Алгоритм ожидания-максимизации
В статистике ожидания -максимизации ( EM ) алгоритм — это итерационный метод поиска (локальной) максимальной правдоподобия или максимальной апостериорной (MAP) оценки параметров в статистических моделях , где модель зависит от ненаблюдаемых скрытых переменных . [1] Итерация EM чередуется между выполнением шага ожидания (E), который создает функцию для ожидания логарифмического правдоподобия , оцениваемого с использованием текущей оценки параметров, и шага максимизации (M), который вычисляет параметры, максимизирующие ожидаемый логарифм. вероятность найдена на E. шаге Эти оценки параметров затем используются для определения распределения скрытых переменных на следующем этапе E. Его можно использовать, например, для оценки смеси гауссиан или для решения задачи множественной линейной регрессии. [2]

История
[ редактировать ]Алгоритм EM был объяснен и получил свое название в классической статье 1977 года Артура Демпстера , Нэн Лэрд и Дональда Рубина . [3] Они отметили, что этот метод «много раз предлагался в особых обстоятельствах» более ранними авторами. Одним из первых является метод подсчета генов для оценки частот аллелей Седрика Смита . [4] Другой был предложен Х. О. Хартли в 1958 году, а также Хартли и Хокингом в 1977 году, из которого возникли многие идеи в статье Демпстера-Лэрда-Рубина. [5] Еще один, сделанный С. К. Нг, Триямбакамом Кришнаном и Г. Дж. Маклахланом в 1977 году. [6] Идеи Хартли можно распространить на любое сгруппированное дискретное распределение. Очень подробное описание метода EM для экспоненциальных семейств было опубликовано Рольфом Сундбергом в его диссертации и нескольких статьях: [7] [8] [9] после его сотрудничества с Пером Мартином-Лёфом и Андерсом Мартином-Лёфом . [10] [11] [12] [13] [14] В статье Демпстера-Лэрда-Рубина 1977 года был обобщен метод и набросан анализ сходимости для более широкого класса задач. В статье Демпстера-Лэрда-Рубина ЭМ-метод стал важным инструментом статистического анализа. См. также Мэн и ван Дайк (1997).
Анализ сходимости алгоритма Демпстера-Лэрда-Рубина был ошибочным, и правильный анализ сходимости был опубликован CF Jeff Wu в 1983 году. [15] Доказательство Ву установило сходимость метода EM также за пределами экспоненциального семейства , как утверждал Демпстер-Лэрд-Рубин. [15]
Введение
[ редактировать ]Алгоритм EM используется для поиска (локальных) максимального правдоподобия параметров статистической модели в тех случаях, когда уравнения не могут быть решены напрямую. Обычно эти модели включают в себя скрытые переменные в дополнение к неизвестным параметрам и известным данным наблюдений. То есть либо среди данных существуют пропущенные значения , либо модель можно сформулировать более просто, предположив существование дополнительных ненаблюдаемых точек данных. Например, модель смеси можно описать проще, если предположить, что каждая наблюдаемая точка данных имеет соответствующую ненаблюдаемую точку данных или скрытую переменную, определяющую компонент смеси, которому принадлежит каждая точка данных.
Для поиска решения максимального правдоподобия обычно требуется взять производные по функции правдоподобия всем неизвестным значениям, параметрам и скрытым переменным и одновременно решить полученные уравнения. В статистических моделях со скрытыми переменными это обычно невозможно. Вместо этого результатом обычно является набор взаимосвязанных уравнений, в которых для решения параметров требуются значения скрытых переменных и наоборот, но замена одного набора уравнений в другой приводит к неразрешимому уравнению.
Алгоритм EM исходит из наблюдения, что существует способ численного решения этих двух наборов уравнений. Можно просто выбрать произвольные значения для одного из двух наборов неизвестных, использовать их для оценки второго набора, затем использовать эти новые значения для нахождения лучшей оценки первого набора, а затем продолжать чередовать эти два набора до тех пор, пока оба полученных значения не будут получены. сходятся к неподвижным точкам. Не очевидно, что это сработает, но это можно доказать в данном контексте. Кроме того, можно доказать, что производная вероятности равна (сколь угодно близкой) нулю в этой точке, что, в свою очередь, означает, что эта точка является либо локальным максимумом, либо седловой точкой . [15] Как правило, может возникнуть несколько максимумов, без гарантии того, что будет найден глобальный максимум. Некоторые вероятности также имеют особенности , т. е. бессмысленные максимумы. Например, одно из решений , которое может быть найдено с помощью EM в модели смеси, включает установку одного из компонентов с нулевой дисперсией, а средний параметр для того же компонента должен быть равен одной из точек данных.
Описание
[ редактировать ]Символы
[ редактировать ]Учитывая статистическую модель , которая генерирует набор наблюдаемых данных, набора ненаблюдаемых скрытых данных или отсутствующих значений , и вектор неизвестных параметров , а также функция правдоподобия , оценка максимального правдоподобия (MLE) неизвестных параметров определяется путем максимизации предельного правдоподобия наблюдаемых данных.





Однако эта величина часто не поддается измерению, поскольку не наблюдается, а распространение неизвестно до достижения .
Алгоритм EM
[ редактировать ]Алгоритм EM пытается найти оценку максимального правдоподобия предельного правдоподобия, итеративно применяя эти два шага:
- Шаг ожидания (шаг E) : Определите как ожидаемое значение логарифмической функции правдоподобия , относительно текущего условного распределения данный и текущие оценки параметров :


![{\displaystyle Q({\boldsymbol {\theta }}\mid {\boldsymbol {\theta }}^{(t)})=\operatorname {E} _ {\mathbf {Z} \sim p(\cdot | \mathbf {X}, {\boldsymbol {\theta }}^{(t)})}\left[\log p(\mathbf {X},\mathbf {Z} |{\boldsymbol {\theta }}) \верно]\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ceb93467728ae61d8611ec69c73ca0dc3a89dbd9)
- Шаг максимизации (шаг M) : Найдите параметры, которые максимизируют эту величину:

Более кратко мы можем записать это в виде одного уравнения:
![{\displaystyle {\boldsymbol {\theta }}^{(t+1)}={\underset {\boldsymbol {\theta }}{\operatorname {arg\,max} }}\operatorname {E} _{\ mathbf {Z} \sim p(\cdot |\mathbf {X} , {\boldsymbol {\theta }}^{(t)})}\left[\log p(\mathbf {X} ,\mathbf {Z } |{\boldsymbol {\theta }})\right]\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02e39e41a9408b3c868929e556216402e17bef76)
Интерпретация переменных
[ редактировать ]Типичные модели, к которым применяется ЭМ, используют как скрытая переменная, указывающая принадлежность к одной из множества групп:
- Наблюдаемые точки данных может быть дискретным (принимающим значения из конечного или счетно-бесконечного множества) или непрерывным (принимающим значения из несчетно-бесконечного множества). С каждой точкой данных может быть связан вектор наблюдений.
- ( Недостающие значения они же скрытые переменные ) являются дискретными , взятыми из фиксированного числа значений и с одной скрытой переменной на наблюдаемую единицу.
- Параметры являются непрерывными и бывают двух видов: параметры, связанные со всеми точками данных, и параметры, связанные с конкретным значением скрытой переменной (т. е. связанные со всеми точками данных, чья соответствующая скрытая переменная имеет это значение).
Однако ЭМ можно применить и к другим типам моделей.
Мотивация следующая. Если значение параметров известно, обычно значение скрытых переменных может быть найден путем максимизации логарифмического правдоподобия по всем возможным значениям , либо просто перебирая или с помощью такого алгоритма, как алгоритм Витерби для скрытых моделей Маркова . И наоборот, если мы знаем значение скрытых переменных , мы можем найти оценку параметров довольно легко, обычно просто группируя наблюдаемые точки данных в соответствии со значением связанной скрытой переменной и усредняя значения или некоторую функцию значений точек в каждой группе. Это предполагает итерационный алгоритм в случае, когда оба и неизвестны:
- Сначала инициализируем параметры некоторым случайным значениям.
- Вычислите вероятность каждого возможного значения , данный .
- Затем используйте только что вычисленные значения чтобы вычислить лучшую оценку параметров .
- Повторяйте шаги 2 и 3 до сходимости.
Только что описанный алгоритм монотонно приближается к локальному минимуму функции стоимости.
Характеристики
[ редактировать ]Хотя EM-итерация действительно увеличивает функцию правдоподобия наблюдаемых данных (т. е. предельную), не существует никакой гарантии, что последовательность сходится к оценщику максимального правдоподобия . Для мультимодальных распределений это означает, что алгоритм EM может сходиться к локальному максимуму наблюдаемой функции правдоподобия данных, в зависимости от начальных значений. Существуют различные эвристические или метаэвристические подходы, позволяющие избежать локального максимума, такие как восхождение на холм со случайным перезапуском (начиная с нескольких различных случайных начальных оценок). ), или применяя методы имитации отжига .
ЭМ особенно полезна, когда вероятность представляет собой экспоненциальное семейство . Подробную трактовку см. в Sundberg (2019, Ch. 8): [16] шаг E становится суммой ожиданий достаточной статистики , а шаг M включает максимизацию линейной функции. В таком случае обычно можно получить обновления выражений в закрытой форме для каждого шага, используя формулу Сундберга. [17] (доказано и опубликовано Рольфом Сундбергом на основе неопубликованных результатов Пера Мартина-Лёфа и Андерса Мартина-Лёфа ). [8] [9] [11] [12] [13] [14]
Метод EM был модифицирован для вычисления максимальных апостериорных оценок (MAP) для байесовского вывода в оригинальной статье Демпстера, Лэрда и Рубина.
Существуют и другие методы для поиска оценок максимального правдоподобия, такие как градиентный спуск , сопряженный градиент или варианты алгоритма Гаусса-Ньютона . В отличие от ЭМ, такие методы обычно требуют оценки первых и/или вторых производных функции правдоподобия.
Доказательство правильности
[ редактировать ]Ожидание-максимизация работает на улучшение а не непосредственно улучшать . Здесь показано, что улучшение первого влечет за собой улучшение второго. [18]

Для любого с ненулевой вероятностью , мы можем написать


Мы берем математическое ожидание по возможным значениям неизвестных данных при текущей оценке параметров умножив обе части на и суммирование (или интегрирование) по . Левая часть — это математическое ожидание константы, поэтому мы получаем:



где определяется отрицательной суммой, которую она заменяет.Последнее уравнение справедливо для любого значения включая ,



и вычитание этого последнего уравнения из предыдущего уравнения дает

Однако неравенство Гиббса говорит нам, что , поэтому мы можем заключить, что


Словом, выбирая улучшить причины улучшиться хотя бы на столько же.
Как процедура максимизации-максимизации
[ редактировать ]Алгоритм EM можно рассматривать как два чередующихся шага максимизации, то есть как пример координатного спуска . [19] [20] Рассмотрим функцию:
![{\displaystyle F(q,\theta):=\operatorname {E} _{q}[\log L(\theta;x,Z)]+H(q),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4e0798985f246154015deb375e1494dfa734922)
где q — произвольное распределение вероятностей по ненаблюдаемым данным z , а H(q) — энтропия распределения q . Эту функцию можно записать как

где - условное распределение ненаблюдаемых данных с учетом наблюдаемых данных и – расходимость Кульбака–Лейблера .



Тогда шаги алгоритма EM можно рассматривать как:
- Шаг ожидания : Выберите максимизировать :
- Шаг максимизации : выберите максимизировать :





Приложения
[ редактировать ]- EM часто используется для оценки параметров смешанных моделей . [21] [22] особенно в количественной генетике . [23]
- В психометрии ЭМ является важным инструментом для оценки параметров заданий и скрытых способностей моделей теории ответов на задания .
- Благодаря способности работать с недостающими данными и наблюдать неопознанные переменные, EM становится полезным инструментом для оценки и управления рисками портфеля. [ нужна ссылка ]
- Алгоритм EM (и его более быстрый вариант максимизации ожидания упорядоченного подмножества ) также широко используется в медицинских изображений реконструкции , особенно в позитронно-эмиссионной томографии , однофотонной эмиссионной компьютерной томографии и рентгеновской компьютерной томографии . Ниже приведены другие более быстрые варианты EM.
- В структурном проектировании используется структурная идентификация с использованием максимизации ожиданий (STRIDE). [24] Алгоритм представляет собой метод только для вывода для определения свойств собственных колебаний структурной системы с использованием данных датчиков (см. Операционный модальный анализ ).
- EM также используется для кластеризации данных . В обработке естественного языка двумя яркими примерами алгоритма являются алгоритм Баума-Уэлча для скрытых моделей Маркова и алгоритм внутри-вне для неконтролируемой индукции вероятностных контекстно-свободных грамматик .
- При анализе времени ожидания между сделками , т.е. времени между последующими сделками с акциями на фондовой бирже, алгоритм EM оказался очень полезным. [25]
Алгоритмы фильтрации и сглаживания EM
[ редактировать ]Фильтр Калмана обычно используется для оперативной оценки состояния, а сглаживатель минимальной дисперсии может использоваться для автономной или пакетной оценки состояния. Однако эти решения с минимальной дисперсией требуют оценок параметров модели в пространстве состояний. EM-алгоритмы могут использоваться для решения совместных задач оценки состояния и параметров.
Алгоритмы фильтрации и сглаживания EM возникают в результате повторения этой двухэтапной процедуры:
- E-шаг
- Используйте фильтр Калмана или сглаживатель минимальной дисперсии, разработанный с текущими оценками параметров, чтобы получить обновленные оценки состояния.
- М-шаг
- Используйте отфильтрованные или сглаженные оценки состояния в вычислениях максимального правдоподобия, чтобы получить обновленные оценки параметров.
Предположим, что фильтр Калмана или сглаживатель минимальной дисперсии работает с измерениями системы с одним входом и одним выходом, которая обладает аддитивным белым шумом. Обновленную оценку дисперсии шума измерения можно получить на основе максимального правдоподобия расчета .

где скалярные выходные оценки, рассчитанные с помощью фильтра или сглаживателя на основе N скалярных измерений . Вышеупомянутое обновление также можно применить для обновления интенсивности шума измерения Пуассона. Аналогично, для авторегрессионного процесса первого порядка обновленную оценку дисперсии шума процесса можно рассчитать по формуле



где и являются скалярными оценками состояния, рассчитанными с помощью фильтра или сглаживателя. Обновленная оценка коэффициента модели получается с помощью


Сходимость оценок параметров, подобных приведенным выше, хорошо изучена. [26] [27] [28] [29]
Варианты
[ редактировать ]Был предложен ряд методов для ускорения иногда медленной сходимости алгоритма EM, например, методы с использованием сопряженного градиента и модифицированные методы Ньютона (Ньютона – Рафсона). [30] Кроме того, EM можно использовать с методами оценки с ограничениями.
Алгоритм максимизации ожидания с расширенными параметрами (PX-EM) часто обеспечивает ускорение за счет «использования« ковариационной корректировки »для корректировки анализа шага M, используя дополнительную информацию, собранную в вмененных полных данных». [31]
Условная максимизация ожидания (ECM) заменяет каждый шаг M последовательностью шагов условной максимизации (CM), в которых каждый параметр θ i максимизируется индивидуально, при условии, что другие параметры остаются фиксированными. [32] Сам по себе может быть расширен до алгоритма условной максимизации ожидания (ECME) . [33]
Эта идея получила дальнейшее развитие в алгоритме максимизации обобщенного ожидания (GEM) , в котором ищется только увеличение целевой функции F как для шага E, так и для шага M, как описано в разделе «Процедура максимизации-максимизации» . [19] GEM развивается в распределенной среде и показывает многообещающие результаты. [34]
Также можно рассматривать алгоритм EM как подкласс алгоритма MM (Majorize/Minimize или Minorize/Maximize, в зависимости от контекста), [35] и поэтому использовать любую технику, разработанную в более общем случае.
алгоритм α-EM
[ редактировать ]Q-функция, используемая в алгоритме EM, основана на логарифмическом правдоподобии. Поэтому его называют логарифмическим алгоритмом EM. Использование логарифмического правдоподобия можно обобщить до использования отношения правдоподобия α-логарифма. Затем отношение правдоподобия α-log наблюдаемых данных можно точно выразить как равенство, используя Q-функцию отношения правдоподобия α-log и α-дивергенции. Получение этой Q-функции является обобщенным E-шагом. Его максимизация представляет собой обобщенный М-шаг. Эта пара называется алгоритмом α-EM. [36] который содержит алгоритм log-EM в качестве своего подкласса. Таким образом, алгоритм α-EM Ясуо Мацуямы является точным обобщением алгоритма log-EM. Никакого вычисления градиента или матрицы Гессе не требуется. α-EM показывает более быструю сходимость, чем алгоритм log-EM, за счет выбора подходящего α. Алгоритм α-EM приводит к более быстрой версии алгоритма оценки скрытой марковской модели α-HMM. [37]
Связь с вариационными методами Байеса
[ редактировать ]EM — частично небайесовский метод максимального правдоподобия. Его окончательный результат дает распределение вероятностей по скрытым переменным (в байесовском стиле) вместе с точечной оценкой θ (либо оценка максимального правдоподобия , либо апостериорная мода). Может потребоваться полностью байесовская версия этого подхода, дающая распределение вероятностей по θ и скрытым переменным. Байесовский подход к выводу заключается в том, чтобы просто рассматривать θ как еще одну скрытую переменную. В этой парадигме различие между этапами E и M исчезает. Если использовать факторизованное приближение Q, как описано выше ( вариационный Байес ), решение может перебирать каждую скрытую переменную (теперь включая θ ) и оптимизировать их по одной. Теперь k необходимо шагов на итерацию, где k — количество скрытых переменных. Для графических моделей это легко сделать, поскольку новое значение Q каждой переменной зависит только от ее марковского бланкета локальную передачу сообщений , поэтому для эффективного вывода можно использовать .
Геометрическая интерпретация
[ редактировать ]В информационной геометрии шаг E и шаг M интерпретируются как проекции при двойных аффинных связях , называемых e-связью и m-связью; Расхождение Кульбака – Лейблера также можно понимать в этих терминах.
Примеры
[ редактировать ]Гауссова смесь
[ редактировать ]
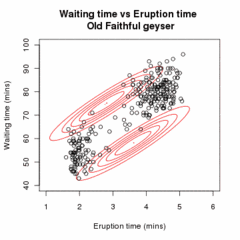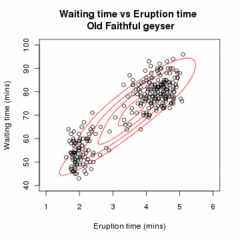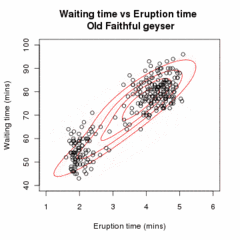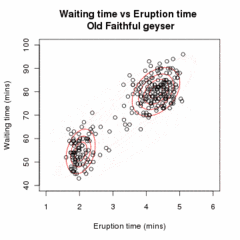
Позволять быть образцом независимые наблюдения на основе смеси двух многомерных нормальных распределений размерности , и пусть быть скрытыми переменными, которые определяют компонент, из которого происходит наблюдение. [20]




- и


где
- и


Цель состоит в том, чтобы оценить неизвестные параметры, представляющие значение смешивания между гауссианами, а также средние значения и ковариации каждого из них:

где функция правдоподобия неполных данных равна

а функция правдоподобия полных данных равна
![{\displaystyle L(\theta;\mathbf {x},\mathbf {z})=p(\mathbf {x},\mathbf {z} \mid \theta)=\prod _{i=1}^{ n}\prod _{j=1}^{2}\ [f(\mathbf {x} _{i};{\boldsymbol {\mu }}_{j},\Sigma _{j})\tau _{j}]^{\mathbb {I} (z_{i}=j)},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8992a646a56612c1c52a38302e6a84ccceeb949a)
или
![{\displaystyle L(\theta;\mathbf {x},\mathbf {z})=\exp \left\{\sum _{i=1}^{n}\sum _{j=1}^{2 }\mathbb {I} (z_{i}=j){\big [}\log \tau _{j}-{\tfrac {1}{2}}\log |\Sigma _{j}|-{ \tfrac {1}{2}}(\mathbf {x} _{i}-{\boldsymbol {\mu }}_{j})^{\top }\Sigma _{j}^{-1}( \mathbf {x} _{i}-{\boldsymbol {\mu }}_{j})-{\tfrac {d}{2}}\log(2\pi ){\big ]}\right\} ,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7c30db649a3d79fca184a9ba9485609ff6ddf62)
где является индикаторной функцией и — функция плотности вероятности многомерной нормальной.


В последнем равенстве для каждого i по одному показателю равен нулю, а один показатель равен единице. Таким образом, внутренняя сумма сводится к одному члену.

шаг Е
[ редактировать ]Учитывая нашу текущую оценку параметров θ ( т ) , условное распределение Z i определяется теоремой Байеса как пропорциональная высота нормальной плотности, взвешенная по τ :

Они называются «вероятностями членства», которые обычно считаются результатом шага E (хотя это не функция Q, показанная ниже).
Этот шаг E соответствует настройке этой функции для Q:
![{\displaystyle {\begin{aligned}Q(\theta \mid \theta ^{(t)})&=\operatorname {E} _ {\mathbf {Z} \mid \mathbf {X} =\mathbf {x } ;\mathbf {\theta } ^{(t)}}[\log L(\theta ;\mathbf {x} ,\mathbf {Z} )]\\&=\operatorname {E} _{\mathbf { Z} \mid \mathbf {X} =\mathbf {x} ;\mathbf {\theta } ^{(t)}}[\log \prod _{i=1}^{n}L(\theta ;\ mathbf {x} _{i},Z_{i})]\\&=\operatorname {E} _{\mathbf {Z} \mid \mathbf {X} =\mathbf {x} ;\mathbf {\theta } ^{(t)}}[\sum _{i=1}^{n}\log L(\theta ;\mathbf {x} _{i},Z_{i})]\\&=\sum _{i=1}^{n}\operatorname {E} _{Z_{i}\mid X_{i}=x_{i};\mathbf {\theta } ^{(t)}}[\log L (\theta ;\mathbf {x} _{i},Z_{i})]\\&=\sum _{i=1}^{n}\sum _{j=1}^{2}P( Z_{i}=j\mid X_{i}=\mathbf {x} _{i};\theta ^{(t)})\log L(\theta _{j};\mathbf {x} _{ i},j)\\&=\sum _{i=1}^{n}\sum _{j=1}^{2}T_{j,i}^{(t)}{\big [} \log \tau _{j}-{\tfrac {1}{2}}\log |\Sigma _{j}|-{\tfrac {1}{2}}(\mathbf {x} _{i} -{\boldsymbol {\mu }}_{j})^{\top }\Sigma _{j}^{-1}(\mathbf {x} _{i}-{\boldsymbol {\mu }}_ {j})-{\tfrac {d}{2}}\log(2\pi ){\big ]}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c4c12cc7f548a84bb750a77d2faf71cb6f06dfd4)
Ожидание внутри сумма берется по функции плотности вероятности , которые могут быть разными для каждого обучающего набора. Все, что содержится в шаге E, известно до его выполнения, за исключением , которое вычисляется согласно уравнению в начале раздела шага E.




Это полное условное ожидание не нужно вычислять за один шаг, поскольку τ и µ / Σ появляются в отдельных линейных терминах и, таким образом, могут быть максимизированы независимо.
М шаг
[ редактировать ]квадратичность по форме означает, что определение максимизирующих значений является относительно простым. Также, , и все они могут быть максимизированы независимо, поскольку все они представлены в отдельных линейных терминах.




Для начала рассмотрим , который имеет ограничение :

![{\displaystyle {\begin{aligned}{\boldsymbol {\tau }}^{(t+1)}&={\underset {\boldsymbol {\tau }}{\operatorname {arg\,max} }}\ Q(\theta \mid \theta ^{(t)})\\&={\underset {\boldsymbol {\tau }}{\operatorname {arg\,max} }}\ \left\{\left[\ sum _{i=1}^{n}T_{1,i}^{(t)}\right]\log \tau _{1}+\left[\sum _{i=1}^{n} T_{2,i}^{(t)}\right]\log \tau _{2}\right\}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3d2b6d3ae054fad990836865c545ef1d4f1fffd)
Это имеет ту же форму, что и оценка максимального правдоподобия для биномиального распределения , поэтому

Для следующих оценок :

Это имеет ту же форму, что и взвешенная оценка максимального правдоподобия для нормального распределения, поэтому
- и


и, по симметрии,
- и


Прекращение действия
[ редактировать ]Завершите итерационный процесс, если для ниже некоторого заданного порога.
![{\displaystyle E_{Z\mid \theta ^{(t)},\mathbf {x} }[\log L(\theta ^{(t)};\mathbf {x},\mathbf {Z})] \leq E_{Z\mid \theta ^{(t-1)},\mathbf {x} }[\log L(\theta ^{(t-1)};\mathbf {x} ,\mathbf {Z } )]+\varepsilon }](https://wikimedia.org/api/rest_v1/media/math/render/svg/1936cdfb30674d85c6029aed6c4b3e571300374b)

Обобщение
[ редактировать ]Проиллюстрированный выше алгоритм можно обобщить для смесей более чем двух многомерных нормальных распределений .
Усеченная и цензурированная регрессия
[ редактировать ]Алгоритм EM был реализован в случае, когда существует базовая модель линейной регрессии, объясняющая изменение некоторой величины, но фактически наблюдаемые значения представляют собой подвергнутые цензуре или усеченные версии представленных в модели. [38] Особые случаи этой модели включают цензурированные или усеченные наблюдения из одного нормального распределения . [38]
Альтернативы
[ редактировать ]EM обычно сходится к локальному оптимуму, а не обязательно к глобальному, без ограничений на скорость сходимости в целом. Возможно, что он может быть сколь угодно бедным в больших размерностях и может существовать экспоненциальное число локальных оптимумов. Следовательно, существует потребность в альтернативных методах гарантированного обучения, особенно в многомерных условиях. Существуют альтернативы EM с лучшими гарантиями последовательности, которые называются подходами, основанными на моменте. [39] или так называемые спектральные методы . [40] [41] Моментные подходы к изучению параметров вероятностной модели имеют такие гарантии, как глобальная конвергенция при определенных условиях, в отличие от EM, который часто сталкивается с проблемой застревания в локальных оптимумах. Алгоритмы с гарантиями обучения могут быть получены для ряда важных моделей, таких как смешанные модели, СММ и т. д. Для этих спектральных методов не возникает ложных локальных оптимумов, и истинные параметры могут быть последовательно оценены при некоторых условиях регулярности. [ нужна ссылка ] .
См. также
[ редактировать ]- распределение смеси
- сложное распределение
- оценка плотности
- Анализ главных компонентов
- спектроскопия полного поглощения
- Алгоритм EM можно рассматривать как частный случай алгоритма мажоризации-минимизации (MM) . [42]
Ссылки
[ редактировать ]- ^ Мэн, X.-L.; ван Дайк, Д. (1997). «ЭМ-алгоритм – старая народная песня, спетая на новую быструю мелодию» . Дж. Королевский статистик. Соц. Б. 59 (3): 511–567. дои : 10.1111/1467-9868.00082 . S2CID 17461647 .
- ^ Чонёль Квон, Константин Караманис Материалы двадцать третьей международной конференции по искусственному интеллекту и статистике , PMLR 108:1727-1736, 2020.
- ^ Демпстер, AP ; Лейрд, Нью-Мексико ; Рубин, Д.Б. (1977). «Максимальное правдоподобие на основе неполных данных с помощью алгоритма EM». Журнал Королевского статистического общества, серия B. 39 (1): 1–38. JSTOR 2984875 . МР 0501537 .
- ^ Цеппелини, РМ (1955). «Оценка частот генов в популяции случайных спариваний». Энн. Хм. Жене . 20 (2): 97–115. дои : 10.1111/j.1469-1809.1955.tb01360.x . ПМИД 13268982 . S2CID 38625779 .
- ^ Хартли, Герман Отто (1958). «Оценка максимального правдоподобия по неполным данным». Биометрия . 14 (2): 174–194. дои : 10.2307/2527783 . JSTOR 2527783 .
- ^ Нг, Шу Кей; Кришнан, Триямбакам; Маклахлан, Джеффри Дж. (21 декабря 2011 г.), «EM-алгоритм» , Справочник по вычислительной статистике , Берлин, Гейдельберг: Springer Berlin Heidelberg, стр. 139–172, doi : 10.1007/978-3-642-21551- 3_6 , ISBN 978-3-642-21550-6 , S2CID 59942212 , получено 15 октября 2022 г.
- ^ Сундберг, Рольф (1974). «Теория максимального правдоподобия для неполных данных из экспоненциального семейства». Скандинавский статистический журнал . 1 (2): 49–58. JSTOR 4615553 . МР 0381110 .
- ^ Перейти обратно: а б Рольф Сундберг. 1971. Теория максимального правдоподобия и приложения для распределений, генерируемых при наблюдении функции экспоненциальной переменной семейства . Диссертация, Институт математической статистики Стокгольмского университета.
- ^ Перейти обратно: а б Сундберг, Рольф (1976). «Итерационный метод решения уравнений правдоподобия для неполных данных из экспоненциальных семейств». Коммуникации в статистике – моделирование и вычисления . 5 (1): 55–64. дои : 10.1080/03610917608812007 . МР 0443190 .
- ↑ См. Благодарность Демпстера, Лэрда и Рубина на страницах 3, 5 и 11.
- ^ Перейти обратно: а б Пер Мартин-Лёф . 1966. Статистика с точки зрения статистической механики . Конспект лекций, Математический институт Орхусского университета. («Формула Сундберга», авторство принадлежит Андерсу Мартину-Лёфу).
- ^ Перейти обратно: а б Пер Мартин-Лёф . 1970. Статистические модели: конспекты семинаров 1969–1970 учебного года (конспекты лекций 1969–1970 гг.), при содействии Рольфа Сундберга. Стокгольмский университет.
- ^ Перейти обратно: а б Мартин-Лёф, П. Понятие избыточности и его использование в качестве количественной меры отклонения между статистической гипотезой и набором данных наблюдений. С обсуждением Ф. Абильдгарда, А. П. Демпстера , Д. Басу , Д. Р. Кокса , А. Ф. Эдвардса , Д. А. Спротта, Г. А. Барнарда , О. Барндорфа-Нильсена, Дж. Д. Калбфляйша и Г. Раша и ответа автора. Материалы конференции по фундаментальным вопросам статистического вывода (Орхус, 1973), стр. 1–42. Мемуары, № 1, Теор.-отд. Статист., Инт. Математика, унив. Орхус, Орхус, 1974 год.
- ^ Перейти обратно: а б Мартин-Лёф, Пер (1974). «Понятие избыточности и его использование в качестве количественной меры несоответствия между статистической гипотезой и набором данных наблюдений». Скан. Дж. Статист . 1 (1): 3–18.
- ^ Перейти обратно: а б с Ву, Джефф (март 1983 г.). «О свойствах сходимости алгоритма EM» . Анналы статистики . 11 (1): 95–103. дои : 10.1214/aos/1176346060 . JSTOR 2240463 . МР 0684867 .
- ^ Сундберг, Рольф (2019). Статистическое моделирование экспоненциальными семействами . Издательство Кембриджского университета. ISBN 9781108701112 .
- ^ Лэрд, Нэн (2006). «Формулы Сундберга» . Энциклопедия статистических наук . Уайли. дои : 10.1002/0471667196.ess2643.pub2 . ISBN 0471667196 .
- ^ Литтл, Родерик Дж.А.; Рубин, Дональд Б. (1987). Статистический анализ с отсутствующими данными . Ряд Уайли по вероятности и математической статистике. Нью-Йорк: Джон Уайли и сыновья. стр. 134–136 . ISBN 978-0-471-80254-9 .
- ^ Перейти обратно: а б Нил, Рэдфорд; Хинтон, Джеффри (1999). «Взгляд на алгоритм EM, который оправдывает инкрементные, разреженные и другие варианты». У Майкла И. Джордана (ред.). Обучение с помощью графических моделей (PDF) . Кембридж, Массачусетс: MIT Press. стр. 355–368. ISBN 978-0-262-60032-3 . Проверено 22 марта 2009 г.
- ^ Перейти обратно: а б Хасти, Тревор ; Тибширани, Роберт ; Фридман, Джером (2001). «8.5 Алгоритм EM». Элементы статистического обучения . Нью-Йорк: Спрингер. стр. 236–243 . ISBN 978-0-387-95284-0 .
- ^ Линдстрем, Мэри Дж; Бейтс, Дуглас М. (1988). «Алгоритмы Ньютона-Рафсона и EM для линейных моделей смешанных эффектов для данных повторных измерений». Журнал Американской статистической ассоциации . 83 (404): 1014. дои : 10.1080/01621459.1988.10478693 .
- ^ Ван Дайк, Дэвид А. (2000). «Подбор моделей со смешанными эффектами с использованием эффективных алгоритмов EM-типа». Журнал вычислительной и графической статистики . 9 (1): 78–98. дои : 10.2307/1390614 . JSTOR 1390614 .
- ^ Диффи, С.М.; Смит, А.Б.; Валлийский, А.Х; Каллис, Б.Р. (2017). «Новый EM-алгоритм REML (расширенный параметр) для линейных смешанных моделей» . Статистический журнал Австралии и Новой Зеландии . 59 (4): 433. doi : 10.1111/anzs.12208 . hdl : 1885/211365 .
- ^ Матараццо, ТиДжей, и Пакзад, С.Н. (2016). «STRIDE для структурной идентификации с использованием максимизации ожиданий: итерационный метод модальной идентификации, предназначенный только для вывода». Журнал инженерной механики. http://ascelibrary.org/doi/abs/10.1061/(ASCE)EM.1943-7889.0000951
- ^ Крир, Маркус; Кизилерсу, Айше; Томас, Энтони В. (2022). «Алгоритм максимизации цензурированного ожидания для смесей: применение ко времени ожидания между сделками» . Физика А: Статистическая механика и ее приложения . 587 (1): 126456. Бибкод : 2022PhyA..58726456K . дои : 10.1016/j.physa.2021.126456 . ISSN 0378-4371 . S2CID 244198364 .
- ^ Эйнике, Джорджия; Малос, Дж.Т.; Рид, округ Колумбия; Хейнсворт, Д.В. (январь 2009 г.). «Уравнение Риккати и сходимость алгоритма EM для выравнивания инерциальной навигации». IEEE Транс. Сигнальный процесс . 57 (1): 370–375. Бибкод : 2009ITSP...57..370E . дои : 10.1109/TSP.2008.2007090 . S2CID 1930004 .
- ^ Эйнике, Джорджия; Фалько, Г.; Малос, Дж.Т. (май 2010 г.). «Оценка матрицы состояния алгоритма EM для навигации». Письма об обработке сигналов IEEE . 17 (5): 437–440. Бибкод : 2010ISPL...17..437E . дои : 10.1109/ЛСП.2010.2043151 . S2CID 14114266 .
- ^ Эйнике, Джорджия; Фалько, Г.; Данн, Монтана; Рид, округ Колумбия (май 2012 г.). «Итеративная оценка дисперсии на основе сглаживания». Письма об обработке сигналов IEEE . 19 (5): 275–278. Бибкод : 2012ISPL...19..275E . дои : 10.1109/ЛСП.2012.2190278 . S2CID 17476971 .
- ^ Эйнике, Джорджия (сентябрь 2015 г.). «Итеративная фильтрация и сглаживание измерений, содержащих пуассоновский шум». Транзакции IEEE по аэрокосмическим и электронным системам . 51 (3): 2205–2011. Бибкод : 2015ITAES..51.2205E . дои : 10.1109/TAES.2015.140843 . S2CID 32667132 .
- ^ Джамшидиан, Мортаза; Дженнрих, Роберт И. (1997). «Ускорение алгоритма EM с использованием квазиньютоновских методов». Журнал Королевского статистического общества, серия B. 59 (2): 569–587. дои : 10.1111/1467-9868.00083 . МР 1452026 . S2CID 121966443 .
- ^ Лю, К. (1998). «Расширение параметров для ускорения EM: алгоритм PX-EM». Биометрика . 85 (4): 755–770. CiteSeerX 10.1.1.134.9617 . дои : 10.1093/biomet/85.4.755 .
- ^ Мэн, Сяо-Ли; Рубин, Дональд Б. (1993). «Оценка максимального правдоподобия с помощью алгоритма ECM: общая основа». Биометрика . 80 (2): 267–278. дои : 10.1093/биомет/80.2.267 . МР 1243503 . S2CID 40571416 .
- ^ Лю, Чуанхай; Рубин, Дональд Б. (1994). «Алгоритм ECME: простое расширение EM и ECM с более быстрой монотонной сходимостью». Биометрика . 81 (4): 633. doi : 10.1093/biomet/81.4.633 . JSTOR 2337067 .
- ^ Цзянтао Инь; Яньфэн Чжан; Лисинь Гао (2012). «Алгоритмы ускорения ожиданий – максимизации с частыми обновлениями» (PDF) . Материалы Международной конференции IEEE по кластерным вычислениям .
- ^ Хантер Д.Р. и Ланге К. (2004), Учебное пособие по алгоритмам ММ , Американский статистик, 58: 30–37.
- ^ Мацуяма, Ясуо (2003). «Алгоритм α-EM: суррогатная максимизация правдоподобия с использованием α-логарифмических информационных мер». Транзакции IEEE по теории информации . 49 (3): 692–706. дои : 10.1109/TIT.2002.808105 .
- ^ Мацуяма, Ясуо (2011). «Оценка скрытой марковской модели на основе алгоритма альфа-EM: дискретные и непрерывные альфа-HMM». Международная совместная конференция по нейронным сетям : 808–816.
- ^ Перейти обратно: а б Волынец, М.С. (1979). «Оценка максимального правдоподобия в линейной модели на основе ограниченных и подвергнутых цензуре нормальных данных». Журнал Королевского статистического общества, серия C. 28 (2): 195–206. дои : 10.2307/2346749 . JSTOR 2346749 .
- ^ Пирсон, Карл (1894). «Вклад в математическую теорию эволюции» . Философские труды Лондонского королевского общества А. 185 : 71–110. Бибкод : 1894РСПТА.185...71П . дои : 10.1098/rsta.1894.0003 . ISSN 0264-3820 . JSTOR 90667 .
- ^ Шабан, Амирреза; Мехрдад, Фараджтабар; Бо, Се; Ле, Сонг; Байрон, Бутс (2015). «Изучение моделей со скрытыми переменными путем улучшения спектральных решений с помощью метода внешней точки» (PDF) . УАИ : 792–801. Архивировано из оригинала (PDF) 24 декабря 2016 г. Проверено 12 июня 2019 г.
- ^ Балле, Борха Кваттони, Ариадна Каррерас, Ксавье (27 июня 2012 г.). Оптимизация локальных потерь в операторских моделях: новый взгляд на спектральное обучение . OCLC 815865081 .
{{cite book}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Ланге, Кеннет. «Алгоритм ММ» (PDF) .
Дальнейшее чтение
[ редактировать ]- Хогг, Роберт; Маккин, Джозеф; Крейг, Аллен (2005). Введение в математическую статистику . Река Аппер-Сэддл, Нью-Джерси: Пирсон Прентис Холл. стр. 359–364.
- Делларт, Фрэнк (февраль 2002 г.). Алгоритм максимизации ожиданий (PDF) (номер технического отчета GIT-GVU-02-20). Технологический колледж вычислительной техники Джорджии. дает более простое объяснение алгоритма EM в отношении максимизации нижней границы.
- Бишоп, Кристофер М. (2006). Распознавание образов и машинное обучение . Спрингер. ISBN 978-0-387-31073-2 .
- Гупта, MR; Чен, Ю. (2010). «Теория и использование алгоритма EM». Основы и тенденции в области обработки сигналов . 4 (3): 223–296. CiteSeerX 10.1.1.219.6830 . дои : 10.1561/2000000034 . Хорошо написанная короткая книга по ЭМ, включая подробный вывод ЭМ для GMM, HMM и Дирихле.
- Билмес, Джефф (1997). Нежное руководство по алгоритму EM и его применению для оценки параметров гауссовой смеси и скрытых марковских моделей (технический отчет TR-97-021). Международный институт компьютерных наук. включает упрощенный вывод уравнений ЭМ для гауссовских смесей и скрытых марковских моделей гауссовских смесей.
- Маклахлан, Джеффри Дж.; Кришнан, Триямбакам (2008). EM-алгоритм и расширения (2-е изд.). Хобокен: Уайли. ISBN 978-0-471-20170-0 .
Внешние ссылки
[ редактировать ]- Различные 1D, 2D и 3D демонстрации ЭМ вместе с моделированием смесей предоставляются как часть парных занятий и апплетов SOCR . Эти апплеты и действия эмпирически показывают свойства алгоритма EM для оценки параметров в различных условиях.
- Иерархия классов в C++ (GPL), включая гауссовские смеси
- Онлайн-учебник Теория Дэвида Дж. Маккея « информации, вывод и алгоритмы обучения » включает простые примеры алгоритма EM, такие как кластеризация с использованием алгоритма мягких k -средних, и подчеркивает вариационный взгляд на алгоритм EM, как описано в Глава 33.7 версии 7.2 (четвертое издание).
- Вариационные алгоритмы для приблизительного байесовского вывода , автор М. Дж. Бил, включает сравнение EM с вариационным байесовским EM и выводы нескольких моделей, включая вариационные байесовские HMM ( главы ).
- Алгоритм максимизации ожиданий: краткое руководство , автономный вывод алгоритма EM Шона Бормана.
- Алгоритм EM , Сяоцзинь Чжу.
- EM-алгоритм и варианты: неформальное руководство Алексиса Роша. Краткое и очень понятное описание ЭМ и множества интересных вариантов.