Частота букв
| Письмо | Относительная частота в английском языке [1] | |||
|---|---|---|---|---|
| Тексты | Словари [ нужна ссылка ] | |||
| А | 8.2% | 7.8% | ||
| Б | 1.5% | 2.0% | ||
| С | 2.8% | 4.0% | ||
| Д | 4.3% | 3.8% | ||
| И | 12.7% | 11.0% | ||
| Ф | 2.2% | 1.4% | ||
| Г | 2.0% | 3.0% | ||
| ЧАС | 6.1% | 2.3% | ||
| я | 7.0% | 8.6% | ||
| Дж | 0.15% | 0.21% | ||
| К | 0.77% | 0.97% | ||
| л | 4.0% | 5.3% | ||
| М | 2.4% | 2.7% | ||
| Н | 6.7% | 7.2% | ||
| ТО | 7.5% | 6.1% | ||
| П | 1.9% | 2.8% | ||
| вопрос | 0.095% | 0.19% | ||
| Р | 6.0% | 7.3% | ||
| С | 6.3% | 8.7% | ||
| Т | 9.1% | 6.7% | ||
| В | 2.8% | 3.3% | ||
| V | 0.98% | 1.0% | ||
| В | 2.4% | 0.91% | ||
| Х | 0.15% | 0.27% | ||
| И | 2.0% | 1.6% | ||
| С | 0.074% | 0.44% | ||
Частота букв — это количество раз, когда встречаются в буквы алфавита среднем в письменной речи . Анализ частоты букв восходит к арабскому математику Аль-Кинди ( ок. 801–873 гг. н.э.), который формально разработал метод взлома шифров . Анализ частоты букв приобрел важное значение в Европе с развитием подвижного шрифта в 1450 году нашей эры, где нужно было оценить количество шрифтов, необходимое для каждой формы буквы . Лингвисты используют частотный анализ букв как элементарный метод идентификации языка , где он особенно эффективен для определения того, является ли неизвестная система письма алфавитной, слоговой или идеографической .
Использование частот букв и частотный анализ играют фундаментальную роль в криптограммах и некоторых играх-головоломках, включая Hangman , Scrabble , Wordle. [2] и телевизионное игровое шоу «Колесо фортуны» . Одно из самых ранних описаний в классической литературе применения знания частоты английских букв для решения криптограммы можно найти в Эдгара Аллана По знаменитом рассказе « Золотой жук », где этот метод успешно применяется для расшифровки сообщения с указанием местоположения. о сокровище, спрятанном капитаном Киддом . [3] [ нужна ссылка ]
Герберт С. Зим в своем классическом вводном учебнике по криптографии « Коды и секретное письмо » дает частотную последовательность английских букв как « ETAON RISHD LFCMU GYPWB VKJXZQ », а наиболее распространенные пары букв — как «TH HE AN RE ER IN ON AT ND ST ES EN». OF TE ED OR TI HI AS TO», а наиболее распространенные двойные буквы — «LL EE SS OO TT FF RR NN PP CC». [4] Разные способы подсчета могут давать несколько разные порядки.
Частота букв также оказывает сильное влияние на дизайн некоторых раскладок клавиатуры . Наиболее часто встречающиеся буквы размещаются на домашнем ряду пишущей машинки Blickensderfer , раскладки клавиатуры Дворжака , Колемака и других оптимизированных раскладок.
Фон
[ редактировать ]
Частота букв в тексте изучалась для использования в криптоанализе и, в частности, частотном анализе , начиная с арабского математика аль-Кинди (ок. 801–873 гг. Н.э.), который официально разработал метод (шифры, которые можно взломать с помощью этого метода). вернитесь хотя бы к шифру Цезаря, использованному Юлием Цезарем , [ нужна ссылка ] так что этот метод мог быть исследован еще в классические времена). Анализ частоты букв приобрел дополнительное значение в Европе с развитием подвижного шрифта в 1450 году нашей эры, где нужно было оценить количество шрифта, необходимое для каждой формы буквы, о чем свидетельствуют различия в размере отсеков для букв в шрифтах типографа.
В основе данного языка не лежит точное распределение частот букв, поскольку все писатели пишут немного по-разному. Однако большинство языков имеют характерное распределение, которое ярко проявляется в более длинных текстах. Даже такие радикальные изменения языка, как от древнеанглийского к современному английскому (считающемуся взаимонепонятным), демонстрируют сильные тенденции в частоте связанных букв: на небольшой выборке библейских отрывков, от наиболее частых к наименее частым, enaid sorhm tgþlwu æcfy ðbpxz из древнеанглийского языка сравнивает to eotha sinrd luymw fgcbp kvjqxz современного английского языка, при этом самые крайние различия, касающиеся форм букв, не являются общими. [5]
Линотипные машины для английского языка предполагали порядок букв, от наиболее распространенного к наименее распространенному, следующий: etaoin shrdlu cmfwyp vbgkqj xz, основываясь на опыте и обычаях ручных наборщиков. Эквивалентом для французского языка было elaoin sdrétu cmfhyp vbgwqj xz .
Если разбить алфавит Морзе на группы букв, для передачи которых требуется равное количество времени, а затем отсортировать эти группы в порядке возрастания, получим e it san hurdm wgvlfbk opxcz jyq . [а] Частота букв использовалась другими телеграфными системами, такими как Кодекс Мюррея .
Подобные идеи используются в современных методах сжатия данных, таких как кодирование Хаффмана .
Частота букв, как и частота слов , обычно варьируется как в зависимости от автора, так и в зависимости от темы. Например, ⟨d⟩ чаще встречается в художественной литературе, поскольку большая часть художественной литературы написана в прошедшем времени, и поэтому большинство глаголов оканчиваются флективным суффиксом -ed / -d . Невозможно написать эссе о рентгеновских лучах, не используя часто ⟨x⟩ . У разных авторов есть привычки, которые могут отразиться на использовании ими букв. стиля Например, стиль письма Хемингуэя заметно отличается от . Фолкнера Буква, биграмма , триграмма , частота слов, длина слова и длина предложения могут рассчитываться для конкретных авторов и использоваться для доказательства или опровержения авторства текстов, даже для авторов, стили которых не так сильно расходятся.
Точные средние частоты букв можно получить только путем анализа большого количества репрезентативного текста. При наличии современных вычислительных средств и коллекций больших текстовых корпусов такие расчеты легко выполнить. Примеры можно взять из различных источников (сообщения в прессе, религиозные тексты, научные тексты и художественная литература), и существуют различия, особенно для художественной литературы общего характера с положением ⟨h⟩ и ⟨i⟩ , при этом ⟨h⟩ становится все более распространенным.
Различные диалекты языка также влияют на частоту употребления букв. Например, автор из Соединенных Штатов может создать что-то, в чем ⟨z⟩ встречается чаще, чем автор из Соединенного Королевства, пишущий на ту же тему: такие слова, как «анализировать», «извиниться» и «признать», содержат букву в американском английском, тогда как в британском английском эти же слова пишутся как «анализировать», «извиняться» и «признавать». Это сильно повлияет на частоту употребления буквы ⟨z⟩ , поскольку британские писатели редко используют ее в английском языке. [6]
Буквы «двенадцати лучших» составляют около 80% от общего использования. Буквы «восьмерки лучших» составляют около 65% от общего использования. двухпараметрическая функция ранга Кочо/Бета . Частота букв как функция ранга может быть хорошо подобрана несколькими функциями ранга, причем лучше всего подходит [7] Другая ранговая функция без регулируемого свободного параметра также достаточно хорошо соответствует распределению частот букв. [8] (та же функция использовалась для подбора частоты аминокислот в белковых последовательностях. [9] ) Шпион, использующий шифр VIC или какой-либо другой шифр, основанный на шахматной доске, обычно использует мнемонику, например, «грех ошибиться» (отбрасывая вторую букву «r»). [10] [11] или «в один сэр» [12] запомнить восемь лучших персонажей.
Относительные частоты букв в английском языке
[ редактировать ]
Есть три способа подсчета частоты букв, которые приводят к совершенно разным диаграммам для распространенных букв. Первый метод, использованный в таблице ниже, заключается в подсчете частоты букв в леммах словаря. Лемма — это слово в его канонической форме. Второй метод заключается в включении в подсчет всех вариантов слов, таких как «абстрактный», «абстрагируемый» и «абстрагируемый», а не только леммы «абстрактный». Этот второй метод приводит к тому, что буквы типа ⟨s⟩ появляются гораздо чаще, например, при подсчете букв в списках наиболее часто используемых английских слов в Интернете. ⟨s⟩ особенно часто встречается в изменяемых словах (формах, не содержащих леммы), поскольку он добавляется для образования глаголов множественного числа и третьего лица единственного числа настоящего времени. Последний метод состоит в подсчете букв на основе частоты их использования в реальных текстах, в результате чего определенные комбинации букв, такие как ⟨th⟩, становятся более распространенными из-за частого использования общих слов, таких как «то», «то», «оба», «это» и т. д. Подобные абсолютные показатели частоты использования используются при создании раскладок клавиатуры или частоте букв в старомодных печатных машинах.
Анализ статей в Кратком Оксфордском словаре без учета частоты использования слов дает порядок «EARIOTNSLCUDPMHGBFYWKVXZJQ». [13]
Приведенная ниже таблица частотности букв взята с веб-сайта Павла Мички, на котором цитируется «Криптологическая математика» Роберта Леванда . [14]
По словам Леванда, буквы расположены в порядке от наиболее распространенного к наименее распространенному: etaoinshrdlcumwfgypbvkjxqz . Порядок Леванда немного отличается от других, например, от проекта Math Explorer Корнелльского университета, который создал таблицу после измерения 40 000 слов. [15]
В английском языке пробел встречается почти в два раза чаще, чем верхняя буква ( ⟨e⟩ ). [16] а неалфавитные символы (цифры, знаки препинания и т. д.) вместе занимают четвертую позицию (уже включая пробел) между ⟨t⟩ и ⟨a⟩ . [17]
Относительная частота первых букв слова в английском языке
[ редактировать ]| Письмо | Относительная частота появления первой буквы английского слова [ нужна ссылка ] | |||
|---|---|---|---|---|
| Тексты | Словари | |||
| А | 11.7% | 5.7% | ||
| Б | 4.4% | 6% | ||
| С | 5.2% | 9.4% | ||
| Д | 3.2% | 6.1% | ||
| И | 2.8% | 3.9% | ||
| Ф | 4% | 4.1% | ||
| Г | 1.6% | 3.3% | ||
| ЧАС | 4.2% | 3.7% | ||
| я | 7.3% | 3.9% | ||
| Дж | 0.51% | 1.1% | ||
| К | 0.86% | 1% | ||
| л | 2.4% | 3.1% | ||
| М | 3.8% | 5.6% | ||
| Н | 2.3% | 2.2% | ||
| ТО | 7.6% | 2.5% | ||
| П | 4.3% | 7.7% | ||
| вопрос | 0.22% | 0.49% | ||
| Р | 2.8% | 6% | ||
| С | 6.7% | 11% | ||
| Т | 16% | 5% | ||
| В | 1.2% | 2.9% | ||
| V | 0.82% | 1.5% | ||
| В | 5.5% | 2.7% | ||
| Х | 0.045% | 0.05% | ||
| И | 0.76% | 0.36% | ||
| С | 0.045% | 0.24% | ||
Частота первых букв слов или имен полезна при предварительном назначении места в физических файлах и индексах. [18] Учитывая 26 ящиков картотечного шкафа , а не соотношение 1:1 одного ящика к одной букве алфавита, часто бывает полезно использовать более равночастотный буквенный код, назначая одному и тому же ящику несколько низкочастотных букв (часто один ящик помечен как VWXYZ) и разделить наиболее часто встречающиеся начальные буквы ( ⟨s, a, c⟩ ) на несколько ящиков (часто 6 ящиков Aa-An, Ao-Az, Ca-Cj, Ck-Cz, Sa -Си, Сж-Сз). Эта же система используется в некоторых многотомных произведениях, например в некоторых энциклопедиях . Числа резцов — еще одно сопоставление имен с более равночастотным кодом — используются в некоторых библиотеках.
Как общее распределение букв, так и распределение букв в начале слова примерно соответствуют распределению Ципфа и еще более точно соответствуют распределению Юла . [19]
Часто распределение частот первой цифры в каждом элементе данных значительно отличается от общей частоты всех цифр в наборе числовых данных — это наблюдение известно как закон Бенфорда .
Анализ Питером Норвигом слов, которые встречаются 100 000 или более раз в данных Google Книги , расшифрованных с помощью оптического распознавания символов (OCR), среди прочего, определил частоту первых букв английских слов. [20]
Относительные частоты букв в других языках
[ редактировать ]| Письмо | Английский | Французский [21] | немецкий [22] | испанский [23] | португальский [24] | итальянский [25] | турецкий [26] | Шведский [27] | Польский [28] | Голландский [29] | датский [30] | исландский [31] | финский [32] | чешский | венгерский [33] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| а | 8.167% | 7.636% | 6.516% | 11.525% | 14.634% | 11.745% | 11.920% | 9.383% | 8.965% | 7.49% | 6.025% | 10.110% | 12.217% | 8.421% | 8.89% |
| б | 1.492% | 0.901% | 1.886% | 2.215% | 1.043% | 0.927% | 2.844% | 1.535% | 1.482% | 1.58% | 2.000% | 1.043% | 0.281% | 0.822% | 1.94% |
| с | 2.782% | 3.260% | 2.732% | 4.019% | 3.882% | 4.501% | 0.963% | 1.486% | 3.988% | 1.24% | 0.565% | ~0% | 0.281% | 0.740% | 0.646% |
| д | 4.253% | 3.669% | 5.076% | 5.010% | 4.992% | 3.736% | 4.706% | 4.702% | 3.293% | 5.93% | 5.858% | 1.575% | 1.043% | 3.475% | 1.92% |
| и | 12.702% | 14.715% | 16.396% | 12.181% | 12.570% | 11.792% | 8.912% | 10.149% | 7.921% | 18.91% | 15.453% | 6.418% | 7.968% | 7.562% | 11.6% |
| ж | 2.228% | 1.066% | 1.656% | 0.692% | 1.023% | 1.153% | 0.461% | 2.027% | 0.312% | 0.81% | 2.406% | 3.013% | 0.194% | 0.084% | 0.548% |
| г | 2.015% | 0.866% | 3.009% | 1.768% | 1.303% | 1.644% | 1.253% | 2.862% | 1.377% | 3.40% | 4.077% | 4.241% | 0.392% | 0.092% | 3.79% |
| час | 6.094% | 0.937% | 4.577% | 1.973% | 1.281% | 0.136% | 1.212% | 2.090% | 1.072% | 2.38% | 1.621% | 1.871% | 1.851% | 1.356% | 1.26% |
| я | 6.966% | 7.529% | 6.550% | 6.247% | 6.186% | 10.143% | 8.600%* | 5.817% | 8.286% | 6.50% | 6.000% | 7.578% | 10.817% | 6.073% | 4.25% |
| дж | 0.253% | 0.813% | 0.268% | 2.493% | 0.879% | 0.011% | 0.034% | 0.614% | 2.343% | 1.46% | 0.730% | 1.144% | 2.042% | 1.433% | 1.48% |
| к | 1.772% | 0.074% | 1.417% | 0.026% | 0.015% | 0.009% | 4.683% | 3.140% | 3.411% | 2.25% | 3.395% | 3.314% | 4.973% | 2.894% | 4.85% |
| л | 4.025% | 5.456% | 3.437% | 4.967% | 2.779% | 6.510% | 5.922% | 5.275% | 2.136% | 3.57% | 5.229% | 4.532% | 5.761% | 3.802% | 6.71% |
| м | 2.406% | 2.968% | 2.534% | 3.157% | 4.738% | 2.512% | 3.752% | 3.471% | 2.911% | 2.21% | 3.237% | 4.041% | 3.202% | 2.446% | 3.82% |
| н | 6.749% | 7.095% | 9.776% | 6.712% | 4.446% | 6.883% | 7.487% | 8.542% | 5.600% | 10.03% | 7.240% | 7.711% | 8.826% | 6.468% | 6.82% |
| тот | 7.507% | 5.796% | 2.594% | 8.683% | 9.735% | 9.832% | 2.476% | 4.482% | 7.590% | 6.06% | 4.636% | 2.166% | 5.614% | 6.695% | 3.65% |
| п | 1.929% | 2.521% | 0.670% | 2.510% | 2.523% | 3.056% | 0.886% | 1.839% | 3.101% | 1.57% | 1.756% | 0.789% | 1.842% | 1.906% | 0.48% |
| д | 0.095% | 1.362% | 0.018% | 0.877% | 1.204% | 0.505% | 0 | 0.020% | 0.003% | 0.009% | 0.007% | 0 | 0.013% | 0.001% | ~0% |
| р | 5.987% | 6.693% | 7.003% | 6.871% | 6.530% | 6.367% | 6.722% | 8.431% | 4.571% | 6.41% | 8.956% | 8.581% | 2.872% | 4.799% | 2.65% |
| с | 6.327% | 7.948% | 7.270% | 7.977% | 6.805% | 4.981% | 3.014% | 6.590% | 4.263% | 3.73% | 5.805% | 5.630% | 7.862% | 5.212% | 6.99% |
| т | 9.056% | 7.244% | 6.154% | 4.632% | 4.336% | 5.623% | 3.314% | 7.691% | 3.966% | 6.79% | 6.862% | 4.953% | 8.750% | 5.727% | 6.96% |
| в | 2.758% | 6.311% | 4.166% | 3.927% | 3.639% | 2.813% | 3.235% | 1.919% | 2.347% | 1.99% | 1.979% | 4.562% | 5.008% | 2.160% | 0.392% |
| v | 0.978% | 1.838% | 0.846% | 1.138% | 1.575% | 2.097% | 0.959% | 2.415% | 0.034% | 2.85% | 2.332% | 2.437% | 2.250% | 5.344% | 2.31% |
| В | 2.360% | 0.049% | 1.921% | 0.027% | 0.037% | 0.033% | 0 | 0.142% | 4.549% | 1.52% | 0.069% | 0 | 0.094% | 0.016% | ~0% |
| х | 0.250% | 0.427% | 0.034% | 0.515% | 0.453% | 0.008% | 0 | 0.159% | 0.019% | 0.036% | 0.028% | 0.046% | 0.031% | 0.027% | ~0% |
| и | 1.974% | 0.708% | 0.039% | 1.433% | 0.006% | 0.020% | 3.336% | 0.708% | 3.857% | 0.035% | 0.698% | 0.900% | 1.745% | 1.043% | 2.56% |
| С | 0.074% | 0.326% | 1.134% | 0.467% | 0.470% | 1.181% | 1.500% | 0.070% | 5.620% | 1.39% | 0.034% | 0 | 0.051% | 1.599% | 4.3% |
| имеет | ~0% [ нужна ссылка ] | 0.486% | 0 | ~0% | 0.072% | 0.635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| â | ~0% | 0.051% | 0 | 0 | 0.562% | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| на | ~0% | 0 | 0 | 0.502% | 0.118% | 0 | 0 | 0 | 0 | 0 | 0 | 1.799% | 0 | 0.867% | 3.44% |
| к | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 1.34% | 0 | 0 | 1.190% | ~0% | 0.003% | 0 | 0 |
| ä | ~0% | 0 | 0.578% | 0 | 0 | 0 | 0 | 1.80% | 0 | 0 | 0 | 0 | 3.577% | 0 | 0 |
| ã | 0 | 0 | 0 | 0 | 0.733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| а | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.021% | 0 | 0 | 0 | 0 | 0 | 0 |
| ой | ~0% [ нужна ссылка ] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.872% | 0.867% | 0 | 0 | 0 |
| œ | ~0% | 0.018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Что | ~0% | 0.085% | 0 | ~0% | 0.530% | 0 | 1.156% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 |
| Ч | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.448% | 0 | 0 | 0 | 0 | 0 | 0 |
| С | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.462% | 0 |
| д | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.015% | 0 |
| д | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.393% | 0 | 0 | 0 |
| И | ~0% [ нужна ссылка ] | 0.271% | 0 | ~0% | 0 | 0.263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| и | ~0% [ нужна ссылка ] | 1.504% | 0 | 0.433% | 0.337% | 0 | 0 | 0 | ~0% | 0 | 0 | 0.647% | 0 | 0.633% | 4.25% |
| ага | 0 | 0.218% | 0 | 0 | 0.450% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ага | ~0% [ нужна ссылка ] | 0.008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ę | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.131% | 0 | 0 | 0 | 0 | 0 | 0 |
| Э | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.222% | 0 |
| г | 0 | 0 | 0 | 0 | 0 | 0 | 1.125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| вопрос | 0 | 0.045% | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| я | 0 | 0 | 0 | 0 | 0 | (0.030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| в | 0 [ нужна ссылка ] | 0 | 0 | 0.725% | 0.132% | 0.030% | 0 | 0 | 0 | 0 | 0 | 1.570% | 0 | 1.643% | 0.47% |
| я | ~0% [ нужна ссылка ] | 0.005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| я | 0 | 0 | 0 | 0 | 0 | 0 | 5.114%* | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| л | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.746% | 0 | 0 | 0 | 0 | 0 | 0 |
| л | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0 |
| н | ~0% [ нужна ссылка ] | 0 | 0 | 0.311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| является | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.185% | 0 | 0 | 0 | 0 | 0 | 0 |
| нет | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.007% | 0 |
| ò | 0 | 0 | 0 | 0 | 0 | 0.002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| он | ~0% | 0 | 0.443% | 0 | 0 | 0 | 0.777% | 1.31% | 0 | 0 | 0 | 0.777% | 0.444% | 0 | 0.784% |
| Зонтик | ~0% | 0.023% | 0 | 0 | 0.635% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| от | 0 [ нужна ссылка ] | 0 | 0 | 0.827% | 0.296% | ~0% | 0 | 0 | 0.823% | 0 | 0 | 0.994% | 0 | 0.024% | 0.597% |
| он | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.823% |
| он | 0 [ нужна ссылка ] | 0 | 0 | 0 | 0.040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.939% | 0 | 0 | 0 | 0 |
| р | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.380% | 0 |
| ш | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ш | 0 | 0 | 0 | 0 | 0 | 0 | 1.780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| поздно | 0 [ нужна ссылка ] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.683% | 0 | 0 | 0 | 0 | 0 | 0 |
| с | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0.688% | 0 |
| SS | 0 | 0 | 0.307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| й | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.006% | 0 |
| то есть | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.455% | 0 | 0 | 0 |
| ты | 0 | 0.058% | 0 | 0 | 0 | (0.166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ты | 0 [ нужна ссылка ] | 0 | 0 | 0.168% | 0.207% | 0.166% | 0 | 0 | 0 | 0 | 0 | 0.613% | 0 | 0.045% | 0.098% |
| и | ~0% | 0.060% | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ты | ~0% | 0 | 0.995% | 0.012% | 0.026% | 0 | 1.854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.617% |
| фу | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.117% |
| в | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.204% | 0 |
| идея | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.228% | 0 | 0.995% | 0 |
| С | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.061% | 0 | 0 | 0 | 0 | 0 | 0 |
| г | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.885% | 0 | 0 | 0 | 0 | 0 | 0 |
| час | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0.721% | 0 |
*См. İ и I без точки .
На рисунке ниже показано распределение частот 26 наиболее распространенных латинских букв в некоторых языках. Во всех этих языках используется одинаковый алфавит, состоящий из более чем 25 символов.
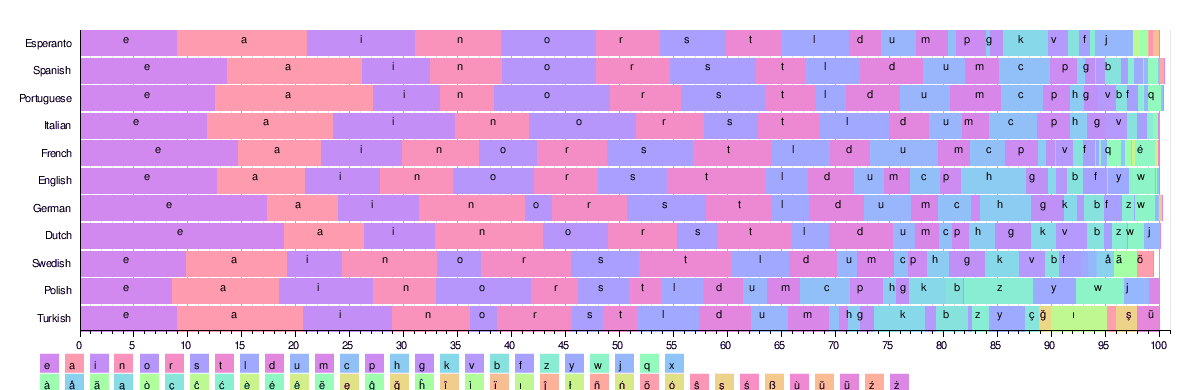
На основании этих таблиц эквивалент ' etaoin shrdlu ' для каждого языка выглядит следующим образом:
- Французский: «esaitn ruoldc»; (Индоевропейский: курсив; традиционно используется слово «эсартинулоп», отчасти из-за простоты произношения. [34] )
- Испанский: 'eaosrn idltcm'; (Индоевропейский: курсив)
- Португальский: 'aeosri dmntcu' (индоевропейский: курсив)
- Итальянский: «eaionl rtscdu»; (Индоевропейский: курсив)
- Немецкий: «ensria tdhulg»; (Индоевропейский: германский)
- Шведский: 'eanrts ildomk'; (Индоевропейский: германский)
- Турецкий: «aeinrl ıdkmyt»; (тюркский)
- Голландский: «enatir odslgv»; (Индоевропейский: германский) [29]
- Польский: «aioezn rwstcy»; (Индоевропейский: балто-славянский)
- Датский: «erntai dslogk»; (Индоевропейский: германский)
- Исландский: «arnies tulðgm»; (Индоевропейский: германский)
- Финский: «aintes loukäm»; (Уральский: Финник)
- Чешский: «aeonit vsrldk»; (Индоевропейский: балто-славянский)
- Венгерский: «eatlsn kizroá»; (Уральский: финно-угорский)
См. также
[ редактировать ]- Частота арабских букв
- Частота английских слов
- Эффект частоты букв
- Липограмма
- РСТЛНЕ ( Колесо Фортуны )
Пояснительные примечания
[ редактировать ]- ^ Американская азбука Морзе была разработана в 1830-х годах Альфредом Вейлом на основе частоты букв английского языка для кодирования наиболее частых букв самыми короткими символами. Некоторая эффективность была потеряна в используемой сейчас реформированной версии: международном коде Морзе.
Ссылки
[ редактировать ]- ^ Мичка, Павел. «Частота букв (английский)» . Алгоритмы.нет . Архивировано из оригинала 4 марта 2021 года . Проверено 14 июня 2022 г.
Источник — Леланд, Роберт. Криптологическая математика. [sl]: Математическая ассоциация Америки, 2000. 199 стр. ISBN 0-88385-719-7
- ^ Гиннесс, Гарри. «Лучшие стартовые слова для победы в Wordle» . Проводной . ISSN 1059-1028 . Проверено 12 февраля 2022 г.
- ^ По, Эдгар Аллан. «Сочинения Эдгара Аллана По в пяти томах» . Проект Гутенберг.
- ^ Зим, Герберт Спенсер (1961). Коды и секретное письмо: санкционированные сокращения . Учебные книжные услуги. OCLC 317853773 .
- ^ Морено, Марша Линн (весна 2005 г.). «Частотный анализ в свете языковых инноваций» (PDF) . Математика. Калифорнийский университет – Сан-Диего . Проверено 19 февраля 2015 г.
- ^ «Британское и американское правописание — Оксфордские словари» . Оксфордские словари — английский язык . Архивировано из оригинала 28 декабря 2011 года . Проверено 18 апреля 2018 г.
- ^ Ли, Вэньтянь; Мирамонтес, Педро (2011). «Фиттинг оценил распределение частот английских и испанских букв в речах президентов США и Мексики». Журнал количественной лингвистики . 18 (4): 359. arXiv : 1103.2950 . дои : 10.1080/09296174.2011.608606 . S2CID 1716455 .
- ^ Гусейн-Заде, С.М. (1988). «Частотное распределение букв в русском языке». Пробл. Передачи Инф . 24 (4): 102–107.
- ^ Гамов, Георгий; Икас, Мартинас (1955). «Статистическая корреляция состава белка и рибонуклеиновой кислоты» . Учеб. Натл. акад. Наука . 41 (12): 1011–1019. Бибкод : 1955ПНАС...41.1011Г . дои : 10.1073/pnas.41.12.1011 . ПМК 528190 . ПМИД 16589789 .
- ^ Бауэр, Фридрих Л. (2006). Расшифрованные секреты: Методы и принципы криптологии . Спрингер. п. 57. ИСБН 9783540481218 – через Google Книги.
- ^ Гебель, Грег (2009). Расцвет полевых шифров: смешанные шифры шахматной доски .
- ^ Рейменанц, Дирк. «Одноразовый блокнот» .
- ^ «Какова частота букв алфавита в английском языке?» . Оксфордский словарь . Издательство Оксфордского университета. Архивировано из оригинала 24 декабря 2011 года . Проверено 29 декабря 2012 г.
- ^ Мичка, Павел. «Частота букв (английский)» . Алгоритмы.нет.
- ^ «Частота английских букв (на основе выборки из 40 000 слов)» . Корнелл.edu . Проверено 24 января 2021 г.
- ^ «Статистическое распределение английского текста» . data-compression.com . Архивировано из оригинала 18 сентября 2017 г.
- ^ Ли, Э. Стюарт. «Очерки компьютерной безопасности» (PDF) . Компьютерная лаборатория Кембриджского университета. п. 181.
- ^ Олман, Герберт Марвин (1959). Частота букв предметного слова с применением к наложенному кодированию . Материалы Международной конференции по научной информации. дои : 10.17226/10866 . ISBN 978-0-309-57421-1 .
- ^ Панде, Хемлата; Дхами, Х.С. «Математическое моделирование появления букв и инициалов слов в текстах языка хинди» (PDF) . ДЖТЛ . 16 .
- ^ «Подсчет частоты английских букв: возвращение к Майзнеру или ETAOIN SRLLDCU» . norvig.com . Проверено 18 апреля 2018 г.
- ^ «Корпус Томаса Темпе» . Архивировано из оригинала 30 сентября 2007 года . Проверено 15 июня 2007 г.
- ^ Бойтельспехер, Альбрехт (2005). Криптология (7-е изд.). Висбаден: Просмотрег. стр. 10. ISBN 3-8348-0014-7 .
- ^ Пратт, Флетчер (1942). Секретно и срочно: История кодов и шифров . Гарден-Сити, Нью-Йорк: Книги Голубой ленты. стр. 254–5. OCLC 795065 .
- ^ «Частота встречаемости букв в португальском языке» . Архивировано из оригинала 3 августа 2009 года . Проверено 16 июня 2009 г.
- ^ Сингх, Саймон; Галли, Стефано (1999). Коды и секреты (на итальянском языке). Милан: Риццоли. ISBN 978-8-817-86213-4 . OCLC 535461359 .
- ^ Серенгиль, Сефик Илькин; Акин, Мурат (20–22 февраля 2011 г.). Атака на турецкие тексты, зашифрованные гомофонным шифром (PDF) . Материалы 10-й Международной конференции WSEAS по электронике, аппаратному обеспечению, беспроводной и оптической связи. Кембридж, Великобритания. стр. 123–126.
- ^ «Практическая криптография» . Проверено 30 октября 2013 г.
- ^ «Частота букв в польских текстах — Языковая клиника PWN» .
- ^ Перейти обратно: а б «Частота букв» . Общество Наш язык . Проверено 17 мая 2009 г.
- ^ «Частота датских букв» . Практическая криптография . Проверено 24 октября 2013 г.
- ^ «Частота исландских букв» . Практическая криптография . Проверено 24 октября 2013 г.
- ^ «Частота финских букв» . Практическая криптография . Проверено 24 октября 2013 г.
- ^ «Частоты венгерских символов» . Вольфрама Альфа -сайт . Проверено 25 марта 2023 г.
- ^ Перек, Жорж; Алфавиты ; Издания Galilée, 1976 г.
Внешние ссылки
[ редактировать ]- Леванд, Роберт Эдвард. «Криптографическая математика» . Pages.central.edu. Архивировано из оригинала 2 апреля 2007 г.
- «Некоторые примеры частотности букв в некоторых распространенных языках» . www.bckelk.org.uk.
- «Визуализация тепловой карты JavaScript, показывающая частоту букв в тексте на разных раскладках клавиатуры» . www.patrick-wied.at.
- Норвиг, Питер. «Обновленная версия работы Майзнера с использованием набора данных Ngrams книг Google» . norvig.com.
- Частота букв —simia.net
Полезные таблицы
[ редактировать ]Полезные таблицы частотности отдельных букв, диграмм, триграмм, тетраграмм и пентаграмм на основе 20 000 слов, которые учитывают комбинации длины слова и положения букв для слов длиной от 3 до 7 букв:
- Майзнер, М.С.; Тресселт, Мэн; Волин, БР (1965). «Таблицы частотности отдельных букв и диграмм для различных комбинаций длины слова и позиции букв». Психономические приложения к монографии . 1 (2): 13–32. OCLC 639975358 .
- Майзнер, М.С.; Тресселт, Мэн; Волин, БР (1965). «Таблицы частотности триграмм для различных комбинаций длины слова и позиции букв». Психономические приложения к монографии . 1 (3): 33–78.
- Майзнер, М.С.; Тресселт, Мэн; Волин, БР (1965). «Таблицы частотности тетраграмм для различных комбинаций длины слова и позиции букв». Психономические приложения к монографии . 1 (4): 79–143.
- Майзнер, М.С.; Тресселт, Мэн; Волин, БР (1965). «Таблицы частотности пентаграмм для различных комбинаций длины слова и положения букв». Психономические приложения к монографии . 1 (5): 144–190.