Байесовская сеть
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( февраль 2011 г. ) |
| Часть серии о |
| Байесовская статистика |
|---|
| Апостериорный = Вероятность × Априорный ÷ Доказательства |
| Фон |
| Модельное здание |
| Апостериорное приближение |
| Оценщики |
| Приближение доказательств |
| Оценка модели |
( Байесовская сеть также известная как сеть Байеса , сеть Байеса , сеть убеждений или сеть решений ) — это вероятностная графическая модель , которая представляет набор переменных и их условных зависимостей через направленный ациклический граф (DAG). [1] Хотя это одна из нескольких форм причинной записи , причинные сети являются частными случаями байесовских сетей. Байесовские сети идеально подходят для анализа произошедшего события и прогнозирования вероятности того, что какая-либо из нескольких возможных известных причин стала способствующим фактором. Например, байесовская сеть может представлять вероятностные связи между заболеваниями и симптомами. Учитывая симптомы, сеть можно использовать для расчета вероятности наличия различных заболеваний.
Эффективные алгоритмы могут выполнять вывод и обучение в байесовских сетях. Байесовские сети, которые моделируют последовательности переменных ( например, речевые сигналы или последовательности белков ), называются динамическими байесовскими сетями . Обобщения байесовских сетей, которые могут представлять и решать проблемы принятия решений в условиях неопределенности, называются диаграммами влияния .
Графическая модель
[ редактировать ]Формально байесовские сети представляют собой ориентированные ациклические графы (DAG), узлы которых представляют переменные в байесовском смысле: это могут быть наблюдаемые величины, скрытые переменные , неизвестные параметры или гипотезы. Каждое ребро представляет собой прямую условную зависимость. Любая пара узлов, которые не связаны (т. е. никакой путь не соединяет один узел с другим), представляют собой переменные, условно независимые друг от друга. Каждый узел связан с функцией вероятности переменных узла , которая принимает в качестве входных данных определенный набор значений для родительских и выдает (в качестве выходных данных) вероятность (или распределение вероятностей, если применимо) переменной, представленной узлом. Например, если родительские узлы представляют Булевы переменные , то функция вероятности может быть представлена таблицей записи, по одной записи для каждого из возможные родительские комбинации. Подобные идеи могут быть применены к неориентированным и, возможно, циклическим графам, таким как сети Маркова .


Пример
[ редактировать ]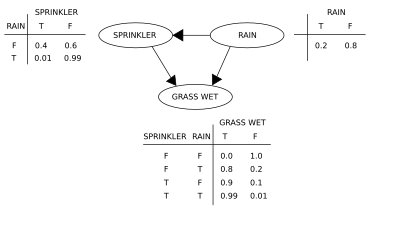
Давайте воспользуемся иллюстрацией, чтобы реализовать концепции байесовской сети. Предположим, мы хотим смоделировать зависимости между тремя переменными: разбрызгивателем (или, точнее, его состоянием — включен он или нет), наличием или отсутствием дождя и мокрой травой или нет. Обратите внимание, что два события могут привести к намоканию травы: активный разбрызгиватель или дождь. Дождь оказывает прямое влияние на использование разбрызгивателя (а именно, когда идет дождь, разбрызгиватель обычно не работает). Эту ситуацию можно смоделировать с помощью байесовской сети (показано справа). Каждая переменная имеет два возможных значения: T (истина) и F (ложь).
Совместная функция вероятности , согласно цепному правилу вероятности ,

где G = «Трава мокрая (верно/неверно)», S = «Разбрызгиватель включен (верно/неверно)», и R = «Дождь (верно/неверно)».
Модель может отвечать на вопросы о наличии причины при наличии эффекта (так называемая обратная вероятность), например: «Какова вероятность того, что идет дождь, учитывая, что трава мокрая?» используя формулу условной вероятности и суммируя все мешающие переменные :

Использование разложения для совместной функции вероятности и условных вероятностей из таблиц условных вероятностей (КПТ), указанных на схеме, можно оценить каждое слагаемое в суммах в числителе и знаменателе. Например,


Затем числовые результаты (с индексами соответствующих значений переменных)

Чтобы ответить на интервенционный вопрос, например: «Какова вероятность того, что пойдет дождь, учитывая, что мы намочили траву?» ответ определяется функцией совместного распределения после вмешательства

получается удалением множителя из распределения до вмешательства. Оператор do заставляет значение G быть истинным. На вероятность дождя действие не влияет:


Чтобы спрогнозировать последствия включения разбрызгивателя:

с термином удалено, показывая, что действие влияет на траву, но не на дождь.

Эти прогнозы могут оказаться неосуществимыми, если учесть ненаблюдаемые переменные, как это происходит в большинстве задач по оценке политики. Эффект от действия Однако все еще можно предсказать, если критерий «черного хода» удовлетворен. [2] [3] В нем говорится, что если можно наблюдать набор Z узлов, который d -разделяет [4] (или блокирует) все обходные пути от X до Y , затем


Обходной путь — это путь, который заканчивается стрелкой в X . Множества, удовлетворяющие критерию «черного хода», называются «достаточными» или «допустимыми». Например, набор Z = R допустим для предсказания влияния S = T на G , поскольку R d - отделяет (единственный) черный путь S ← R → G . Однако, если S не наблюдается, никакое другое множество d- не отделяет этот путь, и эффект включения разбрызгивателя ( S = T ) на траву ( G ) не может быть предсказан на основе пассивных наблюдений. В этом случае P ( G | do( S = T )) не «идентифицирован». Это отражает тот факт, что при отсутствии интервенционных данных наблюдаемая зависимость между S и G обусловлена причинно-следственной связью или является ложной.(кажущаяся зависимость, возникающая по общей причине, R ). (см. парадокс Симпсона )
Чтобы определить, идентифицируется ли причинная связь в произвольной байесовской сети с ненаблюдаемыми переменными, можно использовать три правила « исчисления ». [2] [5] и проверить, можно ли удалить все члены do из выражения этого отношения, тем самым подтвердив, что желаемую величину можно оценить на основе данных о частоте. [6]
Использование байесовской сети может сэкономить значительные объемы памяти при использовании исчерпывающих таблиц вероятностей, если зависимости в совместном распределении редки. Например, простой способ хранения условных вероятностей 10 двузначных переменных в виде таблицы требует места для хранения. ценности. Если локальное распределение ни одной переменной не зависит более чем от трех родительских переменных, представление байесовской сети сохраняет не более ценности.


Одним из преимуществ байесовских сетей является то, что человеку интуитивно легче понять (редкий набор) прямых зависимостей и локальных распределений, чем полные совместные распределения.
Вывод и обучение
[ редактировать ]Байесовские сети выполняют три основные задачи вывода:
Вывод ненаблюдаемых переменных
[ редактировать ]Поскольку байесовская сеть представляет собой полную модель своих переменных и их отношений, ее можно использовать для ответа на вероятностные запросы о них. Например, сеть можно использовать для обновления знаний о состоянии подмножества переменных, когда свидетельства наблюдаются другие переменные (переменные ). Этот процесс вычисления апостериорного распределения переменных с учетом имеющихся данных называется вероятностным выводом. Апостериорный метод дает универсальную достаточную статистику для приложений обнаружения при выборе значений для подмножества переменных, которые минимизируют некоторую функцию ожидаемых потерь, например, вероятность ошибки решения. Таким образом, байесовскую сеть можно рассматривать как механизм автоматического применения теоремы Байеса к сложным задачам.
Наиболее распространенными методами точного вывода являются: исключение переменных , при котором исключаются (путем интегрирования или суммирования) ненаблюдаемые переменные, не относящиеся к запросу, одна за другой путем распределения суммы по произведению; распространение дерева кликов , которое кэширует вычисления, чтобы можно было запрашивать множество переменных одновременно и быстро распространять новые данные; а также рекурсивное кондиционирование и поиск И/ИЛИ, которые позволяют найти компромисс между пространством и временем и соответствуют эффективности исключения переменных при использовании достаточного пространства. сети Все эти методы имеют сложность, экспоненциальную в зависимости от ширины дерева . Наиболее распространенными алгоритмами приближенного вывода являются выборка по значимости , стохастическое моделирование MCMC , исключение мини-корзины, циклическое распространение убеждений , обобщенное распространение убеждений и вариационные методы .
Изучение параметров
[ редактировать ]Чтобы полностью определить байесовскую сеть и, таким образом, полностью представить совместное распределение вероятностей , необходимо указать для каждого узла X распределение вероятностей для X, от X. родителей зависящее Распределение X в зависимости от его родителей может иметь любую форму. Обычно работают с дискретными или гауссовскими распределениями , поскольку это упрощает расчеты. Иногда известны только ограничения на распространение; затем можно использовать принцип максимальной энтропии для определения единственного распределения, имеющего наибольшую энтропию с учетом ограничений. (Аналогично, в конкретном контексте динамической байесовской сети условное распределение временной эволюции скрытого состояния обычно задается для максимизации уровня энтропии подразумеваемого стохастического процесса.)
Часто эти условные распределения включают параметры, которые неизвестны и должны быть оценены на основе данных, например, с помощью подхода максимального правдоподобия . Прямая максимизация правдоподобия (или апостериорной вероятности ) часто является сложной задачей, учитывая ненаблюдаемые переменные. Классическим подходом к этой проблеме является алгоритм максимизации ожидания , который чередует вычисление ожидаемых значений ненаблюдаемых переменных, зависящих от наблюдаемых данных, с максимизацией полной вероятности (или апостериорной) при условии, что ранее вычисленные ожидаемые значения верны. В условиях умеренной регулярности этот процесс сходится к значениям максимального правдоподобия (или максимального апостериорного значения) для параметров.
Более полный байесовский подход к параметрам состоит в том, чтобы рассматривать их как дополнительные ненаблюдаемые переменные и вычислять полное апостериорное распределение по всем узлам при условии соблюдения наблюдаемых данных, а затем интегрировать параметры. Этот подход может быть дорогостоящим и привести к созданию моделей большой размерности, что делает классические подходы к настройке параметров более удобными.
Структурное обучение
[ редактировать ]В простейшем случае байесовская сеть задается экспертом и затем используется для выполнения вывода. В других приложениях задача определения сети слишком сложна для людей. В этом случае структура сети и параметры локальных распределений должны быть изучены из данных.
Автоматическое изучение структуры графа байесовской сети (БС) — задача, решаемая в рамках машинного обучения . Основная идея восходит к алгоритму восстановления, разработанному Ребане и Перлом. [7] и основан на различии между тремя возможными шаблонами, разрешенными в трехузловой DAG:
| Шаблон | Модель |
|---|---|
| Цепь | |
| Вилка | |
| Коллайдер |



Первые 2 представляют собой одни и те же зависимости ( и независимы с учетом ) и поэтому неотличимы. Коллайдер, однако, может быть однозначно идентифицирован, поскольку и маргинально независимы, а все остальные пары зависимы. Таким образом, хотя скелеты (графики без стрелок) этих трех троек идентичны, направление стрелок частично можно определить. То же различие применяется, когда и иметь общих родителей, за исключением того, что нужно сначала поставить условие этим родителям. Были разработаны алгоритмы для систематического определения скелета базового графа и затем ориентации всех стрелок, направление которых диктуется наблюдаемыми условными независимостью. [2] [8] [9] [10]



Альтернативный метод структурного обучения использует поиск на основе оптимизации. Для этого требуется функция оценки и стратегия поиска. Распространенной оценочной функцией является апостериорная вероятность структуры с учетом обучающих данных, такой как BIC или BDeu. Требуемое время для исчерпывающего поиска, возвращающего структуру, которая максимизирует оценку, является суперэкспоненциальной по количеству переменных. Стратегия локального поиска вносит постепенные изменения, направленные на повышение оценки структуры. Алгоритм глобального поиска, такой как цепь Маркова Монте-Карло, может избежать попадания в ловушку локальных минимумов . Фридман и др. [11] [12] обсудите использование взаимной информации между переменными и поиск структуры, которая максимизирует это. Они делают это, ограничивая набор родительских кандидатов k узлами и осуществляя исчерпывающий поиск в нем.
Особенно быстрый метод точного обучения BN — представить задачу как задачу оптимизации и решить ее с помощью целочисленного программирования . В целочисленную программу (ИП) при решении добавляются ограничения ацикличности в виде секущих плоскостей . [13] Такой метод может решать задачи с числом переменных до 100.
Чтобы справиться с проблемами с тысячами переменных, необходим другой подход. Один из них — сначала выбрать один порядок, а затем найти оптимальную структуру BN относительно этого порядка. Это подразумевает работу над пространством поиска возможных упорядочений, что удобно, поскольку оно меньше пространства сетевых структур. Затем несколько заказов отбираются и оцениваются. Доказано, что этот метод является лучшим из доступных в литературе, когда количество переменных огромно. [14]
Другой метод заключается в сосредоточении внимания на подклассе разложимых моделей, для которых MLE имеет замкнутую форму. Тогда можно обнаружить непротиворечивую структуру для сотен переменных. [15]
Изучение байесовских сетей с ограниченной шириной дерева необходимо для обеспечения точного и удобного вывода, поскольку сложность вывода в наихудшем случае экспоненциальна по ширине дерева k (согласно гипотезе экспоненциального времени). Однако, будучи глобальным свойством графа, оно значительно усложняет процесс обучения. В этом контексте можно использовать K-дерево для эффективного обучения. [16]
Статистическое введение
[ редактировать ]Данные данные и параметр простой байесовский анализ начинается с априорной вероятности ( prior ) и вероятность вычислить апостериорную вероятность .





Часто предшествующий зависит в свою очередь от других параметров которые не упоминаются в вероятности. Итак, предшествующий должна быть заменена вероятностью и предшествующий по вновь введенным параметрам требуется, что приводит к апостериорной вероятности




Это простейший пример иерархической модели Байеса .
Процесс может быть повторен; например, параметры может зависеть, в свою очередь, от дополнительных параметров , которые требуют своего собственного предварительного. В конце концов процесс должен завершиться, причем априорные значения не зависят от неупомянутых параметров.

Вводные примеры
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( март 2009 г. ) |
Учитывая измеренные величины каждый с нормально распределенными ошибками известного стандартного отклонения ,



Предположим, нас интересует оценка . Подход мог бы заключаться в оценке использование подхода максимального правдоподобия ; поскольку наблюдения независимы, вероятность факторизуется, а оценка максимального правдоподобия просто


Однако, если количества взаимосвязаны, так что, например, отдельные сами были взяты из базового распределения, то эти отношения разрушают независимость и предлагают более сложную модель, например,


с неподходящими приорами , . Когда , это идентифицированная модель (т.е. существует уникальное решение для параметров модели), а апостериорные распределения отдельных будут иметь тенденцию двигаться или отклоняться от оценок максимального правдоподобия к их общему среднему значению. Такое сокращение является типичным поведением в иерархических моделях Байеса.



Ограничения на приоры
[ редактировать ]Необходима некоторая осторожность при выборе априорных значений в иерархической модели, особенно в отношении масштабных переменных на более высоких уровнях иерархии, таких как переменная в примере. Обычные априоры, такие как априор Джеффриса, часто не работают, поскольку апостериорное распределение не будет нормализоваться, а оценки, сделанные путем минимизации ожидаемых потерь, будут недопустимы .

Определения и понятия
[ редактировать ]Было предложено несколько эквивалентных определений байесовской сети. Для дальнейшего пусть G = ( V , E ) — ориентированный ациклический граф (DAG), и пусть X = ( X v ), v ∈ V — набор случайных величин, индексированных V .
Определение факторизации
[ редактировать ]X является байесовской сетью относительно G, если ее совместная функция плотности вероятности (относительно меры произведения ) может быть записана как произведение отдельных функций плотности, зависящих от их родительских переменных: [17]

где pa( v ) — множество родительских вершин v (т. е. тех вершин, которые указывают непосредственно на v через одно ребро).
Для любого набора случайных величин вероятность любого члена совместного распределения может быть рассчитана на основе условных вероятностей с использованием цепного правила (с учетом топологического порядка X ) следующим образом: [17]

Используя приведенное выше определение, это можно записать так:

Разница между двумя выражениями заключается в условной независимости переменных от любых их не-потомков, учитывая значения их родительских переменных.
Местная марковская собственность
[ редактировать ]X является байесовской сетью относительно G, если она удовлетворяет локальному марковскому свойству : каждая переменная условно независима от своих непотомков, учитывая ее родительские переменные: [18]

где de( v ) — набор потомков, а V \ de( v ) — набор непотомков v .
Это можно выразить в терминах, аналогичных первому определению, как
![{\displaystyle {\begin{aligned}&\operatorname {P} (X_{v}=x_{v}\mid X_{i}=x_{i}{\text{ для каждого }}X_{i}{\ text{ который не является потомком }}X_{v}\,)\\[6pt]={}&P(X_{v}=x_{v}\mid X_{j}=x_{j}{\text { для каждого }}X_{j}{\text{, который является родительским для }}X_{v}\,)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f8f18a3121835ff1e58881ebfc0d5f8ef95b783d)
Множество родителей является подмножеством множества не-потомков, поскольку граф является ациклическим .
Структура предельной независимости
[ редактировать ]В целом, изучение байесовской сети на основе данных, как известно, является NP-сложной задачей . [19] Частично это связано с комбинаторным взрывом перечисления DAG по мере увеличения количества переменных. Тем не менее, представление о базовой байесовской сети можно получить из данных за полиномиальное время, сосредоточив внимание на ее структуре предельной независимости. [20] : в то время как заявления об условной независимости распределения, смоделированного байесовской сетью, кодируются DAG (в соответствии с факторизацией и марковскими свойствами, указанными выше), его заявления о маргинальной независимости — заявления об условной независимости, в которых обусловливающее множество пусто — кодируются простой неориентированный граф со специальными свойствами, такими как равные пересечения и числа независимости .
Разработка байесовских сетей
[ редактировать ]Разработка байесовской сети часто начинается с создания DAG G такого, что удовлетворяет локальному марковскому свойству относительно G. X Иногда это причинная DAG. условные распределения вероятностей каждой переменной с учетом ее родителей в G. Оцениваются Во многих случаях, в частности в случае, когда переменные дискретны, если совместное распределение является произведением этих условных распределений, то X является байесовской сетью относительно G. X [21]
Марковское одеяло
[ редактировать ]Марковское одеяло узла — это множество узлов, состоящее из его родителей, его детей и любых других родителей его детей. Одеяло Маркова делает узел независимым от остальной сети; совместное распределение переменных в марковском бланкете узла является достаточным знанием для расчета распределения узла. X является байесовской сетью относительно G , если каждый узел условно независим от всех других узлов в сети, учитывая его марковское одеяло . [18]
д -разделение
[ редактировать ]Это определение можно сделать более общим, определив «d»-разделение двух узлов, где d означает направление. [2] Сначала мы определяем «d»-разделение следа, а затем с его точки зрения определим «d»-разделение двух узлов.
Пусть P — путь от узла u до v . Трасса — это ненаправленный путь без петель (т. е. все направления ребер игнорируются) между двумя узлами. Тогда P говорят, что d -разделен набором узлов Z, если выполняется любое из следующих условий:
- P содержит (но не обязательно должен быть полностью) направленную цепь, или , такой, что средний узел m находится в Z ,
- P содержит вилку, , такой, что средний узел m находится в Z , или
- P содержит перевернутую вилку (или коллайдер), , так что средний узел m не находится в Z и ни один потомок m не находится в Z .




Узлы u и v Z d -разделены , если все маршруты между ними d -разделены. Если u и v не d-разделены, они d-связны.
X является байесовской сетью относительно G , если для любых двух узлов u , v :

где Z — множество, которое d -разделяет u и v . ( Марковское одеяло — это минимальный набор узлов, который d -отделяет узел v от всех остальных узлов.)
Причинно-следственные сети
[ редактировать ]Хотя байесовские сети часто используются для представления причинно-следственных связей, это не обязательно так: направленное ребро от u до v не требует, чтобы X v был причинно зависим от X u . Об этом свидетельствует тот факт, что байесовские сети на графиках:

эквивалентны: то есть они предъявляют одни и те же требования условной независимости.
Причинная сеть — это байесовская сеть с требованием, чтобы отношения были причинными. Дополнительная семантика причинных сетей определяет, что если узел X активно приводится в заданное состояние x (действие, записанное как do( X = x )), то функция плотности вероятности меняется на функцию плотности вероятности сети, полученной путем разрезания ссылки от родителей X на X и установка X в вызванное значение x . [2] Используя эту семантику, можно предсказать влияние внешнего вмешательства на основе данных, полученных до вмешательства.
Сложность вывода и алгоритмы аппроксимации
[ редактировать ]В 1990 году, работая в Стэнфордском университете над крупными биоинформационными приложениями, Купер доказал, что точный вывод в байесовских сетях NP-труден . [22] Этот результат побудил к исследованию алгоритмов аппроксимации с целью разработки удобного приближения к вероятностному выводу. В 1993 году Пол Дагам и Майкл Луби доказали два удивительных результата о сложности аппроксимации вероятностного вывода в байесовских сетях. [23] Во-первых, они доказали, что ни один послушный детерминированный алгоритм не может аппроксимировать вероятностный вывод с точностью до абсолютной ошибки ɛ < 1/2. Во-вторых, они доказали, что ни один управляемый рандомизированный алгоритм не может аппроксимировать вероятностный вывод с точностью до абсолютной ошибки ɛ < 1/2 с доверительной вероятностью больше 1/2.
Примерно в то же время Рот доказал, что точный вывод в байесовских сетях на самом деле #P-полный (и, следовательно, так же сложен, как подсчет количества удовлетворяющих присвоений формулы конъюнктивной нормальной формы (КНФ)) и что аппроксимационный вывод в пределах множителя 2 н 1- е для любого ɛ > 0, даже для байесовских сетей с ограниченной архитектурой, является NP-трудной. [24] [25]
С практической точки зрения эти результаты по сложности показали, что, хотя байесовские сети являются богатым представлением приложений искусственного интеллекта и машинного обучения, их использование в крупных реальных приложениях должно ограничиваться либо топологическими структурными ограничениями, такими как наивные байесовские сети, либо ограничениями. об условных вероятностях. Алгоритм ограниченной дисперсии [26] разработанный Дагумом и Луби, был первым доказуемым алгоритмом быстрой аппроксимации, позволяющим эффективно аппроксимировать вероятностный вывод в байесовских сетях с гарантиями аппроксимации ошибок. Этот мощный алгоритм требовал небольшого ограничения на условные вероятности байесовской сети, которые должны быть отделены от нуля и единицы на где был любой полином от количества узлов в сети, .



Программное обеспечение
[ редактировать ]Известное программное обеспечение для байесовских сетей включает:
- Просто еще один сэмплер Гиббса (JAGS) — альтернатива WinBUGS с открытым исходным кодом. Использует выборку Гиббса.
- OpenBUGS — разработка WinBUGS с открытым исходным кодом.
- SPSS Modeler – коммерческое программное обеспечение, включающее реализацию байесовских сетей.
- Stan (программное обеспечение) — Stan — это пакет с открытым исходным кодом для получения байесовского вывода с использованием сэмплера No-U-Turn (NUTS), [27] вариант гамильтониана Монте-Карло.
- PyMC — библиотека Python, реализующая встроенный предметно-ориентированный язык для представления байесовских сетей и различные сэмплеры (включая NUTS).
- WinBUGS — одна из первых вычислительных реализаций сэмплеров MCMC. Больше не поддерживается.
История
[ редактировать ]Термин «байесовская сеть» был придуман Джудеей Перл в 1985 году, чтобы подчеркнуть: [28]
- часто субъективный характер входной информации
- использование байесовского кондиционирования как основы для обновления информации
- различие между причинным и доказательным способами рассуждения [29]
В конце 1980-х годов Перл «Вероятностное рассуждение в интеллектуальных системах» [30] и рассуждения Неаполитана вероятностные в экспертных системах [31] обобщил их свойства и определил их как область исследования.
См. также
[ редактировать ]- Байесовская эпистемология
- Байесовское программирование
- Причинно-следственный вывод
- Диаграмма причинно-следственной петли
- Дерево Чоу-Лю
- Вычислительный интеллект
- Вычислительная филогенетика
- Сеть глубоких убеждений
- Теория Демпстера – Шафера - обобщение теоремы Байеса.
- Алгоритм ожидания-максимизации
- Факторный график
- Иерархическая временная память
- Фильтр Калмана
- Структура прогнозирования памяти
- Распределение смеси
- Модель смеси
- Наивный классификатор Байеса
- Обозначение таблички
- Политри
- Датчик слияния
- Выравнивание последовательности
- Моделирование структурными уравнениями
- Субъективная логика
- Байесовская сеть переменного порядка
Примечания
[ редактировать ]- ^ Руджери, Фабрицио; Кенетт, Рон С.; Фалтин, Фредерик В., ред. (14 декабря 2007 г.). Энциклопедия статистики качества и надежности (1-е изд.). Уайли. п. 1. дои : 10.1002/9780470061572.eqr089 . ISBN 978-0-470-01861-3 .
- ^ Перейти обратно: а б с д и Перл, Иудея (2000). Причинность: модели, рассуждения и выводы . Издательство Кембриджского университета . ISBN 978-0-521-77362-1 . OCLC 42291253 .
- ^ «Критерий черного хода» (PDF) . Проверено 18 сентября 2014 г.
- ^ «Д-Разлука без слез» (PDF) . Проверено 18 сентября 2014 г.
- ^ Перл Дж (1994). «Вероятностное исчисление действий» . В Лопес де Мантарас Р., Пул Д. (ред.). UAI'94 Материалы Десятой международной конференции «Неопределенность в искусственном интеллекте» . Сан-Матео, Калифорния: Морган Кауфманн . стр. 454–462. arXiv : 1302.6835 . Бибкод : 2013arXiv1302.6835P . ISBN 1-55860-332-8 .
- ^ Шпицер И, Перл Дж (2006). «Идентификация условных интервенционных распределений». В Дехтер Р., Ричардсон Т.С. (ред.). Материалы двадцать второй конференции по неопределенности в искусственном интеллекте . Корваллис, Орегон: AUAI Press. стр. 437–444. arXiv : 1206.6876 .
- ^ Ребане Дж., Перл Дж. (1987). «Восстановление причинных полидеревьев по статистическим данным». Материалы 3-го семинара по неопределенности в ИИ . Сиэтл, Вашингтон. стр. 222–228. arXiv : 1304.2736 .
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) - ^ Спиртес П., Глимур С. (1991). «Алгоритм быстрого восстановления разреженных причинных графов» (PDF) . Компьютерный обзор социальных наук . 9 (1): 62–72. CiteSeerX 10.1.1.650.2922 . дои : 10.1177/089443939100900106 . S2CID 38398322 .
- ^ Спиртес П., Глимур К.Н., Шайнс Р. (1993). Причинно-следственная связь, прогнозирование и поиск (1-е изд.). Спрингер Верлаг. ISBN 978-0-387-97979-3 .
- ^ Верма Т., Перл Дж (1991). «Эквивалентность и синтез причинных моделей» . В Бониссоне П., Генрионе М., Канале Л.Н., Леммере Дж.Ф. (ред.). UAI '90 Материалы шестой ежегодной конференции по неопределенности в искусственном интеллекте . Эльзевир. стр. 255–270. ISBN 0-444-89264-8 .
- ^ Фридман Н., Гейгер Д., Гольдшмидт М. (ноябрь 1997 г.). «Байесовские сетевые классификаторы» . Машинное обучение . 29 (2–3): 131–163. дои : 10.1023/А:1007465528199 .
- ^ Фридман Н., Линиал М., Нахман И., Пеер Д. (август 2000 г.). «Использование байесовских сетей для анализа данных о выражениях». Журнал вычислительной биологии . 7 (3–4): 601–20. CiteSeerX 10.1.1.191.139 . дои : 10.1089/106652700750050961 . ПМИД 11108481 .
- ^ Кассенс Дж. (2011). «Обучение байесовской сети с помощью секущих плоскостей» (PDF) . Материалы 27-й ежегодной конференции по неопределенности в искусственном интеллекте : 153–160. arXiv : 1202.3713 . Бибкод : 2012arXiv1202.3713C .
- ^ Сканагатта М., де Кампос С.П., Корани Г., Заффалон М. (2015). «Изучение байесовских сетей с тысячами переменных» . NIPS-15: Достижения в области нейронных систем обработки информации . Том. 28. Карран Ассошиэйтс. стр. 1855–1863.
- ^ Петижан Ф., Уэбб Дж.И., Николсон А.Е. (2013). Масштабирование лог-линейного анализа для многомерных данных (PDF) . Международная конференция по интеллектуальному анализу данных. Даллас, Техас, США: IEEE.
- ^ М. Сканагатта, Дж. Корани, К. П. де Кампос и М. Заффалон. Изучение байесовских сетей, ограниченных по ширине дерева, с тысячами переменных. В NIPS-16: Достижения в области нейронных систем обработки информации, 29, 2016 г.
- ^ Перейти обратно: а б Рассел и Норвиг 2003 , с. 496.
- ^ Перейти обратно: а б Рассел и Норвиг 2003 , с. 499.
- ^ Чикеринг, Дэвид М.; Хеккерман, Дэвид; Мик, Кристофер (2004). «Обучение байесовских сетей на большой выборке NP-сложно» (PDF) . Журнал исследований машинного обучения . 5 : 1287–1330.
- ^ Делигеоргаки, Данай; Маркхэм, Алекс; Мишра, Пратик; Солус, Лиам (2023). «Комбинаторные и алгебраические взгляды на структуру предельной независимости байесовских сетей». Алгебраическая статистика . 14 (2): 233–286. arXiv : 2210.00822 . дои : 10.2140/astat.2023.14.233 .
- ^ Неаполитанский RE (2004). Изучение байесовских сетей . Прентис Холл. ISBN 978-0-13-012534-7 .
- ^ Купер Г.Ф. (1990). «Вычислительная сложность вероятностного вывода с использованием байесовских сетей убеждений» (PDF) . Искусственный интеллект . 42 (2–3): 393–405. дои : 10.1016/0004-3702(90)90060-д . S2CID 43363498 .
- ^ Дагум П. , Луби М. (1993). «Аппроксимация вероятностного вывода в байесовских сетях убеждений NP-трудна». Искусственный интеллект . 60 (1): 141–153. CiteSeerX 10.1.1.333.1586 . дои : 10.1016/0004-3702(93)90036-б .
- ^ Д. Рот, О сложности приближенных рассуждений , IJCAI (1993).
- ^ Д. Рот, О сложности приближенных рассуждений , Искусственный интеллект (1996).
- ^ Дагум П. , Луби М. (1997). «Оптимальный алгоритм приближения для байесовского вывода» . Искусственный интеллект . 93 (1–2): 1–27. CiteSeerX 10.1.1.36.7946 . дои : 10.1016/s0004-3702(97)00013-1 . Архивировано из оригинала 6 июля 2017 г. Проверено 19 декабря 2015 г.
- ^ Хоффман, Мэтью Д.; Гельман, Эндрю (2011). «Пробоотборник без разворота: адаптивная установка длины пути в гамильтоновом методе Монте-Карло». arXiv : 1111.4246 [ stat.CO ].
- ^ Перл Дж (1985). Байесовские сети: модель самоактивируемой памяти для доказательного рассуждения (Технический отчет Калифорнийского университета в Лос-Анджелесе CSD-850017) . Материалы 7-й конференции Общества когнитивных наук, Калифорнийский университет, Ирвин, Калифорния. стр. 329–334 . Проверено 1 мая 2009 г.
- ^ Байес Т. , Прайс (1763). «Очерк решения проблемы учения о шансах» . Философские труды Королевского общества . 53 : 370–418. дои : 10.1098/rstl.1763.0053 .
- ^ Перл Дж (15 сентября 1988 г.). Вероятностные рассуждения в интеллектуальных системах . Сан-Франциско, Калифорния: Морган Кауфманн . п. 1988. ISBN 978-1-55860-479-7 .
- ^ Неаполитанский RE (1989). Вероятностные рассуждения в экспертных системах: теория и алгоритмы . Уайли. ISBN 978-0-471-61840-9 .
Ссылки
[ редактировать ]- Бен Гал I (2007). «Байесовские сети» (PDF) . В Руджери Ф., Кеннетте Р.С., Фалтине Ф.В. (ред.). Страница поддержки . Энциклопедия статистики качества и надежности . Джон Уайли и сыновья . дои : 10.1002/9780470061572.eqr089 . ISBN 978-0-470-01861-3 . Архивировано из оригинала (PDF) 23 ноября 2016 г. Проверено 27 августа 2007 г.
- Берч МакГрейн С. (2011). Теория, которая не умрет . Нью-Хейвен: Издательство Йельского университета .
- Боргельт С., Крузе Р. (март 2002 г.). Графические модели: методы анализа и анализа данных . Чичестер, Великобритания : Wiley . ISBN 978-0-470-84337-6 .
- Борсук М.Е. (2008). «Экологическая информатика: байесовские сети». Йоргенсен , Свен Эрик , Фат, Брайан (ред.). Энциклопедия экологии . Эльзевир. ISBN 978-0-444-52033-3 .
- Кастильо Э., Гутьеррес Х.М., Хади А.С. (1997). «Изучение байесовских сетей». Экспертные системы и вероятностные сетевые модели . Монографии по информатике. Нью-Йорк: Springer-Verlag . стр. 481–528. ISBN 978-0-387-94858-4 .
- Комли Дж.В., Доу Д.Л. (июнь 2003 г.). «Общие байесовские сети и асимметричные языки» . Материалы 2-й Гавайской международной конференции по статистике и смежным областям .
- Комли Дж.В., Доу Д.Л. (2005). «Минимальная длина сообщения и обобщенные байесовские сети с асимметричными языками» . В полиции Грюнвальда, Мьюнг И.Дж., Питт М.А. (ред.). Достижения в минимальной длине описания: теория и приложения . Серия нейронной обработки информации. Кембридж, Массачусетс : Bradford Books ( MIT Press ) (опубликовано в апреле 2005 г.). стр. 265–294. ISBN 978-0-262-07262-5 . (В этом документе деревья решений размещаются во внутренних узлах сетей Байеса с использованием минимальной длины сообщения ( MML ).
- Дарвич А. (2009). Моделирование и рассуждения с помощью байесовских сетей . Издательство Кембриджского университета . ISBN 978-0-521-88438-9 .
- Доу, Дэвид Л. (31 мая 2011 г.). «Графические модели гибридных байесовских сетей, статистическая согласованность, инвариантность и уникальность» (PDF) . Философия статистики . Эльзевир. стр. 901–982 . ISBN 978-0-08-093096-1 .
- Фентон Н., Нил М.Э. (ноябрь 2007 г.). «Управление рисками в современном мире: применение байесовских сетей» (PDF) . Отчет о передаче знаний от Лондонского математического общества и Сети передачи знаний по промышленной математике . Лондон (Англия) : Лондонское математическое общество . Архивировано из оригинала (PDF) 14 мая 2008 г. Проверено 29 октября 2008 г.
- Фентон Н., Нил М.Э. (23 июля 2004 г.). «Объединение доказательств при анализе рисков с использованием байесовских сетей» (PDF) . Информационный бюллетень Клуба критических систем безопасности . Том. 13, нет. 4. Ньюкасл-апон-Тайн , Англия. стр. 8–13. Архивировано из оригинала (PDF) 27 сентября 2007 г.
- Гельман А., Карлин Дж.Б., Стерн Х.С., Рубин Д.Б. (2003). «Часть II: Основы байесовского анализа данных: глава 5, иерархические модели» . Байесовский анализ данных . ЦРК Пресс . стр. 120–. ISBN 978-1-58488-388-3 .
- Хеккерман, Дэвид (1 марта 1995 г.). «Учебное пособие по обучению с помощью байесовских сетей» . В Иордании, Майкл Ирвин (ред.). Обучение графическим моделям . Адаптивные вычисления и машинное обучение. Кембридж, Массачусетс : MIT Press (опубликовано в 1998 г.). стр. 301–354. ISBN 978-0-262-60032-3 . Архивировано из оригинала 19 июля 2006 года . Проверено 15 сентября 2006 г.
{{cite book}}: CS1 maint: bot: original URL status unknown (link):Also appears as Хеккерман, Дэвид (март 1997 г.). «Байесовские сети для интеллектуального анализа данных». Интеллектуальный анализ данных и обнаружение знаний . 1 (1): 79–119. дои : 10.1023/А:1009730122752 . S2CID 6294315 .
- Более ранняя версия опубликована под названием Microsoft Research , 1 марта 1995 г. Статья посвящена изучению как параметров, так и структур в байесовских сетях.
- Йенсен Ф.В., Нильсен Т.Д. (6 июня 2007 г.). Байесовские сети и графы решений . Серия «Информатика и статистика» (2-е изд.). Нью-Йорк : Springer-Verlag . ISBN 978-0-387-68281-5 .
- Карими К., Гамильтон HJ (2000). «Нахождение временных отношений: причинно-следственные байесовские сети против C4.5» (PDF) . Двенадцатый международный симпозиум по методологиям интеллектуальных систем .
- Корб КБ, Николсон А.Е. (декабрь 2010 г.). Байесовский искусственный интеллект . CRC Информатика и анализ данных (2-е изд.). Чепмен и Холл ( CRC Press ). дои : 10.1007/s10044-004-0214-5 . ISBN 978-1-58488-387-6 . S2CID 22138783 .
- Ланн Д., Шпигельхальтер Д., Томас А., Бест Н. (ноябрь 2009 г.). «Проект BUGS: эволюция, критика и будущие направления». Статистика в медицине . 28 (25): 3049–67. дои : 10.1002/сим.3680 . ПМИД 19630097 . S2CID 7717482 .
- Нил М., Фентон Н., Тейлор М. (август 2005 г.). Гринберг, Майкл Р. (ред.). «Использование байесовских сетей для моделирования ожидаемых и неожиданных эксплуатационных потерь» (PDF) . Анализ рисков . 25 (4): 963–72. дои : 10.1111/j.1539-6924.2005.00641.x . ПМИД 16268944 . S2CID 3254505 .
- Перл Дж (сентябрь 1986 г.). «Слияние, распространение и структурирование сетей убеждений». Искусственный интеллект . 29 (3): 241–288. дои : 10.1016/0004-3702(86)90072-X .
- Перл Дж (1988). Вероятностные рассуждения в интеллектуальных системах: сети правдоподобных выводов . Серия «Представление и рассуждение» (2-е печатное изд.). Сан-Франциско, Калифорния : Морган Кауфманн . ISBN 978-0-934613-73-6 .
- Перл Дж. , Рассел С. (ноябрь 2002 г.). «Байесовские сети». В Арбиб М.А. (ред.). Справочник по теории мозга и нейронным сетям . Кембридж, Массачусетс : Bradford Books ( MIT Press ). стр. 157–160. ISBN 978-0-262-01197-6 .
- Рассел, Стюарт Дж .; Норвиг, Питер (2003), Искусственный интеллект: современный подход (2-е изд.), Аппер-Сэддл-Ривер, Нью-Джерси: Прентис-Холл, ISBN 0-13-790395-2 .
- Чжан Н.Л., Пул Д. (май 1994 г.). «Простой подход к вычислениям байесовской сети» (PDF) . Материалы десятой канадской конференции по искусственному интеллекту (AI-94), проводимой раз в два года. : 171–178. В этой статье представлено исключение переменных для сетей убеждений.
Дальнейшее чтение
[ редактировать ]- Конради С., Жуфф Л. (01.07.2015). Байесовские сети и BayesiaLab — практическое введение для исследователей . Франклин, Теннесси: Байесианские США. ISBN 978-0-9965333-0-0 .
- Чарняк Э. (зима 1991 г.). «Байесовские сети без разрывов» (PDF) . Журнал ИИ .
- Крузе Р., Боргельт С., Клавонн Ф., Мовес С., Штайнбрехер М., Хелд П. (2013). Вычислительный интеллект. Методологическое введение . Лондон: Издательство Springer. ISBN 978-1-4471-5012-1 .
- Боргельт С., Штайнбрехер М., Крузе Р. (2009). Графические модели - представления для обучения, рассуждения и интеллектуального анализа данных (второе изд.). Чичестер: Уайли. ISBN 978-0-470-74956-2 .
Внешние ссылки
[ редактировать ]- Введение в байесовские сети и их современные приложения
- Онлайн-учебник по байесовским сетям и вероятности
- Веб-приложение для создания байесовских сетей и их запуска методом Монте-Карло.
- Байесовские сети с непрерывным временем
- Байесовские сети: объяснение и аналогия
- Живое руководство по изучению байесовских сетей
- Иерархическая байесовская модель для обработки неоднородности выборки в задачах классификации обеспечивает модель классификации, учитывающую неопределенность, связанную с измерением повторяющихся образцов.
- Иерархическая наивная байесовская модель для обработки неопределенности выборки. Архивировано 28 сентября 2007 г. на Wayback Machine . Показывает, как выполнять классификацию и обучение с непрерывными и дискретными переменными с повторяемыми измерениями.