База данных генных заболеваний
| Классификация | Биоинформатика |
|---|---|
| Подклассификация | Базы данных |
| Тип баз данных | Биологический |
| Подтип баз данных | Ген-болезнь |
В биоинформатике база данных генных заболеваний представляет собой систематизированный набор данных, обычно структурированный для моделирования аспектов реальности, позволяющий понять основные механизмы сложных заболеваний путем понимания множества сложных взаимодействий между фенотип - генотипическими отношениями и механизмами генов и заболеваний. [1] Базы данных генных заболеваний объединяют ассоциации генов человека и болезней из различных баз данных, курируемых экспертами, и ассоциации, основанные на интеллектуальном анализе текста , включая менделевские, сложные и экологические заболевания. [2] [3]
Введение
[ редактировать ]Специалисты в различных областях биологии и биоинформатики уже давно пытаются понять молекулярные механизмы заболеваний для разработки профилактических и терапевтических стратегий. В отношении некоторых заболеваний стало очевидным, что необходимо проявить необходимую степень враждебности не для того, чтобы получить индекс генов, связанных с заболеванием, а для того, чтобы раскрыть, как нарушения молекулярных решеток в клетке приводят к возникновению фенотипов заболеваний. [4] Более того, даже при беспрецедентном обилии доступной информации получить такие каталоги крайне сложно.
Генетика. Грубо говоря, генетические заболевания вызваны аберрациями в генах или хромосомах . Многие генетические заболевания развиваются еще до рождения. Генетические нарушения являются причиной значительного числа проблем здравоохранения в нашем обществе. Достижения в понимании этих заболеваний увеличили как продолжительность, так и качество жизни многих из тех, кто страдает генетическими нарушениями. Недавние разработки в области биоинформатики и лабораторной генетики позволили лучше определить некоторые синдромы пороков развития и умственной отсталости, чтобы можно было понять способ их наследования. Эта информация позволяет генетическому консультанту прогнозировать риск возникновения большого количества генетических нарушений. [2] Однако в большинстве случаев генетическое консультирование проводится только после того, как рождение хотя бы одного пострадавшего человека предупредило семью о том, что они склонны иметь детей с генетическим заболеванием. Ассоциация одного гена с заболеванием встречается редко, и генетическое заболевание может быть или не быть трансмиссивным заболеванием. [5] Некоторые генетические заболевания наследуются от генов родителей, но другие вызваны новыми мутациями или изменениями в ДНК . В других случаях одно и то же заболевание, например, некоторые формы карциномы или меланомы , может быть вызвано врожденным заболеванием у некоторых людей, новыми изменениями у других людей и негенетическими причинами у других людей. [6]
Известно более шести тысяч моногенных нарушений (моногенных), которые встречаются примерно у 1 из каждых 200 новорожденных. [1] Как следует из их термина, эти заболевания вызваны мутацией в одном гене. Напротив, полигенные нарушения вызываются несколькими генами, обычно в сочетании с факторами окружающей среды. [7] Примеры генетических фенотипов включают болезнь Альцгеймера , рак молочной железы, лейкемию, синдром Дауна, пороки сердца и глухоту; поэтому необходима каталогизация, чтобы разобраться во всех заболеваниях, связанных с генами.
Проблемы с созданием
[ редактировать ]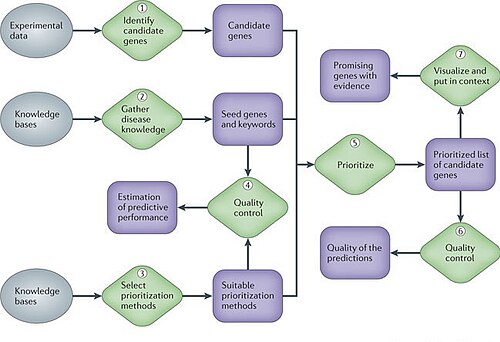
На разных этапах любого проекта по генным заболеваниям молекулярным биологам приходится выбирать, даже после тщательного статистического анализа данных, какие гены или белки следует исследовать дальше экспериментально, а какие оставить в стороне из-за ограниченности ресурсов. Вычислительные методы, которые объединяют сложные, гетерогенные наборы данных, такие как данные об экспрессии, информацию о последовательностях, функциональные аннотации и биомедицинскую литературу, позволяют более осознанно расставлять приоритеты генов для будущих исследований. Такие методы могут существенно повысить результативность последующих исследований и становятся неоценимыми для исследователей. Поэтому одной из главных задач биологических и биомедицинских исследований является распознавание механизмов, лежащих в основе этих сложных генетических фенотипов. Огромные усилия были потрачены на поиск генов, связанных с болезнями. [8]
Однако все больше данных указывают на то, что большинство заболеваний человека не могут быть связаны с одним геном, а возникают из-за сложных взаимодействий между многочисленными генетическими вариантами и факторами риска окружающей среды. Было разработано несколько баз данных, хранящих связи между генами и заболеваниями, такие как База данных сравнительной токсикогеномики (CTD), Онлайн-менделевская наследственность у человека (OMIM), База данных генетических ассоциаций (GAD) или База данных генетических ассоциаций заболеваний (DisGeNET). Каждая из этих баз данных фокусируется на различных аспектах взаимоотношений фенотип-генотип, и из-за характера процесса создания базы данных они не являются полными, но в некотором смысле полностью дополняют друг друга. [9]
Типы баз данных
[ редактировать ]По сути, существует четыре типа баз данных: курируемые базы данных, прогнозные базы данных, базы данных литературы и интегративные базы данных. [1]
Кураторские базы данных
[ редактировать ]Термин «курируемые данные» относится к информации, которая может включать в себя самые сложные вычислительные форматы для структурированных данных, научных обновлений и курируемых знаний, которая была составлена и подготовлена под руководством одного или нескольких экспертов, которые считаются квалифицированными для участия в таком процессе. активность [10] Подразумевается, что полученная база данных будет высокого качества. Контрастом являются данные, которые могли быть собраны с помощью какого-либо автоматизированного процесса или с использованием данных особенно низкого или некомпетентного, неподтвержденного качества и, возможно, не заслуживающих доверия. [10] Некоторые из наиболее распространенных примеров включают: CTD и UNIPROT.
База данных сравнительной токсикогеномики (CTD)
[ редактировать ]База данных сравнительной токсикогеномики помогает понять влияние соединений окружающей среды на здоровье человека путем интеграции данных из тщательно подобранной научной литературы для описания биохимических взаимодействий с генами и белками, а также связей между болезнями и химическими веществами, а также болезнями и генами или белками. [11] CTD содержит тщательно подобранные данные, определяющие межвидовые химические, генные и белковые взаимодействия, а также ассоциации химических и генных заболеваний, чтобы пролить свет на молекулярные механизмы, лежащие в основе изменчивой восприимчивости и заболеваний, влияющих на окружающую среду. Эти данные дают представление о сложных сетях взаимодействия химикатов, генов и белков. Одним из основных источников этой базы данных является тщательно подобранная информация OMIM. [11]
CTD — это уникальный ресурс, где специалисты по биоинформатике читают научную литературу и вручную обрабатывают четыре типа основных данных:
- Химико-генные взаимодействия
- Ассоциации химических заболеваний
- Ассоциации генов и заболеваний
- Химико-фенотипические ассоциации
Универсальный ресурс белка (UNIPROT)
[ редактировать ]Universal Protein Resource ( UniProt ) — это всеобъемлющий ресурс для данных о последовательностях белков и аннотаций. Это всеобъемлющая, первоклассная и свободно доступная база данных последовательностей белков и функциональной информации, в которой содержится множество записей, полученных в результате проектов секвенирования генома . Он содержит большое количество информации о биологической функции белков, полученной из научной литературы, что может намекать на прямую связь между геном-белком-заболеванием. [12]
| Содержание | |
|---|---|
| Описание | UniProt — это универсальный ресурс по белкам , центральное хранилище данных о белках, Swiss-Prot, TrEMBL и PIR-PSD созданное путем объединения баз данных . |
| Типы данных захвачен | Белковая аннотация |
| Организмы | Все |
| Контакт | |
| Исследовательский центр | EMBL-EBI , Великобритания; СИБ , Швейцария; ПИР , США. |
| Первичное цитирование | Текущие и будущие разработки Universal Protein Resource [13] |
| Доступ | |
| Формат данных | Пользовательский плоский файл, FASTA , GFF , RDF , XML . |
| Веб-сайт | www www |
| URL-адрес загрузки | www |
| веб-службы URL-адрес | Да – JAVA API см. информацию здесь , а REST см. информацию здесь. |
| Инструменты | |
| Интернет | Расширенный поиск, BLAST , Clustal O, массовое извлечение/загрузка, сопоставление идентификаторов |
| Разнообразный | |
| Лицензия | Creative Commons с указанием авторства – без производных |
| Управление версиями | Да |
| Выпуск данных частота | 4 недели |
| Политика курирования | Да, ручной и автоматический. Правила автоматического аннотирования, генерируемые кураторами базы данных и вычислительными алгоритмами. |
| Добавить в закладки сущности | Да – как отдельные записи белков, так и поиск |

Курируемые данные могут включать в себя процесс от практического опыта и обзора литературы до публикации базы данных в Интернете. [14]
Прогнозные базы данных
[ редактировать ]Прогнозирующая база данных основана на статистических выводах. Один конкретный подход к такому выводу известен как прогнозирующий вывод, но прогноз может быть выполнен в рамках любого из нескольких подходов к статистическому выводу. Действительно, одно из описаний биостатистики заключается в том, что она обеспечивает средства передачи знаний об образце генетической популяции всей популяции ( геномика ) и другим связанным генам или геномам, что, как и прогнозирование во времени, не обязательно. [15] Когда информация передается во времени, часто в определенные моменты времени, этот процесс называется прогнозированием. К трем основным примерам баз данных, которые можно отнести к этой категории, относятся: База данных генома мыши (MGD), База данных генома крысы (RGD), OMIM и инструмент SIFT от Ensembl. [1]
База данных генома мыши (MGD)
[ редактировать ]База данных генома мыши (MGD) — это ресурс международного сообщества, содержащий интегрированные генетические, геномные и биологические данные о лабораторных мышах. MGD предоставляет полную аннотацию фенотипов и ассоциаций заболеваний человека для мышиных моделей (генотипов) с использованием терминов из онтологии фенотипов млекопитающих и названий болезней из OMIM. [16]
База данных генома крыс (RGD)
[ редактировать ]| Содержание | |
|---|---|
| Описание | База данных генома крысы |
| Организмы | Rattus norvegicus (крыса) |
| Контакт | |
| Исследовательский центр | Медицинский колледж Висконсина |
| Лаборатория | Центр молекулярной и генетики человека |
| Авторы | Мэри Э. Симояма, доктор философии; Говард Дж. Джейкоб, доктор философии |
| Первичное цитирование | ПМИД 25355511 |
| Доступ | |
| Веб-сайт | СРГ |
| URL-адрес загрузки | Публикация данных РГД |
База данных генома крыс (RGD) возникла как совместная работа ведущих исследовательских институтов, занимающихся генетическими и геномными исследованиями крыс. Крыса по-прежнему широко используется исследователями в качестве модельного организма для изучения биологии и патофизиологии заболеваний. В последние несколько лет наблюдается быстрый рост генетических и геномных данных о крысах. [17] Этот взрывной рост информации подчеркнул необходимость в централизованной базе данных для эффективного и действенного сбора, управления и распространения крысиной точки зрения на эти данные среди исследователей по всему миру. База данных генома крыс была создана в качестве хранилища генетических и геномных данных крыс, а также картографической, штаммовой и физиологической информации. Он также облегчает исследовательскую работу следователей, предоставляя инструменты для поиска, анализа и прогнозирования этих данных. [17]
Данные RGD, полезные для исследователей, исследующих гены болезней, включают аннотации болезней для генов крыс, мышей и человека. Аннотации составляются вручную из литературы или загружаются через автоматизированные конвейеры из других баз данных, связанных с заболеваниями. Загруженные аннотации сопоставляются с тем же словарем заболеваний, который используется для ручных аннотаций, чтобы обеспечить согласованность всего набора данных. RGD также хранит данные количественного фенотипа, связанные с заболеванием, у крыс (PhenoMiner). [18]
Онлайн-менделевское наследование у человека ( OMIM )
[ редактировать ]| Содержание | |
|---|---|
| Описание | OMIM — это сборник человеческих генов и генетических фенотипов. |
| Организмы | Человек ( H. Sapiens ) |
| Контакт | |
| Исследовательский центр | NCBI |
| Первичное цитирование | ПМИД 25398906 |
| Доступ | |
| Веб-сайт | www |
При поддержке NCBI онлайн-менделевское наследование у человека (OMIM) представляет собой базу данных, в которой каталогизируются все известные заболевания с генетическим компонентом, прогнозируется их связь с соответствующими генами в геноме человека, а также предоставляются ссылки для дальнейших исследований и инструменты для геномного анализа. каталогизированного гена. [19] OMIM — это всеобъемлющий, авторитетный сборник человеческих генов и генетических фенотипов, который находится в свободном доступе и обновляется ежедневно. База данных использовалась как ресурс для прогнозирования соответствующей информации о наследственных состояниях. [19]

Инструмент ансамбля SIFT
[ редактировать ] | |
| Содержание | |
|---|---|
| Описание | Вместе |
| Контакт | |
| Исследовательский центр | |
| Первичное цитирование | Хаббард и др. (2002) [20] |
| Доступ | |
| Веб-сайт | www |
Это один из крупнейших ресурсов, доступных для всех геномных и генетических исследований. Он предоставляет централизованный ресурс для генетиков, молекулярных биологов и других исследователей, изучающих геномы наших собственных видов и других позвоночных, а также моделирующих болезнетворные организмы. Ensembl — один из нескольких известных геномных браузеров для поиска информации о геномных заболеваниях. Ensembl импортирует данные о вариантах из множества различных источников, Ensembl прогнозирует эффекты вариантов. [21] Для каждой вариации, картированной с эталонным геномом, идентифицируется каждый транскрипт Ensembl, который перекрывает вариацию. Затем он использует подход, основанный на правилах, для прогнозирования влияния, которое каждая аллель вариации может оказать на транскрипт. Набор терминов последствий, определенный Онтологией последовательностей (SO), в настоящее время может быть присвоен каждой комбинации аллели и транскрипта. Каждая аллель каждой вариации может иметь разный эффект в разных транскриптах. Для прогнозирования человеческих мутаций в базе данных Ensembl используется множество различных инструментов, одним из наиболее широко используемых является SIFT, который предсказывает, может ли аминокислотная замена повлиять на функцию белка, на основе гомологии последовательностей и физико-химического сходства между альтернативные аминокислоты. Данные, предоставленные для каждой аминокислотной замены, представляют собой оценку и качественный прогноз (либо «переносимый», либо «вредный»). Оценка представляет собой нормализованную вероятность того, что изменение аминокислоты допустимо, поэтому значения, близкие к 0, с большей вероятностью будут вредными. Качественный прогноз выводится на основе этой оценки, так что замены с оценкой <0,05 называются «вредными», а все остальные — «терпимыми». SIFT может применяться к встречающимся в природе несинонимичным полиморфизмам и миссенс-мутациям, вызванным лабораторными исследованиями, что приведет к построению взаимосвязей в характеристиках фенотипа. протеомика и геномика. [21]
Литературные базы данных
[ редактировать ]В базах данных такого типа собраны книги, статьи, рецензии на книги, диссертации и аннотации о базах данных по генным заболеваниям. Некоторые из следующих примеров являются примерами этого типа: GAD, LGHDN и BeFree Data.
База данных генетических ассоциаций (GAD)
[ редактировать ]База данных генетических ассоциаций представляет собой архив исследований человеческих генетических ассоциаций сложных заболеваний. GAD в первую очередь сосредоточен на архивировании информации об распространенных сложных заболеваниях человека, а не о редких менделевских расстройствах, обнаруженных в OMIM. Он включает тщательно подобранные сводные данные, извлеченные из опубликованных статей в рецензируемых журналах по исследованиям генов-кандидатов и широкогеномных ассоциаций ( GWAS ). [22] GAD был заморожен 01.09.2014, но все еще доступен для загрузки. [23]
Сеть генных заболеваний человека, основанная на литературных данных (LHGDN)
[ редактировать ]Сеть генов человека, основанная на литературе (LHGDN), представляет собой базу данных, основанную на интеллектуальном анализе текста и ориентированную на извлечение и классификацию ассоциаций генов и заболеваний в отношении нескольких биомолекулярных состояний. Он использует алгоритм, основанный на машинном обучении, для извлечения семантических связей ген-болезнь из интересующего текстового источника. Это часть Linked Life Data LMU в Мюнхене, Германия. [1]
Данные BeFree
[ редактировать ]Извлекает ассоциации генов и заболеваний из реферата MEDLINE с использованием системы BeFree. BeFree состоит из биомедицинского модуля распознавания именованных объектов (BioNER) для обнаружения заболеваний и генов, а также модуля извлечения связей на основе морфосинтаксической информации. [24]
Интегративные базы данных
[ редактировать ]Базы данных такого типа включают менделевские, сложные и экологические заболевания в интегрированный архив ассоциаций генов и болезней и показывают, что концепция модульности применима ко всем из них. Они обеспечивают функциональный анализ болезней в случае важных новых биологических открытий, которые могут быть неактуальны. обнаружены при рассмотрении каждой из ассоциаций ген-болезнь независимо. Таким образом, они представляют собой подходящую основу для изучения того, как генетические факторы и факторы окружающей среды, такие как лекарства, способствуют развитию заболеваний. Лучшим примером базы данных такого типа является DisGeNET. [8] [25]
База данных ассоциаций генных заболеваний DisGeNET
[ редактировать ]| Содержание | |
|---|---|
| Описание | Интегрирует ассоциации генов человека и болезней. |
| Типы данных захвачен | База данных ассоциаций |
| Организмы | Человек ( H. Sapiens ) |
| Контакт | |
| Исследовательский центр | Программа исследований по биомедицинской информатике (ГРИБ) ИМИМ-УПФ |
| Лаборатория | Группа интегративной биомедицинской информатики |
| Авторы | Ферран Санс и Лаура И. Ферлонг (Пинеро и др., 2015 г.) |
| Первичное цитирование | PMID 25877637 |
| Доступ | |
| Веб-сайт | www |
| Разнообразный | |
| Выпуск данных частота | ежегодный |
| Версия | 3 |
DisGeNET — это комплексная база данных ассоциаций генов и заболеваний, которая объединяет ассоциации из нескольких источников и охватывает различные биомедицинские аспекты заболеваний. [25] В частности, он сосредоточен на современных знаниях о генетических заболеваниях человека, включая менделевские, сложные и экологические заболевания. Чтобы оценить концепцию модульности заболеваний человека, эта база данных выполняет систематическое исследование новых свойств сетей генов человека с помощью топологии сети и анализа функциональных аннотаций. [1] Результаты указывают на широко распространенное генетическое происхождение болезней человека и показывают, что для большинства болезней, включая менделевские, сложные и экологические заболевания, существуют функциональные модули. Более того, обнаружено, что основной набор биологических путей связан с большинством заболеваний человека. Полученные аналогичные результаты при изучении кластеров заболеваний, данные этой базы данных позволяют предположить, что родственные заболевания могут возникнуть из-за дисфункции общих биологических процессов в клетке. Сетевой анализ этой интегрированной базы данных показывает, что интеграция данных необходима для получения комплексного представления о генетическом ландшафте заболеваний человека и что генетическое происхождение сложных заболеваний встречается гораздо чаще, чем ожидалось. [1]

Описание каждого типа ассоциации в этой онтологии следующее: #Терапевтическая ассоциация: ген/белок играет терапевтическую роль в облегчении заболевания. #Ассоциация биомаркеров: Ген/белок либо играет роль в этиологии заболевания (например, участвует в молекулярном механизме, приводящем к заболеванию), либо является биомаркером заболевания. #Ассоциация генетических вариаций: используется, когда вариация последовательности (мутация, SNP) связана с фенотипом заболевания, но до сих пор нет доказательств того, что вариация вызывает заболевание. В некоторых случаях наличие вариантов увеличивает восприимчивость к заболеванию. Обычно предоставляются идентификаторы SNP NCBI. #Ассоциация измененной экспрессии: Изменения в функции белка посредством измененной экспрессии гена связаны с фенотипом заболевания. #Ассоциация посттрансляционных модификаций: Изменения в функции белка посредством посттрансляционных модификаций (метилирование или фосфорилирование белка) связаны с фенотипом заболевания. [1]
Некоторые варианты использования
[ редактировать ]Некоторые из наиболее интересных случаев использования баз данных генов и заболеваний можно найти в следующих статьях: [1] [8]
- Сантьяго, Хосе А.; Поташкин, Юдит А. (2014). «Сетевой подход к клиническому вмешательству при нейродегенеративных заболеваниях». Тенденции молекулярной медицины . 20 (12): 694–703. doi : 10.1016/j.molmed.2014.10.002 . ПМИД 25455073 .
- Кайкконен, Минна У.; Нисканен, Анри; Романоски, Кейси Э.; Кансанен, Эмилия; Кивеля, Аннукка М.; Лайталайнен, Яркко; Хайнц, Свен; Беннер, Кристофер; Гласс, Кристофер К.; Юля-Херттуала, Сеппо (2014). «Контроль транскрипционных программ VEGF-A путем приостановки и компартментализации генома» . Исследования нуклеиновых кислот . 42 (20): 12570–12584. дои : 10.1093/nar/gku1036 . ПМЦ 4227755 . ПМИД 25352550 .
- Гросдидье, Солен; Феррер, Антони; Фанер, Роза; Пиньеро, Джанет; Рока, Хосеп; Косио, Борха; Агусти, Альвар; Хеа, Хоаким; Санс, Ферран; Ферлонг, Лаура И. (2014). «Сетевой медицинский анализ мультиморбидности ХОБЛ» . Респираторные исследования . 15 (1): 111. дои : 10.1186/s12931-014-0111-4 . ПМК 4177421 . ПМИД 25248857 .
- Криштиану, Франческа; Велтри, Пьеранджело (2014). «Инструмент на основе R для анализа данных микроРНК и корреляции с клиническими онтологиями». Материалы 5-й конференции ACM по биоинформатике, вычислительной биологии и медицинской информатике - BCB '14 . стр. 768–773. дои : 10.1145/2649387.2660847 . ISBN 9781450328944 . S2CID 17123912 .
- Галлахер, Сюзанна Реник; Домбрауэр, Мика; Голдберг, Дебра С. (2014). «Использование коэффициентов кластеризации двухузлового гиперграфа для анализа сетей генов болезней». Материалы 5-й конференции ACM по биоинформатике, вычислительной биологии и медицинской информатике - BCB '14 . стр. 647–648. дои : 10.1145/2649387.2660817 . ISBN 9781450328944 . S2CID 30593231 .
- Маннил, Дипти; Фогт, Инго; Принц, Жанетт; Кампильос, Моника (2015). «БД гетерогенности систем органов: база данных для визуализации фенотипов на уровне систем органов» . Исследования нуклеиновых кислот . 43 (Проблема с базой данных): D900–D906. дои : 10.1093/nar/gku948 . ПМК 4384019 . ПМИД 25313158 .
- Фогт, Инго; Принц, Жанетт; Кампильос, Моника (2014). «Молекулярно и клинически родственные лекарства и заболевания обогащены фенотипически сходными парами лекарство-болезнь» . Геномная медицина . 6 (7): 52. дои : 10.1186/s13073-014-0052-z . ПМК 4165361 . ПМИД 25276232 .
- Сантьяго, Хосе А.; Поташкин, Юдит А. (2014). «Системные подходы к расшифровке молекулярных связей болезни Паркинсона и диабета». Нейробиология болезней . 72 : 84–91. дои : 10.1016/j.nbd.2014.03.019 . ПМИД 24718034 . S2CID 41944859 .
- Ли, Ин Хи; Ли, Кёнджун; Хсинг, Майкл; Чхве, Ёнджун; Пак, Джин-Хо; Ким, Шу Хи; Бон, Джастин М.; Ной, Мэтью Б.; Хван, Кю-Бэк; Грин, Роберт С.; Кохане, Исаак С.; Конг, Сек Вон (2014). «Приоритизация вариантов, генов и путей, связанных с заболеваниями, с помощью интерактивного конвейера полногеномного анализа» . Человеческая мутация . 35 (5): 537–547. дои : 10.1002/humu.22520 . ПМК 4130156 . ПМИД 24478219 .
- Лю, Мин-Си; Чен, Син; Чен, Гэн; Цуй, Цин-Хуа; Ян, Гуй-Ин (2014). «Вычислительная система для определения длинных некодирующих РНК, связанных с заболеваниями человека» . ПЛОС ОДИН . 9 (1): e84408. Бибкод : 2014PLoSO...984408L . дои : 10.1371/journal.pone.0084408 . ПМЦ 3879311 . ПМИД 24392133 .
- Чжао, Илей; Ван, Чен; Ву, Цзяньвэй; Ван, Ян; Чжу, Вэньлян; Чжан, Юн; Ду, Жимин (2013). «Холин защищает от сердечной гипертрофии, вызванной повышенной постнагрузкой» . Международный журнал биологических наук . 9 (3): 295–302. дои : 10.7150/ijbs.5976 . ПМК 3596715 . ПМИД 23493786 .
- Кочор, Кристофер А.; Ли, Ева К.; Торрес, Ребекка А.; Бойд, Эми; Вега, Дж. Дэвид; Уппал, Каран; Юань, Фань; Филдс, Эрл Дж.; Самарел, Аллен М.; Льюис, Уильям (2013). «Обнаружение дифференциально метилированных промоторов генов в поврежденном и исправном миокарде левого желудочка человека с использованием компьютерного анализа» . Физиологическая геномика . 45 (14): 597–605. doi : 10.1152/физиологгеномика.00013.2013 . ПМК 3727018 . ПМИД 23695888 .
- Гу, Ин; Лю, Гуан-Хуэй; Плонгтонгкум, Нонглюк; Беннер, Кристофер; Йи, Фей; Цюй, Цзин; Сузуки, Кейитиро; Ян, Цзипин; Чжан, Вэйци; Ли, Мо; Монтсеррат, Нурия; Креспо, Исаак; Дель Соль, Антонио; Эстебан, Консепсьон Родригес; Чжан, Кун; Изписуа Бельмонте, Хуан Карлос (2014). «Глобальное метилирование ДНК и транскрипционный анализ кардиомиоцитов человека, происходящих из ЭСК» . Белок и клетка . 5 (1): 59–68. дои : 10.1007/s13238-013-0016-x . ПМЦ 3938846 . ПМИД 24474197 .
- Галхардо, Мафальда; Синкконен, Лассе; Бернингер, Филипп; Лин, Джейк; Заутер, Томас; Хейняниеми, Мерья (2014). «Комплексный анализ регуляции метаболизма на уровне транскриптов выявляет связанные с заболеванием узлы метаболической сети человека» . Исследования нуклеиновых кислот . 42 (3): 1474–1496. дои : 10.1093/нар/gkt989 . ПМЦ 3919568 . ПМИД 24198249 .
- Тьери, Паоло; Терманини, Альберто; Беллависта, Елена; Сальвиоли, Стефано; Капри, Мириам; Франчески, Клаудио (2012). «Составление карты интерактома путей NF-κB» . ПЛОС ОДИН . 7 (3): e32678. Бибкод : 2012PLoSO...732678T . дои : 10.1371/journal.pone.0032678 . ПМЦ 3293857 . ПМИД 22403694 .
Замечания о будущем баз данных генных заболеваний
[ редактировать ]
Завершение генома человека изменило способ поиска генов болезней. В прошлом подход заключался в сосредоточении внимания на одном или нескольких генах одновременно. Теперь такие проекты, как DisGeNET, служат примером усилий по систематическому анализу всех изменений генов, связанных с одним или несколькими заболеваниями. [26] Следующим шагом является получение полной картины механистических аспектов болезней и разработки лекарств против них. Для этого потребуется сочетание двух подходов: систематического поиска и углубленного изучения каждого гена.Будущее этой области будет определяться новыми методами интеграции больших объемов данных из разных источников и включения функциональной информации в анализ крупномасштабных данных, полученных в результате биоинформатических исследований. [1]
Биоинформатика — это одновременно термин, обозначающий совокупность исследований биологических генных заболеваний, в которых компьютерное программирование является частью их методологии, а также ссылка на конкретные конвейеры анализа, которые неоднократно используются, особенно в области генетики и геномики. [1] Обычное использование биоинформатики включает идентификацию генов-кандидатов и нуклеотидов, SNP . Часто такая идентификация проводится с целью лучшего понимания генетической основы заболевания, уникальных адаптаций, желаемых свойств или различий между популяциями. Менее формальным способом биоинформатика также пытается понять принципы организации последовательностей нуклеиновых кислот и белков. [1]
Реакция биоинформатики на новые экспериментальные методы открывает новую перспективу в анализе экспериментальных данных, о чем свидетельствуют достижения в анализе информации из баз данных генных заболеваний и других технологий. Ожидается, что эта тенденция продолжится благодаря новым подходам в ответ на новые методы, такие как технологии секвенирования следующего поколения. Например, наличие большого количества отдельных человеческих геномов будет способствовать развитию компьютерного анализа редких вариантов, включая статистический анализ их связи с образом жизни, взаимодействием лекарств и другими факторами. [1] Биомедицинские исследования также будут зависеть от нашей способности эффективно анализировать большой объем существующих и постоянно генерируемых биомедицинских данных. Методы анализа текста, в частности, в сочетании с другими молекулярными данными, могут предоставить информацию о мутациях и взаимодействиях генов и станут иметь решающее значение для того, чтобы опережать экспоненциальный рост данных, генерируемых в биомедицинских исследованиях. Еще одной областью, которая извлекает выгоду из достижений в области разработки и интеграции молекулярного, клинического анализа и анализа лекарств, является фармакогеномика. Исследования in silico взаимосвязей между человеческими вариациями и их влиянием на болезни станут ключом к развитию персонализированной медицины. [8] Таким образом, базы данных генных заболеваний уже изменили поиск генов болезней и потенциально могут стать важнейшим компонентом других областей медицинских исследований. [1]
См. также
[ редактировать ]- Информатика биоразнообразия
- Биоинформатические компании
- Биомедицина
- Вычислительная биология
- Компьютерное биомоделирование
- Вычислительная геномика
- Идентификация гена заболевания
- Европейский институт биоинформатики
- Функциональная геномика
- Информатика здравоохранения
- Проект «Геном человека»
- Интегративная биоинформатика
- Международное общество вычислительной биологии
- Прыгающая библиотека
- Список журналов по биоинформатике
- Список биологических баз данных
- Список программного обеспечения для биоинформатики с открытым исходным кодом
- Патология
- Филогенетика
- Структурная биоинформатика
Ссылки
[ редактировать ]- ^ Перейти обратно: а б с д и ж г час я дж к л м н А. Бауэр-Мерен, «Анализ сети генов и заболеваний выявляет функциональные модули при менделевских , комплексных и экологических заболеваниях », PLOS One, стр. 1–3, 2011 г.
- ^ Перейти обратно: а б Ботштейн, Д. (2003). «Обнаружение генотипов, лежащих в основе фенотипов человека: прошлые успехи в лечении менделевской болезни, будущие подходы к сложным заболеваниям». Природная генетика . 33 (1): 228–237. дои : 10.1038/ng1090 . ПМИД 12610532 . S2CID 10599219 .
- ^ Рен Дж.Д., Бейтман А. (2008). «Базы данных, могилы данных и пыль на ветру» . Биоинформатика . 24 (19): 2127–8. doi : 10.1093/биоинформатика/btn464 . ПМИД 18819940 .
- ^ «Стратегический план Американской ассоциации медицинской информатики» . Американская ассоциация медицинской информатики. Архивировано из оригинала 26 октября 2009 года.
- ^ Оти, М (2007). «Модульная природа генетических заболеваний» . Клиническая генетика . 71 (1): 1–11. дои : 10.1111/j.1399-0004.2006.00708.x . ПМИД 17204041 . S2CID 24615025 .
- ^ Дэвис, А.; Кинг, Б. (2011). «База данных сравнительной токсикогеномики: обновление 2011 г.» . Нуклеиновые кислоты Рез . 39 (1): 1067–1072. дои : 10.1093/нар/gkq813 . ПМК 3013756 . ПМИД 20864448 .
- ^ Дэвис, А.; Вигерс, Т. (2013). «Интеллектуальный анализ текста эффективно оценивает и ранжирует литературу по улучшению лечения химических генных заболеваний в базе данных сравнительной токсикогеномики» . ПЛОС ОДИН . 8 (4): 1–29. Бибкод : 2013PLoSO...858201D . дои : 10.1371/journal.pone.0058201 . ПМК 3629079 . ПМИД 23613709 .
- ^ Перейти обратно: а б с д Бауэр-Мерен, А.; Рауча, М. (2010). «DisGeNET: плагин Cytoscape для визуализации, интеграции, поиска и анализа сетей генов и заболеваний» . Биоинформатика . 26 (22): 2924–2926. doi : 10.1093/биоинформатика/btq538 . ПМИД 20861032 .
- ^ Фогт, И. (2014). «Систематический анализ свойств генов, влияющих на фенотипы систем органов при нарушениях у млекопитающих» . Биоинформатика . 30 (21): 3093–3100. doi : 10.1093/биоинформатика/btu487 . ПМК 4609011 . ПМИД 25061072 .
- ^ Перейти обратно: а б Бунеман, П. (2008). «Кураторские базы данных». Библиометрия . 978 (1): 152–162.
- ^ Перейти обратно: а б Мерфи, К.; Дэвис, А. (2009). «База данных сравнительной токсикогеномики: база знаний и инструмент обнаружения сетей химических веществ, генов и заболеваний» . Биоинформатика . 37 (1): 786–792. дои : 10.1093/нар/gkn580 . ПМЦ 2686584 . ПМИД 18782832 .
- ^ Юнипрот, Консорциум (2008). «Универсальный ресурс белка (UniProt)» . Исследования нуклеиновых кислот . 36 (1): 190–195. дои : 10.1093/nar/gkm895 . ПМК 1669721 . ПМИД 18045787 .
- ^ Юнипрот, К. (2010). «Текущие и будущие разработки Universal Protein Resource» . Исследования нуклеиновых кислот . 39 (Проблема с базой данных): D214–D219. дои : 10.1093/нар/gkq1020 . ПМК 3013648 . ПМИД 21051339 .
- ^ К. Браун, «Онлайн-база данных по прогнозируемым человеческим взаимодействиям», Биоинформатика , том. 21, нет. 9, стр. 2076–2082, 2005.
- ^ С. Хантер и П. Джонс, «ИнтерПро в 2011 году: новые разработки в базе данных прогнозирования семейств и доменов», Nucleic Acids Research , vol. 10, нет. 1, стр. 12–22, 2011 г.
- ^ К. Балт и Дж. Эппиг, «База данных генома мыши (MGD): биология мыши и модельные системы», Nucleic Acids Research , vol. 36, нет. 1, стр. 724-728, 2007 г.
- ^ Перейти обратно: а б М. Дуинелл, Э. Уорти и С.М., «База данных генома крысы, 2009 г.: вариации, онтологии и пути», Nucleic Acids Research , vol. 37, нет. 1, стр. 744-749, 2009 г.
- ^ Симояма М., Де Понс Дж., Хейман Г.Т. и др. (2015). «База данных генома крыс 2015: геномные, фенотипические и экологические вариации и болезни» . Исследования нуклеиновых кислот . 43 (Проблема с базой данных): D743–50. дои : 10.1093/nar/gku1026 . ПМЦ 4383884 . ПМИД 25355511 .
- ^ Перейти обратно: а б А. Хомош, «Онлайн-менделевское наследование у человека (OMIM), база знаний о человеческих генах и генетических нарушениях», Nucleic Acids Research , vol. 33, нет. 1, стр. 514-517, 2005 г.
- ^ Хаббард Т. и др. (январь 2002 г.). «Проект базы данных генома Ensembl» . Исследования нуклеиновых кислот . 30 (1): 38–41. дои : 10.1093/нар/30.1.38 . ПМК 99161 . ПМИД 11752248 .
- ^ Перейти обратно: а б П. Фличек и М. Ридван, «Ensembl 2012», Nucleic Acids Research , vol. 40, нет. 1, стр. 84-90, 2012 г.
- ^ Беккер, К.; Барнс, К. (2004). «База данных генетических ассоциаций» . Природная генетика . 36 (5): 431–432. дои : 10.1038/ng0504-431 . ПМИД 15118671 .
- ^ «Архивная копия» . Архивировано из оригинала 24 февраля 2021 года . Проверено 18 ноября 2016 г.
{{cite web}}: CS1 maint: архивная копия в заголовке ( ссылка ) - ^ Браво, А; и др. (2014). «Извлечение связей между генами и болезнями из текста и крупномасштабного анализа данных: значение для трансляционных исследований» . БМК Биоинформатика . 16 (1): 55. дои : 10.1186/s12859-015-0472-9 . ПМК 4466840 . ПМИД 25886734 .
- ^ Перейти обратно: а б Пиньеро; и др. (2015). «DisGeNET: платформа открытий для динамического исследования болезней человека и их генов» . База данных . 2015 : bav028. дои : 10.1093/база данных/bav028 . ПМК 4397996 . ПМИД 25877637 .
- ^ Оти, М (2006). «Прогнозирование генов болезней с использованием белок-белковых взаимодействий» . Дж. Мед. Жене . 43 (8): 691–698. дои : 10.1136/jmg.2006.041376 . ПМЦ 2564594 . ПМИД 16611749 .