405 (6786): 590–3. Бибкод : 2000Natur.405..590B . дои : 10.1038/35014651 . ПМИД 10850721 . S2CID 4407358 .
- ^ Дубланш И., Михалодимитракис К., Кюммерер Н., Фольерини М., Серрано Л. (2006). «Шум в петлях отрицательной обратной связи транскрипции: моделирование и экспериментальный анализ» . Мол. Сист. Биол . 2 (1): 41. дои : 10.1038/msb4100081 . ПМК 1681513 . ПМИД 16883354 .
- ^ Шимога В., Уайт Дж., Ли Ю., Зонтаг Э., Блерис Л. (2013). «Синтетическая негативная ауторегуляция трансгена млекопитающих» . Мол. Сист. Биол . 9 : 670. дои : 10.1038/msb.2013.27 . ПМЦ 3964311 . ПМИД 23736683 .
- ^ Маэда Ю.Т., Сано М. (июнь 2006 г.). «Регуляторная динамика синтетических генных сетей с положительной обратной связью». Дж. Мол. Биол . 359 (4): 1107–24. дои : 10.1016/j.jmb.2006.03.064 . ПМИД 16701695 .
- ^ Беккей А., Серафин Б., Серрано Л. (май 2001 г.). «Положительная обратная связь в генных сетях эукариот: дифференцировка клеток путем преобразования ступенчатого ответа в бинарный» . ЭМБО Дж . 20 (10): 2528–35. дои : 10.1093/emboj/20.10.2528 . ПМК 125456 . ПМИД 11350942 .
- ↑ Перейти обратно: Перейти обратно: а б с Манган С., Алон У (октябрь 2003 г.). «Структура и функция мотива сети петли прямой связи» . Учеб. Натл. акад. наук. США . 100 (21): 11980–5. Бибкод : 2003PNAS..10011980M . дои : 10.1073/pnas.2133841100 . ПМК 218699 . ПМИД 14530388 .
- ^ Ма Х.В., Кумар Б., Дитжес У., Ганзер Ф., Буер Дж., Зенг А.П. (2004). «Расширенная сеть регуляции транскрипции Escherichia coli и анализ ее иерархической структуры и сетевых мотивов» . Нуклеиновые кислоты Рез . 32 (22): 6643–9. дои : 10.1093/nar/gkh1009 . ПМЦ 545451 . ПМИД 15604458 .
- ^ Манган С., Заславер А., Алон У. (ноябрь 2003 г.). «Когерентная петля прямой связи служит чувствительным к знаку элементом задержки в сетях транскрипции». Дж. Мол. Биол . 334 (2): 197–204. CiteSeerX 10.1.1.110.4629 . дои : 10.1016/j.jmb.2003.09.049 . ПМИД 14607112 .
- ^ Калир С., Манган С., Алон У. (2005). «Когерентный цикл прямой связи с функцией ввода SUM продлевает экспрессию жгутиков в Escherichia coli » . Мол. Сист. Биол . 1 (1): Е1–Е6. дои : 10.1038/msb4100010 . ПМК 1681456 . ПМИД 16729041 .
- ^ Сюн, Кун; Ланкастер, Алекс К.; Сигал, Марк Л.; Мазель, Джоанна (3 июня 2019 г.). «При наличии собственного шума регулирование с упреждением адаптивно развивается через динамику, а не топологию» . Природные коммуникации . 10 (1): 2418. Бибкод : 2019NatCo..10.2418X . дои : 10.1038/s41467-019-10388-6 . ПМК 6546794 . ПМИД 31160574 .
- ^ Манган С., Ицковиц С., Заславер А., Алон У. (март 2006 г.). «Некогерентная петля прямой связи ускоряет время реакции гал-системы Escherichia coli ». Дж. Мол. Биол . 356 (5): 1073–81. CiteSeerX 10.1.1.184.8360 . дои : 10.1016/j.jmb.2005.12.003 . ПМИД 16406067 .
- ^ Энтус Р., Ауфдерхайде Б., Сауро Х.М. (август 2007 г.). «Разработка и реализация трех датчиков биологической концентрации на основе некогерентных мотивов прямой связи» . Сист Синт Биол . 1 (3): 119–28. дои : 10.1007/s11693-007-9008-6 . ПМК 2398716 . ПМИД 19003446 .
- ^ Каплан С., Брен А., Декель Э., Алон У. (2008). «Некогерентный цикл прямой связи может генерировать немонотонные входные функции для генов» . Мол. Сист. Биол . 4 (1): 203. doi : 10.1038/msb.2008.43 . ПМК 2516365 . ПМИД 18628744 .
- ↑ Перейти обратно: Перейти обратно: а б Блерис Л., Се З., Гласс Д., Ададей А., Зонтаг Э., Бененсон Ю. (2011). «Синтетические некогерентные цепи прямой связи демонстрируют адаптацию к объему своего генетического шаблона» . Мол. Сист. Биол . 7 (1): 519. doi : 10.1038/msb.2011.49 . ПМК 3202791 . ПМИД 21811230 .
- ^ Сюн, Кун; Герштейн, Марк; Мазель, Джоанна (5 ноября 2021 г.). «Различия в эволюционной доступности определяют, какой одинаково эффективный регуляторный мотив развивается для генерации импульсов» . Генетика . 219 (3): ияб140. дои : 10.1093/генетика/iyab140 . ПМЦ 8570775 . ПМИД 34740240 .
- ^ Калир С., МакКлюр Дж., Паббараджу К. и др. (июнь 2001 г.). «Упорядочение генов в пути жгутиков путем анализа кинетики экспрессии живых бактерий». Наука . 292 (5524): 2080–3. дои : 10.1126/science.1058758 . ПМИД 11408658 . S2CID 14396458 .
- ^ Заславер А., Мэйо А.Е., Розенберг Р. и др. (май 2004 г.). «Программа срочной транскрипции метаболических путей» . Нат. Жене . 36 (5): 486–91. дои : 10.1038/ng1348 . ПМИД 15107854 .
- ^ Конагурту А.С., Леск А.М. (2008). «Одиночные и множественные модули ввода в регулирующих сетях». Белки . 73 (2): 320–324. дои : 10.1002/prot.22053 . ПМИД 18433061 . S2CID 35715566 .
- ^ Каплан С., Брен А., Заславер А., Декель Э., Алон У. (март 2008 г.). «Разнообразные двумерные функции ввода контролируют гены бактериального сахара» . Мол. Клетка . 29 (6): 786–92. doi : 10.1016/j.molcel.2008.01.021 . ПМК 2366073 . ПМИД 18374652 .
- ^ Чечик Г., О Э, Рандо О, Вайсман Дж, Регев А, Коллер Д (ноябрь 2008 г.). «Мотивы активности раскрывают принципы синхронизации транскрипционного контроля метаболической сети дрожжей» . Нат. Биотехнология . 26 (11): 1251–9. дои : 10.1038/nbt.1499 . ПМК 2651818 . ПМИД 18953355 .
- ^ Ингрэм П.Дж., Штумпф, член парламента, Старк Дж. (2006). «Сетевые мотивы: структура не определяет функцию» . БМК Геномика . 7 :108. дои : 10.1186/1471-2164-7-108 . ПМЦ 1488845 . ПМИД 16677373 .
- ^ Фойгт К.А., Вольф Д.М., Аркин А.П. (март 2005 г.). « Оперон греха Bacillus subtilis : развивающийся сетевой мотив» . Генетика . 169 (3): 1187–202. doi : 10.1534/genetics.104.031955 . ПМЦ 1449569 . ПМИД 15466432 . Архивировано из оригинала 4 февраля 2023 г. Проверено 26 февраля 2011 г.
- ^ Кнабе Ю.Ф., Неханив К.Л., Шилстра М.Ю. (2008). «Отражают ли мотивы развившуюся функцию? - Нет конвергентной эволюции топологий подграфов генетической регуляторной сети». БиоСистемы . 94 (1–2): 68–74. Бибкод : 2008BiSys..94...68K . doi : 10.1016/j.biosystems.2008.05.012 . ПМИД 18611431 .
- ^ Тейлор Д., Рестрепо Дж.Г. (2011). «Сетевое подключение во время слияний и роста: оптимизация добавления модуля». Физический обзор E . 83 (6): 66112. arXiv : 1102.4876 . Бибкод : 2011PhRvE..83f6112T . дои : 10.1103/PhysRevE.83.066112 . ПМИД 21797446 . S2CID 415932 .
- ^ Конагурту, Арун С.; Леск, Артур М. (23 апреля 2008 г.). «Одиночные и множественные модули ввода в регулирующих сетях». Белки: структура, функции и биоинформатика . 73 (2): 320–324. дои : 10.1002/prot.22053 . ПМИД 18433061 . S2CID 35715566 .
- ^ Конагурту А.С., Леск А.М. (2008). «О происхождении закономерностей распределения мотивов в биологических сетях» . BMC Сист Биол . 2:73 . doi : 10.1186/1752-0509-2-73 . ПМЦ 2538512 . ПМИД 18700017 .
Внешние ссылки [ править ]
- Программный инструмент, который может обнаруживать сетевые мотивы
- СЕТЕВЫЕ МОТИВЫ биофизики-вики
- FANMOD: инструмент для быстрого обнаружения сетевых мотивов
- MAVisto: инструмент анализа и визуализации сетевых мотивов
- НеМоФиндер
- Грочоу – Келлис
- МОДА
- Кавош
- ЦитоКавош
- G-Попытки
- инструмент обнаружения Acc-MOTIF