Коэффициент детерминации
Вы можете помочь дополнить эту статью текстом, переведенным из соответствующей статьи на немецком языке . (сентябрь 2019 г.) Нажмите [показать], чтобы просмотреть важные инструкции по переводу. |


В статистике коэффициент детерминации , обозначаемый R 2 или р 2 и произносится как «R в квадрате» — это доля изменения зависимой переменной, которую можно предсказать на основе независимой переменной (переменных).
Это статистика, используемая в контексте статистических моделей , основной целью которых является либо прогнозирование будущих результатов, либо проверка гипотез на основе другой соответствующей информации. Он обеспечивает оценку того, насколько хорошо наблюдаемые результаты воспроизводятся моделью, на основе доли общей вариации результатов, объясненной моделью. [1] [2] [3]
Существует несколько определений Р. 2 которые лишь иногда эквивалентны. Один класс таких случаев включает случай простой линейной регрессии , где r 2 используется вместо R 2 . только перехват Если включен , то r 2 — это просто квадрат выборочного коэффициента корреляции (т. е. r ) между наблюдаемыми результатами и наблюдаемыми значениями предикторов. [4] дополнительные регрессоры Если включены , R 2 – квадрат коэффициента множественной корреляции . В обоих случаях коэффициент детерминации обычно находится в диапазоне от 0 до 1.
Бывают случаи, когда Р. 2 может давать отрицательные значения. Это может возникнуть, когда прогнозы, которые сравниваются с соответствующими результатами, не были получены в результате процедуры подбора модели с использованием этих данных. Даже если использовалась процедура подбора модели, R 2 может по-прежнему быть отрицательным, например, когда линейная регрессия проводится без включения пересечения, [5] или когда для подбора данных используется нелинейная функция. [6] В случаях, когда возникают отрицательные значения, среднее значение данных обеспечивает лучшее соответствие результатам, чем значения подобранной функции, согласно этому конкретному критерию.
Коэффициент детерминации может быть более информативным, чем MAE , MAPE , MSE и RMSE при оценке регрессионного анализа , поскольку первый может быть выражен в процентах, тогда как вторые меры имеют произвольные диапазоны. Он также оказался более устойчивым к плохим подгонкам по сравнению с SMAPE на тестовых наборах данных в статье. [7]
При оценке согласия смоделированных ( Y pred ) и измеренных ( Y obs ) значений нецелесообразно основывать это на R 2 линейной регрессии (т.е. Y obs = m · Y pred + b). [ нужна ссылка ] Р 2 количественно определяет степень любой линейной корреляции между Y obs и Y pred , в то время как для оценки согласия следует принимать во внимание только одну конкретную линейную корреляцию: Y obs = 1 · Y pred + 0 (т. е. 1:1 линия). [8] [9]
Определения
[ редактировать ]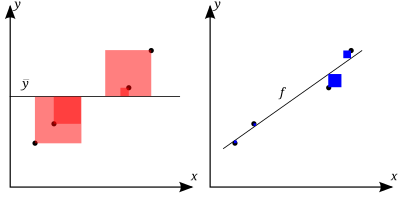

Чем лучше линейная регрессия (справа) соответствует данным по сравнению с простым средним (на левом графике), тем ближе значение R 2 равно 1. Области синих квадратов представляют собой квадраты остатков по отношению к линейной регрессии. Площади красных квадратов представляют собой квадраты остатков относительно среднего значения.
Набор данных имеет n значений, отмеченных y 1 , ..., y n (в совокупности известные как y i или вектор y = [ y 1 , ..., y n ] Т ), каждое из которых связано с подобранным (или смоделированным, или предсказанным) значением f 1 , ..., f n (известным как fi , или иногда ŷ i , как вектор f ).
Определите остатки как e i = y i - f i (образуя вектор e ).
Если среднее значение наблюдаемых данных: тогда изменчивость набора данных можно измерить с помощью двух формул суммы квадратов :


- Сумма квадратов остатков, называемая также остаточной суммой квадратов :
- Общая сумма квадратов (пропорциональная дисперсии данных):


Наиболее общее определение коэффициента детерминации:

В лучшем случае смоделированные значения точно соответствуют наблюдаемым значениям, что приводит к и Р 2 = 1 . Базовая модель, которая всегда предсказывает y , будет иметь R 2 = 0 .

Связь с необъяснимой дисперсией
[ редактировать ]В общем виде Р 2 можно увидеть, что он связан с долей необъяснимой дисперсии (FVU), поскольку второй член сравнивает необъяснимую дисперсию (дисперсию ошибок модели) с общей дисперсией (данных):

Как объяснили дисперсию
[ редактировать ]Большее значение R 2 подразумевает более успешную регрессионную модель. [4] : 463 Предположим, Р 2 = 0,49 . Это означает, что 49% изменчивости зависимой переменной в наборе данных учтено, а оставшийся 51% изменчивости все еще не учтен. Для регрессионных моделей сумма квадратов регрессии, также называемая объясненной суммой квадратов , определяется как

В некоторых случаях, как в простой линейной регрессии , общая сумма квадратов равна сумме двух других сумм квадратов, определенных выше:

См. Разделение в общей модели МНК для получения этого результата для одного случая, когда это соотношение выполняется. Когда это соотношение действительно выполняется, приведенное выше определение R 2 эквивалентно

где n — количество наблюдений (случаев) над переменными.
В этой форме Р 2 выражается как отношение объясненной дисперсии (дисперсии предсказаний модели, которая равна SS reg / n ) к общей дисперсии (выборочной дисперсии зависимой переменной, которая равна SS tot / n ).
Это разделение суммы квадратов справедливо, например, когда значения модели ƒ i были получены с помощью линейной регрессии . Более мягкое достаточное условие имеет вид: Модель имеет вид

где q i — произвольные значения, которые могут зависеть или не зависеть от i или других свободных параметров (обычный выбор q i = x i — это всего лишь один частный случай), а оценки коэффициентов и получаются минимизацией остаточной суммы квадратов.


Этот набор условий является важным и имеет ряд последствий для свойств подобранных остатков и смоделированных значений. В частности, в этих условиях:

Как квадрат коэффициента корреляции
[ редактировать ]В линейной множественной регрессии по методу наименьших квадратов с оценкой члена-члена R 2 равен квадрату коэффициента корреляции Пирсона между наблюдаемыми и смоделировано (прогнозировано) значения данных зависимой переменной.


В линейной регрессии наименьших квадратов с одним объяснителем, но без члена-члена , это также равно квадрату коэффициента корреляции Пирсона зависимой переменной. и объясняющая переменная

Его не следует путать с коэффициентом корреляции между двумя объясняющими переменными , определяемым как

где ковариация между двумя оценками коэффициентов, а также их стандартные отклонения получены из ковариационной матрицы оценок коэффициентов, .

В более общих условиях моделирования, когда прогнозируемые значения могут быть получены на основе модели, отличной от линейной регрессии наименьших квадратов, R 2 значение может быть рассчитано как квадрат коэффициента корреляции между исходным и смоделировал значения данных. В этом случае значение не является прямой мерой того, насколько хороши смоделированные значения, а скорее мерой того, насколько хорош предиктор может быть построен на основе смоделированных значений (путем создания пересмотренного предиктора формы α + βƒ i ). [ нужна ссылка ] По словам Эверитта, [10] это использование, в частности, является определением термина «коэффициент детерминации»: квадрата корреляции между двумя (общими) переменными.
Интерпретация
[ редактировать ]Р 2 является мерой качества соответствия модели. [11] В регрессии R 2 Коэффициент детерминации — это статистическая мера того, насколько хорошо прогнозы регрессии приближаются к реальным точкам данных. Р 2 Значение 1 указывает на то, что прогнозы регрессии идеально соответствуют данным.
Значения R 2 Выходы за пределы диапазона от 0 до 1 возникают, когда модель соответствует данным хуже, чем худший из возможных предсказателей метода наименьших квадратов (эквивалент горизонтальной гиперплоскости на высоте, равной среднему значению наблюдаемых данных). Это происходит, когда была выбрана неверная модель или по ошибке были применены бессмысленные ограничения. Если уравнение 1 Кволсета [12] (это уравнение используется чаще всего), R 2 может быть меньше нуля. Если используется уравнение 2 Кволсета, R 2 может быть больше единицы.
Во всех случаях, когда Р 2 используется, предикторы рассчитываются с помощью обычной регрессии наименьших квадратов: то есть путем минимизации SS res . В этом случае Р 2 увеличивается с увеличением количества переменных в модели ( R 2 монотонно возрастает с увеличением числа включенных переменных — оно никогда не убывает). Это иллюстрирует недостаток одного возможного использования R 2 , где можно продолжать добавлять переменные ( регрессия кухонной мойки ), чтобы увеличить R 2 ценить. Например, если кто-то пытается спрогнозировать продажи модели автомобиля, исходя из расхода бензина, цены и мощности двигателя, можно включить, вероятно, нерелевантные факторы, такие как первая буква названия модели или рост ведущего инженера. проектирование автомобиля, потому что R 2 никогда не уменьшится при добавлении переменных и, скорее всего, увеличится только по случайности.
Это приводит к альтернативному подходу рассмотрения скорректированного R. 2 . Объяснение этой статистики почти такое же, как у R 2 но это ухудшает статистику, поскольку в модель включены дополнительные переменные. Для случаев, отличных от аппроксимации методом обычных наименьших квадратов, R 2 Статистику можно рассчитать, как указано выше, и она все равно может быть полезной мерой. Если аппроксимация осуществляется методом взвешенных наименьших квадратов или обобщенным методом наименьших квадратов , альтернативные версии R 2 могут быть рассчитаны в соответствии с этими статистическими основами, в то время как «необработанный» R 2 может все еще быть полезным, если его будет легче интерпретировать. Значения для R 2 может быть рассчитан для любого типа прогнозной модели, которая не обязательно должна иметь статистическую основу.
В множественной линейной модели
[ редактировать ]Рассмотрим линейную модель с более чем одной объясняющей переменной в форме

где для i -го случая — переменная ответа, являются пререгрессорами и представляет собой термин средней нулевой ошибки . Количества — неизвестные коэффициенты, значения которых оцениваются методом наименьших квадратов . Коэффициент детерминации R 2 является мерой глобального соответствия модели. В частности, Р 2 является элементом [0, 1] и представляет долю изменчивости в Y i , которую можно отнести к некоторой линейной комбинации регрессоров ( объяснительных переменных в X. ) [13]




Р 2 часто интерпретируется как доля вариаций ответа, «объясняемая» регрессорами в модели. Таким образом, Р 2 = 1 означает, что подобранная модель объясняет всю изменчивость , в то время как Р 2 = 0 указывает на отсутствие «линейной» зависимости (для прямой регрессии это означает, что модель прямой линии представляет собой постоянную линию (наклон = 0, точка пересечения = ) между переменной ответа и регрессорами). Внутреннее значение, такое как R 2 = 0,7 можно интерпретировать следующим образом: «Семьдесят процентов дисперсии переменной отклика можно объяснить объясняющими переменными. Остальные тридцать процентов можно отнести к неизвестным, скрытым переменным или внутренней изменчивости».
Предупреждение, касающееся R 2 Что касается других статистических описаний корреляции и ассоциации, то это то, что « корреляция не подразумевает причинно-следственную связь ». Другими словами, хотя корреляции иногда могут дать ценные подсказки для выявления причинно-следственных связей между переменными, ненулевая предполагаемая корреляция между двумя переменными сама по себе не является свидетельством того, что изменение значения одной переменной приведет к изменениям значений других переменных. другие переменные. Например, практика ношения спичек (или зажигалки) коррелирует с заболеваемостью раком легких, но ношение спичек не вызывает рак (в стандартном смысле слова «причина»).
В случае одного регрессора, аппроксимируемого методом наименьших квадратов, R 2 представляет собой квадрат коэффициента корреляции момента произведения Пирсона, связывающего регрессор и переменную отклика. В более общем смысле, Р 2 представляет собой квадрат корреляции между построенным предиктором и переменной ответа. При наличии более чем одного регрессора R 2 можно назвать коэффициентом множественной детерминации .
Инфляция рубля 2
[ редактировать ]В регрессии наименьших квадратов с использованием типичных данных R 2 хотя бы слабо возрастает с увеличением числа регрессоров в модели. Поскольку увеличение числа регрессоров увеличивает значение R 2 , Р 2 сам по себе не может использоваться для значимого сравнения моделей с очень разным количеством независимых переменных. Для значимого сравнения двух моделей F-тест можно выполнить по остаточной сумме квадратов. [ нужна ссылка ] , аналогично F-тестам причинности Грейнджера , хотя это не всегда уместно. [ нужны дальнейшие объяснения ] . Напоминая об этом, некоторые авторы обозначают R 2 по р q 2 , где q — количество столбцов в X (количество объяснителей, включая константу).
Чтобы продемонстрировать это свойство, сначала вспомните, что целью линейной регрессии по методу наименьших квадратов является

где X i - вектор-строка значений объясняющих переменных для случая i, а b - вектор-столбец коэффициентов соответствующих элементов X i .
Оптимальное значение цели немного меньше по мере добавления дополнительных объясняющих переменных и, следовательно, дополнительных столбцов таблицы. (матрица пояснительных данных, i -я строка которой равна X i ) добавляются в связи с тем, что менее ограниченная минимизация приводит к оптимальной стоимости, которая немного меньше, чем более ограниченная минимизация. Учитывая предыдущий вывод и отмечая, что зависит только от y , свойство неубывания R 2 следует непосредственно из приведенного выше определения.


Интуитивная причина того, что использование дополнительной независимой переменной не может снизить R 2 это: Минимизация эквивалентно максимизации R 2 . Когда включена дополнительная переменная, данные всегда имеют возможность присвоить ей расчетный коэффициент, равный нулю, оставив прогнозируемые значения и R 2 без изменений. Единственный способ, которым задача оптимизации даст ненулевой коэффициент, — это если это улучшит R 2 .

Вышеизложенное дает аналитическое объяснение инфляции R 2 . Далее ниже показан пример, основанный на обычном методе наименьших квадратов с геометрической точки зрения. [14]
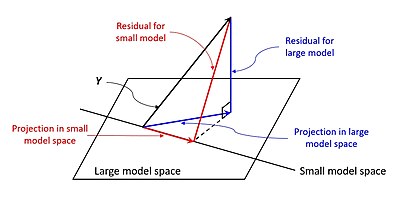
Простой случай, который следует рассмотреть в первую очередь:

Это уравнение описывает обычную модель регрессии наименьших квадратов с одним регрессором. Прогноз показан красным вектором на рисунке справа. Геометрически это проекция истинной ценности на модельное пространство. (без перехвата). Остаток показан красной линией.


Это уравнение соответствует обычной модели регрессии наименьших квадратов с двумя регрессорами. Прогноз показан синим вектором на рисунке справа. Геометрически это проекция истинной ценности на большее пространство модели. (без перехвата). Примечательно, что значения и не такие же, как в уравнении для меньшего модельного пространства, если и не являются нулевыми векторами. Следовательно, ожидается, что уравнения будут давать разные предсказания (т. е. ожидается, что синий вектор будет отличаться от красного вектора). Критерий регрессии наименьших квадратов гарантирует минимизацию остатка. На рисунке синяя линия, представляющая остаток, ортогональна пространству модели в , дающий минимальное расстояние от пространства.




Меньшее модельное пространство является подпространством большего, поэтому остаток меньшей модели гарантированно будет больше. Если сравнить красную и синюю линии на рисунке, то можно увидеть, что синяя линия ортогональна пространству, а любая другая линия будет больше синей. Учитывая расчет R 2 , меньшее значение приведет к большему значению R 2 , что означает, что добавление регрессоров приведет к инфляции R 2 .
Предостережения
[ редактировать ]Р 2 не указывает, является ли:
- независимые переменные являются причиной изменения зависимой переменной ;
- смещение по пропущенной переменной ; существует
- правильная регрессия ; использовалась
- выбран наиболее подходящий набор независимых переменных;
- коллинеарность ; в данных по объясняющим переменным присутствует
- модель можно улучшить, используя преобразованные версии существующего набора независимых переменных;
- данных достаточно, чтобы сделать однозначный вывод.
Расширения
[ редактировать ]Скорректированный R 2
[ редактировать ]Использование скорректированного R 2 (одним из распространенных обозначений является , произносится как «R-бар в квадрате»; другой или ) представляет собой попытку объяснить феномен R 2 автоматически увеличивается при добавлении в модель дополнительных независимых переменных. Есть много разных способов регулировки. [15] Безусловно, наиболее часто используемым, вплоть до того, что его обычно называют просто скорректированным R , является исправление, предложенное Мордехаем Иезекиилем . [15] [16] [17] Скорректированный R 2 определяется как




где df res — это степени свободы оценки дисперсии генеральной совокупности вокруг модели, а df tot — это степени свободы оценки дисперсии генеральной совокупности вокруг среднего значения. df res определяется размером выборки n и количеством переменных p в модели: df res = n − p − 1 . df tot задается таким же образом, но p равно единице для среднего значения, т.е. df tot = n − 1 .
Подставляя степени свободы и используя определение R 2 , его можно переписать как:

где p — общее количество объясняющих переменных в модели, [18] и n — размер выборки.
Скорректированный R 2 может быть отрицательным, и его значение всегда будет меньше или равно значению R 2 . В отличие от Р 2 , скорректированный R 2 увеличивается только тогда, когда увеличение R 2 (из-за включения новой объясняющей переменной) — это больше, чем можно было бы ожидать случайно. Если набор независимых переменных с заранее определенной иерархией важности вводится в регрессию по одной, со скорректированным R 2 каждый раз вычисляется уровень, на котором скорректирован R 2 достигает максимума, а затем уменьшается, это будет регрессия с идеальной комбинацией наилучшего соответствия без лишних/ненужных условий.
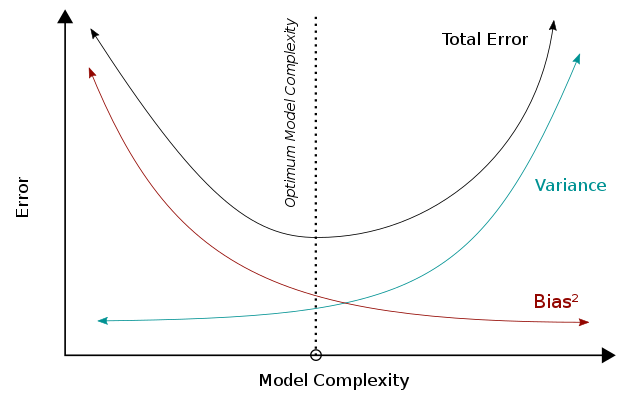
Скорректированный R 2 можно интерпретировать как пример компромисса между смещением и дисперсией . Когда мы рассматриваем производительность модели, меньшая ошибка означает лучшую производительность. Когда модель становится более сложной, дисперсия будет увеличиваться, тогда как квадрат смещения будет уменьшаться, и эти две метрики в сумме образуют общую ошибку. Сочетая эти две тенденции, компромисс между смещением и дисперсией описывает взаимосвязь между производительностью модели и ее сложностью, которая показана в виде U-образной кривой справа. Для скорректированного R 2 в частности, сложность модели (т.е. количество параметров) влияет на R 2 и термин / frac и тем самым отражает их атрибуты в общей производительности модели.
Р 2 можно интерпретировать как дисперсию модели, на которую влияет сложность модели. Высокий Р 2 указывает на меньшую ошибку смещения, поскольку модель может лучше объяснить изменение Y с помощью предикторов. По этой причине мы делаем меньше (ошибочных) предположений, и это приводит к меньшей ошибке смещения. Между тем, чтобы учесть меньше предположений, модель имеет тенденцию усложняться. Исходя из компромисса смещения и дисперсии, более высокая сложность приведет к уменьшению смещения и лучшей производительности (ниже оптимальной линии). В Р 2 , член ( 1 − R 2 ) будет ниже при высокой сложности и приведет к более высокому R 2 , что постоянно указывает на лучшую производительность.
С другой стороны, на термин/член гидроразрыва обратное влияние оказывает сложность модели. Срок/разрыв увеличится при добавлении регрессоров (т. е. увеличится сложность модели) и приведет к ухудшению производительности. На основании компромисса между смещением и дисперсией более высокая сложность модели (за пределами оптимальной линии) приводит к увеличению ошибок и снижению производительности.
Учитывая расчет R 2 , большее количество параметров увеличит R 2 и привести к увеличению R 2 . Тем не менее, добавление дополнительных параметров увеличит срок/разрыв и, таким образом, уменьшит R. 2 . Эти две тенденции создают обратную U-образную зависимость между сложностью модели и R. 2 , что соответствует U-образной тенденции зависимости сложности модели от общей производительности. В отличие от Р 2 , которое всегда будет увеличиваться с увеличением сложности модели, R 2 будет увеличиваться только тогда, когда смещение, устраняемое добавленным регрессором, больше, чем дисперсия, вносимая одновременно. Использование Р 2 вместо Р 2 таким образом можно было бы предотвратить переобучение.
Следуя той же логике, скорректировали R 2 можно интерпретировать как менее предвзятую оценку совокупности R 2 , тогда как наблюдаемый образец R 2 представляет собой положительно смещенную оценку стоимости совокупности. [19] Скорректированный R 2 более подходит при оценке соответствия модели (дисперсия зависимой переменной, учитываемая независимыми переменными) и при сравнении альтернативных моделей на этапе выбора признаков при построении модели. [19]
Принцип скорректированного R 2 статистику можно увидеть, переписав обычный R 2 как

где и представляют собой выборочные дисперсии оцененных остатков и зависимой переменной соответственно, которые можно рассматривать как смещенные оценки генеральных дисперсий ошибок и зависимой переменной. Эти оценки заменяются статистически несмещенными версиями: и .




Несмотря на использование несмещенных оценок генеральной дисперсии ошибки и зависимой переменной, скорректированный R 2 не является несмещенной оценкой совокупности R 2 , [19] что получается за счет использования генеральных дисперсий ошибок и зависимой переменной вместо их оценки. Ингрэм Олкин и Джон В. Пратт получили несмещенную оценку с минимальной дисперсией для совокупности R. 2 , [20] который известен как оценка Олкина – Пратта. Сравнение различных подходов к настройке R 2 пришел к выводу, что в большинстве ситуаций либо приближенная версия оценки Олкина – Пратта [19] или точная оценка Олкина – Пратта [21] следует отдавать предпочтение перед скорректированным (Иезекиилем) R 2 .
Коэффициент частичной детерминации
[ редактировать ]Коэффициент частичной детерминации можно определить как долю вариаций, которую нельзя объяснить в сокращенной модели, но можно объяснить с помощью предикторов, указанных в полной (полной) модели. [22] [23] [24] Этот коэффициент используется для определения того, могут ли один или несколько дополнительных предикторов быть полезны в более полной регрессионной модели.
Расчет частичного R 2 относительно просто после оценки двух моделей и создания для них таблиц ANOVA . Расчет частичного R 2 является

что аналогично обычному коэффициенту детерминации:

Обобщение и декомпозиция R 2
[ редактировать ]Как объяснялось выше, эвристики выбора модели, такие как скорректированный R 2 критерий и F-тест проверяют, является ли общий R 2 достаточно увеличивается, чтобы определить, следует ли добавлять в модель новый регрессор. Если к модели добавляется регрессор, который сильно коррелирует с другими уже включенными регрессорами, то общий R 2 вряд ли увеличится, даже если новый регрессор будет уместен. В результате вышеупомянутые эвристики будут игнорировать соответствующие регрессоры, когда взаимная корреляция высока. [25]

В качестве альтернативы можно разложить обобщенную версию R 2 количественно оценить релевантность отклонения от гипотезы. [25] Как показывает Хорнвег (2018), несколько оценок усадки , таких как байесовская линейная регрессия , гребневая регрессия и (адаптивное) лассо , используют это разложение R 2 когда они постепенно сокращают параметры неограниченных решений МНК до гипотетических значений. Давайте сначала определим модель линейной регрессии как

Предполагается, что матрица X стандартизирована с помощью Z-показателей и что вектор-столбец центрирован так, чтобы иметь среднее значение, равное нулю. Пусть вектор-столбец обратитесь к предполагаемым параметрам регрессии и позвольте вектор-столбцу обозначают расчетные параметры. Затем мы можем определить


Р 2 75 % означает, что точность в выборке увеличивается на 75 %, если b . вместо гипотетического решения используются оптимизированные для данных решения ценности. В частном случае, когда — вектор нулей, мы получаем традиционный R 2 снова.
Индивидуальное влияние на R 2 отклонения от гипотезы можно вычислить с помощью («R-внешний»). Этот раз матрица имеет вид



где . Диагональные элементы ровно прибавьте к R 2 . Если регрессоры некоррелированы и вектор нулей, то диагональный элемент просто соответствует r 2 значение между и . Когда регрессоры и коррелируют, может увеличиться за счет уменьшения . В результате диагональные элементы может быть меньше 0 и, в более исключительных случаях, больше 1. Чтобы справиться с такими неопределенностями, некоторые программы оценки усадки неявно принимают средневзвешенное значение диагональных элементов количественно оценить значимость отклонения от гипотетического значения. [25] Нажмите на лассо , чтобы увидеть пример.






Р 2 в логистической регрессии
[ редактировать ]В случае логистической регрессии , обычно подходящей по максимальному правдоподобию , существует несколько вариантов псевдо- R. 2 .
Одним из них является обобщенный R 2 первоначально предложено Cox & Snell, [26] и независимо Маги: [27]

где - вероятность модели только с перехватом, — правдоподобие оцениваемой модели (т. е. модели с заданным набором оценок параметров), а n — размер выборки. Его легко переписать так:



где D — тестовая статистика теста отношения правдоподобия .
Нико Нагелькерке отметил, что он обладает следующими свойствами: [28] [23]
- Это соответствует классическому коэффициенту детерминации, когда оба могут быть вычислены;
- Его значение максимизируется за счет оценки максимального правдоподобия модели;
- Он асимптотически не зависит от размера выборки;
- Интерпретация – это доля вариаций, объясняемая моделью;
- Значения находятся в диапазоне от 0 до 1, где 0 означает, что модель не объясняет никаких изменений, а 1 означает, что она полностью объясняет наблюдаемые изменения;
- У него нет никакой единицы.
Однако в случае логистической модели, где не может быть больше 1, R 2 находится между 0 и : таким образом, Нагелькерке предложил возможность определить масштабированный R 2 как Р 2 / Р 2 макс . [23]


Сравнение с нормой остатков
[ редактировать ]Иногда норма для определения степени соответствия используется остатков. Этот член рассчитывается как квадратный корень из суммы квадратов остатков :

Оба Р 2 и норма остатков имеют свои относительные достоинства. Для методом наименьших квадратов анализа R 2 варьируется от 0 до 1, причем большие цифры указывают на лучшее соответствие, а 1 — на идеальное соответствие. Норма остатков варьируется от 0 до бесконечности, при этом меньшие числа указывают на лучшее соответствие, а ноль — на идеальное соответствие. Одно преимущество и недостаток R 2 это термин действует для нормализации значения. Если все значения y i умножить на константу, норма остатков также изменится на эту константу, но R 2 останется прежним. В качестве базового примера для линейного метода наименьших квадратов, подходящего к набору данных:

х 1 2 3 4 5 и 1.9 3.7 5.8 8.0 9.6
Р 2 = 0,998, а норма остатков = 0,302.Если все значения y умножаются на 1000 (например, при изменении префикса SI ), то R 2 остается прежним, но норма остатков = 302.
Еще одним однопараметрическим индикатором соответствия является среднеквадратическое отклонение остатков или стандартное отклонение остатков. Для приведенного выше примера это значение будет равно 0,135, учитывая, что подгонка была линейной с непринудительным пересечением. [29]
История
[ редактировать ]Создание коэффициента детерминации приписывается генетику Сьюэллу Райту и впервые было опубликовано в 1921 году. [30]
См. также
[ редактировать ]- квартет Анскомба
- Доля дисперсии необъяснима
- Хорошая посадка
- Коэффициент эффективности модели Нэша – Сатклиффа ( гидрологические приложения )
- Коэффициент корреляции момента произведения Пирсона
- Пропорциональное сокращение потерь
- Проверка регрессионной модели
- Среднеквадратичное отклонение
- Пошаговая регрессия
Примечания
[ редактировать ]- ^ Сталь, РГД; Торри, Дж. Х. (1960). Принципы и процедуры статистики с особым упором на биологические науки . МакГроу Хилл .
- ^ Гланц, Стэнтон А.; Слинкер, БК (1990). Основы прикладной регрессии и дисперсионного анализа . МакГроу-Хилл. ISBN 978-0-07-023407-9 .
- ^ Дрейпер, Северная Каролина; Смит, Х. (1998). Прикладной регрессионный анализ . Уайли-Интерсайенс. ISBN 978-0-471-17082-2 .
- ^ Jump up to: а б Девор, Джей Л. (2011). Вероятность и статистика для техники и наук (8-е изд.). Бостон, Массачусетс: Cengage Learning. стр. 508–510. ISBN 978-0-538-73352-6 .
- ^ Бартен, Антон П. (1987). «Коэффициент детерминации регрессии без постоянного члена». Ин Хейманс, Ристо; Нойдекер, Хайнц (ред.). Практика эконометрики . Дордрехт: Клювер. стр. 181–189. ISBN 90-247-3502-5 .
- ^ Колин Кэмерон, А.; Виндмейер, Франк А.Г. (1997). «R-квадратная мера согласия для некоторых распространенных моделей нелинейной регрессии». Журнал эконометрики . 77 (2): 1790–2. дои : 10.1016/S0304-4076(96)01818-0 .
- ^ Чикко, Давиде; Уорренс, Маттейс Дж.; Юрман, Джузеппе (2021). «Коэффициент детерминации R-квадрат более информативен, чем SMAPE, MAE, MAPE, MSE и RMSE при оценке регрессионного анализа» . PeerJ Информатика . 7 (e623): e623. дои : 10.7717/peerj-cs.623 . ПМЦ 8279135 . ПМИД 34307865 .
- ^ Легаты, ДР; Маккейб, Дж.Дж. (1999). «Оценка использования показателей согласия при проверке гидрологических и гидроклиматических моделей». Водный ресурс. Рез . 35 (1): 233–241. Бибкод : 1999WRR....35..233L . дои : 10.1029/1998WR900018 . S2CID 128417849 .
- ^ Риттер, А.; Муньос-Карпена, Р. (2013). «Оценка эффективности гидрологических моделей: статистическая значимость для снижения субъективности в оценках согласия». Журнал гидрологии . 480 (1): 33–45. Бибкод : 2013JHyd..480...33R . дои : 10.1016/j.jгидрол.2012.12.004 .
- ^ Эверитт, бакалавр наук (2002). Кембриджский статистический словарь (2-е изд.). ЧАШКА. п. 78. ИСБН 978-0-521-81099-9 .
- ^ Казелла, Жорж (2002). Статистический вывод (Второе изд.). Пасифик Гроув, Калифорния: Даксбери/Томсон Лиринг. п. 556. ИСБН 9788131503942 .
- ^ Квалсет, Таральд О. (1985). «Предупреждение о R2». Американский статистик . 39 (4): 279–285. дои : 10.2307/2683704 . JSTOR 2683704 .
- ^ «Линейная регрессия – MATLAB и Simulink» . www.mathworks.com .
- ^ Вдали, Джулиан Джеймс (2005). Линейные модели с R (PDF) . Чепмен и Холл/CRC. ISBN 9781584884255 .
- ^ Jump up to: а б Раджу, Намбери С.; Билгич, Рейхан; Эдвардс, Джек Э.; Флир, Пол Ф. (1997). «Обзор методологии: оценка генеральной и перекрестной достоверности, а также использование равных весов в прогнозировании» . Прикладные психологические измерения . 21 (4): 291–305. дои : 10.1177/01466216970214001 . ISSN 0146-6216 . S2CID 122308344 .
- ^ Мордехай Иезекииль (1930), Методы корреляционного анализа , Wiley , Wikidata Q120123877 , стр. 208–211.
- ^ Инь, Пин; Фань, Ситао (январь 2001 г.). «Оценка R 2 Сокращение в множественной регрессии: сравнение различных аналитических методов» (PDF) . Журнал экспериментального образования . 69 (2): 203–224. doi : 10.1080/00220970109600656 . ISSN 0022-0973 . S2CID 121614674 .
- ^ Предполагая, что параметры p + 1 оценены
- ^ Jump up to: а б с д Ши, Гвовен (01 апреля 2008 г.). «Улучшенная оценка сокращения квадрата коэффициента множественной корреляции и квадрата коэффициента перекрестной достоверности». Организационные методы исследования . 11 (2): 387–407. дои : 10.1177/1094428106292901 . ISSN 1094-4281 . S2CID 55098407 .
- ^ Олкин, Ингрэм; Пратт, Джон В. (март 1958 г.). «Непредвзятая оценка некоторых коэффициентов корреляции» . Анналы математической статистики . 29 (1): 201–211. дои : 10.1214/aoms/1177706717 . ISSN 0003-4851 .
- ^ Карч, Джулиан (29 сентября 2020 г.). «Улучшение скорректированного R-квадрата» . Коллабра: Психология . 6 (45). дои : 10.1525/collabra.343 . hdl : 1887/3161248 . ISSN 2474-7394 .
- ^ Ричард Андерсон-Спречер, « Сравнение моделей и R 2 «, Американский статистик , том 48, выпуск 2, 1994 г., стр. 113–117.
- ^ Jump up to: а б с Нагелькерке, NJD (сентябрь 1991 г.). «Примечание к общему определению коэффициента детерминации» (PDF) . Биометрика . 78 (3): 691–692. дои : 10.1093/biomet/78.3.691 . JSTOR 2337038 .
- ^ «регрессия – R реализация коэффициента частичной детерминации» . Крест проверен .
- ^ Jump up to: а б с Хорнвег, Виктор (2018). «Часть II: О сохранении фиксированных параметров» . Наука: Подчинение . Хорнвег Пресс. ISBN 978-90-829188-0-9 .
- ^ Кокс, Д.Д.; Снелл, Э.Дж. (1989). Анализ двоичных данных (2-е изд.). Чепмен и Холл.
- ^ Маги, Л. (1990). " Р 2 меры, основанные на тестах совместной значимости Уолда и отношения правдоподобия». The American Statistician . 44 (3): 250–3. doi : 10.1080/00031305.1990.10475731 .
- ^ Нагелькерке, Нико Джей Ди (1992). Оценка максимального правдоподобия функциональных связей, Pays-Bas . Конспект лекций по статистике. Том. 69. ИСБН 978-0-387-97721-8 .
- ^ Веб-страница OriginLab, http://www.originlab.com/doc/Origin-Help/LR-Algorithm . Проверено 9 февраля 2016 г.
- ^ Райт, Сьюэлл (январь 1921 г.). «Корреляция и причинно-следственная связь». Журнал сельскохозяйственных исследований . 20 : 557–585.
Дальнейшее чтение
[ редактировать ]- Гуджарати, Дамодар Н .; Портер, Дон К. (2009). Основная эконометрика (Пятое изд.). Нью-Йорк: МакГроу-Хилл/Ирвин. стр. 73–78. ISBN 978-0-07-337577-9 .
- Хьюз, Энн; Гравойг, Деннис (1971). Статистика: основа анализа . Чтение: Аддисон-Уэсли. стр. 344–348 . ISBN 0-201-03021-7 .
- Кмента, Ян (1986). Элементы эконометрики (второе изд.). Нью-Йорк: Макмиллан. стр. 240–243 . ISBN 978-0-02-365070-3 .
- Льюис-Бек, Майкл С .; Скалабан, Эндрю (1990). « R -квадрат: немного откровенного разговора». Политический анализ . 2 : 153–171. дои : 10.1093/пан/2.1.153 . JSTOR 23317769 .
- Чикко, Давиде; Уорренс, Маттейс Дж.; Юрман, Джузеппе (2021). «Коэффициент детерминации R-квадрат более информативен, чем SMAPE, MAE, MAPE, MSE и RMSE при оценке регрессионного анализа» . PeerJ Информатика . 7 (e623): e623. дои : 10.7717/peerj-cs.623 . ПМЦ 8279135 . ПМИД 34307865 .
| Базы данных органов управления : Национальные |
|---|