Количественная генетика
| Часть серии о |
| Генетика |
|---|
 |
|
|
Эту статью может потребовать очистки Википедии , чтобы она соответствовала стандартам качества . Конкретная проблема заключается в следующем: вложенные дроби, вероятно, лучше писать с помощью <math>...</math> разметка. ( февраль 2024 г. ) |
Количественная генетика — это изучение количественных признаков , которые представляют собой фенотипы , которые постоянно изменяются (например, рост или масса), в отличие от фенотипов и генных продуктов, которые можно идентифицировать дискретно , таких как цвет глаз или наличие определенного биохимического вещества.
Обе эти ветви генетики используют частоты различных аллелей гена для анализа закономерностей наследования между в размножающихся популяциях (гамодемах) и объединяют их с концепциями простого менделевского наследования поколениями и потомками. В то время как популяционная генетика может сосредоточиться на конкретных генах и продуктах их последующего метаболизма, количественная генетика больше фокусируется на внешних фенотипах и дает лишь обобщение лежащей в их основе генетики.
Из-за непрерывного распределения фенотипических значений количественная генетика должна использовать множество других статистических методов (таких как размер эффекта , среднее значение и дисперсия ), чтобы связать фенотипы (атрибуты) с генотипами. Некоторые фенотипы можно анализировать либо как дискретные категории, либо как непрерывные фенотипы, в зависимости от определения пороговых значений или метрики, используемой для их количественной оценки. [ 1 ] : 27–69 Сам Мендель должен был обсудить этот вопрос в своей знаменитой статье: [ 2 ] особенно в отношении атрибута его гороха высокий/карликовый , который на самом деле был получен путем добавления точки отсечения к «длине стебля». [ 3 ] [ 4 ] Анализ локусов количественных признаков или QTL, [ 5 ] [ 6 ] [ 7 ] является более поздним дополнением к количественной генетике, более непосредственно связывающим ее с молекулярной генетикой .
Генные эффекты
[ редактировать ]У диплоидных организмов средняя генотипическая «ценность» (значение локуса) может определяться «эффектом» аллеля вместе с эффектом доминирования , а также тем, как гены взаимодействуют с генами в других локусах ( эпистаз ). Основатель количественной генетики сэр Рональд Фишер многое из этого осознал, когда предложил первую математику в этой области генетики. [ 8 ]

Будучи статистиком, он определил эффекты генов как отклонения от центрального значения, что позволило использовать такие статистические понятия, как среднее значение и дисперсия, которые используют эту идею. [ 9 ] Центральным значением, которое он выбрал для гена, была середина между двумя противоположными гомозиготами в одном локусе. Отклонение оттуда к «большому» гомозиготному генотипу можно назвать « +а »; и, следовательно, это « -а » от той же средней точки до «меньшего» гомозиготного генотипа. Это упомянутый выше эффект «аллеля». Отклонение гетерозигот от одной и той же средней точки можно назвать « d », это и есть упомянутый выше эффект «доминирования». [ 10 ] Схема отражает идею. Однако на самом деле мы измеряем фенотипы, и на рисунке также показано, как наблюдаемые фенотипы связаны с эффектами генов. Формальные определения этих эффектов признают этот фенотипический фокус. [ 11 ] [ 12 ] Статистически эпистаз рассматривается как взаимодействие (т. е. несоответствие), [ 13 ] но эпигенетика предполагает, что может потребоваться новый подход.
Если 0 < d < a , доминирование считается частичным или неполным , тогда как d = a указывает на полное или классическое доминирование. Раньше d > a было известно как «чрезмерное доминирование». [ 14 ]
Атрибут гороха Менделя «длина стебля» дает нам хороший пример. [ 3 ] Мендель заявил, что длина стебля высоких чистокровных родителей варьировалась от 6–7 футов (183–213 см), что дает средний рост 198 см (= P1). Короткие родители имели длину стебля от 0,75 до 1,25 фута (23–46 см) с округлой медианой 34 см (= P2). Их гибрид имел длину от 6–7,5 футов (183–229 см) со средней длиной 206 см (= F1). Среднее значение P1 и P2 составляет 116 см, что является фенотипическим значением средней точки гомозигот (mp). Аллельный эффект ( а ) составляет [P1-mp] = 82 см = -[P2-mp]. Эффект доминирования ( d ) составляет [F1-mp] = 90 см. [ 15 ] Этот исторический пример ясно иллюстрирует, как связаны значения фенотипа и эффекты генов.
Частоты аллелей и генотипов
[ редактировать ]Для получения средних значений, дисперсий и других статистических данных как количества , так и их появление необходимы . Эффекты генов (выше) обеспечивают основу для количественных показателей , а частоты контрастирующих аллелей в пуле гамет оплодотворения предоставляют информацию о явлениях .
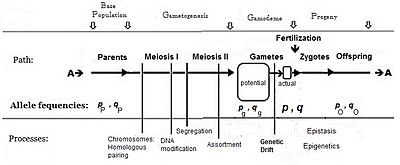
Обычно частота аллеля, вызывающая «большее» фенотипа (включая доминирование), обозначается символом p , а частота контрастного аллеля — q . Первоначальное предположение, сделанное при создании алгебры, заключалось в том, что родительская популяция была бесконечной и имела случайное спаривание, что было сделано просто для облегчения вывода. Последующие математические разработки также показали, что распределение частот внутри эффективного пула гамет было однородным: не было локальных возмущений при изменении p и q . Глядя на диаграммный анализ полового размножения, это то же самое, что заявить, что p P = p g = p ; и аналогично для q . [ 14 ] Эта система спаривания, основанная на этих предположениях, стала известна как «панмиксия».
Панмиксия редко встречается в природе. [ 16 ] : 152–180 [ 17 ] поскольку распространение гамет может быть ограничено, например, ограничениями на распространение, поведением или случайным отбором проб (эти локальные возмущения, упомянутые выше). Хорошо известно, что в природе происходит огромная потеря гамет, поэтому на диаграмме потенциальный пул гамет изображен отдельно от реального пула гамет. Только последний устанавливает определённые частоты для зигот: это и есть истинная «гамодема» («гамо» относится к гаметам, а «дема» происходит от греческого слова «популяция»). Но, согласно предположениям Фишера, гамодема может быть эффективно расширена обратно до потенциального пула гамет и даже обратно до родительской базовой популяции («исходной» популяции). Случайная выборка, возникающая, когда небольшие «действительные» пулы гамет отбираются из большого «потенциального» пула гамет, известна как генетический дрейф и рассматривается далее.
Хотя панмиксия, возможно, не широко распространена, вероятность ее возникновения все же имеет место, хотя она может быть лишь эфемерной из-за этих локальных нарушений. Было показано, например, что F2, полученный в результате случайного оплодотворения особей F1 ( аллогамный F2) после гибридизации, является источником новой потенциально панмиктической популяции. [ 18 ] [ 19 ] Также было показано, что если бы панмиктическое случайное оплодотворение происходило постоянно, оно сохраняло бы одни и те же частоты аллелей и генотипов в каждом последующем панмиктическом половом поколении — это и есть равновесие Харди Вайнберга . [ 13 ] : 34–39 [ 20 ] [ 21 ] [ 22 ] [ 23 ] Однако, как только генетический дрейф инициируется локальной случайной выборкой гамет, равновесие прекращается.
Случайное оплодотворение
[ редактировать ]Считается, что мужские и женские гаметы в реальном оплодотворяющем пуле обычно имеют одинаковые частоты соответствующих аллелей. (Учитываются исключения.) Это означает, что когда p мужских гамет, несущих аллель А , случайным образом оплодотворяют p женских гамет, несущих тот же аллель, полученная зигота имеет генотип АА , и при случайном оплодотворении сочетание происходит с частотой p x р (= р 2 ). Аналогично зигота аа возникает с частотой q 2 . Гетерозиготы ( Аа ) могут возникнуть двумя способами: когда p самец ( аллель А ) случайным образом оплодотворяет q женские ( аллель а ) гаметы, и наоборот . Таким образом, результирующая частота гетерозиготных зигот равна 2pq . [ 13 ] : 32 Обратите внимание, что такая популяция никогда не бывает гетерозиготной более чем наполовину, причем этот максимум наблюдается при p = q = 0,5.
Таким образом, при случайном оплодотворении частоты зигот (генотипов) представляют собой квадратичное расширение гаметических (аллельных) частот: . (Знак «=1» означает, что частоты указаны в дробях, а не в процентах; и что в предлагаемой структуре нет пропусков.)

Обратите внимание, что «случайное оплодотворение» и «панмиксия» не являются синонимами.
Исследовательский крест Менделя – контраст
[ редактировать ]Эксперименты Менделя с горошком были построены путем установления чистокровных родителей с «противоположными» фенотипами по каждому признаку. [ 3 ] Это означало, что каждый противоположный родитель был гомозиготен только по соответствующему аллелю. В нашем примере «высокий против карлика» высокий родитель будет иметь генотип TT с p = 1 (и q = 0 ); в то время как родитель-карлик будет иметь генотип tt с q = 1 (и p = 0 ). После контролируемого скрещивания их гибридом является Tt с p = q = 1/2 . Однако частота этой гетерозиготы = 1 , поскольку это F1 искусственного скрещивания: она возникла не в результате случайного оплодотворения. [ 24 ] Поколение F2 было получено путем естественного самоопыления F1 (с контролем заражения насекомыми), в результате чего p = q = 1 / 2 поддерживается. Такой F2 называется «автогамным». Однако частоты генотипов (0,25 TT , 0,5 Tt , 0,25 tt ) возникли в результате системы спаривания, сильно отличающейся от случайного оплодотворения, и поэтому использования квадратичного расширения удалось избежать. Полученные числовые значения были такими же, как и для случайного оплодотворения, только потому, что это особый случай первоначального скрещивания гомозиготных противоположных родителей. [ 25 ] Мы можем заметить, что из-за доминирования T- [частота (0,25 + 0,5)] над tt [частота 0,25] соотношение 3:1 все еще получается.
Скрещивание, подобное скрещиванию Менделя, при котором чистокровные (в основном гомозиготные) противоположные родители скрещиваются контролируемым образом для получения F1, является особым случаем гибридной структуры. F1 часто считают «полностью гетерозиготным» по рассматриваемому гену. Однако это чрезмерное упрощение и не применимо в целом — например, когда отдельные родители не гомозиготны или когда популяции подвергаются интергибридизации с образованием гибридных стаев . [ 24 ] Общие свойства внутривидовых гибридов (F1) и F2 (как «автогамных», так и «аллогамных») рассматриваются в следующем разделе.
Самооплодотворение – альтернатива
[ редактировать ]Заметив, что горох естественно самоопыляется, мы не можем продолжать использовать его как пример для иллюстрации свойств случайного оплодотворения. Самоопыление («самопыление») — основная альтернатива случайному оплодотворению, особенно у растений. Большинство зерновых культур на Земле являются самоопыляемыми естественным путем (например, рис, пшеница, ячмень), а также бобовые. Учитывая миллионы особей каждого из них на Земле в любое время, очевидно, что самооплодотворение по меньшей мере столь же значимо, как и случайное оплодотворение. Самооплодотворение — наиболее интенсивная форма инбридинга , возникающая всякий раз, когда существует ограничение независимости генетического происхождения гамет. Такое снижение независимости возникает, если родители уже связаны между собой и/или из-за генетического дрейфа или других пространственных ограничений на распространение гамет. Анализ пути показывает, что это одно и то же. [ 26 ] [ 27 ] Исходя из этого, коэффициент инбридинга (часто обозначаемый как F или f ) количественно определяет эффект инбридинга по любой причине. Существует несколько формальных определений f , некоторые из них рассматриваются в последующих разделах. А пока заметим, что для многолетнего самооплодотворяющегося вида f = 1 . Однако естественные самооплодотворенные популяции представляют собой не отдельные « чистые линии », а смеси таких линий. Это становится особенно очевидным, если рассматривать одновременно более одного гена. Следовательно, частоты аллелей ( p и q ), отличные от 1 или 0, все еще актуальны в этих случаях (обратитесь к сечению Менделя). Однако частоты генотипов принимают другую форму.
В целом частоты генотипов становятся для АА и для Аа и для аа . [ 13 ] : 65
![{\textstyle [p^{2}(1-f)+pf]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f1f42f5a9c30f57d018ee039f24e662ebeafb72)

![{\textstyle [q^{2}(1-f)+qf]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/03c693d0435f960d467b31a0d257d1ac8c647390)
Обратите внимание, что частота гетерозигот снижается пропорционально f . Когда f = 1 , эти три частоты становятся соответственно p , 0 и q. И наоборот, когда f = 0 , они сводятся к квадратичному разложению со случайным оплодотворением, показанному ранее.
Среднее значение численности населения
[ редактировать ]Среднее значение популяции смещает центральную точку отсчета от средней точки гомозиготы ( mp ) к среднему значению популяции, воспроизводимой половым путем. Это важно не только для того, чтобы перенести фокус на мир природы, но и для использования меры центральной тенденции, используемой статистикой/биометрией. В частности, квадрат этого среднего значения является поправочным фактором, который позже используется для получения генотипических отклонений. [ 9 ]

Поочередно для каждого генотипа эффект его аллеля умножается на частоту его генотипа; и продукты накапливаются по всем генотипам в модели. Для достижения краткого результата обычно следует некоторое алгебраическое упрощение.
Среднее значение после случайного оплодотворения
[ редактировать ]Вклад АА что Аа , а аа , . Собрав вместе два термина и суммируя все, мы получаем следующий результат: . Упрощение достигается за счет того, что и, напоминая, что , тем самым сводя правый член к .







Таким образом, краткий результат . [ 14 ] : 110

Это определяет среднее значение популяции как «смещение» от средней точки гомозиготы (напомним, что a и d определяются как отклонения от этой средней точки). На рисунке изображен G для всех значений p для нескольких значений d , включая один случай небольшого чрезмерного доминирования. Обратите внимание, что G часто отрицательна, тем самым подчеркивая, что она сама по себе является отклонением (от mp ).
Наконец, чтобы получить фактическое среднее значение численности населения в «фенотипическом пространстве», к этому смещению добавляется значение средней точки: .

Примером могут служить данные о длине початков кукурузы. [ 28 ] : 103 Предположим на данный момент, что представлен только один ген, a = 5,45 см, d = 0,12 см [фактически «0», на самом деле], mp = 12,05 см. Далее предположив, что p = 0,6 и q = 0,4 в этом примере совокупности, тогда:
G = 5,45 (0,6 – 0,4) + (0,48)0,12 = 1,15 см (округлено); и
Р =1,15+12,05= 13,20 см (округленно).
Среднее значение после длительного самооплодотворения
[ редактировать ]Вклад АА , в то время аа как . [Частоты см. выше.] Объединение этих двух членов a сразу же приводит к очень простому конечному результату:


. Как и прежде, .

Часто «G (f=1) » сокращается до «G 1 ».
Горох Менделя может предоставить нам аллельные эффекты и среднюю точку (см. ранее); а смешанная самоопыляемая популяция с p = 0,6 и q = 0,4 представляет собой пример частоты. Таким образом:
G (f=1) = 82 (0,6-0,04) = 59,6 см (округленно); и
Р (f=1) = 59,6 + 116 = 175,6 см (округленно).
Среднее значение – генерализованное оплодотворение
[ редактировать ]Общая формула включает коэффициент инбридинга f и может быть адаптирована к любой ситуации. Процедура точно такая же, как и раньше, с использованием взвешенных частот генотипов, указанных ранее. После перевода в наши символы и дальнейшей перестановки: [ 13 ] : 77–78
Здесь G 0 представляет собой G , указанный ранее. (Часто, когда речь идет об инбридинге, «G 0 » предпочтительнее «G».)
![{\displaystyle {\begin{aligned}G_{f}&=a(qp)+[2pqd-f(2pqd)]\\&=a(pq)+(1-f)2pqd\\&=G_{0 }-f\ 2pqd\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c9b62dfeae280dc4f4e334a3478d8481ca3b464b)
Предположим, что пример с кукурузой [приведенный ранее] был ограничен холмом (узким прибрежным лугом) и имел частичное инбридинг до степени f = 0,25 , затем, используя третью версию (выше) G f :
Г 0,25 = 1,15 - 0,25 (0,48) 0,12 = 1,136 см (округлено), при Р 0,25 = 13,194 см (округлено).
В этом примере практически нет эффекта от инбридинга, который возникает из-за того, что по этому признаку практически не было доминирования ( d → 0). Анализ всех трех версий G f показывает, что это приведет к тривиальному изменению среднего значения численности населения. Однако там, где доминирование было заметным, происходили значительные изменения.
Генетический дрейф
[ редактировать ]Генетический дрейф был введен при обсуждении вероятности того, что панмиксия широко распространена как естественный образец оплодотворения. [См. раздел «Частоты аллелей и генотипов».] Здесь выборка гамет из потенциальной гамодемы обсуждается более подробно. Выборка включает случайное оплодотворение между парами случайных гамет, каждая из которых может содержать аллель A или a . Таким образом, выборка является биномиальной. [ 13 ] : 382–395 [ 14 ] : 49–63 [ 29 ] : 35 [ 30 ] : 55 Каждый «пакет» выборки включает 2N аллелей и дает N в результате зигот («потомство» или «линию»). В течение репродуктивного периода эта выборка повторяется снова и снова, так что конечным результатом является смесь потомков выборки. Результатом является рассеянное случайное внесение удобрений. Эти события и общий конечный результат рассматриваются здесь на наглядном примере.

«Базовые» частоты аллелей в примере соответствуют частотам потенциальной гамодемы : частота A равна p g = 0,75 , а частота a равна q g = 0,25 . [ Белая метка « 1 » на диаграмме.] Пять примеров реальных гамодем выбираются из этой базы биномиально ( s = количество выборок = 5), и каждый образец обозначается «индексом» k : с k = 1. ... последовательно. (Это «пакеты» выборки, упомянутые в предыдущем абзаце.) Число гамет, участвующих в оплодотворении, варьируется от образца к образцу и обозначается как 2N k [в белой метке « 2 » на диаграмме). Общее количество (Σ) гамет, отобранных в общей сложности, составляет 52 ( белая метка « 3 » на диаграмме). Поскольку каждая выборка имеет свой размер, веса необходимы для получения средних значений (и других статистических данных) при получении общих результатов. Это и обозначены белой меткой « 4 » на диаграмме.


Образец гамодем – генетический дрейф
[ редактировать ]После завершения этих пяти событий биномиальной выборки каждая результирующая фактическая гамодема содержала разные частоты аллелей — ( p k и q k ). [Они обозначены цифрой « 5 » на диаграмме.] Этот результат на самом деле является самим генетическим дрейфом. Обратите внимание, что два образца (k = 1 и 5) имеют те же частоты, что и базовая ( потенциальная ) гамодема. В другом (k = 3) p и q «перевернуты». Выборка (k = 2) представляет собой «крайний» случай: p k = 0,9 и q k = 0,1 ; в то время как оставшийся образец (k = 4) находится в «середине диапазона» частот аллелей. Все эти результаты возникли лишь «случайно», благодаря биномиальной выборке. Однако, возникнув, они закрепляют все последующие свойства потомков.
Поскольку выборка предполагает случайность, интерес представляют вероятности ( ∫ k ) получения каждой из этих выборок. Эти биномиальные вероятности зависят от начальных частот ( p g и q g ) и размера выборки ( 2N k ). Их утомительно получать, [ 13 ] : 382–395 [ 30 ] : 55 но представляют значительный интерес. [См. белую метку « 6 » на диаграмме.] Два образца (k = 1, 5) с частотами аллелей такими же, как и в потенциальной гамодеме , имели более высокие «шансы» возникновения, чем другие образцы. Однако их биномиальные вероятности различались из-за разного размера выборки (2N k ). «Обратный» образец (k = 3) имел очень низкую вероятность возникновения, что, возможно, подтверждает то, что можно было ожидать. Однако «крайняя» гамодема частоты аллелей (k = 2) не была «редкой»; и выборка «среднего диапазона» (k = 4) была редкой. Те же самые вероятности применимы и к потомству от этих оплодотворений.
Здесь некоторое подведение итогов можно начать . Общие частоты аллелей в основной массе потомков представляют собой средневзвешенные значения соответствующих частот отдельных образцов. То есть: и . (Обратите внимание, что k заменяется на • для общего результата — обычная практика.) [ 9 ] Результаты для примера: p • = 0,631 и q • = 0,369 [ черная метка « 5 » на диаграмме]. Эти значения сильно отличаются от начальных ( p g и q g ) [ белая метка « 1 »]. Частоты аллелей в выборке также имеют как дисперсию, так и среднее значение. Это было получено с использованием суммы квадратов (SS). метода [ 31 ] [Смотрите справа от черной метки « 5 » на схеме]. [Дальнейшее обсуждение этой разницы происходит в разделе «Обширный генетический дрейф» ниже.]


Потомственные линии – дисперсия
[ редактировать ]Частоты генотипов пяти выборочных потомков получены путем обычного квадратичного разложения соответствующих частот аллелей ( случайное оплодотворение ). » на диаграмме Результаты приведены на белой метке « 7 для гомозигот и на белой метке « 8 » для гетерозигот. Такая реорганизация готовит почву для мониторинга уровня инбридинга. Это можно сделать либо путем исследования уровня тотальной гомозиготности [( p 2 к + д 2 k ) = ( 1 - 2p k q k )] , или путем изучения уровня гетерозиготности ( 2p k q k ), поскольку они дополняют друг друга. [ 32 ] Обратите внимание, что образцы k = 1, 3, 5 имели одинаковый уровень гетерозиготности, несмотря на то, что один из них был «зеркальным отражением» других в отношении частот аллелей. Случай «крайней» частоты аллелей (k = 2 ) имел наибольшую гомозиготность (наименьшую гетерозиготность) среди всех образцов. Случай «среднего диапазона» (k = 4 ) имел наименьшую гомозиготность (наибольшую гетерозиготность): фактически каждый из них был равен 0,50.
Общий итог можно продолжить получением средневзвешенного значения соответствующих частот генотипов для массы потомства. Таким образом, для АА это , для Аа это и для аа это . Результаты примера даны с черной меткой « 7 » для гомозигот и с черной меткой « 8 » для гетерозигот. Обратите внимание, что среднее значение гетерозиготности составляет 0,3588 , которое в следующем разделе используется для изучения инбридинга, возникшего в результате этого генетического дрейфа.



Следующим объектом интереса является сама дисперсия, которая относится к «распространению» популяционных средств потомства . Они получены как [см. раздел «Среднее значение популяции») для каждого выборочного потомства по очереди, используя примеры эффектов генов, указанные под белой меткой « 9 » на диаграмме. Затем каждый также получается [по белой метке « 10 » на диаграмме]. Обратите внимание, что «лучшая» линия (k = 2) имела самую высокую частоту аллеля для «большего» аллеля ( А ) (она также имела самый высокий уровень гомозиготности). Худшее потомство (k = 3) имело самую высокую частоту «меньшего» аллеля ( a ), что и объясняло его плохие характеристики. Эта «бедная» линия была менее гомозиготной, чем «лучшая» линия; и фактически он имел тот же уровень гомозиготности, что и две вторые лучшие линии (k = 1, 5). Линия потомства, в которой аллели «больше» и «меньше» присутствовали с одинаковой частотой (k = 4), имела среднее значение ниже общего среднего (см. Следующий параграф) и имела самый низкий уровень гомозиготности. Эти результаты показывают тот факт, что аллели, наиболее распространенные в «генном фонде» (также называемом «зародышевой плазмой»), определяют производительность, а не уровень гомозиготности как таковой. Только биномиальная выборка влияет на эту дисперсию.


теперь Общий итог можно подвести, получив и . Пример результата для P • равен 36,94 ( черная метка « 10 » на диаграмме). Позже это используется для количественной оценки общей инбридинговой депрессии на основе выборки гамет. [См. следующий раздел.] Однако вспомните, что некоторые «недепрессивные» средства потомства уже идентифицированы (k = 1, 2, 5). Это загадка инбридинга: хотя в целом может наблюдаться «депрессия», среди выборок гамодем обычно есть превосходящие линии.


Эквивалент пост-расселенной панмиктики – инбридинг.
[ редактировать ]В общий итог были включены средние частоты аллелей в смеси линий потомства ( p * и q * ). Теперь их можно использовать для создания гипотетического панмиктического эквивалента. [ 13 ] : 382–395 [ 14 ] : 49–63 [ 29 ] : 35 Это можно рассматривать как «эталон» для оценки изменений, вызванных отбором проб гамет. В примере такая панмиктика добавляется справа от диаграммы. частота АА Следовательно, равна (p • ) 2 = 0,3979. Это меньше, чем в дисперсной массе (0,4513 по черной метке « 7 »). Аналогично для aa , (q • ) 2 = 0,1303 – опять меньше эквивалента в массе потомков (0,1898). Видно, что генетический дрейф увеличил общий уровень гомозиготности на величину (0,6411 - 0,5342) = 0,1069. В дополнительном подходе вместо этого можно использовать гетерозиготность. Панмиктический эквивалент Аа составляет 2 p • q • = 0,4658, что выше , чем в выборке (0,3588) [ черная метка « 8 »]. Выборка привела к уменьшению гетерозиготности на 0,1070, что незначительно отличается от предыдущей оценки из-за ошибок округления.
Коэффициент инбридинга ( f ) был введен в начале раздела о самооплодотворении. Здесь рассматривается его формальное определение: f — это вероятность того, что две «одинаковые» аллели (то есть A и A или a и a ), которые оплодотворяются вместе, имеют общее наследственное происхождение, или (более формально) f — это вероятность того, что два гомологичных аллеля являются автозиготными. [ 14 ] [ 27 ] Рассмотрим любую случайную гамету в потенциальной гамодеме, партнер по сингамии которой ограничен биномиальной выборкой. Вероятность того, что вторая гамета гомологична и автозиготна первой, равна 1/(2N) — обратной величине размера гамодемы. Для пяти примеров потомства эти количества составляют 0,1, 0,0833, 0,1, 0,0833 и 0,125 соответственно, а их средневзвешенное значение составляет 0,0961 . Это коэффициент инбридинга для массы образцовых потомков, при условии, что он несмещен по отношению к полному биномиальному распределению. Однако пример, основанный на s = 5 , вероятно, будет предвзятым по сравнению с подходящим полным биномиальным распределением, основанным на количестве выборки ( s ), приближающемся к бесконечности ( s → ∞ ). Другое производное определение f для полного распределения состоит в том, что f также равно увеличению гомозиготности, что равно падению гетерозиготности. [ 33 ] Для примера эти изменения частоты составляют 0,1069 и 0,1070 соответственно. Этот результат отличается от приведенного выше и указывает на то, что в примере присутствует смещение по отношению к полному базовому распределению. примера Для самого лучше использовать последние значения, а именно f • = 0,10695 .
Среднее популяционное значение эквивалентного панмиктика находится как [a (p • -q • ) + 2 p • q • d] + mp . Используя пример эффектов генов ( белая метка « 9 » на диаграмме), это среднее значение равно 37.87. Эквивалентное среднее значение в дисперсной массе равно 36,94 ( черная метка « 10 »), что понижено на величину 0,93 . Это инбридинговая депрессия, вызванная генетическим дрейфом. Однако, как отмечалось ранее, три потомства не были депрессивными (k = 1, 2, 5) и имели значения даже выше, чем у панмиктического эквивалента. Это те линии, которые селекционер ищет в программе селекции линий. [ 34 ]

Обширная биномиальная выборка – восстанавливается ли панмиксия?
[ редактировать ]Если количество биномиальных выборок велико ( s → ∞ ), то p • → p g и q • → q g . Можно задаться вопросом, действительно ли панмиксия вновь появится в этих обстоятельствах. Однако выборка частот аллелей , все же произошла в результате чего σ 2 п, д ≠ 0 . [ 35 ] Действительно, при s → ∞ , что является дисперсией всего биномиального распределения . [ 13 ] : 382–395 [ 14 ] : 49–63 Более того, «уравнения Валунда» показывают, что частоты гомозигот по массе потомства могут быть получены как суммы их соответствующих средних значений ( p 2 • или q 2 • ) плюс σ 2 п, д . [ 13 ] : 382–395 Аналогично, общая частота гетерозигот равна (2 p • q • ) минус удвоенная σ . 2 п, д . Заметно присутствует дисперсия, возникающая в результате биномиальной выборки. Таким образом, даже когда s → ∞ потомства , частоты генеральных генотипов по-прежнему обнаруживают повышенную гомозиготность и снижение гетерозиготности , все еще существует дисперсия средств потомства и все еще инбридинг и инбредная депрессия . То есть панмиксия не достигается повторно после потери из-за генетического дрейфа (биномиальная выборка). Однако новая потенциальная панмиксия может быть инициирована посредством аллогамного F2 после гибридизации. [ 36 ]

Продолжающийся генетический дрейф – усиление дисперсии и инбридинга
[ редактировать ]Предыдущее обсуждение генетического дрейфа рассматривало только один цикл (поколение) этого процесса. Когда выборка продолжается в течение последующих поколений, происходят заметные изменения в σ. 2 п , д и ж . Кроме того, для отслеживания «времени» необходим еще один «индекс»: t = 1 .... y , где y = количество рассматриваемых «лет» (поколений). Методика часто заключается в добавлении текущего биномиального приращения ( Δ = « de novo ») к тому, что произошло ранее. [ 13 ] Здесь рассматривается все биномиальное распределение. [Нет никакой дополнительной пользы от сокращенного примера.]
Рассеяние через σ 2 п, д
[ редактировать ]Ранее эта дисперсия (σ 2 п, д [ 35 ] ) было замечено как: -

С расширением во времени это тоже результат первого цикла, и так (для краткости). В цикле 2 эта дисперсия генерируется еще раз — на этот раз она становится дисперсией de novo ( ) — и накапливается до того, что уже присутствовало — «переходящей» дисперсии. Вторая дисперсия цикла ( ) представляет собой взвешенную сумму этих двух компонентов, причем веса равны для снова и = за «перенос».






Таким образом,
| ( 1 ) |

Расширение для обобщения на любое время t после значительного упрощения становится следующим: [ 13 ] : 328 -
| ( 2 ) |
![{\displaystyle \sigma _{t}^{2}=p_{g}q_{g}\left[1-\left(1-\Delta f\right)^{t}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4e55f249d313eb204b0aad0fdd43789c5c9162df)
Поскольку именно это изменение частот аллелей вызвало «разброс» средних потомков ( дисперсию ), изменение σ 2 t по поколениям указывает на изменение уровня дисперсии .
Дисперсия через f
[ редактировать ]Метод исследования коэффициента инбридинга аналогичен методу, использованному для σ 2 п, q . Те же веса, что и раньше, используются соответственно для de novo f ( Δ f ) [напомним, что это 1/(2N) ] и переноса f . Поэтому, , что аналогично уравнению (1) в предыдущем подразделе.


В общем, после перестановки [ 13 ] Графики слева показывают уровни инбридинга в двадцати поколениях, возникающие в результате генетического дрейфа для различных фактических размеров гамодем (2N).

Дальнейшие перестановки этого общего уравнения выявляют некоторые интересные зависимости.
(А) После некоторого упрощения [ 13 ] . Левая часть представляет собой разницу между текущим и предыдущим уровнями инбридинга: изменение инбридинга ( δf t ). Обратите внимание, что это изменение инбридинга ( δf t ) равно инбридингу de novo ( Δf ) только для первого цикла — когда f t-1 равно нулю .

(B) Следует отметить (1-f t-1 ) , который является «индексом отсутствия инбридинга ». Он известен как панмиктический индекс . [ 13 ] [ 14 ] .

(C) Возникают дальнейшие полезные зависимости, связанные с панмиктическим индексом . [ 13 ] [ 14 ] . (D) Ключевая связь возникает между σ 2 p,q и f . Во-первых... [ 13 ] Во-вторых, предполагая, что f 0 = 0 , правая часть этого уравнения сводится к разделу в скобках уравнения (2) в конце последнего подраздела. То есть, если изначально инбридинга нет, ! Кроме того, если это затем переставить, . То есть, когда начальный инбридинг равен нулю, две основные точки зрения на биномиальную выборку гамет (генетический дрейф) напрямую взаимоконвертируются.




Самоопыление при случайном оплодотворении
[ редактировать ]
Легко упустить из виду, что случайное оплодотворение включает и самооплодотворение. Сьюэлл Райт показал, что доля 1/N случайных оплодотворений на самом деле является самооплодотворением. , а остаток (N-1)/N представляет собой перекрестное оплодотворение. . После анализа пути и упрощения было обнаружено, что новый взгляд на инбридинг со случайным оплодотворением выглядит следующим образом: . [ 27 ] [ 37 ] При дальнейшей перестановке были подтверждены предыдущие результаты биномиальной выборки, а также некоторые новые схемы. Два из них были потенциально очень полезны, а именно: (А) ; и (Б) .



![{\textstyle f_{t}=\Delta f\left[1+f_{t-1}\left(2N-1\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/17a24c2fb8d160fe93430b166097b4cc095d60ad)

Признание того, что самоопыление по своей сути может быть частью случайного оплодотворения, приводит к некоторым проблемам, связанным с использованием предыдущего случайного оплодотворения «коэффициента инбридинга» . Очевидно, что он не подходит для любых видов, неспособных к самооплодотворению , включая растения с механизмами самонесовместимости, двудомные растения и двуполые животные . Уравнение Райта позже было модифицировано, чтобы обеспечить версию случайного оплодотворения, которая включала только перекрестное оплодотворение без самооплодотворения . Пропорция 1/N, ранее возникшая в результате самоопыления, теперь определяла перенос генного дрейфа инбридинга, возникший в результате предыдущего цикла. Новая версия: [ 13 ] : 166 .

справа показаны различия между стандартным случайным оплодотворением RF и случайным оплодотворением с поправкой на «только перекрестное оплодотворение» CF. На графиках Как можно видеть, проблема нетривиальна для небольших размеров выборки гамодем.
Теперь необходимо отметить, что не только «панмиксия» не является синонимом «случайного оплодотворения», но и что «случайное оплодотворение» не является синонимом «перекрестного оплодотворения».
Гомозиготность и гетерозиготность
[ редактировать ]В подразделе «Выборка гамодем – Генетический дрейф» была проведена серия выборок гамет, результатом которых стало увеличение гомозиготности за счет гетерозиготности. С этой точки зрения повышение гомозиготности произошло за счет выборок гамет. Уровни гомозиготности можно рассматривать также по тому, возникли ли гомозиготы аллозиготно или автозиготно. Напомним, что автозиготные аллели имеют одинаковое аллельное происхождение, вероятность (частота) которого является коэффициентом инбридинга ( f ) по определению. Таким образом, доля, возникающая аллозиготно, равна (1-f) . для гамет, несущих А , общая частота которых равна p , общая частота автозиготных гамет равна ( fp Таким образом , ). Аналогично, для гамет, несущих a , автозиготная частота равна ( f q ). [ 38 ] Эти две точки зрения относительно частоты генотипов должны быть связаны, чтобы обеспечить согласованность.
Следуя в первую очередь точке зрения auto/allo , рассмотрим аллозиготный компонент. Это происходит с частотой (1-f) , и аллели объединяются в соответствии с квадратичным расширением случайного оплодотворения . Таким образом: Далее рассмотрим автозиготный компонент. Поскольку эти аллели являются автозиготными , они фактически являются самоопыляющимися и производят генотипы АА или АА , но не гетерозиготы. Поэтому они производят «АА» гомозиготы плюс «аа» гомозиготы. Объединение этих двух компонентов вместе приводит к: для гомозиготы АА ; для гомозиготы аа ; и для гетерозиготы Аа . [ 13 ] : 65 [ 14 ] Это то же уравнение, что и представленное ранее в разделе «Самооплодотворение – альтернатива». Здесь становится ясной причина снижения гетерозиготности. Гетерозиготы могут возникнуть только из аллозиготного компонента, и его частота в массе выборки равна всего (1-f) : следовательно, это также должно быть фактором, контролирующим частоту гетерозигот.
![{\displaystyle \left(1-f\right)\left[p_{0}+q_{0}\right]^{2} =\left(1-f\right)\left[p_{0}^{ 2}+q_{0}^{2}\right]+\left(1-f\right)\left[2p_{0}q_{0}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/991c1f0545c26c29bd5dc324a08fd084d599990d)


![{\textstyle \left[\left(1-f\right)p_{0}^{2}+fp_{0}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c68483dd44cb95ca503376fb095d8cba86179be)
![{\textstyle \left[\left(1-f\right)q_{0}^{2}+fq_{0}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/087333e8a96612e7fb9b5c5da00ac55b23584278)

Во-вторых, выборки пересматривается точка зрения . Ранее отмечалось, что снижение числа гетерозигот было . Это снижение равномерно распределяется среди каждой гомозиготы; и добавляется к их основным ожиданиям случайного оплодотворения . Таким образом, частоты генотипов составляют: для гомозиготы «АА» ; для гомозиготы «аа» ; и для гетерозиготы.




В-третьих, необходимо установить соответствие между двумя предыдущими точками зрения. Сразу видно [из соответствующих уравнений, приведенных выше], что частота гетерозигот одинакова с обеих точек зрения. Однако такой простой результат не сразу очевиден для гомозигот. Начните с рассмотрения АА окончательного уравнения гомозиготы в параграфе auto/allo выше: . Раскройте скобки, а затем заново соберите [в пределах результирующего] два новых члена с общим множителем f в них. Результат: . Далее, для заключенного в скобки " p 2 0 ", a (1-q) заменяется на p , результат становится . После этой замены остается простой вопрос умножения, упрощения и наблюдения за знаками. Конечный результат , что в точности соответствует результату для АА в разделе выборки . Таким образом, обе точки зрения согласуются в отношении гомозиготы АА . последовательность точек зрения аа Подобным же образом можно продемонстрировать . Обе точки зрения едины для всех классов генотипов.

![{\textstyle p_{0}^{2}-f\left[p_{0}\left(1-q_{0}\right)-p_{0}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f31341803ce88db781b4f1c1fdc94e7a19a81488)

Расширенные принципы
[ редактировать ]Другие схемы внесения удобрений
[ редактировать ]
В предыдущих разделах всесторонне рассматривалось дисперсионное случайное оплодотворение ( генетический дрейф ), а также в различной степени исследовались самооплодотворение и гибридизация. На диаграмме слева изображены первые два из них, а также еще один «пространственный» шаблон: острова . Это образец случайного оплодотворения , включающий рассредоточенные гамодемы с добавлением «перекрытий», при которых происходит недисперсионное случайное оплодотворение. При островковом отдельные размеры гамодем ( 2N узоре наблюдаются ), а перекрытия ( m ) минимальны. Это одна из возможностей Сьюэлла Райта. [ 37 ] Помимо «пространственных» моделей оплодотворения, существуют и другие, основанные либо на «фенотипических», либо на «родственных» критериях. К фенотипическим основам относятся ассортативное оплодотворение (между сходными фенотипами) и дисассортативное оплодотворение (между противоположными фенотипами). Паттерны взаимоотношений включают скрещивание сибсов , кузенов и обратное скрещивание — и рассматриваются в отдельном разделе. Самооплодотворение можно рассматривать как с пространственной точки зрения, так и с точки зрения отношений.
«Острова» случайного оплодотворения
[ редактировать ]Гнездящаяся популяция состоит из небольших . рассредоточенных гамодем случайного оплодотворения размером выборки ( k = 1 ... s ) с « перекрытиями » пропорций при котором происходит недисперсионное случайное оплодотворение . Дисперсионная пропорция , таким образом, равна . Основная популяция состоит из средневзвешенных размеров выборки, частот аллелей и генотипов и средних значений потомства, как это было сделано для генетического дрейфа в предыдущем разделе. Однако размер выборки каждой гаметы уменьшается, чтобы учесть перекрытие , таким образом находя эффективен для .




Для краткости аргумент следует далее без индексов. Напомним, что является в общем. [Здесь и далее 2N относится к ранее определенному размеру выборки, а не к какой-либо версии, «скорректированной на острова».]


После упрощения [ 37 ] Обратите внимание, что когда m = 0, это уменьшается до предыдущего Δ f . Обратное к этому значение дает оценку « эффективен для ", упоминалось выше.

Это Δf также подставляется в предыдущий коэффициент инбридинга , чтобы получить [ 37 ] где t — индекс по поколениям, как и раньше.

Эффективную пропорцию перекрытия можно также получить, [ 37 ] как
![{\displaystyle m_{t}=1-\left[{\frac {2N\ {^{\mathsf {острова}}\Delta f_{t}}}{\left(2N-1\right)\ {^{ \mathsf {острова}}\Delta f_{t}+1}}}\right]^{\tfrac {1}{2}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a63b7a6c5b54623d679828146c2530268c3193c)
Графики справа показывают инбридинг для размера гамодемы 2N = 50 для обычного рассеянного случайного оплодотворения (RF) (m=0) и для четырех уровней перекрытия (m = 0,0625, 0,125, 0,25, 0,5) островов . случайного оплодотворения . Действительно, произошло сокращение инбридинга в результате нерассредоточенного случайного оплодотворения при перекрывании. Это особенно заметно, поскольку m → 0,50 . Сьюэлл Райт предположил, что это значение должно быть пределом для использования этого подхода. [ 37 ]
Перетасовка аллелей – замена аллелей
[ редактировать ]Генная модель рассматривает путь наследственности с точки зрения «входов» (аллели/гаметы) и «выходов» (генотипы/зиготы), при этом оплодотворение является «процессом» преобразования одного в другое. Альтернативная точка зрения концентрируется на самом «процессе» и считает, что генотипы зигот возникают в результате перетасовки аллелей. В частности, он рассматривает результаты так, как если бы один аллель «заместил» другой во время перетасовки, вместе с остатком, который отклоняется от этой точки зрения. Это составляло неотъемлемую часть метода Фишера. [ 8 ] в дополнение к использованию частот и эффектов для создания своей генетической статистики. [ 14 ] Далее следует дискурсивный вывод альтернативы замены аллелей . [ 14 ] : 113

Предположим, что обычное случайное оплодотворение гамет в «базовой» гамодеме, состоящей из p гамет ( A ) и q гамет ( a ), заменяется оплодотворением «наводнением» гамет, содержащих одну аллель ( A или a , но не оба). Результаты зиготики можно интерпретировать как аллель «затопления», «заменившую» альтернативную аллель в лежащей в основе «базовой» гамодеме. Следовать этой точке зрения помогает диаграмма: верхняя часть изображает замену А , а нижняя часть показывает замену . (Аллель RF на диаграмме — это аллель «базовой» гамодемы.)
Сначала рассмотрим верхнюю часть. Поскольку основание A присутствует с частотой p , заменитель A оплодотворяет его с частотой p, в результате чего образуется зигота AA с аллельным эффектом a . Таким образом, его вклад в результат – это продукт . Аналогично, когда заменитель оплодотворяет основание a (что приводит к Aa с частотой q и гетерозиготным эффектом d ), вклад равен . общий результат замены на А равен: Таким образом, . Теперь он ориентирован на среднее значение генеральной совокупности [см. предыдущий раздел], выражая его как отклонение от этого среднего значения:




После некоторого алгебраического упрощения это становится - замещения А. эффект
![{\displaystyle \beta _{A}=q\ \left[a+\left(qp\right)d\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c2a8cb74299e659b83fc9cc07fe4056495b026ed)
Аналогичные рассуждения можно применить к нижней части диаграммы, учитывая различия в частотах и эффектах генов. Результатом является эффект замещения a , который Общим фактором внутри скобок является средний эффект замены аллеля , [ 14 ] : 113 и есть Его можно получить и более прямым путем, но результат тот же. [ 39 ]
![{\displaystyle \beta _{a}=-\ p\left[a+\left(qp\right)d\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aedc78c372df5239f7f7ef9b28f19c8766374064)

В последующих разделах эти эффекты замены помогают определить генотипы генной модели как состоящие из разделения, предсказанного этими новыми эффектами ( замены ожиданиями ), и остатком ( отклонениями замены ) между этими ожиданиями и предыдущими эффектами генной модели. Ожидания , также называются племенными ценностями а отклонения также называются отклонениями доминирования .
В конечном итоге дисперсия, возникающая в результате ожиданий замены, становится так называемой аддитивной генетической дисперсией (σ 2 А ) [ 14 ] (также генная вариация [ 40 ] ) — а возникающая в результате отклонений замещения становится так называемой дисперсией доминирования (σ 2 Д ) . Примечательно, что ни один из этих терминов не отражает истинного значения этих отклонений. «Генная вариативность » менее сомнительна, чем аддитивная генетическая вариативность , и больше соответствует названию этого раздела, которое Фишер дал самому Фишеру. [ 8 ] [ 29 ] : 33 Менее вводящее в заблуждение название дисперсии отклонений доминирования — «дисперсия квазидоминирования» (см. дальнейшее обсуждение в следующих разделах). Эти последние термины являются здесь предпочтительными.
Переопределение эффектов генов
[ редактировать ]Эффекты генной модели ( a , d и -a ) вскоре станут важными при выводе отклонений от замены , которые впервые обсуждались в предыдущем разделе «Замена аллелей» . Однако их необходимо переопределить, прежде чем они станут полезными в этом упражнении. Во-первых, их необходимо повторно централизовать вокруг среднего значения популяции ( G ), а во-вторых, их необходимо перестроить в зависимости от β , среднего эффекта замены аллеля .
Рассмотрим в первую очередь рецентрализацию. Рецентрализованный эффект для AA равен a• = a - G , который после упрощения становится a• = 2 q (a- p d) . Аналогичный эффект для Aa равен d• = d - G = a( q - p ) + d(1-2 pq ) после упрощения. Наконец, эффект рецентрализации для aa равен (-a)• = -2 p (a+ q d) . [ 14 ] : 116–119
Во-вторых, рассмотрим перераспределение этих рецентрализованных эффектов в зависимости от β . Вспоминая из раздела «Замена аллелей», что β = [a +(qp)d], перегруппировка дает a = [β -(qp)d] . После замены этого на a в a• и упрощения окончательная версия становится a•• = 2q(β-qd) . Аналогично, d• становится d•• = β(qp) + 2pqd ; и (-a)• становится (-a)•• = -2p(β+pd) . [ 14 ] : 118
Замена генотипа – ожидания и отклонения
[ редактировать ]Генотипы зигот являются целью всей этой подготовки. Гомозиготный генотип АА представляет собой объединение двух эффектов замещения А , по одному от каждого пола. его ожидание замены Следовательно, равно β AA = 2β A = 2 q β (см. предыдущие разделы). Аналогично, ожидание замены Aa равно β + Aa = β A β a = ( q - p )β ; для аа а β аа = 2β а = -2 п β . Эти ожидания замены генотипов также называются племенной ценностью . [ 14 ] : 114–116
Отклонения замещения — это различия между этими ожиданиями и эффектами генов после их двухэтапного переопределения в предыдущем разделе. Следовательно, d AA = a•• - β AA = -2 q 2 д после упрощения. Аналогично, d Aa = d•• - β Aa = 2 pq d после упрощения. Наконец, d aa = (-a)•• - β aa = -2 p 2 д после упрощения. [ 14 ] : 116–119 Обратите внимание, что все эти отклонения от замены в конечном итоге являются функциями генного эффекта d , который объясняет использование ["d" плюс нижний индекс] в качестве их символов. Однако было бы серьезным логическим нарушением рассматривать их как причину доминирования (гетерозиготности) во всей генной модели: они являются просто функциями «d», а не аудитом «d» в системе. Они такие же, как и производные: отклонения от ожиданий замещения !
«Ожидания замещения» в конечном итоге приводят к возникновению σ 2 А (так называемая «аддитивная» генетическая изменчивость); а «отклонения замещения» приводят к σ 2 D (так называемая генетическая вариация «доминирования»). Однако имейте в виду, что средний эффект замещения (β) также содержит «d» [см. предыдущие разделы], что указывает на то, что доминирование также включено в «аддитивную» дисперсию (их вывод см. в следующих разделах, посвященных генотипической дисперсии). Помните также [см. предыдущий параграф], что «отклонения замещения» не объясняют доминирование в системе (представляя собой не что иное, как отклонения от ожиданий замещения ), но которые алгебраически состоят из функций «d». Более подходящими именами для этих соответствующих отклонений могли бы быть σ. 2 B (дисперсия «ожиданий размножения») и σ 2 δ (дисперсия «Селекционные отклонения»). Однако, как отмечалось ранее, «Геник» (σ 2 А ) и «Квази-доминирование» (σ 2 D ), соответственно, будут здесь предпочтительными.
Генотипическая дисперсия
[ редактировать ]Существует два основных подхода к определению и распределению генотипической вариативности . Один из них основан на эффектах генной модели , [ 40 ] в то время как другой основан на эффектах замены генотипа [ 14 ] Они алгебраически взаимоконвертируемы друг с другом. [ 36 ] В этом разделе рассматривается основной процесс случайного оплодотворения , без учета эффектов инбридинга и дисперсии. Это будет рассмотрено позже, чтобы прийти к более общему решению. До тех пор, пока это моногенное лечение не будет заменено мультигенным и пока эпистаз не будет решен в свете результатов эпигенетики , генотипическая дисперсия имеет только компоненты, рассматриваемые здесь.
Подход генной модели – Мэзер Джинкс Хейман
[ редактировать ]
Удобно следовать биометрическому подходу, который основан на корректировке нескорректированной суммы квадратов (USS) путем вычитания поправочного коэффициента (CF) . Поскольку все эффекты были рассмотрены с помощью частот, USS можно получить как сумму произведений «частоты каждого генотипа» и квадрата его генного эффекта . CF в данном случае является среднеквадратическим. В результате получается СС, который, опять же из-за использования частот, также сразу же является дисперсией . [ 9 ]
The и .



После частичного упрощения Последняя строка взята из терминологии Мэзера. [ 40 ] : 212 [ 41 ] [ 42 ]

Здесь σ 2 a - гомозигота или аллельная дисперсия, а σ 2 d - гетерозигота или дисперсия доминирования . Дисперсия отклонений замещения ( σ 2 Д ) тоже присутствует. Объявление ) ( взвешенная_ковариация [ 43 ] далее сокращенно « cov ad ».
Эти компоненты отображены на графике для всех значений p на прилагаемом рисунке. Обратите внимание, что cov ad имеет отрицательное значение при p > 0,5 .
На большинство этих компонентов влияет изменение центрального фокуса от средней точки гомозиготы ( mp ) к среднему значению популяции ( G ), причем последнее является основой поправочного фактора . Дисперсии COV отклонения от и замещения являются просто артефактами этого сдвига. Аллельные вариации являются подлинными генетическими разделами исходной генной модели и являются и доминантные единственными эвгенетическими компонентами. Даже в этом случае на алгебраическую формулу аллельной дисперсии влияет присутствие G : это всего лишь дисперсия доминирования (т.е. σ 2 d на который не влияет переход от mp к G. ) , [ 36 ] Эти идеи обычно не оцениваются по достоинству.
Дальнейший сбор терминов [в формате Mather] приводит к , где . Это полезно позже при анализе Диаллеля, который представляет собой экспериментальный план оценки этой генетической статистики. [ 44 ]


Если после последних перестановок первые три члена объединяются вместе, переставляются дальше и упрощаются, результатом является дисперсия ожидания замены Фишера .
То есть:

Особо отметим, что σ 2 А не σ 2 а . Первый — это дисперсия ожиданий замены , а второй — аллельная дисперсия. [ 45 ] Заметим также, что σ 2 D ( дисперсия отклонений замещения ) не равна σ 2 d ( дисперсия доминирования ), и напомним, что это артефакт, возникающий из-за использования G в качестве поправочного коэффициента. [См. «синий абзац» выше.] Теперь это будет называться дисперсией «квазидоминирования».
Также отметим, что σ 2 Д < σ 2 d («2pq» всегда является дробью); и заметим, что (1) σ 2 D = 2pq σ 2 d и что (2) σ 2 д = п 2 Д /(2пк) . То есть: подтверждено, что σ 2 D не дает количественной оценки дисперсии доминирования в модели. Это σ 2 d, который это делает. Однако дисперсия доминирования (σ 2 d ) можно легко оценить по σ 2 D , если 2pq доступен .
На рисунке эти результаты можно визуализировать как накопление σ 2 а , п 2 d и cov ad , чтобы получить σ 2 A , оставляя σ 2 Буду все еще расставаться. Из рисунка также видно, что σ 2 Д < σ 2 d , как и ожидалось из уравнений.
Общий результат (в формате Фишера) равен Компоненты Фишера только что были выведены, но их вывод через сами эффекты замещения также дан в следующем разделе.
![{\displaystyle {\begin{aligned}\sigma _{G}^{2}&=2pq\left[a+(qp)d\right]^{2}+\left(2pq\right)^{2}d ^{2}\\&=\sigma _{A}^{2}+\sigma _{D}^{2}\\&=\left[\left(\sigma _{a}^{2}+{\mathsf {cov}}_{ad}+\sigma _{d}^{2 }\right)\right]+\left[2pq\\sigma_{d}^{2}\right]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c33eb29c59ac7394562c287f1b65e8d3fea9a8d7)
Подход аллель-замещения - Фишер
[ редактировать ]
Ссылка на несколько предыдущих разделов, посвященных замене аллелей, показывает, что двумя окончательными эффектами являются ожидания замены генотипа и отклонения замены генотипа . Обратите внимание, что каждое из них уже определено как отклонения от среднего значения случайной популяции оплодотворения ( G ). Таким образом, для каждого генотипа по очереди получается произведение частоты и квадрата соответствующего эффекта, и они суммируются для непосредственного получения SS и σ. 2 . [ 46 ] Подробности следуют.
п 2 А = п 2 β АА 2 + 2 pq β Аа 2 + д 2 β аа 2 , что упрощается до σ 2 А = 2 pq β 2 — Генная вариация.
п 2 Д = п 2 д АА 2 + 2 шт. д Аа 2 + q д аа 2 , что упрощается до σ 2 Д = (2 пк ) 2 д 2 – дисперсия квазидоминирования.
Суммируя эти результаты, σ 2 г = п 2 А + р 2 Д. Эти компоненты визуализируются на графиках справа. Средний эффект замены аллеля также представлен на графике, но символом является «α» (как принято в цитатах), а не «β» (как используется здесь).
Однако еще раз обратимся к предыдущим дискуссиям об истинных значениях и идентичности этих компонентов. Сам Фишер не использовал эти современные термины для своих компонентов. Дисперсию ожиданий замены он назвал «генетической» дисперсией; а дисперсию отклонений замещения он рассматривал просто как неназванный остаток между «генотипической» дисперсией (его название для нее) и его «генетической» дисперсией. [ 8 ] [ 29 ] : 33 [ 47 ] [ 48 ] [Терминология и вывод, использованные в этой статье, полностью соответствуют терминологии Фишера.] Термин Мэзера для обозначения ожиданий дисперсии — «генный». [ 40 ] - очевидно, происходит от термина Фишера и избегает использования слова «генетический» (которое стало слишком общим в использовании, чтобы иметь ценность в данном контексте). Происхождение современных вводящих в заблуждение терминов «аддитивная» и «доминантная» дисперсия неясно.
Обратите внимание, что этот подход с аллель-заменой определял компоненты отдельно, а затем суммировал их для получения окончательной генотипической дисперсии. И наоборот, подход генной модели вывел всю ситуацию (компоненты и сумму) как одно упражнение. Бонусами, вытекающими из этого, были: (а) открытие реальной структуры σ 2 A и (b) реальные значения и относительные размеры σ 2 d и σ 2 D (см. предыдущий подраздел). Также очевидно, что анализ «Мазера» более информативен и что на его основе всегда можно построить анализ «Фишера». Однако обратное преобразование невозможно, поскольку информация о cov- рекламе будет отсутствовать.
Дисперсия и генотипическая дисперсия
[ редактировать ]В разделе, посвященном генетическому дрейфу, и в других разделах, посвященных инбридингу, основным результатом выборки частот аллелей стал разброс средних значений потомства. Этот набор средних имеет собственное среднее значение, а также дисперсию: межстрочную дисперсию . (Это вариация самого признака, а не частот аллелей .) По мере дальнейшего развития дисперсии в последующих поколениях можно ожидать, что эта межлинейная дисперсия будет увеличиваться. И наоборот, по мере повышения гомозиготности можно ожидать, что внутрилинейная дисперсия уменьшится. Поэтому возникает вопрос, меняется ли общая дисперсия, и если да, то в каком направлении. На сегодняшний день эти вопросы были представлены с точки зрения генного (σ 2 A ) и квазидоминирование (σ 2 D ) дисперсии, а не компоненты генной модели. Это будет сделано и здесь.
Ключевое уравнение обзора принадлежит Сьюэллу Райту: [ 13 ] : 99, 130 [ 37 ] и представляет собой схему инбредной генотипической дисперсии, основанную на средневзвешенном значении ее крайних значений , причем веса квадратичны по отношению к коэффициенту инбридинга. . Это уравнение:

![{\displaystyle \sigma _{G_{f}}^{2}=\left(1-f\right)\sigma _{G_{0}}^{2}+f\ \sigma _{G_{1} }^{2}+f\left(1-f\right)\left[G_{0}-G_{1}\right]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/baa52231a4dac02644cad91c045a5eb586f2502d)
где коэффициент инбридинга, это генотипическая дисперсия е=0 , - генотипическая дисперсия при f=1 , среднее значение численности населения при f=0 , и — среднее значение численности населения при f=1 .




The Компонент [в приведенном выше уравнении] характеризует уменьшение дисперсии внутри линий потомства. Компонент направлен на увеличение вариативности между линиями потомства. Наконец, Компонент виден (в следующей строке), чтобы устранить дисперсию квазидоминирования . [ 13 ] : 99 и 130 Эти компоненты можно расширить дальше, тем самым раскрывая дополнительную информацию. Таким образом:-


![{\displaystyle \sigma _{G_{f}}^{2}=\left(1-f\right)\left[\sigma _{A_{0}}^{2}+\sigma _{D_{0 }}^{2}\right]+f\ \left(4pq\ a^{2}\right)+f\ \left(1-f\right)\left[2pq\ d\вправо]^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a8e77c382254b7230fcc0cb09f36d8a056cba93a)
Во-первых, σ 2 G(0) [в приведенном выше уравнении] был расширен, чтобы показать два его подкомпонента [см. раздел «Генотипическая дисперсия»]. Далее, σ 2 G(1) преобразован в 4pqa. 2 , и выводится в следующем разделе. Замена третьего компонента представляет собой разницу между двумя «инбридинговыми крайностями» среднего значения популяции [см. раздел «Среднее значение популяции»]. [ 36 ]
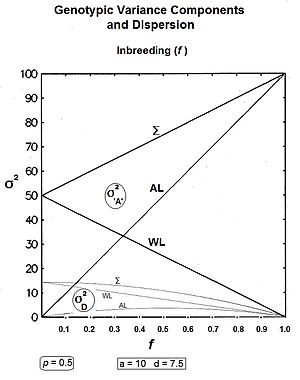
Подводя итог: внутрилинейные компоненты и ; и межстрочные компоненты и . [ 36 ]





Перестановка дает следующее: Версия в последней строке обсуждается далее в следующем разделе.

Сходным образом,

Графики слева показывают эти три генные дисперсии вместе с тремя дисперсиями квазидоминирования для всех значений f для p = 0,5 (при котором дисперсия квазидоминирования максимальна). Графики справа показывают разделы генотипической дисперсии (представляющие собой суммы соответствующих разделов генного и квазидоминирования ), изменяющиеся в течение десяти поколений на примере f = 0,10 .
Отвечая, во-первых, на вопросы, поставленные в начале об общих дисперсиях ( Σ на графиках): генная дисперсия растет линейно с коэффициентом инбридинга , достигая максимума в два раза по сравнению с начальным уровнем. Дисперсия квазидоминирования снижается со скоростью (1 − f 2 ), пока не закончится на нуле. При низких уровнях f снижение происходит очень постепенно, но оно ускоряется при более высоких уровнях f .
Во-вторых, обратите внимание на другие тенденции. Вероятно, интуитивно понятно, что внутрилинейные дисперсии снижаются до нуля при продолжении инбридинга, и это действительно так (обе с одинаковой линейной скоростью (1-f) ). Межлинейные дисперсии увеличиваются с инбридингом до f = 0,5 , генная дисперсия - со скоростью 2f , а дисперсия квазидоминирования - со скоростью (f - f 2 ) . Однако при f > 0,5 тенденции меняются. между линиями Генная дисперсия продолжает линейно увеличиваться до тех пор, пока не станет равной общей генетической дисперсии . Но среди линий дисперсия квазидоминирования теперь снижается до нуля , потому что (f − f 2 ) также снижается при f > 0,5 . [ 36 ]
Вывод σ 2 Г(1)
[ редактировать ]Напомним, что когда f=1 , гетерозиготность равна нулю, внутрилинейная дисперсия равна нулю, и вся генотипическая дисперсия, таким образом, является межлинейной дисперсией и лишена дисперсии доминирования. Другими словами, σ 2 G(1) — это дисперсия среди средних значений полностью инбредных линий. Вспомните далее [из раздела «Среднее значение после самооплодотворения», что такими средними (фактически G 1 ) являются G = a(pq) . Подстановка (1-q) на p дает G 1 = a (1 - 2q) = a - 2aq . [ 14 ] : 265 Следовательно, σ 2 G(1) – это σ 2 (a-2aq) на самом деле. Теперь, в общем, дисперсия разности (xy) равна [ σ 2 х + р 2 y - 2 cov xy ] . [ 49 ] : 100 [ 50 ] : 232 Следовательно, σ 2 G(1) = [ п 2 а + р 2 2aq - 2 cov (a, 2aq) ] . Но a аллеля ( эффект ) и q аллеля ( частота ) независимы , поэтому эта ковариация равна нулю. Более того, a является константой от одной строки к другой, поэтому σ 2 а также равно нулю. Кроме того, 2a — еще одна константа (k), поэтому σ 2 2aq имеет тип σ 2 к Х. В общем случае дисперсия σ 2 k X равен k 2 п 2 Х. [ 50 ] : 232 Если сложить все это вместе, то окажется, что σ 2 (а-2aq) = (2а) 2 п 2 q . Напомним [из раздела «Продолжение генетического дрейфа»], что σ 2 q знак равно pq ж . При f=1 здесь, в рамках данного вывода, это становится pq 1 (то есть pq ), и оно заменяется на предыдущее.
Конечный результат: σ 2 Г(1) = п 2 (а-2aq) = 4а 2 pq = 2(2pq а 2 ) = 2 п 2 а .
Отсюда сразу следует, что f σ 2 Г(1) = ж 2 п 2 а . [Последнее f происходит из исходного уравнения Сьюэлла-Райта : это не f , только что установленное в «1» в выводе, заключенном двумя строками выше.]
Общая дисперсная генная дисперсия – σ 2 A(f) и β f
[ редактировать ]В предыдущих разделах было обнаружено, что внутрилинейная генная вариабельность основана на вызванной заменами генной вариативности, ( σ 2 A ) — но между линиями генная вариабельность основана на модели гена аллельной вариабельности ( σ 2 а ) . Эти два вида нельзя просто сложить, чтобы получить общую генную вариативность . Одним из подходов, позволяющих избежать этой проблемы, было повторное рассмотрение вывода среднего эффекта замены аллеля и построение версии ( β f ) , которая включает эффекты дисперсии. Кроу и Кимура добились этого [ 13 ] : 130–131 с использованием эффектов перецентрированной аллели ( a•, d•, (-a)• ), обсуждавшихся ранее [«Переопределение эффектов генов»]. Однако впоследствии было обнаружено, что это несколько недооценивает общую генетическую дисперсию , и новый вывод, основанный на дисперсии, привел к уточненной версии. [ 36 ]
версия Уточненная : β f = { a 2 + [(1− f ) / (1 + f )] 2(q − p ) ad + [(1- f ) / (1 + f )] (q − p ) 2 д 2 } (1/2)
Следовательно, σ 2 A(f) = (1 + f ) 2pq β f 2 теперь согласуется с [ (1-f) σ 2 А(0) + 2f р 2 a(0) ] точно.
Общие и разделенные дисперсные дисперсии квазидоминирования
[ редактировать ]Общая генетическая вариативность сама по себе представляет интерес. Но до уточнений Гордона [ 36 ] у него было и другое важное применение. Оценок «рассредоточенного» квазидоминирования не существовало. Это было оценено как разница между инбредной генотипической дисперсией Сьюэлла Райта. [ 37 ] и общая «рассеянная» генетическая вариативность [см. предыдущий подраздел]. Однако возникла аномалия, поскольку общая дисперсия квазидоминирования, по-видимому, увеличивалась на ранних этапах инбридинга, несмотря на снижение гетерозиготности. [ 14 ] : 128 : 266
Уточнения в предыдущем подразделе исправили эту аномалию. [ 36 ] В то же время было получено прямое решение для общей дисперсии квазидоминирования , что позволило избежать необходимости использования метода «вычитания», как в предыдущие разы. прямые решения для межлинейного и внутристрочного распределения дисперсии квазидоминирования Кроме того, впервые были получены . [Они представлены в разделе «Дисперсия и генотипическая дисперсия».]
Экологическая изменчивость
[ редактировать ]Экологическая изменчивость — это фенотипическая изменчивость, которую нельзя приписать генетике. Это звучит просто, но экспериментальный план, необходимый для разделения этих двух явлений, требует очень тщательного планирования. Даже «внешнюю» среду можно разделить на пространственную и временную составляющие («Места» и «Годы»); или на такие разделы, как «помет» или «семья» и «культура» или «история». Эти компоненты во многом зависят от фактической экспериментальной модели, использованной для проведения исследования. Такие вопросы очень важны при проведении самих исследований, но в этой статье о количественной генетике этого обзора может быть достаточно.
Однако это подходящее место для подведения итогов:
Фенотипическая дисперсия = генотипическая дисперсия + дисперсия окружающей среды + взаимодействие генотипа и окружающей среды + экспериментальная дисперсия «ошибок».
т. е. σ 2 П = п 2 Г + р 2 Е + σ 2 ГЭ + σ 2
или σ 2 П = п 2 А + р 2 Д + р 2 я + п 2 Е + σ 2 ГЭ + σ 2
после разделения генотипической дисперсии (G) на составляющие дисперсии «генная» (А), «квазидоминантная» (D) и «эпистатическая» (I). [ 51 ]
Отклонения от окружающей среды появятся в других разделах, таких как «Наследственность» и «Коррелированные атрибуты».
Наследственность и повторяемость
[ редактировать ]Наследуемость σ признака — это доля общей (фенотипической) дисперсии ( 2 P ), что связано с генетической изменчивостью, будь то полная генотипическая изменчивость или какой-то ее компонент. Он количественно определяет степень, в которой фенотипическая изменчивость обусловлена генетикой: но точное значение зависит от того, какой раздел генетической вариативности используется в числителе пропорции. [ 52 ] Исследовательские оценки наследственности имеют стандартные ошибки, как и вся оценочная статистика. [ 53 ]
Где дисперсия числителя представляет собой всю генотипическую дисперсию ( σ 2 G ), наследственность известна как наследственность «широкого смысла» ( H 2 ). Он количественно определяет степень, в которой изменчивость признака определяется генетикой в целом. [См. раздел «Генотипическая дисперсия».]
![{\displaystyle {\begin{aligned}H^{2}&={\frac {\sigma_{G}^{2}}{\sigma_{P}^{2}}}\\&={\ frac { \sigma_{A}^{2}+\sigma_{D}^{2}}{\sigma _{P}^{2}}}\\&={\frac {\left[\sigma_{a}^{2}+\sigma_{d}^{2}+cov_{ad}\right] +\ sigma_{D}^{2}}{\sigma_{P}^{2}}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/76a552eecb057ebb771e98bc0b94b39ed29de3c3)
Если бы только генная дисперсия ( σ 2 A ) используется в числителе, то наследуемость можно назвать «узким смыслом» (h 2 ). Он количественно определяет степень, в которой фенотипическая дисперсия определяется дисперсией ожиданий замещения Фишера . Фишер предположил, что эта наследственность в узком смысле может быть уместна при рассмотрении результатов естественного отбора, уделяя особое внимание способности к изменению, то есть «адаптации». [ 29 ] Он предложил это в отношении количественной оценки дарвиновской эволюции.

Вспоминая, что аллельная дисперсия ( σ 2 a ) и дисперсия доминирования ( σ 2 d ) являются эвгенетическими компонентами генной модели (см. раздел «Генотипическая дисперсия») и что σ 2 D ( отклонения замещения или «квазидоминантности» дисперсия ) и cov ad обусловлены переходом от средней точки гомозиготы ( mp ) к популяционному среднему значению ( G ), можно видеть, что реальные значения этих наследственностей неясны. Наследственность и имеют однозначное значение.


Наследственность в узком смысле также использовалась для прогнозирования результатов искусственного отбора . Однако в последнем случае наследственность в широком смысле может быть более подходящей, поскольку изменяется весь атрибут, а не только адаптивная способность. Как правило, прогресс от отбора происходит тем быстрее, чем выше наследственность. [См. раздел «Отбор».] У животных наследственность репродуктивных признаков обычно низкая, тогда как наследственность устойчивости к болезням и продуктивности от умеренно низкой до умеренной, а наследственность строения тела высокая.
Повторяемость (r 2 ) — это доля фенотипической дисперсии, обусловленная различиями в повторных измерениях одного и того же субъекта, возникающими из более поздних записей. Его используют, в частности, для долгоживущих видов. Это значение можно определить только для признаков, которые проявляются несколько раз в течение жизни организма, таких как масса тела взрослой особи, скорость метаболизма или размер помета. Например, индивидуальная масса тела при рождении не будет иметь значения повторяемости, но будет иметь значение наследственности. Обычно, но не всегда, повторяемость указывает на верхний уровень наследуемости. [ 54 ]
р 2 = (с 2 Г +С 2 ПЭ )/с 2 П
где с 2 PE = взаимодействие фенотипа и окружающей среды = повторяемость.
Однако вышеупомянутая концепция повторяемости проблематична для признаков, которые обязательно сильно изменяются между измерениями. Например, у многих организмов масса тела значительно увеличивается в период между рождением и взрослением. Тем не менее, в пределах определенного возрастного диапазона (или этапа жизненного цикла) можно проводить повторные измерения, и повторяемость будет иметь значение на этом этапе.
Отношение
[ редактировать ]
С точки зрения наследственности, родственники — это особи, унаследовавшие гены от одного или нескольких общих предков. Следовательно, их «родство» можно оценить количественно, исходя из вероятности того, что каждый из них унаследовал копию аллели от общего предка. В предыдущих разделах коэффициент инбридинга определялся как «вероятность того, что две одинаковые аллели ( А и А или а и а ) имеют общее происхождение» — или, более формально, «Вероятность того, что две гомологичные аллели являются автозиготными». " Раньше упор делался на вероятность наличия у человека двух таких аллелей, и коэффициент составлялся соответствующим образом. Однако очевидно, что эта вероятность аутозиготности для особи должна также быть вероятностью того, что каждый из двух ее родителей имел этот автозиготный аллель. В этой перефокусированной форме вероятность называется коэффициентом совместного происхождения для двух людей i и j ( f ij ). В этой форме его можно использовать для количественной оценки отношений между двумя людьми, а также его можно назвать коэффициент родства или коэффициент кровного родства . [ 13 ] : 132–143 [ 14 ] : 82–92
Родословный анализ
[ редактировать ]
Родословные — это диаграммы семейных связей между людьми и их предками и, возможно, между другими членами группы, которые разделяют с ними генетическое наследование. Это карты отношений. Таким образом, можно проанализировать родословную, чтобы выявить коэффициенты инбридинга и родства. Такие родословные на самом деле являются неформальным изображением диаграмм путей , используемых в анализе путей , который был изобретен Сьюэллом Райтом, когда он формулировал свои исследования по инбридингу. [ 55 ] : 266–298 Используя соседнюю диаграмму, вероятность того, что особи «B» и «C» получили автозиготные аллели от предка «A», равна 1/2 (один из двух диплоидных аллелей). Это инбридинг «de novo» ( Δf Ped ) на данном этапе. Однако другой аллель мог иметь «переносную» аутозиготность от предыдущих поколений, поэтому вероятность этого равна ( комплементация de novo , умноженная на инбридинг предка A ), то есть (1 − Δf Ped ) f A = ( 1/2) А. ж Следовательно, общая вероятность автозиготности у B и C после бифуркации родословной равна сумме этих двух компонентов, а именно (1/2) + (1/2)f A = (1/2) ( 1+f А ) . Это можно рассматривать как вероятность того, что две случайные гаметы предка А несут автозиготные аллели, и в этом контексте называется коэффициентом происхождения ( f AA ). [ 13 ] : 132–143 [ 14 ] : 82–92 Оно часто появляется в следующих абзацах.
Следуя по пути «B», вероятность того, что какой-либо автозиготный аллель «передастся» каждому последующему родителю, снова равна (1/2) на каждом этапе (включая последний «целевой» X ). Таким образом, общая вероятность передачи по «пути B» равна (1/2). 3 . Степень, до которой возводится (1/2), можно рассматривать как «количество промежуточных звеньев на пути между A и X », n B = 3 . Аналогично, для «пути C» n C = 2 и «вероятность передачи» равна (1/2). 2 . Таким образом, совокупная вероятность автозиготного переноса от A к X равна [ f AA (1/2) (н Б ) (1/2) (н С ) ] . Вспоминая, что f AA = (1/2) (1+f A ) , f X = f PQ = (1/2) (п Б + н С + 1) (1 + ж А ) . В этом примере предполагается, что f A = 0, f X 0,0156 (округлено) = f PQ , одна мера «связности» между P и Q. =
В этом разделе степени ( 1/2 ) использовались для представления «вероятности автозиготности». Позже этот же метод будет использован для представления пропорций наследственных генофондов, наследуемых по родословной [раздел «Родство между родственниками»].

Правила перекрестного умножения
[ редактировать ]В следующих разделах, посвященных скрещиванию сибсов и подобным темам, будет полезен ряд «правил усреднения». Они вытекают из анализа пути . [ 55 ] Правила показывают, что любой коэффициент совместного происхождения может быть получен как среднее значение перекрестного совместного происхождения между соответствующими комбинациями дедушек и родителей. Таким образом, ссылаясь на соседнюю диаграмму, перекрестный множитель 1 означает, что f PQ = среднее значение ( f AC , f AD , f BC , f BD ) = (1/4) [f AC + f AD + f BC + f BD ] знак равно ж Y . Аналогичным образом перекрестный множитель 2 утверждает, что f PC = (1/2) [f AC + f BC ] — тогда как перекрестный множитель 3 утверждает, что f PD = (1/2) [ f AD + f BD ] . Возвращаясь к первому множителю, теперь можно увидеть, что он также равен f PQ = (1/2) [ f PC + f PD ] , который после замены множителей 2 и 3 возобновляет свою первоначальную форму.
В дальнейшем поколение прародителей обозначается как (t-2) , родительское поколение — как (t-1) , а «целевое» поколение — как t .
Полнородственное скрещивание (FS)
[ редактировать ]
Диаграмма справа показывает, что полное скрещивание сибсов является прямым применением перекрестного множителя 1 с небольшой модификацией, которую повторяют родители A и B (вместо C и D ), чтобы указать, что у особей P1 и P2 есть оба родителя . в общем, то есть они полные братья и сестры . Особь Y является результатом скрещивания двух полных братьев и сестер. Следовательно, f Y = f P1,P2 = (1/4) [ f AA + 2 f AB + f BB ] . Напомним, что f AA и f BB были определены ранее (при анализе родословной) как коэффициенты происхождения , равные (1/2)[1+f A ] и (1/2)[1+f B ] соответственно, в настоящем контекст. Помните, что в этом облике предки A и B представляют поколение (t-2) . Таким образом, если предположить, что в любом поколении все уровни инбридинга одинаковы, этих двух коэффициентов происхождения каждый из представляет собой (1/2) [1 + f (t-2) ] .

Теперь рассмотрим f AB . Напомним, что это тоже f P1 или f P2 и поэтому представляет их поколение — f (t-1) . Сложив все это вместе, f t = (1/4) [ 2 f AA + 2 f AB ] = (1/4) [ 1 + f (t-2) + 2 f (t-1) ] . Это коэффициент инбридинга для скрещивания Full-Sib . [ 13 ] : 132–143 [ 14 ] : 82–92 График слева показывает скорость этого инбридинга в течение двадцати повторяющихся поколений. «Повторение» означает, что потомство после цикла t становится родителями-скрещиваниями, которые порождают цикл ( t+1 ) и так далее последовательно. На графиках также для сравнения показан инбридинг при случайном оплодотворении 2N=20 . Напомним, что этот коэффициент инбридинга для потомства Y также является коэффициентом совместного происхождения для его родителей, а также является мерой родства двух братьев и сестер Fill .
Полуродственное скрещивание (HS)
[ редактировать ]Вывод скрещивания полуродственных братьев происходит немного иначе, чем для полных сибсов. На соседней диаграмме два сводных брата в поколении (t-1) имеют только одного общего родителя — родителя «А» в поколении (t-2). Перекрестный множитель 1 используется снова, что дает f Y = f (P1,P2) = (1/4) [ f AA + f AC + f BA + f BC ] . На этот раз существует только один коэффициент отцовства , но три коэффициента совместного происхождения на уровне (t-2) (один из них — f BC — является «пустышкой» и не представляет реального человека на уровне (t-1) поколение). Как и раньше, коэффициент происхождения равен (1/2)[1+f A ] , и каждый из трех родственников представляет f (t-1) . Вспоминая, что f A представляет собой f (t-2) , окончательный сбор и упрощение терминов дает f Y = f t = (1/8) [ 1 + f (t-2) + 6 f (t-1) ] . [ 13 ] : 132–143 [ 14 ] : 82–92 Графики слева включают инбридинг этого полусиба (HS) в течение двадцати последовательных поколений.

Как и раньше, это также количественно определяет родство двух полусибсов в поколении (t-1) в альтернативной форме f (P1, P2) .
Самооплодотворение (SF)
[ редактировать ]Справа приведена родословная схема для самоопыления. Это настолько просто, что не требует каких-либо правил перекрестного умножения. Он использует только базовое сопоставление коэффициента инбридинга и его альтернативы коэффициента родства ; с последующим признанием того, что в данном случае последний также является коэффициентом происхождения . Таким образом, f Y = f (P1, P1) = f t = (1/2) [ 1 + f (t-1) ] . [ 13 ] : 132–143 [ 14 ] : 82–92 Это самый быстрый темп инбридинга из всех типов, как видно на графиках выше. Кривая самоопыления, по сути, представляет собой график коэффициента происхождения .
Переезды кузенов
[ редактировать ]
Они получены методами, аналогичными методам для братьев и сестер. [ 13 ] : 132–143 [ 14 ] : 82–92 Как и раньше, совместного происхождения с точки зрения коэффициент инбридинга обеспечивает меру «родства» между родителями P1 и P2 в этих выражениях кузена.
Родословная двоюродных братьев и сестер (FC) указана справа. Простое уравнение: f Y = f t = f P1,P2 = (1/4) [ f 1D + f 12 + f CD + f C2 ] . После замены соответствующими коэффициентами инбридинга, сбора терминов и упрощения это становится f t = (1/4) [ 3 f (t-1) + (1/4) [2 f (t-2) + f (t- 3) + 1 ]] , версия для итерации, полезная для наблюдения за общей закономерностью и для компьютерного программирования. «Окончательная» версия — f t = (1/16) [ 12 f (t-1) + 2 f (t-2) + f (t-3) + 1 ] .

Родословная троюродных братьев и сестер (SC) находится слева. Родители в родословной, не относящиеся к общему Предку, обозначаются цифрами вместо букв. Здесь простое уравнение имеет вид f Y = f t = f P1,P2 = (1/4) [ f 3F + f 34 + f EF + f E4 ] . После работы с соответствующей алгеброй это становится f t = (1/4) [ 3 f (t-1) + (1/4) [3 f (t-2) + (1/4) [2 f (t -3) + f (t-4) + 1 ]]] , что является итерационной версией. «Окончательная» версия — f t = (1/64) [ 48 f (t-1) + 12 f (t-2) + 2 f (t-3) + f (t-4) + 1 ] .

Чтобы визуализировать закономерность в уравнениях полного кузена , начните серию с полного уравнения sib , переписанного в итерационной форме: f t = (1/4)[2 f (t-1) + f (t-2) + 1 ] . Обратите внимание, что это «основной план» последнего члена в каждой из итеративных форм двоюродного брата: с той небольшой разницей, что индексы генерации увеличиваются на «1» на каждом «уровне» двоюродного брата. Теперь определите уровень двоюродного брата как k = 1 (для двоюродных братьев и сестер), = 2 (для троюродных братьев и сестер), = 3 (для троюродных братьев и сестер) и т. д. и т. д.; и = 0 (для полных сибсов, которые являются «двоюродными братьями нулевого уровня»). Последний член теперь можно записать как: (1/4) [ 2 f (t-(1+k)) + f (t-(2+k)) + 1] . Перед этим последним членом складываются один или несколько приращений итерации в форме (1/4) [ 3 f (tj) + ... , где j - индекс итерации и принимает значения от 1 ... k на протяжении последовательных итерации по мере необходимости. Собрав все это вместе, можно получить общую формулу для всех возможных уровней полнородных кузенов , включая полных сибсов . Для k -го уровня полных кузенов f{k} t = Ιter j = 1 к { (1/4) [ 3 f (tj) + } j + (1/4) [ 2 f (t-(1+k)) + f (t-(2+k)) + 1] . В начале итерации всем f (t- x ) присваивается значение «0», и каждое значение заменяется по мере его вычисления в ходе поколений. Графики справа показывают последовательное инбридинг для нескольких уровней полных кузенов.
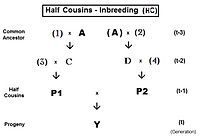
У двоюродных братьев и сестер (FHC) родословная слева. Обратите внимание, что есть только один общий предок (человек А ). Также, что касается троюродных братьев и сестер , родители, не связанные с общим предком, обозначаются цифрами. Здесь простое уравнение имеет вид f Y = f t = f P1,P2 = (1/4) [ f 3D + f 34 + f CD + f C4 ] . После работы с соответствующей алгеброй это становится f t = (1/4) [ 3 f (t-1) + (1/8) [6 f (t-2) + f (t-3) + 1 ]] , что является версией итерации. «Окончательная» версия — f t = (1/32) [ 24 f (t-1) + 6 f (t-2) + f (t-3) + 1 ] . Алгоритм итерации аналогичен алгоритму для полных кузенов , за исключением того, что последний член равен (1/8) [ 6 f (t-(1+k)) + f (t-(2+k)) + 1 ] . Обратите внимание, что этот последний член в основном аналогичен уравнению полуродственного брата, параллельно модели для полных кузенов и полных братьев. Другими словами, сводные братья и сестры являются сводными двоюродными братьями «нулевого уровня».
Существует тенденция рассматривать скрещивание кузенов с точки зрения, ориентированной на человека, возможно, из-за широкого интереса к генеалогии. Использование родословных для установления инбридинга, возможно, усиливает эту точку зрения на «семейную историю». Однако такие виды скрещивания происходят и в естественных популяциях, особенно в тех, которые ведут оседлый образ жизни или имеют «зону размножения», которую они повторно посещают из сезона в сезон. Группа потомства гарема с доминирующим самцом, например, может содержать элементы скрещивания братьев и сестер, кузена и обратного скрещивания, а также генетического дрейфа, особенно «островного» типа. В дополнение к этому, случайное «ауткроссирование» добавляет в смесь элемент гибридизации. Это не панмиксия.
Обратное скрещивание (BC)
[ редактировать ]

После гибридизации между A и R F1 ) с (индивид B ) скрещивается обратно ( BC1 исходным родителем ( R ) для получения поколения BC1 (индивид C ). [Обычно используют один и тот же ярлык для акта обратного скрещивания и для поколения, произведенного в результате него. Акт обратного скрещивания выделен курсивом . ] Родитель R — повторяющийся родительский элемент. Изображены два последовательных обратных скрещивания, причем отдельный D представляет собой поколение BC2 . Как указано, этим поколениям также были присвоены t- индексы. Как и раньше, f D = f t = f CR = (1/2) [ f RB + f RR ] с использованием ранее заданного перекрестного множителя 2 . Только что определенный f ( RB — это тот, который включает генерацию t-1) с (t-2) . Однако существует еще один такой f RB, полностью содержащийся в поколении (t-2) , и именно он используется сейчас: как совместное происхождение индивидуума родителей C в поколении (t-1) . По существу, это также коэффициент инбридинга C и , следовательно, f (t-1) . Оставшийся f RR представляет собой коэффициент происхождения рекуррентного родителя. , а также (1/2) [1 + f R ] . Сложим все это вместе: f t = (1/2) [ (1/2) [ 1 + f R ] + f (t-1) ] = (1/4) [ 1 + f R + 2 f (t- 1) ] . Графики справа иллюстрируют инбридинг обратного скрещивания более двадцати обратных скрещиваний для трех различных уровней (фиксированного) инбридинга у рекуррентного родителя.
Эта процедура обычно используется в программах по разведению животных и растений. Часто после создания гибрида (особенно если особи недолговечны) рекуррентному родителю требуется отдельное «линейное разведение» для его поддержания в качестве будущего рекуррентного родителя при обратном скрещивании. Это поддержание может осуществляться путем самоопыления, скрещивания полных или полусибсов или за счет ограниченных случайно оплодотворенных популяций, в зависимости от репродуктивных возможностей вида. Конечно, это постепенное повышение f R переносится и на f t обратного скрещивания. В результате кривая поднимается к асимптотам более плавно, чем показано на настоящих графиках, поскольку f R не находится на фиксированном уровне с самого начала.
Вклад наследственных генофондов
[ редактировать ]В разделе «Анализ родословной» использовался для представления вероятностей автозиготного происхождения аллелей в течение n поколений по ветвям родословной. Эта формула возникла из-за правил, налагаемых половым размножением: (i) два родителя вносят практически равные доли аутосомных генов и (ii) последовательное разбавление для каждого поколения между зиготой и «фокусным» уровнем происхождения. Эти же правила применимы и к любой другой точке зрения на происхождение в двуполой репродуктивной системе. Одним из них является доля любого наследственного генофонда (также известного как «зародышевая плазма»), которая содержится в генотипе любой зиготы.

Следовательно, доля предкового генофонда в генотипе равна: где n = количество половых поколений между зиготой и фокусным предком.

Например, каждый родитель определяет генофонд, способствующий своему потомству; в то время как каждый прадедушка и прадедушка вносят свой вклад своему праправнуку.


Общий генофонд зиготы ( Γ ), конечно, представляет собой сумму полового вклада в ее происхождение.

Отношения через наследственные генофонды
[ редактировать ]Лица, произошедшие от общего предкового генофонда, очевидно, связаны между собой. Это не означает, что они идентичны по своим генам (аллелям), поскольку на каждом уровне предка при образовании гамет происходит сегрегация и сортировка. Но они произошли из того же пула аллелей, доступных для этих мейозов и последующих оплодотворений. [Эта идея впервые была встречена в разделах, посвященных анализу родословной и взаимоотношениям.] Таким образом, вклад генофонда [см. раздел выше] их ближайшего общего предкового генофонда ( предкового узла ) может быть использован для определения их родства. Это приводит к интуитивному определению отношений, которое хорошо согласуется со знакомыми представлениями о «родстве», встречающимися в семейной истории; и позволяет сравнивать «степень родства» для сложных моделей отношений, возникающих из такой генеалогии.
Единственные необходимые модификации (по очереди для каждого человека) находятся в Γ и связаны с переходом к «общему общему предку», а не к «индивидуальному общему происхождению». Для этого определим Р (вместо Г ); m = количество общих предков в узле (т.е. m = только 1 или 2); и «индивидуальный индекс» k . Таким образом:

где, как и раньше, n = количество половых поколений между особью и предковым узлом.
Примером могут служить двое двоюродных братьев и сестер. Их ближайшим общим предковым узлом являются их бабушка и дедушка, которые дали начало двум их родным братьям и сестрам, и у них обоих есть общие дедушка и бабушка. [См. предыдущую родословную.] В этом случае m=2 и n=2 , поэтому для каждого из них

В этом простом случае каждый двоюродный брат имеет численно одно и то же Р.
Второй пример может быть между двумя полными кузенами, но один ( k=1 ) имеет три поколения до исходного узла (n=3), а другой ( k=2 ) только два (n=2) [т.е. второе и отношения двоюродного брата]. Для обоих m=2 (они полные родственники).

и

Обратите внимание, что у каждого двоюродного брата есть разные Ρ k .
GRC – коэффициент родства генофонда.
[ редактировать ]При любой попарной оценке отношений для каждой особи имеется один Ρ k : остается их усреднить, чтобы объединить в единый «Коэффициент связи». Поскольку каждое Р представляет собой часть общего генофонда , подходящим средним значением для них является среднее геометрическое. [ 56 ] [ 57 ] : 34–55 Это среднее значение и есть их коэффициент родства генофонда — «GRC».
Для первого примера (два полных двоюродных брата) их GRC = 0,5; для второго случая (полный двоюродный и троюродный брат) их GRC = 0,3536.
Все эти отношения (GRC) являются приложениями путевого анализа. [ 55 ] : 214–298 Ниже приводится краткое описание некоторых уровней взаимоотношений (GRC).
| ГРЦ | Примеры отношений |
|---|---|
| 1.00 | полные братья и сестры |
| 0.7071 | Родитель ↔ Потомство; Дядя/тетя ↔ Племянник/Племянница |
| 0.5 | полные двоюродные братья; наполовину сибсы; великий родитель ↔ великий потомок |
| 0.3536 | полный Кузенс Первый ↔ Второй; полная версия «Двоюродные братья» {1 удалить} |
| 0.25 | полные троюродные братья; наполовину двоюродные братья и сестры; полная версия «Двоюродные братья» {2 удалений} |
| 0.1768 | полная версия «Двоюродный брат» {3 удаления}; полная Троюродные братья {1 удалить} |
| 0.125 | полные троюродные братья и сестры; половина троюродных братьев и сестер; полностью Двоюродные братья и сестры {4 удаления} |
| 0.0884 | полные двоюродные братья {5 удалений}; половина троюродных братьев и сестер {1 удалить} |
| 0.0625 | полные четвертые кузены; половина троюродных братьев и сестер |
Сходство между родственниками
[ редактировать ]Они, как и генотипические вариации, могут быть получены либо с помощью подхода генной модели («Мазер»), либо с помощью подхода аллель-замены («Фишер»). Здесь каждый метод демонстрируется для альтернативных случаев.
Ковариация родителей и потомков
[ редактировать ]Их можно рассматривать либо как ковариацию между любым потомком и любым из его родителей ( PO ), либо как ковариацию между любым потомком и значением «промежуточного родителя» обоих его родителей ( MPO ).
Один родитель и потомство (PO)
[ редактировать ]Это можно получить как сумму перекрестных произведений между эффектами родительских генов и половиной ожиданий потомства с использованием подхода аллель-замены. Половина ожидаемого потомства объясняется тем фактом, что только один из двух родителей рассматривается . Таким образом, соответствующие эффекты родительских генов представляют собой переопределенные генные эффекты второй стадии, используемые для определения генотипических отклонений ранее, то есть: a″ = 2q(a − qd) и d″ = (qp)a + 2pqd , а также (-a )″ = -2p(a + pd) [см. раздел «Переопределение эффектов генов»]. Аналогичным образом, соответствующие эффекты потомства для ожиданий замены аллелей составляют половину значений более раннего разведения , причем последнее составляет: a AA = 2qa , a Aa = (qp)a а также aa , = -2pa [см. раздел, посвященный «Замена генотипа – ожидания и отклонения».
Поскольку все эти эффекты уже определены как отклонения от среднего генотипического значения, сумма перекрестного произведения с использованием { частота генотипа * эффект родительского гена * значение полуразведения } немедленно обеспечивает ковариацию ожиданий замены аллелей между любым одним родителем. и его потомство. После тщательного сбора терминов и упрощения получается cov(PO) A = pqa. 2 = 1/2 с 2 А. [ 13 ] : 132–141 [ 14 ] : 134–147
К сожалению, аллель-замещения-отклонения обычно не замечают, но они тем не менее не «перестали существовать»! Напомним, что эти отклонения составляют: d AA = -2q 2 d и d Aa = 2pq d , а также d aa = -2p 2 d [см. раздел «Замена генотипа – ожидания и отклонения»]. Следовательно, сумма перекрестного произведения с использованием { частота генотипа * эффект родительского гена * отклонения половинных замен } также немедленно обеспечивает ковариацию отклонений аллель-замены между любым одним родителем и его потомством. Еще раз, после тщательного сбора терминов и упрощения, это становится cov(PO) D = 2p. 2 д 2 д 2 = 1/2 с 2 Д.
Отсюда следует, что: cov(PO) = cov(PO) A + cov(PO) D = 1/2 с 2 А + 1/2 с 2 D , когда доминирование не упускается из виду!
Средний родитель и потомство (MPO)
[ редактировать ]Поскольку существует множество комбинаций родительских генотипов, необходимо учитывать множество различных способов получения средних родителей и потомков, а также различную частоту получения каждой родительской пары. Генно-модельный подход в данном случае является наиболее целесообразным. Таким образом, нескорректированная сумма перекрестных произведений (USCP) — с использованием всех продуктов { частота родительской пары * эффект среднего родительского гена * среднее значение генотипа потомства } — корректируется путем вычитания {общего среднего генотипического значения} 2 в качестве поправочного коэффициента (CF) . После умножения всех различных комбинаций, тщательного сбора терминов, упрощения, факторизации и сокращения, где это применимо, это становится:
cov(MPO) = pq [a + (qp)d ] 2 = pq а 2 = 1/2 с 2 A , причем в данном случае не было упущено из виду доминирование, поскольку оно было использовано при определении a . [ 13 ] : 132–141 [ 14 ] : 134–147
Приложения (родитель-потомок)
[ редактировать ]Наиболее очевидным применением является эксперимент, в котором участвуют все родители и их потомки, с взаимным скрещиванием или без него, предпочтительно воспроизведенный без систематической ошибки, позволяющий оценить все соответствующие средние значения, дисперсии и ковариации, а также их стандартные ошибки. Эти приблизительные статистические данные затем можно использовать для оценки генетических отклонений. Двойная разница между оценками двух форм (скорректированной) ковариации родитель-потомок дает оценку s 2 Д ; и удвоенная cov(MPO) оценка s 2 А. При соответствующем экспериментальном планировании и анализе [ 9 ] [ 49 ] [ 50 ] Стандартные ошибки также могут быть получены для этой генетической статистики. Это основная суть эксперимента, известного как анализ Диаллеля , версия которого Мэзера, Джинкса и Хеймана обсуждается в другом разделе.
Второе приложение предполагает использование регрессионного анализа , который оценивает на основе статистики ординату (оценка Y), производную (коэффициент регрессии) и константу (пересечение Y) исчисления. [ 9 ] [ 49 ] [ 58 ] [ 59 ] Коэффициент регрессии оценивает скорость изменения функции, прогнозирующей Y от X , на основе минимизации остатков между подобранной кривой и наблюдаемыми данными (MINRES). Никакой альтернативный метод оценки такой функции не удовлетворяет этому основному требованию MINRES. В общем, коэффициент регрессии оценивается как отношение ковариации (XY) к дисперсии определителя (X) . На практике размер выборки обычно одинаков для X и Y, поэтому его можно записать как SCP(XY)/SS(X) , где все термины были определены ранее. [ 9 ] [ 58 ] [ 59 ] В данном контексте родители рассматриваются как «определяющая переменная» (X), потомство — как «определяемая переменная» (Y), а коэффициент регрессии — как «функциональная связь» (ßPO ) между ними. Принимая cov(MPO) = 1/2 с 2 A как cov(XY) и s 2 P / 2 (дисперсия среднего значения двух родителей — среднего родителя) как s 2 X , видно, что ß MPO = [ 1/2 с 2 А ] / [ 1/2 с 2 п ] = час 2 . [ 60 ] Далее, используя cov(PO) = [ 1/2 с 2 А + 1/2 с 2 D ] как cov(XY) и s 2 Проходить 2 X , видно, что 2 ß PO = [ 2 ( 1/2 с 2 А + 1/2 с 2 Д )]/с 2 П = Ч 2 .
Анализ эпистаза ранее предпринимался с использованием дисперсионного подхода типа s. 2 АА и с 2 нашей эры , а также с 2 ДД . Это было интегрировано с этими существующими ковариациями, чтобы предоставить оценки эпистазных дисперсий. Однако результаты эпигенетики предполагают, что это может быть неподходящим способом определения эпистаза.
Ковариации братьев и сестер
[ редактировать ]Ковариантность между полусибсами ( HS ) легко определяется с помощью методов аллельной замены; но, опять же, вклад доминирования исторически не учитывался. Однако, как и в случае с ковариацией среднего родителя/потомка, ковариация между полными сибсами ( FS ) требует подхода «родительской комбинации», что делает необходимым использование метода перекрестного произведения с поправкой на модель гена; и вклад доминирования исторически не упускался из виду. Превосходство производных генной модели здесь так же очевидно, как и генотипических вариаций.
Полуродные братья одного и того же общего родителя (HS)
[ редактировать ]Сумма перекрестных произведений {частота общего родителя * значение половинного разведения одного полусибса * значение половинного разведения любого другого полусибса в той же группе общих родителей} немедленно дает одно из требуемых ковариации, поскольку используемые эффекты [ породные значения , представляющие ожидания замены аллелей] уже определены как отклонения от генотипического среднего значения [см. раздел «Замена аллелей – Ожидания и отклонения»]. После упрощения. это становится: cov(HS) A = 1 / 2 pq а 2 = 1/4 с 2 А. [ 13 ] : 132–141 [ 14 ] : 134–147 Однако отклонения замещения также существуют, определяя сумму перекрестных произведений { частота общего родителя * отклонение полузамены одного полуродственного брата * отклонение полузамены любого другого полуродителя в том же общем родителе -group } , что в конечном итоге приводит к: cov(HS) D = p 2 д 2 д 2 = 1/4 с 2 Д. Добавление двух компонентов дает:
cov(HS) = cov(HS) A + cov(HS) D = 1/4 с 2 А + 1/4 с 2 Д.
Полные братья и сестры (FS)
[ редактировать ]Как пояснялось во введении, используется метод, аналогичный методу, используемому для ковариации средних родителей/потомков. Таким образом, нескорректированная сумма перекрестных произведений (USCP) с использованием всех продуктов — { частота родительской пары * квадрат среднего генотипа потомка } — корректируется путем вычитания {общего среднего генотипического значения} 2 в качестве поправочного коэффициента (CF) . В этом случае перемножение всех комбинаций, тщательный сбор членов, упрощение, факторизация и вычитание занимают очень много времени. В конечном итоге это становится:
cov(FS) = pq a 2 + р 2 д 2 д 2 = 1/2 с 2 А + 1/4 с 2 D , при этом ни одно доминирование не было упущено из виду. [ 13 ] : 132–141 [ 14 ] : 134–147
Приложения (братья и сестры)
[ редактировать ]Наиболее полезным применением генетической статистики здесь является корреляция между полусибсами . Напомним, что коэффициент корреляции ( r ) представляет собой отношение ковариации к дисперсии (см., например, раздел «Связанные атрибуты»). Следовательно, r HS = cov(HS)/s 2 все ГС вместе = [ 1/4 с 2 А + 1/4 с 2 Д ]/с 2 П = 1 / 4 Ч 2 . [ 61 ] Корреляция между полными сибсами малополезна: r FS = cov(FS)/s. 2 все ФС вместе = [ 1/2 с 2 А + 1/4 с 2 Д ]/с 2 П. Предположение о том, что оно «приближает» ( 1/2 ч 2 ) плохой совет.
Конечно, корреляции между братьями и сестрами представляют интерес сами по себе, совершенно независимо от какой-либо полезности, которую они могут иметь для оценки наследственности или генотипических различий.
Возможно, стоит отметить, что [ cov(FS) − cov(HS)] = 1/4 с 2 А. Эксперименты, состоящие из семейств FS и HS, могли бы использовать это, используя внутриклассовую корреляцию для приравнивания компонентов дисперсии эксперимента к этим ковариациям (обоснование этого см. в разделе «Коэффициент связи как внутриклассовая корреляция»).
Более ранние комментарии относительно эпистаза снова применимы и здесь [см. раздел «Применение (родители-потомки»).
Выбор
[ редактировать ]Основные принципы
[ редактировать ]
Отбор действует на основе атрибута (фенотипа), так что особи, которые равны или превышают порог отбора (z P ), становятся эффективными родителями для следующего поколения. Доля , которую они представляют в базовой популяции, является давлением отбора . Чем меньше доля, тем сильнее давление. Среднее значение выбранной группы (P s ) превосходит среднее значение базовой совокупности (P 0 ) за счет разницы, называемой дифференциалом выбора (S) . Все эти величины фенотипичны. Чтобы «связаться» с лежащими в основе генами, наследственность (h 2 ) используется, выполняя роль коэффициента детерминации в биометрическом смысле. Ожидаемое генетическое изменение , все еще выраженное в фенотипических единицах измерения , называется генетическим прогрессом (ΔG) и получается как произведение дифференциала отбора (S) и его коэффициента детерминации (h). 2 ) . Ожидаемое среднее значение потомства (P 1 ) находится путем прибавления генетического прогресса (ΔG) к базовому среднему значению (P 0 ) . Графики справа показывают, как (начальный) генетический прогресс увеличивается при более сильном давлении отбора (меньшая вероятность ). Они также показывают, как прогресс от последовательных циклов отбора (даже при одном и том же давлении отбора) неуклонно снижается, поскольку фенотипическая дисперсия и наследственность уменьшаются самим отбором. Это обсуждается далее в ближайшее время.
Таким образом . [ 14 ] : 1710–181 и . [ 14 ] : 1710–181


Узкосмысловая наследственность (h 2 ) обычно используется, тем самым связываясь с генной дисперсией (σ 2 А ) . Однако, если это уместно, использование наследственности в широком смысле (H 2 ) будет связано с генотипической дисперсией (σ 2 Г ) ; и даже, возможно, аллельная наследственность [ h 2 я = (σ 2 а ) / (р 2 P ) ] можно рассматривать как соединение с ( σ 2 а ). [См. раздел «Наследственность».]
Чтобы применить эти концепции до того, как отбор действительно произойдет, и таким образом спрогнозировать результат альтернатив (например, выбора порога отбора ), эти фенотипические статистические данные пересматриваются с учетом свойств нормального распределения, особенно тех, которые касаются усечения превосходный хвост распределения. При таком рассмотрении стандартизованный дифференциал отбора (i)″ и стандартизированный вместо предыдущих «фенотипических» версий используются фенотипическое стандартное отклонение (σ P(0) ) порог отбора (z)″. Также необходимо . Это описано в следующем разделе.
Следовательно, ΔG = (i σ P ) h 2 , где (i σ P(0) ) = S ранее. [ 14 ] : 1710–181

В приведенном выше тексте отмечено, что последовательные ΔG снижаются, потому что «входные данные» [ фенотипическая дисперсия ( σ 2 P ) ] уменьшается по сравнению с предыдущим выбором. [ 14 ] : 1710–181 Наследственность также снижена. Графики слева показывают это снижение в течение десяти циклов повторного отбора, в течение которых утверждается то же самое давление отбора. В этом примере накопленный генетический прогресс ( ΣΔG ) практически достиг своей асимптоты к шестому поколению. Это снижение частично зависит от свойств усечения нормального распределения, а частично от наследственности вместе с детерминацией мейоза ( b 2 ) . Последние два пункта количественно определяют степень, в которой усечение «компенсируется» новыми вариациями, возникающими в результате сегрегации и ассортимента во время мейоза. [ 14 ] : 1710–181 [ 27 ] Это скоро будет обсуждаться, но здесь обратите внимание на упрощенный результат для недисперсного случайного оплодотворения (f = 0) .
Таким образом: п 2 Р(1) = р 2 P(0) [1 − я ( из) 1/2 ч 2 ] , где i ( iz) = K = коэффициент усечения и 1/2 ч 2 = R = коэффициент воспроизводства [ 14 ] : 1710–181 [ 27 ] Это можно записать также как σ 2 Р(1) = р 2 P(0) [1 − KR] , что облегчает более детальный анализ задач выбора.
Здесь i и z уже определены, 1 / 2 — детерминация мейоза ( б 2 ) для f=0 , а оставшийся символ — это наследственность. Они обсуждаются далее в следующих разделах. Также обратите внимание, что в более общем смысле R = b 2 час 2 . Если определение общего мейоза ( b 2 ) результаты предшествующего инбридинга могут быть включены в отбор. Тогда уравнение фенотипической дисперсии принимает вид:
п 2 Р(1) = р 2 P(0) [1 − i ( iz) b 2 час 2 ] .
Фенотипическая дисперсия, усеченная выбранной группой ( σ 2 P(S) ) — это просто σ 2 P(0) [1 − K] , а его содержащаяся генная дисперсия равна (h 2 0 п 2 П(С) ). Предполагая, что отбор не изменил изменчивость окружающей среды , генетическую изменчивость потомства можно аппроксимировать σ 2 А(1) = ( п 2 П(1) - п 2 Е ) . Исходя из этого, ч 2 1 = (п 2 А(1) /п 2 Р(1) ) . Аналогичные оценки можно сделать и для σ 2 Г(1) и Н 2 1 или для σ 2 а(1) и ч 2 eu(1), если требуется.
Альтернативный вариант ΔG
[ редактировать ]Следующая перестановка полезна для рассмотрения выбора по нескольким атрибутам (символам). Он начинается с расширения наследственности на компоненты дисперсии. ΔG = я σ P ( σ 2 А /п 2 П ) σ σ P и 2 P частично отменить, оставив соло σ P . Далее, σ 2 A внутри наследуемости можно разложить как ( σ A × σ A ), что приводит к:

ΔG знак равно я σ А ( σ А / σ п ) знак равно я σ А час .
Соответствующие перестановки могут быть сделаны с использованием альтернативных наследственных свойств, давая ΔG = i σ или eu ΔG = i σ a h GH .
Модели полигенной адаптации в популяционной генетике
[ редактировать ]Этот традиционный взгляд на адаптацию в количественной генетике обеспечивает модель того, как выбранный фенотип меняется со временем в зависимости от дифференциала отбора и наследственности. Однако он не дает понимания (и не зависит от) каких-либо генетических деталей - в частности, количества задействованных локусов, частот их аллелей и размеров эффекта, а также изменений частоты, вызванных отбором. Это, напротив, является предметом работ по полигенной адаптации. [ 62 ] в области популяционной генетики . Недавние исследования показали, что такие черты, как рост, развились у людей за последние несколько тысяч лет в результате небольших сдвигов частоты аллелей в тысячах вариантов, влияющих на рост. [ 63 ] [ 64 ] [ 65 ]
Фон
[ редактировать ]Стандартизированный отбор – нормальное распределение
[ редактировать ]Вся базовая совокупность очерчена нормальной кривой. [ 59 ] : 78–89 Направо. По оси Z отложено каждое значение атрибута от наименьшего до наибольшего, а высота от этой оси до самой кривой — это частота значения на оси ниже. Уравнение нахождения этих частот для «нормальной» кривой (кривой «общего опыта») представлено в виде эллипса. Обратите внимание, что оно включает в себя среднее значение ( µ ) и дисперсию ( σ 2 ). Бесконечно перемещаясь вдоль оси z, частоты соседних значений могут «складываться» рядом с предыдущими, тем самым накапливая область, которая представляет вероятность получения всех значений в стеке. [Это интеграция из исчисления.] Отбор фокусируется на такой вероятностной области, которая представляет собой заштрихованную область от порога выбора (z) до конца верхнего хвоста кривой. Это давление отбора . Выбранная группа (эффективные родители следующего поколения) включает все значения фенотипа от z до «конца» хвоста. [ 66 ] Среднее значение выбранной группы — μ s , а разница между ним и базовым средним значением ( μ ) представляет собой дифференциал выбора (S) . Путем частичного интегрирования по интересующим участкам кривой и некоторой перестановки алгебры можно показать, что «дифференциал выбора» равен S = [ y (σ / Prob.)] , где y — частота значения в точке порог выбора» z ( ордината z « ). [ 13 ] : 226–230 Перестановка этого соотношения дает S/σ = y/Prob. , левая часть которого, по сути, представляет собой дифференциал отбора, разделенный на стандартное отклонение , — это стандартизированный дифференциал отбора (i) . Правая часть соотношения представляет собой «оценщик» для i — ординаты порога выбора, деленной на давление выбора . Таблицы нормального распределения [ 49 ] : 547–548 можно использовать, но i . также доступны таблицы самого [ 67 ] : 123–124 Последняя ссылка также дает значения i , скорректированные для небольших популяций (400 и меньше), [ 67 ] : 111–122 где «квазибесконечность» не может быть принята (но предполагалась в схеме «Нормального распределения» выше). Стандартизованный дифференциал отбора ( i ) известен также как интенсивность отбора . [ 14 ] : 174, 186
Наконец, может оказаться полезной перекрестная связь с другой терминологией из предыдущего подраздела: μ (здесь) = «P 0 » (там), μ S = « PS » и σ. 2 = "σ 2 П ».
Определение мейоза – анализ репродуктивного пути
[ редактировать ]

Определение мейоза (b 2 ) — коэффициент детерминации мейоза, то есть деления клеток, в результате которого родители образуют гаметы. Следуя принципам стандартизированной частичной регрессии , графической версией которой является анализ путей , Сьюэлл Райт проанализировал пути потока генов во время полового размножения и установил «силы вклада» ( коэффициенты детерминации ) различных компонентов в общий результат. результат. [ 27 ] [ 37 ] Анализ пути включает в себя частичные корреляции , а также коэффициенты частичной регрессии (последние являются коэффициентами пути ). Линии с одинарным наконечником стрелки представляют собой определяющие направления пути , а линии с двойными наконечниками стрелок являются корреляционными связями . Отслеживание различных маршрутов в соответствии с правилами анализа путей имитирует алгебру стандартизированной частичной регрессии. [ 55 ]
Диаграмма пути слева представляет этот анализ полового размножения. Из его интересных элементов важным в контексте отбора является мейоз . Именно здесь происходят сегрегация и ассортимент — процессы, которые частично смягчают сокращение фенотипической вариативности, возникающей в результате отбора. Коэффициенты пути b представляют собой пути мейоза. Те, что отмечены буквой a, представляют собой пути оплодотворения. Корреляция между гаметами одного родителя ( g ) — мейотическая корреляция . Между родителями одного поколения есть r A . Коэффициент между гаметами от разных родителей ( f ) впоследствии стал называться коэффициентом инбридинга . [ 13 ] : 64 Штрихи (') обозначают поколение (t-1) , а незаштрихованные указывают поколение t . Здесь приведены некоторые важные результаты настоящего анализа. Сьюэлл Райт интерпретировал многие из них с точки зрения коэффициентов инбридинга. [ 27 ] [ 37 ]
Определение мейоза ( b 2 ) является 1/2 и равно +g) ( 1 1/2 g (t - (1 + f (t-1) ) , подразумевая, что = f 1) . [ 68 ] При недисперсном случайном внесении f (t-1) ) = 0, что дает b 2 = 1 / 2 , как указано в разделе выбора выше. Однако, зная об этом, при необходимости можно использовать и другие схемы внесения удобрений. Другая детерминация также включает инбридинг — детерминация оплодотворения ( а 2 ) равно 1 / [ 2 ( 1 + ж т ) ] . Также еще одной корреляцией является показатель инбридинга — r A = 2 f t / ( 1 + f (t-1) ) , также известный как коэффициент родства . [Не путайте это с коэффициентом родства — альтернативным названием коэффициента родства . См. введение к разделу «Взаимосвязи».] Это r A снова встречается в подразделе, посвященном дисперсии и отбору.
Эти связи с инбридингом открывают интересные аспекты полового размножения, которые не очевидны сразу. На графиках справа показаны мейоза и сингамии (оплодотворения) коэффициенты детерминации в зависимости от коэффициента инбридинга. Там выявлено, что по мере усиления инбридинга большее значение приобретает мейоз (увеличивается коэффициент), а сингамия становится менее значимой. Общая роль воспроизводства (произведение двух предыдущих коэффициентов — r 2 ] остается прежним. [ 69 ] Это увеличение b 2 особенно актуально для отбора, поскольку это означает, что сокращение фенотипической дисперсии при отборе компенсируется в меньшей степени во время последовательности отборов, когда оно сопровождается инбридингом (что часто имеет место).
Генетический дрейф и отбор
[ редактировать ]В предыдущих разделах дисперсия рассматривалась как «помощник» отбора , и стало очевидно, что они хорошо работают вместе. В количественной генетике отбор обычно исследуется таким «биометрическим» способом, но изменения в средних значениях (отслеживаемые по ΔG) отражают изменения частот аллелей и генотипов под этой поверхностью. Обращение к разделу «Генетический дрейф» заставляет вспомнить, что он также влияет на изменения частот аллелей и генотипов и связанных с ними средств; и что это сопутствующий аспект рассматриваемой здесь дисперсии («другая сторона одной медали»). Однако эти две силы изменения частоты редко действуют согласованно и часто могут действовать вопреки друг другу. Один (отбор) является «направленным» и обусловлен давлением отбора, действующим на фенотип: другой (генетический дрейф) обусловлен «случайностью» оплодотворения (биномиальными вероятностями образцов гамет). Если они имеют тенденцию к одной и той же частоте аллелей, их «совпадение» — это вероятность получения образца этих частот в результате генетического дрейфа; однако вероятность того, что они находятся «в конфликте», равна сумма вероятностей всех альтернативных выборок частоты . В крайних случаях одна-единственная выборка сингамии может свести на нет то, чего достиг отбор, и вероятности того, что это произойдет, известны. Важно помнить об этом. Однако генетический дрейф, приводящий к тому, что частоты выборки аналогичны частотам выборки, не приводит к столь радикальному результату, а вместо этого замедляет прогресс в достижении целей отбора.
Коррелирующие атрибуты
[ редактировать ]При совместном наблюдении двух (или более) атрибутов ( например, роста и массы) можно заметить, что они изменяются вместе по мере изменения генов или окружающей среды. Эта ковариация измеряется ковариацией , которая может быть представлена как « cov » или θ . [ 43 ] Будет положительно, если они изменяются вместе в одном и том же направлении; или отрицательным, если они изменяются вместе, но в противоположном направлении. Если два атрибута изменяются независимо друг от друга, ковариация будет равна нулю. Степень связи между атрибутами количественно оценивается коэффициентом корреляции (символ r или ρ ). В общем, коэффициент корреляции представляет собой отношение ковариации к среднему геометрическому. [ 70 ] из двух вариантов атрибутов. [ 59 ] : 196–198 Наблюдения обычно происходят на фенотипе, но в исследованиях они также могут происходить на «эффективном гаплотипе» (эффективном генном продукте) (см. рисунок справа). Таким образом, ковариация и корреляция могут быть «фенотипическими», «молекулярными» или любыми другими обозначениями, которые допускает модель анализа. Фенотипическая ковариация является «самым внешним» уровнем и соответствует «обычной» ковариации в биометрии/статистике. Однако ее можно разделить с помощью любой подходящей исследовательской модели так же, как и фенотипическую дисперсию. Каждому разделу ковариации соответствует соответствующий раздел корреляции. Некоторые из этих разделов приведены ниже. Первый нижний индекс (G, A и т. д.) указывает на раздел. Индексы второго уровня (X, Y) являются «хранителями места» для любых двух атрибутов.

Первый пример — неразделенный фенотип.

Далее следуют генетические разделы (а) «генотипические» (общий генотип), (б) «генные» (ожидания замещения) и (в) «аллельные» (гомозиготы).
(а)

(б)

(с)

При правильно спланированном эксперименте негенетическое можно также получить (средовое) разделение.

Основные причины корреляции
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( июль 2016 г. ) |
Существует несколько различных способов возникновения фенотипической корреляции. Дизайн исследования, размер выборки, статистика выборки и другие факторы могут влиять на возможность различать их с большей или меньшей статистической достоверностью. Каждый из них имеет разное научное значение и относится к разным областям работы.
Прямая причинно-следственная связь
[ редактировать ]Один фенотип может напрямую влиять на другой фенотип, влияя на развитие, метаболизм или поведение.
Генетические пути
[ редактировать ]Общий ген или фактор транскрипции в биологических путях двух фенотипов может привести к корреляции.
Метаболические пути
[ редактировать ]Метаболические пути от гена к фенотипу сложны и разнообразны, но причины корреляции между признаками лежат внутри них.
Факторы развития и окружающей среды
[ редактировать ]На несколько фенотипов могут влиять одни и те же факторы. Например, существует множество фенотипических признаков, коррелирующих с возрастом, поэтому рост, вес, потребление калорий, эндокринная функция и многое другое имеют корреляцию. Исследование, направленное на поиск других общих факторов, должно сначала исключить их.
Коррелирующие генотипы и давление отбора
[ редактировать ]Различия между подгруппами в популяции, между популяциями или селективные предубеждения могут означать, что некоторые комбинации генов представлены чрезмерно по сравнению с тем, что можно было бы ожидать. Хотя гены могут не оказывать существенного влияния друг на друга, между ними все же может существовать корреляция, особенно когда определенным генотипам не разрешено смешиваться. Популяции, находящиеся в процессе генетической дивергенции или уже подвергшиеся ей, могут иметь разные характерные фенотипы. [ 71 ] а это значит, что при совместном рассмотрении появляется корреляция. Фенотипические качества человека, преимущественно зависящие от происхождения, также вызывают корреляции этого типа. Это также можно наблюдать у пород собак, где несколько физических особенностей составляют отличительные черты данной породы и, следовательно, коррелируют. [ 72 ] Ассортативное спаривание , которое представляет собой сексуальное избирательное давление с целью спаривания со схожим фенотипом, может привести к тому, что генотипы останутся коррелированными в большей степени, чем можно было бы ожидать. [ 73 ]
См. также
[ редактировать ]- Искусственный отбор
- Диаллельный крест
- Дуглас Скотт Фалконер
- Формула выборки Юэнса
- Экспериментальная эволюция
- Вопрос СТ
- Генетическая архитектура
- Генетическая дистанция
- Наследственность
- Рональд Фишер
Сноски и ссылки
[ редактировать ]- ^ Андерберг, Майкл Р. (1973). Кластерный анализ приложений . Нью-Йорк: Академическая пресса.
- ^ Мендель, Грегор (1866). «Опыты над гибридами растений». Переговоры Ассоциации естественных исследований в Брно . iv .
- ^ Jump up to: а б с Мендель, Грегор (1891). «Опыты по гибридизации растений». Дж. Рой. Хорт. Соц. (Лондон) . XXV . Перевод Бейтсона, Уильяма: 54–78.
- ^ Мендель Г.; Статья Бейтсона В. (1891) с дополнительными комментариями Бейтсона перепечатана в: Sinnott EW; Данн Л.С.; Добжанский Т. (1958). «Основы генетики»; Нью-Йорк, МакГроу-Хилл: 419–443. В сноске 3, стр. 422 указано, что Бейтсон является оригинальным переводчиком, и приводится ссылка на этот перевод.
- ^ QTL — это участок генома ДНК, который влияет на количественные фенотипические признаки или связан с ними.
- ^ Уотсон, Джеймс Д.; Гилман, Майкл; Витковский, Ян; Золлер, Марк (1998). Рекомбинантная ДНК (Второе (7-е издание) изд.). Нью-Йорк: WH Freeman (Scientific American Books). ISBN 978-0-7167-1994-6 .
- ^ Джайн, Гонконг; Харквал, MC, ред. (2004). Селекция растений - менделевский и молекулярный подходы . Бостон Дордехт, Лондон: Kluwer Academic Publishers. ISBN 978-1-4020-1981-4 .
- ^ Jump up to: а б с д Фишер, Р.А. (1918). «Корреляция между родственниками при предположении о менделевском наследовании» . Труды Королевского общества Эдинбурга . 52 (2): 399–433. дои : 10.1017/s0080456800012163 . S2CID 181213898 . Архивировано из оригинала 8 октября 2020 года . Проверено 7 сентября 2020 г.
- ^ Jump up to: а б с д и ж г Сталь, РГД; Торри, Дж. Х. (1980). Принципы и процедуры статистики (2-е изд.). Нью-Йорк: МакГроу-Хилл. ISBN 0-07-060926-8 .
- ^ Иногда используются и другие символы, но они распространены.
- ^ Эффект аллеля - это среднее фенотипическое отклонение гомозиготы от средней точки двух контрастирующих фенотипов гомозиготы в одном локусе, наблюдаемое на бесконечности всех фоновых генотипов и сред. На практике этот параметр заменяют оценки на основе больших несмещенных выборок.
- ^ Эффект доминирования - это среднее фенотипическое отклонение гетерозиготы от средней точки двух гомозигот в одном локусе, наблюдаемое на бесконечности всех фоновых генотипов и сред. На практике этот параметр заменяют оценки на основе больших несмещенных выборок.
- ^ Jump up to: а б с д и ж г час я дж к л м н тот п д р с т в v В х и С аа аб и объявление но из в ах Кроу, Дж. Ф.; Кимура, М. (1970). Введение в теорию популяционной генетики . Нью-Йорк: Харпер и Роу.
- ^ Jump up to: а б с д и ж г час я дж к л м н тот п д р с т в v В х и С аа аб и объявление но из в ах есть также и аль Фальконер, Д.С.; Маккей, Труди (1996). Введение в количественную генетику (Четвертое изд.). Харлоу: Лонгман. ISBN 978-0582-24302-6 .
- Уильям Дж. Хилл; Труди Маккей (август 2004 г.). «Д.С. Фальконер и введение в количественную генетику» . Генетика . 167 (4): 1529–1536. дои : 10.1093/генетика/167.4.1529 . ПМК 1471025 . ПМИД 15342495 .
- ^ Мендель прокомментировал эту конкретную тенденцию для F1> P1, т.е. свидетельство гибридной силы длины стебля. Однако разница может быть не существенной. (Соотношение между диапазоном и стандартным отклонением известно [Steel and Torrie (1980): 576), что позволяет провести приблизительный тест значимости для этой существующей разницы.)
- ^ Ричардс, Эй Джей (1986). Системы селекции растений . Бостон: Джордж Аллен и Анвин. ISBN 0-04-581020-6 .
- ^ Институт Джейн Гудолл. «Социальная структура шимпанзе» . Шимпанзе Централ . Архивировано из оригинала 3 июля 2008 года . Проверено 20 августа 2014 г.
- ^ Гордон, Ян Л. (2000). «Количественная генетика аллогамных F2: происхождение случайно оплодотворенных популяций» . Наследственность . 85 : 43–52. дои : 10.1046/j.1365-2540.2000.00716.x . ПМИД 10971690 .
- ^ Однако F2, полученный в результате самооплодотворения особей F1 ( автогамный F2), не является источником случайно оплодотворенной структуры популяции. См. Гордон (2001).
- ^ Замок, МЫ (1903 г.). «Закон наследственности Гальтона и Менделя и некоторые законы, регулирующие улучшение расы путем отбора». Труды Американской академии искусств и наук . 39 (8): 233–242. дои : 10.2307/20021870 . hdl : 2027/hvd.32044106445109 . JSTOR 20021870 .
- ^ Харди, GH (1908). «Менделевские пропорции в смешанном населении» . Наука . 28 (706): 49–50. Бибкод : 1908Sci....28...49H . дои : 10.1126/science.28.706.49 . ПМЦ 2582692 . ПМИД 17779291 .
- ^ Вайнберг, В. (1908). «О доказательствах наследственности у человека». ежегодный Клуб Ф. Ватерля. Натюрк, Вюртем . 64 :368-382.
- ^ Обычно в научной этике открытие называют в честь первого человека, который его предложил. Касла, однако, похоже, не заметили: а позже, когда его снова нашли, название «Харди Вайнберг» стало настолько повсеместным, что обновлять его казалось уже слишком поздно. Возможно, равновесие «Замка Харди Вайнберга» было бы хорошим компромиссом?
- ^ Jump up to: а б Гордон, Ян Л. (1999). «Количественная генетика внутривидовых гибридов» . Наследственность . 83 (6): 757–764. дои : 10.1046/j.1365-2540.1999.00634.x . ПМИД 10651921 .
- ^ Гордон, Ян Л. (2001). «Количественная генетика автогамных F2» . Эредитас . 134 (3): 255–262. дои : 10.1111/j.1601-5223.2001.00255.x . ПМИД 11833289 .
- ^ Райт, С. (1917). «Средняя корреляция внутри подгрупп населения». Дж. Ваш. Акад. Наука . 7 : 532–535.
- ^ Jump up to: а б с д и ж г Райт, С. (1921). «Системы спаривания. I. Биометрические отношения между родителем и потомством» . Генетика . 6 (2): 111–123. дои : 10.1093/генетика/6.2.111 . ПМК 1200501 . ПМИД 17245958 .
- ^ Синнотт, Эдмунд В.; Данн, ЖК; Добжанский, Феодосий (1958). Принципы генетики . Нью-Йорк: МакГроу-Хилл.
- ^ Jump up to: а б с д и Фишер, РА (1999). Генетическая теория естественного отбора (изд. Varorum). Оксфорд: Издательство Оксфордского университета. ISBN 0-19-850440-3 .
- ^ Jump up to: а б Кокран, Уильям Г. (1977). Методы отбора проб (Третье изд.). Нью-Йорк: Джон Уайли и сыновья.
- ^ Это описано далее в разделе генотипических отклонений.
- ^ Оба широко используются.
- ^ См. предыдущие цитаты.
- ^ Аллард, RW (1960). Принципы селекции растений . Нью-Йорк: Джон Уайли и сыновья.
- ^ Jump up to: а б Это читается как «σ 2 p и/или σ 2 q ". Поскольку p и q дополняют друг друга, σ 2 п ≡ п 2 q и σ 2 р = р 2 q .
- ^ Jump up to: а б с д и ж г час я Гордон, Иллинойс (2003). «Уточнения к разделению инбредной генотипической дисперсии» . Наследственность . 91 (1): 85–89. дои : 10.1038/sj.hdy.6800284 . ПМИД 12815457 .
- ^ Jump up to: а б с д и ж г час я дж Райт, Сьюэлл (1951). «Генетическая структура популяций». Анналы евгеники . 15 (4): 323–354. дои : 10.1111/j.1469-1809.1949.tb02451.x . ПМИД 24540312 .
- ^ Помните, что вопрос ауто/алло-зиготности может возникнуть только для гомологичных аллелей (то есть A и A или a и a ), а не для негомологичных аллелей ( A и a ), которые не могут иметь один и тот же аллель. источник .
- ^ Для этой величины обычно используют «α», а не «β» (например, в уже цитированных ссылках). Последнее используется здесь, чтобы свести к минимуму любую путаницу с «а», которая часто возникает в этих же уравнениях.
- ^ Jump up to: а б с д Мэзер, Кеннет; Джинкс, Джон Л. (1971). Биометрическая генетика . Том. 26 (2-е изд.). Лондон: Чепмен и Холл. стр. 349–364. дои : 10.1038/hdy.1971.47 . ISBN 0-412-10220-Х . ПМИД 5285746 . S2CID 46065232 .
{{cite book}}:|journal=игнорируется ( помогите ) - ^ В терминологии Мэзера дробь перед буквой является частью этикетки компонента.
- ^ В каждой строке этих уравнений компоненты представлены в одном и том же порядке. Поэтому вертикальное сравнение по компонентам дает определение каждого в различных формах. Таким образом, компоненты Мазера были переведены в символы Фишера, что облегчило их сравнение. Перевод также был получен формально. См. Гордон 2003.
- ^ Jump up to: а б Ковариация — это ковариантность между двумя наборами данных. Как и дисперсия, она основана на сумме перекрестных произведений (SCP), а не на SS. Отсюда ясно, что дисперсия есть лишь особая форма ковариации.
- ^ Хейман, Б.И. (1960). «Теория и анализ диаллельного креста. III» . Генетика . 45 (2): 155–172. дои : 10.1093/генетика/45.2.155 . ПМК 1210041 . ПМИД 17247915 .
- ^ Было замечено, что когда p = q или когда d = 0 , β [= a+(qp)d] «сводится» к a . В таких обстоятельствах σ 2 А = п 2 а — но только численно . Они до сих пор не стали одной и той же личностью. Это было бы аналогично тому , что отмечалось ранее для «отклонений замещения», рассматриваемых как «доминирование» генной модели.
- ^ Подтверждающие цитаты уже приводились в предыдущих разделах.
- ↑ Фишер отметил, что эти остатки возникли в результате эффектов доминирования: но он воздержался от определения их как «дисперсии доминирования». (См. приведенные выше цитаты.) Еще раз обратитесь к предыдущим обсуждениям здесь.
- ^ При рассмотрении происхождения терминов: Фишер также предложил слово «дисперсия» для этой меры изменчивости. См. Фишер (1999), стр. 311 и Фишер (1918).
- ^ Jump up to: а б с д Снедекор, Джордж В.; Кокран, Уильям Г. (1967). Статистические методы (Шестое изд.). Эймс: Издательство Университета штата Айова. ISBN 0-8138-1560-6 .
- ^ Jump up to: а б с Кендалл, Миннесота; Стюарт, А. (1958). Передовая теория статистики. Том 1 (2-е изд.). Лондон: Чарльз Гриффин.
- ^ Обычной практикой является отсутствие нижнего индекса у экспериментальной дисперсии «ошибки».
- ^ В биометрии это коэффициент дисперсии, в котором часть выражается как часть целого: то есть коэффициент детерминации . Такие коэффициенты используются, в частности, в регрессионном анализе . Стандартизированной версией регрессионного анализа является анализ пути . В данном случае стандартизация означает, что данные сначала были разделены на собственные экспериментальные стандартные ошибки, чтобы унифицировать шкалы для всех атрибутов. Такое генетическое использование является еще одним важным проявлением коэффициентов детерминации.
- ^ Гордон, Иллинойс; Бит, Делавэр; Валаам, Л.Н. (1972). «Вариация коэффициентов наследственности, оцененная на основе компонентов фенотипической дисперсии». Биометрия . 28 (2): 401–415. дои : 10.2307/2556156 . JSTOR 2556156 . ПМИД 5037862 .
- ^ Дом, MR (2002). «Оценки повторяемости не всегда устанавливают верхний предел наследуемости» . Функциональная экология . 16 (2): 273–280. Бибкод : 2002FuEco..16..273M . дои : 10.1046/j.1365-2435.2002.00621.x .
- ^ Jump up to: а б с д Ли, Чинг Чун (1977). Анализ пути - Букварь (второе издание с исправлениями под ред.). Пасифик Гроув: Самшит Пресс. ISBN 0-910286-40-Х .
- ^ квадратный корень из их произведения
- ^ Морони, MJ (1956). Факты из цифр (третье изд.). Хармондсворт: Книги Пингвинов.
- ^ Jump up to: а б Дрейпер, Норман Р.; Смит, Гарри (1981). Прикладной регрессионный анализ (Второе изд.). Нью-Йорк: Джон Уайли и сыновья. ISBN 0-471-02995-5 .
- ^ Jump up to: а б с д Валаам, Л.Н. (1972). Основы биометрии . Лондон: Джордж Аллен и Анвин. ISBN 0-04-519008-9 .
- ^ В прошлом обе формы ковариации родитель-потомок применялись к этой задаче оценки h 2 , но, как отмечалось в подразделе выше, только один из них ( cov(MPO) на самом деле подходит ). Однако cov (PO) полезен для оценки H 2 как видно из основного текста ниже.
- ^ Обратите внимание, что тексты, игнорирующие компонент доминирования cov(HS), ошибочно предполагают, что r HS «приближается» ( 1/4 ч . 2 ).
- ^ Причард, Джонатан К.; Пикрелл, Джозеф К.; Куп, Грэм (23 февраля 2010 г.). «Генетика адаптации человека: жесткие меры, мягкие меры и полигенная адаптация» . Современная биология . 20 (4): Р208–215. Бибкод : 2010CBio...20.R208P . дои : 10.1016/j.cub.2009.11.055 . ISSN 1879-0445 . ПМЦ 2994553 . ПМИД 20178769 .
- ^ Турчин, Майкл С.; Чан, Чарльстон, штат Западная Каролина; Палмер, Кэмерон Д.; Шанкарараман, Шрирам; Райх, Дэвид; Консорциум генетических исследований антропометрических признаков (GIANT); Хиршхорн, Джоэл Н. (сентябрь 2012 г.). «Свидетельства широко распространенного отбора по вариациям стояния в Европе по SNP, связанным с высотой» . Природная генетика . 44 (9): 1015–1019. дои : 10.1038/ng.2368 . ISSN 1546-1718 . ПМЦ 3480734 . ПМИД 22902787 .
- ^ Берг, Джереми Дж.; Куп, Грэм (август 2014 г.). «Популяционно-генетический сигнал полигенной адаптации» . ПЛОС Генетика . 10 (8): e1004412. дои : 10.1371/journal.pgen.1004412 . ISSN 1553-7404 . ПМК 4125079 . ПМИД 25102153 .
- ^ Поле, Яир; Бойл, Эван А.; Телис, Натали; Гао, Зиюэ; Голтон, Кайл Дж.; Голан, Дэвид; Йенго, Лоик; Рошельо, Гислен; Фрогель, Филипп (11 ноября 2016 г.). «Обнаружение адаптации человека за последние 2000 лет» . Наука . 354 (6313): 760–764. Бибкод : 2016Sci...354..760F . дои : 10.1126/science.aag0776 . ISSN 0036-8075 . ПМК 5182071 . ПМИД 27738015 .
- ^ Теоретически хвост бесконечен , но на практике есть квазиконец .
- ^ Jump up to: а б Беккер, Уолтер А. (1967). Руководство по количественной генетике (Второе изд.). Пуллман: Университет штата Вашингтон.
- ^ Обратите внимание, что это б 2 - это коэффициент происхождения ( f AA ) переписанный анализа родословной, с использованием «уровня поколения» вместо буквы «А» в скобках.
- ^ Существует небольшое «колебание», возникающее из-за того, что b 2 меняется на одно поколение за 2 — изучить их уравнения инбридинга.
- ^ Оценивается как квадратный корень их произведения.
- ^ «Репродуктивная изоляция» . Понимание эволюции . Беркли. 16 апреля 2021 г.
- ^ Серрес-Армеро, А; Дэвис, BW; Поволоцкая И.С.; Морсильо-Суарес, К; Плассе, Дж; Хуан, Д; Острандер, Э.А.; Маркес-Боне, Т. (май 2021 г.). «Изменение числа копий лежит в основе сложных фенотипов у домашних пород собак и других псовых» . Геномные исследования . 31 (5): 762–774. дои : 10.1101/гр.266049.120 . ПМК 8092016 . ПМИД 33863806 .
- ^ Цзян, Юэсинь; Больник, Дэниел И.; Киркпатрик, Марк (2013). «Ассортативное спаривание животных» (PDF) . Американский натуралист . 181 (6): Е125–Е138. дои : 10.1086/670160 . HDL : 2152/31270 . ПМИД 23669548 . S2CID 14484725 .
Дальнейшее чтение
[ редактировать ]- Фальконер Д.С. и Маккей TFC (1996). Введение в количественную генетику, 4-е издание. Лонгман, Эссекс, Англия.
- Кабальеро, А. (2020) Количественная генетика. Издательство Кембриджского университета.
- Линч М. и Уолш Б. (1998). Генетика и анализ количественных признаков. Зинауер, Сандерленд, Массачусетс.
- Рофф Д.А. (1997). Эволюционная количественная генетика. Чепмен и Холл, Нью-Йорк.
- Сейкора, Тони. Зоотехника 3221 Животноводство. Тех. Миннеаполис: Университет Миннесоты, 2011. Печать.
Внешние ссылки
[ редактировать ]- Уравнение заводчика
- Ресурсы по количественной генетике Майкла Линча и Брюса Уолша , включая два тома их учебника « Генетика и анализ количественных признаков» и «Эволюция и отбор количественных признаков» .
- Ресурсы Ника Бартона и др. . из учебника Эволюция .
- G-Матрица Онлайн