Анализ текста
Интеллектуальный анализ текста , анализ текстовых данных ( TDM ) или текстовая аналитика — это процесс извлечения высококачественной информации из текста . Он предполагает «открытие компьютером новой, ранее неизвестной информации путем автоматического извлечения информации из различных письменных ресурсов». [1] Письменные ресурсы могут включать веб-сайты , книги , электронные письма , обзоры и статьи. Высококачественная информация обычно получается путем выявления закономерностей и тенденций с помощью таких средств, как статистическое изучение закономерностей . По данным Хото и др. (2005) мы можем различать три различных подхода к интеллектуальному анализу текста: извлечение информации , интеллектуальный анализ данных и процесс обнаружения знаний в базах данных (KDD). [2] Интеллектуальный анализ текста обычно включает в себя процесс структурирования входного текста (обычно синтаксический анализ вместе с добавлением некоторых производных лингвистических функций и удалением других, а также последующую вставку в базу данных ), получение шаблонов в структурированных данных и, наконец, оценку и интерпретацию. вывода. «Высокое качество» при интеллектуальном анализе текста обычно означает некоторую комбинацию релевантности , новизны и интереса. Типичные задачи интеллектуального анализа текста включают категоризацию текста , кластеризацию текста , извлечение концепций/сущностей, создание детальной таксономии, анализ настроений , обобщение документов и моделирование отношений сущностей ( т. е . изучение связей между именованными сущностями ).
Анализ текста включает в себя поиск информации , лексический анализ для изучения распределения частот слов, распознавание образов , тегирование / аннотации , извлечение информации , методы интеллектуального анализа данных , включая анализ связей и ассоциаций, визуализацию и прогнозную аналитику . Основная цель, по сути, состоит в том, чтобы превратить текст в данные для анализа с помощью применения обработки естественного языка (НЛП), различных типов алгоритмов и аналитических методов. Важным этапом этого процесса является интерпретация собранной информации.
Типичным применением является сканирование набора документов, написанных на естественном языке , и либо моделирование набора документов для целей прогнозной классификации , либо заполнение базы данных или поискового индекса извлеченной информацией. Документ . является основным элементом при начале анализа текста Здесь мы определяем документ как единицу текстовых данных, которая обычно существует во многих типах коллекций. [3]
Текстовая аналитика [ править ]
Текстовый анализ описывает набор лингвистических , статистических и машинных методов обучения, которые моделируют и структурируют информационный контент текстовых источников для бизнес-аналитики , исследовательского анализа данных , исследований или расследований. [4] Этот термин является примерно синонимом интеллектуального анализа текста; действительно, Ронен Фельдман изменил описание «интеллектуального анализа текста» 2000 года. [5] в 2004 году для описания «текстовой аналитики». [6] Последний термин сейчас чаще используется в бизнес-среде, тогда как «интеллектуальный анализ текста» используется в некоторых из самых ранних областей применения, начиная с 1980-х годов. [7] особенно исследования в области наук о жизни и правительственная разведка.
Термин «текстовая аналитика» также описывает применение текстовой аналитики для реагирования на бизнес-проблемы независимо или в сочетании с запросом и анализом полевых числовых данных. Общеизвестно, что 80 процентов деловой информации возникает в неструктурированной форме, в основном в текстовой форме. [8] Эти методы и процессы обнаруживают и представляют знания – факты, бизнес-правила и отношения – которые в противном случае заперты в текстовой форме и недоступны для автоматической обработки.
Процессы анализа текста [ править ]
Подзадачи — компоненты более масштабной работы по анализу текста — обычно включают в себя:
- Уменьшение размерности является важным методом предварительной обработки данных. Этот метод используется для определения корневого слова реальных слов и уменьшения размера текстовых данных. [ нужна ссылка ]
- Поиск информации или идентификация корпуса — это подготовительный этап: сбор или идентификация набора текстовых материалов, находящихся в Интернете или хранящихся в файловой системе , базе данных или менеджере корпуса контента , для анализа.
- Хотя некоторые системы анализа текста применяют исключительно передовые статистические методы, многие другие применяют более обширную обработку естественного языка , такую как часть речевых тегов , синтаксический анализ и другие виды лингвистического анализа. [9]
- Распознавание именованного объекта — это использование справочников или статистических методов для идентификации названных элементов текста: людей, организаций, географических названий, биржевых символов, определенных сокращений и т. д.
- Устранение неоднозначности — использование контекстуальных подсказок — может потребоваться, чтобы решить, где, например, «Форд» может относиться к бывшему президенту США, производителю автомобилей, кинозвезде, переправе через реку или какому-либо другому объекту. [10]
- Распознавание объектов, идентифицируемых по шаблону. Такие функции, как номера телефонов, адреса электронной почты, количества (с единицами измерения), можно распознать с помощью регулярных выражений или других сопоставлений с шаблонами .
- Кластеризация документов : идентификация наборов похожих текстовых документов. [11]
- Кореферентность : идентификация именной группы и других терминов, относящихся к одному и тому же объекту.
- Связь, факт и событие. Извлечение: выявление ассоциаций между объектами и другой информацией в текстах.
- Анализ настроений включает в себя различение субъективного (в отличие от фактического) материала и извлечение различных форм информации об отношениях: чувств, мнений, настроений и эмоций. Методы анализа текста помогают анализировать настроения на уровне сущности, концепции или темы и различать держателей мнений и объектов. [12]
- Количественный анализ текста — это набор методов, зародившихся в социальных науках, где либо человек-судья, либо компьютер извлекает семантические или грамматические отношения между словами, чтобы выяснить значение или стилистические закономерности, обычно случайного личного текста, с целью психологическое профилирование и т. д. [13]
- Предварительная обработка обычно включает в себя такие задачи, как токенизация, фильтрация и стемминг.
Приложения [ править ]
Технология интеллектуального анализа текста в настоящее время широко применяется для решения широкого круга задач правительства, исследований и бизнеса. Все эти группы могут использовать анализ текста для управления записями и поиска документов, имеющих отношение к их повседневной деятельности. юристы могут использовать интеллектуальный анализ текста для обнаружения электронных данных Например, . Правительства и военные группировки используют анализ текста в целях национальной безопасности и разведки. Научные исследователи включают подходы интеллектуального анализа текста в усилия по организации больших наборов текстовых данных (т. е. для решения проблемы неструктурированных данных ), для определения идей, передаваемых через текст (например, анализ настроений в социальных сетях). [14] [15] [16] ) и поддерживать научные открытия в таких областях, как науки о жизни и биоинформатика . В бизнесе приложения используются для поддержки конкурентной разведки и автоматического размещения рекламы , а также для множества других действий.
Приложения безопасности [ править ]
Многие пакеты программного обеспечения для интеллектуального анализа текста продаются для приложений безопасности , особенно для мониторинга и анализа онлайн-источников простого текста, таких как новости Интернета , блоги и т. д., в целях национальной безопасности . [17] Он также занимается изучением шифрования / дешифрования текста .
приложения Биомедицинские

Был описан ряд приложений интеллектуального анализа текста в биомедицинской литературе: [19] включая вычислительные подходы для помощи в исследованиях стыковки белков , [20] белковые взаимодействия , [21] [22] и ассоциации белковых заболеваний. [23] Кроме того, благодаря большим наборам текстовых данных о пациентах в клинической области, наборам демографических данных в популяционных исследованиях и отчетам о нежелательных явлениях интеллектуальный анализ текста может облегчить клинические исследования и точную медицину. Алгоритмы интеллектуального анализа текста могут облегчить стратификацию и индексацию конкретных клинических событий в больших наборах текстовых данных пациентов о симптомах, побочных эффектах и сопутствующих заболеваниях из электронных медицинских карт, отчетов о событиях и отчетов о конкретных диагностических тестах. [24] Одним из онлайн-приложений для интеллектуального анализа текста в биомедицинской литературе является PubGene , общедоступная поисковая система , которая сочетает в себе биомедицинский анализ текста с сетевой визуализацией. [25] [26] GoPubMed — это основанная на знаниях поисковая система по биомедицинским текстам. Методы интеллектуального анализа текста также позволяют нам извлекать неизвестные знания из неструктурированных документов в клинической области. [27]
Программные приложения [ править ]
Методы и программное обеспечение для интеллектуального анализа текста также исследуются и разрабатываются крупными фирмами, включая IBM и Microsoft , для дальнейшей автоматизации процессов интеллектуального анализа и анализа, а также различными фирмами, работающими в области поиска и индексирования в целом, как способа улучшения своих результатов. . В государственном секторе много усилий было сосредоточено на создании программного обеспечения для отслеживания и мониторинга террористической деятельности . [28] В учебных целях программное обеспечение Weka является одним из самых популярных вариантов в научном мире и служит отличной отправной точкой для новичков. Для программистов Python существует отличный инструментарий NLTK для более общих целей. Для более продвинутых программистов есть также библиотека Gensim , которая фокусируется на текстовых представлениях на основе встраивания слов.
Приложения онлайн-медиа [ править ]
Анализ текста используется крупными медиакомпаниями, такими как Tribune Company , для уточнения информации и предоставления читателям более удобных возможностей поиска, что, в свою очередь, увеличивает «прилипчивость» сайта и доходы. Кроме того, редакторы получают выгоду от возможности делиться, связывать и упаковывать новости между ресурсами, что значительно увеличивает возможности монетизации контента.
Бизнес и маркетинговые приложения [ править ]
Текстовая аналитика используется в бизнесе, в частности, в маркетинге, например, в управлении взаимоотношениями с клиентами . [29] Куссеман и Ван ден Поэль (2008) [30] [31] примените его для улучшения моделей прогнозной аналитики оттока клиентов ( истощения клиентов ). [30] Анализ текста также применяется для прогнозирования доходности акций. [32]
Анализ настроений [ править ]
Анализ настроений может включать в себя анализ таких продуктов, как фильмы, книги или обзоры отелей, для оценки того, насколько благоприятным является отзыв о продукте. [33] Для такого анализа может потребоваться размеченный набор данных или маркировка эффективности слов . созданы ресурсы по эффективности слов и понятий. Для WordNet [34] и КонцептНет , [35] соответственно.
Текст использовался для обнаружения эмоций в соответствующей области аффективных вычислений. [36] Текстовые подходы к аффективным вычислениям использовались во многих корпусах, таких как оценки учащихся, детские рассказы и новости.
Научная литература по горному делу приложениям и академическим
Проблема анализа текста важна для издателей, которые владеют большими базами данных с информацией, требующей индексации для поиска. Это особенно актуально для научных дисциплин, в которых в письменном тексте часто содержится весьма специфическая информация. Поэтому были предприняты такие инициативы, как предложение Nature по интерфейсу интеллектуального анализа открытого текста (OTMI) и (DTD) Национального института здравоохранения для публикации журнала общее определение типа документа , которое будет предоставлять машинам семантические подсказки для ответа на конкретные запросы, содержащиеся в текст, не снимая барьеров издателей для публичного доступа.
Академические учреждения также присоединились к инициативе интеллектуального анализа текста:
- Национальный центр интеллектуального анализа текста (NaCTeM) — первый в мире центр интеллектуального анализа текста, финансируемый государством. NaCTeM находится в ведении Манчестерского университета. [37] в тесном сотрудничестве с лабораторией Tsujii, [38] Токийский университет . [39] NaCTeM предоставляет индивидуальные инструменты, исследовательские возможности и дает советы академическому сообществу. Они финансируются Объединенным комитетом информационных систем (JISC) и двумя исследовательскими советами Великобритании ( EPSRC и BBSRC ). Первоначально исследования были сосредоточены на интеллектуальном анализе текста в биологических и биомедицинских науках, а затем расширились и на области социальных наук .
- В Соединенных Штатах Школа информации разрабатывает Калифорнийского университета в Беркли программу под названием BioText, которая поможет исследователям -биологам в извлечении и анализе текста.
- Портал анализа текста для исследований (TAPoR), в настоящее время расположенный в Университете Альберты , представляет собой научный проект по каталогизации приложений анализа текста и созданию портала для исследователей, впервые знакомых с этой практикой.
Методы добычи научной литературы [ править ]
Вычислительные методы были разработаны для помощи в поиске информации из научной литературы. Опубликованные подходы включают методы поиска, [40] определение новизны, [41] и уточнение омонимов [42] среди технических отчетов.
Цифровые гуманитарные науки компьютерная социология и
Автоматический анализ обширных текстовых корпусов дал ученым возможность анализироватьмиллионы документов на нескольких языках с очень ограниченным ручным вмешательством. Ключевыми технологиями являются синтаксический анализ, машинный перевод тем , категоризация и машинное обучение.
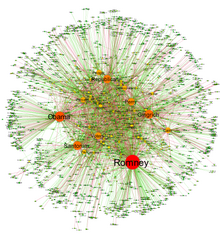
Автоматический анализ текстовых корпусов позволил извлекать акторов и их реляционные сети в огромных масштабах, превращая текстовые данные в сетевые данные. Полученные сети, которые могут содержать тысячи узлов, затем анализируются с использованием инструментов теории сетей для определения ключевых участников, ключевых сообществ или сторон, а также общих свойств, таких как надежность или структурная стабильность всей сети или центральность определенных узлы. [44] Это автоматизирует подход, представленный количественным нарративным анализом, [45] при этом тройки субъект-глагол-объект отождествляются с парами актеров, связанных действием, или парами, образованными актером-объектом. [43]
Контент-анализ уже давно стал традиционной частью социальных наук и медиаисследований. Автоматизация контент-анализа позволила совершить революцию « больших данных » в этой области: исследования социальных сетей и газетного контента включают миллионы новостей. Гендерная предвзятость , читабельность , сходство содержания, предпочтения читателей и даже настроение были проанализированы на основе методов анализа текста на миллионах документов. [46] [47] [48] [49] [50] Анализ читабельности, гендерной предвзятости и тематической предвзятости был продемонстрирован Flaounas et al. [51] показывая, как разные темы имеют разные гендерные предубеждения и уровни читабельности; Также была продемонстрирована возможность выявления моделей настроения у огромной популяции путем анализа контента Twitter. [52] [53]
Программное обеспечение [ править ]
Компьютерные программы для анализа текста доступны во многих коммерческих компаниях и с открытым исходным кодом источниках .
Закон об интеллектуальной собственности [ править ]
Ситуация в Европе [ править ]
Согласно европейским об авторском праве и законам базах данных , добыча произведений, защищенных авторскими правами (например, веб-майнинг ) без разрешения владельца авторских прав является незаконной. В Великобритании в 2014 году по рекомендации обзора Харгривза правительство внесло поправки в закон об авторском праве. [54] разрешить интеллектуальный анализ текста в качестве ограничения и исключения . Это была вторая страна в мире, сделавшая это после Японии , которая в 2009 году ввела исключение, касающееся горнодобывающей промышленности. Однако из-за ограничений Директивы об информационном обществе (2001 года) исключение в Великобритании разрешает добычу контента только для не- коммерческих целях. Законодательство Великобритании об авторском праве не позволяет отменять это положение договорными условиями.
Европейская комиссия способствовала обсуждению заинтересованных сторон по интеллектуальному анализу текста и данных в 2013 году под названием «Лицензии для Европы». [55] Тот факт, что в решении этого юридического вопроса основное внимание уделялось лицензиям, а не ограничениям и исключениям из закона об авторском праве, заставил представителей университетов, исследователей, библиотек, групп гражданского общества и издателей открытого доступа покинуть диалог с заинтересованными сторонами в мае 2013 года. [56]
Ситуация в США [ править ]
Закон США об авторском праве и, в частности, его положения о добросовестном использовании означают, что майнинг текста в Америке, а также в других странах добросовестного использования, таких как Израиль, Тайвань и Южная Корея, считается законным. Поскольку интеллектуальный анализ текста является преобразующим, то есть не заменяет оригинальную работу, он считается законным при добросовестном использовании. Например, в рамках мирового соглашения по Google Book председательствующий судья по делу постановил, что проект Google по оцифровке книг, защищенных авторскими правами, был законным, отчасти из-за преобразующего использования, которое продемонстрировал проект оцифровки - одним из таких применений является интеллектуальный анализ текста и данных. . [57]
Ситуация в Австралии [ править ]
нет исключений В австралийском законе об авторском праве для интеллектуального анализа текста или данных в рамках Закона об авторском праве 1968 года . Австралийская комиссия по реформе законодательства отметила, что маловероятно, что исключение в отношении добросовестной деловой практики в отношении «исследований и исследований» будет распространяться и на такую тему, поскольку оно будет выходить за рамки требования «разумной доли». [58]
Последствия [ править ]
До недавнего времени веб-сайты чаще всего использовали текстовый поиск, при котором находили только документы, содержащие определенные пользователем слова или фразы. Теперь, благодаря использованию семантической сети , анализ текста может находить контент на основе значения и контекста (а не только по конкретному слову). Кроме того, программное обеспечение для интеллектуального анализа текста можно использовать для создания больших досье информации о конкретных людях и событиях. Например, можно создавать большие наборы данных на основе данных, извлеченных из новостных сообщений, для облегчения анализа социальных сетей или контрразведки . По сути, программное обеспечение для интеллектуального анализа текста может действовать в качестве аналитика разведки или библиотекаря-исследователя, хотя и с более ограниченным объемом анализа. Анализ текста также используется в некоторых спам-фильтрах электронной почты как способ определения характеристик сообщений, которые могут быть рекламой или другим нежелательным материалом. Анализ текста играет важную роль в определении настроений финансового рынка .
См. также [ править ]
- Концепция майнинга
- Обработка документов
- Полнотекстовый поиск
- Список программного обеспечения для интеллектуального анализа текста
- Настроения рынка
- Разрешение имен (семантика и извлечение текста)
- Распознавание названного объекта
- Новостная аналитика
- Обучение онтологии
- Связь с записью
- Последовательный анализ шаблонов (интеллектуальный анализ строк и последовательностей)
- ш-черепица
- Веб-майнинг — задача, которая может включать в себя анализ текста (например, сначала найти подходящие веб-страницы путем классификации просканированных веб-страниц, а затем извлечь нужную информацию из текстового содержимого этих страниц, которые считаются релевантными).
Ссылки [ править ]
Цитаты [ править ]
- ^ «Марти Херст: Что такое анализ текста?» .
- ^ Хото А., Нюрнбергер А. и Паас Г. (2005). «Краткий обзор интеллектуального анализа текста». В Ldv Forum, Vol. 20(1), с. 19-62
- ^ Фельдман Р. и Сэнгер Дж. (2007). Руководство по текстовому майнингу. Издательство Кембриджского университета. Нью-Йорк
- ^ [1] Архивировано 29 ноября 2009 г. в Wayback Machine.
- ^ «Семинар KDD-2000 по интеллектуальному анализу текста - прием докладов» . Cs.cmu.edu . Проверено 23 февраля 2015 г.
- ^ [2] Архивировано 3 марта 2012 г., в Wayback Machine.
- ^ Хоббс, Джерри Р.; Уокер, Дональд Э.; Амслер, Роберт А. (1982). «Доступ к структурированному тексту на естественном языке». Материалы 9-й конференции по компьютерной лингвистике . Том. 1. С. 127–32. дои : 10.3115/991813.991833 . S2CID 6433117 .
- ^ «Неструктурированные данные и правило 80 процентов» . Прорывной анализ. Август 2008 года . Проверено 23 февраля 2015 г.
- ^ Антунес, Жуан (14 ноября 2018 г.). Использование контекстной информации для семантического обогащения текстовых представлений (дипломная работа на степень магистра в области компьютерных наук и вычислительной математики) (на португальском языке). Сан-Карлос: Университет Сан-Паулу. doi : 10.11606/d.55.2019.tde-03012019-103253 .
- ^ Моро, Андреа; Раганато, Алессандро; Навильи, Роберто (декабрь 2014 г.). «Связывание сущностей и устранение неоднозначности смысла слов: единый подход» . Труды Ассоциации компьютерной лингвистики . 2 : 231–244. дои : 10.1162/tacl_a_00179 . ISSN 2307-387X .
- ^ Чанг, Уи Ли; Тай, Кай Мэн; Лим, Чи Пэн (06 февраля 2017 г.). «Новая развивающаяся древовидная модель с локальным повторным обучением для кластеризации и визуализации документов». Нейронная обработка писем . 46 (2): 379–409. дои : 10.1007/s11063-017-9597-3 . ISSN 1370-4621 . S2CID 9100902 .
- ^ Бенчимол, Джонатан; Казинник, Софья; Саадон, Йоси (2022). «Методологии интеллектуального анализа текста с помощью R: приложение к текстам центральных банков» . Машинное обучение с приложениями . 8 : 100286. дои : 10.1016/j.mlwa.2022.100286 . S2CID 243798160 .
- ^ Мель, Матиас Р. (2006). «Количественный анализ текста». Справочник по мультиметодическому измерению в психологии . п. 141. дои : 10.1037/11383-011 . ISBN 978-1-59147-318-3 .
- ^ Панг, Бо; Ли, Лилиан (2008). «Анализ мнений и анализ настроений». Основы и тенденции в области информационного поиска . 2 (1–2): 1–135. CiteSeerX 10.1.1.147.2755 . дои : 10.1561/1500000011 . ISSN 1554-0669 . S2CID 207178694 .
- ^ Палтоглу, Георгиос; Телвалл, Майк (1 сентября 2012 г.). «Twitter, MySpace, Digg: неконтролируемый анализ настроений в социальных сетях». Транзакции ACM в интеллектуальных системах и технологиях . 3 (4): 66. дои : 10.1145/2337542.2337551 . ISSN 2157-6904 . S2CID 16600444 .
- ^ «Анализ настроений в Твиттере < SemEval-2017, Задание 4» . alt.qcri.org . Проверено 02 октября 2018 г.
- ^ Занаси, Алессандро (2009). «Виртуальное оружие для реальных войн: анализ текста в целях национальной безопасности». Материалы международного семинара по вычислительному интеллекту в обеспечении безопасности информационных систем CISIS'08 . Достижения в области мягких вычислений. Том. 53. с. 53. дои : 10.1007/978-3-540-88181-0_7 . ISBN 978-3-540-88180-3 .
- ^ Бадал, Варша Д.; Кундротас, Пятрас Дж.; Ваксер, Илья А. (09 декабря 2015 г.). «Интеллектуальный анализ текста для стыковки белков» . PLOS Вычислительная биология . 11 (12): e1004630. Бибкод : 2015PLSCB..11E4630B . дои : 10.1371/journal.pcbi.1004630 . ISSN 1553-7358 . ПМЦ 4674139 . ПМИД 26650466 .
- ^ Коэн, К. Бретоннель; Хантер, Лоуренс (2008). «Начало работы с текстовым анализом» . PLOS Вычислительная биология . 4 (1): е20. Бибкод : 2008PLSCB...4...20C . дои : 10.1371/journal.pcbi.0040020 . ПМК 2217579 . ПМИД 18225946 .
- ^ Бадал В.Д.; Кундротас, П.Дж.; Ваксер, И. А (2015). «Интеллектуальный анализ текста для стыковки белков» . PLOS Вычислительная биология . 11 (12): e1004630. Бибкод : 2015PLSCB..11E4630B . дои : 10.1371/journal.pcbi.1004630 . ПМЦ 4674139 . ПМИД 26650466 .
- ^ Папаниколау, Николас; Павлопулос, Георгиос А.; Феодосиу, Феодосий; Илиопулос, Иоаннис (2015). «Прогнозирование межбелкового взаимодействия с использованием методов анализа текста». Методы . 74 : 47–53. дои : 10.1016/j.ymeth.2014.10.026 . ISSN 1046-2023 . ПМИД 25448298 .
- ^ Шклярчик, Дамиан; Моррис, Джон Х; Кук, Хелен; Кун, Майкл; Уайдер, Стефан; Симонович, Милан; Сантос, Альберто; Дончева, Надежда Т; Рот, Александр (18 октября 2016 г.). «База данных STRING в 2017 году: сети белок-белковых ассоциаций с контролируемым качеством стали широко доступными» . Исследования нуклеиновых кислот . 45 (Д1): Д362–Д368. дои : 10.1093/nar/gkw937 . ISSN 0305-1048 . ПМК 5210637 . ПМИД 27924014 .
- ^ Лием, Дэвид А.; Мурали, Санджана; Сигдель, Дибакар; Ши, Ю; Ван, Сюань; Шен, Цзямин; Чой, Ховард; Кофилд, Джон Х.; Ван, Вэй; Пинг, Пейбэй; Хан, Цзявэй (01 октября 2018 г.). «Фразовый анализ текстовых данных для анализа белков внеклеточного матрикса при сердечно-сосудистых заболеваниях» . Американский журнал физиологии. Физиология сердца и кровообращения . 315 (4): H910–H924. дои : 10.1152/ajpheart.00175.2018 . ISSN 1522-1539 . ПМК 6230912 . ПМИД 29775406 .
- ^ Ван Ле, защитник; Монтгомери, Дж; Киркби, КК; Сканлан, Дж. (10 августа 2018 г.). «Прогнозирование риска с использованием обработки естественного языка электронных записей о психическом здоровье в условиях стационарной судебной психиатрии» . Журнал биомедицинской информатики . 86 : 49–58. дои : 10.1016/j.jbi.2018.08.007 . ПМИД 30118855 .
- ^ Йенссен, Тор-Кристиан; Легрейд, Астрид; Коморовский, Ян; Ховиг, Эйвинд (2001). «Литературная сеть человеческих генов для высокопроизводительного анализа экспрессии генов». Природная генетика . 28 (1): 21–8. дои : 10.1038/ng0501-21 . ПМИД 11326270 . S2CID 8889284 .
- ^ Масис, Дэниел Р. (2001). «Связывание данных микрочипов с литературой». Природная генетика . 28 (1): 9–10. дои : 10.1038/ng0501-9 . ПМИД 11326264 . S2CID 52848745 .
- ^ Ренганатан, Винайтеэртан (2017). «Интеллектуальный анализ текста в биомедицинской сфере с упором на кластеризацию документов» . Исследования в области медицинской информатики . 23 (3): 141–146. дои : 10.4258/hir.2017.23.3.141 . ISSN 2093-3681 . ПМЦ 5572517 . ПМИД 28875048 .
- ^ [3] Архивировано 4 октября 2013 г., в Wayback Machine.
- ^ «Текстовая аналитика» . Медальия . Проверено 23 февраля 2015 г.
- ↑ Перейти обратно: Перейти обратно: а б Куссеман, Кристоф; Ван Ден Поэл, Дирк (2008). «Интеграция голоса клиентов через электронную почту колл-центра в систему поддержки принятия решений для прогнозирования оттока» . Информация и управление . 45 (3): 164–74. CiteSeerX 10.1.1.113.3238 . дои : 10.1016/j.im.2008.01.005 .
- ^ Куссеман, Кристоф; Ван Ден Поэл, Дирк (2008). «Улучшение управления жалобами клиентов за счет автоматической классификации электронной почты с использованием функций лингвистического стиля в качестве предикторов» . Системы поддержки принятия решений . 44 (4): 870–82. дои : 10.1016/j.dss.2007.10.010 .
- ^ Рамиро Х. Гальвес; Агустин Гравано (2017). «Оценка полезности онлайн-анализа досок объявлений в автоматических системах прогнозирования запасов». Журнал вычислительной науки . 19 : 1877–7503. дои : 10.1016/j.jocs.2017.01.001 .
- ^ Панг, Бо; Ли, Лилиан; Вайтьянатан, Шивакумар (2002). "Недурно?". Материалы конференции ACL-02 «Эмпирические методы обработки естественного языка» . Том. 10. С. 79–86. дои : 10.3115/1118693.1118704 . S2CID 7105713 .
- ^ Алессандро Валитутти; Карло Страппарава; Оливьеро Сток (2005). «Развитие аффективных лексических ресурсов» (PDF) . Психологический журнал . 2 (1): 61–83.
- ^ Эрик Камбрия; Роберт Спир; Кэтрин Хаваси; Амир Хусейн (2010). «SenticNet: общедоступный семантический ресурс для анализа мнений» (PDF) . Труды АААИ ЦСК . стр. 14–18.
- ^ Кальво, Рафаэль А; д'Мелло, Сидни (2010). «Обнаружение аффектов: междисциплинарный обзор моделей, методов и их приложений». Транзакции IEEE для аффективных вычислений . 1 (1): 18–37. дои : 10.1109/T-AFFC.2010.1 . S2CID 753606 .
- ^ «Манчестерский университет» . Manchester.ac.uk . Проверено 23 февраля 2015 г.
- ^ «Лаборатория Цудзи» . Tsujii.is.su-tokyo.ac.jp. Архивировано из оригинала 7 марта 2012 г. Проверено 23 февраля 2015 г.
- ^ «Токийский университет» . УТокё . Проверено 23 февраля 2015 г.
- ^ Шен, Цзямин; Сяо, Цзиньфэн; Он, Синьвэй; Шан, Цзинбо; Синха, Саураб; Хан, Цзявэй (27 июня 2018 г.). Поиск по набору сущностей в научной литературе: неконтролируемый подход к ранжированию . АКМ. стр. 565–574. дои : 10.1145/3209978.3210055 . ISBN 978-1-4503-5657-2 . S2CID 13748283 .
- ^ Уолтер, Лотар; Радауэр, Альфред; Мёрле, Мартин Г. (06 февраля 2017 г.). «Красота серной бабочки: новизна патентов, выявленных с помощью анализа окружающей среды на основе анализа текста». Наукометрия . 111 (1): 103–115. дои : 10.1007/s11192-017-2267-4 . ISSN 0138-9130 . S2CID 11174676 .
- ^ Ролл, Ури; Коррейя, Рикардо А.; Бергер-Таль, Одед (10 марта 2018 г.). «Использование машинного обучения для распутывания омонимов в больших текстовых корпусах». Биология сохранения . 32 (3): 716–724. дои : 10.1111/cobi.13044 . ISSN 0888-8892 . ПМИД 29086438 . S2CID 3783779 .
- ↑ Перейти обратно: Перейти обратно: а б Автоматизированный анализ президентских выборов в США с использованием больших данных и сетевого анализа; С. Судхахар, Г. А. Велтри, Н. Кристианини; Большие данные и общество 2 (1), 1–28, 2015 г.
- ^ Сетевой анализ повествовательного контента в крупных корпусах; С. Судхахар, Г. Де Фацио, Р. Франзози, Н. Кристианини; Инженерия естественного языка, 1–32, 2013 г.
- ^ Количественный описательный анализ; Роберто Францози; Университет Эмори © 2010
- ^ Лансдалл-Велфэр, Томас; Судхахар, Саатвига; Томпсон, Джеймс; Льюис, Джастин; Команда газеты FindMyPast; Кристианини, Нелло (9 января 2017 г.). «Контент-анализ британских периодических изданий за 150 лет» . Труды Национальной академии наук . 114 (4): Е457–Е465. Бибкод : 2017PNAS..114E.457L . дои : 10.1073/pnas.1606380114 . ISSN 0027-8424 . ПМЦ 5278459 . ПМИД 28069962 .
- ^ И. Флаунас, М. Турки, О. Али, Н. Файсон, Т. Де Би, Н. Мосделл, Дж. Льюис, Н. Кристианини, Структура медиасферы ЕС, PLoS ONE, Vol. 5(12), стр. e14243, 2010.
- ^ Прогнозирование текущей погоды из социальной сети со статистическим обучениемВ. Лампос, Н. Кристианини; Транзакции ACM в интеллектуальных системах и технологиях (TIST) 3 (4), 72
- ^ NOAM: система анализа и мониторинга новостных агентств; И. Флаунас, О. Али, М. Турки, Т. Сноусилл, Ф. Никарт, Т. Де Би, Н. Кристианини Proc. международной конференции ACM SIGMOD 2011 года по управлению данными
- ^ Автоматическое обнаружение закономерностей в медиаконтенте, Н. Кристианини, Сопоставление комбинаторных шаблонов, 2–13, 2011 г.
- ^ И. Флаунас, О. Али, Т. Лансдалл-Велфэр, Т. Де Би, Н. Мосделл, Дж. Льюис, Н. Кристианини, МЕТОДЫ ИССЛЕДОВАНИЯ В ЭПОХУ ЦИФРОВОЙ ЖУРНАЛИСТИКИ, Цифровая журналистика, Routledge, 2012
- ^ Циркадные вариации настроения в контенте Твиттера; Фабон Дзоганг, Стаффорд Лайтман, Нелло Кристианини. Достижения в области мозга и нейробиологии, 1, 2398212817744501.
- ^ Влияние рецессии на общественные настроения в Великобритании; Т. Лансдалл-Велфер, В. Лампос, Н. Кристианини; Сеанс Mining Social Network Dynamics (MSND) в приложениях социальных сетей
- ↑ Исследователи получили право на интеллектуальный анализ данных в соответствии с новыми законами Великобритании об авторском праве. Архивировано 9 июня 2014 г., в Wayback Machine.
- ^ «Лицензии для Европы – Структурированный диалог заинтересованных сторон 2013» . Европейская комиссия . Проверено 14 ноября 2014 г.
- ^ «Интеллектуальный анализ текста и данных: его важность и необходимость перемен в Европе» . Ассоциация европейских исследовательских библиотек . 25 апреля 2013 г. Архивировано из оригинала 29 ноября 2014 г. Проверено 14 ноября 2014 г.
- ^ «Судья выносит решение в порядке упрощенного судопроизводства в пользу Google Книги — победа в области добросовестного использования» . Лексология . Antonelli Law Ltd., 19 ноября 2013 г. Проверено 14 ноября 2014 г.
- ^ «Интеллектуальный анализ текста и данных» . Комиссия по реформе законодательства Австралии . 4 июня 2013 года . Проверено 10 февраля 2023 г.
Источники [ править ]
- Ананиаду С. и Макнот Дж. (редакторы) (2006). Анализ текста для биологии и биомедицины . Книги Артех Хаус. ISBN 978-1-58053-984-5
- Билисоли, Р. (2008). Практический анализ текста с помощью Perl . Нью-Йорк: Джон Уайли и сыновья. ISBN 978-0-470-17643-6
- Фельдман Р. и Сэнгер Дж. (2006). Руководство по интеллектуальному анализу текста . Нью-Йорк: Издательство Кембриджского университета. ISBN 978-0-521-83657-9
- Хото А., Нюрнбергер А. и Паас Г. (2005). «Краткий обзор интеллектуального анализа текста». В Ldv Forum, Vol. 20(1), с. 19-62
- Индурхья Н. и Дамерау Ф. (2010). Справочник по обработке естественного языка , 2-е издание. Бока-Ратон, Флорида: CRC Press. ISBN 978-1-4200-8592-1
- Као А. и Потит С. (редакторы). Обработка естественного языка и анализ текста . Спрингер. ISBN 1-84628-175-X
- Кончади, М. Прикладное программирование интеллектуального анализа текста (Серия «Программирование») . Чарльз Ривер Медиа. ISBN 1-58450-460-9
- Мэннинг К. и Шутце Х. (1999). Основы статистической обработки естественного языка . Кембридж, Массачусетс: MIT Press. ISBN 978-0-262-13360-9
- Майнер Г., Элдер Дж., Хилл. Т., Нисбет Р., Делен Д. и Фаст А. (2012). Практический анализ текста и статистический анализ приложений с неструктурированными текстовыми данными . Эльзевир Академик Пресс. ISBN 978-0-12-386979-1
- Макнайт, В. (2005). «Построение бизнес-аналитики: интеллектуальный анализ текстовых данных в бизнес-аналитике». Обзор ДМ , 21-22.
- Шривастава А. и Сахами. М. (2009). Анализ текста: классификация, кластеризация и приложения . Бока-Ратон, Флорида: CRC Press. ISBN 978-1-4200-5940-3
- Занаси, А. (редактор) (2007). Анализ текста и его применение в разведке, CRM и управлении знаниями . ВИТ Пресс. ISBN 978-1-84564-131-3
Внешние ссылки [ править ]
- Марти Херст: Что такое анализ текста? (октябрь 2003 г.)
- Автоматическое извлечение контента, Консорциум лингвистических данных. Архивировано 25 сентября 2013 г. на Wayback Machine.
- Автоматическое извлечение контента, NIST
| Базы данных органов управления : Национальные |
|---|