Простая линейная регрессия
Было предложено эту статью дисперсию средних и прогнозируемых ответов объединить в . ( Обсудить ) Предлагается с ноября 2023 г. |

| Часть серии о |
| Регрессионный анализ |
|---|
| Модели |
| Оценка |
| Фон |
В статистике — простая линейная регрессия ) (SLR это модель линейной регрессии с одной объясняющей переменной . [1] [2] [3] [4] [5] То есть он касается двумерных точек выборки с одной независимой переменной и одной зависимой переменной (обычно координаты x и y в декартовой системе координат ) и находит линейную функцию (невертикальную прямую ), которая с такой же точностью, как и возможно, прогнозирует значения зависимой переменной как функцию независимой переменной.Прилагательное простое относится к тому факту, что переменная результата связана с одним предиктором.
Обычно дополнительно оговаривается, что следует использовать обычный метод наименьших квадратов (OLS): точность каждого прогнозируемого значения измеряется его квадратом невязки (вертикальное расстояние между точкой набора данных и подобранной линией) и цель состоит в том, чтобы сделать сумму этих квадратов отклонений как можно меньшей. В этом случае наклон подобранной линии равен корреляции между y и x , скорректированной отношением стандартных отклонений этих переменных. Точка пересечения подобранной линии такова, что линия проходит через центр масс ( x , y ) точек данных.
Формулировка и расчет
[ редактировать ]Рассмотрим модельную функцию

которая описывает линию с наклоном β и y -пересечением α . В общем, такая связь может не соблюдаться в точности для практически ненаблюдаемой совокупности значений независимых и зависимых переменных; мы называем ненаблюдаемые отклонения от приведенного выше уравнения ошибками . Предположим, мы наблюдаем n пар данных и называем их {( x i , y i ), i = 1, ..., n }. Мы можем описать основную взаимосвязь между y i и x i, включающую этот ошибочный член ε i, следующим образом:

Эта связь между истинными (но ненаблюдаемыми) базовыми параметрами α и β и точками данных называется моделью линейной регрессии.
Цель – найти оценочные значения и для параметров α и β, которые в некотором смысле обеспечили бы «наилучшее» соответствие точкам данных. Как упоминалось во введении, в этой статье под «наилучшим» соответствием будет пониматься метод наименьших квадратов : линия, которая минимизирует сумму квадратов остатков (см. также Ошибки и остатки ). (разницы между фактическими и прогнозируемыми значениями зависимой переменной y ), каждое из которых определяется выражением для любых возможных значений параметра и ,






Другими словами, и решить следующую задачу минимизации :

где целевая функция Q :

Разложив, получим квадратное выражение в и мы можем вывести минимизирующие значения аргументов функции, обозначаемые и : [6]

![{\displaystyle {\begin{aligned}{\widehat {\alpha }}&={\bar {y}}-({\widehat {\beta }}\, {\bar {x}}),\\[ 5pt]{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\ бар {y}})}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}={\frac {\sum _{i =1}^{n}\Delta x_{i}\Delta y_{i}}{\sum _{i=1}^{n}\Delta x_{i}^{2}}}\end{aligned} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/59819b2ba266487624878946052a924ce01f12b4)
Здесь мы представили
- и как среднее значение x i и y i соответственно
- и как отклонения x y i и i . относительно их соответствующих средних значений




Расширенные формулы
[ редактировать ]Приведенные выше уравнения эффективно использовать, если среднее значение переменных x и y ( ) известны. Если на момент расчета средние значения неизвестны, возможно, будет более эффективно использовать расширенную версию уравнения. Эти расширенные уравнения могут быть получены из более общих полиномиальной регрессии. уравнений [7] [8] определив полином регрессии первого порядка следующим образом.



Вышеупомянутая система линейных уравнений может быть решена непосредственно или автономные уравнения для может быть получено путем расширения матричных уравнений, приведенных выше. Полученные уравнения алгебраически эквивалентны уравнениям, показанным в предыдущем абзаце, и показаны ниже без доказательства. [9] [7]
![{\displaystyle {\begin{aligned}&\qquad {\widehat {\alpha }}={\frac {\sum _{i=1}^{n}y_{i}\sum _{i=1}^ {n}x_{i}^{2}-\sum _{i=1}^{n}x_{i}\sum _{i=1}^{n}x_{i}y_{i}}{ n\sum _{i=1}^{n}x_{i}^{2}-(\sum _{i=1}^{n}x_{i})^{2}}}\\[5pt ]\\&\qquad {\widehat {\beta }}={\frac {n\sum _{i=1}^{n}x_{i}y_{i}-\sum _{i=1}^ {n}x_{i}\sum _{i=1}^{n}y_{i}}{n\sum _{i=1}^{n}x_{i}^{2}-(\sum _{i=1}^{n}x_{i})^{2}}}\\&\qquad \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6e22946f99289cf4bb175251c8f407edcaf4ab7)
Интерпретация
[ редактировать ]Связь с выборочной ковариационной матрицей
[ редактировать ]Решение можно переформулировать, используя элементы ковариационной матрицы :

где
- r xy — выборочный коэффициент корреляции между x и y.
- s x и s y — неисправленные выборочные стандартные отклонения x . и y
- и — выборочная дисперсия и выборочная ковариация соответственно


Подставив приведенные выше выражения на и в исходное решение дает

Это показывает, что r xy — это наклон линии регрессии стандартизированных точек данных (и что эта линия проходит через начало координат). С тогда мы получаем, что если x — какое-то измерение, а y — последующее измерение того же объекта, то мы ожидаем, что y (в среднем) будет ближе к среднему измерению, чем к исходному значению x. Это явление известно как регрессия к среднему значению .

Обобщая обозначения, мы можем написать горизонтальную полосу над выражением, чтобы указать среднее значение этого выражения по набору образцов. Например:

Эти обозначения позволяют нам получить краткую формулу для r xy :

Коэффициент детерминации («R в квадрате») равен когда модель линейна с одной независимой переменной. см . в примере коэффициента корреляции Дополнительные сведения .

Толкование про наклон
[ редактировать ]Умножив все члены суммы в числителе на: (при этом не меняя его):

![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})( y_{i}-{\bar {y}})}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}={\ frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}{\frac {(y_{i}-{\bar {y}}) }{(x_{i}-{\bar {x}})}}}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2} }}=\sum _{i=1}^{n}{\frac {(x_{i}-{\bar {x}})^{2}}{\sum _{j=1}^{n }(x_{j}-{\bar {x}})^{2}}}{\frac {(y_{i}-{\bar {y}})}{(x_{i}-{\bar {x}})}}\\[6pt]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc26c9980ced33c9461b7e9b8aece55f65677e00)
Мы видим, что наклон (тангенс угла) линии регрессии представляет собой средневзвешенное значение это наклон (тангенс угла) линии, соединяющей i-ю точку со средним значением всех точек, взвешенный по потому что чем дальше находится точка, тем она более «важна», поскольку небольшие ошибки в ее положении будут больше влиять на наклон, соединяющий ее с центральной точкой.


Толкование о перехвате
[ редактировать ]![{\displaystyle {\begin{aligned}{\widehat {\alpha }}&={\bar {y}}-{\widehat {\beta }}\,{\bar {x}},\\[5pt] \end{выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e5ec3259ace40cc2734621fc00464bc5b87bc3fc)
Данный с угол, который линия образует с положительной осью x, у нас есть



Интерпретация корреляции
[ редактировать ]В приведенной выше формулировке обратите внимание, что каждый является постоянным («известным заранее») значением, а являются случайными величинами, которые зависят от линейной функции и случайный член . Это предположение используется при определении стандартной ошибки наклона и демонстрации его несмещенности .



В этом контексте, когда на самом деле не является случайной величиной , какой тип параметра определяет эмпирическая корреляция? оценивать? Проблема в том, что для каждого значения i мы будем иметь: и . Возможная интерпретация это представить, что определяет случайную величину, полученную из эмпирического распределения значений x в нашей выборке. Например, если x имеет 10 значений натуральных чисел : [1,2,3...,10], то мы можем представить x как дискретное равномерное распределение . Согласно этой интерпретации все имеют одинаковое математическое ожидание и некоторую положительную дисперсию. Используя эту интерпретацию, мы можем думать о как средство оценки корреляции Пирсона между случайной величиной y и случайной величиной x (как мы только что ее определили).



Числовые свойства
[ редактировать ]- Линия регрессии проходит через точку центра масс , , если модель включает в себя термин-перехват (т. е. не принудительно проходит через начало координат).
- Сумма остатков равна нулю, если модель включает в себя член-перехват:
- Остатки и значения x не коррелируют (независимо от того, есть ли в модели член пересечения), что означает:
- Отношения между ( коэффициент корреляции для совокупности ) и популяционные дисперсии ( ) и член ошибки ( ) является: [10] : 401
- Для крайних значений это само собой разумеется. С каких пор затем . И когда затем .













Статистические свойства
[ редактировать ]Описание статистических свойств оценок на основе оценок простой линейной регрессии требует использования статистической модели . Следующее основано на предположении о справедливости модели, согласно которой оценки оптимальны. Также возможно оценить свойства при других предположениях, таких как неоднородность , но это обсуждается в другом месте. [ нужны разъяснения ]
Беспристрастность
[ редактировать ]Оценщики и являются беспристрастными .
Чтобы формализовать это утверждение, мы должны определить структуру, в которой эти оценки являются случайными величинами. Мы рассматриваем остатки ε i как случайные величины, полученные независимо от некоторого распределения со средним нулевым значением. Другими словами, для каждого значения x соответствующее значение y генерируется как средний отклик α + βx плюс дополнительная случайная величина ε , называемая членом ошибки , равная в среднем нулю. При такой интерпретации оценки методом наименьших квадратов и сами будут случайными величинами, средние значения которых будут равны «истинным значениям» α и β . Это определение несмещенной оценки.
Доверительные интервалы
[ редактировать ]приведенные в предыдущем разделе, позволяют рассчитать точечные оценки α Формулы , и β — то есть коэффициенты линии регрессии для заданного набора данных. Однако эти формулы не говорят нам, насколько точны оценки, т. е. насколько оценки и варьируются от выборки к выборке для заданного размера выборки. Доверительные интервалы были разработаны для того, чтобы дать правдоподобный набор значений оценкам, которые можно было бы получить, если бы эксперимент повторялся очень большое количество раз.
Стандартный метод построения доверительных интервалов для коэффициентов линейной регрессии основан на предположении о нормальности, которое оправдано, если:
- ошибки в регрессии распределены нормально (так называемое классическое предположение о регрессии ), или
- количество наблюдений n достаточно велико, и в этом случае оценка имеет приблизительно нормальное распределение.
Последний случай оправдывается центральной предельной теоремой .
Предположение о нормальности
[ редактировать ]При первом предположении, приведенном выше, о нормальности членов ошибки, оценка коэффициента наклона сама будет нормально распределяться со средним значением β и дисперсией. где σ 2 — это дисперсия членов ошибки (см. Доказательства с использованием обычных наименьших квадратов ). При этом сумма квадратов невязок Q распределяется пропорционально χ 2 с n − 2 степенями свободы и независимо от . Это позволяет нам построить t -значение


где

является несмещенной оценкой стандартной ошибки оценщика .
Это значение t имеет -распределение Стьюдента t с n - 2 степенями свободы. Используя его, мы можем построить доверительный интервал для β :
![{\displaystyle \beta \in \left[{\widehat {\beta }}-s_ {\widehat {\beta }}t_ {n-2}^{*}, \ {\widehat {\beta }}+s_ {\widehat {\beta }}t_{n-2}^{*}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98a15da255d6643725a6bd9b50d02b3f6c2c497f)
на уровне доверия (1 − γ ) , где это квантиль распределения t n −2 . Например, если γ = 0,05 , то уровень достоверности составляет 95%.


Аналогично, доверительный интервал для коэффициента пересечения α определяется выражением
![{\displaystyle \alpha \in \left[{\widehat {\alpha }}-s_ {\widehat {\alpha }}t_ {n-2}^{*}, \ {\widehat {\alpha }}+s_ {\widehat {\alpha }}t_{n-2}^{*}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6085d0ecef794ef2f78a3d3e0f9802acb9a4aada)
на уровне достоверности (1 − γ ), где

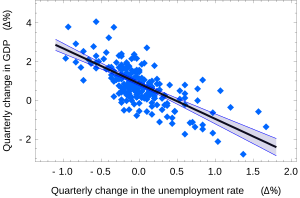
Доверительные интервалы для α и β дают нам общее представление о том, где, скорее всего, будут находиться эти коэффициенты регрессии. Например, в показанной здесь регрессии по закону Оукена точечные оценки равны

95% доверительные интервалы для этих оценок составляют
![{\displaystyle \alpha \in \left[\,0,76,0,96\right],\qquad \beta \in \left[-2,06,-1,58\,\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aca739a7d1ecc8fdddffbdea549b9acba00b464d)
Чтобы представить эту информацию графически, в виде доверительных полос вокруг линии регрессии, необходимо действовать осторожно и учитывать совместное распределение оценок. Это можно показать [11] что на уровне достоверности (1 − γ ) доверительный интервал имеет гиперболическую форму, заданную уравнением
![{\displaystyle (\alpha +\beta \xi)\in \left[\,{\widehat {\alpha }}+{\widehat {\beta }}\xi \pm t_ {n-2}^{*} {\sqrt {\left({\frac {1}{n-2}}\sum {\widehat {\varepsilon }}_{i}^{\,2}\right)\cdot \left({\frac {1}{n}}+{\frac {(\xi -{\bar {x}})^{2}}{\sum (x_{i}-{\bar {x}})^{2} }}\вправо)}}\,\вправо].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7007e876b527e8f59c394898488fd150df4b9f61)
Когда модель предполагала, что точка пересечения фиксирована и равна 0 ( ), стандартная ошибка наклона превращается в:


С:

Асимптотическое предположение
[ редактировать ]Альтернативное второе предположение гласит, что, когда количество точек в наборе данных «достаточно велико», становятся применимыми закон больших чисел и центральная предельная теорема , и тогда распределение оценок становится примерно нормальным. полученные в предыдущем разделе, остаются в силе, за исключением того, что квантиль t* n −2 Стьюдента При этом предположении все формулы , распределения заменяется квантилем q* стандартного нормального распределения . Иногда дробь 1 / n −2 заменяется на 1 / п . Когда n велико, такое изменение существенно не меняет результаты.
Численный пример
[ редактировать ]Этот набор данных дает среднюю массу женщин в зависимости от их роста в выборке американских женщин в возрасте 30–39 лет. Хотя в статье OLS утверждается, что для этих данных было бы более целесообразно использовать квадратичную регрессию, вместо этого здесь применяется простая модель линейной регрессии.
Высота (м), x i 1.47 1.50 1.52 1.55 1.57 1.60 1.63 1.65 1.68 1.70 1.73 1.75 1.78 1.80 1.83 Масса (кг), y i 52.21 53.12 54.48 55.84 57.20 58.57 59.93 61.29 63.11 64.47 66.28 68.10 69.92 72.19 74.46
| 1 | 1.47 | 52.21 | 2.1609 | 76.7487 | 2725.8841 |
| 2 | 1.50 | 53.12 | 2.2500 | 79.6800 | 2821.7344 |
| 3 | 1.52 | 54.48 | 2.3104 | 82.8096 | 2968.0704 |
| 4 | 1.55 | 55.84 | 2.4025 | 86.5520 | 3118.1056 |
| 5 | 1.57 | 57.20 | 2.4649 | 89.8040 | 3271.8400 |
| 6 | 1.60 | 58.57 | 2.5600 | 93.7120 | 3430.4449 |
| 7 | 1.63 | 59.93 | 2.6569 | 97.6859 | 3591.6049 |
| 8 | 1.65 | 61.29 | 2.7225 | 101.1285 | 3756.4641 |
| 9 | 1.68 | 63.11 | 2.8224 | 106.0248 | 3982.8721 |
| 10 | 1.70 | 64.47 | 2.8900 | 109.5990 | 4156.3809 |
| 11 | 1.73 | 66.28 | 2.9929 | 114.6644 | 4393.0384 |
| 12 | 1.75 | 68.10 | 3.0625 | 119.1750 | 4637.6100 |
| 13 | 1.78 | 69.92 | 3.1684 | 124.4576 | 4888.8064 |
| 14 | 1.80 | 72.19 | 3.2400 | 129.9420 | 5211.3961 |
| 15 | 1.83 | 74.46 | 3.3489 | 136.2618 | 5544.2916 |
| 24.76 | 931.17 | 41.0532 | 1548.2453 | 58498.5439 |





В этом наборе данных n = 15 точек. Ручные вычисления можно было бы начать с нахождения следующих пяти сумм:
![{\displaystyle {\begin{aligned}S_{x}&=\sum x_{i}\,=24.76,\qquad S_{y}=\sum y_{i}\,=931.17,\\[5pt]S_ {xx}&=\sum x_{i}^{2}=41.0532,\;\;\,S_{yy}=\sum y_{i}^{2}=58498.5439,\\[5pt]S_{xy }&=\sum x_{i}y_{i}=1548.2453\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a239d81a6a9897b666146526c8252a18d2603adf)
Эти величины будут использоваться для расчета оценок коэффициентов регрессии и их стандартных ошибок.
![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {nS_{xy}-S_{x}S_{y}}{nS_{xx}-S_{x}^{2 }}}=61.272\\[8pt]{\widehat {\alpha }}&={\frac {1}{n}}S_{y}-{\widehat {\beta }}{\frac {1}{ n}}S_{x}=-39.062\\[8pt]s_{\varepsilon }^{2}&={\frac {1}{n(n-2)}}\left[nS_{yy}-S_ {y}^{2}-{\widehat {\beta }}^{2}(nS_{xx}-S_{x}^{2})\right]=0,5762\\[8pt]s_{\widehat { \beta }}^{2}&={\frac {ns_{\varepsilon }^{2}}{nS_{xx}-S_{x}^{2}}}=3.1539\\[8pt]s_{\ Widehat {\alpha }}^{2}&=s_{\widehat {\beta }}^{2}{\frac {1}{n}}S_{xx}=8.63185\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c171ecde06fcbcb38ea0c3e080b7c14efcfdd96)
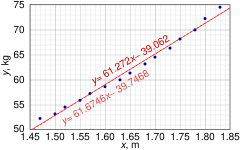
-распределения Стьюдента Квантиль 0,975 t с 13 степенями свободы равен t * 13 = 2,1604 , и, таким образом, 95% доверительные интервалы для α и β равны
![{\displaystyle {\begin{aligned}&\alpha \in [\,{\widehat {\alpha }}\mp t_{13}^{*}s_{\alpha }\,]=[\,{-45.4 },\ {-32.7}\,]\\[5pt]&\beta \in [\,{\widehat {\beta }}\mp t_{13}^{*}s_{\beta }\,]= [\,57.4,\ 65.1\,]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f1e96281c93edfc8cb8e830744328f62081c8010)
Коэффициент корреляции момента продукта также может быть рассчитан:

Альтернативы
[ редактировать ]
В SLR лежит допущение, что только зависимая переменная содержит ошибку измерения; если независимая переменная также измеряется с ошибкой, то простая регрессия не подходит для оценки базовой взаимосвязи, поскольку она будет смещена из-за разбавления регрессии .
Другие методы оценки, которые можно использовать вместо обычных методов наименьших квадратов, включают метод наименьших абсолютных отклонений (минимизация суммы абсолютных значений остатков) и оценщик Тейла – Сена (который выбирает линию, наклон которой является медианой наклонов, определяемых парами точки отбора проб).
Регрессия Деминга (полные наименьшие квадраты) также находит линию, которая соответствует набору двумерных точек выборки, но (в отличие от обычных методов наименьших квадратов, регрессии наименьших абсолютных отклонений и регрессии медианного наклона) на самом деле это не пример простой линейной регрессии, потому что он не разделяет координаты на одну зависимую и одну независимую переменную и потенциально может возвращать вертикальную линию в соответствии с ней. может привести к модели, которая пытается соответствовать выбросам больше, чем данным.
Линия фитинга
[ редактировать ]Подбор линии — это процесс построения прямой линии , которая наилучшим образом соответствует ряду точек данных.
Существует несколько методов, учитывая:
- Вертикальное расстояние: простая линейная регрессия
- Устойчивость к выбросам : надежная простая линейная регрессия.
- Перпендикулярное расстояние : ортогональная регрессия
- Взвешенное геометрическое расстояние: регрессия Деминга
- Масштабная инвариантность : регрессия по главной оси
Простая линейная регрессия без члена (одиночный регрессор)
[ редактировать ]Иногда целесообразно заставить линию регрессии проходить через начало координат, поскольку x и y предполагается, что пропорциональны. Для модели без члена-члена y = βx оценка МНК для β упрощается до

Замена ( x − h , y − k ) вместо ( x , y ) дает регрессию через ( h , k ) :
![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}(x_{i}-h)(y_{i}-k )}{\sum _{i=1}^{n}(x_{i}-h)^{2}}}={\frac {\overline {(xh)(yk)}}{\overline {( xh)^{2}}}}\\[6pt]&={\frac {{\overline {xy}}-k{\bar {x}}-h{\bar {y}}+hk}{{ \overline {x^{2}}}-2h{\bar {x}}+h^{2}}}\\[6pt]&={\frac {{\overline {xy}}-{\bar { x}}{\bar {y}}+({\bar {x}}-h)({\bar {y}}-k)}{{\overline {x^{2}}}-{\bar {x}}^{2}+({\bar {x}}-h)^{2}}}\\[6pt]&={\frac {\operatorname {Cov} (x,y)+({ \bar {x}}-h)({\bar {y}}-k)}{\operatorname {Var} (x)+({\bar {x}}-h)^{2}}},\ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d49812c28d9bc6840e891d5d04ae52a83397b840)
где Cov и Var относятся к ковариации и дисперсии выборочных данных (без поправки на систематическую ошибку).Последняя форма выше демонстрирует, как перемещение линии от центра масс точек данных влияет на наклон.
См. также
[ редактировать ]- Матрица проектирования # Простая линейная регрессия
- Оценка линейного тренда
- Линейная сегментированная регрессия
- Доказательства с использованием обычных наименьших квадратов - вывод всех формул, использованных в этой статье, в общем многомерном случае.
- Оценщик Ньюи – Уэста
Ссылки
[ редактировать ]- ^ Селтман, Ховард Дж. (8 сентября 2008 г.). Экспериментальный дизайн и анализ (PDF) . п. 227.
- ^ «Статистическая выборка и регрессия: простая линейная регрессия» . Колумбийский университет . Проверено 17 октября 2016 г.
Когда в регрессии используется одна независимая переменная, она называется простой регрессией; (...)
- ^ Лейн, Дэвид М. Введение в статистику (PDF) . п. 462.
- ^ Цзоу К.Х.; Тункали К; Сильверман С.Г. (2003). «Корреляция и простая линейная регрессия» . Радиология . 227 (3): 617–22. дои : 10.1148/radiol.2273011499 . ISSN 0033-8419 . ОСЛК 110941167 . ПМИД 12773666 .
- ^ Альтман, Наоми; Кшивинский, Мартин (2015). «Простая линейная регрессия» . Природные методы . 12 (11): 999–1000. дои : 10.1038/nmeth.3627 . ISSN 1548-7091 . OCLC 5912005539 . ПМИД 26824102 . S2CID 261269711 .
- ^ Кенни, Дж. Ф. и Кингинг, Э. С. (1962) «Линейная регрессия и корреляция». Ч. 15 по математике и статистике , Pt. 1, 3-е изд. Принстон, Нью-Джерси: Ван Ностранд, стр. 252–285.
- ^ Jump up to: а б Мутукришнан, Гоури (17 июня 2018 г.). «Математика полиномиальной регрессии, Мутукришнан» . Математика, лежащая в основе полиномиальной регрессии . Проверено 30 января 2024 г.
- ^ «Математика полиномиальной регрессии» . Полиномиальная регрессия. Класс регрессии PHP .
- ^ «Счет, математика и статистика — комплект академических навыков, Университет Ньюкасла» . Простая линейная регрессия . Проверено 30 января 2024 г.
- ^ Валиант, Ричард, Джилл А. Девер и Фрауке Кройтер. Практические инструменты для составления и взвешивания выборок обследований. Нью-Йорк: Спрингер, 2013.
- ^ Казелла, Г. и Бергер, Р.Л. (2002), «Статистический вывод» (2-е издание), Cengage, ISBN 978-0-534-24312-8 , стр. 558–559.