Бутстрап-агрегирование
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Бутстрап-агрегирование , также называемое ) , представляет собой мета мешком (от бутстрап-агрегирование , - ансамбля машинного обучения алгоритм предназначенный для повышения стабильности и точности алгоритмов машинного обучения , используемых в статистической классификации и регрессии . Это также уменьшает дисперсию и помогает избежать переобучения . Хотя он обычно применяется к методам дерева решений , его можно использовать с любым типом метода. Бэггинг — это частный случай подхода усреднения модели .
Описание техники
[ редактировать ]Учитывая стандартный обучающий набор размера n , упаковка генерирует m новых обучающих наборов , каждый размером n' , путем выборки из D равномерно и с заменой . Путем выборки с заменой некоторые наблюдения могут повторяться в каждом . Если n ′ = n , то при больших n множество ожидается, что доля (1 - 1/ e ) (≈63,2%) будет содержать уникальные примеры D , остальные будут дубликатами. [ 1 ] Этот тип выборки известен как бутстрап- выборка. Выборка с заменой гарантирует, что каждый бутстрап независим от своих аналогов, поскольку он не зависит от предыдущих выбранных выборок при выборке. Затем m моделей подбираются с использованием m приведенных выше бутстрап-выборок и объединяются путем усреднения выходных данных (для регрессии) или голосования (для классификации).


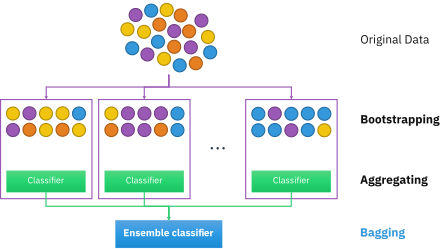
Упаковка приводит к «улучшению нестабильных процедур». [ 2 ] которые включают, например, искусственные нейронные сети , деревья классификации и регрессии , а также выбор подмножества в линейной регрессии . [ 3 ] Было показано, что упаковка в пакеты улучшает обучение прообразам. [ 4 ] [ 5 ] С другой стороны, это может слегка ухудшить производительность стабильных методов, таких как K-ближайшие соседи. [ 2 ]
Процесс алгоритма
[ редактировать ]Ключевые термины
[ редактировать ]При начальной загрузке существует три типа наборов данных. Это исходные, начальные и готовые наборы данных. В каждом разделе ниже объясняется, как создается каждый набор данных, за исключением исходного набора данных. Исходный набор данных — это любая предоставленная информация.
Создание набора данных начальной загрузки
[ редактировать ]Набор данных начальной загрузки создается путем случайного выбора объектов из исходного набора данных. Кроме того, он должен быть того же размера, что и исходный набор данных. Однако разница в том, что набор данных начальной загрузки может содержать повторяющиеся объекты. Вот простой пример, демонстрирующий, как это работает, вместе с иллюстрацией ниже:

Предположим, исходный набор данных представляет собой группу из 12 человек. Их зовут Эмили, Джесси, Джордж, Константин, Лекси, Теодор, Джон, Джеймс, Рэйчел, Энтони, Элли и Джамал.
Случайным образом выбрав группу имен, предположим, что в нашем наборе данных начальной загрузки были Джеймс, Элли, Константин, Лекси, Джон, Константин, Теодор, Константин, Энтони, Лекси, Константин и Теодор. В этом случае образец начальной загрузки содержал четыре дубликата для Константина и два дубликата для Лекси и Теодора.
Создание готового набора данных
[ редактировать ]Набор данных «из сумки» представляет остальных людей, которых не было в наборе данных начальной загрузки. Его можно рассчитать, взяв разницу между исходным набором данных и набором данных начальной загрузки. В этом случае оставшиеся образцы, которые не были выбраны, — это Эмили, Джесси, Джордж, Рэйчел и Джамал. Имейте в виду, что, поскольку оба набора данных являются наборами, при учете разницы повторяющиеся имена игнорируются в наборе данных начальной загрузки. На рисунке ниже показано, как выполняются математические вычисления:

Важность
[ редактировать ]Создание наборов данных начальной загрузки и исходных данных имеет решающее значение, поскольку оно используется для проверки точности алгоритма случайного леса. Например, модель, которая создает 50 деревьев с использованием наборов данных начальной загрузки/из пакета, будет иметь лучшую точность, чем если бы она создавала 10 деревьев. Поскольку алгоритм генерирует несколько деревьев и, следовательно, несколько наборов данных, вероятность того, что объект останется вне набора данных начальной загрузки, невелика. В следующих нескольких разделах более подробно рассказывается о том, как работает алгоритм случайного леса.
Создание деревьев решений
[ редактировать ]Следующий шаг алгоритма включает в себя генерацию деревьев решений из загрузочного набора данных. Для достижения этой цели процесс исследует каждый ген/признак и определяет, для скольких образцов наличие или отсутствие признака дает положительный или отрицательный результат. Эта информация затем используется для вычисления матрицы путаницы , в которой перечислены истинные положительные, ложные положительные, истинные отрицательные и ложные отрицательные значения признака при использовании в качестве классификатора. Затем эти функции ранжируются в соответствии с различными показателями классификации на основе их матриц путаницы. Некоторые общие показатели включают оценку положительной правильности (рассчитываемую путем вычитания ложноположительных результатов из истинных положительных), меру «хорошести» и прирост информации . Эти признаки затем используются для разделения выборок на два набора: те, у кого есть верхний признак, и те, у кого его нет.
На диаграмме ниже показано дерево решений второй глубины, используемое для классификации данных. Например, точке данных, которая демонстрирует функцию 1, но не имеет функцию 2, будет присвоено значение «Нет». Другой точке, которая не соответствует признаку 1, но имеет признак 3, будет присвоен ответ «Да».

Этот процесс повторяется рекурсивно для последовательных уровней дерева, пока не будет достигнута желаемая глубина. В самом низу дерева образцы с положительным результатом теста на последний признак обычно классифицируются как положительные, а образцы, в которых этот признак отсутствует, классифицируются как отрицательные. Эти деревья затем используются в качестве предикторов для классификации новых данных.
Случайные леса
[ редактировать ]Следующая часть алгоритма включает в себя введение еще одного элемента изменчивости среди самонастраиваемых деревьев. В дополнение к тому, что каждое дерево исследует только набор выборок, при ранжировании их в качестве классификаторов учитывается лишь небольшое, но постоянное количество уникальных функций. Это означает, что каждое дерево знает только данные, относящиеся к небольшому постоянному количеству объектов, и переменному количеству выборок, которое меньше или равно количеству исходного набора данных. Следовательно, деревья с большей вероятностью дадут более широкий спектр ответов, полученных на основе более разнообразных знаний. В результате получается случайный лес , который обладает многочисленными преимуществами по сравнению с одним деревом решений, сгенерированным без случайности. В случайном лесу каждое дерево «голосует» за то, следует ли классифицировать образец как положительный на основании его особенностей. Затем выборка классифицируется на основе большинства голосов. Пример этого приведен на диаграмме ниже, где четыре дерева в случайном лесу голосуют за то, есть ли у пациента с мутациями A, B, F и G рак. Поскольку три из четырех деревьев голосуют «за», пациент классифицируется как рак-положительный.

Из-за своих свойств случайные леса считаются одним из наиболее точных алгоритмов интеллектуального анализа данных, с меньшей вероятностью переопределяют свои данные и работают быстро и эффективно даже для больших наборов данных. [ 6 ] Они в первую очередь полезны для классификации, а не для регрессии , которая пытается выявить наблюдаемые связи между статистическими переменными в наборе данных. Это делает случайные леса особенно полезными в таких областях, как банковское дело, здравоохранение, фондовый рынок и электронная коммерция , где важно иметь возможность прогнозировать будущие результаты на основе прошлых данных. [ 7 ] Одним из их применений может стать полезный инструмент для прогнозирования рака на основе генетических факторов, как показано в приведенном выше примере.
При проектировании случайного леса следует учитывать несколько важных факторов. Если деревья в случайных лесах расположены слишком глубоко, переобучение все равно может произойти из-за чрезмерной специфичности. Если лес слишком велик, алгоритм может стать менее эффективным из-за увеличения времени выполнения. Случайные леса также обычно неэффективны при наличии скудных данных с небольшой изменчивостью. [ 7 ] Тем не менее, они по-прежнему имеют многочисленные преимущества перед аналогичными алгоритмами классификации данных, такими как нейронные сети , поскольку их гораздо легче интерпретировать и, как правило, требуется меньше данных для обучения. [ нужна ссылка ] Будучи неотъемлемым компонентом случайных лесов, бутстреп-агрегирование очень важно для алгоритмов классификации и обеспечивает критический элемент изменчивости, который позволяет повысить точность при анализе новых данных, как описано ниже.
Улучшение случайных лесов и мешков
[ редактировать ]Хотя описанные выше методы используют случайные леса и пакетирование (также известное как начальная загрузка), существуют определенные методы, которые можно использовать для улучшения их выполнения и времени голосования, точности прогнозирования и общей производительности. Ниже приведены ключевые шаги по созданию эффективного случайного леса:
- Укажите максимальную глубину деревьев: вместо того, чтобы позволять вашему случайному лесу продолжаться до тех пор, пока все узлы не станут чистыми, лучше отрезать его в определенной точке, чтобы еще больше уменьшить вероятность переобучения.
- Сократите набор данных. Использование чрезвычайно большого набора данных может привести к получению результатов, которые менее показательны для предоставленных данных, чем меньший набор, который более точно представляет то, на чем сосредоточено внимание.
- Продолжайте сокращать данные на каждом узле, а не только в исходном процессе упаковки.
- Решите, точность или скорость: в зависимости от желаемых результатов может помочь увеличение или уменьшение количества деревьев в лесу. Увеличение количества деревьев обычно дает более точные результаты, а уменьшение количества деревьев дает более быстрые результаты.
| Плюсы | Минусы |
|---|---|
| В целом для нормализации и масштабирования требуется меньше требований, что делает использование случайных лесов более удобным. [ 8 ] | Алгоритм может существенно измениться, если в данных, загружаемых и используемых в лесах, произойдут небольшие изменения. [ 9 ] Другими словами, случайные леса невероятно зависят от своих наборов данных, и их изменение может радикально изменить структуру отдельных деревьев. |
| Простая подготовка данных. Данные подготавливаются путем создания набора начальной загрузки и определенного количества деревьев решений для построения случайного леса, который также использует выбор признаков, как указано в разделе « Случайные леса» . | Случайные леса сложнее реализовать, чем одиночные деревья решений или другие алгоритмы. Это связано с тем, что они предпринимают дополнительные шаги для упаковки, а также требуют рекурсии для создания всего леса, что усложняет реализацию. Из-за этого требуется гораздо больше вычислительной мощности и вычислительных ресурсов. |
| Состоящие из нескольких деревьев решений , леса способны более точно делать прогнозы, чем отдельные деревья. | Требуется гораздо больше времени для обучения данных по сравнению с деревьями решений. Наличие большого леса может быстро начать снижать скорость работы программы, поскольку ей приходится обрабатывать гораздо больше данных, хотя каждое дерево использует меньший набор образцов и функций. |
| Хорошо работает с нелинейными данными. Поскольку большинство алгоритмов на основе деревьев используют линейное разбиение, использование ансамбля набора деревьев работает лучше, чем использование одного дерева для данных, которые имеют нелинейные свойства (т.е. большинство реальных распределений). Хорошая работа с нелинейными данными является огромным преимуществом, поскольку другие методы интеллектуального анализа данных, такие как одиночные деревья решений, также не справляются с этим. | Гораздо проще интерпретировать, чем случайный лес. По одному дереву можно пройти вручную (человеком), что приводит к несколько «объяснимому» пониманию аналитиком того, что на самом деле делает дерево. По мере того, как растет число деревьев и схем объединения этих деревьев в прогнозы, этот анализ становится намного сложнее, если не невозможен. |
| Существует меньший риск переобучения и эффективная работа даже с большими наборами данных. [ 10 ] Это результат использования случайного леса в сочетании со случайным выбором признаков. | Не прогнозирует за пределами диапазона обучающих данных. Это обман, потому что, хотя пакетирование часто бывает эффективным, все данные не учитываются, поэтому он не может предсказать весь набор данных. |
| Классификатор случайного леса работает с высокой точностью и скоростью. [ 11 ] Случайные леса работают намного быстрее, чем деревья решений, поскольку используют меньший набор данных. | Чтобы воссоздать конкретные результаты, вам необходимо отслеживать точное случайное начальное число, использованное для генерации наборов начальной загрузки. Это может быть важно при сборе данных для исследований или в рамках занятий по интеллектуальному анализу данных. Использование случайных начальных значений имеет важное значение для случайных лесов, но может затруднить подтверждение ваших утверждений, основанных на лесах, если не удастся записать начальные значения. |
| Хорошо справляется с отсутствующими данными и наборами данных со многими выбросами. Они справляются с этим, используя биннинг или группируя значения вместе, чтобы избежать значений, которые очень далеко друг от друга. |
Алгоритм (классификация)
[ редактировать ]
Для классификации используйте обучающий набор , Индуктор и количество бутстрап-сэмплов в качестве ввода. Создать классификатор как результат [ 12 ]



- Создавать новые тренировочные наборы , от с заменой
- Классификатор строится из каждого набора с использованием определить классификацию множества
- Наконец классификатор генерируется с использованием ранее созданного набора классификаторов на исходном наборе данных , классификация, чаще всего предсказываемая подклассификаторами это окончательная классификация

for i = 1 to m {
D' = bootstrap sample from D (sample with replacement)
Ci = I(D')
}
C*(x) = argmax #{i:Ci(x)=y} (most often predicted label y)
y∈Y
Пример: данные по озону
[ редактировать ]Чтобы проиллюстрировать основные принципы упаковки в мешки, ниже приводится анализ взаимосвязи между озоном и температурой (данные Руссеу и Лероя). [ нужны разъяснения ] (1986), анализ проведен в R ).
Судя по диаграмме рассеяния, в этом наборе данных взаимосвязь между температурой и озоном является нелинейной. Для математического описания этой зависимости LOESS используются сглаживатели (с шириной полосы 0,5). Вместо построения одного сглаживателя для всего набора данных 100 бутстрап- было взято выборок. Каждая выборка состоит из случайного подмножества исходных данных и сохраняет подобие распределения и изменчивости основного набора. Для каждого образца бутстрепа подходил сглаживатель LOESS. Затем были сделаны прогнозы на основе этих 100 сглаживателей по всему диапазону данных. Черные линии представляют эти первоначальные прогнозы. Линии не согласуются в своих предсказаниях и имеют тенденцию переопределять свои точки данных, о чем свидетельствует шаткое течение линий.
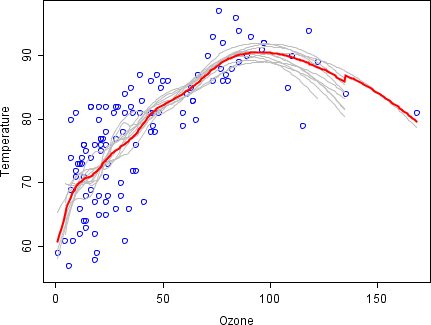
Взяв среднее значение для 100 сглаживателей, каждый из которых соответствует подмножеству исходного набора данных, мы получаем один пакетный предиктор (красная линия). Поток красной линии стабилен и не слишком соответствует какой-либо точке(ям) данных.
Преимущества и недостатки
[ редактировать ]Преимущества:
- Многие слабые учащиеся в совокупности обычно превосходят одного учащегося по всему набору и имеют меньшую переподготовку.
- Уменьшает дисперсию у слабого ученика с высокой дисперсией и низкой предвзятостью , [ 13 ] что может повысить эффективность (статистика)
- Может выполняться параллельно , так как каждый отдельный бутстрап может обрабатываться самостоятельно перед агрегацией. [ 14 ]
Недостатки:
- Для слабого учащегося с высокой предвзятостью сбор также будет привносить высокую предвзятость в его совокупность. [ 13 ]
- Потеря интерпретируемости модели.
- Может быть дорогостоящим в вычислительном отношении в зависимости от набора данных
История
[ редактировать ]Концепция бутстреп-агрегации основана на концепции бутстреп-агрегации, разработанной Брэдли Эфроном. [ 15 ] Бутстрап-агрегирование было предложено Брейманом, также ввёл сокращенный термин «бэггинг» ( bootstrap который agg regating Лео ). Брейман разработал концепцию упаковки в 1994 году, чтобы улучшить классификацию путем объединения классификаций случайно сгенерированных обучающих наборов. Он утверждал: «Если возмущение обучающего набора может привести к значительным изменениям в построенном предикторе, то объединение в пакеты может повысить точность». [ 3 ]
См. также
[ редактировать ]- Бустинг (мета-алгоритм)
- Начальная загрузка (статистика)
- Перекрестная проверка (статистика)
- Ошибка «нет в сумке»
- Случайный лес
- Метод случайного подпространства (пакетирование атрибутов)
- Изменена эффективная граница
- Прогнозный анализ: деревья классификации и регрессии
Ссылки
[ редактировать ]- ^ Аслам, Джавед А.; Попа, Ралука А.; и Ривест, Рональд Л. (2007); Об оценке размера и достоверности статистического аудита , Труды семинара по технологиям электронного голосования (EVT '07), Бостон, Массачусетс, 6 августа 2007 г. В более общем плане, при рисовании с заменой значений n' из набора n ( разные и одинаково вероятны), ожидаемое количество уникальных розыгрышей равно .
- ^ Jump up to: а б Брейман, Лео (1996). «Предсказатели мешков». Машинное обучение . 24 (2): 123–140. CiteSeerX 10.1.1.32.9399 . дои : 10.1007/BF00058655 . S2CID 47328136 .
- ^ Jump up to: а б Брейман, Лео (сентябрь 1994 г.). «Предсказатели мешков» (PDF) . Технический отчет (421). Статистический факультет Калифорнийского университета в Беркли . Проверено 28 июля 2019 г.
- ^ Саху, А., Рангер, Г., Апли, Д., Удаление шума изображения с помощью многофазного подхода основных компонентов ядра и ансамблевой версии , Семинар по распознаванию образов прикладных изображений IEEE, стр. 1-7, 2011.
- ^ Шинде, Амит, Аншуман Саху, Дэниел Апли и Джордж Рангер. « Прообразы для вариационных шаблонов из ядра PCA и мешков ». ИИЭ Сделки, Том 46, Выпуск 5, 2014
- ^ «Случайные леса – классификационное описание» . stat.berkeley.edu . Проверено 9 декабря 2021 г.
- ^ Jump up to: а б «Введение в случайный лес в машинном обучении» . Программа инженерного образования (EngEd) | Раздел . Проверено 9 декабря 2021 г.
- ^ «Случайный лес за и против» . HolyPython.com . Проверено 26 ноября 2021 г.
- ^ К, Дирадж (22 ноября 2020 г.). «Преимущества и недостатки алгоритма случайного леса» . Середина . Проверено 26 ноября 2021 г.
- ^ Команда «На пути к искусственному интеллекту». «Зачем выбирать случайный лес, а не деревья решений – На пути к искусственному интеллекту – ведущее в мире издание по искусственному интеллекту и технологиям» . Проверено 26 ноября 2021 г.
- ^ «Случайный лес» . Институт корпоративных финансов . Проверено 26 ноября 2021 г.
- ^ Бауэр, Эрик; Кохави, Рон (1999). «Эмпирическое сравнение алгоритмов классификации голосования: объединение, повышение и варианты» . Машинное обучение . 36 : 108–109. дои : 10.1023/А:1007515423169 . S2CID 1088806 .
- ^ Jump up to: а б «Что такое пакетирование (бутстрап-агрегирование)?» . КФИ . Институт корпоративных финансов . Проверено 5 декабря 2020 г.
- ^ Зогни, Рауф (5 сентября 2020 г.). «Бэггинг (бутстрап-агрегирование), обзор» . Стартап – через Medium.
- ^ Эфрон, Б. (1979). «Методы начальной загрузки: еще один взгляд на складной нож» . Анналы статистики . 7 (1): 1–26. дои : 10.1214/aos/1176344552 .

Дальнейшее чтение
[ редактировать ]- Брейман, Лео (1996). «Предсказатели мешков». Машинное обучение . 24 (2): 123–140. CiteSeerX 10.1.1.32.9399 . дои : 10.1007/BF00058655 . S2CID 47328136 .
- Альфаро Э., Гамес М. и Гарсия Н. (2012). «adabag: пакет R для классификации с помощью AdaBoost.M1, AdaBoost-SAMME и Baging» .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) CS1 maint: несколько имен: список авторов ( ссылка ) - Коциантис, Сотирис (2014). «Варианты объединения и повышения качества для решения проблем классификации: обзор». Знания англ. Обзор . 29 (1): 78–100. дои : 10.1017/S0269888913000313 . S2CID 27301684 .
- Бёмке, Брэдли; Гринвелл, Брэндон (2019). «Бэггинг». Практическое машинное обучение с помощью R . Чепмен и Холл. стр. 191–202. ISBN 978-1-138-49568-5 .