Анализ чувствительности
Анализ чувствительности — это исследование того, как неопределенность выходных данных математической модели или системы (числовая или иная) может быть разделена и распределена по различным источникам неопределенности на входных данных. Связанной с этим практикой является анализ неопределенности , в котором большее внимание уделяется количественной оценке неопределенности и распространению неопределенности ; в идеале анализ неопределенности и чувствительности должен проводиться одновременно.
Процесс пересчета результатов при альтернативных предположениях для определения влияния переменной при анализе чувствительности может быть полезен для ряда целей: [1] включая:
- Проверка устойчивости результатов модели или системы в условиях неопределенности.
- Более глубокое понимание взаимосвязей между входными и выходными переменными в системе или модели.
- Снижение неопределенности за счет выявления входных данных модели, которые вызывают значительную неопределенность в выходных данных и поэтому должны быть в центре внимания для повышения надежности (возможно, путем дальнейших исследований).
- Поиск ошибок в модели (путем обнаружения неожиданных связей между входными и выходными данными).
- Упрощение модели — исправление входных данных модели, которые не влияют на выходные данные, или выявление и удаление избыточных частей структуры модели.
- Улучшение взаимодействия между разработчиками моделей и лицами, принимающими решения (например, делая рекомендации более достоверными, понятными, убедительными или убедительными).
- Поиск областей в пространстве входных факторов, для которых выходные данные модели максимальны или минимальны или соответствуют некоторому оптимальному критерию (см. оптимизацию и фильтрацию Монте-Карло).
- В случае калибровки моделей с большим количеством параметров первичный тест на чувствительность может облегчить этап калибровки, сосредоточив внимание на чувствительных параметрах. Незнание чувствительности параметров может привести к бесполезной трате времени на нечувствительные параметры. [2]
- Стремиться выявить важные связи между наблюдениями, входными данными модели и прогнозами или прогнозами, что приведет к разработке более эффективных моделей. [3] [4]
Обзор
[ редактировать ]( Математическая модель например, в биологии, изменении климата, экономике или технике) может быть очень сложной, и в результате ее взаимосвязь между входными и выходными данными может быть плохо понята. В таких случаях модель можно рассматривать как черный ящик , т.е. выходные данные представляют собой «непрозрачную» функцию входных данных. Довольно часто некоторые или все входные данные модели подвержены источникам неопределенности , включая ошибки измерения , отсутствие информации и плохое или частичное понимание движущих сил и механизмов. Эта неопределенность накладывает ограничения на нашу уверенность в ответе или результатах модели. Кроме того, моделям, возможно, придется учитывать естественную внутреннюю изменчивость системы (алеаторию), например возникновение стохастических событий. [5]
В моделях, включающих множество входных переменных, анализ чувствительности является важным компонентом построения модели и обеспечения качества. Национальные и международные агентства, участвующие в исследованиях по оценке воздействия , включили в свои руководства разделы, посвященные анализу чувствительности. Примерами являются Европейская комиссия (см., например, руководящие принципы оценки воздействия ), [6] Белого дома Административно-бюджетное управление , Межправительственная группа экспертов по изменению климата и руководящие принципы моделирования Агентства по охране окружающей среды США . [7]
Настройки, ограничения и связанные с ними проблемы
[ редактировать ]Настройки и ограничения
[ редактировать ]Выбор метода анализа чувствительности обычно диктуется рядом ограничений или настроек задачи. Некоторые из наиболее распространенных:
- Затраты на вычисления: анализ чувствительности почти всегда выполняется путем прогона модели (возможно, большого) количества раз, т.е. подход, основанный на выборке . [8] Это может стать серьезной проблемой, если
- Один прогон модели занимает значительное количество времени (минуты, часы или больше). Это не является чем-то необычным для очень сложных моделей.
- Модель имеет большое количество неопределенных входных данных. Анализ чувствительности — это, по сути, исследование многомерного входного пространства , размер которого растет экспоненциально с увеличением количества входных данных. См. проклятие размерности .
- Затраты на вычисления являются проблемой во многих практических анализах чувствительности. Некоторые методы снижения вычислительных затрат включают использование эмуляторов (для больших моделей) и методов скрининга (для уменьшения размерности задачи). Другой метод — использовать метод анализа чувствительности на основе событий для выбора переменных для приложений, ограниченных по времени. [9] Это метод выбора входной переменной (IVS), который собирает информацию об изменении входных и выходных данных системы с использованием анализа чувствительности для создания матрицы входных/выходных триггеров/событий, которая предназначена для отображения взаимосвязей между входными данными как причинами. которые запускают события, и выходные данные, описывающие фактические события. Причинно-следственная связь между причинами изменения состояния, т.е. входными переменными, и выходными параметрами системы эффектов определяет, какой набор входных данных оказывает реальное влияние на данный выходной результат. Этот метод имеет явное преимущество перед аналитическим и вычислительным методом IVS, поскольку он пытается понять и интерпретировать изменение состояния системы в кратчайшие сроки с минимальными вычислительными затратами. [9] [10]
- Коррелированные входные данные. Большинство распространенных методов анализа чувствительности предполагают независимость входных данных модели, но иногда входные данные могут быть сильно коррелированы. Это все еще незрелая область исследований, и окончательные методы еще не созданы.
- Нелинейность. Некоторые подходы к анализу чувствительности, например, основанные на линейной регрессии , могут неточно измерить чувствительность, когда реакция модели нелинейна по отношению к ее входным данным. В таких случаях измерения, основанные на дисперсии . более подходящими являются
- Множественные выходные данные. Практически все методы анализа чувствительности рассматривают один одномерный выходной результат модели, однако многие модели выдают большое количество, возможно, пространственных или временных данных. Обратите внимание, что это не исключает возможности проведения различных анализов чувствительности для каждого интересующего результата. Однако для моделей, в которых выходные данные коррелируют, показатели чувствительности может быть сложно интерпретировать.
Предположения против выводов
[ редактировать ]В анализе неопределенности и чувствительности существует решающий компромисс между тем, насколько скрупулезно аналитик исследует исходные предположения , и насколько широкими могут быть полученные в результате выводы . Эту точку зрения хорошо иллюстрирует эконометрик Эдвард Э. Лимер : [11] [12]
Я предложил форму организованного анализа чувствительности, которую я называю «анализом глобальной чувствительности», в котором выбирается окрестность альтернативных предположений и определяется соответствующий интервал выводов. Выводы считаются надежными только в том случае, если окрестность предположений достаточно широка, чтобы быть достоверными, а соответствующий интервал выводов достаточно узок, чтобы быть полезными.
Обратите внимание, что Лимер подчеркивает необходимость «достоверности» при выборе предположений. Самый простой способ признать модель недействительной — продемонстрировать, что она хрупка по отношению к неопределенности в предположениях, или показать, что ее предположения не были приняты «достаточно широко». Ту же концепцию выражает Джером Р. Равец, для которого плохое моделирование означает, что неопределенности во входных данных необходимо подавлять, чтобы результаты не стали неопределенными. [13]
Подводные камни и трудности
[ редактировать ]Некоторые распространенные трудности при анализе чувствительности включают:
- Слишком много входных данных модели для анализа. Для уменьшения размерности можно использовать экранирование. Другой способ справиться с проклятием размерности — использовать выборку на основе последовательностей с низким расхождением. [14]
- Модель работает слишком долго. Эмуляторы (включая HDMR ) могут сократить общее время за счет ускорения модели или уменьшения количества необходимых запусков модели.
- Недостаточно информации для построения вероятностных распределений входных данных. Распределения вероятностей можно построить на основе данных экспертов , хотя даже в этом случае построить распределения с большой уверенностью может оказаться затруднительно. Субъективность вероятностных распределений или диапазонов сильно повлияет на анализ чувствительности.
- Непонятна цель анализа. К проблеме применяются различные статистические тесты и меры и получаются различные ранжирования факторов. Вместо этого тест должен быть адаптирован к цели анализа, например, используется фильтрация Монте-Карло, если вас интересует, какие факторы наиболее ответственны за формирование высоких/низких значений выходных данных.
- Учитывается слишком много выходных данных модели. Это может быть приемлемо для обеспечения качества подмоделей, но этого следует избегать при представлении результатов общего анализа.
- Кусочная чувствительность. Это когда анализ чувствительности выполняется по одной подмодели за раз. Этот подход неконсервативен, поскольку он может упускать из виду взаимодействие между факторами в различных подмоделях (ошибка II рода).
Методы анализа чувствительности
[ редактировать ]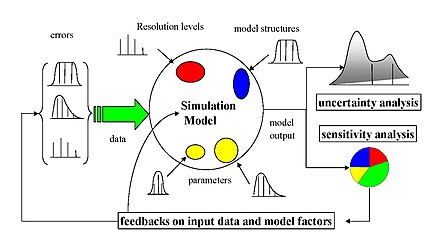

Существует большое количество подходов к проведению анализа чувствительности, многие из которых были разработаны для устранения одного или нескольких ограничений, обсуждавшихся выше. Они также различаются по типу меры чувствительности, будь то на основе (например) дисперсионного разложения , частных производных или элементарных эффектов . Однако в целом большинство процедур придерживаются следующей схемы:
- Определите количественно неопределенность каждого входного параметра (например, диапазоны, распределения вероятностей). Обратите внимание, что это может быть сложно, и существует множество методов для определения распределения неопределенности на основе субъективных данных. [15]
- Определите выходные данные модели, подлежащие анализу (цель интереса в идеале должна иметь прямое отношение к проблеме, решаемой моделью).
- Запустите модель несколько раз, используя определенный план экспериментов . [16] диктуется выбором метода и входной неопределенностью.
- Используя полученные результаты модели, рассчитайте интересующие показатели чувствительности.
В некоторых случаях эта процедура будет повторяться, например, в задачах большой размерности, когда пользователю приходится отсеивать несущественные переменные перед выполнением полного анализа чувствительности.
Различные типы «основных методов» (обсуждаемые ниже) отличаются различными рассчитываемыми показателями чувствительности. Эти категории могут каким-то образом пересекаться. Могут быть предложены альтернативные способы получения этих показателей с учетом ограничений проблемы.
По одному (ОАТ)
[ редактировать ]Один из самых простых и распространенных подходов — это изменение по одному фактору за раз (OAT), чтобы увидеть, какое влияние это окажет на результат. [17] [18] [19] ОАТ обычно включает в себя
- перемещение одной входной переменной, сохранение базовых (номинальных) значений других, затем
- возвращая переменной ее номинальное значение, а затем повторяя действия для каждого из остальных входов таким же образом.
Чувствительность затем можно измерить путем мониторинга изменений выходных данных, например, с помощью частных производных или линейной регрессии . Это кажется логичным подходом, поскольку любое изменение, наблюдаемое в выходных данных, будет однозначно связано с изменением одной переменной. Более того, изменяя одну переменную за раз, можно сохранить центральные или базовые значения всех остальных переменных. Это увеличивает сопоставимость результатов (все «эффекты» рассчитываются относительно одной и той же центральной точки пространства) и сводит к минимуму вероятность сбоя компьютерной программы, что более вероятно, когда несколько входных факторов изменяются одновременно.Разработчики моделей часто предпочитают OAT по практическим причинам. В случае сбоя модели при анализе OAT разработчик модели немедленно узнает, какой входной фактор ответственен за сбой.
Однако, несмотря на свою простоту, этот подход не полностью исследует входное пространство, поскольку не учитывает одновременное изменение входных переменных. Это означает, что подход OAT не может обнаружить наличие взаимодействий между входными переменными и непригоден для нелинейных моделей. [20]
Доля входного пространства, которая остается неисследованной при использовании подхода OAT, растет суперэкспоненциально с увеличением количества входных данных. Например, пространство параметров с тремя переменными, которое исследуется по одной, эквивалентно взятию точек вдоль осей x, y и z куба с центром в начале координат. Выпуклая оболочка, ограничивающая все эти точки, представляет собой октаэдр , объем которого составляет лишь 1/6 от общего пространства параметров. В более общем смысле, выпуклая оболочка осей гиперпрямоугольника образует гипероктаэдр , объемная доля которого составляет . При наличии 5 входов исследуемое пространство уже падает до менее 1% от общего пространства параметров. И даже это завышенная оценка, поскольку внеосевой объем фактически вообще не дискретизируется. Сравните это со случайной выборкой пространства, где выпуклая оболочка приближается ко всему объему по мере добавления новых точек. [21] Хотя разреженность OAT теоретически не является проблемой для линейных моделей , истинная линейность в природе встречается редко.

Локальные методы на основе производных
[ редактировать ]Методы, основанные на локальной производной, включают в себя получение частной производной выходного сигнала Y по входному коэффициенту X i :

где индекс x 0 указывает, что производная берется в некоторой фиксированной точке входного пространства (отсюда и слово «локальный» в названии класса). Сопряженное моделирование [22] [23] и автоматическая дифференциация [24] — это методы, которые позволяют вычислять все частные производные затрачивая максимум в 4–6 раз больше, чем затраты на вычисление исходной функции. Подобно OAT, локальные методы не пытаются полностью исследовать входное пространство, поскольку они исследуют небольшие возмущения, обычно по одной переменной за раз. Можно выбрать аналогичные образцы на основе чувствительности на основе производных с помощью нейронных сетей и выполнить количественную оценку неопределенности.
Одним из преимуществ локальных методов является то, что можно составить матрицу для представления всех уязвимостей системы, обеспечивая таким образом обзор, которого невозможно достичь с помощью глобальных методов, если имеется большое количество входных и выходных переменных.
Регрессионный анализ
[ редактировать ]Регрессионный анализ в контексте анализа чувствительности включает в себя подгонку линейной регрессии к отклику модели и использование стандартизированных коэффициентов регрессии в качестве прямых мер чувствительности. Регрессия должна быть линейной по отношению к данным (т. е. гиперплоскости, следовательно, без квадратичных членов и т. д. в качестве регрессоров), поскольку в противном случае трудно интерпретировать стандартизованные коэффициенты. Поэтому этот метод наиболее подходит, когда реакция модели фактически линейна; линейность может быть подтверждена, например, если коэффициент детерминации велик. Преимущества регрессионного анализа заключаются в его простоте и низких вычислительных затратах.
Методы, основанные на дисперсии
[ редактировать ]Методы, основанные на дисперсии [26] представляют собой класс вероятностных подходов, которые количественно определяют входные и выходные неопределенности как распределения вероятностей и разлагают выходную дисперсию на части, относящиеся к входным переменным и комбинациям переменных. Таким образом, чувствительность выходных данных к входной переменной измеряется величиной отклонений выходных данных, вызванных этими входными данными. Их можно выразить как условные ожидания, т. е., рассматривая модель Y = f ( X ) для X = { X 1 , X 2 , ... X k }, мера чувствительности i -й переменной X i задается как ,

где «Var» и « E » обозначают операторы дисперсии и ожидаемого значения соответственно, а X ~i обозначает набор всех входных переменных, кроме X i . Это выражение по существу измеряет вклад только X i в неопределенность (дисперсию) Y (усредненную по вариациям других переменных) и известно как индекс чувствительности первого порядка или индекс основного эффекта . Важно отметить, что он не измеряет неопределенность, вызванную взаимодействием с другими переменными. Дополнительная мера, известная как индекс общего эффекта , дает общую дисперсию Y , вызванную X i и его взаимодействием с любой другой входной переменной. Обе величины обычно стандартизируются путем деления на Var( Y ).
Методы, основанные на дисперсии, позволяют полностью исследовать входное пространство, учитывать взаимодействия и нелинейные реакции. По этим причинам они широко используются, когда возможно их вычислить. Обычно этот расчет включает использование методов Монте-Карло , но, поскольку он может включать в себя многие тысячи прогонов модели, при необходимости можно использовать другие методы (например, эмуляторы) для сокращения вычислительных затрат.
Вариограммный анализ поверхностей отклика ( VARS )
[ редактировать ]Одним из основных недостатков предыдущих методов анализа чувствительности является то, что ни один из них не учитывает пространственно упорядоченную структуру поверхности отклика/выходных данных модели Y = f ( X ) в пространстве параметров. Используя концепции направленных вариограмм и ковариограмм, вариограммный анализ поверхностей отклика (VARS) устраняет этот недостаток путем распознавания пространственно непрерывной структуры корреляции со значениями Y и, следовательно, также со значениями . [27] [28]

По сути, чем выше изменчивость, тем более неоднородной является поверхность отклика в определенном направлении/параметре в определенном масштабе возмущений. Соответственно, в рамках VARS значения направленных вариограмм для данного масштаба возмущений можно рассматривать как комплексную иллюстрацию информации о чувствительности путем увязки анализа вариограмм с концепциями как направления, так и масштаба возмущений. В результате структура VARS учитывает тот факт, что чувствительность является концепцией, зависящей от масштаба, и, таким образом, преодолевает проблему масштаба традиционных методов анализа чувствительности. [29] Что еще более важно, VARS способен обеспечить относительно стабильные и статистически надежные оценки чувствительности параметров при гораздо меньших вычислительных затратах, чем другие стратегии (примерно на два порядка более эффективные). [30] Примечательно, что было показано, что существует теоретическая связь между структурой VARS и подходами, основанными на дисперсии и производной.
Альтернативные методы
[ редактировать ]Был разработан ряд методов для преодоления некоторых из ограничений, обсуждавшихся выше, которые в противном случае сделали бы оценку показателей чувствительности невозможной (чаще всего из-за вычислительных затрат ). Как правило, эти методы направлены на эффективный расчет показателей чувствительности на основе дисперсии.
Эмуляторы
[ редактировать ]Эмуляторы (также известные как метамодели, суррогатные модели или поверхности отклика) — это подходы к моделированию данных / машинному обучению , которые включают в себя создание относительно простой математической функции, известной как эмулятор , которая аппроксимирует поведение ввода/вывода самой модели. [31] Другими словами, это понятие «моделирование модели» (отсюда и название «метамодель»). Идея состоит в том, что, хотя компьютерные модели могут представлять собой очень сложную серию уравнений, решение которых может занять много времени, их всегда можно рассматривать как функцию входных данных Y = f ( X ). Запустив модель в нескольких точках входного пространства, можно будет подобрать гораздо более простой эмулятор η ( X ), такой, что η ( X ) ≈ f ( X ) с допустимой погрешностью. [32] Затем меры чувствительности можно рассчитать с помощью эмулятора (либо с помощью Монте-Карло, либо аналитически), что потребует незначительных дополнительных вычислительных затрат. Важно отметить, что количество прогонов модели, необходимых для адаптации к эмулятору, может быть на порядки меньше, чем количество прогонов, необходимых для непосредственной оценки показателей чувствительности модели. [33]
Очевидно, что суть подхода к эмулятору состоит в том, чтобы найти η (эмулятор), который является достаточно близким приближением к модели f . Для этого необходимо выполнить следующие шаги,
- Выборка (запуск) модели в нескольких точках ее входного пространства. Для этого необходим образец дизайна.
- Выбор типа эмулятора (математической функции) для использования.
- «Обучение» эмулятора с использованием образцов данных из модели — обычно это включает в себя настройку параметров эмулятора до тех пор, пока эмулятор не будет максимально имитировать истинную модель.
Выборка модели часто может выполняться с использованием последовательностей с низким расхождением , таких как последовательность Соболя , предложенная математиком Ильей М. Соболем , или выборка латинского гиперкуба , хотя можно также использовать случайные планы, но с потерей некоторой эффективности. Выбор типа эмулятора и обучение неразрывно связаны, поскольку метод обучения будет зависеть от класса эмулятора. Некоторые типы эмуляторов, которые успешно использовались для анализа чувствительности, включают:
- Гауссовские процессы [33] (также известный как кригинг ), где предполагается, что любая комбинация выходных точек распределяется как многомерное распределение Гаусса . Недавно «деревовидные» гауссовские процессы стали использоваться для работы с гетероскедастическими и прерывистыми реакциями. [34] [35]
- Случайные леса , [31] большое количество деревьев решений и усредняется результат. в котором обучается
- Повышение градиента , [31] где последовательность простых регрессий используется для взвешивания точек данных с целью последовательного уменьшения ошибки.
- Полиномиальные разложения хаоса , [36] которые используют ортогональные полиномы для аппроксимации поверхности отклика.
- Сглаживание сплайнов , [37] обычно используется в сочетании с усечениями HDMR (см. ниже).
- Дискретные байесовские сети , [38] в сочетании с каноническими моделями, такими как шумные модели. Шумные модели используют информацию об условной независимости между переменными, чтобы значительно уменьшить размерность.
Использование эмулятора создает проблему машинного обучения , которая может оказаться сложной, если реакция модели сильно нелинейна . Во всех случаях полезно проверить точность работы эмулятора, например, с помощью перекрестной проверки .
Представления многомерных моделей (HDMR)
[ редактировать ]( Представление многомерной модели HDMR) [39] [40] (термин принадлежит Х. Рабицу [41] ) по сути представляет собой подход эмулятора, который включает в себя разложение вывода функции на линейную комбинацию входных терминов и взаимодействий возрастающей размерности. Подход HDMR использует тот факт, что модель обычно можно хорошо аппроксимировать, пренебрегая взаимодействиями более высокого порядка (второго или третьего порядка и выше). Затем каждый из членов усеченного ряда может быть аппроксимирован, например, полиномами или сплайнами (REFS), а ответ выражен как сумма основных эффектов и взаимодействий до порядка усечения. С этой точки зрения HDMR можно рассматривать как эмуляторы, которые пренебрегают взаимодействиями высокого порядка; Преимущество состоит в том, что они способны эмулировать модели более высокой размерности, чем эмуляторы полного порядка.
Тест амплитудной чувствительности Фурье (FAST)
[ редактировать ]Тест амплитудной чувствительности Фурье (FAST) использует ряд Фурье для представления многомерной функции (модели) в частотной области с использованием одной частотной переменной. Таким образом, интегралы, необходимые для расчета индексов чувствительности, становятся одномерными, что приводит к экономии вычислительных ресурсов.
Фильтрация Монте-Карло
[ редактировать ]Анализ чувствительности с помощью фильтрации Монте-Карло [42] также является подходом, основанным на выборке, целью которого является выявление областей в пространстве входных факторов, соответствующих конкретным значениям (например, высоким или низким) выходных данных.
Эффекты Шепли
[ редактировать ]Эффекты Шепли основаны на значениях Шепли и представляют собой средний предельный вклад данного фактора во все возможные комбинации факторов. Эти значения связаны с индексами Соболя, поскольку их значение находится между эффектом Соболя первого порядка и эффектом общего порядка. [43]
Приложения
[ редактировать ]Примеры анализа чувствительности можно найти в различных областях применения, таких как:
- Науки об окружающей среде
- Бизнес
- Социальные науки
- Химия
- Инженерное дело
- Эпидемиология
- Мета-анализ
- Многокритериальное принятие решений
- Принятие срочных решений
- Калибровка модели
- Количественная оценка неопределенности
- Теория хаоса
- В популяционной генетике . Станет ли популяция хаотичной, когда наступит период стохастичности. [44] : 183
Аудит чувствительности
[ редактировать ]Может случиться так, что анализ чувствительности исследования, основанного на модели, предназначен для обоснования вывода и подтверждения его надежности в контексте, когда вывод влияет на политику или процесс принятия решений. В этих случаях структура самого анализа, его институциональный контекст и мотивы его автора могут стать вопросом огромной важности, а чистый анализ чувствительности – с его акцентом на параметрической неопределенности – может рассматриваться как недостаточный. Акцент на формулировке может быть обусловлен, среди прочего, актуальностью политического исследования для различных групп населения, которые характеризуются разными нормами и ценностями, и, следовательно, из-за разной истории о том, «в чем проблема» и, прежде всего, о том, «кто говорит история». Чаще всего формулировка включает в себя более или менее неявные предположения, которые могут быть как политическими (например, какая группа нуждается в защите), так и техническими (например, какую переменную можно рассматривать как константу).
Чтобы принять во внимание эти опасения, инструменты SA были расширены, чтобы обеспечить оценку всего процесса создания знаний и моделей. Этот подход получил название «аудит чувствительности». Он черпает вдохновение из NUSAP, [45] метод, используемый для определения ценности количественной информации с помощью создания «родословных» чисел. Аудит чувствительности был специально разработан для состязательного контекста, когда не только характер доказательств, но также степень определенности и неопределенности, связанных с доказательствами, будут предметом партийных интересов. [46] Аудит чувствительности рекомендуется в руководящих принципах Европейской комиссии по оценке воздействия. [6] а также в отчете «Научные рекомендации для политики европейских академий». [47]
Связанные понятия
[ редактировать ]Анализ чувствительности тесно связан с анализом неопределенности; в то время как последний изучает общую неопределенность в выводах исследования, анализ чувствительности пытается определить, какой источник неопределенности больше влияет на выводы исследования.
Постановка задачи анализа чувствительности также имеет большое сходство с областью планирования экспериментов . [48] При планировании экспериментов изучается влияние некоторого процесса или вмешательства («лечение») на некоторые объекты («экспериментальные единицы»). При анализе чувствительности рассматривается влияние изменения входных данных математической модели на выходные данные самой модели. В обеих дисциплинах стремятся получить информацию от системы с минимумом физических или численных экспериментов.
См. также
[ редактировать ]- Причинность
- Метод элементарных эффектов
- Экспериментальный анализ неопределенности
- Тестирование амплитудной чувствительности Фурье
- Теория принятия решений при информационном дефиците
- Интервал ПЯТЬ
- Анализ возмущений
- Вероятностный дизайн
- Анализ границ вероятности
- Робастификация
- ROC-кривая
- Количественная оценка неопределенности
- Анализ чувствительности на основе отклонений
- Анализ мультивселенной
- Выбор функции
Ссылки
[ редактировать ]- ^ Паннелл, диджей (1997). «Анализ чувствительности нормативных экономических моделей: теоретическая основа и практические стратегии» (PDF) . Экономика сельского хозяйства . 16 (2): 139–152. doi : 10.1016/S0169-5150(96)01217-0 (неактивен 8 мая 2024 г.).
{{cite journal}}: CS1 maint: DOI неактивен по состоянию на май 2024 г. ( ссылка ) - ^ Бахреманд, А.; Де Смедт, Ф. (2008). «Распределенное гидрологическое моделирование и анализ чувствительности в водоразделе Ториса, Словакия». Управление водными ресурсами . 22 (3): 293–408. Бибкод : 2008WatRM..22..393B . дои : 10.1007/s11269-007-9168-x . S2CID 9710579 .
- ^ Хилл, М.; Кавецкий, Д.; Кларк, М.; Йе, М.; Араби, М.; Лу, Д.; Фолья, Л.; Мель, С. (2015). «Практическое использование вычислительно-экономных методов анализа моделей» . Подземные воды . 54 (2): 159–170. дои : 10.1111/gwat.12330 . ОСТИ 1286771 . ПМИД 25810333 .
- ^ Хилл, М.; Тидеман, К. (2007). Эффективная калибровка модели подземных вод с анализом данных, чувствительности, прогнозов и неопределенностей . Джон Уайли и сыновья.
- ^ Дер Кюрегян А.; Дитлевсен, О. (2009). «Алеаторный или эпистемический? Имеет ли это значение?». Структурная безопасность . 31 (2): 105–112. doi : 10.1016/j.strusafe.2008.06.020 .
- ^ Jump up to: а б Европейская комиссия. 2021. «Набор инструментов для лучшего регулирования». 25 ноября.
- ^ «Архивная копия» (PDF) . Архивировано из оригинала (PDF) 26 апреля 2011 г. Проверено 16 октября 2009 г.
{{cite web}}: CS1 maint: архивная копия в заголовке ( ссылка ) - ^ Хелтон, Джей Си; Джонсон, доктор юридических наук; Салаберри, CJ; Сторли, CB (2006). «Обзор методов выборочного анализа неопределенности и чувствительности» . Инженерия надежности и системная безопасность . 91 (10–11): 1175–1209. дои : 10.1016/j.ress.2005.11.017 .
- ^ Jump up to: а б Таваколи, Сиамак; Мусави, Алиреза (2013). «Отслеживание событий для неосознанного анализа чувствительности в реальном времени (EventTracker)» . Транзакции IEEE по знаниям и инженерии данных . 25 (2): 348–359. дои : 10.1109/tkde.2011.240 . S2CID 17551372 .
- ^ Таваколи, Сиамак; Мусави, Алиреза; Послад, Стефан (2013). «Выбор входной переменной в срочных приложениях интеграции знаний: обзор, анализ и рекомендации» . Высшая инженерная информатика . 27 (4): 519–536. дои : 10.1016/j.aei.2013.06.002 .
- ^ Лимер, Эдвард Э. (1983). «Давайте устраним мошенничество из эконометрики». Американский экономический обзор . 73 (1): 31–43. JSTOR 1803924 .
- ^ Лимер, Эдвард Э. (1985). «Анализ чувствительности поможет». Американский экономический обзор . 75 (3): 308–313. JSTOR 1814801 .
- ^ Равец, младший, 2007, Серьезный путеводитель по науке , New Internationalist Publications Ltd.
- ^ Цветкова О.; Уарда, TBMJ (2019). «Техника квази-Монте-Карло в глобальном анализе чувствительности оценки ветровых ресурсов с исследованием ОАЭ» (PDF) . Журнал возобновляемой и устойчивой энергетики . 11 (5): 053303. дои : 10.1063/1.5120035 . S2CID 208835771 .
- ^ О'Хаган, А.; и др. (2006). Неопределенные суждения: выявление вероятностей экспертов . Чичестер: Уайли. ISBN 9780470033302 .
- ^ Сакс, Дж.; Уэлч, WJ; Митчелл, Ти Джей; Винн, HP (1989). «Планирование и анализ компьютерных экспериментов» . Статистическая наука . 4 (4): 409–435. дои : 10.1214/ss/1177012413 .
- ^ Кэмпбелл, Дж.; и др. (2008). «Фотосинтетический контроль содержания карбонилсульфида в атмосфере в течение вегетационного периода» . Наука . 322 (5904): 1085–1088. Бибкод : 2008Sci...322.1085C . дои : 10.1126/science.1164015 . ПМИД 19008442 . S2CID 206515456 .
- ^ Бейлис, Р.; Эззати, М.; Каммен, Д. (2005). «Смертность и влияние парниковых газов на будущее биомассы и нефтяной энергетики в Африке». Наука . 308 (5718): 98–103. Бибкод : 2005Sci...308...98B . дои : 10.1126/science.1106881 . ПМИД 15802601 . S2CID 14404609 .
- ^ Мерфи, Дж.; и др. (2004). «Количественная оценка неопределенностей моделирования в большом ансамбле симуляций изменения климата». Природа . 430 (7001): 768–772. Бибкод : 2004Natur.430..768M . дои : 10.1038/nature02771 . ПМИД 15306806 . S2CID 980153 .
- ^ Цитром, Вероника (1999). «Однофакторные и спланированные эксперименты». Американский статистик . 53 (2): 126–131. дои : 10.2307/2685731 . JSTOR 2685731 .
- ^ Гацурас, Д; Яннопулос, А (2009). «Порог объема, охватываемого случайными точками с независимыми координатами» . Израильский математический журнал . 169 (1): 125–153. дои : 10.1007/s11856-009-0007-z .
- ^ Какучи, Дэн Г. Анализ чувствительности и неопределенности: теория . Том. И. Чепмен и Холл.
- ^ Какучи, Дэн Г.; Ионеску-Бужор, Михаэла; Навон, Майкл (2005). Анализ чувствительности и неопределенности: приложения к крупномасштабным системам . Том. II. Чепмен и Холл.
- ^ Гриванк, А. (2000). Вычисление производных, принципы и методы алгоритмического дифференцирования . СИАМ.
- ^ Кабир Х.Д., Хосрави А., Нахаванди Д., Нахаванди С. Нейронная сеть количественной оценки неопределенности на основе сходства и чувствительности. Международная совместная конференция по нейронным сетям In2020 (IJCNN), 19 июля 2020 г. (стр. 1–8). IEEE.
- ^ Соболь, Я (1990). «Оценки чувствительности нелинейных математических моделей». Математическое моделирование . 2 : 112–118. ; переведено на английский язык в Соболь, Я (1993). «Анализ чувствительности нелинейных математических моделей». Математическое моделирование и вычислительный эксперимент . 1 : 407–414.
- ^ Разави, Саман; Гупта, Хосин В. (январь 2016 г.). «Новая основа для комплексного, надежного и эффективного глобального анализа чувствительности: 1. Теория» . Исследования водных ресурсов . 52 (1): 423–439. Бибкод : 2016WRR....52..423R . дои : 10.1002/2015WR017558 . ISSN 1944-7973 .
- ^ Разави, Саман; Гупта, Хосин В. (январь 2016 г.). «Новая основа для всестороннего, надежного и эффективного глобального анализа чувствительности: 2. Применение» . Исследования водных ресурсов . 52 (1): 440–455. Бибкод : 2016WRR....52..440R . дои : 10.1002/2015WR017559 . ISSN 1944-7973 .
- ^ Хагнегадар, Амин; Разави, Саман (сентябрь 2017 г.). «Анализ чувствительности моделей Земли и экологических систем: влияние масштаба возмущения параметров». Экологическое моделирование и программное обеспечение . 95 : 115–131. Бибкод : 2017EnvMS..95..115H . дои : 10.1016/j.envsoft.2017.03.031 .
- ^ Гупта, Х; Разави, С (2016). «Проблемы и перспективы анализа чувствительности» . В Петропулосе, Джордж; Шривастава, Прашант (ред.). Анализ чувствительности при моделировании наблюдения Земли (1-е изд.). Эльзевир. стр. 397–415. ISBN 9780128030318 .
- ^ Jump up to: а б с Сторли, CB; Свилер, LP; Хелтон, Джей Си; Саллаберри, CJ (2009). «Внедрение и оценка процедур непараметрической регрессии для анализа чувствительности моделей, требующих вычислительных затрат». Проектирование надежности и системная безопасность . 94 (11): 1735–1763. дои : 10.1016/j.ress.2009.05.007 .
- ^ Ван, Шаньин; Фан, Кай; Луо, Нан; Цао, Янсяолу; Ву, Фейлун; Чжан, Кэролайн; Хеллер, Кэтрин А.; Ты, Линчун (25 сентября 2019 г.). «Массовое ускорение вычислений за счет использования нейронных сетей для эмуляции биологических моделей, основанных на механизмах» . Природные коммуникации . 10 (1): 4354. Бибкод : 2019NatCo..10.4354W . дои : 10.1038/s41467-019-12342-y . ISSN 2041-1723 . ПМК 6761138 . ПМИД 31554788 .
- ^ Jump up to: а б Окли, Дж.; О'Хаган, А. (2004). «Вероятностный анализ чувствительности сложных моделей: байесовский подход». JR Стат. Соц. Б. 66 (3): 751–769. CiteSeerX 10.1.1.6.9720 . дои : 10.1111/j.1467-9868.2004.05304.x . S2CID 6130150 .
- ^ Грамейси, РБ; Тедди, Массачусетс (2010). «Категорические входные данные, анализ чувствительности, оптимизация и регулирование важности с помощью tgp версии 2, пакета R для древовидных моделей гауссовских процессов» (PDF) . Журнал статистического программного обеспечения . 33 (6). дои : 10.18637/jss.v033.i06 .
- ^ Беккер, В.; Уорден, К.; Роусон, Дж. (2013). «Байесовский анализ чувствительности бифуркационных нелинейных моделей» . Механические системы и обработка сигналов . 34 (1–2): 57–75. Бибкод : 2013MSSP...34...57B . дои : 10.1016/j.ymssp.2012.05.010 .
- ^ Судрет, Б. (2008). «Анализ глобальной чувствительности с использованием полиномиальных разложений хаоса». Проектирование надежности и системная безопасность . 93 (7): 964–979. дои : 10.1016/j.ress.2007.04.002 .
- ^ Ратто, М.; Пагано, А. (2010). «Использование рекурсивных алгоритмов для эффективной идентификации сглаживающих сплайн-моделей ANOVA». AStA: достижения в области статистического анализа . 94 (4): 367–388. дои : 10.1007/s10182-010-0148-8 . S2CID 7678955 .
- ^ Карденас, IC (2019). «Об использовании байесовских сетей в качестве подхода к метамоделированию для анализа неопределенностей при анализе устойчивости склонов». Геориск: оценка и управление рисками для инженерных систем и опасных геологических процессов . 13 (1): 53–65. Бибкод : 2019GAMRE..13...53C . дои : 10.1080/17499518.2018.1498524 . S2CID 216590427 .
- ^ Ли, Г.; Ху, Дж.; Ван, Юго-Западный; Георгопулос, П.; Шендорф, Дж.; Рабиц, Х. (2006). «Представление многомерной модели случайной выборки (RS-HDMR) и ортогональность ее функций компонентов различного порядка». Журнал физической химии А. 110 (7): 2474–2485. Бибкод : 2006JPCA..110.2474L . дои : 10.1021/jp054148m . ПМИД 16480307 .
- ^ Ли, Г. (2002). «Практические подходы к построению функций компонента RS-HDMR». Журнал физической химии . 106 (37): 8721–8733. Бибкод : 2002JPCA..106.8721L . дои : 10.1021/jp014567t .
- ^ Рабиц, Х. (1989). «Системный анализ на молекулярном уровне». Наука . 246 (4927): 221–226. Бибкод : 1989Sci...246..221R . дои : 10.1126/science.246.4927.221 . ПМИД 17839016 . S2CID 23088466 .
- ^ Хорнбергер, Г.; Спир, Р. (1981). «Подход к предварительному анализу экологических систем». Журнал экологического менеджмента . 7 :7–18.
- ^ Оуэн, AB (1 января 2014 г.). «Индексы Соболя и стоимость Шепли». Журнал SIAM/ASA по количественной оценке неопределенности . 2 (1). Общество промышленной и прикладной математики: 245–251. дои : 10.1137/130936233 .
- ^ Перри, Джо; Смит, Роберт; Войвод, Ян; Морс, Дэвид (2000). Перри, Джо Н; Смит, Роберт Х; Войвод, Ян П; Морс, Дэвид Р. (ред.). Хаос в реальных данных: анализ нелинейной динамики на основе коротких экологических временных рядов . Серия по популяционной и общественной биологии (1-е изд.). Springer Science+Business Media Дордрехт . стр. xii+226. дои : 10.1007/978-94-011-4010-2 . ISBN 978-94-010-5772-1 . S2CID 37855255 .
- ^ Ван дер Слейс, JP; Крей, М; Фунтович, С; Клопрогге, П; Равец, Дж; Рисби, Дж (2005). «Сочетание количественных и качественных показателей неопределенности в экологической оценке на основе моделей: система NUSAP». Анализ рисков . 25 (2): 481–492. Бибкод : 2005РискА..25..481В . дои : 10.1111/j.1539-6924.2005.00604.x . hdl : 1874/386039 . ПМИД 15876219 . S2CID 15988654 .
- ^ Ло Пиано, С; Робинсон, М (2019). «Экономические оценки питания и общественного здравоохранения под призмой постнормальной науки». Фьючерсы . 112 : 102436. doi : 10.1016/j.futures.2019.06.008 . S2CID 198636712 .
- ^ Научные рекомендации для политики европейских академий, Осмысление науки для политики в условиях сложности и неопределенности, Берлин, 2019.
- ^ Вставка GEP, Hunter WG, Хантер, Дж. Стюарт. Статистика для экспериментаторов [Интернет]. Нью-Йорк: Wiley & Sons
Дальнейшее чтение
[ редактировать ]- Каннаво, Ф. (2012). «Анализ чувствительности для оценки качества моделирования вулканических источников и выбора модели». Компьютеры и геонауки . 44 : 52–59. Бибкод : 2012CG.....44...52C . дои : 10.1016/j.cageo.2012.03.008 .
- Фассо А. (2007) «Статистический анализ чувствительности и качество воды». В книге Уаймер Л. Эд, Статистическая основа критериев и мониторинга качества воды . Уайли, Нью-Йорк.
- Фассо А., Перри П.Ф. (2002) «Анализ чувствительности». Абделя Х. Эль-Шарави и Уолтера В. Пигорша (редакторы) В Энциклопедии экологической метрики , том 4, стр. 1968–1982, Wiley.
- Фассо А., Эспозито Э., Порку Э., Ревербери А.П., Вельо Ф. (2003) «Статистический анализ чувствительности насадочных колонных реакторов к загрязненным сточным водам». Экологометрия . Том. 14, № 8, 743–759.
- Хауг, Эдвард Дж.; Чой, Кён К.; Комков, Вадим (1986) Анализ чувствительности конструктивных систем . Математика в науке и технике, 177. Academic Press, Inc., Орландо, Флорида.
- Пианози, Ф.; Бевен, К.; Фрир, Дж.; Холл, JW; Ружье, Дж.; Стивенсон, Д.Б.; Вагенер, Т. (2016). «Анализ чувствительности моделей окружающей среды: систематический обзор с практическим рабочим процессом» . Экологическое моделирование и программное обеспечение . 79 : 214–232. Бибкод : 2016EnvMS..79..214P . дои : 10.1016/j.envsoft.2016.02.008 . hdl : 10871/21086 .
- Пилки, Огайо и Л. Пилки-Джарвис (2007), Бесполезная арифметика. Почему ученые-экологи не могут предсказать будущее. Нью-Йорк: Издательство Колумбийского университета.
- Сантнер, Ти Джей; Уильямс, Би Джей; Нотц, Висконсин (2003) Планирование и анализ компьютерных экспериментов ; Спрингер-Верлаг.
- Талеб, Н.Н., (2007) Черный лебедь: влияние крайне невероятного, Random House.
Внешние ссылки
[ редактировать ]- Веб-сайт с материалами серии конференций САМО (1995-2025 гг.)
- веб-страница по анализу чувствительности – (Объединенный исследовательский центр Европейской комиссии)
- Проект MUCM. Архивировано 24 апреля 2013 г. в Wayback Machine . Обширные ресурсы для анализа неопределенности и чувствительности моделей, требующих вычислительных затрат.