Алгоритм Смита – Уотермана
 Анимированный пример, показывающий шаги постепенно. см. здесь . Подробные инструкции | |
| Сорт | Выравнивание последовательности |
|---|---|
| Худшая производительность | |
| Наихудшая пространственная сложность | |

Алгоритм Смита-Уотермана выполняет локальное выравнивание последовательностей ; то есть для определения сходных областей между двумя цепочками последовательностей нуклеиновых кислот или белковых последовательностей . Вместо просмотра всей последовательности алгоритм Смита-Уотермана сравнивает сегменты всех возможных длин и оптимизирует меру сходства .
Алгоритм был впервые предложен Темплом Ф. Смитом и Майклом С. Уотерманом в 1981 году. [ 1 ] Как и алгоритм Нидлмана-Вунша , разновидностью которого он является, Смит-Уотерман является алгоритмом динамического программирования . По существу, он обладает тем желательным свойством, что гарантированно находит оптимальное локальное выравнивание относительно используемой системы оценок (которая включает в себя матрицу замещения и схему оценки пробелов ). Основное отличие от алгоритма Нидлмана – Вунша заключается в том, что ячейки матрицы отрицательных оценок устанавливаются в ноль. Процедура обратной трассировки начинается с ячейки матрицы с наивысшей оценкой и продолжается до тех пор, пока не встретится ячейка с нулевой оценкой, что дает локальное выравнивание с наивысшей оценкой. Из-за своей кубической временной сложности его часто невозможно практически применить к крупномасштабным задачам, и его заменяют более эффективными в вычислительном отношении альтернативами, такими как (Gotoh, 1982), [ 2 ] ( Альтшул и Эриксон, 1986), [ 3 ] и (Майерс и Миллер, 1988). [ 4 ]
История
[ редактировать ]В 1970 году Сол Б. Нидлман и Кристиан Д. Вунш предложили эвристический алгоритм гомологии для выравнивания последовательностей, также называемый алгоритмом Нидлмана-Вунша. [ 5 ] Это глобальный алгоритм выравнивания, который требует шаги расчета ( и — длины двух выравниваемых последовательностей). Он использует итеративный расчет матрицы с целью отображения глобального выравнивания. В следующее десятилетие Санкофф, [ 6 ] Райхерт, [ 7 ] Бейер [ 8 ] и другие сформулировали альтернативные эвристические алгоритмы для анализа последовательностей генов. Селлерс представил систему измерения расстояний последовательности. [ 9 ] В 1976 году Уотерман и др. добавили понятие пробелов в исходную систему измерения. [ 10 ] В 1981 году Смит и Уотерман опубликовали свой алгоритм Смита-Уотермана для расчета локального выравнивания.


Алгоритм Смита-Уотермана довольно требователен ко времени: для выравнивания двух последовательностей длин и , требуется время. Гото [ 2 ] и Альтшуль [ 3 ] оптимизировал алгоритм, чтобы шаги. Пространственная сложность была оптимизирована Майерсом и Миллером. [ 4 ] от к (линейный), где — длина более короткой последовательности для случая, когда требуется только одно из многих возможных оптимальных выравниваний. Чоудхури, Ле и Рамачандран [ 11 ] позже оптимизировал производительность кэша алгоритма, сохраняя при этом линейное использование пространства в зависимости от общей длины входных последовательностей.


Мотивация
[ редактировать ]В последние годы геномные проекты, проведенные на различных организмах, позволили получить огромные объемы данных о последовательностях генов и белков, что требует компьютерного анализа. Выравнивание последовательностей показывает отношения между генами или между белками, что приводит к лучшему пониманию их гомологии и функциональности. Выравнивание последовательностей также может выявить консервативные домены и мотивы .
Одной из причин локального выравнивания является сложность получения правильного выравнивания в областях с низким сходством между отдаленно родственными биологическими последовательностями, поскольку мутации добавили слишком много «шума» в течение эволюционного времени, чтобы обеспечить значимое сравнение этих областей. Локальное выравнивание вообще избегает таких регионов и фокусируется на тех регионах, которые имеют положительный балл, т.е. тех, у которых имеется эволюционно консервативный сигнал сходства. Обязательным условием локального выравнивания является отрицательный показатель ожидания. Оценка ожидания определяется как средняя оценка, которую система оценки ( матрица замен и штрафы за пропуски ) даст для случайной последовательности.
Другая причина использования локальных выравниваний заключается в том, что существует надежная статистическая модель (разработанная Карлином и Альтшулом) для оптимальных локальных выравниваний. Выравнивание несвязанных последовательностей имеет тенденцию давать оптимальные показатели локального выравнивания, которые соответствуют распределению экстремальных значений. Это свойство позволяет программам генерировать математическое ожидание для оптимального локального выравнивания двух последовательностей, которое является мерой того, как часто две несвязанные последовательности будут обеспечивать оптимальное локальное выравнивание, оценка которого больше или равна наблюдаемой оценке. Очень низкие значения ожидания указывают на то, что две рассматриваемые последовательности могут быть гомологичными , то есть иметь общего предка.
Алгоритм
[ редактировать ]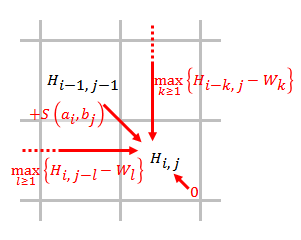
Позволять и — последовательности, подлежащие выравниванию, где и длины и соответственно.




- Определите матрицу замены и схему штрафа за пропуск.
- - Оценка сходства элементов, составляющих две последовательности.
- - Штраф за разрыв, имеющий длину
- Построить оценочную матрицу и инициализируйте его первую строку и первый столбец. Размер оценочной матрицы составляет . В матрице используется индексация, отсчитываемая от 0.
- Заполните матрицу оценок, используя приведенное ниже уравнение.
- где
- это оценка выравнивания и ,
- это оценка, если находится в конце промежутка длины ,
- это оценка, если находится в конце промежутка длины ,
- значит сходства нет и .
- Обратная связь. Начиная с наивысшего балла в матрице оценок и заканчивая ячейкой матрицы, имеющей оценку 0, обратная трассировка на основе источника каждой оценки рекурсивно для создания наилучшего локального выравнивания.














Объяснение
[ редактировать ]Алгоритм Смита-Уотермана выравнивает две последовательности путем совпадений/несоответствий (также известных как замены), вставок и удалений. И вставка, и удаление представляют собой операции, которые вводят пробелы, которые обозначены тире. Алгоритм Смита – Уотермана состоит из нескольких шагов:
- Определите матрицу замены и схему штрафа за пропуск . Матрица замен присваивает каждой паре оснований или аминокислот оценку совпадения или несовпадения. Обычно совпадения получают положительные оценки, тогда как несоответствия получают относительно более низкие оценки. Функция штрафа за пробелы определяет стоимость за открытие или расширение пробелов. Пользователям предлагается выбрать подходящую систему оценки в зависимости от целей. Кроме того, полезно попробовать различные комбинации матриц замен и штрафов за пропуски.
- Инициализируйте матрицу оценок . Размеры оценочной матрицы составляют 1+длина каждой последовательности соответственно. Всем элементам первой строки и первого столбца присваивается значение 0. Дополнительные первая строка и первый столбец позволяют выравнивать одну последовательность с другой в любой позиции, а установка их в 0 освобождает терминальный разрыв от штрафов.
- Подсчет очков . Оцените каждый элемент слева направо, сверху вниз в матрице, учитывая результаты замен (диагональные оценки) или добавления пробелов (горизонтальные и вертикальные оценки). Если ни одна из оценок не является положительной, этому элементу присваивается 0. В противном случае используется наивысшая оценка и записывается источник этой оценки.
- Трассировка . Начиная с элемента с наивысшим баллом, отслеживание рекурсивно основано на источнике каждого балла, пока не встретится 0. В этом процессе генерируются сегменты, имеющие наивысший балл сходства на основе данной системы оценки. Чтобы получить второе лучшее локальное выравнивание, примените процесс обратной трассировки, начиная со второго по величине балла за пределами трассы лучшего выравнивания.
Сравнение с алгоритмом Нидлмана – Вунша.
[ редактировать ]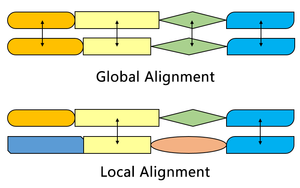
Алгоритм Смита-Уотермана находит сегменты в двух последовательностях, которые имеют сходство, а алгоритм Нидлмана-Вунша выравнивает две полные последовательности. Поэтому они служат разным целям. Оба алгоритма используют концепции матрицы замены, функции штрафа за пропуск, матрицы оценок и процесса обратной трассировки. Три основных различия:
| Алгоритм Смита – Уотермана | Алгоритм Нидлмана – Вунша | |
|---|---|---|
| Инициализация | Первая строка и первый столбец установлены на 0. | Первая строка и первый столбец подлежат штрафу за пропуск. |
| Подсчет очков | Отрицательный балл равен 0. | Оценка может быть отрицательной |
| обратная трассировка | Начните с наивысшего балла и закончите, когда встретите 0. | Начните с ячейки в правом нижнем углу матрицы и закончите в верхней левой ячейке. |
Одним из наиболее важных отличий является то, что в системе оценок алгоритма Смита-Уотермана не присваивается отрицательная оценка, что обеспечивает локальное выравнивание. Когда какой-либо элемент имеет оценку ниже нуля, это означает, что последовательности до этой позиции не имеют сходства; затем этот элемент будет установлен на ноль, чтобы исключить влияние предыдущего выравнивания. Таким образом, впоследствии расчет может продолжить поиск выравнивания в любом положении.
Исходная матрица оценок алгоритма Смита – Уотермана позволяет сопоставить любой сегмент одной последовательности с произвольной позицией в другой последовательности. Однако в алгоритме Нидлмана-Вунша также необходимо учитывать штраф за конечный разрыв, чтобы выровнять полные последовательности.
Матрица замены
[ редактировать ]Каждой замене основания или аминокислотной замены присваивается балл. Как правило, совпадениям присваиваются положительные оценки, а несоответствиям — относительно более низкие оценки. Возьмем в качестве примера последовательность ДНК. Если совпадения получают +1, несовпадения получают -1, то матрица замены имеет вид:
| А | Г | С | Т | |
|---|---|---|---|---|
| А | 1 | -1 | -1 | -1 |
| Г | -1 | 1 | -1 | -1 |
| С | -1 | -1 | 1 | -1 |
| Т | -1 | -1 | -1 | 1 |
Эту матрицу замены можно описать так:

Различные замены оснований или аминокислотные замены могут иметь разные оценки. Матрица замещения аминокислот обычно сложнее, чем у оснований. См. ПАМ , БЛОСУМ .
Штраф за разрыв
[ редактировать ]Штраф за пробел обозначает баллы за вставку или удаление. Простая стратегия штрафа за пробел заключается в использовании фиксированного счета за каждый пробел. Однако в биологии баллы следует подсчитывать по-другому по практическим соображениям. С одной стороны, частичное сходство между двумя последовательностями — обычное явление; с другой стороны, событие мутации одного гена может привести к появлению одного длинного разрыва. Таким образом, связанные гэпы, образующие длинный гэп, обычно более предпочтительны, чем несколько разрозненных коротких гэпов. Чтобы принять во внимание эту разницу, в систему подсчета очков были добавлены концепции открытия и расширения пробелов. Оценка открытия гэпа обычно выше, чем оценка расширения гэпа. Например, параметры по умолчанию в EMBOSS Water : открытие гэпа = 10, расширение гэпа = 0,5.
Здесь мы обсуждаем две распространенные стратегии штрафа за пробелы. см. в разделе Штраф за разрыв Дополнительные стратегии . Позволять — функция штрафа за разрыв для разрыва длиной :
Линейный
[ редактировать ]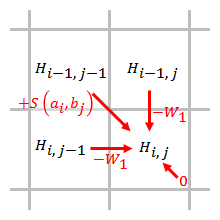
Штраф за линейный разрыв имеет одинаковые баллы за открытие и расширение разрыва:
,

где стоимость одного разрыва.

Штраф за пробел прямо пропорционален длине пробела. Когда используется штраф за линейный зазор, алгоритм Смита – Уотермана можно упростить до:

Упрощенный алгоритм использует шаги. Когда элемент оценивается, необходимо учитывать только штрафы за пропуски от элементов, которые непосредственно примыкают к этому элементу.
Аффинный
[ редактировать ]Штраф за аффинный гэп учитывает открытие и расширение гэпа отдельно:
,

где - штраф за открытие гэпа, и – это штраф за расширение разрыва. Например, штраф за разрыв длиной 2 равен .



В оригинальной статье об алгоритме Смита – Уотермана использовался произвольный штраф за пропуск. Он использует шагов, поэтому довольно требовательна ко времени. Гото оптимизировал шаги по штрафу за аффинный разрыв, чтобы , [ 2 ] но оптимизированный алгоритм пытается найти только одно оптимальное выравнивание, и его обнаружение не гарантируется. [ 3 ] Альтшул модифицировал алгоритм Гото, чтобы найти все оптимальные выравнивания, сохранив при этом вычислительную сложность. [ 3 ] Позже Майерс и Миллер отметили, что алгоритм Гото и Альтшуля можно дополнительно модифицировать на основе метода, опубликованного Хиршбергом в 1975 году. [ 12 ] и применил этот метод. [ 4 ] Алгоритм Майерса и Миллера может выравнивать две последовательности, используя пространство, с длина более короткой последовательности. Чоудхури, Ле и Рамачандран [ 11 ] позже показал, как эффективно использовать кэш алгоритма Гото в линейном пространстве, используя другую рекурсивную стратегию «разделяй и властвуй», чем та, которую использовал Хиршберг. Полученный алгоритм на практике работает быстрее, чем алгоритм Майерса и Миллера, благодаря превосходной производительности кэша. [ 11 ]

Пример штрафа за пробел
[ редактировать ]Проведите выравнивание последовательностей TACGGGCCCGCTAC и TAGCCTATCGGTCA в качестве примера. При использовании функции штрафа за линейный пробел результат равен (Выравнивание выполняется с помощью EMBOSS Water. Матрица замещения заполнена ДНК (оценка сходства: +5 для совпадающих символов, в противном случае -4). Открытие и расширение пробела составляют 0,0 и 1,0 соответственно):
TACGGGCCCGCTA-C TA---G-CC-CTATC
При использовании штрафа за аффинный гэп результат будет следующим (открытие и расширение гэпа равны 5,0 и 1,0 соответственно):
TACGGGCCCGCTA TA---GCC--CTA
Этот пример показывает, что штраф за аффинный пробел может помочь избежать разбросанных небольших пробелов.
Матрица оценок
[ редактировать ]Функция оценочной матрицы заключается в проведении сравнений один к одному между всеми компонентами в двух последовательностях и записи оптимальных результатов выравнивания. Процесс оценки отражает концепцию динамического программирования. Окончательное оптимальное выравнивание находится путем итеративного расширения растущего оптимального выравнивания. Другими словами, текущее оптимальное выравнивание генерируется путем принятия решения о том, какой путь (совпадение/несовпадение или вставка пробела) дает наивысший балл по сравнению с предыдущим оптимальным выравниванием. Размер матрицы равен длине одной последовательности плюс 1 к длине другой последовательности плюс 1. Дополнительные первая строка и первый столбец служат для выравнивания одной последовательности по любым позициям в другой последовательности. И первая строка, и первый столбец имеют значение 0, поэтому конечный пробел не наказывается. Исходная матрица оценок:
| б 1 | ... | б дж | ... | б м | ||
|---|---|---|---|---|---|---|
| 0 | 0 | ... | 0 | ... | 0 | |
| 1 | 0 | |||||
| ... | ... | |||||
| а с | 0 | |||||
| ... | ... | |||||
| н | 0 |
Пример
[ редактировать ]Проведите выравнивание последовательностей ДНК ТГТТАКГГ и ГГТТГАКТА в качестве примера. Используйте следующую схему:
- Матрица замены:
- Штраф за пробел: (штраф за линейный зазор )



Инициализируйте и заполните матрицу оценок, как показано ниже. На этом рисунке показан процесс оценки первых трех элементов. Желтым цветом обозначены рассматриваемые основания. Красный цвет указывает на максимально возможный балл для оцениваемой ячейки.

Готовая оценочная матрица показана ниже слева. Синий цвет показывает наивысший балл. Элемент может получать оценку от более чем одного элемента, каждый из которых будет формировать свой путь, если этот элемент будет прослежен. В случае нескольких наивысших оценок отслеживание следует выполнять, начиная с каждого наивысшего балла. Процесс обратной трассировки показан ниже справа. Наилучшее локальное выравнивание создается в обратном направлении.
 |
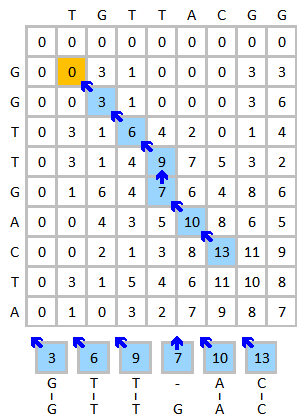 |
| Готовая матрица оценок (самый высокий балл выделен синим цветом) | Процесс обратной трассировки и результат выравнивания |
Результат выравнивания:
G T T - A C G T T G A C
Выполнение
[ редактировать ]Реализация алгоритма Смита-Уотермана, SSEARCH, доступна в FASTA пакете анализа последовательностей на сайте UVA FASTA Downloads . Эта реализация включает Altivec ускоренный код для процессоров PowerPC G4 и G5, который ускоряет сравнения в 10–20 раз с использованием модификации подхода Возняка, 1997 г. [ 13 ] и векторизация SSE2, разработанная Фарраром. [ 14 ] что делает поиск оптимальных белковых последовательностей в базе данных весьма практичным. Библиотека SSW расширяет реализацию Фаррара и позволяет возвращать информацию о выравнивании в дополнение к оптимальному показателю Смита-Уотермана. [ 15 ]
Ускоренные версии
[ редактировать ]ПЛИС
[ редактировать ]Крэй продемонстрировал ускорение алгоритма Смита-Уотермана с использованием реконфигурируемой вычислительной платформы на базе микросхем FPGA , при этом результаты показали ускорение до 28 раз по сравнению со стандартными решениями на базе микропроцессора. Другая версия алгоритма Смита – Уотермана на основе FPGA демонстрирует ускорение FPGA (Virtex-4) до 100 раз. [ 16 ] на процессоре Opteron с тактовой частотой 2,2 ГГц. [ 17 ] Системы TimeLogic DeCypher и CodeQuest также ускоряют поиск Смита-Уотермана и Framesearch с использованием карт PCIe FPGA.
Магистерская диссертация 2011 года. [ 18 ] включает анализ ускорения Смита – Уотермана на основе FPGA.
В публикации 2016 года код OpenCL, скомпилированный с помощью Xilinx SDAccel, ускоряет секвенирование генома, превосходит производительность процессора/графического процессора/Вт в 12–21 раз , и была представлена очень эффективная реализация. При использовании одной карты PCIe FPGA, оснащенной FPGA Xilinx Virtex-7 2000T, производительность на ватт была выше, чем у CPU/GPU, в 12-21 раз.
графический процессор
[ редактировать ]Ливерморская национальная лаборатория Лоуренса Министерства энергетики США (США) и Объединенный институт генома реализовали ускоренную версию поиска локального выравнивания последовательностей Смита-Уотермана с использованием графических процессоров (GPU), причем предварительные результаты показали двукратное ускорение по сравнению с программными реализациями. [ 19 ] Подобный метод уже реализован в программе Biofacet с 1997 года с таким же коэффициентом ускорения. [ 20 ]
несколько графическом процессоре реализаций алгоритма на NVIDIA на платформе CUDA C. Также доступны [ 21 ] По сравнению с наиболее известной реализацией ЦП (с использованием инструкций SIMD в архитектуре x86), проведенной Farrar, тесты производительности этого решения с использованием одной карты NVidia GeForce 8800 GTX показывают небольшое увеличение производительности для меньших последовательностей, но небольшое снижение производительность для более крупных. Однако те же тесты, проведенные на двух картах NVidia GeForce 8800 GTX , почти в два раза быстрее, чем реализация Farrar для всех протестированных размеров последовательности.
Теперь доступна новая реализация программного обеспечения GPU CUDA, которая работает быстрее, чем предыдущие версии, а также снимает ограничения на длину запросов. См. CUDASW++ .
Сообщалось об одиннадцати различных реализациях ПО на CUDA, три из которых сообщают об ускорении в 30 раз. [ 22 ]
Наконец, другие реализации Смита-Уотермана с графическим ускорением можно найти в NVIDIA Parabricks , пакете программного обеспечения NVIDIA для анализа генома. [ 23 ] .
SIMD
[ редактировать ]В 2000 году быстрая реализация алгоритма Смита-Уотермана с использованием технологии одной инструкции и нескольких данных ( SIMD ), доступной в процессорах Intel Pentium MMX и аналогичной технологии, была описана в публикации Рогнеса и Сиберга. [ 24 ] В отличие от подхода Возняка (1997), новая реализация была основана на векторах, параллельных последовательности запроса, а не на диагональных векторах. Компания Sencel Bioinformatics подала заявку на патент, охватывающий этот подход. Sencel занимается дальнейшей разработкой программного обеспечения и бесплатно предоставляет исполняемые файлы для академического использования.
Теперь доступна векторизация алгоритма SSE2 (Фаррар, 2007), обеспечивающая ускорение в 8–16 раз на процессорах Intel/AMD с расширениями SSE2. [ 14 ] При работе на процессоре Intel с использованием микроархитектуры Core реализация SSE2 достигает 20-кратного увеличения. Реализация SSE2 от Farrar доступна как программа SSEARCH в пакете сравнения последовательностей FASTA . SSEARCH включен в Европейского института биоинформатики набор программ поиска сходства .
, датская биоинформатическая компания CLC bio добилась ускорения почти в 200 раз по сравнению со стандартными программными реализациями с помощью SSE2 на процессоре Intel Core 2 Duo с частотой 2,17 ГГц Согласно общедоступному официальному документу .
Ускоренная версия алгоритма Смита-Уотермана на на базе Intel и Advanced Micro Devices (AMD) серверах Linux поддерживается пакетом GenCore 6 , предлагаемым Biocceleration . Тесты производительности этого программного пакета показывают ускорение до 10 раз по сравнению со стандартной программной реализацией на том же процессоре.
единственная компания в области биоинформатики, предлагающая решения SSE и FPGA для ускорения работы Смита-Уотермана, В настоящее время CLC bio, добилась ускорения более чем в 110 раз по сравнению со стандартными программными реализациями с помощью CLC Bioinformatics Cube . [ нужна ссылка ]
Самую быструю реализацию алгоритма на процессорах с SSSE3 можно найти в программном обеспечении SWIPE (Rognes, 2011), [ 25 ] который доступен по лицензии GNU Affero General Public License . Параллельно это программное обеспечение сравнивает остатки из шестнадцати различных последовательностей базы данных с одним остатком запроса. Используя последовательность запросов из 375 остатков, скорость 106 миллиардов обновлений ячеек в секунду (GCUPS) была достигнута на двойной Intel Xeon шестиядерной процессорной системе он быстрее, чем BLAST X5650, что более чем в шесть раз быстрее, чем программное обеспечение, основанное на «полосатом» подходе Фаррара. При использовании матрицы BLOSUM50 .
Реализация Смита-Уотермана под названием «диагональ » на C и C++ использует наборы инструкций SIMD ( SSE4.1 для платформы x86 и AltiVec для платформы PowerPC). Он выпущен под лицензией MIT с открытым исходным кодом .
Механизм сотовой широкополосной связи
[ редактировать ]В 2008 году Фаррар [ 26 ] описал порт Полосатого Смита-Уотермана. [ 14 ] к Cell Broadband Engine и сообщил о скорости 32 и 12 GCUPS на блейд-сервере IBM QS20 и Sony PlayStation 3 соответственно.
Ограничения
[ редактировать ]Быстрое расширение генетических данных бросает вызов скорости современных алгоритмов выравнивания последовательностей ДНК. Насущные потребности в эффективном и точном методе обнаружения вариантов ДНК требуют инновационных подходов к параллельной обработке в реальном времени.
См. также
[ редактировать ]- Биоинформатика
- Выравнивание последовательности
- Последовательный майнинг
- Алгоритм Нидлмана – Вунша
- Расстояние Левенштейна
- ВЗРЫВ
- ГОСТ
Ссылки
[ редактировать ]- ^ Смит, Темпл Ф. и Уотерман, Майкл С. (1981). «Идентификация общих молекулярных последовательностей» (PDF) . Журнал молекулярной биологии . 147 (1): 195–197. CiteSeerX 10.1.1.63.2897 . дои : 10.1016/0022-2836(81)90087-5 . ПМИД 7265238 .
- ^ Перейти обратно: а б с Осаму Гото (1982). «Улучшенный алгоритм сопоставления биологических последовательностей». Журнал молекулярной биологии . 162 (3): 705–708. CiteSeerX 10.1.1.204.203 . дои : 10.1016/0022-2836(82)90398-9 . ПМИД 7166760 .
- ^ Перейти обратно: а б с д Стивен Ф. Альтшул и Брюс В. Эриксон (1986). «Оптимальное выравнивание последовательностей с использованием затрат на аффинные разрывы». Бюллетень математической биологии . 48 (5–6): 603–616. дои : 10.1007/BF02462326 . ПМИД 3580642 . S2CID 189889143 .
- ^ Перейти обратно: а б с Миллер, Уэбб; Майерс, Юджин (1988). «Оптимальные выравнивания в линейном пространстве». Биоинформатика . 4 (1): 11–17. CiteSeerX 10.1.1.107.6989 . дои : 10.1093/биоинформатика/4.1.11 . ПМИД 3382986 .
- ^ Сол Б. Нидлман; Кристиан Д. Вунш (1970). «Общий метод, применимый для поиска сходства в аминокислотной последовательности двух белков». Журнал молекулярной биологии . 48 (3): 443–453. дои : 10.1016/0022-2836(70)90057-4 . ПМИД 5420325 .
- ^ Санкофф Д. (1972). «Сопоставление последовательностей при ограничениях на удаление/вставку» . Труды Национальной академии наук Соединенных Штатов Америки . 69 (1): 4–6. Бибкод : 1972PNAS...69....4S . дои : 10.1073/pnas.69.1.4 . ПМЦ 427531 . ПМИД 4500555 .
- ^ Томас А. Райхерт; Дональд Н. Коэн; Эндрю К.К. Вонг (1973). «Применение теории информации к генетическим мутациям и сопоставлению полипептидных последовательностей». Журнал теоретической биологии . 42 (2): 245–261. Бибкод : 1973JThBi..42..245R . дои : 10.1016/0022-5193(73)90088-X . ПМИД 4762954 .
- ^ Уильям А. Бейер, Майрон Л. Штайн, Темпл Ф. Смит и Станислав М. Улам (1974). «Метрика молекулярной последовательности и эволюционные деревья». Математические биологические науки . 19 (1–2): 9–25. дои : 10.1016/0025-5564(74)90028-5 .
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Питер Х. Селлерс (1974). «К теории и расчету эволюционных расстояний». Журнал прикладной математики . 26 (4): 787–793. дои : 10.1137/0126070 .
- ^ М. С. Уотерман; Т. Ф. Смит; В.А. Бейер (1976). «Некоторые показатели биологической последовательности» . Достижения в математике . 20 (3): 367–387. дои : 10.1016/0001-8708(76)90202-4 .
- ^ Перейти обратно: а б с Чоудхури, Резаул; Ле, Хай-Сон; Рамачандран, Виджая (июль 2010 г.). «Динамическое программирование без учета кэша для биоинформатики» . Транзакции IEEE/ACM по вычислительной биологии и биоинформатике . 7 (3): 495–510. дои : 10.1109/TCBB.2008.94 . ПМИД 20671320 . S2CID 2532039 .
- ^ Д.С. Хиршберг (1975). «Алгоритм линейного пространства для вычисления максимальных общих подпоследовательностей». Коммуникации АКМ . 18 (6): 341–343. CiteSeerX 10.1.1.348.4774 . дои : 10.1145/360825.360861 . S2CID 207694727 .
- ^ Возняк, Анджей (1997). «Использование видеоинструкций для ускорения сравнения последовательностей» . Компьютерные приложения в биологических науках . 13 (2): 145–50. дои : 10.1093/биоинформатика/13.2.145 . ПМИД 9146961 .
- ^ Перейти обратно: а б с Фаррар, Майкл С. (2007). «Striped Smith-Waterman ускоряет поиск в базе данных в шесть раз по сравнению с другими реализациями SIMD» . Биоинформатика . 23 (2): 156–161. doi : 10.1093/биоинформатика/btl582 . ПМИД 17110365 .
- ^ Чжао, Мэнъяо; Ли, Ван-Пин; Гаррисон, Эрик П.; Март, Габор Т. (4 декабря 2013 г.). «Библиотека SSW: библиотека SIMD Smith-Waterman C/C++ для использования в геномных приложениях» . ПЛОС ОДИН . 8 (12): е82138. arXiv : 1208.6350 . Бибкод : 2013PLoSO...882138Z . дои : 10.1371/journal.pone.0082138 . ПМЦ 3852983 . ПМИД 24324759 .
- ^ Документы по FPGA 100x: «Архивная копия» (PDF) . Архивировано из оригинала (PDF) 5 июля 2008 г. Проверено 17 октября 2007 г.
{{cite web}}: CS1 maint: archived copy as title (link), «Архивная копия» (PDF) . Архивировано из оригинала (PDF) 5 июля 2008 г. Проверено 17 октября 2007 г.{{cite web}}: CS1 maint: archived copy as title (link), and «Архивная копия» (PDF) . Архивировано из оригинала (PDF) 20 июля 2011 г. Проверено 17 октября 2007 г.{{cite web}}: CS1 maint: архивная копия в заголовке ( ссылка ) - ^ Progeniq Pte. Ltd., « Белая книга – Ускорение ресурсоемких приложений в 10–50 раз для устранения узких мест в вычислительных рабочих процессах ».
- ^ Вермидж, Эрик (2011). Выравнивание генетических последовательностей на суперкомпьютерной платформе (PDF) (магистерская диссертация). Делфтский технологический университет. Архивировано из оригинала (PDF) 30 сентября 2011 г. Проверено 17 августа 2011 г.
- ^ Лю, Ян; Хуанг, Уэйн; Джонсон, Джон; Вайдья, Шейла (2006). «Ускорение Смита-Уотермана с помощью графического процессора» . Вычислительная наука – ICCS 2006 . Конспекты лекций по информатике. Том. 3994. Спрингер. стр. 188–195 . дои : 10.1007/11758549_29 . ISBN 978-3-540-34385-1 .
- ^ «Биоинформатика, поиск и анализ высокопроизводительных последовательностей (информационный документ)» . ГеномКвест. Архивировано из оригинала 13 мая 2008 года . Проверено 9 мая 2008 г.
- ^ «Зона CUDA» . Нвидиа . Проверено 25 февраля 2010 г.
- ^ «НВИДИА Парабрикс» . NVIDIA . Проверено 11 июля 2024 г.
- ^ Рогнес, Торбьёрн; Сиберг, Эрлинг (2000). «Шестикратное ускорение поиска в базе данных последовательностей Смита – Уотермана с использованием параллельной обработки на обычных микропроцессорах» . Биоинформатика . 16 (8): 699–706. дои : 10.1093/биоинформатика/16.8.699 . ПМИД 11099256 .
- ^ Рогнес, Торбьёрн (2011). «Быстрый поиск в базе данных Смита – Уотермана с межпоследовательным распараллеливанием SIMD» . БМК Биоинформатика . 12 :221. дои : 10.1186/1471-2105-12-221 . ПМК 3120707 . ПМИД 21631914 .
- ^ Фаррар, Майкл С. (2008). «Оптимизация Смита-Уотермана для механизма сотовой широкополосной связи» . Архивировано из оригинала 12 февраля 2012 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь )
Внешние ссылки
[ редактировать ]- JAligner — Java-реализация алгоритма Смита – Уотермана с открытым исходным кодом.
- БАБА — апплет (с исходниками), наглядно объясняющий алгоритм
- FASTA/SSEARCH — страница услуг в EBI
- Плагин UGENE Smith – Waterman — SSEARCH-совместимая реализация алгоритма с открытым исходным кодом и графическим интерфейсом, написанная на C++.
- OPAL — библиотека SIMD C/C++ для массового оптимального выравнивания последовательностей.
- диагональсв — реализация C/C++ с открытым исходным кодом и наборами инструкций SIMD (в частности, SSE4.1) под лицензией MIT.
- SSW — библиотека C++ с открытым исходным кодом, предоставляющая API для реализации SIMD алгоритма Смита – Уотермана под лицензией MIT.
- выравнивание мелодической последовательности — реализация JavaScript для выравнивания мелодической последовательности
- DRAGMAP Порт C++ реализации Illumina DRAGEN FPGA.