Микроархитектура
Эта статья нуждается в дополнительных цитатах для проверки . ( январь 2010 г. ) |
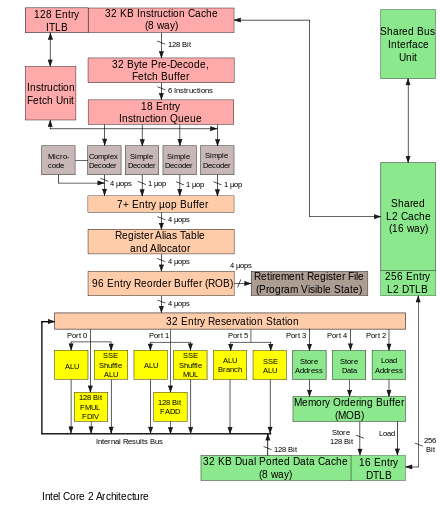
В электронике , информатике и компьютерной инженерии микроархитектура , также называемая компьютерной организацией и иногда сокращенно µarch или uarch , представляет собой способ реализации заданной архитектуры набора команд (ISA) в конкретном процессоре . [1] Данная ISA может быть реализована с использованием различных микроархитектур; [2] [3] реализации могут различаться из-за разных целей данной конструкции или из-за изменений в технологии. [4]
Архитектура компьютера представляет собой комбинацию микроархитектуры и архитектуры набора команд.
Связь с архитектурой набора команд
[ редактировать ]
ISA примерно такая же , как модель программирования процессора, как ее видит программист на языке ассемблера или автор компилятора. ISA включает в себя инструкции , модель выполнения , регистры процессора , форматы адресов и данных, среди прочего. Микроархитектура включает в себя составные части процессора и способы их взаимодействия и взаимодействия для реализации ISA.
Микроархитектуру машины обычно представляют в виде (более или менее детальных) схем, описывающих взаимосвязи различных микроархитектурных элементов машины, которые могут быть чем угодно — от отдельных вентилей и регистров до законченных арифметико-логических устройств (АЛУ) и даже более крупных. элементы. Эти диаграммы обычно разделяют путь данных (где размещаются данные) и путь управления (который, можно сказать, управляет данными). [5]
Человек, проектирующий систему, обычно рисует конкретную микроархитектуру как своего рода диаграмму потока данных . Как и блок-схема , схема микроархитектуры показывает элементы микроархитектуры, такие как арифметико-логический блок и файл регистров, в виде одного схематического символа. Обычно на диаграмме эти элементы соединяются стрелками, толстыми и тонкими линиями, чтобы различать шины с тремя состояниями (которые требуют буфера с тремя состояниями для каждого устройства, которое управляет шиной), однонаправленные шины (всегда управляемые одним источником, например поскольку адресная шина на более простых компьютерах всегда управляется регистром адреса памяти ) и отдельными линиями управления. Очень простые компьютеры имеют единую организацию шины данных — у них есть одна шина с тремя состояниями . На схеме более сложных компьютеров обычно показано несколько шин с тремя состояниями, которые помогают машине выполнять больше операций одновременно.
Каждый элемент микроархитектуры, в свою очередь, представлен схемой , описывающей взаимосвязи логических элементов, используемых для его реализации. Каждый логический элемент, в свою очередь, представлен принципиальной схемой, описывающей соединения транзисторов, используемых для его реализации в некотором конкретном логическом семействе . Машины с разными микроархитектурами могут иметь одинаковую архитектуру набора команд и, следовательно, быть способны выполнять одни и те же программы. Новые микроархитектуры и/или схемотехнические решения, а также достижения в производстве полупроводников позволяют новым поколениям процессоров достигать более высокой производительности при использовании той же ISA.
В принципе, одна микроархитектура может выполнять несколько разных ISA лишь с небольшими изменениями в микрокоде .
Аспекты
[ редактировать ]
Конвейерный путь передачи данных сегодня является наиболее часто используемой конструкцией пути передачи данных в микроархитектуре. Этот метод используется в большинстве современных микропроцессоров, микроконтроллеров и DSP . Конвейерная архитектура позволяет нескольким инструкциям перекрываться при выполнении, подобно сборочной линии. Конвейер включает в себя несколько различных этапов, которые являются фундаментальными при проектировании микроархитектуры. [5] Некоторые из этих этапов включают выборку инструкций, декодирование инструкций, выполнение и обратную запись. Некоторые архитектуры включают в себя другие этапы, такие как доступ к памяти. Проектирование трубопроводов является одной из центральных микроархитектурных задач.
Исполнительные устройства также важны для микроархитектуры. К исполнительным блокам относятся арифметико-логические блоки (ALU), блоки с плавающей запятой (FPU), блоки загрузки/сохранения, прогнозирования ветвей и SIMD . Эти блоки выполняют операции или вычисления процессора. Выбор количества исполнительных блоков, их задержки и пропускной способности является центральной задачей проектирования микроархитектуры. Размер, задержка, пропускная способность и возможности подключения памяти внутри системы также являются микроархитектурными решениями.
Решения по проектированию на уровне системы, например, включать ли периферийные устройства , такие как контроллеры памяти , или нет , можно рассматривать как часть процесса проектирования микроархитектуры. Сюда входят решения об уровне производительности и возможности подключения этих периферийных устройств.
В отличие от архитектурного проектирования, где главной целью является достижение определенного уровня производительности, микроархитектурное проектирование уделяет больше внимания другим ограничениям. Поскольку решения по проектированию микроархитектуры напрямую влияют на то, что входит в систему, необходимо уделять внимание таким вопросам, как площадь/стоимость чипа, энергопотребление, сложность логики, простота подключения, технологичность, простота отладки и тестируемость.
Микроархитектурные концепции
[ редактировать ]Циклы инструкций
[ редактировать ]Для запуска программ все одно- или многочиповые процессоры:
- Прочтите инструкцию и расшифруйте ее.
- Найдите любые связанные данные, необходимые для обработки инструкции.
- Обработать инструкцию
- Напишите результаты
Цикл инструкций повторяется непрерывно до тех пор, пока не будет отключено питание.
Многоцикловая микроархитектура
[ редактировать ]Исторически самые ранние компьютеры были многоцикловыми. Самые маленькие и самые дешевые компьютеры часто до сих пор используют этот метод. Многоцикловые архитектуры часто используют наименьшее общее количество логических элементов и разумное количество мощности. Они могут быть спроектированы так, чтобы иметь детерминированное время и высокую надежность. В частности, у них нет конвейера, который мог бы останавливаться при выполнении условных переходов или прерываний. Однако другие микроархитектуры часто выполняют больше инструкций в единицу времени, используя то же самое семейство логики. При обсуждении «повышения производительности» улучшение часто связано с многоцикловой конструкцией.
В многоцикловом компьютере компьютер последовательно выполняет четыре шага в течение нескольких тактов. Некоторые конструкции могут выполнять последовательность за два тактовых цикла, выполняя последовательные этапы поочередным тактовым фронтам, возможно, с более длительными операциями, происходящими вне основного цикла. Например, первая ступень — на нарастающем фронте первого цикла, вторая — на спадающем фронте первого цикла и т. д.
В логике управления комбинация счетчика циклов, состояния цикла (высокого или низкого) и битов регистра декодирования команд точно определяют, что должна делать каждая часть компьютера. Для разработки логики управления можно создать таблицу битов, описывающую сигналы управления для каждой части компьютера в каждом цикле каждой инструкции. Затем эту логическую таблицу можно протестировать с помощью тестового кода программного моделирования. Если логическая таблица помещается в память и используется для работы реального компьютера, она называется микропрограммой . В некоторых компьютерных конструкциях логическая таблица оптимизируется в форме комбинационной логики, состоящей из логических элементов, обычно с использованием компьютерной программы, оптимизирующей логику. Первые компьютеры использовали для управления специальную логику, пока Морис Уилкс не изобрел табличный подход и не назвал его микропрограммированием. [6]
Увеличение скорости выполнения
[ редактировать ]Эту простую на первый взгляд серию шагов усложняет тот факт, что иерархия памяти, включающая кэширование , основную память и энергонезависимое хранилище, такое как жесткие диски (где находятся инструкции программы и данные), всегда работала медленнее, чем сам процессор. Шаг (2) часто приводит к длительной (по меркам процессора) задержке при поступлении данных по компьютерной шине . Значительный объем исследований был направлен на разработку проектов, позволяющих максимально избежать этих задержек. На протяжении многих лет основной целью было параллельное выполнение большего количества инструкций, тем самым увеличивая эффективную скорость выполнения программы. Эти усилия привели к созданию сложной логики и схемных структур. Первоначально эти методы можно было реализовать только на дорогих мейнфреймах или суперкомпьютерах из-за большого количества схем, необходимых для этих методов. По мере развития производства полупроводников все больше и больше этих технологий можно было реализовать на одном полупроводниковом кристалле. См. закон Мура .
Выбор набора команд
[ редактировать ]Наборы инструкций с годами менялись: от изначально очень простых до иногда очень сложных (в различных отношениях). В последние годы архитектуры load-store , типы VLIW и EPIC в моде . Архитектуры, которые имеют дело с параллелизмом данных, включают SIMD и Vectors . Некоторые метки, используемые для обозначения классов архитектур ЦП, не особенно информативны, особенно метка CISC; Многие ранние разработки, получившие задним числом обозначение CISC , на самом деле значительно проще современных RISC-процессоров (в нескольких отношениях).
Однако выбор архитектуры набора команд может сильно повлиять на сложность реализации высокопроизводительных устройств. Основная стратегия, использованная при разработке первых RISC-процессоров, заключалась в упрощении инструкций до минимума индивидуальной семантической сложности в сочетании с высокой регулярностью и простотой кодирования. Такие унифицированные инструкции легко извлекались, декодировались и выполнялись конвейерным способом, а также применялась простая стратегия уменьшения количества логических уровней для достижения высоких рабочих частот; Кэш-память инструкций компенсировала более высокую рабочую частоту и низкую плотность кода , в то время как большие наборы регистров использовались для исключения как можно большего количества (медленных) обращений к памяти.
Конвейерная обработка инструкций
[ редактировать ]Одним из первых и наиболее мощных методов повышения производительности является использование конвейерной обработки инструкций . Ранние конструкции процессоров выполняли все описанные выше шаги для одной инструкции, прежде чем переходить к следующей. Большие части схемы оставались бездействующими на любом этапе; например, схема декодирования инструкций будет простаивать во время выполнения и так далее.
Конвейерная обработка повышает производительность, позволяя нескольким инструкциям одновременно проходить через процессор. В том же базовом примере процессор начнет декодировать (шаг 1) новую инструкцию, пока последняя ожидает результатов. Это позволит одновременно выполнять до четырех инструкций, в результате чего процессор будет выглядеть в четыре раза быстрее. Хотя выполнение любой инструкции занимает столько же времени (этапов по-прежнему четыре), процессор в целом «выводит» инструкции из эксплуатации гораздо быстрее.
RISC делает конвейеры меньшими и упрощает их построение, четко разделяя каждый этап процесса инструкций и заставляя их занимать одинаковое количество времени — один цикл. Процессор в целом работает по принципу конвейера : инструкции приходят с одной стороны, а результаты — с другой. Из-за уменьшенной сложности классического RISC-конвейера конвейерное ядро и кэш инструкций можно было разместить на кристалле того же размера, который в противном случае поместился бы только в ядре в конструкции CISC. Это была настоящая причина того, что RISC был быстрее. Ранние разработки, такие как SPARC и MIPS, часто работали более чем в 10 раз быстрее, чем решения CISC Intel и Motorola при той же тактовой частоте и цене.
Трубопроводы ни в коем случае не ограничиваются конструкциями RISC. К 1986 году лучшая реализация VAX ( VAX 8800 ) представляла собой сильно конвейерную конструкцию, немного предшествовавшую первым коммерческим разработкам MIPS и SPARC. Большинство современных ЦП (даже встроенных ЦП) теперь имеют конвейерную обработку, а ЦП с микрокодированием без конвейерной обработки можно встретить только во встроенных процессорах с наибольшими ограничениями по площади. [ необходимы примеры ] Большие CISC-машины, от VAX 8800 до современных Pentium 4 и Athlon, реализованы как с помощью микрокода, так и с помощью конвейеров. Улучшения в конвейерной обработке и кэшировании — два основных достижения в микроархитектуре, которые позволили производительности процессоров идти в ногу с схемотехническими технологиями, на которых они основаны.
Кэш
[ редактировать ]Вскоре усовершенствования в производстве микросхем позволили разместить на кристалле еще больше схем, и конструкторы начали искать способы их использования. Одним из наиболее распространенных было добавление постоянно растущего объема кэш-памяти на кристалле. Кэш — очень быстрая и дорогая память. Доступ к нему можно получить за несколько циклов, в отличие от многих, необходимых для «разговора» с основной памятью. ЦП включает в себя контроллер кэша, который автоматизирует чтение и запись из кэша. Если данные уже находятся в кэше, доступ к ним осуществляется оттуда – при значительной экономии времени, тогда как в противном случае процессор «зависает», пока контроллер кэша считывает их.
В RISC-проектах в середине-конце 1980-х годов начали добавлять кэш, часто всего 4 КБ. Это число со временем росло, и теперь типичные процессоры имеют как минимум 2 МБ, в то время как более мощные процессоры имеют 4, 6, 12 МБ или даже 32 МБ или более, при этом наибольший объем памяти составляет 768 МБ в недавно выпущенной линейке EPYC Milan-X, организованной в несколько уровней иерархии памяти . Вообще говоря, больший объем кэша означает большую производительность из-за уменьшения зависаний.
Кэши и конвейеры идеально подходили друг другу. Раньше не имело особого смысла создавать конвейер, который мог бы работать быстрее, чем задержка доступа к внешней памяти. Вместо этого использование встроенной кэш-памяти означало, что конвейер мог работать со скоростью задержки доступа к кэшу, то есть в течение гораздо меньшего периода времени. Это позволило рабочим частотам процессоров увеличиваться гораздо быстрее, чем у внекристальной памяти.
Прогнозирование ветвей
[ редактировать ]Одним из препятствий на пути достижения более высокой производительности за счет параллелизма на уровне инструкций являются остановки конвейера и сбросы данных из-за ветвей. Обычно неизвестно, будет ли выполнен условный переход, до самого конца конвейера, поскольку условные переходы зависят от результатов, поступающих из регистра. С того момента, как декодер команд процессора обнаружил, что он столкнулся с командой условного перехода, и до момента, когда решающее значение регистра может быть считано, конвейер должен быть остановлен на несколько циклов, или, если это не так, и ветвь прекращается. принято, трубопровод необходимо промыть. По мере увеличения тактовой частоты глубина конвейера увеличивается, и некоторые современные процессоры могут иметь 20 и более этапов. В среднем каждая пятая выполняемая инструкция представляет собой ветвление, поэтому без какого-либо вмешательства это приводит к большому количеству остановок.
Такие методы, как предсказание ветвлений и спекулятивное выполнение, используются для уменьшения этих штрафов за ветвление. Прогнозирование ветвей — это когда оборудование делает обоснованные предположения о том, будет ли выбрана конкретная ветвь. В действительности на ту или иную сторону ветки будут звонить гораздо чаще, чем на другую. Современные конструкции имеют довольно сложные системы статистического прогнозирования, которые отслеживают результаты прошлых ветвей, чтобы с большей точностью предсказать будущее. Это предположение позволяет оборудованию предварительно выбирать инструкции, не дожидаясь чтения регистра. Спекулятивное выполнение — это дальнейшее усовершенствование, при котором код по предсказанному пути не только предварительно извлекается, но и выполняется до того, как станет известно, следует ли переходить по этой ветви или нет. Это может повысить производительность, если предположение верно, но с риском огромных штрафов, если предположение неверно, поскольку инструкции необходимо отменить.
Суперскаляр
[ редактировать ]Несмотря на всю добавленную сложность и элементы, необходимые для поддержки изложенных выше концепций, улучшения в производстве полупроводников вскоре позволили использовать еще больше логических элементов.
В схеме выше процессор обрабатывает части одной инструкции за раз. Компьютерные программы могли бы выполняться быстрее, если бы одновременно обрабатывалось несколько инструкций. Именно этого достигают суперскалярные процессоры, копируя функциональные блоки, такие как ALU. Тиражирование функциональных блоков стало возможным только тогда, когда площадь кристалла процессора одного выпуска больше не выходила за пределы того, что можно было надежно произвести. К концу 1980-х годов на рынок начали выходить суперскалярные конструкции.
В современных конструкциях обычно встречаются две единицы загрузки, одно хранилище (многие инструкции не имеют результатов для хранения), два или более целочисленных математических модуля, два или более модуля с плавающей запятой и часто SIMD какой-либо модуль . Логика выдачи инструкций усложняется из-за считывания огромного списка инструкций из памяти и передачи их различным исполнительным модулям, которые в этот момент простаивают. Затем результаты собираются и в конце переупорядочиваются.
Исполнение вне очереди
[ редактировать ]Добавление кешей снижает частоту или продолжительность зависаний из-за ожидания выборки данных из иерархии памяти, но не избавляет от этих зависаний полностью. В ранних разработках промах в кэше заставлял контроллер кэша останавливать процессор и ждать. Конечно, в программе может быть какая-то другая инструкция, данные которой в этот момент доступны в кэше. Выполнение вне порядка позволяет обработать готовую инструкцию, пока более старая инструкция ожидает в кеше, а затем переупорядочивает результаты, чтобы казалось, что все произошло в запрограммированном порядке. Этот метод также используется, чтобы избежать других задержек из-за зависимостей операндов, таких как инструкция, ожидающая результата от операции с плавающей запятой с большой задержкой или других многоцикловых операций.
Зарегистрировать переименование
[ редактировать ]Переименование регистров относится к методу, используемому для предотвращения ненужного последовательного выполнения программных инструкций из-за повторного использования этими инструкциями одних и тех же регистров. Предположим, у нас есть две группы инструкций, которые будут использовать один и тот же регистр . Один набор инструкций выполняется первым, чтобы оставить регистр другому набору, но если другой набор назначен другому аналогичному регистру, оба набора инструкций могут выполняться параллельно (или) последовательно.
Многопроцессорность и многопоточность
[ редактировать ]Компьютерные архитекторы оказались в тупике из-за растущего несоответствия рабочих частот ЦП и времени доступа к DRAM . Ни один из методов, использующих параллелизм на уровне команд (ILP) в одной программе, не мог компенсировать длительные задержки, возникающие при необходимости извлечения данных из основной памяти. Кроме того, большое количество транзисторов и высокие рабочие частоты, необходимые для более совершенных методов ILP, требовали таких уровней рассеиваемой мощности, которые больше нельзя было дешево охлаждать. По этим причинам новые поколения компьютеров начали использовать более высокие уровни параллелизма, существующие за пределами одной программы или программного потока .
Эту тенденцию иногда называют « вычислением пропускной способности» . Эта идея возникла на рынке мэйнфреймов, где при онлайн-обработке транзакций особое внимание уделялось не только скорости выполнения одной транзакции, но и способности обрабатывать огромное количество транзакций. Поскольку за последнее десятилетие значительно увеличилось количество приложений, основанных на транзакциях, таких как сетевая маршрутизация и обслуживание веб-сайтов, компьютерная индустрия вновь обратила внимание на проблемы емкости и пропускной способности.
Один из способов достижения этого параллелизма — использование многопроцессорных систем, компьютерных систем с несколькими процессорами. ранее предназначенные для высокопроизводительных мейнфреймов и суперкомпьютеров Небольшие (2–8) многопроцессорные серверы, , стали обычным явлением на рынке малого бизнеса. Для крупных корпораций обычно используются крупномасштабные (16–256) мультипроцессоры. даже персональные компьютеры С 1990-х годов появились с несколькими процессорами.
С дальнейшим уменьшением размеров транзисторов, ставшим возможным благодаря достижениям полупроводниковых технологий, появились многоядерные процессоры , в которых несколько процессоров реализованы на одном кремниевом чипе. Первоначально использовался в чипах, предназначенных для рынков встраиваемых систем, где более простые и меньшие по размеру процессоры позволяли разместить несколько экземпляров на одном куске кремния. для двух высокопроизводительных настольных процессоров CMP К 2005 году полупроводниковые технологии позволили массово производить чипы . Некоторые конструкции, такие как Sun Microsystems от UltraSPARC T1 , вернулись к более простым (скалярным, упорядоченным) конструкциям, чтобы разместить больше процессоров на одном кристалле.
Еще один метод, который в последнее время стал более популярным, — это многопоточность . При многопоточности, когда процессору приходится извлекать данные из медленной системной памяти, вместо того, чтобы ждать прибытия данных, процессор переключается на другую программу или программный поток, готовый к выполнению. Хотя это не ускоряет конкретную программу/поток, оно увеличивает общую пропускную способность системы за счет сокращения времени простоя ЦП.
Концептуально многопоточность эквивалентна переключению контекста на уровне операционной системы. Разница в том, что многопоточный ЦП может выполнить переключение потоков за один цикл ЦП вместо сотен или тысяч циклов ЦП, которые обычно требуются для переключения контекста. Это достигается путем репликации аппаратного обеспечения состояния (например, файла регистров и счетчика программ ) для каждого активного потока.
Еще одним усовершенствованием является одновременная многопоточность . Этот метод позволяет суперскалярным процессорам одновременно выполнять инструкции из разных программ/потоков в одном и том же цикле.
См. также
[ редактировать ]- Блок управления
- Аппаратная архитектура
- Язык описания оборудования (HDL)
- Параллелизм на уровне инструкций (ILP)
- Список микроархитектур процессоров AMD
- Список микроархитектур процессоров Intel
- Дизайн процессора
- Потоковая обработка
- VHDL
- Очень крупномасштабная интеграция (СБИС)
- Верилог
Ссылки
[ редактировать ]- ^ Рекомендации по учебной программе для программ бакалавриата в области компьютерной инженерии (PDF) . Ассоциация вычислительной техники. 2004. с. 60. Архивировано из оригинала (PDF) 3 июля 2017 г.
Комментарии к компьютерной архитектуре и организации: Компьютерная архитектура является ключевым компонентом компьютерной инженерии, и практикующий компьютерный инженер должен иметь практическое понимание этой темы...
- ^ Мердокка, Майлз; Хеуринг, Винсент (2007). Компьютерная архитектура и организация, комплексный подход . Уайли. п. 151. ИСБН 9780471733881 .
- ^ Клементс, Алан. Принципы компьютерного оборудования (4-е изд.). стр. 1–2.
- ^ Флинн, Майкл Дж. (2007). «Введение в архитектуру и машины» . Архитектура компьютера. Проектирование конвейерных и параллельных процессоров . Джонс и Бартлетт. стр. 1–3. ISBN 9780867202045 .
- ^ Перейти обратно: а б Хеннесси, Джон Л .; Паттерсон, Дэвид А. (2006). Компьютерная архитектура: количественный подход (4-е изд.). Морган Кауфманн. ISBN 0-12-370490-1 .
- ^ Уилкс, М.В. (1969). «Рост интереса к микропрограммированию: обзор литературы» . Обзоры вычислительной техники ACM . 1 (3): 139–145. дои : 10.1145/356551.356553 . S2CID 10673679 .
Дальнейшее чтение
[ редактировать ]- Паттерсон, Д.; Хеннесси, Дж. (2004). Организация и проектирование компьютера: аппаратно-программный интерфейс . Морган Кауфманн. ISBN 1-55860-604-1 .
- Хамахер, ВК; Врасенич, З.Г.; Заки, С.Г. (2001). Компьютерная организация . МакГроу-Хилл. ISBN 0-07-232086-9 .
- Столлингс, Уильям (2002). Компьютерная организация и архитектура . Прентис Холл. ISBN 0-13-035119-9 .
- Хейс, JP (2002). Компьютерная архитектура и организация . МакГроу-Хилл. ISBN 0-07-286198-3 .
- Шнайдер, Гэри Майкл (1985). Принципы организации компьютера . Уайли. стр. 6–7 . ISBN 0-471-88552-5 .
- Мано, М. Моррис (1992). Архитектура компьютерной системы . Прентис Холл. п. 3 . ISBN 0-13-175563-3 .
- Абд-эль-Барр, Мостафа; Эль-Ревини, Хешам (2004). Основы организации и архитектуры компьютера . Уайли. п. 1. ISBN 0-471-46741-3 .
- Гарднер, Дж (2001). «Микроархитектура процессора ПК» . ЭкстримТех.
- Гилрит, Уильям Ф.; Лапланте, Филип А. (2012) [2003]. Компьютерная архитектура: минималистский взгляд . Спрингер. ISBN 978-1-4615-0237-1 .
- Паттерсон, Дэвид А. (10 октября 2018 г.). Новый золотой век компьютерной архитектуры . Коллоквиум лауреатов премии ACM AM Turing в Беркли, США. ctwj53r07yI.