Текст добыча
Майнинг текста , интеллектуальный анализ текстовых данных ( TDM ) или текстовая аналитика -это процесс получения высококачественной информации из текста . Он включает в себя «обнаружение по компьютеру новой, ранее неизвестной информации путем автоматического извлечения информации из разных письменных ресурсов». [ 1 ] Письменные ресурсы могут включать веб -сайты , книги , электронные письма , обзоры и статьи. Высококачественная информация обычно получается путем разработки закономерностей и тенденций, такими как статистическое обучение шаблона . Согласно Hotho et al. (2005) Мы можем различать три различных перспективы добычи текста: извлечение информации , интеллектуальный анализ данных и процесс обнаружения знаний в базах данных (KDD). [ 2 ] Майнинг текста обычно включает в себя процесс структурирования входного текста (обычно анализ , наряду с добавлением некоторых полученных лингвистических особенностей и удаления других, а также последующей вставки в базу данных ), получение шаблонов в структурированных данных и, наконец, оценка и интерпретация вывода. «Высокое качество» в добыче текста обычно относится к некоторой комбинации актуальности , новизны и интереса. Типичные задачи по добыче текста включают в себя категоризация текста , кластеризацию текста , извлечение концепции/сущности, производство гранулярных таксономий, анализ настроений , суммирование документов и моделирование отношений сущности ( то есть обучающие отношения между названными объектами ).
Анализ текста включает в себя поиск информации , лексический анализ для изучения распределений частот слов, распознавания шаблонов , тегов / аннотации , извлечения информации , методов интеллектуального анализа данных , включая анализ ссылок и ассоциации, визуализацию и прогнозирующую аналитику . По сути, всеобъемлющей целью состоит в том, чтобы превратить текст в данные для анализа с помощью применения обработки естественного языка (NLP), различных типов алгоритмов и аналитических методов. Важной фазой этого процесса является интерпретация собранной информации.
Типичным приложением является сканирование набора документов, записанных на естественном языке , и либо моделировать документ , набор для целей прогнозирующей классификации , либо заполнить базу данных или индекс поиска с помощью извлеченной информации. Документ . является основным элементом при начинании с добычи текста Здесь мы определяем документ как единицу текстовых данных, которая обычно существует во многих типах коллекций. [ 3 ]
Текстовая аналитика
[ редактировать ]Text Analytics описывает набор лингвистических , статистических методов и машинного обучения , которые моделируют и структурируют информационное содержание текстовых источников для бизнес -аналитики , анализа данных , исследований или исследований. [ 4 ] Термин является примерно синонимом добычи текста; Действительно, Ронен Фельдман изменил описание «добычи текста» в 2000 году. [ 5 ] в 2004 году для описания «Текстовой аналитики». [ 6 ] Последний термин в настоящее время используется чаще в бизнес -настройках, в то время как «добыча текста» используется в некоторых из самых ранних областей применения, датируемых 1980 -х годов, [ 7 ] Примечательно исследования наук о жизни и правительственных разведке.
Термин «Аналитика текста» также описывает, что применение текстовой аналитики для реагирования на бизнес -задачи, независимо от того, независимо от того, независимо от того, независимо от того, независимо от того, в сочетании с запросом и анализом полевых, численных данных. Это трюизм, что 80 процентов связанной с бизнесом информации возникает в неструктурированной форме, в первую очередь в тексте. [ 8 ] Эти методы и процессы обнаруживают и представляют знания - факты, бизнес -правила и отношения - которые в противном случае заблокированы в текстовой форме, непроницаемой для автоматизированной обработки.
Процессы анализа текста
[ редактировать ]Подзадачи-совместные средства более крупных текстовых усилий-типично включают в себя:
- Сокращение размерности является важным методом предварительной обработки данных. Техника используется для определения корневого слова для реальных слов и уменьшения размера текстовых данных. [ Цитация необходима ]
- Поиск информации или идентификация корпуса - это подготовительный шаг: сбор или идентификация набора текстовых материалов, в Интернете или удерживаемых в файловой системе , базе данных или Content Corpus Manager , для анализа.
- Хотя некоторые системы текстовых анализов применяют исключительно продвинутые статистические методы, многие другие применяют более обширную обработку естественного языка , такие как часть тегинга речи , синтаксического анализа и других типов лингвистического анализа. [ 9 ]
- Признание объекта - это использование газетчиков или статистических методов для определения названных текстовых функций: люди, организации, названия помещений, символы фондовых тикеров, определенные сокращения и так далее.
- Несчастное значение - использование контекстуальных подсказок - может быть необходимо решить, где, например, «Форд» может относиться к бывшему президенту США, производителю транспортных средств, кинозвезде, пересечению реки или какой -либо другой организации. [ 10 ]
- Распознавание идентифицированных объектов с шаблоном: такие функции, как телефонные номера, адреса электронной почты, величины (с единицами), могут быть замечены с помощью регулярного выражения или других совпадений с шаблонами .
- Кластеризация документов : идентификация наборов аналогичных текстовых документов. [ 11 ]
- Coreference : идентификация существительных фраз и другие термины, которые относятся к одному и тому же объекту.
- Отношения, факт и извлечение событий: выявление ассоциаций между организациями и другой информацией в текстах.
- Анализ настроений включает в себя проницательное субъективное (в отличие от фактического) материала и извлечение различных форм взгляда на отношение: настроения, мнение, настроение и эмоции. Методы текстовой аналитики помогают анализировать настроения на уровне сущности, концепции или темы и различать владельцев и объектов мнений. [ 12 ]
- Количественный анализ текста представляет собой набор методов, связанных с социальными науками, в которых либо человеческий судья, либо компьютерные издает семантические или грамматические отношения между словами, чтобы выяснить значение или стилистические модели, как правило, случайный личный текст для целей цели Психологическое профилирование и т. Д. [ 13 ]
- Предварительная обработка обычно включает в себя такие задачи, как токенизация, фильтрация и вытекание.
Приложения
[ редактировать ]Технология текста в настоящее время широко применяется к широкому разнообразию правительственных, исследований и потребностей бизнеса. Все эти группы могут использовать добычу текста для управления записями и поисковые документы, относящиеся к их повседневной деятельности. специалисты юристов могут использовать текстовое майнинг для электронного открытия Например, . Правительства и военные группы используют текстовое добычу в целях национальной безопасности и разведки. Научные исследователи включают подходы добычи текста в усилия по организации больших наборов текстовых данных (то есть, решающим проблему неструктурированных данных ), для определения идей, передаваемых через текст (например, анализ настроений в социальных сетях [ 14 ] [ 15 ] [ 16 ] ) и поддержать научное открытие в таких областях, как наук о жизни и биоинформатика . В бизнесе приложения используются для поддержки конкурентной разведки и автоматического размещения рекламы , среди множества других видов деятельности.
Заявки на безопасность
[ редактировать ]Многие пакеты программного обеспечения для добычи текста продаются для приложений безопасности , особенно для мониторинга и анализа онлайн -источников текста, таких как интернет -новости , блоги и т. Д. Для целей национальной безопасности . [ 17 ] Он также участвует в изучении текстового шифрования / дешифрования .
Биомедицинские применения
[ редактировать ]
Был описан ряд применений для добычи текста в биомедицинской литературе, [ 19 ] включая вычислительные подходы, чтобы помочь в исследованиях на стыковке белка , [ 20 ] белковые взаимодействия , [ 21 ] [ 22 ] и протеиновые ассоциации. [ 23 ] Кроме того, с крупными текстовыми наборами данных пациента в клинической области, наборы данных демографической информации в популяционных исследованиях и отчетах о побочных явлениях, добыча текста может облегчить клинические исследования и точную медицину. Алгоритмы добычи текста могут облегчить стратификацию и индексацию специфических клинических событий в крупных текстовых наборах пациентов с симптомами, побочными эффектами и сопутствующими заболеваниями из электронных медицинских карт, отчетов о событиях и отчетов из конкретных диагностических тестов. [ 24 ] Одним из онлайн -приложений для майнинга текста в биомедицинской литературе является Pubgene , общедоступная поисковая система , которая объединяет майнинги биомедицинского текста с визуализацией сети. [ 25 ] [ 26 ] Gopubmed -это поисковая система, основанная на знаниях для биомедицинских текстов. Методы добычи текста также позволяют нам извлекать неизвестные знания из неструктурированных документов в клинической области [ 27 ]
Программные приложения
[ редактировать ]Методы добычи текста и программное обеспечение также исследуются и разрабатываются крупными фирмами, включая IBM и Microsoft , для дальнейшей автоматизации процессов добычи и анализа, а также различными фирмами, работающими в области поиска и индексации в целом как способ улучшить свои результаты Полем В государственном секторе много усилий было сосредоточено на создании программного обеспечения для отслеживания и мониторинга террористической деятельности . [ 28 ] Для учебных целей программное обеспечение WEKA является одним из самых популярных вариантов в научном мире, выступая в качестве отличной точки зрения для начинающих. Для программистов Python есть отличный инструментарий под названием NLTK для более общих целей. Для более продвинутых программистов есть также библиотека Генсим , которая фокусируется на текстовых представлениях на основе слова.
Онлайн -приложения для медиа
[ редактировать ]Майнинг текста используется крупными медиа -компаниями, такими как компания Tribune , чтобы прояснить информацию и предоставить читателям больший поисковый опыт, что, в свою очередь, увеличивает «липкость» и доходы. Кроме того, на заднем плане редакторы получают выгоду, имея возможность делиться, ассоциировать и упаковывать новости по свойствам, что значительно увеличивает возможности для монетизации контента.
Приложения для бизнеса и маркетинга
[ редактировать ]Текстовая аналитика используется в бизнесе, особенно в маркетинге, например, в управлении взаимоотношениями с клиентами . [ 29 ] Кузенция и Ван ден Поэль (2008) [ 30 ] [ 31 ] Примените его, чтобы улучшить модели прогнозирующей аналитики для оттока клиентов ( истощение клиентов ). [ 30 ] Добыча текста также применяется в прогнозировании доходов. [ 32 ]
Анализ настроений
[ редактировать ]Анализ настроений может включать анализ продуктов, таких как фильмы, книги или обзоры отелей для оценки того, насколько благоприятный обзор для продукта. [ 33 ] Такой анализ может потребоваться маркированный набор данных или маркировка влияния слов . Ресурсы для влияния слов и концепций были сделаны для Wordnet [ 34 ] и conceptNet , [ 35 ] соответственно.
Текст использовался для обнаружения эмоций в соответствующей области аффективных вычислений. [ 36 ] Текстовые подходы к аффективным вычислениям использовались в нескольких корпусах, таких как оценки студентов, детские истории и новости.
Научная литература добыча и академические применения
[ редактировать ]Вопрос о добыче текста имеет важное значение для издателей, которые содержат большие базы данных информации, нуждающихся в индексации для поиска. Это особенно верно в научных дисциплинах, в которых очень специфическая информация часто содержится в письменном тексте. Таким образом, были приняты инициативы, такие как предложение Nature для раздела интерфейс с открытым текстом (OTMI) и институт здравоохранения» журнал «Национальный общий . Текст, не удаляя барьеры издателей для публичного доступа.
Академические учреждения также участвовали в инициативе по добыче текста:
- Национальный центр по добыче текста (NACTEM) является первым финансируемым в мире центром добычи текста в мире. NACTEM управляется Университетом Манчестера [ 37 ] в тесном сотрудничестве с лабораторией Tsujii, [ 38 ] Университет Токио . [ 39 ] Nactem предоставляет индивидуальные инструменты, исследовательские объекты и дает советы академическому сообществу. Они финансируются Комитетом Объединенных информационных систем (JISC) и двумя исследовательскими советами Великобритании ( EPSRC & BBSRC ). С первоначальным акцентом на добычу текста в биологических и биомедицинских науках, исследования с тех пор расширились до областей социальных наук .
- В Соединенных Штатах, Школе информации в Калифорнийском университете, Беркли разрабатывает программу под названием Biotext для оказания помощи исследователям биологии в добыче текста и анализе.
- Портал «Анализ текста для исследований» (Tapor), в настоящее время размещенный в Университете Альберты , является научным проектом по каталогу приложений для анализа текста и создания шлюза для исследователей, новых для практики.
Методы добычи научной литературы
[ редактировать ]Вычислительные методы были разработаны, чтобы помочь с поиском информации из научной литературы. Опубликованные подходы включают методы поиска, [ 40 ] Определение новизны, [ 41 ] и уточняет омонимы [ 42 ] Среди технических отчетов.
Цифровые гуманитарные и вычислительные социологии
[ редактировать ]Автоматический анализ обширных текстовых корпораций создал возможность для ученых анализировать Миллионы документов на нескольких языках с очень ограниченным ручным вмешательством. Ключевыми технологиями были анализ, машинный перевод тем , категоризация и машинное обучение.
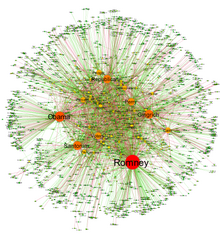
Автоматический анализ текстовых корпораций позволил извлечь участников и их реляционные сети в обширном масштабе, превратив текстовые данные в сетевые данные. Полученные сети, которые могут содержать тысячи узлов, затем анализируются с использованием инструментов из теории сети для определения ключевых субъектов, ключевых сообществ или сторон, а также общие свойства, такие как надежность или структурная стабильность общей сети, или столетняя определенных узлы. [ 44 ] Это автоматизирует подход, введенный количественным повествовательным анализом, [ 45 ] в результате чего триплеты субъекта-верб-объекта идентифицируются с парами актеров, связанных действием, или пар, образованные актером-объектом. [ 43 ]
Контент -анализ долгое время был традиционной частью социальных наук и средств массовой информации. Автоматизация анализа контента позволила революции « большие данные » в этой области, с исследованиями в социальных сетях и газетном контенте, которые включают миллионы новостей. Гендерные предвзятости , читабельность , сходство контента, предпочтения читателя и даже настроение были проанализированы на основе методов добычи текста в течение миллионов документов. [ 46 ] [ 47 ] [ 48 ] [ 49 ] [ 50 ] Анализ читабельности, гендерного смещения и предвзятости темы был продемонстрирован во Flaounas et al. [ 51 ] показывая, как разные темы имеют разные гендерные смещения и уровни читабельности; Возможность обнаружения моделей настроения в огромной популяции путем анализа контента в Твиттере также была продемонстрирована. [ 52 ] [ 53 ]
Программное обеспечение
[ редактировать ]Компьютерные программы для добычи текста доступны во многих коммерческих и открытых компаниях и источниках.
Закон об интеллектуальной собственности
[ редактировать ]Ситуация в Европе
[ редактировать ]В соответствии с европейскими об авторском праве и законами базах данных добыча работ в сфере капиталов (например, веб-добыча ) без разрешения владельца авторских прав является незаконным. В Великобритании в 2014 году, по рекомендации Обзора Hargreaves , правительство внесено в изменение закона об авторском праве [ 54 ] Чтобы позволить добыче текста как ограничение и исключение . Это была вторая страна в мире, которая сделала это после Японии , которая внесла специальное исключение в 2009 году. Однако из-за ограничения Директивы Информационного общества (2001) исключение в Великобритании позволяет только добывать контент для не в том, чтобы не допустить. Коммерческие цели. Закон об авторском праве в Великобритании не позволяет переопределять это положение по договорным условиям.
Европейская комиссия облегчила обсуждение заинтересованных сторон по поводу интеллектуального анализа текстов и данных в 2013 году под названием лицензий на Европу. [ 55 ] Тот факт, что акцентом на решение этой юридической проблемы было лицензии, а не ограничения и исключения из -за закона об авторском праве, привели представителей университетов, исследователей, библиотек, групп гражданского общества и издателей открытого доступа , чтобы оставить диалог заинтересованных сторон в мае 2013 года. [ 56 ]
Ситуация в Соединенных Штатах
[ редактировать ]Закон об авторском праве США и, в частности, его положения о справедливом использовании , означает, что добыча текста в Америке, а также другие страны справедливого использования, такие как Израиль, Тайвань и Южная Корея, считаются законными. Поскольку добыча текста преобразует, что означает, что она не вытесняет исходную работу, она рассматривается как законная при справедливом использовании. Например, как часть урегулирования книги Google, председательствующий судья по этому делу постановил, что проект оцифровки Google в книгах с капиталом был законным, отчасти из-за трансформационного использования, который отображался проект оцифровки-одним из таких использования является интеллектуальным анализом. Полем [ 57 ]
Ситуация в Австралии
[ редактировать ]нет исключений В австралийском законе об авторском праве для интеллектуального анализа в соответствии с Законом об авторском праве 1968 года . Австралийская комиссия по реформе юристов отметила, что маловероятно, что исключение «Исследования и исследования» также распространится на то, чтобы охватить такую тему, учитывая, что это будет за пределами требования «разумной части». [ 58 ]
Подразумеваемое
[ редактировать ]До недавнего времени веб-сайты чаще всего использовали текстовые поиски, которые находили только документы, содержащие определенные пользовательские слова или фразы. Теперь, используя семантическую паутину , добыча текста может найти контент на основе значения и контекста (а не только с помощью конкретного слова). Кроме того, программное обеспечение для добычи текста может использоваться для создания больших досье информации о конкретных людях и событиях. Например, крупные наборы данных, основанные на данных, извлеченных из новостей, могут быть созданы для облегчения анализа социальных сетей или контрразведки . По сути, программное обеспечение для добычи текста может действовать в качестве мощности, аналогичного аналитику разведки или исследовательского библиотекаря, хотя и с более ограниченным объемом анализа. Майнинг текста также используется в некоторых спам -фильтрах по электронной почте как способ определения характеристик сообщений, которые, вероятно, будут рекламными объявлениями или другим нежелательным материалом. Майнинг текста играет важную роль в определении настроений финансового рынка .
Смотрите также
[ редактировать ]- Концепция добычи
- Обработка документов
- Полный текстовый поиск
- Список программного обеспечения для добычи текста
- Рыночные настроения
- Разрешение имени (семантика и извлечение текста)
- Названное признание сущности
- Аналитика новостей
- Онтология обучение
- Записная связь
- Последовательное майнингование рисунков (добыча строки и последовательности)
- W-Shingling
- Интернет -майнинг , задача, которая может включать в себя добычу текста (например, сначала найдите соответствующие веб -страницы, классифицируя ползанные веб -страницы, а затем извлеките желаемую информацию из текстового содержания этих страниц, которые считаются актуальными)
Ссылки
[ редактировать ]Цитаты
[ редактировать ]- ^ "Марти Херст: Что такое добыча текста?" Полем
- ^ Hotho, A., Nürnberger, A. and Paaus, G. (2005). «Краткий обзор добычи текста». На форуме LDV, вып. 20 (1), с. 19-62
- ^ Feldman, R. and Sanger, J. (2007). Справочник по добыче текста. Издательство Кембриджского университета. Нью-Йорк
- ^ [1] Архивировано 29 ноября 2009 г., на машине Wayback
- ^ «KDD-2000 Workshop по добыче текста-звоните для документов» . Cs.cmu.edu . Получено 2015-02-23 .
- ^ [2] Архивировано 3 марта 2012 года на машине Wayback
- ^ Хоббс, Джерри Р.; Уокер, Дональд Э.; Амслер, Роберт А. (1982). «Доступ естественного языка к структурированному тексту». Материалы 9 -й конференции по вычислительной лингвистике . Тол. 1. С. 127–32. doi : 10.3115/991813.991833 . S2CID 6433117 .
- ^ «Неструктурированные данные и правило 80 процентов» . Прорывной анализ. Август 2008 . Получено 2015-02-23 .
- ^ Антунес, Жуао (2018-11-14). Исследование контекстной информации для семантического обогащения в текстовых представлениях (Мастер в области компьютерных наук и вычислительной математики) (по португальскому языку). Сан -Карлос: Университет Сан -Паулу. Doi : 10.11606/d.55.2019.tde-03012019-103253 .
- ^ Моро, Андреа; Раганато, Алессандро; Navigli, Roberto (декабрь 2014 г.). «Связь сущности соответствует смысл слов неоднозначности: единый подход» . Транзакции Ассоциации по вычислительной лингвистике . 2 : 231–244. doi : 10.1162/tacl_a_00179 . ISSN 2307-387X .
- ^ Чанг, Вуи Ли; Тай, Кай Мэн; Лим, Чи Пэн (2017-02-06). «Новая развивающаяся модель на основе дерева с локальным повторным обучением для кластеризации и визуализации документов». Нейронные обработки букв . 46 (2): 379–409. doi : 10.1007/s11063-017-9597-3 . ISSN 1370-4621 . S2CID 9100902 .
- ^ Бенджамол, Джонатан; Казиньник, София; Саадон, Йосси (2022). «Методологии добычи текста с R: применение в текстовых текстах центрального банка» . Машинное обучение с приложениями . 8 : 100286. DOI : 10.1016/j.mlwa.2022.100286 . S2CID 243798160 .
- ^ Мел, Матиас Р. (2006). «Количественный анализ текста». Справочник по мультиметодному измерению в психологии . п. 141. doi : 10.1037/11383-011 . ISBN 978-1-59147-318-3 .
- ^ Панг, Бо; Ли, Лилиан (2008). «Анализ добычи мнений и настроений». Фонды и тенденции в поиске информации . 2 (1–2): 1–135. Citeseerx 10.1.1.147.2755 . DOI : 10.1561/1500000011 . ISSN 1554-0669 . S2CID 207178694 .
- ^ Paltoglou, Georgios; Thelwall, Mike (2012-09-01). «Twitter, Myspace, Digg: анализ неконтролируемых настроений в социальных сетях». Транзакции ACM по интеллектуальным системам и технологиям . 3 (4): 66. doi : 10.1145/2337542.2337551 . ISSN 2157-6904 . S2CID 16600444 .
- ^ «Анализ настроений в Twitter <Semeval-2017 Задача 4» . alt.qcri.org . Получено 2018-10-02 .
- ^ Занаси, Алессандро (2009). «Виртуальное оружие для реальных войн: добыча текста для национальной безопасности». Материалы Международного семинара по вычислительной интеллекте в области безопасности для информационных систем Cisis'08 . Достижения в мягких вычислениях. Тол. 53. с. 53. doi : 10.1007/978-3-540-88181-0_7 . ISBN 978-3-540-88180-3 .
- ^ Бадал, Варша Д.; Kundrotas, Petras J.; Vakser, Ilya A. (2015-12-09). «Текст -майнинга для белковой стыковки» . PLOS Computational Biology . 11 (12): E1004630. BIBCODE : 2015PLSCB..11E4630B . doi : 10.1371/journal.pcbi.1004630 . ISSN 1553-7358 . PMC 4674139 . PMID 26650466 .
- ^ Коэн, К. Бретоннел; Хантер, Лоуренс (2008). «Начало работы в добыче текста» . PLOS Computational Biology . 4 (1): E20. Bibcode : 2008plscb ... 4 ... 20с . doi : 10.1371/journal.pcbi.0040020 . PMC 2217579 . PMID 18225946 .
- ^ Бадал, В. Д; Kundrotas, P. J; Vakser, I. A (2015). «Текст -майнинга для белковой стыковки» . PLOS Computational Biology . 11 (12): E1004630. BIBCODE : 2015PLSCB..11E4630B . doi : 10.1371/journal.pcbi.1004630 . PMC 4674139 . PMID 26650466 .
- ^ Папаниколау, Николас; Павлопулос, Джорджиос А.? Теодосиу, Теодосиос; Iliopoulos, ioannis (2015). «Прогнозы взаимодействия белка - белок с использованием методов добычи текста». Методы 74 : 47–53. Doi : 10.1016/j.ymeth.2014.10.026 . ISSN 1046-2023 . PMID 25448298 .
- ^ Шкларцик, Дамиан; Моррис, Джон Х; Кук, Хелен; Кун, Майкл; Уайдер, Стефан; Симонович, Милан; Сантос, Альберто; Doncheva, Nadezhda T; Рот, Александр (2016-10-18). «База данных String в 2017 году: сети, контролируемые качеством белков-белковой ассоциации, стали широко доступными» . Исследование нуклеиновых кислот . 45 (D1): D362 - D368. doi : 10.1093/nar/gkw937 . ISSN 0305-1048 . PMC 5210637 . PMID 27924014 .
- ^ Liem, David A.; Мурали, Санджана; Сигдель, Дибакар; Ши, Ю; Ван, Сюань; Шен, Джиамин; Чой, Говард; Кауфилд, Джон Х.; Ван, Вэй; Пинг, Пипеи; Хан, Цзявей (2018-10-01). «Фраза добыча текстовых данных для анализа паттернов белка внеклеточного матрикса по сердечно -сосудистым заболеваниям» . Американский журнал физиологии. Сердечная и циркуляторная физиология . 315 (4): H910 - H924. doi : 10.1152/ajpheart.00175.2018 . ISSN 1522-1539 . PMC 6230912 . PMID 29775406 .
- ^ Ван Ле, D; Монтгомери, J; Киркби, KC; Scanlan, J (10 августа 2018 г.). «Прогноз риска с использованием обработки естественного языка электронных психиатрических карт в стационарной криминалистической психиатрии» . Журнал биомедицинской информатики . 86 : 49–58. doi : 10.1016/j.jbi.2018.08.007 . PMID 30118855 .
- ^ Jenssen, Tor-Kristian; Lægreid, Astrid; Коморовский, Ян; Hovig, Eivind (2001). «Литературная сеть генов человека для высокопроизводительного анализа экспрессии генов». Природа генетика . 28 (1): 21–8. doi : 10.1038/ng0501-21 . PMID 11326270 . S2CID 8889284 .
- ^ Masys, Daniel R. (2001). «Связывание данных микрочипа с литературой». Природа генетика . 28 (1): 9–10. doi : 10.1038/ng0501-9 . PMID 11326264 . S2CID 52848745 .
- ^ Ренганатан, Vinaitheerthan (2017). «Майнинг текста в биомедицинской области с акцентом на кластеризацию документов» . Исследование информатики в области здравоохранения . 23 (3): 141–146. doi : 10.4258/hir.2017.23.3.141 . ISSN 2093-3681 . PMC 5572517 . PMID 28875048 .
- ^ [3] Архивировано 4 октября 2013 г., на машине Wayback
- ^ «Текстовая аналитика» . Medallia . Получено 2015-02-23 .
- ^ Jump up to: а беременный Кус, Кристоф; Ван ден Поэль, Дирк (2008). «Интеграция голоса клиентов через электронные письма Call Center в систему поддержки принятия решений для прогнозирования оттока» . Информация и управление . 45 (3): 164–74. Citeseerx 10.1.1.113.3238 . doi : 10.1016/j.im.2008.01.005 .
- ^ Кус, Кристоф; Ван ден Поэль, Дирк (2008). «Улучшение управления жалобами клиентов путем автоматической классификации электронной почты с использованием функций языкового стиля в качестве предикторов» . Системы поддержки решений . 44 (4): 870–82. doi : 10.1016/j.dss.2007.10.010 .
- ^ Рамиро Х. Галвес; Агустин Гравано (2017). «Оценка полезности добычи доски онлайн -доски в автоматических системах прогнозирования запасов». Журнал вычислительной науки . 19 : 1877–7503. doi : 10.1016/j.jocs.2017.01.001 . HDL : 11336/60065 .
- ^ Панг, Бо; Ли, Лилиан; Vaithyanathan, Shivakumar (2002). "Недурно?". Труды конференции ACL-02 по эмпирическим методам в обработке естественного языка . Тол. 10. С. 79–86. doi : 10.3115/1118693.1118704 . S2CID 7105713 .
- ^ Алессандро Валитутти; Карло Страпарава; Oliviero Stock (2005). «Развитие аффективных лексических ресурсов» (PDF) . Психологический журнал . 2 (1): 61–83.
- ^ Эрик Камбрия; Роберт Спеер; Кэтрин Хаваси; Амир Хуссейн (2010). «Senticnet: общедоступный семантический ресурс для добычи мнений» (PDF) . Труды AAAI CSK . С. 14–18.
- ^ Кальво, Рафаэль А; D'Emello, Sidney (2010). «Обнаружение аффекта: междисциплинарный обзор моделей, методов и их приложений». IEEE транзакции на аффективные вычисления . 1 (1): 18–37. doi : 10.1109/t-affc.2010.1 . S2CID 753606 .
- ^ «Манчестерский университет» . Manchester.ac.uk . Получено 2015-02-23 .
- ^ "Tsujii Laboratory" . Tsujii.is.su-tokyo.ac.jp. Архивировано с оригинала 2012-03-07 . Получено 2015-02-23 .
- ^ «Университет Токио» . Утокио . Получено 2015-02-23 .
- ^ Шэньчжэнь, ; Jiaming . 978-1-4503-5657-2 Полем S2CID 13748283 .
- ^ Уолтер, Лотар; Радауэр, Альфред; Moehrle, Martin G. (2017-02-06). «Красота бабочки Brimstone: новизна патентов, идентифицированная с помощью анализа ближнего окружающей среды на основе добычи текста». Scientometrics . 111 (1): 103–115. doi : 10.1007/s11192-017-2267-4 . ISSN 0138-9130 . S2CID 11174676 .
- ^ Roll, Uri; Correia, Ricardo A.; Berger-Tal, Oded (2018-03-10). «Использование машинного обучения для распутывания омонимов в крупных текстовых корпусах». Биология сохранения . 32 (3): 716–724. doi : 10.1111/cobi.13044 . ISSN 0888-8892 . PMID 29086438 . S2CID 3783779 .
- ^ Jump up to: а беременный Автоматизированный анализ президентских выборов в США с использованием больших данных и сетевого анализа; S Sudhahar, Ga Veltri, N Cristianini; Большие данные и общество 2 (1), 1-28, 2015
- ^ Анализ сетевого повествовательного содержания в крупных корпусах; S Sudhahar, G De Fazio, R Franzosi, N Cristianini; Инженерия естественного языка, 1-32, 2013
- ^ Количественный повествовательный анализ; Роберто Франзози; Университет Эмори © 2010
- ^ Лансдалл-Веса, Томас; Судхахар, Саатвига; Томпсон, Джеймс; Льюис, Джастин; Команда, Findmypast газета; Cristianini, Nello (2017-01-09). «Контент -анализ 150 лет британских периодических изданий» . Труды Национальной академии наук . 114 (4): E457 - E465. BIBCODE : 2017PNAS..114E.457L . doi : 10.1073/pnas.1606380114 . ISSN 0027-8424 . PMC 5278459 . PMID 28069962 .
- ^ I. Flaounas, M. Turchi, O. Ali, N. Fyson, T. de Bie, N. Mosdell, J. Lewis, N. Cristianini, Структура Eu Mediassphere, Plos One, vol. 5 (12), с. E14243, 2010.
- ^ СОВЕРШЕНИЯ событий из социальной сети со статистическим обучением V Лампос, N Cristianini; Транзакции ACM по интеллектуальным системам и технологиям (TIST) 3 (4), 72
- ^ Ноам: система анализа и мониторинга новостей; I Flaounas, O Ali, M Turchi, T Snowsill, F Nicart, T De Bie, N Cristianini Proc. Международной конференции ACM SIGMOD 2011 года по управлению данными
- ^ Автоматическое обнаружение шаблонов в медиа-контенте, N Cristianini, сопоставление комбинаторных схем, 2-13, 2011
- ^ I. Flaounas, O. Ali, T. Lansdall-Welfare, T. de Bie, N. Mosdell, J. Lewis, N. Cristianini, Методы исследований в эпоху цифровой журналистики, цифровой журналистики, Routledge, 2012
- ^ Циркадные вариации настроения в контенте в Твиттере; Фабон Дзоганг, Стаффорд Лайтман, Нелло Криштианини. Достижения в мозге и нейробиологии, 1, 2398212817744501.
- ^ Влияние рецессии на общественное настроение в Великобритании; T Lansdall-Welfare, V Lampos, N Cristianini; Сессия динамики динамики социальной сети (MSND) в приложениях социальных сетей
- ^ Исследователи, которые дают данные прямо в соответствии с новыми британскими законами об авторском праве, архивированы 9 июня 2014 года на машине Wayback
- ^ «Лицензии на Европу - Структурированный диалог заинтересованных сторон 2013» . Европейская комиссия . Получено 14 ноября 2014 года .
- ^ «Текст и добыча данных: его важность и потребность в изменениях в Европе» . Ассоциация европейских исследовательских библиотек . 2013-04-25. Архивировано из оригинала 2014-11-29 . Получено 14 ноября 2014 года .
- ^ «Судья предоставляет суммарное суждение в пользу Google Books - победы справедливого использования» . Лексология . Antonelli Law Ltd. 19 ноября 2013 года . Получено 14 ноября 2014 года .
- ^ «Текст и интеллектуальный анализ данных» . Австралийская комиссия по реформе права . 4 июня 2013 года . Получено 10 февраля 2023 года .
Источники
[ редактировать ]- Ananiadou, S. and McNaught, J. (редакторы) (2006). Текст добыча для биологии и биомедицины . Artech House Books. ISBN 978-1-58053-984-5
- Bilisoly, R. (2008). Практический текст добычи с перлом . Нью -Йорк: Джон Уайли и сыновья. ISBN 978-0-470-17643-6
- Feldman, R. и Sanger, J. (2006). Справочник по добыче текста . Нью -Йорк: издательство Кембриджского университета. ISBN 978-0-521-83657-9
- Хото А., Нюрнбергер А. и Паас Г. (2005). «Краткий обзор добычи текста». На форуме LDV, вып. 20 (1), с. 19-62
- Indurkhya, N. и Damerau, F. (2010). Справочник по обработке естественного языка , 2 -е издание. Boca Raton, FL: CRC Press. ISBN 978-1200-8592-1
- Као, А. и Потет С. (редакторы). Обработка естественного языка и добыча текста . Спрингер. ISBN 1-84628-175-X
- Konchady, M. Программирование приложения для майнинга текста (серия программирования) . Чарльз Ривер СМИ. ISBN 1-58450-460-9
- Manning, C. и Schutze, H. (1999). Основы статистической обработки естественного языка . Кембридж, Массачусетс: MIT Press. ISBN 978-0-262-1360-9
- Miner, G., Elder, J., Hill. T, Nisbet R., Delen, D. and Fast, A. (2012). Практическая добыча текста и статистический анализ для неструктурированных приложений текстовых данных . Elsevier Academic Press. ISBN 978-0-12-386979-1
- McKnight, W. (2005). «Создание бизнес -аналитики: интеллектуальный анализ текстовых данных в бизнес -аналитике». Обзор DM , 21-22.
- Шривастава А. и Саами. М. (2009). Майнинг текста: классификация, кластеризация и приложения . Boca Raton, FL: CRC Press. ISBN 978-1200-5940-3
- Занаси А. (редактор) (2007). Добыча текста и его приложения к интеллекту, CRM и управлению знаниями . Остроумие пресс. ISBN 978-1-84564-131-3
Внешние ссылки
[ редактировать ]- Марти Херст: Что такое добыча текста? (Октябрь 2003 г.)
- Автоматическое извлечение контента, лингвистический консорциум данных архив 2013-09-25 на The Wayback Machine
- Автоматическое извлечение контента, NIST
| Базы данных управления авторитетом : национальный |
|---|